
融合注意力机制的轻量级戴口罩人脸识别算法
2023-02-14 10:31叶子勋张红英何昱均
计算机工程与应用 2023年3期
叶子勋,张红英,何昱均
1.西南科技大学 信息工程学院,四川 绵阳 621010
2.西南科技大学 特殊环境机器人技术四川省重点实验室,四川 绵阳 621010
3.西南科技大学 计算机科学与技术学院,四川 绵阳 621010
人脸识别在当下仍是一种广泛应用的身份验证手段,鉴于新型冠状病毒肺炎(COVID-19)在全球范围的肆虐,许多国家要求人们在公共场合佩戴口罩。因为佩戴医用外科、KN95、N95等口罩是目前防范包含新型冠状病毒肺炎在内的呼吸道传染病传播最为有效、经济的手段。学术界认为,新型冠状病毒将与人类长期共存[1],佩戴口罩出行已然成为人们日常生活中的常态。在机场、火车站等身份识别场景中,以及在社区、学校、公司等身份验证场景中,佩戴口罩会隐藏部分人脸特征,阻碍人脸识别系统做出正确的决策,因此人们必须摘下口罩进行人脸识别,此举提高了呼吸道暴露在病毒中的概率,给病毒以可乘之机,提高了感染风险。因此探索出一种戴口罩人脸识别算法对于公众防范新型冠状病感染具有重要意义。
长期以来,局部特征方法和浅层特征学习一直是人脸识别研究的重点[2]。直到2015年FaceNet[3]的诞生,这才将人脸识别的研究重心转移到基于深度学习的方向,当前基于深度学习的最先进的方法如ArcFace[4]、CosFace[5]等在LFW[6]数据集上的准确率已经达到99.5%以上,深度学习在人脸识别研究中取得了巨大的成功。但基于深度学习的方法仍不能解决环境光照、人脸姿态、局部遮挡等不可控环境因素所带来的影响。
其中,面部遮挡是人脸识别算法中最具挑战的问题之一,此前的一些研究都是处理眼镜、面部饰品等一系列遮挡面积较小的遮挡场景[7-8],然而口罩这一遮挡物造成了鼻子、嘴巴这两个人脸固有结构的缺失,也给人脸关键点位置信息带来了更多的噪声,半数的人脸关键特征被隐藏。相较于其他遮挡物,口罩遮挡给人脸识别算法带来了更大的挑战,因此口罩遮挡人脸识别又是遮挡人脸识别中的难点。当前,基于深度学习的遮挡人脸识别主要可分为三个研究方向,第一种是优化损失函数:文献[9]使用ArcFace与口罩人脸分类损失函数相结合的方式,设计了MTArcFace(multi-task ArcFace)损失函数,使得模型兼具无遮挡与遮挡两种场景下的人脸识别任务;文献[10]提出了Balanced Curricular Loss损失函数在训练过程更有力地在遮挡人脸中发掘困难样本。第二种是基于注意力的方法,文献[11]提出了一种基于裁剪和注意力机制的方法,只截取口罩佩戴人脸的眼部区域以训练人脸识别模型,这种方法的缺陷也较为明显,由于人脸的部分特征有所缺损,在无遮挡人脸识别场景下,准确率有所下降;文献[12]使用约束三元组损失函数Constraint Triplet Loss来获得用于口罩遮挡人脸识别的优化嵌入,并借此重点关注眼部区域;文献[13]将同一个人的上半人脸与遮挡人脸分别输入到网络中计算Loss,也能兼顾有遮挡和无遮挡这两种识别场景。第三种是基于人脸修复的方法,文献[14-16]使用生成对抗网络GAN预测被遮挡的脸部区域特征,将其还原到未被遮挡时的状态,再将还原后的人脸传入到识别网络中。