
基于区块链及联邦计算的主机入侵检测方法
2023-02-02 09:09常英贤王红梅宋益睿
浙江工业大学学报 2023年1期
常英贤,桂 纲,杨 涛,王红梅,宋益睿,汤 泉,田 野
(1.国网山东省电力公司,山东 济南 250001;2.国网山东省电力公司济宁供电公司,山东 济宁 272073;3.杭州链城数字科技有限公司,浙江 杭州 310012)
随着产业数字化进程的推进和能源互联网的发展,安全生产管理范畴开始涉及网络安全问题。2017年5月,受到WannaCry永恒之蓝勒索病毒的攻击,中国石油紧急中断所有加油站网络端口,对油罐业务造成严重影响。在能源互联网中,对网络攻击进行主动感知并预警至关重要。为此,研究者提出多种入侵检测系统(Intrusion detection system,IDS),并广泛部署在能源企业的主机上进行威胁检测与攻击溯源。当前主机入侵检测方法可以分为两种:一种是基于特征规则的方法,另一种是基于人工智能的方法。在基于特征规则的入侵检测中,一种常用的方法是基于网络数据包各维度数据特征进行攻击分析,如根据流量日志中的源IP、目的IP、端口号和协议类型等协议信息[1-3],或是流量熵、主机之间的字节流量等统计信息[4-6]。有研究者提出了基于主机静态代码特征的分析方法,其通常是指在不运行程序的情况下,提取程序的指令、函数调用等可用于异常检测的静态代码特征[7-9]。作为静态检测的补充,动态检测方法[10-12]可以根据记录的程序运行时上下文行为进行检测。然而,上述基于特征规则的检测方法需要大量的先验知识和专家判断,一旦有新的恶意软件或者新的攻击手段,基于特征规则的检测就很难有效应对。基于人工智能的入侵检测因具有较强的泛化能力和识别未知攻击的能力,有效克服了传统基于特征规则的入侵检测固有缺陷,已被广大研究者所采用。研究人员提出了传统的机器学习方法(如支持向量机(SVM)[13]、K邻近(KNN)[14]、人工神经网络(ANN)[15]和随机森林(RF)[16]),传统的机器学习需要手工提取特征,存在覆盖率与精度的瓶颈,故基于深度学习的方法被众多研究者提出,如卷积神经网络(CNN)[17-18]和循环神经网络(RNN)[19-20]等。然而,现有基于传统机器学习和深度学习的入侵检测方法均假设数据集是已有的,无法保障数据本身的隐私安全,亦无法适用于真实复杂的能源互联网环境。与上述工作不同,笔者设计了一种基于智能合约的私有链,并结合联邦学习实现本地模型训练并聚合生成全局模型,保障了原始数据的隐私。此外,笔者结合自编码器(AutoEncoder)深度学习(循环神经网络)构建模型,对已有的机器学习和深度学习方法作了详细的对比分析。
在构建私有链的过程当中,传统的PoW共识算法解决了选择共识领导者以及在参与者之间公平分配奖励的问题。为了防止攻击者通过廉价伪装成多台机器来获得多数权力,PoW系统的参与者只能根据其在系统中投资的计算量来领导共识轮次,然而这将会花费大量成本[21],能源企业的主机将是一笔巨大的开销。为此,研究者提出基于PoUW的共识算法[22-23],该算法依赖于Intel的SGX技术,用户可以将其CPU用于任何所需的工作负载,并且可以为保护区块链生态环境作出贡献。笔者综合能源企业环境,结合主机CPU中内置的Intel SGX技术,达到资源节约型的共识。