
基于原始点云的三维目标检测算法
2023-02-14 10:31张冬冬
计算机工程与应用 2023年3期
张冬冬,郭 杰,陈 阳
陆军工程大学,南京 210007
目标检测,作为三维数据处理与分析的基础技术、基础算法,是计算机视觉当前热门研究方向之一。目前主流的3D数据表示方法主要有深度图、三角网格、体素和点云。其中,点云是最简单的一种3D数据表示方法,具有获取简单、易于存储、可视性强、结构描述精细等优点,而且能够方便地与深度图、体素等其他数据格式相互转换,已成为最基本的3D数据格式。近年来,随着深度传感器和三维激光扫描仪的普及运用,点云的获取变得越来越便捷,数据量、数据种类迅速增长,针对点云场景中的三维目标检测也因此深受关注,应用前景非常广泛。
随着深度学习的迅速发展和广泛应用,研究人员提出了大量基于深度学习的三维目标检测方法[1-4]。按照输入数据划分,主要有图像点云融合方法和纯点云方法。图像点云融合方法,结合了图像的高分辨率优势和点云的精确位置信息优势,首先利用成熟的二维目标检测算法从图像中获得目标位置,然后利用图像与点云的映射关系从点云中获得目标的候选区域,再从该区域提取目标的3D包围盒,典型的方法有F-PointNet[5]、Point-Fusion[6]、SIFRNet[7]、F-ConvNet[8]等。纯点云方法,按照点云的特征提取方式区分,可分为基于体素的方法和基于原始点云的方法。其中,基于体素的方法首先将点云转化为一个个堆叠的、相同大小的规则体素网格,然后提取体素网格特征,再进行类别和位置的预测回归,典型的方法有VoxelNet[9]、SECOND[10]、CIA-SSD[11]、SE-SSD[12]等;基于原始点云的方法直接作用于原始点云,直接学习提取点的特征,然后回归物体的3D包围盒,典型的方法有VoteNet[13]、PointRCNN[14]、STD[15]、3DSSD[16]等。
尽管上述方法在三维目标检测任务上都取得了不错的效果,达到了较高的精度和速度,但仍存在一定局限性。其中,图像点云融合方法的精度受二维目标检测器影响非常大,如果目标在二维图像中未被检测到,那么就不会在点云中继续检测,会出现漏检,并且此类方法需要将图像中检测的目标映射回点云,因此对传感器的同步要求很高。基于体素的方法,在将点云体素化过程中会有信息的隐性丢失。基于原始点云的方法,由于点云自身的稀疏性、离散性、无序性和旋转平移不变性等特点,特征提取算法设计较为复杂,且难以处理大规模点云。
基于原始点云的三维目标检测是一个非常具有挑战性的任务,主要有三大难点:一是原始点云数据量大,数据降采样计算代价昂贵、内存占用大;二是原始点云特征提取不充分、特征信息隐性丢失、感受野有限,且特征提取算法复杂、计算代价高;三是原始点云中的点均为物体表面点而非物体中心点,直接用物体表面点回归预测会导致候选包围盒质量不高。
为提高三维目标检测的精度和速度,本文提出了基于原始点云、单阶段、无锚框的RPV-SSD算法,针对以上问题,设计了随机体素采样层,能够利用随机采样的效率优势和体素网格采样的相对均匀分布优势,解决原始点云降采样难的问题,使得采样点铺满整个空间且包含更多前景点;设计了特征聚合层,能够聚合关键点逐点特征、3D稀疏卷积特征和鸟瞰图特征,解决点云特征提取不充分等问题;设计了候选点生成层,能够利用点的聚合特征将点向物体中心进行自修正,解决3D包围盒回归质量不高的问题。
