
结合自监督学习的图神经网络会话推荐
2023-02-14 10:32王永贵赵晓暄
计算机工程与应用 2023年3期
王永贵,赵晓暄
辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105
在互联网信息日益超载的时代,推荐系统已经成为帮助人们从纷繁复杂的信息中迅速获得有用信息的重要工具[1]。推荐系统被广泛应用在学习、生活、工作和娱乐等各个领域。大多数现有的推荐系统都依赖于用户的个人信息和过去的历史行为数据,但是在真实场景中很多服务器上无法访问这些信息,只有正在进行的会话期间的匿名行为记录可用。为此,基于会话的推荐方法受到了广泛的关注。会话是一段连续时间内用户与项目交互的行为记录[2],例如一小时内用户购买的商品。基于会话的推荐系统不需要对用户的身份信息和历史数据进行详细分析,只需从用户当前会话中的交互记录中提取其偏好信息来进行下一步预测。
因基于会话的推荐具有很高的实用性,许多相关研究成果不断涌现。当前表现较好的是基于图神经网络(graph neural network,GNN)的推荐模型。GNN具有很强的对图中节点之间的依赖关系进行建模的能力[3]。基于GNN的推荐模型与之前的模型不同,它将会话序列建模成会话图,利用GNN进一步挖掘会话图中项目之间丰富的隐藏信息,从而获得良好的预测结果。但是,基于GNN的推荐模型仍面临着数据稀疏性问题。基于会话的推荐由于缺乏长期的用户历史行为数据,只能利用短期会话生成的用户交互记录进行推荐,然而一次会话中大多数用户只能点击大量项目中的一小部分,其交互数量非常有限,远少于长期的用户行为数据。可用数据的匮乏使得基于会话的推荐模型无法学习到准确的用户偏好,从而导致模型推荐性能不佳。
自监督学习作为一种新型学习范式,它利用数据本身的内在关系而非人工标注数据进行监督,有益于几乎所有类型的下游任务[4],在解决数据稀疏性问题上具有很大的优势。因此,为更好地利用有限的会话数据,缓解数据稀疏对会话推荐的影响,本文提出了结合自监督学习的图神经网络会话推荐模型(self-supervised graph neural networks for session-based recommendation,Ss-GNN)。Ss-GNN模型将GNN与自监督学习相结合来挖掘原始数据中更有价值的信息以缓解数据稀疏性问题对推荐性能的影响,进而实现推荐性能的提升。
本文主要工作如下:
(1)根据会话序列构建会话图,采用图注意力网络(graph attention network,GAT)的思想,在GNN中加入注意力机制来学习会话中项目之间的关联程度以减少数据噪声,进而生成更准确的项目级表示,并结合项目的位置信息生成会话级表示。
(2)考虑用户长短期兴趣,在获得项目级表示的基础上通过全局嵌入和局部嵌入来构建辅助任务生成辅助会话级表示。在两个会话级表示之间利用自监督学习来辅助推荐模型在有限的会话数据中捕获更有价值的用户偏好信息,缓解数据稀疏性问题。
(3)本文在两个真实的数据集上进行实验,实验结果表明,所提模型优于对比的10个基线模型,证明了Ss-GNN模型的有效性。
1 相关工作
1.1 基于会话的推荐系统
给定一个正在进行的会话中的用户历史行为(如点击),基于会话的推荐系统可以预测用户下一步操作。基于会话的推荐系统作为一种新兴的推荐系统范式引起了人们的广泛关注,相关技术和方法不断迭代更新。在传统推荐方法中,矩阵分解是常见的方法,它的基本目标是把用户-项目评分矩阵分解成两个低秩矩阵,每个矩阵代表用户或项目的潜藏信息[5]。由于会话中提供用户偏好信息的交互项目并不多,矩阵分解并不适用于基于会话的推荐系统。基于马尔可夫决策的思想,文献[6]提出了FPMC(factorizing personalized Markov chains for next-basket recommendation)模型,将马尔可夫链与矩阵分解结合,以捕捉时间信息和长期的用户偏好,该模型可以对两个邻近的点击项之间的连续行为进行建模,从而生成更精准的推荐。但是该模型仅考虑到了邻近交互项目之间的局部信息,而未考虑会话上下文传递的整体信息。
