
基于集成方法的自动车型识别方法设计
2023-02-03 02:56廖骏杰
自动化仪表 2023年1期
向 冲,廖骏杰
(1.长江职业学院数据信息学院,湖北 武汉 430070;2.武汉职业技术学院电子信息工程学院,湖北 武汉 430074)
0 引言
自动车型分类(automatic vehicle classification,AVC)是支撑诸如智慧城市、自动驾驶、智能交通、交通分析与车辆安全等不同领域的重要基础条件[1]。高性能计算,如具有图形处理单元(graphics processing unit,GPU)的云计算、机器学习算法等的发展,加速了许多基于计算机视觉的AVC方法的开发[2]。作为AVC的实际用例,已经有许多应用场景部署了自动收费系统。但由于车型识别中的任何误差都会带来经济损失,因此仍然需要通过人力来手动纠正错误的分类结果。
基于卷积神经网络(convolutional neural network,CNN)的方法越来越多地被应用于计算机视觉的目标识别。最近基于图像的AVC更是广泛采用了此方法[3]。作为独立分类器,基于CNN的分类器相对于光学传感器(optical sensor,OS)而言,在整体性能上有显著的改进。但是CNN仍存在局限性,例如从前视图中很难区分重型车辆的类别。而这些重型车辆可以通过OS很好地进行分类。这表明,可以通过有效结合基于图像的分类器与OS决策,开发1种针对AVC的识别方法。
因此,本文提出了1种新颖的车型识别方法。该方法在以下2个阶段分别执行集成方案。第一阶段集成来自OS和CNN的输出,从而提供1个集成特征向量作为下一阶段的输入。第二阶段集成上一阶段得到的特征向量而获得的分类结果。这一步通过应用梯度提升方法来执行。试验结果表明,本文提出的车型识别方法以显著的优势胜过了现有系统,能大大降低人力的使用。此外,与1组基于CNN方法的比较结果表明,本文提出的方法更优。
1 研究现状
多模态和多传感器数据集成是基于早期集成和后期集成应用于监督和非监督分类问题的技术。其中,后期集成[3]方法融合了用于分类不同模态或(与)传感器数据的多个分类器的决策结果。一般而言,车辆分类通常使用不同的传感器数据完成后期集成,例如应变仪和光检测传感器。许多方法[4]组合了这些传感器以提高准确性。就组合方法而言,通常使用判别模型进行后期集成,例如支持向量机(support vector machine,SVM)、神经网络(neural network,NN)、随机森林(random forest,RF)等。本文研究采用梯度提升方法。