1 整体框架
RPV-SSD算法网络结构如图1所示,具体可分为五个部分:(1)随机体素采样层,主要是将原始点云按照随机体素采样方法进行降采样,获得关键点点云。(2)3D稀疏卷积层,先将原始点云体素化,然后利用3D稀疏卷积提取点云特征,并将之投影到俯视图下获得鸟瞰图特征,待后续进行特征聚合。(3)特征聚合层,首先利用PointNet++[17]的SA(set abstraction)模块提取关键点逐点特征,然后从上一层获得的3D稀疏卷积特征和鸟瞰图特征中,取出每个关键点对应位置的特征,与逐点特征进行连接聚合。(4)候选点生成层,首先从关键点点云中取出关键点坐标,然后利用关键点的聚合特征为每个点生成一个坐标偏移量,两者相减即得到修正的候选中心点坐标。(5)区域建议网络层,将候选中心点坐标与特征聚合层获得的聚合特征组合,回归预测物体类别、3D包围盒及物体朝向。
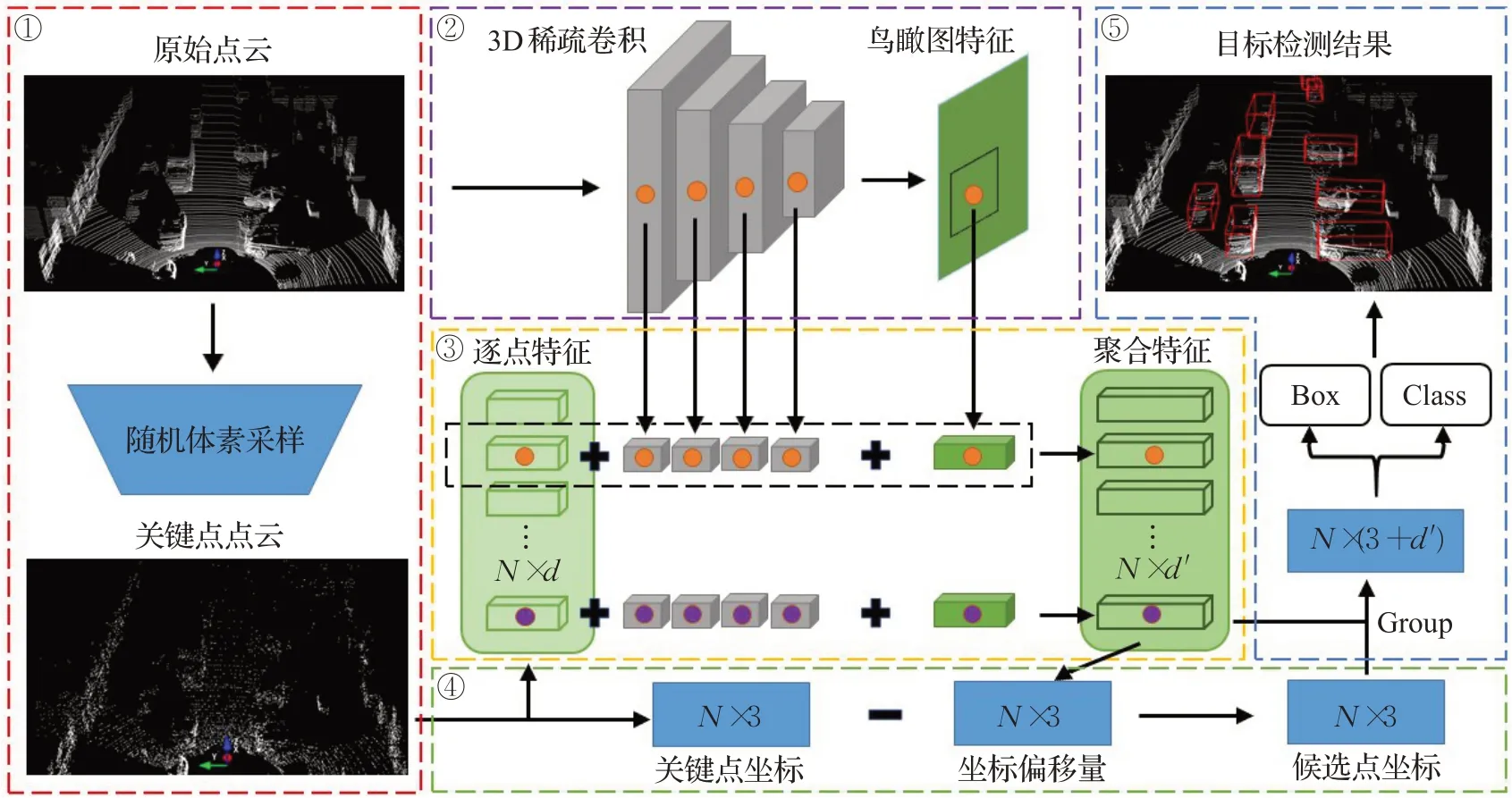
图1 RPV-SSD网络结构示意图Fig.1 Network framework of RPV-SSD
2 具体实现
2.1 随机体素采样层
激光雷达扫描的原始点云可能包含几十万甚至百千万个点,为降低数据规模,需对点云进行降采样。降采样难点主要有二,一是降采样算法的时间复杂度较高,二是点云的有效空间特征信息难保持。
现有的采样方法主要有最远点采样、格点采样、曲率采样、随机采样等。其中,最远点采样每次从点云中取一个距离已采样点集最远的点作为新采样点,该方法能够较好地保证采样点的均匀分布和场景覆盖率,但计算复杂度较高,与输入点云的点数量呈平方相关。格点采样将点云体素网格化后,从每个网格里采样自定义数量个点,其效率非常高,采样点分布也比较均匀,但均匀性相对最远点采样较低。曲率采样在曲率越大的地方采样点个数越多,由于噪点附近曲率较小,所以其抗噪性较强。随机采样随机地从点云中进行采样,每个点具有相同的被选中概率,其采样效率非常高,但场景覆盖率和点的均匀分布较差。
本文设计了随机体素采样算法,首先将点云体素网格化,然后对点云进行随机采样并放入对应体素网格。由于设置了体素网格最大采样点数,所以密集区域点云采样会受到抑制,相对地稀疏区域点云采样概率会得到提升,致使采样点更可能覆盖整个点云空间。该算法核心思想是利用了随机采样和格点采样二者的优势,在保证采样效率的情况下,提高场景覆盖率和前景点比例,最大限度保持原始点云有效空间特征信息,随机体素采样算法描述如下所示:

首先,输入N×3维的原始点云LiDAR,设置采样点总数量K,体素网格尺寸vd、vh、vw,单个体素网格最大采样点数T,以及采样点的范围xrange、yrange、zrange。初始化相关参数,主要包括计算体素网格尺寸范围D、H、W(高、宽、长),初始化体素网格内点的数量counts矩阵,随机排列原始点云的数组顺序,初始化已采样点个数k和已采样关键点集合keypoints。然后,从随机排列的点云LiDAR中按顺序取出第i个点(xi,yi,zi)。对于第i个点,首先判断该点是否在采样范围内,如果“否”则舍弃该点继续循环下一个点,如果“是”则计算该点所处的体素网格坐标(di,hi,wi),并进行两个判断:(1)判断当前已采样点的总个数k是否已达到采样目标数量K,如果达到则跳出循环结束采样,否则继续循环;(2)判断第i个点所处的体素网格内已采样点数量counts[di,hi,wi]是否达到单个体素网格最大采样点数T,如果“是”则舍弃该点继续循环,如果“否”则将该点添加到关键点集合keypoints中,同时将counts[di,hi,wi]和k分别加1,至此第i个点循环结束。遍历整个点云,最终输出K×3维的关键点集合keypoints。