然而,基于对抗网络的方法无法重现人脸关键点的具体细节,且遇到口罩等大面积遮挡物的重建效果不理想,识别准确率提升不大。文献[17]使用虚拟口罩遮挡数据集和ArcFace损失函数重新训练当前三种先进的轻量级人脸识别模型得到了适配口罩遮挡场景的轻量级模型VarGFaceNet-Mask、MobileFaceNet-Mask、Shuffle-FaceNet-Mask,然而这些模型不能兼顾无遮挡场景和口罩遮挡场景下的人脸识别任务。
基于深度学习的人脸识别方法都需要大规模的人脸图片作为训练集,然而当前的无遮挡人脸训练集有很多,但口罩遮挡人脸训练集很少,ICCV 2021戴口罩人脸识别比赛的冠军方案[18]采用FMA-3D[19]对2D人脸图片进行3D重建,生成人脸的UV映射图,在映射图中添加口罩后返回2D人脸,用于制作虚拟口罩遮挡数据集,但这种方法还存在这一些问题,因此本文提出了一种生成三维人脸网格后,逐网格进行仿射变换添加虚拟虚拟口罩的数据增强器,并与冠军方案做了多维度的对比以证明本文方法的优越性。
在这项工作中,本文提出了一种融合注意力机制的轻量级人脸识别算法GhostFace,该算法能兼顾未佩戴口罩和戴口罩场景下的人脸识别任务。首先,针对当前人脸识别模型规模庞大的缺点,本文以改进后的Ghost-Net[20]为主干特征提取网络,通过一系列的线性变换,可以花费更少的运算量从原始特征中发掘出所需信息的特征信息,使得模型参数量下降了一个量级,以便在嵌入式、移动设备上部署模型;其次,采用基于人脸修复还需要对输入图片进行有无遮挡的判断,并且修补人脸进一步降低了识别效率,而采用裁剪的方法将降低在无口罩遮挡场景下的识别精度,而本文所提出的融合空间注意力机制的FocusNet可使算法对人脸的眼、眉部分进行重点关注,通过这种方式不会损失人脸被遮挡区域的局部特征,在遮挡和无遮挡任务中都有较高的准确率。最后,针对当前口罩遮挡人脸数据集不充分的问题,提出了一种采用三维人脸网络生成添加口罩遮挡的数据增强方法。
1 GhostFace网络结构
GhostFace——以GhostNet为Backbone的口罩遮挡人脸识别网络主要包含以下几个部分:
第一部分是本文提出的对输入人脸增加口罩遮挡的实时数据增强器。第二部分是由GhostNet构成的主干特征提取网络,此部分将口罩遮挡人脸图片初步提取为3个不同尺度的特征张量。第三部分是本文提出的特征加强提取网络FocusNet,此部分将来自主干特征提取网络的2个不同尺度的特征层进行特征融合,并引入了注意力机制,此部分能自适应地融合有判别力的人脸关键部位信息,在遮挡和无遮挡任务中都有较强的鲁棒性。第四部分是分类器,此部分在网络的特征加强提取模块之后接上一个全连接层用于构建人脸分类器,可在后续的模型训练过程引入Arcface损失函数辅助模型更快收敛。整体的网络结构如图1所示,接下来将对网络结构分模块进行详细阐述。

图1 整体网络结构Fig.1 Overall network structure
1.1 主干特征提取
