
基于自监督学习语言模型的罪名预测研究
2023-02-14 10:32:12田杰文毛国庆林鸿飞
计算机工程与应用 2023年3期
田杰文,杨 亮,张 琍,毛国庆,林鸿飞
1.大连海洋大学 信息工程学院,辽宁 大连 116023
2.大连理工大学 辽宁 大连 116024
3.北京计算机技术及应用研究所,北京 100854
4.北京国双科技有限公司,北京 100083
在过去的几年里,司法领域所产生的数据量增长迅速。自然语言处理是一个成熟的人工智能的子领域,其中利用人工智能进行法律判决预测[1-2]在司法领域的应用逐渐变得成熟,法律判决预测任务是计算机在阅读案件的事实描述之后进行预测该法律案件的判决结果的过程,这一过程包括罪名预测、刑期预测、罚金预测等。利用人工智能进行法律判决预测一方面可以以更廉价方式为不熟悉法律的人提供更简单高效的获取高质量法律资源的途径,另一方面也可以为法律从业者提供一定程度的法律参考有助于提高其工作效率以及减少因人为因素而带来的不必要的麻烦。从另一个角度来看,充分利用人工智能进行法律判决预测也有利于提升司法部门的工作效率,还能响应号召进一步推动司法系统的公平公正公开透明。
中国大陆是大陆法系的实行地区,法院只利用案件的事件陈述和成文法进行法律判决,而不会参考判例的判决,法官会根据案件所涉及的相关法律条款以及该案件的事实陈述,结合现实具体情况综合考量做出最终判决。
现有大多数的工作都是试图将法律判决任务形式化为文本分类任务,这些工作一般采用现成的分类模型[3-5]从文本中提取浅层特征[6-7],或将案例归档[8],或通过手工注释案例和设计具体特征来获得对案例描述的更深层次的语义理解[9],或者采用机器学习和自然语言处理的神经网络方法,可以更好地对法律文本进行分析处理[10-12]。
本文旨在通过引入适当的机制,利用神经网络模型将刑事案件的文本事实描述与法律条款相结合来解决罪名预测问题,为了更好地理解法律文书和更具体的表述,综合分析了相关的法律条款和裁判文书,总结形成了分类模型,然后利用现有的神经网络模型结合自监督学习方法学习文本特征,再将句子级特征合并为案例级特征后,通过神经网络模型来解决罪名预测问题。在实验中,采用2018“中国法研杯”司法人工智能挑战赛构建的数据集[13]。实验结果表明,本文的方法和模型与对比模型相比能够有效地从数据文本中提取到特征,最大程度上确保预测的准确率,在2018“中国法研杯”司法人工智能挑战赛构建的数据集上精度达到了88.1%。
1 相关工作
为了减少人工和提高相关的工作效率,人工智能与法律领域的联系越来越紧密,法律判决预测的相关研究越来越受人关注。在早期研究中倾向使用统计学模型进行预测,Kort等[14]利用数学和统计学模型分析大量的历史案例来预测美国联邦最高法院的最终判决。Ulmer等[15]使用基于规则的方法分析法律文本数据来帮助法官对事实证据进行分析。Keown等[16]利用数学模型分析特定情况下的现有法律案件进行预测。然而这些方法都被限制在很少标签的小数据集下。后来,随着计算机算力的提高,一些基于机器学习[6,9]的方法被提出,他们都是将一些手工设计的特征与线性分类器相结合,用来提高模型的性能。这样做的缺点就是这些方法严重依赖手工设计的特征,使得设计出的模型不能更好地解决其他问题。