表1和图2所示为随机体素采样和最远点采样在KITTI数据集[18]上的对比实验结果(采样率设置为0.1),可以明显看出,随机体素采样在相同采样率条件下,较最远点采样能够采集更多的前景点。
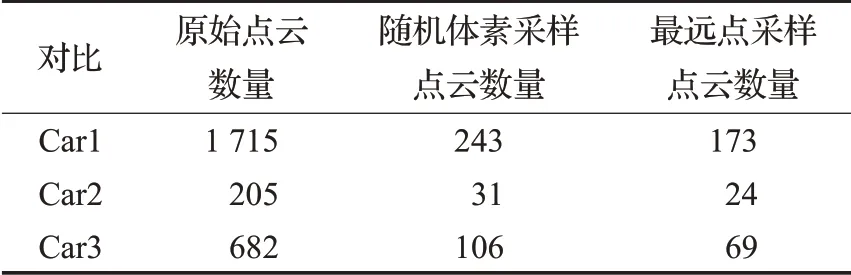
表1 KITTI数据集降采样对比实验Table 1 Sampling experiments on KITTI datasets
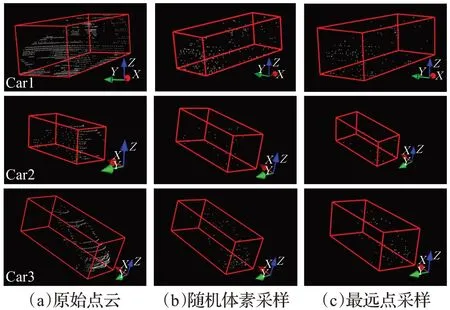
图2 KITTI数据集降采样对比实验Fig.2 Sampling experiments on KITTI datasets
2.2 3D稀疏卷积层
3D稀疏卷积层主要利用稀疏卷积算法[10]提取点云特征,其核心思想是建立一个输入输出规则对照表(RuleBook),使得卷积计算仅在非空体素网格上进行,避免了无效的空卷积操作,大大提高了卷积效率。
稀疏卷积算法包括两种卷积,一种是常规稀疏卷积,另一种是位置不变稀疏卷积,也译作子流形卷积。主要区别在于卷积的计算方式:常规稀疏卷积在3D卷积核覆盖非空体素时即进行卷积计算,而位置不变稀疏卷积只有当3D卷积核的中心覆盖非空体素时才进行卷积计算,图3对两种卷积进行了示意说明。

图3 两种稀疏卷积操作区别示意图Fig.3 Schematic diagram of difference between two sparse convolution operations
3D稀疏卷积层具体实现如下:
(1)点云体素化。对任意输入的点云,首先将其转换成体素网格。由于点云本身所处的三维空间是无限大的,为生成体素需确定一个有限的采样范围。以KITTI数据集Car为例,其在z轴、y轴、x轴的采样范围分别为[-3,1]、[-40,40]、[0,70.4](单位:m),体素网格尺寸vd、vh、vw分别为0.1 m、0.05 m、0.05 m,因此生成的体素网格高度、宽度、深度尺寸D、H、W分别为40、1 600、1 408。单个体素网格最大采样点数T取5,体素网格采样最大数量取16 384。
(2)体素特征提取。假设由第一步得到一个非空体素网格V={pi=[xi,yi,zi,ri]T}∈ℝ4}i=1,2,…,t,表示该体素网格中包含t个点(其中t不大于T),每个点pi包含4个维度特征,分别代表点云的三维空间坐标(xi,yi,zi)和反射强度ri,因此初始输入特征尺寸为(t,4)。首先计算该体素网格中所有采样点的中心点坐标(vx,vy,vz),计算方法如下:

然后利用中心点坐标计算该体素内每个点的相对偏移量(xi-vx,yi-vy,zi-vz),得到尺寸大小为(t,3)的相对坐标特征,并将每个点的相对偏移量与其初始输入特征叠加,得到大小为(t,7)的体素特征Vin={p̂i=[xi,yi,zi,ri,xi-vx,yi-vy,zi-vz]T}∈ℝ7}i=1,2,…,t。最后,利用体素特征提取层[9(]voxel feature encoding)进一步提取体素网格特征Vout。