随着深度学习的蓬勃发展,大量的深度学习方法被应用到了基于会话的推荐模型中,以获取项目之间丰富的隐藏信息。文献[7]提出了GRU4Rec(gated recurrent unit for recommendation)模型,首次提出使用循环神经网络(recurrent neural network,RNN)来解决基于会话的推荐问题。该模型利用RNN和门控循环单元(gated recurrent unit,GRU)对会话数据进行建模,可以通过给定会话的历史交互来学习会话级表示,进而对用户的下一步行动进行预测。之后,文献[8]提出了NARM(neural attentive recommendation machine)模型,该模型利用RNN和注意力机制对用户的顺序行为进行建模,捕获当前会话中用户的主要意图。文献[9]提出STAMP(short-term attention/memory priority)模型,该模型考虑到了最后一次点击项目的重要性,设计了一个注意力层同时捕获会话中用户的长短期兴趣。
近年来,图神经网络被引入到了基于会话的推荐中,并取得了优异的成果[10-15]。与之前的会话推荐方法不同,GNN通过建模会话图来进一步学习项目之间的隐藏信息。文献[10]提出了SR-GNN(session-based recommendation with graph neural network)模型,将会话序列建模成会话图,不仅考虑了传统序列方法难以捕获的复杂项目之间的转换,还结合了会话的一般兴趣和当前兴趣来进行更好的预测。文献[11]提出GC-SAN(graph contextual self-attention model based on graph neural network)模型,在GNN的基础上加入了自注意力机制,利用两者之间的互补性来提高推荐性能。文献[13]提出FGNN(full graph neural network)模型,该模型考虑了会话中项目的内在顺序,利用一个加权图注意力层和Readout函数来学习会话中项目之间的隐藏信息。文献[15]提出了GCE-GNN(global context enhanced graph neural networks)模型,该模型考虑到了当前会话以外的其他会话,在会话图的基础上增加了全局图,利用来自两个层次的图模型的项目嵌入信息来提高当前会话的推荐性能。由于基于会话的推荐场景中用户交互行为有限,这些基于GNN的方法都面临着数据稀疏性问题。
1.2 自监督学习
自监督学习是一种从大量无标记数据中挖掘自身监督信息的表示学习方法,因其在表示学习方面的优异表现而受到广泛的关注。自监督学习早期被应用在计算机视觉和自然语言处理领域[16-17],通过对原样本进行扰乱,例如对图像随机翻转、剪切放大和句子剪裁等方式来获得一些新样本,以增强原始数据。随后受其他领域的影响,一些研究开始将自监督学习引入到了序列推荐中。文献[18]利用属性、项目、子序列和序列之间的关联度来获得自监督信号,并通过预训练方法来增强数据表示。文献[19]提出了一种新的seq2seq(sequence to sequence)训练策略,通过在潜在空间执行自监督和解藕行为序列背后的用户意图来捕获额外的监督信号。文献[20]提出了三种数据增强方法实现预训练,以提取更有价值的用户模式。以上序列推荐模型虽然取得了良好的成绩,但它们并不适用于会话推荐,因为包含在这些模型中的随机屏蔽方法会导致会话数据更加稀疏,产生无效的自监督信号。因此,如何更有效地结合自监督学习来提升基于会话的推荐模型的推荐性能是一个值得研究的问题。文献[21]提出利用超图建模会话数据并设计了基于超图的线图将自监督学习集成到了基于会话的推荐场景中。受其启发,本文尝试从会话级表示的角度出发设计一个新的辅助任务,将自监督学习与基于GNN的会话推荐模型联合,以增强会话数据,缓解数据稀疏性问题给推荐系统带来的影响。