此外,为了在攻击发生后进行溯源分析,判断攻击的入口点与攻击造成的影响,有必要对采集的日志数据进行长时间的存储。传统的数据加密方法存在不足,如对称密钥存在密钥分发困难、管理复杂问题,而非对称密钥存在效率低下、加解密时间过长问题,且传统加密的验证对于流量与运算资源开销大,不适合进行频繁的存储性验证[24-25]。为了解决上述问题,实现数据的可信存储,笔者通过存储总体数据的默克尔树以及随机向参与存储节点发起不同挑战的方式确保数据安全可靠。
在笔者所提的威胁模型中,假设能源集团下有多家企业,每个企业有若干终端主机存储企业的关键信息,如关键数据资产、员工身份信息和企业数据库等,由于不同企业所处的网络环境不同,同样的系统行为表现出的日志信息也会有所差异。为了保护存有企业关键信息的主机的安全,基于深度学习的入侵检测系统被部署在各台主机上。基于深度学习的模型训练需要大量且有差异的样本来提高模型的覆盖率和泛化能力,因此通常将不同环境下主机的日志数据进行整合并构建适用于全能源企业的通用入侵检测模型,从而大大提高模型的利用率和鲁棒性。然而,不同的主机日志数据交互(如都传到云端服务器)会存在隐私泄露问题。主机本地收集数据并具有一定的计算能力,同时CPU支持Intel SGX。笔者将能源企业的主机视为客户端,最终目的是在保护隐私的情况下,对各个存有能源企业关键数字资产的主机的日志数据进行共享(模型训练),从而完成准确高效的主机入侵检测,同时能够完成对主机日志数据的可信存储,以便在攻击发生后进行溯源分析。
1 方 法
笔者提出的主机入侵检测方法包含4个模块,各模块之间的关系如图1所示。各模块具体如下:1) 构建基于区块链与联邦学习的私有链,实现数据不出本地的模型训练并聚合生成全局模型;2) 利用基于Intel SGX的PoUW共识算法进行区块的生成与发布,从而减少资源的开销;3) 构建存储总体数据的默克尔树,并随机向参与存储客户端节点发起不同的挑战,实现数据的可信追溯与存储;4) 构建基于AutoEncoder与RNN的主机入侵检测模型,实现模型的快捷构建与威胁的高精度检测。其中,模块二、三、四分别为模块一(基于区块链与联邦学习的私有链)提供工作量证明、数据分布式存储和深度学习模型。
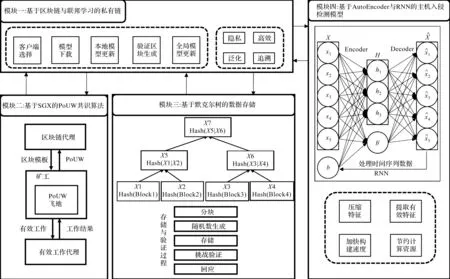
图1 基于区块链有用工作量证明及联邦计算的主机入侵检测方法架构图Fig.1 Architecture diagram of host intrusion detection method based on blockchain Proof-of-Useful-Work and federated computing
在主机入侵检测中,N个客户端(能源集团下多家企业的主机)共同组成一个基于智能合约的私有链,其中每个客户端配置了支持SGX的Intel芯片,任意客户端可以发起联邦学习任务(发起任务的客户端记为Req),在联邦学习任务之前,Req首先通告任务规范,例如应用程序的类型(如异常入侵检测模型)、设备类型、训练数据的类型和格式(如操作系统日志、流量日志和沙箱日志等)、学习模型的类型(如RNN)、计算要求(如深度学习的学习率)以及任务事务设置(如所需客户端的数量、批量大小等),愿意加入任务的客户端会回复申请并加入训练过程,在多次迭代后完成任务,并将所有交易记录到账本中。各模块的设计将在下文中详细描述。