文献[5]提出了1种集成方法来识别3类目标,分别为汽车、行人和骑自行车的人。该方法将后期集成策略与SVM分类器相结合,以利用电荷耦合器件(charge coupled derive,CCD)和激光探测及测距系统(light detection and ranging,LIDAR)传感器数据训练CNN模型。文献[6]提出了1种基于后期融合的车辆检测方法。该方法具有不同的数据模式,例如彩色图像、密集深度图和反射图。以上这些方法采用了多层感知机(multilayer perceptron,MLP)融合,从每种模态训练的独立CNN模型获得的对象边界框。尽管与这些方法的基本概念相似,但本文方法具有以下特点:①本文执行的是分类任务而非检测任务;②模态不同,即本文为OS和摄像机相结合的模态;③本文使用不同且更有挑战性的数据集。
近年来,因基于CNN的目标检测与分类方法和开源的车辆数据集的突破性表现,使得基于CNN的AVC变得非常流行。文献[7]提出了1种级联的基于部分图像的车辆识别方法。该方法采用了潜在的SVM方法和基于部分的CNN模型。文献[8]将SVM分类器应用于从多个CNN提取的级联特征。该方法的CNN模型根据车辆的整体和部分图像对车辆进行分类。文献[9]提出了1种具有不同CNN模型的空间加权池化操作,可以从经过裁剪的图像中提取重要特征。不同于上述提到的方法,本文研究将图像视为整体输入,而非经过裁剪的车辆图像。
2 车型识别方法设计
本文设计的自动车型识别方法总体流程如图1所示。
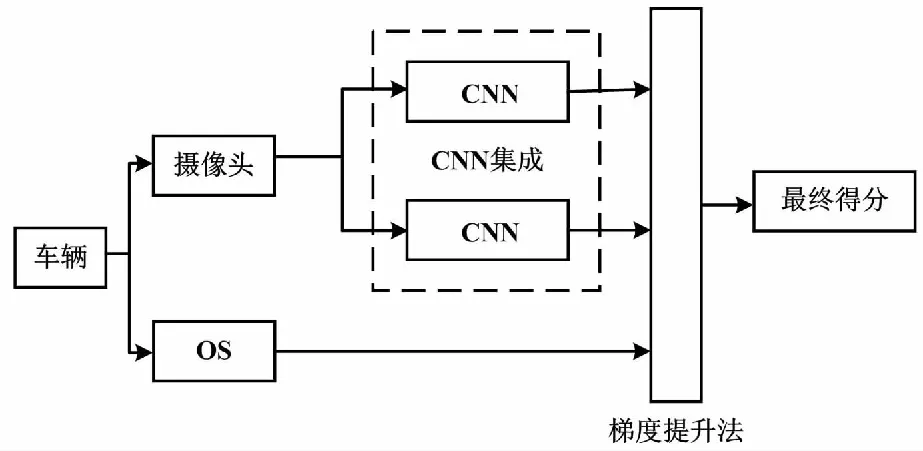
图1 自动车型识别方法总体流程图
本文方法可分为以下3个步骤:①利用OS直接提供类别标签决策;②使用摄像头捕获彩色图像,并将其输入CNN以确定车辆类型;③采用梯度提升分类器融合来自前置与后置OS获得的离散类别标签,以及CNN分类器的连续类别概率,从而得到车辆类别。
2.1 CNN
CNN的基本架构主要包括卷积操作、池化操作、激活函数、全连接层与损失层。
卷积操作的定式如式(1)所示。
(1)

池化操作应用于局部空域中,会降低特征图的空间分辨率。局部邻域平均值的平均池化操作的计算如式(2)所示。
(2)
式中:Nx,y为局部空间邻域。
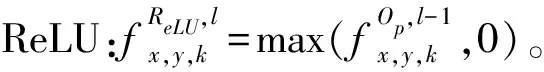
全连接层通常出现在串联层的末端,用于进一步提取特征。
损失层针对损失函数优化模型参数。通常使用的Softmax损失函数具有以下形式:
(3)
式中:Yiyi为将第i个样本分配给其真实类别标签yi的概率;N为训练样本的数量。
(4)
式中:K为训练样本的类别数量。
在式(3)和式(4)中,可以用任意的类标签替换真实的类标签yi,以计算所有类的概率集合。
本文方法使用基于超分辨率测试序列(visual geometry group,VGG)(CNN-1)和Inception(CNN-2)架构的2个不同CNN模型。CNN-1通过以下方式修改VGG-16:①在最后的最大池化层后增加了1个7×7大小的平均池化;②取消最后2个全连接(fully connected,FC)层;③将第一个FC层中的神经元数量从4 096个减少到1 024个;④在FC层之前(0.5%)和之后(0.25%)添加Dropout层,从而使VGG-16模型的复杂度降低为原来的九分之一,即仅包含15 MB的参数。主干网络参数如表1所示。