2 Ss-GNN模型
基于会话的推荐系统从输入的会话序列(例如,用户在某购物平台一小时内点击的商品)中捕捉用户偏好,来对用户下一次交互项进行预测。为了增强会话数据以缓解数据稀疏性问题对系统带来的影响,本文提出了结合自监督学习的图神经网络会话推荐(Ss-GNN)模型,其整体框架如图1所示。该模型通过设计辅助任务来实现自监督学习,将自监督学习提取到的会话级表示信息,以特征增强的方式辅助基于图神经网络的会话推荐模型。

图1 Ss-GNN模型整体框架Fig.1 Overall framework of Ss-GNN model
2.1 符号及问题描述
本文中符号定义如下:令V={v1,v2,…,vn}表示项目的集合,n为项目的数量。V中的每个项目vm被编码到一个统一的嵌入空间hm∈ℝd,d为项目嵌入的维度。s={vs,1,vs,2,…,vs,n}表示一个长度为n的会话序列,vs,t∈V(1≤t≤n)为会话s内用户交互的项目,项目按交互时间排序。
Ss-GNN模型的任务是学习t时刻会话s={vs,1,vs,2,…,vs,t}中的用户偏好,预测t+1时刻最可能交互的项目vs,t+1。模型输入会话序列s,输出所有可能项目的推荐得分ŷ={ŷ1,ŷ2,…,ŷn},最后将ŷ中得分最高的前N个项目作为会话s的推荐候选项目。
2.2 基于图神经网络的推荐任务
2.2.1 构造会话图
每个会话序列s可以被建模成一个有向会话图Gs=(Vs,Es),其中Vs为表示用户点击的项目集合的点集,Es为表示会话中项目之间关联关系的边集,(vs,n-1,vs,n)∈Es表示用户在会话s中点击vs,n-1之后点击了vs,n。在日常生活中,用户在当前会话中多次点击相同的项目是很常见的,所以在会话图中相邻项目之间边的类型除了入度边、出度边、入度-出度边(同时存在入度边和出度边),还添加了自连接边(自环)[13]。会话图的构造如图2所示。

图2 会话图Fig.2 Session graph
2.2.2 学习项目级表示
会话图中包含着当前会话中相邻项目之间丰富的隐藏信息。在推荐场景中,会话中的每个项目周围的邻居项目对其本身的重要性不同,因此本文跟随文献[15]的工作,利用GAT的思想来学习会话中的项目级表示。GAT是GNN的延伸,它在GNN中加入了注意力机制,可以学习不同节点之间的权重[22],为邻域内的不同项目分配不同的重要性,使得GNN能够更加关注重要的邻居节点,以减少边缘噪声给推荐带来的影响。模型中的GNN不需要进行复杂的矩阵运算,计算高效,同时可解释性强。
在会话图Gs中,模型学习项目级表示的过程如下:
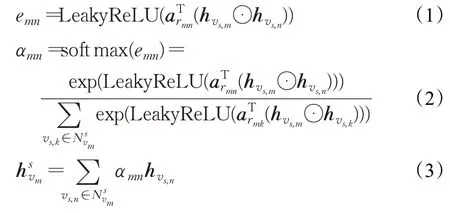
通过式(1)计算不同节点间的注意力权重。其中,emn代表了项目vn的特征对项目vm的重要性,a*∈ℝd为一个可训练的权重向量,rmn则为相邻项目m和n之间对应边的类型,激活函数使用LeakyReLU函数,LeakyReLU函数继承了ReLU函数的优点,同时给每个负值赋予一个小的正斜率,可以对输入的负值进行反向传播。式(2)中,为方便比较不同节点之间的注意力权重系数,使用softmax函数对其进行归一化处理。最后通过式(3)对当前会话中各个项目及其邻居特征进行聚合来获得会话图中各项目的项目级表示。其中,N vs m表示vm的一阶邻居。αmn的大小随着不同的邻居项目而变化,表明不同邻居对项目的重要性不同。