(3)稀疏卷积。稀疏卷积网络结构如图4所示,其中橙色方形表示位置不变稀疏卷积SubMConv3d,蓝色方形表示常规稀疏卷积SparseConv3d,两类卷积均包含(in_channels,out_channels,kernel_size,stride,padding)5个参数,其中in_channels、out_channels表示输入、输出特征通道数,kernel_size表示卷积核尺寸(默认为3),stride表示卷积步长(默认为1),padding表示填充数量(默认为0)。每个卷积后均连接1个批归一化层和1个ReLU激活函数。该网络由Conv1、Conv2、Conv3、Conv4四个卷积组构成,每组都进行了padding操作,并且除第一组外,每组都进行了下降样(卷积步长为2)。输入第二步得到的体素网格特征Vout,可计算得到每组卷积的体素特征f conv1、f conv2、f conv3、f conv4及鸟瞰图特征f BEV。以KITTI数据集Car为例,输入(40,1 600,1 408)尺寸的体素网格特征,最终将得到(2,200,176)的二维鸟瞰图特征。
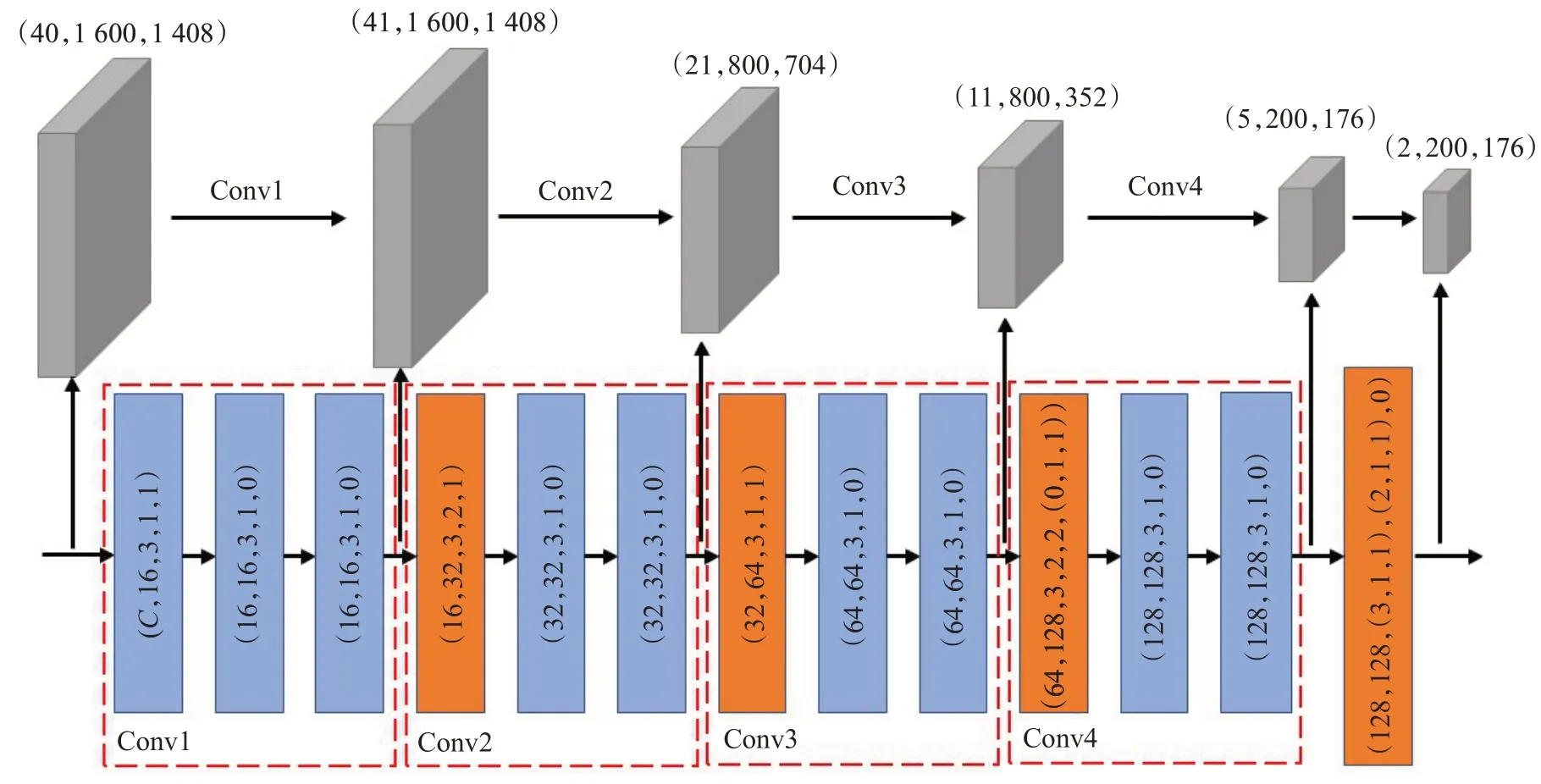
图4 3D稀疏卷积层网络结构示意图Fig.4 Network framework of 3D sparse convolutional layer
2.3 特征聚合层
特征聚合层由两部分组成,第一部分是生成关键点集合的局部特征,第二部分是特征聚合。具体如下:
(1)关键点特征生成。利用PointNet++[17]的SA模块对关键点进行逐点特征提取。SA模块包括采样、分组、特征提取三个步骤,其中:采样是将原始点云降采样成若干个关键点,主要利用随机体素采样算法进行降采样;分组,利用球查询求得以关键点为中心的球半径范围内所有点集合,将其编为一个组,通过改变球半径大小可以获得不同的感受野;特征提取,将PointNet[19]网络应用于每个分组的点,得到分组特征。重复SA模块逐级提取过程,可获得整个点云的特征
(2)特征聚合。主要是聚合关键点特征、3D稀疏卷积特征和鸟瞰图特征。对于keypoints关键点集合中的任意点pi来说,将其逐点特征与3D稀疏卷积特征和鸟瞰图特征进行拼接,得到将其送入多层感知机MLP中,得到(N,d′)维关键点聚合特征。
逐点特征不仅包含每个关键点的精确坐标,利于后续3D包围盒回归,而且由于采用了PointNet++中的SA模块进行特征提取,因此具有较大且更为灵活的感受野;3D稀疏卷积特征和鸟瞰图特征由体素化点云稀疏卷积计算得到,不仅计算效率高,而且包含了由低到高多个级别语义特征,能够描述更为精细的点云空间结构。聚合了上述所有特征,相比于单个点云特征,其涵盖了更多有用信息,特征提取更充分。
2.4 候选点生成层
激光雷达通过发射激光束测算物体的位置,激光遇到物体表面即发生反射,故激光雷达采集的点云位于物体表面而非物体中心。然而,利用物体表面点直接进行3D包围盒回归,包围盒质量较差,而利用物体中心点进行回归,效果相对较好[13]。因此,Qi等人设计了VoteNet,利用霍夫投票网络生成一些靠近物体中心的虚拟点。为提升包围盒质量,本文设计候选点生成层,利用MLP将关键点(降采样得到的物体表面点)向物体中心进行修正,如图5所示。