1.1 基于区块链与联邦学习的私有链构建
基于区块链与联邦学习的私有链构建如图2所示。
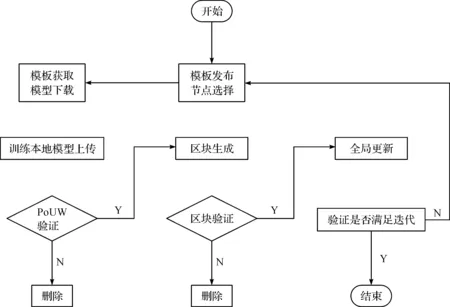
图2 基于区块链与联邦学习的私有链构建流程图Fig.2 Flow chart of private chain construction based on blockchain and federated learning
在私有链中,Req为了实现数据不出本地的模型训练并聚合生成全局模型,需要进行多次通信迭代,每次通信迭代具体步骤如下:
1) 区块模板发布与节点选择。在模型训练之前,需要选择出在本轮迭代中参与模型构建任务的客户端。Req在检测客户端是否满足支持SGX且飞地页面缓存(Enclave page cache,EPC,Intel利用SGX技术在处理器中搭建了一个安全的飞地来保护重要数据)大小足够时,为满足条件的客户端创建一个承诺交易,并为所有客户端广播区块模板(包括任务要求、参与客户端和迭代轮数等信息)。其中,所有客户端的集合称为P,发布的模板缺少PoUW,需要客户端在完成任务后进行填充。
2) 模板与模型下载。对于每个被选择的客户端Pt,需要通过网络下载Req提供的全局模型mi以及区块模板,其中Pt⊂P,t表示被选择的第t个节点,i表示通信迭代的次数。
3) 本地模型更新与上传。对于每个被选择的节点Pt,在接收到全局模型和区块模板后,在SGX的可信内存中执行区块模板要求的对应代码,具体是对本地数据进行预处理,利用本地数据继续训练模型并更新参数,直至多次本地迭代后模型再次收敛,并执行PoUW飞地计数器,根据有效工作指令数量进行伯努利实验,判断是否产生PoUW,最后节点上传本地梯度更新参数、时间戳Timestamp至请求方,如果成功产生PoUW则一起上传。此处的PoUW生成流程详见1.2节。
4) PoUW验证与区块生成。请求方Req在接收到所有节点P上传的本地模型与某个节点的PoUW后,会按照新的共识算法PoUW来验证该PoUW,即证明SGX生成的证明是否证明PoUW飞地符合节约型挖掘(Resource-efficient mining,REM)以及证明PoUW是否成功开采了一个块且满足给定的难度参数。当Req验证PoUW为真时,将其与区块模板结合为一个区块发布到区块链中。此处的PoUW验证流程详见1.2节。
5) 区块验证。当区块链参与者验证在区块链网络上接收到的新块时,除了验证更高层的属性(如在比特币等加密货币中,交易、先前的块引用等是否有效),参与者验证相关区块,验证完毕的区块会被入链,此时参与该任务的客户端将会得到加密货币奖励。
6) 全局模型更新与可信存储。请求方Req根据本次获得的所有客户端的本地梯度更新参数并结合联邦学习的FedAvg算法[26]来更新全局模型。此外,Req方无法直接将诸多本地更新参数上链且其保存容量有限,为了实现本地对模型更新参数的溯源,满足日后对异常攻击行为进行追溯以及模型迭代更新的需求,需要将本地梯度更新参数数据分片存储至所有参与本次迭代的客户端节点上(值得注意的是,本次迭代的元信息,如具体的参与者和迭代轮数在步骤4区块生成中已经上链),并通过存储总体数据的默克尔树以及随机向参与存储节点发起不同的挑战来实现数据的可信存储。