表1 主干网络参数
表1中,输入数为224×234大小的图像,最终分类层采用Softmax函数,Dropout率为0.5。
CNN-2是Inception V3模型。在3.2节提供了CNN训练策略的详细信息。这些模型将尺寸为224×224(CNN-1)和299×299(CNN-2)的图像作为输入,并提供类别概率的5维向量作为输出。
2.2 梯度提升法
梯度提升法是1种典型的异构数据分类方法。它通过迭代组合弱分类器来构建单个的强分类器。这种结合是通过贪婪算法实现的。
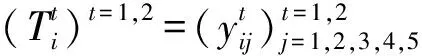
(5)
式中:wi为权重;ai为第i个样本的目标函数的值。
本文使用CatBoost算法进行梯度提升方法的分类。选择CatBoost算法的原因是它可以融合多种类别的数据,尤其是离散的类别数据。
3 试验结果及分析
3.1 所用数据集
本文使用具有代表性的VINCA数据集[10]进行试验。VINCA数据集图例如图2所示。

图2 VINCA数据集图例
VINCA数据集由73 438张图像组成,并且根据物理量(例如高度、重量与轴数等)将车型分为5个不同类别:第一类为高度小于2 m的44 437张轻型车辆数据;第二类为高度为2~3 m的8 074张中型车辆数据;第三类为高度超过3 m且有2个车轴的11 477张重型车辆数据;第四类为高度超过3 m且有至少3个车轴的3 462张重型车辆数据;第五类为包含摩托车、小汽车与三轮车在内的6 400张车辆数据。此外,VINCA数据集还包括在不同条件下(如照明、遮挡、姿态、位置、多车存在等)的捕获图像。
3.2 试验设置
首先,训练CNN模型以获得每个图像的分类概率。然后,对梯度提升方法进行训练,以获取最终的类别标签。最后,将收集的数据集随机分为训练-验证-测试集,并分别按70%-15%-15%的比例来选择训练数据集。每个图像集上样本的分布必须与整个数据集的分布相似。
3.2.1 CNN的训练
训练集中的图像用于优化CNN模型参数。CNN使用文献[11]中的参数模型进行初始化。由3.1节的介绍可知,使用的数据集含有严重的类不平衡问题。其中,第一类与其他类样本相比样本数量更多。因此,本文使用加权Softmax损失作为目标函数。其中,每个类别的权重对应于该类样本容量的倒数。L2正则化应用于CNN参数。学习率设置为0.001。mini-batch大小设置为100。通过水平翻转图像,可以进一步扩充数据集。随机梯度下降方法可用于参数优化。
3.2.2 梯度提升方法的训练