图5 关键点坐标修正示意图Fig.5 Schematic diagram of keypoints coordinates correction
首 先 从keypoints={pi=[xi,yi,zi,ri]T}∈ℝ4}i=1,2,…,K中取出关键点pi的三维坐标(xi,yi,zi);利用该点的聚合特征,估计该点概略中心位置。具体地,设计一个MLP函数,在对网络训练时,引入一个强监督,即利用真值标签的物体中心点坐标,对物体表面点与中心点的坐标偏移量进行监督学习,监督标签设为预测时,利用聚合特征估计坐标偏移量,并将其与关键点坐标相减得到坐标为的点,称之为候选点,作为下一步回归的近似中心点。
2.5 区域建议网络层
区域建议网络采用anchor-free方法回归物体的3D包围盒,采用三维中心度方法计算物体的类别。将候选点坐标与聚合特征拼接组合,作为区域建议网络的输入。
(1)3D包围盒回归
为实现物体3D包围盒的无锚预测,将其参数化为(dx,dy,dz,dl,dw,dh,r)7个目标回归量,其中(dx,dy,dz)表示候选中心点到真值标签中心点的距离,(dl,dw,dh)表示预测物体的长、宽、高尺寸信息,r代表偏航角yaw,即物体绕y轴(velodyne坐标系下为z轴)的旋转角度。
(2)物体分类
区域建议网络会生成许多重复地3D包围盒,质量参差不齐,一般通过NMS方法去除冗余,仅保留置信度较高的包围盒。然而,分类置信度和定位精度之间存在不对齐问题[11],也即两者不完全成正比,存在置信度分值较高但包围盒质量较差的情况,致使NMS剔除了质量较好的3D包围盒,导致检测精度下降。
为了缓解这种不对齐问题,借鉴FCOS[20]提出的二维目标检测中心度,如图6所示,提出三维中心度。三维中心度是一个0到1之间的值,计算公式如式(2)所示,反应了候选中心点到真值标签中心点的(标准化)距离,越大表明该点越靠近物体中心。


图6 中心度示意图Fig.6 Schematic diagram of centerness
式中,(f,b,l,r,t,d)6个变量分别表示候选中心点到其对应的真值标签包围盒前、后、左、右、上、下六个面的距离。
首先,在3D包围盒NMS操作前将该包围盒的置信度分值乘以其对应候选中心点的三维中心度,得到真正用于NMS的置信度分值,从而过滤掉中心度较小、质量较差但置信度分值较高的包围盒。根据候选中心点是否在某一个物体内确定一个lmask,这个是一个非0即1的二值,表示是否在物体内。最后,对于任一候选中心点,将lctrness与lmask相乘得到最终的分类标签ui。
3 损失函数
RPV-SSD的全局训练损失函数由分类损失、回归损失和候选点偏移损失三部分组成,计算公式如下:

式中,Nc表示所有候选点的个数,Np表示候选点中属于前景点(即待检测物体)的个数,Lc、Lr、Ls分别表示分类损失、回归损失和候选点偏移损失。
(1)分类损失
分类损失Lr采用交叉熵损失(cross entropy loss)函数计算,计算公式如下:

式中,si表示神经网络分类分支的预测值,ui表示分类标签,由lctrness与lmask相乘得到。
(2)回归损失
回归损失Lr主要包括距离回归损失Ldist、尺寸回归损失Lsize、角度回归损失Langle和角点回归损失Lcorner四个方面。
①距离回归损失Ldist,采用smooth L1损失函数对候选中心点到真值标签中心点的距离(dx,dy,dz)进行计算,计算公式如下:
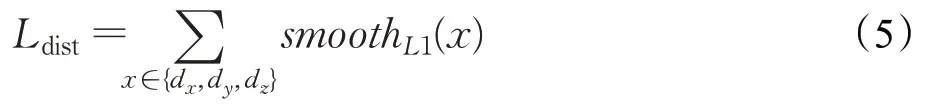
其中:
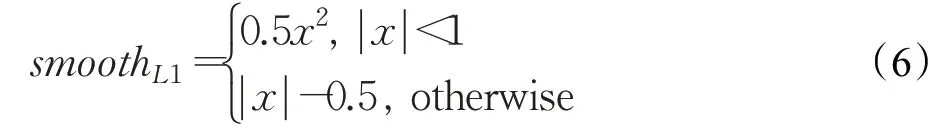
②尺寸回归损失Lsize,同样采用smooth L1损失函数对预测目标的长宽高尺寸(dl,dw,dh)与真值标签尺寸(l,w,h)的差值(dl-l,dw-w,dh-h)进行计算,计算公式如下:
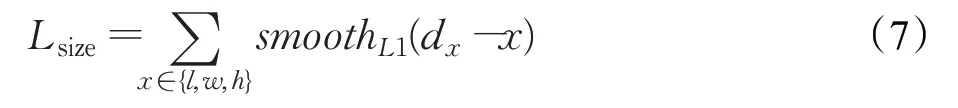
③角度回归损失Langle,包含bin、res两部分,其中整数部分bin采用分类损失,小数部分res采用回归损失,计算公式如下:

式中,dca、dra分别代表预测角度的整数部分和小数部分,tca、tra分别代表真值标签中偏航角对应的整数部分和小数部分。
④角点回归损失Lcorner,即预测包围盒的八个角点{Pm}m=1,2,…,8与真值标签八个角点{Gm}m=1,2,…,8之间的欧式距离,计算公式如下:

(3)偏移损失
偏移损失是针对候选点生成层中的监督学习任务设计的,计算的是候选点向中心点修正时预测的坐标偏移量(xishift,yishift,zishift)与候选点到对应的真值标签中心点实际坐标偏移量zi-zigt)之间的误差,同样采用smooth L1损失函数计算,计算公式如下:
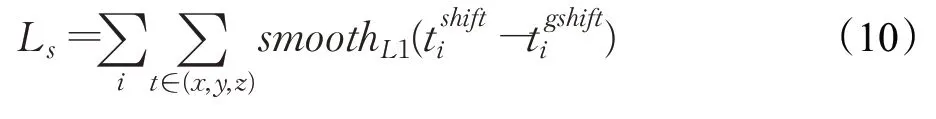
4 实验与分析
本文在KITTI三维目标检测数据集上对RPV-SSD算法性能进行了测试评估,并与当前性能较好的一些方法做了对比,最后对检测结果进行了可视化分析。
4.1 实验环境
本文所使用的实验硬件平台为Intel®Xeon Silver 4110 CPU@2.10 GHz(双处理器),内存(RAM)64 GB,NVIDIA GTX 2080Ti显卡(显存16 GB),操作系统为Ubuntu 16.04LTS,实验软件:使用Python3.7.10和Pytorch1.3.1搭建深度学习网络模型,使用CUDA 10.1和cuDNN 7.6.5进行计算加速,使用mayavi 4.7.1、opencv 3.4.2和matplotlib 3.3.2分别进行点云和图像可视化。
4.2 参数设置
训练过程中,按照文献[21]中所描述的方法将KITTI训练集按照0.5∶0.5的比例划分为训练集与验证集,二者分别包含3 712张图像和3 769张图像。对于不同类别目标的IoU阈值设置,汽车的设为0.7,行人和骑行的人设为0.5,当预测框与真值框交并比超过这一阈值,则认为命中该实例。
训练时,采用Adam算法对网络模型参数进行优化更新,训练的epoch设置为200个,batch_size设置为4,每个epoch迭代928个batch,总迭代步数steps共18.56万个,Adam优化器初始学习率设置为0.001,动量系数β1和β2设置为0.9和0.999,学习率ηt随着迭代epoch次数增加而衰减,衰减率ρ设置为0.8,每20个epoch衰减一次,学习率更新公式如下:

式中,t为已完成训练的epoch总次数,T取20表示衰减周期。
4.3 结果分析
表2列出了不同算法在KITTI汽车(Car)上的3D检测结果和BEV检测结果(利用平均精度AP作为评测度量),表中“L”和“R”代表LiDAR点云和RGB图像。
