
基于模糊约束的贝叶斯网络参数学习
2023-02-01 03:16:58茹鑫鑫高晓光王阳阳
系统工程与电子技术 2023年2期
茹鑫鑫, 高晓光, 王阳阳
(西北工业大学电子信息学院, 陕西 西安 710129)
0 引 言
贝叶斯网络(Bayesian network,BN)[1]已经成为表示和处理不确定信息的有效工具,一个完整的BN包括一个有向无环图(directed acyclic graph,DAG)和对应的条件概率表(conditional probability table,CPT),分别从定性和定量角度表示出节点之间的依赖关系。目前BN已经在故障诊断[2]、基因分析[3]等领域有了广泛应用。
通常BN的结构[4-6]和参数[7-10]都是从数据中学习得来,当数据充足时,K2[11]是常用的结构学习算法,最大似然估计(maximum likelihood estimation,MLE)算法[12]是常用的参数学习算法。当训练样本量难以满足学习需求时,仅利用K2算法和MLE算法会造成学习结果过拟合,无法得到精确的结构和参数。对于该问题,在结构学习中,专家可以直接给出节点间的定性关系,但在参数学习中,专家难以给出准确的参数值。目前,相关研究主要通过基于约束的方法、数据扩展以及两者混合的方法来解决这一问题。基于约束的方法主要有两种:凸优化(convex optimization,CO)[13-14]和定性最大后验(qualitative maximum a poste-rior,QMAP)估计[15-18]。CO将参数学习问题转化为在约束空间内寻找目标函数最优解。约束MLE(constrained MLE,CMLE)是将MLE与约束条件相结合来构建CO优化模型。QMAP首先利用蒙特卡罗方法生成满足约束条件的先验参数,再构建超参进行最大后验(maximum a posterior,MAP)估计。基于数据扩展的方法力求通过增加样本量来解决数据不足的问题。文献[19]使用迁移学习来增加数据量,当目标网络和源网络具有相同的结构时,直接迁移数据进行参数学习。文献[20]用额外的数据源解决了节点样本完全缺失的参数学习问题,通过元分析法结合多源样本来学习参数。文献[21]认为在多样本条件下,低质量样本在参数学习中不应与高质量样本拥有相同的权重,通过使用马氏距离对样本进行评分加权学习。对于约束与数据扩展混合的方法,文献[22-23]通过不等式约束判断备选源域的样本是否可以被迁移,通过范围约束确定备选源域在迁移学习中的权重,从而提高样本迁移准确度。文献[24]提出了一种基于约束的参数扩展方法,通过自助法扩展数据产生满足约束条件的参数进行学习。
尽管约束在参数学习中已经得到了广泛应用,但如何平衡约束干预学习过程的过拟合和欠拟合仍然是一个亟待解决的问题。在小样本量下,如果参数学习完全依靠数据,就会出现因样本不足而造成的参数学习结果过拟合问题。对于基于约束的MAP方法,不论其约束形式和先验参数量化方式有何不同,都需要构建Dirichlet超参来实现参数学习。当约束的干预效能较低时,即选取的超参值较小,难以消除学习结果的过拟合。当约束干预过强时,即选取的超参值过大,学习结果会完全偏向约束,造成学习结果欠拟合。假设专家对一个约束条件有90%的把握,而对另一个约束条件只有60%的把握,如果这两个约束在学习过程中有相同的超参值也是不合适的。因此,如何让约束在学习过程中发挥适当角色,关键是构建合适的超参。
本文核心思想是对于同一约束,专家把握度(隶属度)越大对应的超参值应该越大;对于同一约束,给定学习样本为100所对应的超参应大于给定学习样本量为300的超参,即给定的样本量越大,对应的超参应该越小。
综上,本文提出基于模糊先验约束的BN参数学习算法,通过将隶属度引入到超参的构建过程中,解决小样本下参数学习的过拟合问题。同时,引入样本量边界来避免因外界过度干预而造成参数学习结果的欠拟合问题。此外,将本文所提算法应用到网络安全评估中,以漏洞评分作为先验信息,结合迁移学习思想,利用漏洞编号进行迁移学习。
1 预备知识
1.1 参数学习