近年来,随着神经网络的应用越来越广泛,研究人员更倾向于使用神经网络来解决法律相关问题。Luo等[11]提出了一个分层注意力网络来识别处理事实描述与相关法律条款之间的关系来提高预测性能。Zhong等[12]将法律判决预测任务的子任务的依赖关系形式化为一个有向无环图来建模,从而提出了一个基于神经网络的多任务学习框架,用于有效地共同解决这些子任务。Hu等[10]人工定义了10个判别属性,并通过模型学习这些属性来对易混淆的罪名进行分类。Long等[17]利用阅读理解对判决流程进行法律判决预测。Wu等[18]利用自监督学习的方法解决对话系统中的问题。
上述基于统计学模型和机器学习的方法,都需要花费大量的数据和人工来保证对判决预测的准确性,再加上有的模型需要利用人工设计特征提取,模型在泛化问题上存在严重不足。基于深度学习的方法使用神经网络来解决法律判决预测问题才是当下研究的热点。但是训练时长增长,亦或是因使用自监督学习而产生大量的参数,而导致所需的硬件代价过大以及模型预测的准确率低,是当前利用深度学习进行预测无法绕开的问题。本文设计提出了结合ALBERT和TextCNN的罪名预测模型ALBT,利用轻量级BERT进行预训练能够大幅减少训练时长,并且确保能够提取到足够的语义表示,然后通过拼接结构简单的TextCNN模型进行分类预测,在保证分类准确性的前提下进一步节省时间,大幅减少训练时长。实验结果表明模型能够高水平地完成罪名预测任务。
2 自监督学习的卷积神经网络ALBT
2.1 ALBERT模型结构
BERT[19]全称为Bidirectional Encoder Representation from Transformers,Devlin等2018年于Google提出的预训练模型,其结构图如图1所示,BERT模型使用双向Transformer编码器进行文本处理,利用大规模无标注的语料训练来获得文本中包含的丰富的语义表示。BERT主要包含了2个预训练任务,第一个是Masked LM即给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词或句来预测被抹去的词是什么。第二个就是下一句话预测(next sentence prediction,NSP),即给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后。BERT的核心的模块是Transformer编码器,Transformer模型为Encoder-Decoder[20-21]结构,而ALBERT只使用其中的Encoder结构作为特征提取器,具体结构如图2所示。Encoder包括自注意力机制(self-attention)用于探索发现上下文中词语之间的关系和前馈神经网络(feed forward neural network)两部分组成。并且每层之间都加入了一个求和归一化层(Add&Norm),用来把本层的输入和输出相加然后归一化处理[22]。最后再把两层网络进行残差连接[23]。