采用联邦平均(Federated learning averaging,FedAvg)算法来实现全局模型更新这个步骤。联邦平均算法将多个使用随机梯度下降算法的深度学习模型整合成一个全局模型。与单机机器学习类似,联邦学习的目标也是经验风险最小化,即
(1)
式中:n为样本容量;si为第i个样本个体;f(x;si)为在模型上的损失函数。假设有K个局部模型,Pk表示第k个模型拥有的样本个体的序号集合,nk=|Pk|,目标函数可重写为
(2)
(3)
值得注意的是,由于每个终端设备的数据不能代表全局数据,不能认为EPk[Fk(x)]与f(x)相同,也就是说任何一个局部模型都不能作为全局模型。
此处将局部模型的一次参数更新称为1次迭代。用b表示一个batch,那么第k个局部模型迭代公式为
(4)
整体采用的方法总结如下:将训练过程分为多个回合,每个回合中选择C×K(0≤C≤1)个局部模型对数据进行学习;第k个局部模型在一个回合中的epoch数量为E,batch大小为B,从而迭代次数为Enk/B;在一个回合结束之后,对所有参与学习的局部模型的参数进行加权平均,得到全局模型。
对于请求方Req,只需要进行以上6个步骤的迭代,直至全局模型收敛或者达到需求后,即可实现数据可信存储与模型安全训练。
1.2 基于Intel SGX的PoUW共识算法构建
在区块链系统设计时,利用PoW共识算法可以在参与者之间公平分配奖励,防止攻击者通过廉价伪装成多台机器来获得多数权力。然而,使用PoW的成本过高,综合的能源浪费实际上相当惊人,不适用于能源企业。结合能源企业中的实际环境与需求,笔者采用REM框架,以PoUW作为共识算法来替代PoW,其核心依赖于英特尔的SGX技术,在PoUW系统中,用户可以将其CPU用于任何所需的工作负载,并且可以同时为保护区块链作出贡献。
REM的核心是一个矿工程序,它可以做有用的工作并产生PoUW,PoUW中执行的每条CPU指令类似于PoW方案中的一个Hash函数计算,即每条指令都有一些成功挖掘区块的概率,如果飞地确定是这种情况,它会生成一个PoUW。PoUW的具体生成流程如图3所示,具体如下:1) PoUW运行时充当“in-enclave”加载器,它以适当的输入启动有用的工作程序并收集结果指令计数,同时需要块哈希和难度,并通过运行挖掘程序开始挖掘;2) 一旦挖矿程序返回,PoUW运行时就会从保留寄存器中提取指令计数器,并确定当前是否需要进行伯努利实验来生成数据块;3) 每当运行一定数量的指令后,PoUW会从SGX的随机数生成器中抽取一个随机值,并根据指令计数器和当前难度确定是否应该生成新块。如果应该生成一个块,PoUW运行时会生成一个证明,记录调用它的模板哈希和难度。
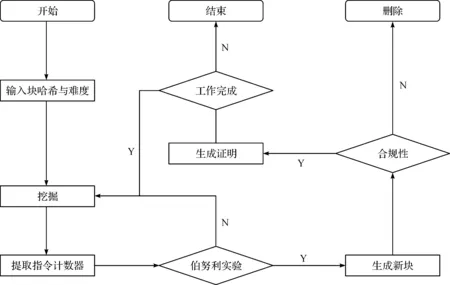
图3 PoUW生成流程图Fig.3 Flow chart of PoUW generation