MobileNets[21-23]系列轻量化卷积神经网络是为嵌入式等移动设备设计的,实验发现这些网络生成的特征图存在一定的冗余,而且其使用的深度可分离卷积中的点卷积部分中使用了大量的1×1卷积,运算量仍有待优化。GhostNet提出Ghost module代替深度可分离卷积中的点卷积,在识别性能不变的情况下,降低了运算量。一般卷积过程如图2所示,给定一个输入特征图G∈ℝC×H×W,经过C′个卷积核K∈ℝC×K×K卷积之后得到输出特征图G′∈ℝC′×H′×W′,其运算量(FLOPs)为:
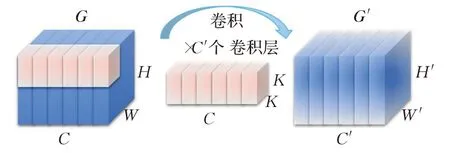
图2 一般卷积过程Fig.2 General convolution process
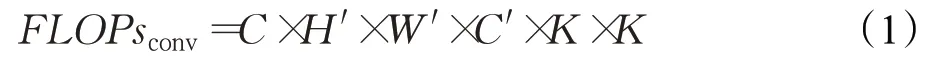
Ghost module的卷积过程如图3所示,给定一个输入特征图G∈ℝC×H×W,经过C′个卷积核K∈ℝC×K×K卷积之后得到中间特征层G′∈ℝC s×H′×W′,其中的s为超参数,它决定了此次卷积对通道压缩的程度。再使用深度可分离卷积对G′进行卷积之后与G′本身拼接起来得到输出特征图G″∈ℝC′×H′×W′,其运算量(FLOPs)为:
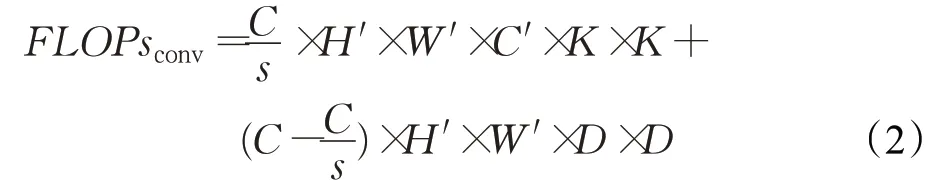
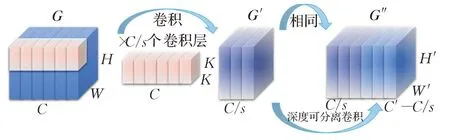
图3 Ghost module的卷积过程Fig.3 Convolution process of Ghost module
由此可见使用了Ghost module之后,模型的运算量得以降低,然后再使用Ghost module和深度可分离卷积之间的组合构成了残差网络Ghost bottleneck用于减缓深层网络的梯度消失现象。如图4所示。主干特征提取网络GhostNet便是由尺度不同的Ghost bottleneck前后连接所组成的,原GhostNet的输入大小为(224,224,3),并在最开始使用步长为2的3×3卷积进行下采样,本文将此卷积的步长变为1,并修改网络输入大小为(112,112,3),这样做可增大深层网络的尺度,有利于获取更多特征。

图4 Ghost bottleneck残差结构Fig.4 Ghost bottleneck residual structure
1.2 加强特征提取网络
为了使算法能自适应地融合有判别力的人脸关键部位信息,并在遮挡人脸识别中重点关注未被遮挡的上半脸区域,本文提出了一种融合空间注意力机制的FocusNet加强特征提取网络。其网络结构如图5所示。

图5 FocusNet加强特征提取网络Fig.5 FocusNet enhanced feature extraction network
首先从主干特征提取网络中分别取出尺度为(14,14,112)和(7,7,160)的特征层feat1、feat2。并将feat2通过1×1卷积和上采样操作得到尺度与feat1相同的特征层feat3,之后就可以将feat1与feat3拼接起来得到尺度大小为(14,14,224)的融合特征层feat4。
受CSPNet[24]的启发,本文将融合特征层feat4分别进行两次普通卷积得到两个相同尺度的特征层,并将第二个特征层接入连续三个Ghost bottleneck后与第一个特征层直接进行拼接。这样就构建了一个大残差边,之所以称之为大残差边是因为Ghost bottleneck也包含了残差结构,也就是说大残差网络中还包含了小残差网络。