2.2.3 学习会话级表示
将相应的会话序列输入到图神经网络中,通过2.2.2小节中的方法可以获得对应会话图中的项目级表示该章节中将介绍如何根据学习到的项目级表示来生成会话级表示。
位置嵌入已在许多场景下被用来存储项目的位置信息[23]。在真实的会话场景中,通常偏后交互的项目更能代表用户当前的偏好,这说明了会话中的反向位置信息对于改进推荐性能的重要性。跟随文献[15]的工作,本文利用一个可学习的位置矩阵P=[p1,p2,…,pn]将反向位置信息与已学习到的项目级表示相结合来获取会话中各项目的反向位置嵌入:

其中,W1∈ℝd×2d,b1∈ℝd为可训练的参数,pm∈ℝd是特定位置m的位置向量,n是当前会话序列的长度,表示连接。
通过求和的方式浓缩学习到的项目级表示来获得当前会话中的会话嵌入:

考虑到这些嵌入信息在会话中的重要性不同,本文进一步采用软注意力机制来获取最终的会话级表示:
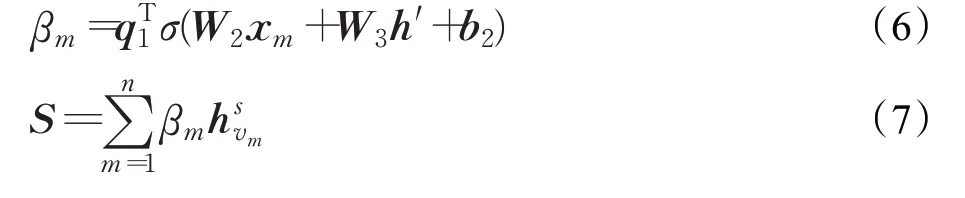
其中,W2,W3∈ℝd×d,q1,b2∈ℝd为可训练的参数。
2.2.4 预测
使用得到的会话级表示S和会话中的每个候选项目vi∈V的项目级表示hi来计算候选项目的推荐分数,并利用softmax函数获取模型的输出向量:

其中,∈ℝm表示每个候选项目的推荐分数,∈ℝm表示每个候选项目成为用户下一次点击的项目的概率。选用推荐系统常用的交叉熵损失函数作为学习目标来训练模型:

其中,yi为用户实际交互物品的one-hot向量。
2.3 辅助任务
通过构建辅助任务将自监督学习融入到基于图神经网络的会话推荐模型中,以增强模型对会话中深层交互信息的学习,弥补模型中推荐任务的不足。本文采用另一种求解会话级表示的方法[10]来设计辅助任务以产生自监督信号。
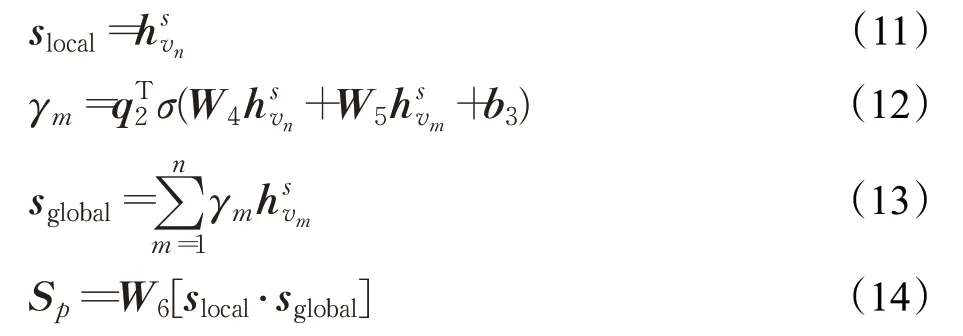
其中,W4,W5∈ℝd×d,W6∈ℝd×2d,q2,b3∈ℝd为可训练的参数。
用户最后一次交互的项目被认为更能代表用户的当前兴趣[9],因此令会话序列中最后一次点击项的项目级表示作为当前会话的局部嵌入slocal。式(13)中sglobal为当前会话的全局嵌入,代表用户的长期偏好。连接全局嵌入和局部嵌入做线性转换得到最终的辅助会话级表示Sp。
2.4 自监督学习
本文从获取会话级表示的角度出发,采用了两种不同的方法学习到了相应的会话级表示。推荐任务中采用位置嵌入和浓缩的会话嵌入来学习会话级表示,辅助任务则通过全局嵌入与局部嵌入来获取会话级表示。两组任务学习的角度不同,但都基于模型得到的项目级表示来获取会话级表示,它们有相近之处,并非完全不同,所以两组会话级表示可以成为彼此监督学习的ground-truth,相互补充来对会话数据进行增强。这也体现了自监督学习与利用人工标注数据进行学习的有监督学习的不同之处。
跟随文献[16,21,24]的工作,本文将正负样本之间带有标准二值交叉熵损失的噪声对比型目标函数作为自监督学习的学习目标:

其中,是对Si行列变换打乱顺序获得的负样本,fD(·):ℝd×ℝd↦ℝ是一个鉴别器函数,它对输入的两个向量之间的一致性进行打分。本文将鉴别器实现为两个向量之间的点积。利用这一学习目标来实现两种方法中学习到的会话级表示之间的互信息(mutual information)最大化。
最后将基于图神经网络的推荐模型和自监督学习整合到同一个学习框架中进行联合优化。最终的学习目标见式(16)。其中,δ为自监督学习损失函数的权重系数。