实际应用中,Req必须检查生成区块PoUW的有用工作程序是否遵循协议并正确计算其指令。然而,将所有程序放在区块链上进行验证会产生巨大的开销。此外,攻击者还可能通过发送大量垃圾信息进行拒绝服务攻击。为此,需要进行PoUW的合规性验证,Req通过合规性检查器将单个程序的指纹硬编码到区块链中,并将用户提供的程序作为输入,验证PoUW是否符合定义的要求,其具体验证流程如下:1) 合规性检查器确认文本部分是不可写的;2) 合规性检查器通过反汇编来验证工作程序是否合规,并确认专用寄存器是为指令计数保留的,同时确认计数是正确的且出现位置准确;3) 合规性检查器验证PoUW运行时是否正确链接并且与预期的PoUW运行时代码相同;4) 合规性检查器计算程序的指纹并输出包含此指纹的证明。
1.3 数据可信存储
Req方无法直接将诸多本地更新参数上链且其保存容量有限,为了实现本地对模型更新参数的溯源,满足日后对异常攻击行为进行追溯以及模型迭代更新的需求,需要将本地梯度更新参数数据分片存储至所有参与计算的客户端节点上。为了保障数据的可信存储,实施的存储和验证操作如下:
1) 针对任意需要存储数据的客户端,对需要存储的数据文件F进行切割,得到N个文件块,保存其默克尔树M,并为每个块对应的默克尔树的叶子节点生成随机数R={1,2,…,N}。
2) 将文件块随机传送给参与运算的不同客户端,分到的客户端即为存储方(不同的存储方存储不同的数据块)。
3) 文件F的拥有者随机向存储方发起挑战,设文件F被分割为N块,r为集合R={1,2,…,N}中随机的任意值,s为挑战的随机数,向存储方发送r和s。
4) 存储方需要回复如下应答,即
response=H(F[r]‖s)
(5)
式中:F[r]为第r个文件块;H为Hash生成函数;s用来防止存储方私下保存文件块的Hash值却将原始文件块删除。
5) 存储方的回复通过验证后,传回对应的文件块,拥有者对应的客户端为该文件块重新生成随机数,并更新对应的默克尔树的存储值。
6) 重复步骤3)~5)以进行重复多次的文件块验证过程。
数据可信存储中关键方法的具体说明如下:
1) 在区块链分片存储中,其基本思想是将请求方要求存储的大规模数据按照一定大小进行分割切片,并选择节点来存储部分对应的数据块。为了提高链下存储的可靠性与高效利用率,首先需要使用冗余存储,即一份数据块需要存储到多个节点上,从而避免某节点错误导致数据丢失;然后要有合适的节点选择策略,不能将数据存储到所有节点上,要根据其过去的表现与目前的价格来动态调整选择存储的节点;最后要有合适的存储证明机制来保证数据的有效存储。总而言之,区块链的分片存储可以实现数据安全有效的存储,充分利用区块链网络中多个节点的剩余存储空间,提高存储空间的利用率。
2) 在默克尔树设计中,每个节点都标有一个数据块(如文件或者文件的集合)的Hash值。非叶节点是其对应子节点串联字符串的Hash。默克尔树可以用来验证任何一种在计算机中和计算机之间存储、处理和传输的数据。它们可以确保在点对点网络中数据传输的速度不受影响,数据跨越自由地通过任意媒介,且没有损坏和改变。此外,基于默克尔树的存储机制证明技术中往往会出现一个存储方需要存储多个文件块的情况,那么在这种情况下为了提升验证的效率,可以在上述实现的基础上,将同一个存储方的文件块与随机数结合优先构建子默克尔树,发起挑战验证时只需要存储方按对应顺序构建的子默克尔树返回其文件块即可,从而实现高效率且快速的存储证明与错误定位。