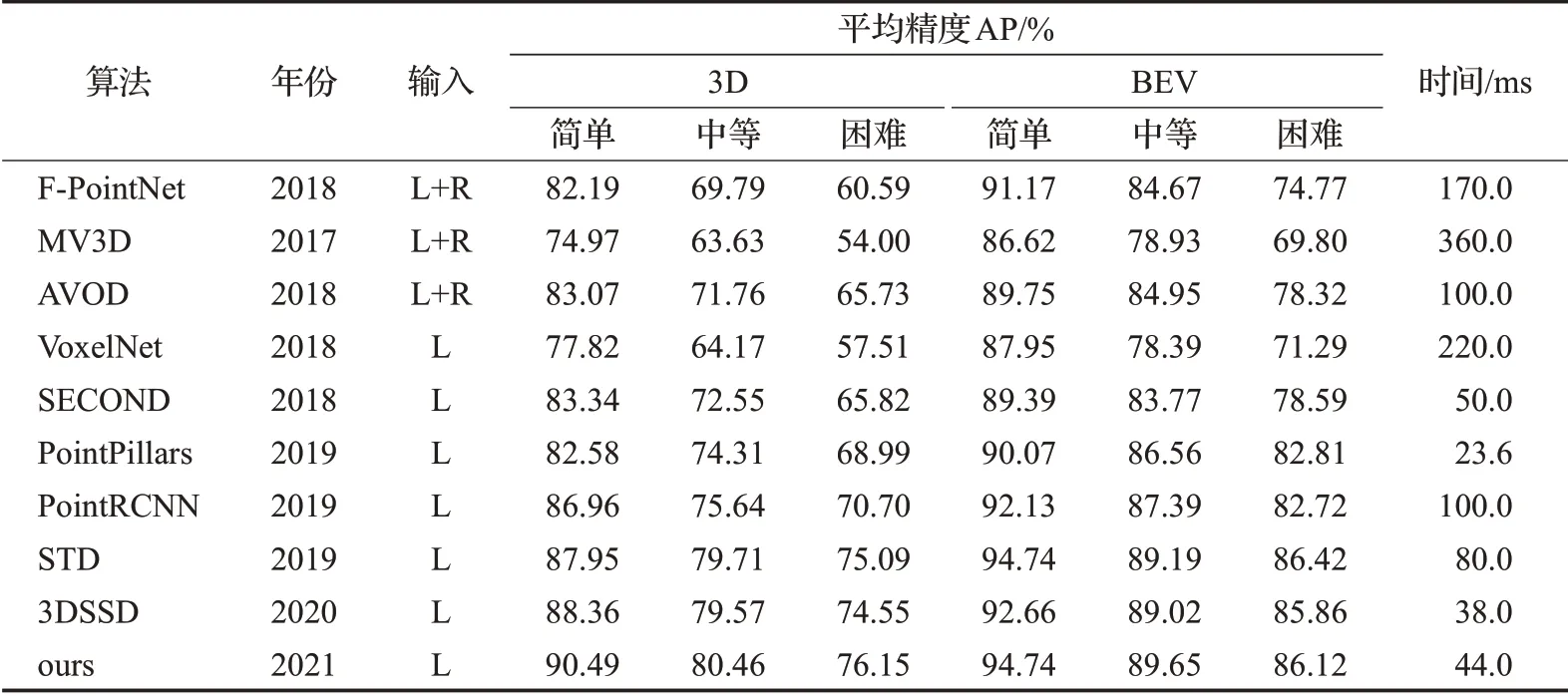
表2 不同算法在KITTI汽车上的检测结果Table 2 Detection results of different algorithms on KITTI car
可以看出,RPV-SSD算法在KITTI汽车上的检测精度较3DSSD有显著提升。在3D目标检测基准上,RPV-SSD在简单、中等、困难三个检测难度上分别提升约2.13、0.89、1.60个百分点,如图7所示;在BEV目标检测基准上,分别提升约2.08、0.63、0.26个百分点。算法精度的提升,分析认为是由于在特征提取时聚合了3D稀疏卷积特征和鸟瞰图特征。在算法的时间复杂度方面,RPV-SSD较3DSSD相对较长,单帧数据推理时间分别为44 ms和38 ms,分析认为是增加了体素稀疏卷积导致推理时间变长。
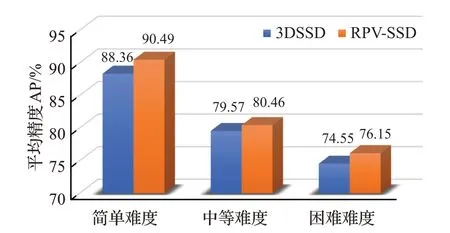
图7 3DSSD和RPV-SSD的3D检测结果对比Fig.7 Comparison of 3DSSD and RPV-SSD 3D object detection results
为比较逐点特征、3D稀疏卷积特征、鸟瞰图特征和候选点生成层对算法性能提升的贡献率,本文做了消融实验,即把上述模块分别从原始模型中移除,然后对网络重新训练,观察各个模块移除后检测性能的变化,具体实验结果如表3和表4所示。
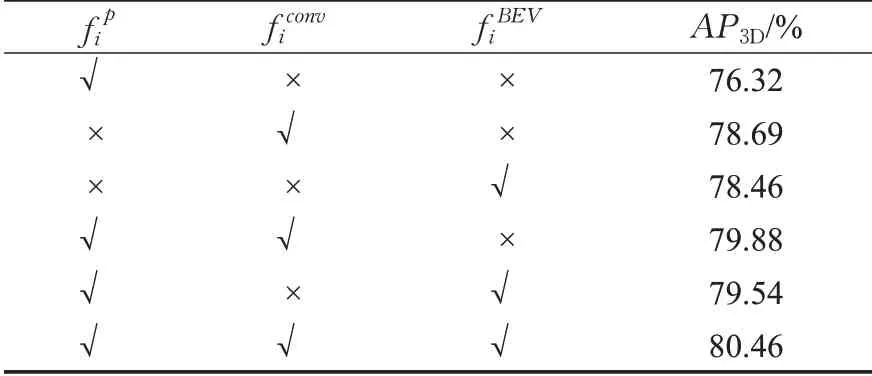
表3 各级别特征对模型性能的影响Table 3 Influence of characteristics of different levels on model performance

表4 候选点生成层对模型性能的影响Table 4 Influence of candidate point generation layer on model performance
由表3可以看出,单独利用逐点特征、3D稀疏卷积特征、鸟瞰图特征进行训练时,模型性能下降较大。当只使用来自关键点的逐点特征时,模型性能下降4.14个百分点,分析认为是逐点的浅层特征不足以提出较好的候选框。当在逐点特征基础上再聚合深层的3D稀疏卷积特征或更高级别的鸟瞰图特征时,则能显著提高模型性能,分别提升3.56和3.22个百分点。如果更进一步聚合所有特征,则仍能继续提升性能,分别提升0.58和0.92个百分点,达到最终模型的最佳性能。对于这一步性能提升幅度变小的原因,分析认为是3D稀疏卷积特征与鸟瞰图特征具有某种相关性,当已经聚合了某一个时,再聚合另一个对模型性能影响减小。从上述数据比较中可以得出,对于模型性能提升的贡献率,3D稀疏卷积特征>鸟瞰图特征>逐点特征。
由表4可以看出,移除候选点生成层,平均精度降低了9.18个百分点,说明利用物体不同位置的点进行3D包围盒回归,对模型的性能影响较大。分析认为,利用物体近似中心点回归3D包围盒,相较于物体表面点,能够得到更高质量的包围盒,提升了网络预测与真值标签3D包围盒的交并比,进而提升了精确率和召回率,提高了精度。
4.4 可视化分析