通过自监督学习,最大限度地利用两种方法学习到的会话级表示之间的互信息,使受会话数据稀疏问题影响的推荐模型可以获得更准确的信息,以提高推荐性能。
3 实验与分析
3.1 数据集和预处理
使用公开的Yoochoose数据集和Tmall数据集进行实验来验证本文提出模型的有效性。Yoochoose数据集来自RecSys 2015挑战赛,其中包含用户6个月内在电子商务网站的点击记录。Tmall数据集来自IJCAI 2015竞赛,其中包含了匿名用户在天猫在线购物平台上的购物记录。为了比较的公平性,参照文献[8-9,21]的工作对两个数据集进行预处理:首先过滤两个数据集上长度为1的会话、出现次数少于5的项目。随后对输入的会话序列进行拆分来生成序列和相应的标签。将Yoochoose数据集上最后一天的会话数据设置为测试集,其余会话数据设置为训练集。将Tmall数据集上最后一周的会话数据设置为测试集,其余会话数据设置为训练集。由于Yoochoose数据集中数据量过大,现有研究按时间对训练集中的会话排序,发现偏后部分的数据能产生更好的训练结果[25],因此本文仅选择距离测试集时间最近的1/64会话序列作为训练集。经过预处理的两个数据集的统计结果如表1所示。
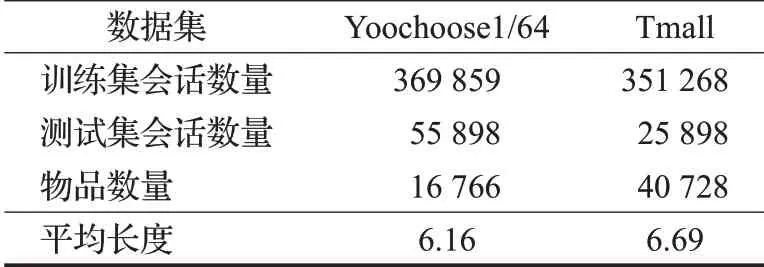
表1 数据集统计结果Table 1 Statistical results of data sets
3.2 评价指标
本文采用精确率(Precision)P@N和平均倒数排名(mean reciprocal rank)MRR@N作为实验结果的评价指标。
P@N被广泛用于衡量会话推荐预测的准确性,它表示正确推荐的物品在前N个物品中的比例。计算公式为:

其中,n为测试集样本总数,nhit为前N个推荐物品中含有正确推荐物品的样本数。
MRR@N表示正确推荐物品的排名的倒数的平均值。当推荐列表中推荐正确的物品位置越靠前时,推荐效果越好。计算公式为:

其中,n为测试集样本总数,R为前N个推荐物品中含有正确推荐物品的样本数,rank(i)为物品i在推荐列表中的排名。
由于在会话推荐系统的实际应用中,大多数用户只关注靠前页数的推荐结果,因此本实验N取值为20。
3.3 对比模型
为了评估该模型性能,实验选取以下模型作为对比模型:
(1)POP:根据物品在训练集中的流行度排名进行推荐。
(2)Item-KNN[26]:通过物品之间的相似度来推荐与已点击物品相似的物品,其中相似度为会话向量之间的余弦相似度。
(3)FPMC[6]:是一种基于矩阵分解和一阶马尔可夫链的序列预测方法,能同时捕获时间信息和用户偏好。
(4)GRU4Rec[7]:初次将RNN引入到基于会话的推荐领域中,使用GRU对会话序列进行建模。
(5)NARM[8]:采用带有注意力机制的RNN方法来捕捉用户的主要意图和序列行为特征。
(6)STAMP[9]:初次考虑长短期记忆,强调了最后一次点击项目的重要性,提出了一种新的注意力机制,同时捕捉用户的一般兴趣和当前兴趣。
(7)SR-GNN[10]:初次将GNN引入到基于会话的推荐领域中,使用GNN捕获会话中项目之间的隐藏信息,同时结合用户的长期偏好和当前兴趣进行推荐。
(8)GCE-GNN[15]:构造了全局图来捕获全局上下文信息,利用图卷积网络和图注意力网络来捕获全局级和会话级的项目转换信息。
(9)CASIF[27]:利用图神经网络并构建短期兴趣优先模块和多层感知机模块来共同捕获用户偏好信息。
(10)S2-DHCN[21]:采用一种双通道超图卷积网络进行推荐并通过自监督学习来增强超图建模。
3.4 参数设置