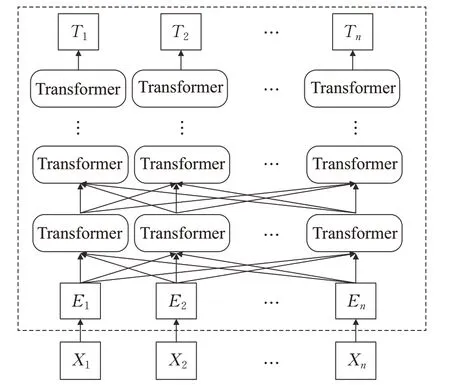
图1 BERT模型结构Fig.1 BERT model structure
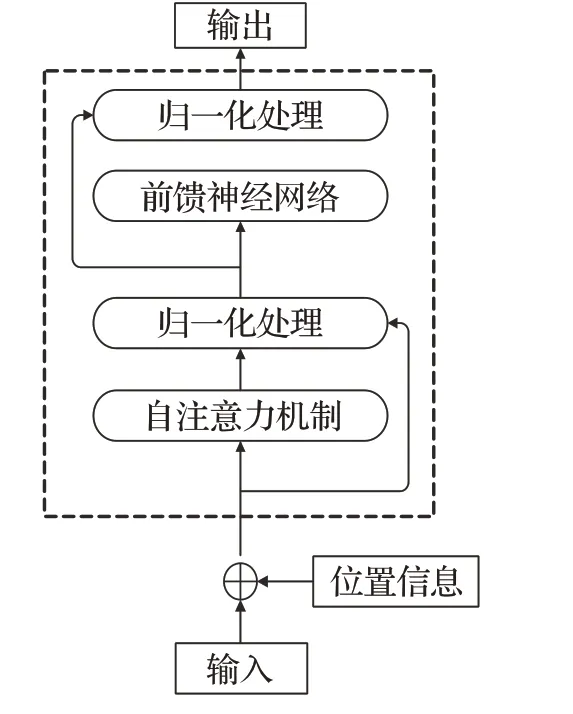
图2 Transformer Encoder结构Fig.2 Transformer Encoder structure
由于BERT模型使用了12层Transformer编码器,从而产生了数以亿计的参数,使训练速度变慢,然而一味地堆叠参数并不能使模型性能变得更加优越,甚至可能导致模型性能的下降。Lan等[24]基于BERT提出ALBERT对BERT加以改进用以精简由于使用多层Transformer编码器而产生的大量的参数量,并且能够适当提升模型的性能。
2.2 TextCNN神经网络模型
Kim等[25]提出了TextCNN,使用卷积神经网络来进行文本分类的模型,模型为了能够更好地捕捉文本中局部的相关性,使用了多个大小不同的卷积核来提取句子中的关键信息。TextCNN模型结构如图3所示。
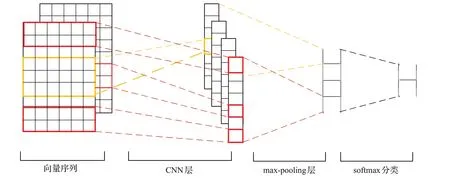
图3 TextCNN模型结构Fig.3 TextCNN model structure
模型的第一层嵌入层(embedding layer)首先接受由ALBERT训练好的向量,预先训练的词嵌入可以利用其他语料库得到更多的先验知识,由预先训练好的向量构成一个由N×K的嵌入矩阵M,N代表句子的长度,K代表词向量的长度。然后进入到模型的第二层卷积层(convolution layer)提取句子的特征,卷积核的大小为w∈Rhk,其中h代表卷积核的高度,k代表卷积核的宽度,卷积核只在高度上从上到下滑动进行卷积操作,在宽度上和词向量的维度保持一致,最后得到的列为1,行为(n-k+1)的特征映射(feature mapping)如式(1)所示:

模型的第三层是一个1-max pooling层,最大池化层,即为从每个滑动窗口产生的特征向量中筛选出一个最大的特征,然后将这些特征拼接起来构成向量表示。经过这层之后不同长度的句子在经过池化层之后都能变成定长表示。
经池化操作后,获得一维向量,再通过ReLU激活函数输出,添加Dropout层,防止过拟合,经过全连接层输出并在全连接层添加正则化参数。最后全连接层的所有输出值都连接到softmax层,最后输出预测罪名的结果。
2.3 融合自监督学习的卷积神经网络
自监督学习的卷积神经网络ALBT结构如图4所示,主要由输入层、ALBERT层、TextCNN层、输出层组成。
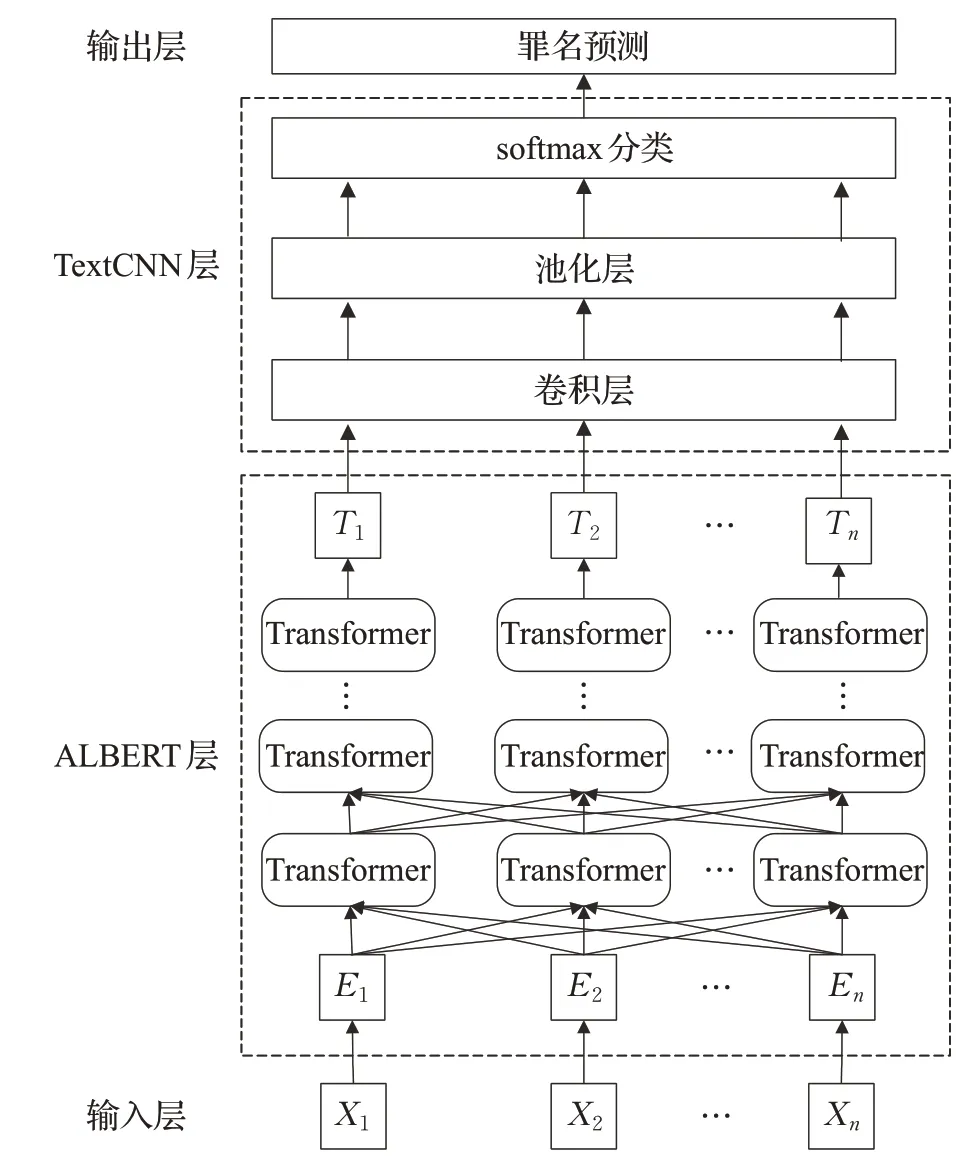
图4 ALBT模型结构Fig.4 ALBT model structure
将事实描述从输入层输入到ALBERT层中,经过编码后将文本数据处理成序列化数据,再输入到Transformer编码器,经过自监督的多层双向Transformer编码器的训练最终输出文本的特征向量表示,之后进入到TextCNN层中,卷积层再提取特征表示,池化层防止过拟合,减少参数,加速计算,最终经过softmax分类器进行分类,完成罪名预测过程。