本文对RPV-SSD算法预测的类别和3D包围盒进行了可视化,并与真值标签进行了对比,图8展示了四个不同场景的对比结果。其中,每个场景的左上图为相机图片,左下图为点云截图,右图为鸟瞰图。为便于观察对比,使用绿色包围盒和文字表示算法的预测结果,红色包围盒和文字表示真值标签,点云截图中每个包围盒附近的“Car”“Pedestrian”“Cyclist”(图像和鸟瞰图中每个包围盒附近的“C”“P”“B”)分别表示汽车、行人和骑行的人三类目标。为更好地进行可视化分析,从KITTI数据集calib参数文件中取出相机与激光雷达传感器的转换矩阵,将3D包围盒从velodyne坐标系映射到相机坐标系,并将其显示在相机图片中。

图8 不同场景算法预测结果与真值标签对比示例Fig.8 Example of comparison between algorithm prediction results and truth labels in different scenarios
根据上述可视化结果,分析得出:
(1)RPV-SSD算法不仅能够检测出近处遮挡较少、数据点丰富的物体,而且对于远处遮挡、截断、重叠、数据点稀疏的物体同样有效。以图8(a)场景为例,算法可以将真值标签中的7辆汽车(Car)全部命中,并且回归质量较高的3D包围盒。对于部分被遮挡未标注的汽车,虽然图片中无法准确辨识,但算法仍然能够做出准确预测,说明算法能够利用物体的部分点云预测出物体的类别和整个包围盒。图8(d)中的可视化结果更能说明这一点,算法不仅检测到了真值标签中的8个行人(Pedestrian)和1个骑行的人(Cyclist),还检测出了道路远处密集重叠在一起的行人和汽车。分析认为,此类目标的点云虽然较为稀疏,但随机体素采样方法仍能采集到目标关键点,进而实现检测。另一方面也从侧面反映出基于点云的目标检测优势,它能够非常容易辨识和定位二维图像上难以区分开的遮挡重叠目标。
(2)RPV-SSD算法存在错误检测和虚假检测的情况。以图8(b)场景为例,算法虽命中了真值标签中的所有目标,并检测出了远处遮挡重叠的未标注汽车,但却将远处骑行的人误检测为行人,并且将道路旁边的墙面和花草虚检测为行人。图8(c)场景也出现了此类情况,算法将远处的广告标牌虚检测为行人,将路边停放的一辆自行车虚检测为骑行的人。对于误检和虚检的情况,分析认为是其点云分布的三维空间结构与误(虚)检目标的形态较为相似,虽然在图像中能够清晰的分辨出差异,但是在三维点云中却难以区分。对于这种情况,一个可行的解决思路是集成学习方法,即利用图像和点云两种传感器数据分别实现目标检测后再进行集成对比检测。
5 结束语
本文在梳理三维目标检测技术路线的基础上,分析了当前基于原始点云的三维目标检测任务存在的困难挑战,提出了一种基于原始点云、单阶段、无锚框的三维目标检测算法RPV-SSD。KITTI数据集上的实验结果和可视化分析表明,该算法整体表现良好,不仅能够命中真值标签中的目标并且回归质量较高的3D包围盒,还能够从物体的不完整点云(距离较远、存在遮挡截断重叠等情况)推测出物体的类别及其完整形状。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05
家庭医学(2022年3期)2022-04-07
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
计算机集成制造系统(2020年4期)2020-05-08
电脑报(2019年4期)2019-09-10
中国惯性技术学报(2019年1期)2019-05-21
大众摄影(2015年9期)2015-09-06