实验设定隐藏向量维度为100,训练批次大小设定为100,初始学习率为0.001且每训练迭代3次学习率衰减10%,正则化系数L2=10-5,随机选取10%的训练集子集作为验证集,对所有参数采用均值为0、标准差为0.1的高斯分布进行初始化,使用Adam算法优化模型参数,训练迭代次数设定为20。
3.5 模型性能比较与分析
为验证所提模型的有效性,将所提模型与基线模型在两个数据集上进行对比实验,实验结果如表2所示。
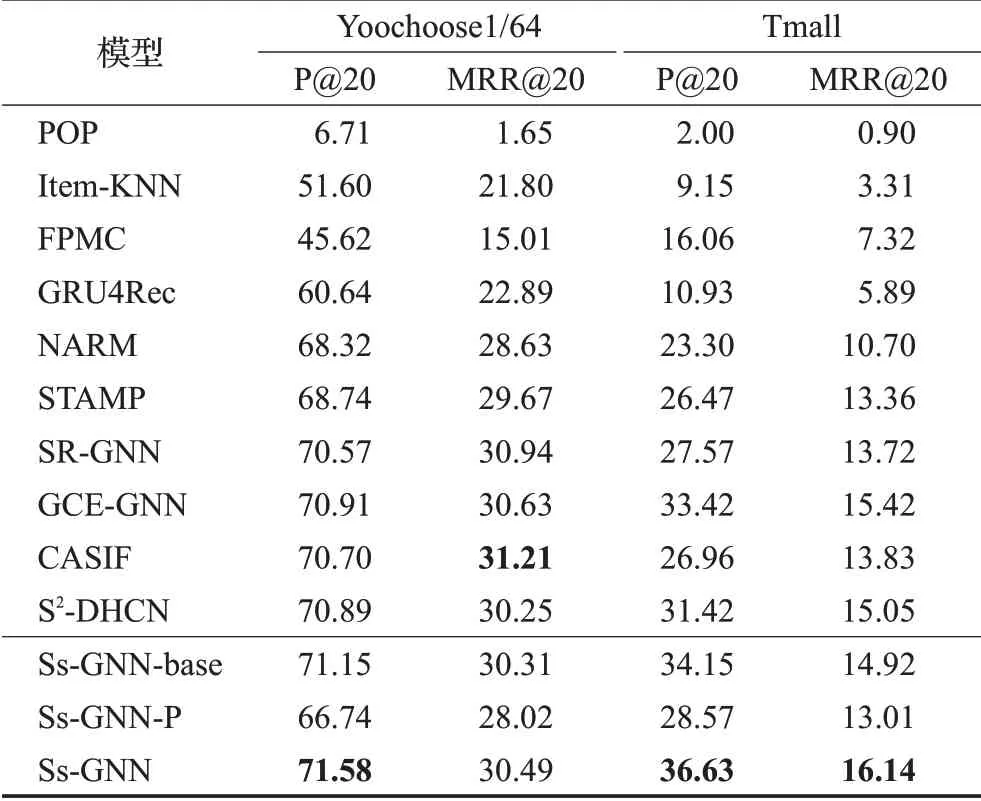
表2 不同模型在两个数据集上的实验结果Table 2 Experimental results of different models on two datasets 单位:%
根据表2给出的实验结果可以得出以下结论:
GRU4Rec模型采用RNN来学习会话中的用户偏好,考虑到了会话信息的时间顺序,因此其性能要优于未考虑时间顺序的POP、Item-KNN、FPMC等传统方法。
NARM和STAMP模型引入了注意力机制,利用注意力机制来学习当前会话中每个项目的重要程度,两者的性能优于GRU4Rec,说明注意力机制有助于在会话中获取用户兴趣信息。另外,STAMP因考虑到了用户当前兴趣的重要性,其性能优于NARM。
SR-GNN、GCE-GNN、CASIF和S2-DHCN模型利用GNN进一步捕获会话中复杂的项目转换,其性能明显优于NARM、STAMP,这表明了基于GNN的推荐模型与传统推荐模型和基于RNN的推荐模型相比更适用于基于会话的推荐情景。
Ss-GNN模型利用GAT的思想在GNN中加入注意力机制来提取重要的会话信息,并在推荐任务的基础上添加了辅助任务,以此来增强会话数据,缓解数据稀疏对推荐性能的影响,帮助系统捕获更准确的用户偏好信息,进而提升推荐性能。Ss-GNN模型与GCE-GNN模型相比,在Tmall数据集上,P@20和MRR@20指标分别提升了9.61%和4.67%;在Yoochoose1/64数据集上,P@20指标提升了0.94%。Ss-GNN模型与CASIF模型相比,在Tmall数据集上,P@20和MRR@20指标分别提升了35.87%和16.70%;在Yoochoose1/64数据集上,P@20指标提升了1.24%。Ss-GNN模型与S2-DHCN模型相比,在Tmall数据集上,P@20和MRR@20指标分别提升了16.58%和7.24%;在Yoochoose1/64数据集上,P@20和MRR@20指标分别提升了0.97%和0.79%。从实验结果可以看出,Ss-GNN模型相比于其他模型更具有竞争力,尤其是在Tmall数据集上,虽只利用了会话图,其性能却远超于利用全局图和会话图的先进模型GCE-GNN。推荐精确率的提升证明了Ss-GNN模型的有效性。由于未充分考虑到边权重信息和会话间信息,Ss-GNN模型在MRR@20指标上的表现稍有不足,但在P@20指标上的表现排名第一,可以根据不同需求选择相应的模型。
3.6 自监督学习的影响
3.6.1 自监督学习有效性
为进一步评估自监督学习在Ss-GNN模型中的有效性,本文设计了两个模型变体与所提模型进行对比:
(1)将Ss-GNN模型中的辅助任务丢弃,不考虑会话数据稀疏带来的影响,只利用基于GNN的推荐模型进行推荐,即表2中的Ss-GNN-base。
(2)只用辅助任务来进行推荐,不进行自监督学习,用辅助任务替代原推荐任务获取会话级表示,即表2中的Ss-GNN-P。
从表2可以看出,与Ss-GNN-base和Ss-GNN-P相比,所提模型Ss-GNN的性能有了很大的提升。两个数据集上的实验结果表明自监督学习的引入是所提模型的主要贡献部分,进一步说明所提模型中的辅助任务的设计和自监督学习部分能够很好地增强会话数据,缓解数据稀疏给系统性能带来的影响。
3.6.2 自监督学习参数影响