由于BERT的局限性,故ALBERT做出以下几点改进:
参数因式分解(factorized embedding parameterization)也叫矩阵分解,本质上是一个低秩分解的操作,通过对词嵌入(embedding)部分的降维来达到减少参数的目的,经过参数因式分解之后的时间复杂度变化如式(2)、(3)所示,其中V代表词表大小,H代表隐藏层维度大小,E代表词向量维度大小,当H≫E时,模型的参数量可以大大减少。

跨层参数共享技术(cross-layer parameter sharing),顾名思义就是可以在不同的层之间共享参数,可共享的分为全连接层、注意力层。通过跨层参数共享技术可将大量的参数减低到一个较低水平。
通过使用参数因式分解技术和跨层参数共享技术可以大大地减少模型所产生的参数量,加快模型的运算速度,减少硬件上的内存开销,加快模型的训练速度。
句子间顺序预测(sentence-order prediction,SOP),不同于BERT的下一句话预测(NSP),ALBERT使用句间顺序预测,给定模型两个句子,让模型预测两个句子的前后顺序,相比原先的NSP、SOP技术更加复杂,能够使模型学习到更多的上下文之间丰富的语义关系。
模型通过引入自监督学习机制在和简单的卷积神经网络相结合构成整体模型ALBT,并且经过上述改进技术,使得模型大大减少了自监督学习过程中所产生的大量的参数,大幅加快了模型的训练速度,而且在经过大量实验之后发现上述改进能够有效提高模型预测的准确率,这说明相关改进是十分必要的。
3 实验与分析
3.1 数据集准备
本文采用2018“中国法研杯”司法人工智能挑战赛(CAIL2018)构建的数据集CAIL2018-small,其中数据来自“中国裁判文书网(http://wenshu.court.gov.cn/)”公开的刑事法律文书,考虑到数据集中包含一些无事实描述的无用文书案例,在实验中将无效数据剔除后,有训练集数据154 177条、验证集数据17 088条和测试数据32 433条,涉及202个罪名和183个法律条款。
3.2 对照实验
为了检验实验模型的预测能力,选择了5种主流的对照模型与本文的模型进行预测效果对比,所涉及的模型包括基于RNN的网络模型、基于CNN的网络模型、基于注意力机制的网络模型、基于拓扑的多任务学习框架模型。具体分别是:
(1)BiLSTM[26]:使用双向的LSTM来获取上下文的信息,最后用全连接层和sigmod激活函数作为输出层。
(2)CNN[27]:使用多卷积核的CNN作为案情描述的编码器,使用最大池化层对卷积后的特征进行筛选。
(3)DPCNN[28]:提出一个深层金字塔卷积网,是第一个广泛有效的深层文本分类卷积神经网络。
(4)Fact-Law[29]:利用SVM分类器从案情描述文本中抽取法条特征,将法条信息融入基于注意力机制的神经网络模型。
(5)TopJudge[11]:将子任务之间的依赖视为有向无环图,并提出一个拓扑的多任务学习框架,该框架将多任务学习和有向无环图依赖融入到判决预测中。
3.3 评价指标