梯度提升方法的训练数据是通过连接CNN中 Softmax层的输出与来自OS的one-hot编码值获得的。该方法使用Catboost分类器,并且设置深度为6、学习率为0.03、最大迭代次数为500。
3.3 结果与讨论
本小节在测试集上评估所提出的方法,并将其与对照方法进行性能比较。所使用的评价指标为分类准确率,并使用精准度进行深入分析。各方法的准确率与运行时间对比如表2所示。由表2可知,本文方法提供了最佳的结果。实际上,基于独立CNN的方法与本文方法的巨大性能差距表明了本文方法的有效性。此外,与感兴趣对象分类(object of interest classification,OIC)方法的比较证明了选择无检测分类方法的合理性。

表2 各方法的准确率与运行时间对比
本文方法的主要对比方法如下。
①汽车整体分类(car classfication holist,CCH)[12]:使用Alexnet进行整体场景的汽车分类。
②OIC:首先使用在COCO数据集上训练过的RetinaNet目标检测器,从使用的数据集中裁剪感兴趣对象;然后在经过裁剪的图像中训练VGG-14模型。
③仅使用本文方法的单一组件(即消融试验):入口OS、出口OS、InceptionV3(CNN-2)和VGG-14(CNN-1)。
除了对比准确性之外,试验还对比了这些方法与本文方法的运行时间。运行时间是在具有12 GB GPU内存的NVIDIA K80 GPU机器上测得的。表2的运行时间数据表明,本文方法是在合理的计算时间内执行的,因此对于车辆识别而言是完全可以接受的。CCH、CNN-1和CNN-2的对比表明,运行时间与CNN模型的复杂性有关。此外,由于本文的方法并行处理2个CNN,因此减少了时间复杂度。接下来,研究每种车辆类别的准确性和精准度,以深入分析本文方法及其组件的特性。表3为各车型的准确率对比。
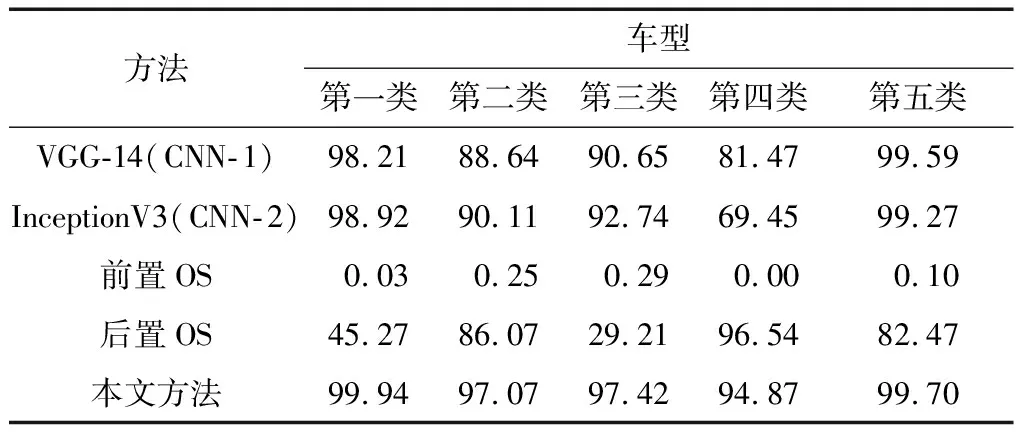
表3 各车型的准确率对比
由表3可知:①除第四类车型,本文方法均提供了最佳准确性;②前置OS的性能非常差;③后置OS在第四类车型表现最好,在第二类车型和第五类车型表现良好,在第三类车型和第一类车型表现最差。CNN模型的准确性表明,CNN-2对于前三类车型更友好,而CNN-1对后两类车型更友好。每个模型针对不同类别的分类优势证明了它们集成之后基本继承了各自的优点。表4为各车型的精准度对比。

表4 各车型的精准度对比
由表4可知,本文方法为所有车型提供了最佳精度。
表5为本文方法分类结果的混淆矩阵。
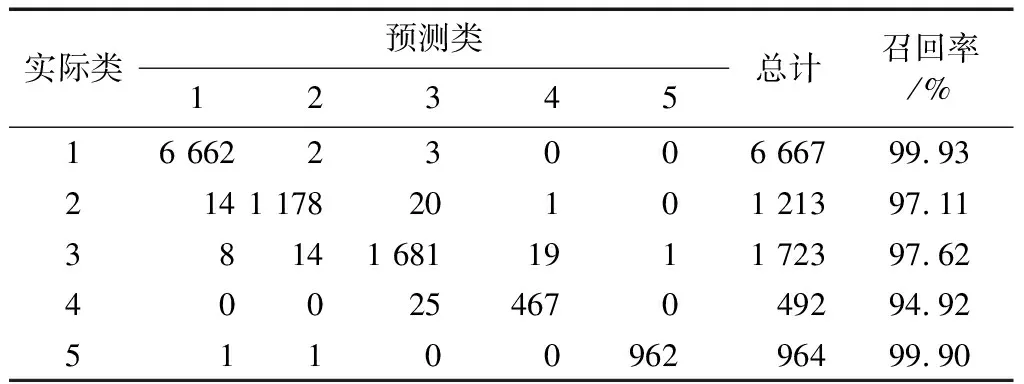
表5 本文方法分类结果的混淆矩阵
由表5可知,本文方法的精确度和召回率都在94%以上,说明了本文方法的误识别和漏识别的概率较低。
基于训练数据集,计算CatBoost特征得分。CatBoost分类器的特征重要性排序如表6所示。