在所提模型中,利用权重系数δ来控制自监督学习的程度,帮助模型在两个学习目标Lr和Ls之间进行权衡,从而挖掘出更有价值的信息。为了避免辅助任务在梯度传播中的负面干扰,本文选择在较小的区间内搜索合适的δ值,并根据实验结果将其设置为0~0.2。在0值之后,首先从0.001开始尝试,并逐渐增加步长。本文在Yoochoose1/64和Tmall数据集上选取了一组具有代表性的δ值{0,0.001,0.005,0.01,0.02,0.05,0.1,0.2}来研究权重系数δ对Ss-GNN模型性能的影响。从图3中可以看出,随着δ值的增加,Ss-GNN模型在两个数据集上的性能均得到了提升,在Tmall数据集上δ值为0.01时性能最佳,在Yoochoose1/64数据集上δ值为0.005时性能最佳。Ss-GNN模型在两个数据集上的性能达到峰值后,随着δ值的增加开始逐步下降。这表明使用较小的δ值可以增强推荐模型的表达力,提升P@20和MRR@20,而较大的δ值则会误导推荐任务,给其带来负面影响。

图3 超参数分析Fig.3 Hyperparameter analysis
3.7 消融实验
为了更好地了解模型中推荐任务各部分的实际价值,本文设计了以下几个模型变体与Ss-GNN-base进行对比研究:
(1)Ss-GNN-1:采用SR-GNN模型中的门控图神经网络(gated graph neural network,GGNN)来学习会话中的项目级表示。
(2)Ss-GNN-2:去掉推荐任务中的反向位置嵌入。
(3)Ss-GNN-3:通过对得到的项目级表示取平均来获取会话嵌入。
为了方便了解推荐任务各部分功能,以上模型变体均不进行自监督学习。
各个模型变体的实验结果如图4所示,从图4(a)和图4(b)中可以看出:
(1)Ss-GNN-1与Ss-GNN-base比较,可以发现加入注意力机制的GNN相比于GGNN更能关注到会话中的重要信息,减少噪声数据带来的干扰,提升推荐性能。
(2)在图4(a)中,可以发现与Ss-GNN-base相比,去掉反向位置嵌入的Ss-GNN-2性能下降,但在图4(b)中,Ss-GNN-2在两个指标上的性能都得到了提升,说明严格的时间顺序可能会对推荐性能产生负面影响。
(3)在图4(b)中,Ss-GNN-3与Ss-GNN-base比较,可以发现取平均值导致Ss-GNN-3性能下降,说明采用平均值来浓缩会话信息可能导致数据平滑影响推荐性能。
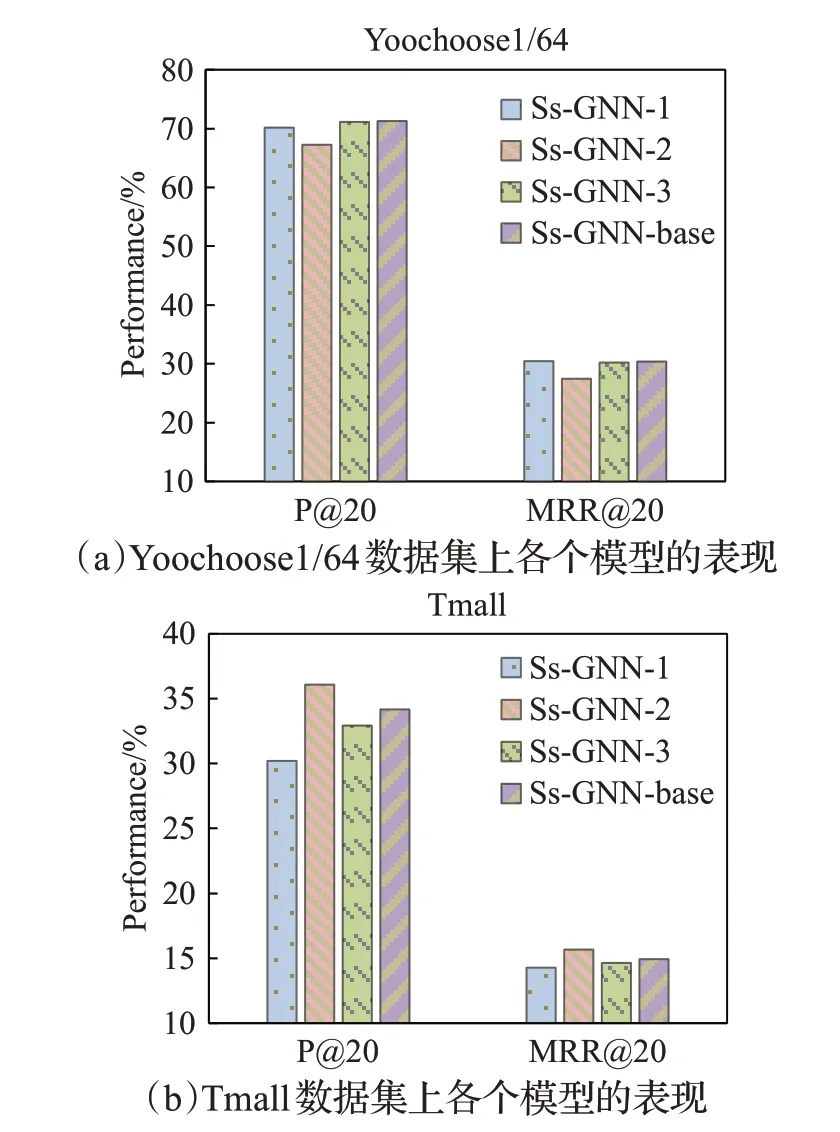
图4 Ss-GNN模型消融实验对比结果Fig.4 Comparison results of Ss-GNN model ablation experiment
通过消融实验,验证了Ss-GNN模型中推荐任务各个部分的设计合理有效,缺一不可。
3.8 优化器分析
为分析不同优化器对性能的影响,本文分别选取SGD、Momentum、RMSprop和Adam优化器对模型进行训练,训练结果和平均训练时间如图5和表3所示。

图5 不同优化器的实验结果Fig.5 Experimental results of different optimizers
从实验结果中可以发现SGD在推荐准确率上的表现较差,尤其是在Yoochoose1/64数据集上,且相比于其他优化器训练时间要长,本文认为主要原因是SGD在随机选择梯度时会引入噪声,同时容易陷入局部最优值。Momentum在SGD的基础上增加了动量(momentum)参数,能够提升SGD的稳定性,进而加快模型训练速度。Momentum的训练速度最快,但在推荐准确率上的表现不够理想。RMSprop引入衰减系数,能够进一步缓解优化过程中参数更新幅度大的问题,进而提升准确率。Adam结合了Momentum和RMSprop的优点,不仅使用动量指导参数更新方向还可以自适应调整学习率,在训练速度和准确率上都具有一定的优势。