将此大残差网络接入空间注意力机制之后得到特征层Spatial1,将Spatial1进行下采样后与feat3拼接得到融合特征层feat5,此时在feat5后连接一个倒置的大残差网络,与上述步骤相同,最终输出特征层Spatial2到分类器中。使用大残差网络这就意味着只有一半的特征通道要经过小的残差结构,另一半直接与经过小残差结构的输出进行拼接,这样做相较于直接使用常规的残差结构可以减少一部分计算量,空间注意力机制则能从不同尺度的特征层中发掘有判别力的空间信息,后续将阐述空间注意力机制是如何作用的。
1.3 注意力机制
GhostNet延续了MobileNet系列的通道注意力机制(squeeze and excitation,SE),称之为通道注意力机制是因为网络只在通道上引入了注意力,部分能带来更多有利于识别任务的特征通道的权重得以增加,其他特征通道的权重得以抑制。然而遮挡人脸识别任务中,更应该重点关注空间上的信息,例如眼睛、眉毛、额头部分的纹理信息,因此本文引入了空间注意力机制在加强特征提取网络中。
空间注意力机制对输入特征图G∈ℝC×H×W使用大小为(H×1)的池化核沿着水平方向和大小为(1×W)的池化核沿着垂直方向进行平均池化操作。因此,在高度为h时,第c个通道的输出为:
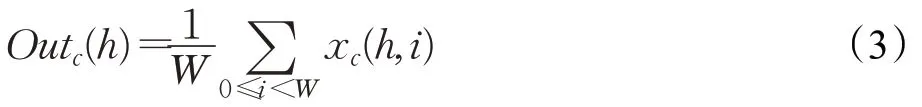
同理在宽度为w时,第c个通道的输出为:

如图6所示,有了上述的计算公式之后,给定一个输入特征图G∈ℝC×H×W,设Wacvg∈ℝC×1×W、Hacvg∈ℝC×H×1分别表示输入特征图在水平方向和垂直方向进行二元自适应均值池化得到浓缩特征。
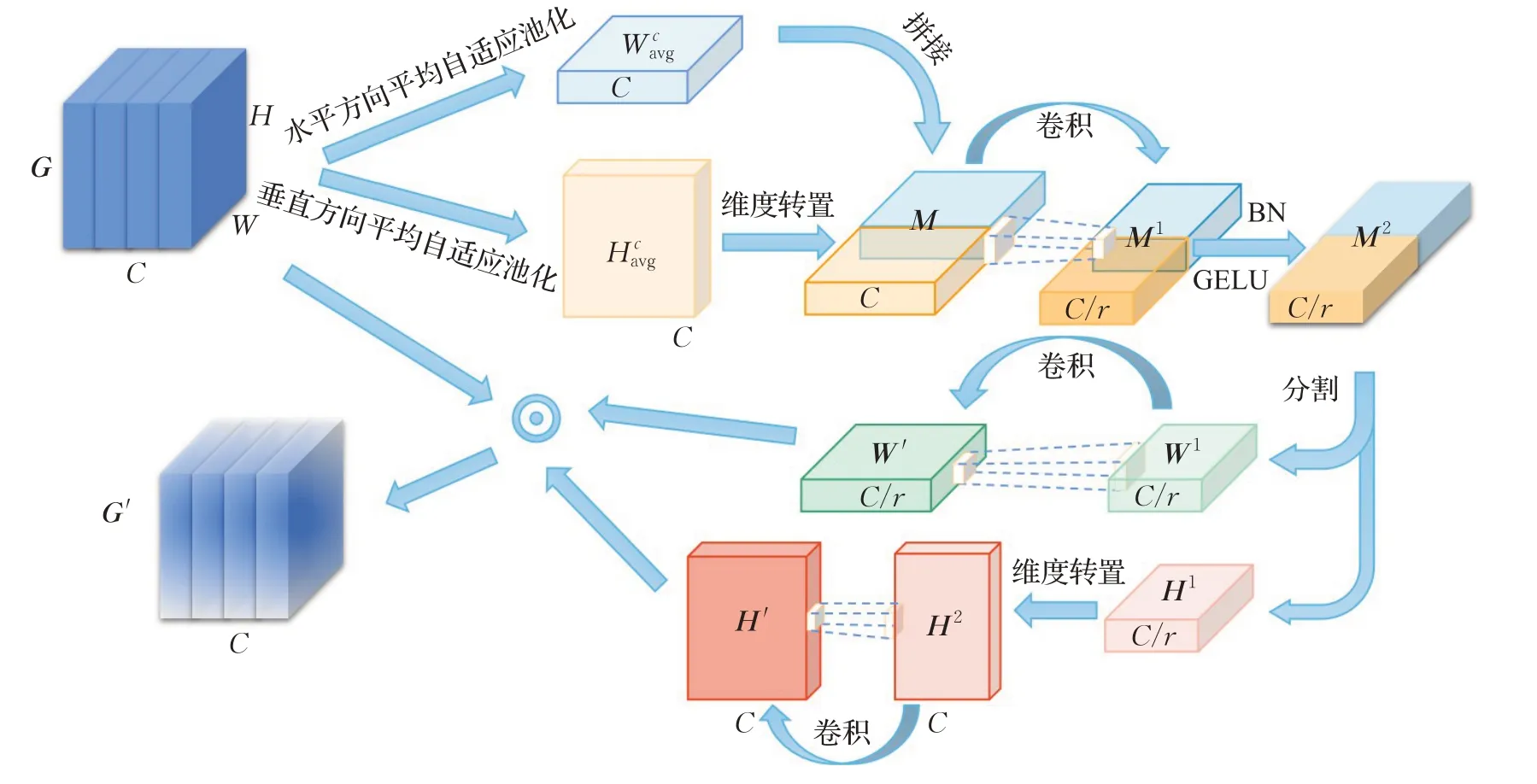
图6 空间注意力机制结构Fig.6 Structure of spatial attention mechanism
(1)首先对浓缩特征进行拼接,由于特征Wacvg和Hacvg之间的维度不匹配,因此需要将特征Hacvg的宽、高维度进行转置后再与Hacvg进行拼接得到特征层M。
(2)设定一个超参数r,使M经过1×1的2维卷积之后得到特征层M1,其通道由c变为c r,本文设定r=32且M1的通道数不得小于8。接下来插入一个BN层和GELU激活函数得到特征层M2,此时的M2同时具备了输入特征G在x轴和y轴上的特征浓缩,因此输入特征G在空间上的信息得以交互。
(3)将混合了空间位置信息的M2进行分割后进行转置,再次通过1×1的2维卷积之后变回通道数为c的W′、H′,这两个特征层的参数代表了空间上的权重。最后将W′、H′与G矩阵对应位置元素进行相乘得到G′,也就是将空间上的权重叠加在输入特征层中,因此G中有利于识别任务的空间上的权重得以增加,图中⊙表示G′与H′、W′逐通道地将对应位置元素两两相乘:
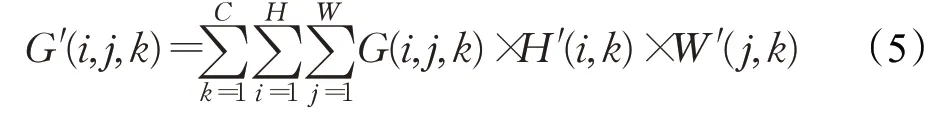
其中G′为注意力机制的输出,G为原始的输入特征图,C、H、W分别代表特征图的通道数、高宽的维度,且H∈ℝC×H×1、W′∈ℝC×1×W。
1.4 损失函数