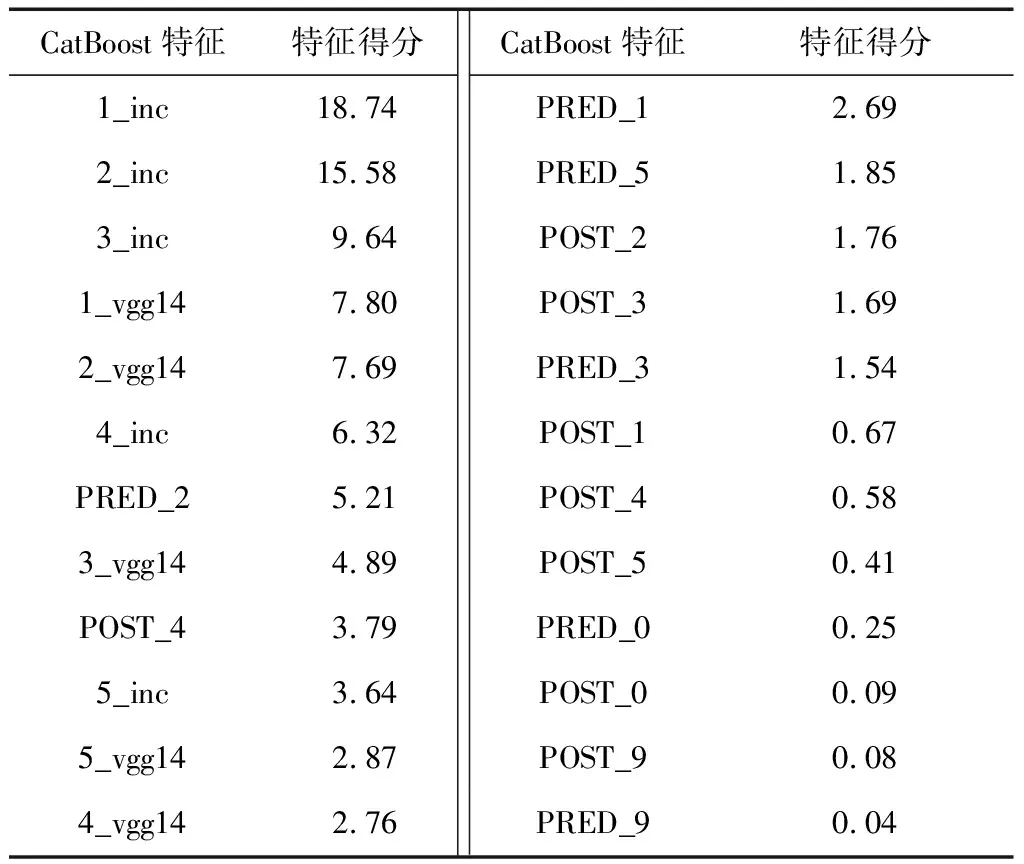
表6 CatBoost分类器的特征重要性排序
由表6可知,来自2个CNN的分数都对最终决策有重要贡献。此外,当前置OS数量为2且后置OS为4时,OS表现最好。这证明了OS的输入对于难以直接从图像中推断出的某些车辆属性(例如轴数等)至关重要。
3.4 性能分析
不同主干网络的准确率与损失值对比如表7所示。

表7 不同主干网络的准确率与损失值对比
3.4.1 CNN模型的选择
初期在选择本文方法的单独组件方面,已经检验了几种CNN模型,即VGG-14、VGG-16、Inception、AlexNet、ResNet50、DenseNet和Xception。这些模型已按照3.2节中的相同试验设置进行了训练。由表7可知这些模型的准确性和损失值。本文方法正是根据这一研究结果选择了VGG-14与Xception。
3.4.2 本文方法的局限性
本文方法的典型误分类结果如图3所示。

图3 本文方法的典型误分类结果
由图3可知,误分类的主要原因如下。
①不良的光照条件和遮挡,尤其是车轴和车辆顶部的遮挡。
②第二类车型由于其后面被遮挡的大篷车而经常被错误分类,这导致车辆被归类为第一类车型。
③其他原因,通常表现为会将第四类车型误分为第三类。
将来可以通过以下几种方法将这些错误减至最少。①通过收集更多不同的样本,尤其是针对第三类车型和第四类车型的样本,来增加训练数据。②使用数据扩充方法来得到更多数据。③配备高效的预处理器以应对恶劣的环境条件。④通过引入改进损失函数来提高分类器的效率。⑤引入更深层的CNN模型。
4 结论
不同于目前单一使用OS的系统,本文提出1种多分类器集成方法用于高速路口中的自动车型识别。该方法通过组合来自OS的分类决策与来自2个CNN模型的分类概率得到最终的分类结果。由分类结果可知,本文提出的方法不但优于传统的车型识别方法,而且还优于基于CNN的车型识别精度。这说明本文提出的方法完全可以应用于实际场景中。未来的研究可通过持续改善以下几个方面继续提升识别效果:①收集更具泛化性的训练数据;②使用更有效的预处理方法以应对恶劣的环境;③研究针对车型识别的损失函数以及运用更深层的CNN。
猜你喜欢
车迷(2022年1期)2022-03-29
中国交通信息化(2020年11期)2021-01-14
民族古籍研究(2018年1期)2018-05-21
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
新校长(2016年8期)2016-01-10
汽车与安全(2015年12期)2015-09-10
车迷(2015年12期)2015-08-23
浙江大学学报(工学版)(2015年1期)2015-03-01
航天返回与遥感(2014年5期)2014-07-31