3) 存储挑战是基于Hash函数实现的,请求方通过对与随机数结合后的文件块进行Hash运算得到对应Hash值并创建对应默克尔树,而存储方在收到对应的文件块后对其进行存储,在收到挑战的随机数后需要将其与文件块对应拼接后进行Hash运算得到对应的Hash值并返回。如果存储方不存储对应文件块,只存储文件块对应的Hash值,在之后收到挑战随机数时,因为对复杂Hash大数逆向求解的困难性,所以无法实现Hash值向文件块转移的运算,从而无法完成挑战。
1.4 深度学习模型构建
笔者主要提出一种基于AutoEncoder和RNN的模型构建方案,具体如下:1) 特征提取。在模型训练时,传统的机器学习方法由于需要提取统计特征,存在覆盖率不足、精度较差等问题。而AutoEncoder通过训练,在维持输入和输出一致的同时,隐藏层对应的特征可以有效代表训练样本,同时对高维度的特征数据进行压缩,减少建模计算开销,笔者通过提取隐藏层的特征向量进行后续模型的高效训练。2) 模型构建。在得到有效的特征之后,通过经典的RNN结构[27]来进行模型训练,并综合比较了不同机器学习与深度学习方法的结果。
2 实验与分析
使用Truffle套件在以太坊上构建区块链,其中Truffle是一个开源的以太坊测试框架。使用基于Intel®Core i7-6700K SR2L0的主机作为客户端,内存为16 GB。
2.1 数据集
利用开源的NSL-KDD作为评估数据集[28],与KDD CUP 99数据集[29]相比,NSL-KDD数据集的训练集中不包含冗余记录,故分类器不会偏向更频繁的记录,不会导致模型单纯记忆原始数据而没有很好的泛化性。NSL-KDD数据集中包含了正常的数据与攻击数据,攻击数据分为4类,分别为拒绝服务攻击(Dos)、提权攻击(U2R)、远程访问攻击(R2L)和端口监视/扫描攻击(Probe)。在NSL-KDD数据集中,训练集共有125 973条记录,测试集共有22 544条记录,其中Dos,U2R,R2L,Probe,Normal样本的训练集和测试集数量分别为45 927,52,995,11 656,67 343和7 458,67,2 887,2 421,9 711。每条记录的维度为41维,在预处理(包括正则化)后,输入共计包含122个维度,包含3种协议类型、70种服务和11个标志位。
2.2 实验设置
在私有链中,参与联邦学习的客户端数量为10;在数据可信存储时,N设定为100;在深度学习模型中,训练集数据被随机分成10等份,每个参与学习的客户端均利用其中1份数据进行训练,Req负责将训练后的模型聚合,用于测试;在Autoencoder中,隐藏层数设置为3层,第1层隐藏层神经元数为64,第2层隐藏层神经元数为32,第3层隐藏层神经元数为64,第2层隐藏层为最终的优化特征,输入层和输出层的维度均为122维,学习速率η=0.1;在RNN中,输入层维度是32,隐藏层数设置为2层,第1层隐藏层神经元数为32,第2层隐藏层神经元数为16,输出层神经元个数为5,表示5分类。值得注意的是,上述参数通过调优获得,在具体的任务中分析人员可以根据实际需要进行调整。
2.3 精度评估