当获取到分类器提取的长度为512人脸特征向量x之后,本文使用ArcFace作为损失函数,将人脸特征向量x映射到超球体上,并压缩相同人脸特征向量x的余弦距离,扩大不同人脸特征向量x的余弦距离:

其中,N为样本数(人脸图片数),n为类别数(人脸种类数),s为超球体的半径,θ为权重W和人脸特征向量x之间的夹角,xi为网络输出的第i个人的人脸特征向量,yi则是第i个人的标签,且权重W与人脸特征向量x都要进行归一化。ArcFace通过在此夹角θ上添加一个间距m,进一步增大了不同人脸特征之间的余弦间隔,这样做可以使模型学习到的特征具有更强的判别能力。代码实现则是通过ArcFace预测的人脸标签logitsArcFace和真实人脸标签labelid计算交叉熵得到最终的损失函数,其中CrossEnt代表交叉熵损失函数:
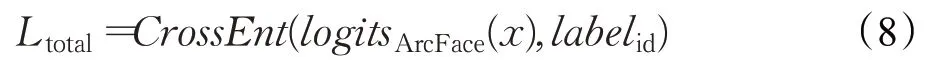
2 数据增强
人脸识别的数据集有很多,但是口罩遮挡人脸数据集的样本很少,不能满足训练识别模型的需求。当前遮挡识别算法主要是在原始数据集的基础上进行人脸关键点检测后,将各类口罩对应关键点位置直接贴到人脸上,在正脸情况下接近真实图片,但遇到侧脸等角度时口罩与人脸不能紧密贴合,因此本文提出了一种实时添加虚拟口罩的数据增强器,并与FMA-3D的效果做了多方位对比。
2.1 FMA-3D数据增强方法
FMA-3D通过PRNet[25]这一端到端的3D人脸重建网络从平面的人脸图像预测出人脸的3D点云图,相比于2D的人脸图像,点云图还包含了人脸的深度信息,具备“降维打击”的优势。
当获取到人脸的点云坐标后,FMA-3D将平面人脸映射到UV纹理图上后,与口罩的纹理图相叠加得到了叠加口罩遮挡的人脸UV图,再将此图逆向映射回二维平面上就实现了虚拟口罩的添加。相较于普通方法,此方法可使口罩与人脸的边缘衔接紧密,其具体流程如图7所示。
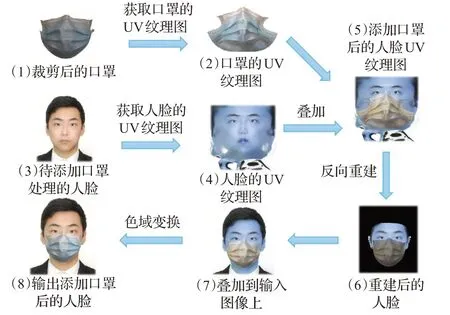
图7 FMA-3D添加虚拟口罩流程Fig.7 FMA-3D adding virtual mouthpiece process
2.2 本文的数据增强方法
本文使用MediaPipe Face Mesh[26]来估计人脸的468个3D关键点,并根据这些关键点进行Delaunay三角剖分将人脸划分了多个网格;对各种样式的口罩同样进行三角剖分得到与人脸位置对应的网格;逐网格的将口罩进行仿射变换映射到人脸对应位置的网格上,此数据增强器最终将输入人脸按3∶1∶1∶1的比例生成未佩戴口罩(不做任何处理)、正确佩戴口罩、佩戴口罩但露出鼻子、佩戴口罩但露出口鼻这四种人脸输入到网络中进行训练。本文的数据增强具体流程如图8所示,相较于FMA-3D,本文提出的数据增强器有如下优点:
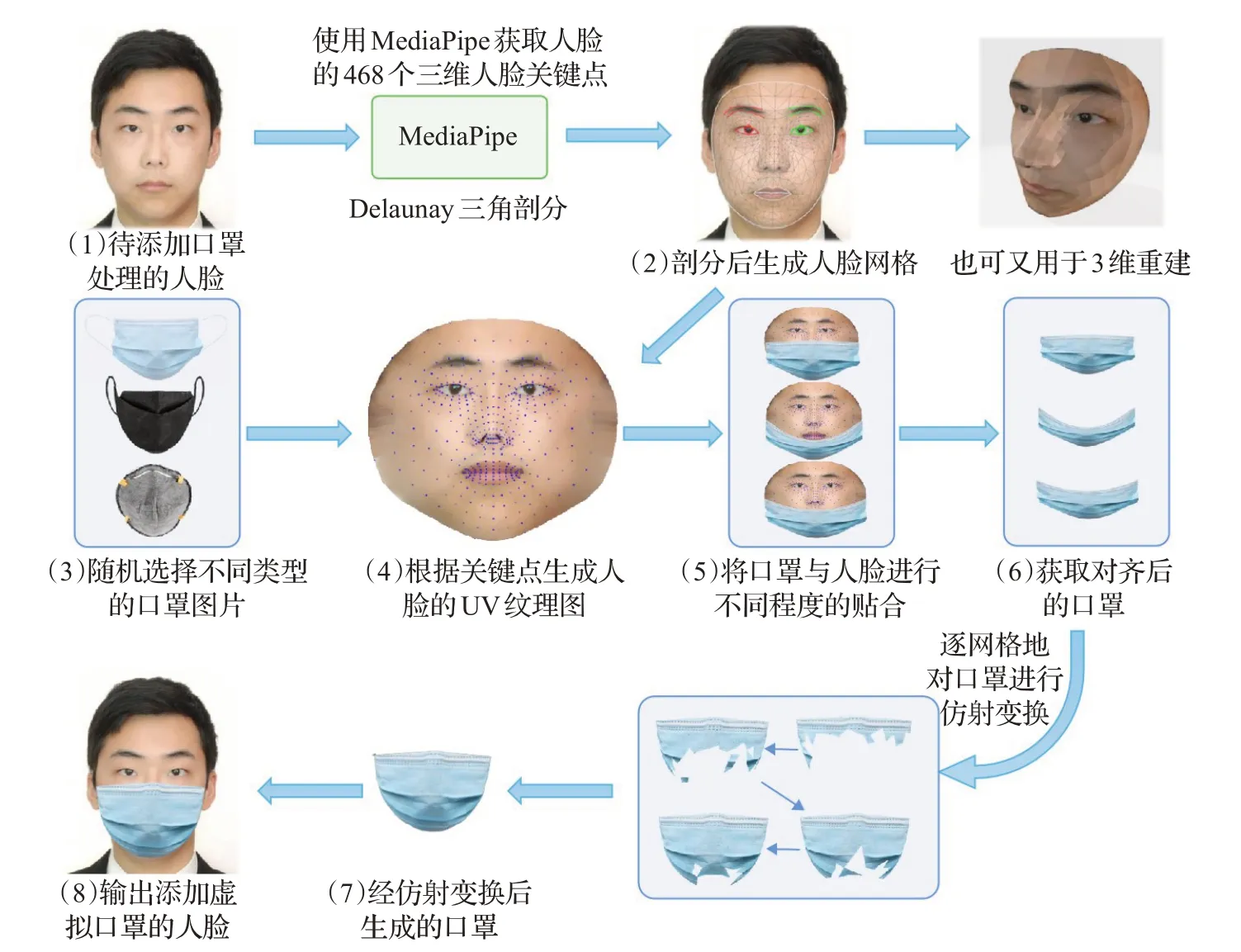
图8 本文的数据增强方法Fig.8 Data enhancement methods in this paper
(1)能生成正确佩戴口罩和未正确佩戴口罩的人脸图片,其中未正确佩戴口罩又可分为暴露鼻子和暴露口鼻两种情况,而FMA-3D则只能生成正确佩戴口罩的人脸图片。