3.9 效率分析
本文从时间复杂度和空间复杂度两个方面对提出模型的效率情况进行分析。
Ss-GNN模型的时间复杂度主要体现在图神经网络、注意力机制和自监督任务三个部分。设会话图中节点个数为|V|,边的个数为|E|,项目嵌入向量的维度为d。模型中的图神经网络通过计算每个节点与其邻居节点的注意力权重来学习会话图中的项目级表示,其计算次数与会话图中边的数量有关,所以此部分的复杂度为O(|E|d);注意力机制复杂度为O(|V|d2);自监督任务由于其计算量的核心是注意力机制,其复杂度同为O(|V|d2)。因此,模型的复杂度可归纳为O(|E|d+|V|d2),可以看出模型复杂度主要与会话图中节点和边的数量以及项目嵌入向量的维度有关。表4显示了Ss-GNN模型与基线模型在Yoochoose1/64和Tmall两个数据集上平均每轮的训练时间。可以观察到,与基线模型相比,Ss-GNN模型的训练效率有所提高。本文认为主要原因是,Ss-GNN模型只在当前会话中学习会话的项目嵌入且模型中的图神经网络只依赖于边,不依赖于完整的图结构,降低了模型计算量。同时,Ss-GNN模型与不进行自监督学习的Ss-GNN-base模型相比,训练时间没有较大差距,说明模型中的自监督学习模块不会增加大量训练时间。因此,Ss-GNN模型不仅在性能上有所提高,在效率上也具有竞争力。
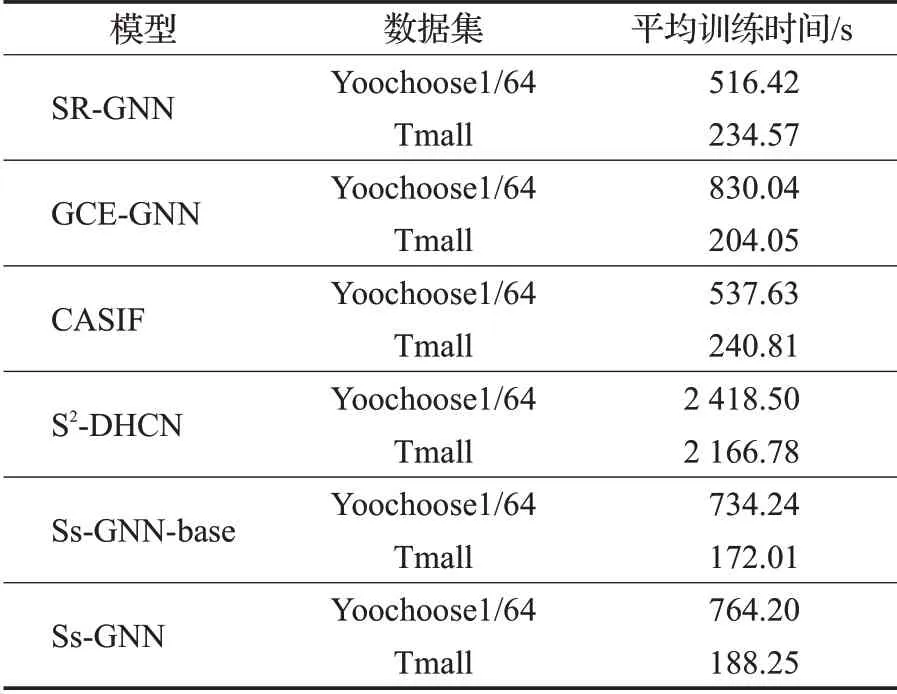
表4 不同模型在两个数据集上的平均训练时间Table 4 Average training time of different models on two datasets
为分析模型的空间复杂度情况,本文在Yoochoose1/64数据集上做进一步实验来获取不同模型的参数量、大小和运行时占用内存信息。从表5可以观察到模型大小以及占用内存与模型参数量有一定关系,说明模型的空间复杂度与其参数量有关。Ss-GNN模型由于增加了辅助任务,其参数量和占用内存有所增加,但与基线模型相比差距较小。综合来看,本文所提模型轻便、高效,在包含大量会话和项目的真实会话推荐场景中更为适合,具有较大优势。
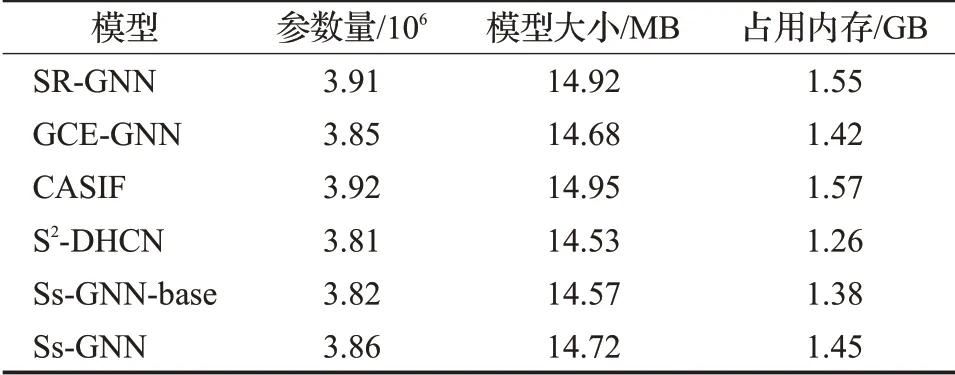
表5 不同模型参数量分析Table 5 Parametric quantitative analysis of different models
4 结束语
考虑到会话数据的稀疏性问题,本文提出一种新颖的结合自监督学习的图神经网络会话推荐模型Ss-GNN。该模型不仅利用GAT的思想降低了噪声数据对模型学习的影响,还通过长短期兴趣设计了辅助任务来产生自监督信号进行自监督学习,增强模型对会话数据特征提取的能力,以缓解数据稀疏性问题对推荐性能的影响,使模型推荐性能得到了提升。目前将自监督学习与会话推荐结合的研究并不多,本文提出的方法给自监督学习在基于会话的推荐上的应用提供了新思路。但本文提出的方法也有一定的局限性,如在Yoochoose数据集上的提升不够明显。在未来研究中,将探讨如何从其他角度设计出更有效的辅助任务来进一步提升推荐性能。
猜你喜欢
长江丛刊(2020年17期)2020-11-19
人大建设(2020年4期)2020-09-21
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
人大建设(2017年2期)2017-07-21
计算机系统应用(2017年3期)2017-03-27
人大建设(2017年9期)2017-02-03
浙江人大(2014年4期)2014-03-20
新课程学习·中(2013年3期)2013-06-14