利用云端集中式训练和联邦学习分布式训练得到收敛的模型后,测试结果对应的混淆矩阵分别如表1,2所示。由表1,2可以看出:模型对于Dos以及Probe两种攻击类型的分类准确率较高,对R2L和U2R的检测能力较弱,这与先前的研究[27]得到的结论一致,其主要原因是R2L和U2R这两类攻击的行为模型和正常行为模型的区别并不大,如正常用户通过远程访问和攻击者通过远程访问的方式在很多时候是非常相近的,想要更加精确地检测此类攻击,需要进一步结合攻击的行为进行分析(如上下文检测)。总体来说,在10个客户端参与的情况下,利用云端集中式训练和联邦学习训练得到模型的精度分别达到了81.45%和80.95%。

表1 云端集中式训练入侵检测精度评估表Table 1 Cloud centralized training intrusion detection accuracy evaluation table
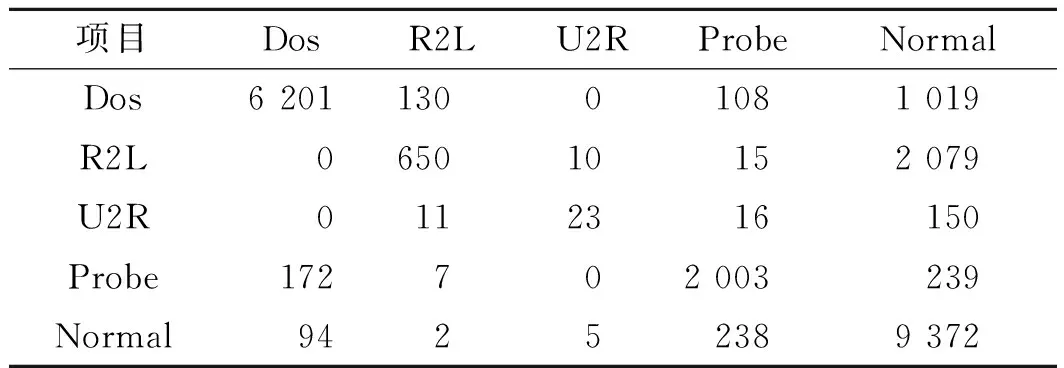
表2 联邦学习分布式训练入侵检测精度评估表Table 2 Federal learning distributed training intrusion detection accuracy evaluation table
为了进一步评估不同模型的精度以及联邦学习对精度的影响,笔者综合比较了Random forest(RF)[16],Support vector machine(SVM)[13],CNN[17],RNN[21]与AutoEncoder+RNN(AutoRNN)的结果,10次独立重复实验后的平均精度如图4所示。当利用云端集中式训练时,RF,SVM,CNN,RNN,AutoRNN的精度分别为74.00%,73.98%,79.90%,81.29%,81.45%;而在联邦分布式学习的情况下,RF,SVM,CNN,RNN,AutoRNN的精度分别为73.21%,73.50%,79.20%,80.60%,80.95%。
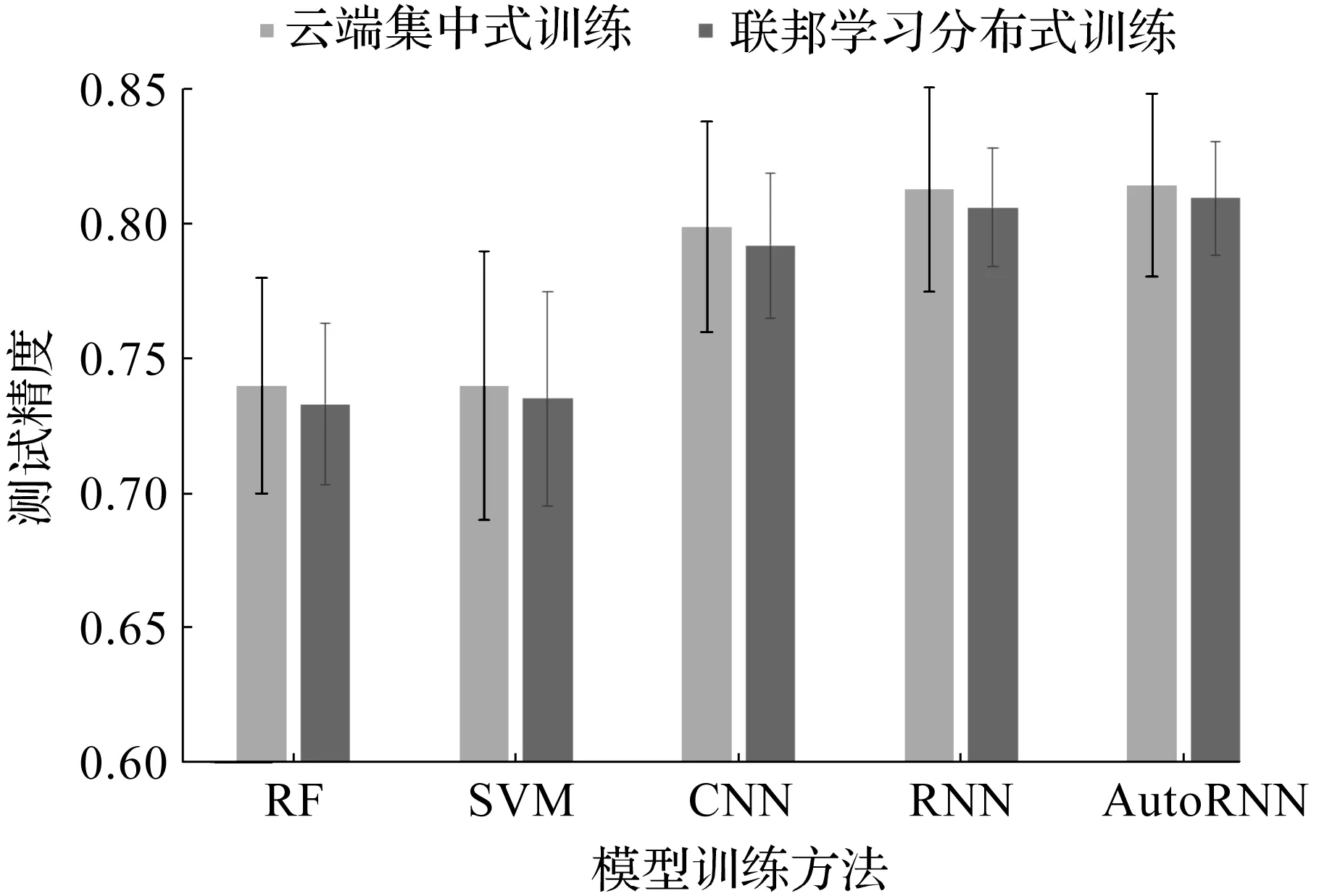
图4 云端集中式训练与联邦学习训练在不同模型下的精度表现Fig.4 Precision performance of cloud-based centralized training and federated learning training under different models
由图4可以看出:1) 使用联邦学习分布式训练会使得精度下降,其原因是联邦学习会将数据分散在不同的客户端,每个客户端的训练量约为正常云端训练的1/10(在本实验中设备客户端数量为10),训练数据减少虽然导致了精度有所下降,但是不同客户端参数的聚合弥补了该缺陷,使得最终精度的下降幅度低于1%;2) 基于传统的机器学习模型(RF,SVM)的精度普遍低于基于深度学习模型(CNN,RNN,AutoRNN)的精度,其原因是传统的机器学习依赖于手工提取特征,其特征的覆盖率不全,无法全面地表征正常日志与攻击日志,然而基于深度学习的模型能够自动从原始数据中提取特征,泛化能力较强,特别要注意的是,基于AutoEncoder和RNN的模型因为加入了自动特征的学习,所以其表现要优于已有的CNN和RNN方法;3) 通过10次独立重复实验,云端集中式训练和联邦学习分布式训练的平均精度均较为稳定,波动在±3%以内。
2.4 开销测试