(2)拥有更快的处理速度,且只需CPU就能实现,本方案只需筛选出下半脸的部分关键点将口罩仿射变换到人脸上,处理单张图需要26 ms;而FMA-3D需要将整张脸从UV图逆向还原到平面人脸上,推理单张图需要113 ms。
(3)相较于传统的二维贴图映射方法与FMA-3D,本方案可使得口罩与不同角度的人脸贴合地更为紧密、边缘衔接地更为自然,逼近真实的口罩遮挡人脸图片,而FMA-3D有几率出现模糊的异常现象,其效果对比如图9所示。
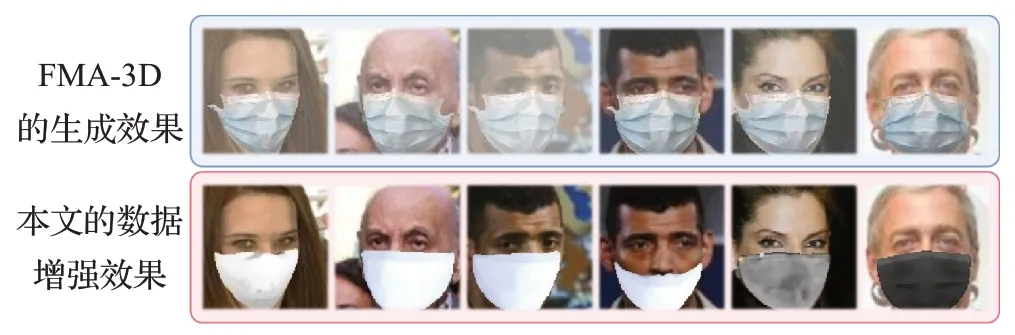
图9 数据增强效果对比Fig.9 Comparison of data enhancement effects
3 实验结果与分析
本文使用一张RTX3080Ti作为GPU,设置最小批次为64,总epoch为20对模型进行训练。并使用了patience为4,初始学习率为10-3的Adam优化器。本章将介绍消融实验的设计与结果,旨在证明所提出方法的优越性,并设计了一个可视化实验,使用类热力图定量、直观地对比添加FocusNet前后的效果。
3.1 数据集
CASIA-WebFace[27]是最常用的人脸识别训练集,包含10 575人的494 414张脸部图像,但样本仍不够丰富。本文选用了Deng等[4]开源的MS1M-ArcFace数据集作为训练集,包含85 000人的580万张脸部图像,此数据集经过清洗,噪声更小且样本丰富。原始测试集选用了最常用的LFW数据集,本文在使用数据增强器对LFW使用3D人脸网格生成方法制作了添加虚拟口罩的Masked LFW(MLFW)数据集,并以此为虚拟测试集。Wang等[28]制作了真实的口罩遮挡人脸数据集Masked WHN,本文以此为真实测试集,本文涉及的测试集信息如表1所示。
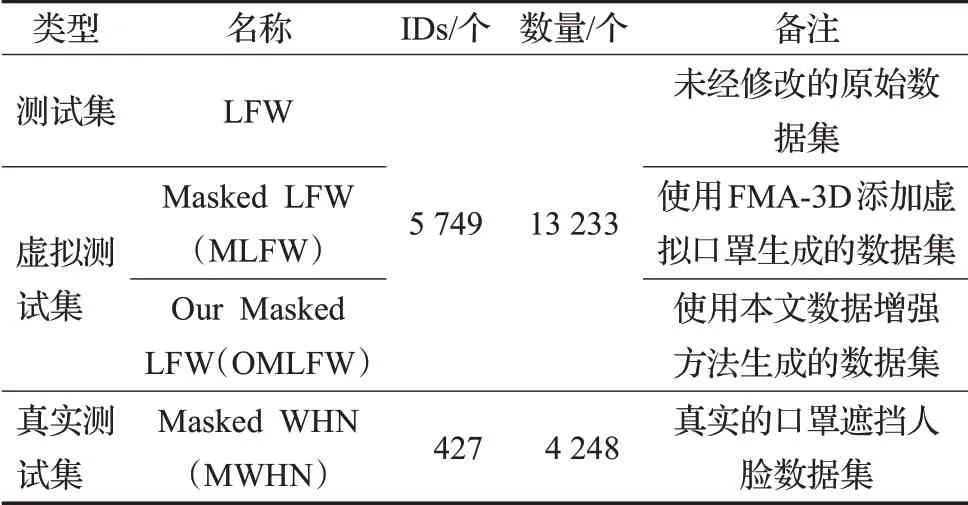
表1 测试集信息Table 1 Test set information
3.2 消融实验
首先本文使用以ResNet50为主干特征提取网络的Arcface[4]网络为Baseline,对比使用了数据增强器的前后性能以验证此数据增强器的效果。
实验的设计与结果如表2所示,第一列为模型的名称,其中+号表示在上一个模型的基础上作出的改进,+GhostNet表示在基准模型的基础上将主干特征提取网络修改为GhostNet;+FMA-3D表示在上一个模型的基础上添加了使用三维人脸重建实时添加虚拟口罩的数据增强器;+Spatial表示在上一个模型的基础上将空间注意力机制加在主干网络之后;+FocusNet表示在上一个模型的基础上将Spatial替换为FocusNet加强特征提取网络。+Ours表示在上个模型的基础上将FMA-3D替换为本文所提出的逐网格仿射变换添加虚拟口罩的数据增强器;第二至四列为模型在无遮挡人脸数据集、虚拟遮挡人脸数据集、真实遮挡人脸数据集上的准确率;第五列为模型的参数量,用来描述复杂度。并用符号(-)标注出相对上一个模型性能的下降,符号(+)标注出性能的提升。
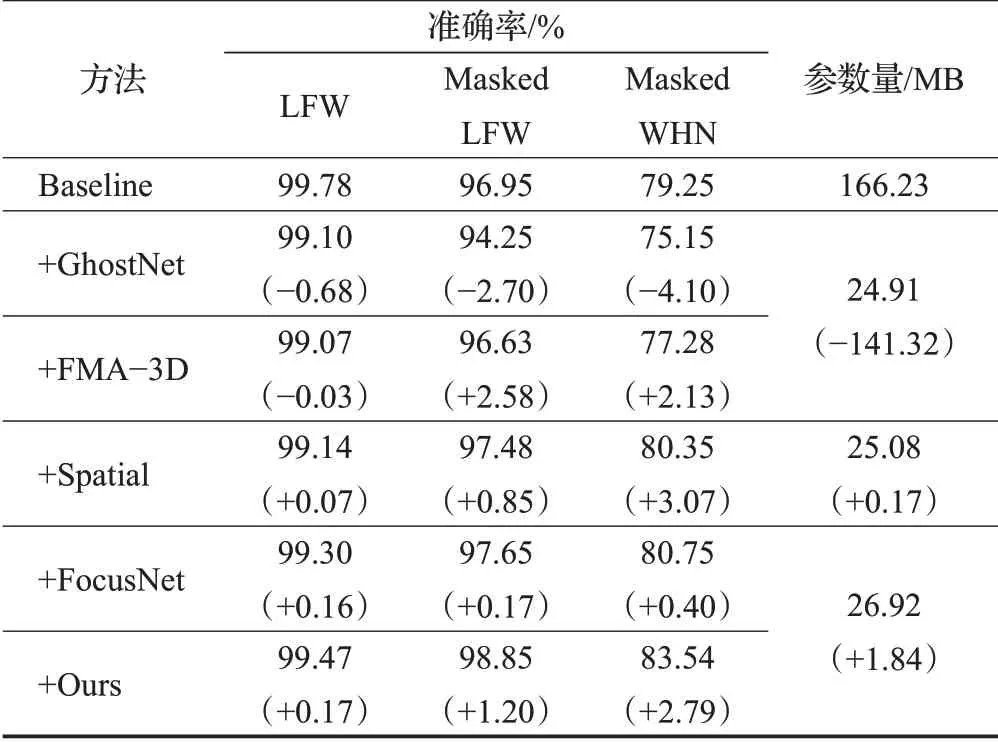
表2 消融实验数的设计与结果Table 2 Design and results of number of ablation experiments