根据对所使用的数据集中所涉及罪名的统计可以看出司法领域的实际数据分布不平衡,训练数据中同一罪名的数据量相差太大,有一半的相同罪名的数据不足500条,同一罪名的数据最多的有8 000条以上,而最少的仅有12条。故本文采用微平均F值Fmicro、宏平均F值Fmacro作为模型的评价指标。计算公式如式(4)、(5)所示:
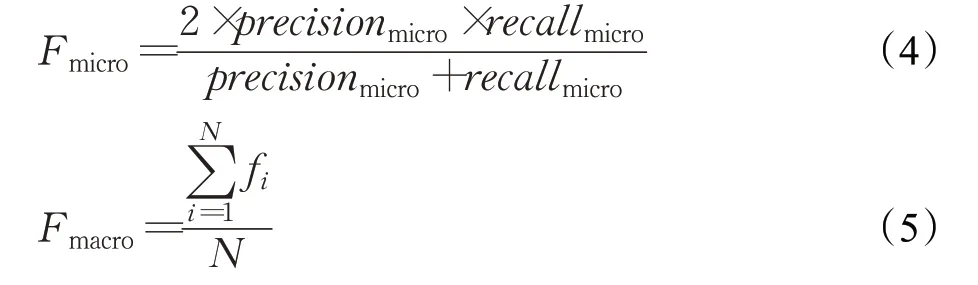
3.4 实验结果及分析
表1展示了基线模型和本文提出的模型在2018“中国法研杯”司法人工智能挑战赛构建的数据集CAIL2018-small上进行罪名预测的实验结果。
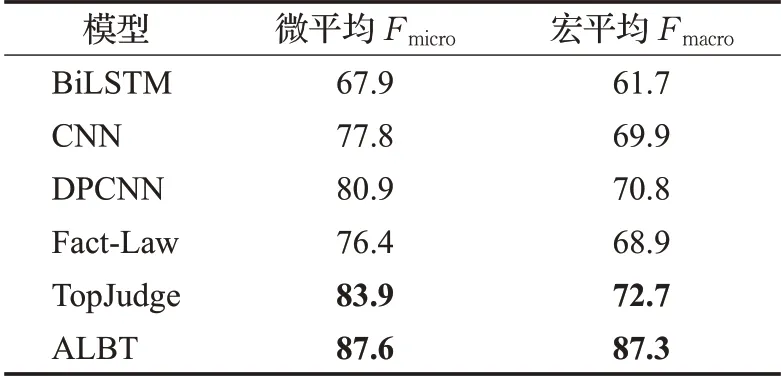
表1 各模型的实验结果对比Table 1 Comparison of experimental results of each model 单位:%
通过表1的对比实验结果可以看出,本文提出的模型在相同数据集的情况下在罪名预测任务上的实验结果要明显优于其他所有对比实验模型。与对比实验中最好的模型相比微平均和宏平均分值高出3.5和14.6个百分点。
模型通过引入自监督学习的方法,并且对其加以优化改进,在技术层面上利用参数因式分解和参数共享两种技术相结合的方式,而后在原先NSP的基础上通过改进,利用SOP技术,尽可能多地学习到文本中的语义信息,在保证模型预测准确率的前提下大大减少了因自监督学习所带来的参数量暴增的问题。
但是由于法律条款的严谨性,相似的犯罪行为就会导致出现一些名称相似的罪名,这些罪名的事实描述也十分相似,但是却又存在着不同点,这导致模型可能无法正确地区分它们,所以模型在区分混淆罪名时表现不理想。
4 总结与展望
针对现有的罪名预测模型方法上,本文提出了ALBT模型来解决罪名预测问题,结合ALBERT和TextCNN模型进行罪名预测,用ALBERT模型进行模型预训练来获得更加丰富的上下文文本表示,利用ALBERT相比于基础BERT来说参数量大大减少的优势,使模型更加轻量,训练速度也更加快,再结合结构简单的卷积神经网络TextCNN模型进行罪名预测,从结果上看取得了不错的效果,结果要优于基线模型。
本文仍存在一些不足之处:对于一些易混淆罪名的分类效果不理想,比如“骗取贷款罪”与“贷款诈骗罪”,两项罪名相同点都是实施了集资行为,但是不同点是前者具有非法占有目的,而后者不具有非法占有目的,如何能更加细粒度的从案件事实描述中提取出有效的信息来区分易混淆的罪名,目前模型在对这一问题的表现上欠佳,将来需要更加深入的研究和探索。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
浙江警察学院学报(2016年5期)2016-08-15 00:55:15
刑法论丛(2016年2期)2016-06-01 12:14:25
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
中国检察官·司法务实(2015年10期)2015-11-12 05:25:05
海军航空大学学报(2015年4期)2015-02-27 13:45:47