使用开源性能测试工具Jmeter进行私有链系统的压力测试。针对每一次通信迭代过程,测试1.1节中每一阶段的耗时、内存开销和CPU开销。所有阶段包括:区块模板发布与节点选择、模板与模型下载、本地模型更新与上传、PoUW验证与区块生成、区块验证、全局模型更新与可信存储。其中,分别计算Req客户端和参与运算的客户端(Req除外)在一次迭代过程中的内存开销和CPU开销,结果如表3所示,所有结果均为10次独立实验的平均值。
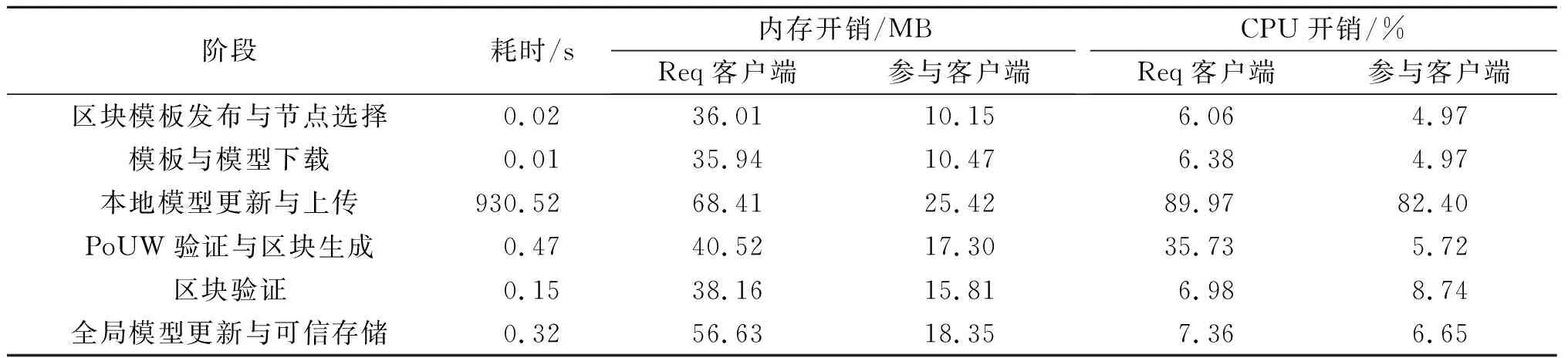
表3 私有链不同通信迭代阶段的平均耗时、内存开销及CPU开销Table 3 The average time, memory cost and CPU cost of different communication iterations of private chain
由表3可以看出:在通信迭代过程中,整个基于智能合约的私有链最耗时的操作为本地模型更新与上传,平均用时为930.52 s,因为模型的构建需要数据的加载以及大量的运算操作;比较耗时和占资源的是区块生成操作,与除模型训练之外的其他阶段相比,区块生成占了约50%的时间;可信存储在一定程度上也消耗了资源,因为各个客户端为了验证数据可信而对随机挑战进行了应答,在使用可信存储的安全增强方案下各个中间环节的耗时如表4所示。基于表3,4计算可得:在使用基于默克尔树的安全分片存储的情况下,全局模型更新的时间约延长0.08 s,性能损耗约为25%,在保证安全性的条件下,这个损耗是可以接受的。

表4 可信存储各阶段的耗时Table 4 The average time cost of each stage for trusted storage
综合来看,基于智能合约的私有链的开销能满足真实环境下的需求。共识机制主要依赖于私有链上客户端的数量,客户端数量越多,需要的耗时和资源开销便越大,因此选择合适数量的客户端对系统性能的提升有一定帮助。此外,主机配置的提高也有助于降低算法运行过程中的时延。
3 结 论
笔者提出了一种基于区块链有用工作量证明及联邦计算的主机入侵检测方法。在区块链设计上,结合联邦学习实现本地模型训练并聚合生成全局模型,保障了原始数据的隐私;在共识机制上,基于主机优势,利用Intel SGX的PoUW共识算法替代PoW,减少了能源的浪费;在数据存储上,通过存储总体数据的默克尔树以及随机向参与存储节点发起不同的挑战,实现了数据的可信存储;在模型构建上,结合AutoEncoder与RNN构建模型,实现了高精度的主机入侵检测。在NSL-KDD开源入侵检测数据集上达到了较优的效果,能够有效保障能源企业主机入侵检测系统的隐私性、安全性和可用性。
猜你喜欢
家庭影院技术(2020年10期)2020-12-14
家庭影院技术(2019年7期)2019-08-27
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
电子测试(2018年10期)2018-06-26
海外星云(2016年15期)2016-12-01
俄罗斯问题研究(2013年1期)2013-03-11
测绘科学与工程(2013年1期)2013-03-11
环球时报(2012-09-04)2012-09-04
中国宪法年刊(2012年0期)2012-03-25