根据表2中的实验结果可知,使用修改后的Ghost-Net作为主干特征提取网络之后,模型的准确率在无遮挡场景下降了0.68个百分点,在虚拟口罩遮挡场景下降了2.7个百分点,在真实口罩遮挡场景下降了4.1个百分点,但模型的参数量减少了85%,准确率的牺牲是值得的。
使用FMA-3D添加口罩的数据增强方法之后,模型的准确率在无遮挡场景下降了0.03个百分点,这是由于数据增强方法会减少无遮挡人脸的数量。在虚拟口罩遮挡场景提升了2.58个百分点,在真实口罩遮挡场景提升了2.13个百分点,提升显著;而使用本文提出的数据增强方法之后,这充分说明了本文提出的数据增强方法适应口罩遮挡下人脸识别任务的需求。
添加空间注意力机制后,模型的准确率在无遮挡场景提升了0.07个百分点,在虚拟口罩遮挡场景提升了0.85个百分点,在真实口罩遮挡场景提升了3.07个百分点。再将空间注意力机制替换为本文的FocusNet加强特征提取网络之后,模型的准确率在无遮挡场景提升了0.16个百分点,在虚拟口罩遮挡场景提升了0.17个百分点,在真实口罩遮挡场景提升了0.40个百分点,本文将在3.3节通过可视化方法说明FocusNet是如何在口罩遮挡场景下显著提升了准确率。
将数据增强方法由FMA-3D替换为本文所提出的数据增强器之后,模型的准确率在无遮挡场景提升了0.17个百分点,在虚拟口罩遮挡场景提升了1.2个百分点,在真实口罩遮挡场景提升了2.79个百分点,这充分说明了本文所提出的数据增强器相较于FMA-3D有着更好的效果。
如表3所示,将本文提出的模型GhostFace与当下主流的轻量级遮挡人脸识别算法分别在虚拟口罩遮挡的LFW、AgeDB-30、CALFW数据集上做对比验证,此三种虚拟数据集都是由MaskTheFace[17]方法生成的,可见本文提出的模型在三种数据集上皆表现最优。
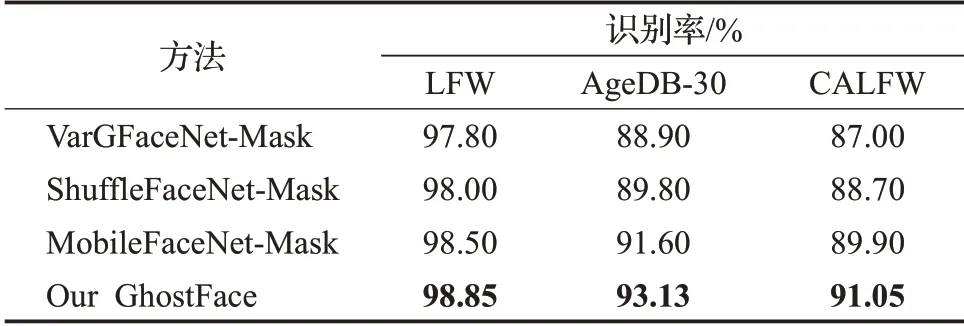
表3 与主流轻量级模型的对比Table 3 Comparison with mainstream lightweight models
综上,本文通过改进网络模型和提出一种数据增强方法,与基准模型相比,模型参数量从166.23 MB下降到26.92 MB(降低了84%)的同时,在虚拟口罩遮挡人脸数据集和真实口罩遮挡人脸数据集的识别率分别提升1.9个百分点和4.29个百分点,有着更好的的识别效率和精度。
3.3 FocusNet效果验证
为定量、直观地分析和解释添加FocusNet的效果,本文使用Axiom-based Grad-CAM[29]来生成添加FocusNet前后的类热力图,通过可视化的类热力图可以找出分类任务中,对分类结果影响力最大的部分特征,也就是模型重点注意的部分特征。如图10所示,Grad-CAM获取到GhostFace中分类器的输出logits,并计算logits相对2维特征矩阵的梯度,通过梯度与2维特征矩阵相乘就可以得到一个热力分布图,此分布图中颜色越深的部分代表了模型越重点关注的空间部分信息。接下来对热力分布图进行上采样和平滑处理后得到与输入图片大小相同的热力分布图,并将此热力分布图叠加在输入图片上就看直观地观测到人脸识别模型重点关注的人脸区域。
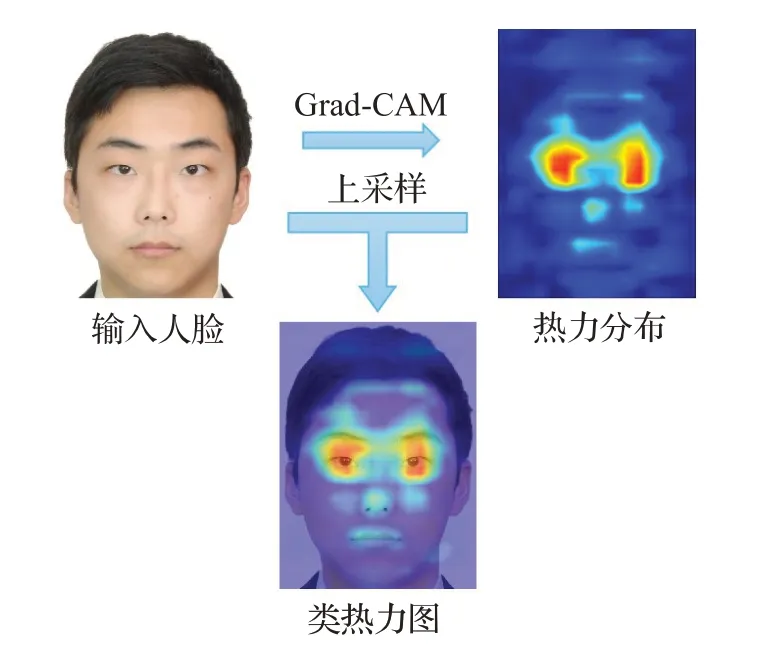
图10 类热力图生成过程Fig.10 Process of generating class heat map
导向反向传播(guided backpropagation)[30]是CNN网络可视化的一种经典算法,导向反向传播可视化后得到的导向反向传播图GB可以直观地看出模型学习到了什么特征,本文将类热力分布图中的权重叠加到GB中得到GB-CAM,通过GB-CAM就可以看到模型重点学习的部分特征。在遮挡人脸识别任务中,如果模型重点学习的是未被遮挡的上半部分人脸区域,则与本文设想的一致,说明添加FocusNet后,起到了预期的作用。
如图11(a)所示,第一行分别为人脸、口罩遮挡人脸的类热力图,第二行为对应的GB图,第三行为对应的GB-CAM图,图11(b)则为添加FocusNet后所对应的可视化结果。根据图11的结果可得知,添加FocusNet之前,在有、无遮挡的情况下,类热力图的分布都没有规律可循,其GB和GB-CAM图模糊不清,说明此时模型没有重点关注、学习的部分特征。
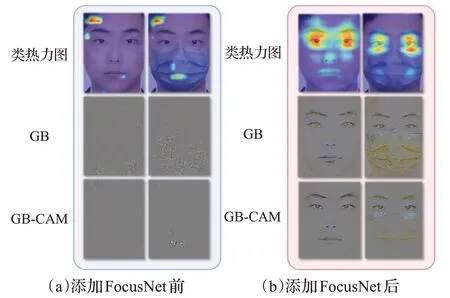
图11 注意力机制效果可视化Fig.11 Visualization of effects of attentional mechanisms
然而在添加了FocusNet后,在无遮挡情况下类热力图中双眼、鼻子、嘴巴部分区域的颜色较深,其GBCAM图中双眼、鼻子这两个部分清晰可见,说明模型在无遮挡情况下重点关注这两个部位。在口罩遮挡情况下,类热力图中,未被口罩遮挡的上半部分人脸区域颜色较深,其GB-CAM图中眉毛、眼睛这两个区域清晰可见,说明模型在有遮挡的情况下重点关注上半部分人脸区域。通过此对照组,本文使用可视化的方法充分添加FocusNet加强特征提取网络可带来识别准确率的提升。
4 结束语
针对口罩遮挡人脸数据集不够逼真、充分的问题,本文构建了使用三维人脸网格生成添加虚拟口罩的实时数据增强器;针对人脸识别算法参数量较大的问题,改进了GhostNet作为主干特征提取网络,极大地降低了模型的复杂度;针对口罩遮挡人脸识别应用场景下,模型识别准确率低的问题,提出了FocusNet加强特征提取网络,使模型重点学习眼、眉部位的特征,有效提升了模型的准确率;最终模型GhostFace能同时兼容遮挡和无遮挡条件下的人脸识别任务,并且在降低84%参数量的同时,在虚拟口罩遮挡人脸数据集和真实口罩遮挡人脸数据集的识别率分别提升1.9个百分点和4.29个百分点,有着更好的识别效率和精度。此外本文使用数据增强器还可以在人脸数据集上添加其他遮挡物如,眼镜、长发等,具有广泛的应用前景。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
电子制作(2019年15期)2019-08-27
电子制作(2019年14期)2019-08-20
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
电子制作(2017年1期)2017-05-17
自动化学报(2017年11期)2017-04-04