BN结构描述节点间的定性关系,参数表达节点的概率分布。因此,BN是由一个DAG和对应的CPT组成的。BN可以定义为G(V,E),其中,V1,V2,…,Vn∈V是网络中的节点集合,E是边集合。给定任意节点Vi的父节点集合Πi,Vi独立于其非子孙节点。当训练数据充足时,MLE是常用的参数学习方法,其目标函数[17]可以表示为
(1)
式中:θ为整个BN的参数;θijk表示网络中节点Vi的父节点Πi为第j个组合时,i取值为k的参数,即P(Vi=k|Πi=j);ri为节点的状态数,为父qi节点Πi组合数;Nijk代表数据集D中网络中节点Vi的父节点Πi为第j个组合时的统计样本量;c为一个常量。最大化式(1)之后,θijk的MLE可以表示为
(2)
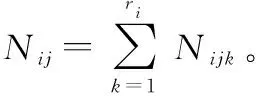
当学习样本量不足时,使用MLE容易造成学习结果过拟合,无法得到准确的参数。为解决此问题,通常将先验信息融入到参数学习中来提高学习精度。此时,参数学习问题便转化为融合先验信息后的MAP问题[13],如下所示:
(3)
式中:αijk为节点Vi的父节点Πi为第j个组合状态时,i取值为k的超参,αijk为Dirichlet分布。超参可以消除过拟合的原因在于αijk作为虚拟样本量进行参数学习,最大化式(3)后,可以得到θijk的MAP估计如下所示:
(4)
式中:αij为节点Vi的父节点Πi为第j个组合状态时的超参权值。
1.2 常见约束形式
专家可以依据在专业领域中的理论和经验积累,对BN参数做出一些约束判断,这些判断可以转换为参数学习过程中的约束条件。常用的约束形式如下。
(1) 范围约束
定义一个参数范围约束空间如下所示:
0≤α≤θijk≤β≤1
(5)
式中:α和β是约束范围的边界。
(2) 不等式约束
定义两个参数之间的大小关系如下所示:
θijk<θij*k*
(6)
式中:θij*k*为与θijk存在不等关系的参数。
(3) 近似相等约束
定义两个参数的近似相等关系如下所示:
|θijk-θijk*|≤δ
(7)
式中:δ为置信区间。
(4) 公理约束
定义参数最基本的概率性质,即归一化和非负性如下所示:
(8)
2 基于模糊约束的参数学习
2.1 模糊超参构建
基于约束的MAP方法是在给定训练样本之后,利用约束来对学习过程进行干预。不论约束形式和先验参数量化方式有何不同,最终都需要构建超参来进行学习。如果完全依赖约束,此时式(3)可以写为
(9)
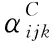
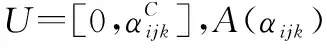
(10)
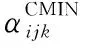
(11)
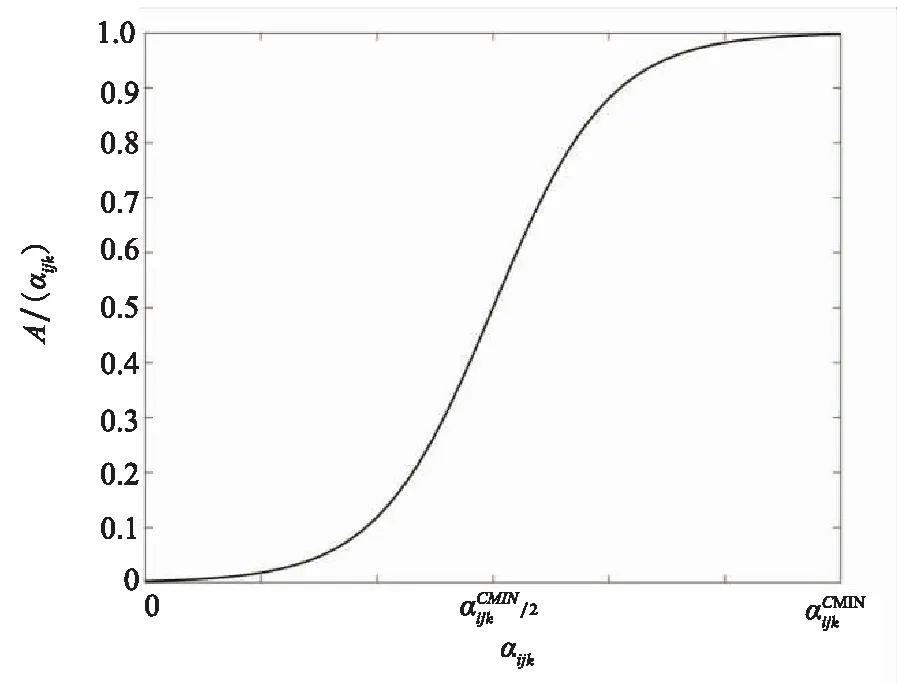
图1 超参隶属度分布图Fig.1 Hyperparameter membership distribution chart
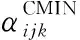
(12)
式中:Ω为参数约束集合。当同分布中,ri比较大时,式(12)难以求解,因此可以将MAP改写来求解,如下所示:
(13)
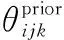
(14)
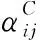
(15)
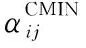
(16)
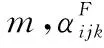
(17)
综上,本文提出的模糊MAP(fuzzy MAP, FMAP)估计的计算方法为
(18)
2.2 FMAP估计
由于约束难以完全覆盖BN中每一个参数,当无约束时,平滑先验和贝叶斯狄利克雷似然等价一致联合分布(Bayesian Dirichlet with likelihood equivalence and a uniform joint distribution,BDeu)是常用的先验分布,解决了由样本不足造成的参数结果为0的问题,一定程度上提高了参数学习的精度。无约束下MAP计算方法如下所示:
(19)
式中:当λ=1时,为平滑先验;当λ=(riqi)-1时,为BDeu先验,本文选择λ=1。
综上,本文提出的FMAP估计方法如算法1所示。

算法1FMAP输入 约束Ω,训练数据D输出 参数 θ1. For each Vi of BN2. For each j of Πi3. For each k of ri4. If θijkis not constrained∥如果不存在约束5. θijk←式(19);∥θMAPijk为最终参数6. Else7. θMLEijk←式(2);∥θMLEijk为最终参数8. If θMLEijk∈Ω∥如果θMLEijk符合约束9. θijk←θMLEijk;∥θMLEijk为最终参数10. Else11. θpriorijk←Ω;∥约束量化出先验参数θpriorijk12. αCij=1;13. While (θijk∉Ω)∥交叉验证求式(14)中 αCMINij14. αCMINij=+1;15. θijk=Nijk+ αCMINijθpriorijkNij+ αCMINij;16. End While17. αFij←式(16);18. For each k of ri∥参数归一化19. θijk←式(18);∥θFMAPijk为最终参数20. End For21. End If22. End If23. End For24. End For25. End For
3 实验验证
3.1 实验设置
实验代码基于BNT工具进行实现,运行在Matlab 2020上,实验硬件配置为CPU AMD 5950X和RAM 32G。实验选取6个不同规模的标准BN,通过对比不同算法来验证FMAP的有效性。标准BN[26]信息如表1所示,根据参数数量可将实验标准网络分为小、中、大。
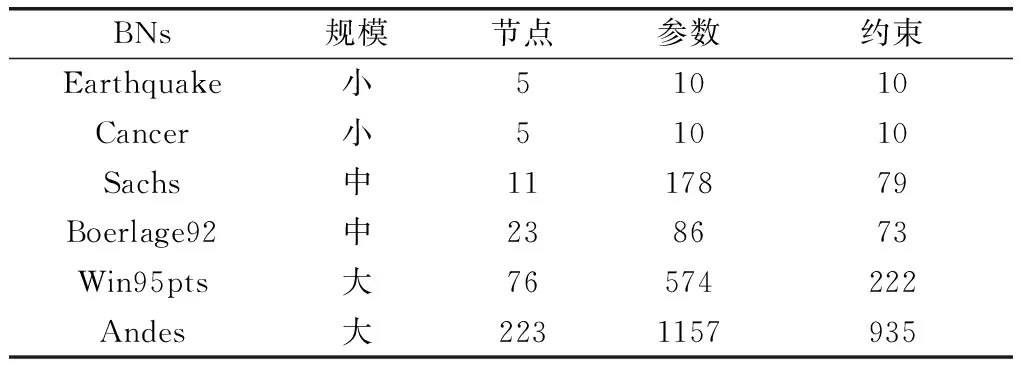
表1 标准BN信息
标准BN的结构和网络参数是已知的,训练数据是由BNT[27]工具箱提供的“sample_bnet”函数根据标准BN产生。进行对比实验算法如下:
(1) MLE:纯数据驱动的学习方法,不融合任何先验信息;
(2) MAP:融合先验的参数学习方法,使用平滑先验,即αijk=1;
(3) CMLE:结合约束与CO的方法;
本文实验通过相对熵又称KL(Kullback-Leibler)散度[28]来评价标准网络参数和学习结果之间的误差,KL值越低说明学习结果精度越高,KL计算方法如下所示:
(20)
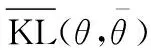
图2展示了Cancer网络的结构和每个节点对应的CPT表。依据约束构建原则和图2中节点的CPT表,构建出表2中Cancer网络的正常约束,即η=0,本文实验中的其他BN约束的构建方式与Cancer相同。
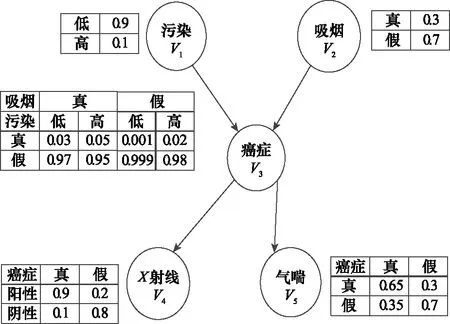
图2 Cancer网络结构和参数Fig.2 Cancer network structure and parameters

表2 Cancer网络约束
本文主要研究的是小样本下参数学习精度问题,为此实验样本量设置为100、300、500。通常小样本下参数学习研究的训练样本量设置为50到500,对于小型网络,500样本量依然被认为是不充足的。而Cancer 和Earthquake 参数个数都为10,1 000样本量已经相对充足,在文献[5]中对于大型网络,认为10 000为相对充足的样本量。因此,对式(17)中的M,小型网络设置为M=1 000,中型网络为M=5 000,大型网络为M=10 000。为得到更加稳定准确的实验结果,每个学习案例重复学习20次。每次都重新生成训练数据,20次实验的方差也将在结果中显示。对于每个学习案例,性能表现最好的算法结果在表格中加粗表示。
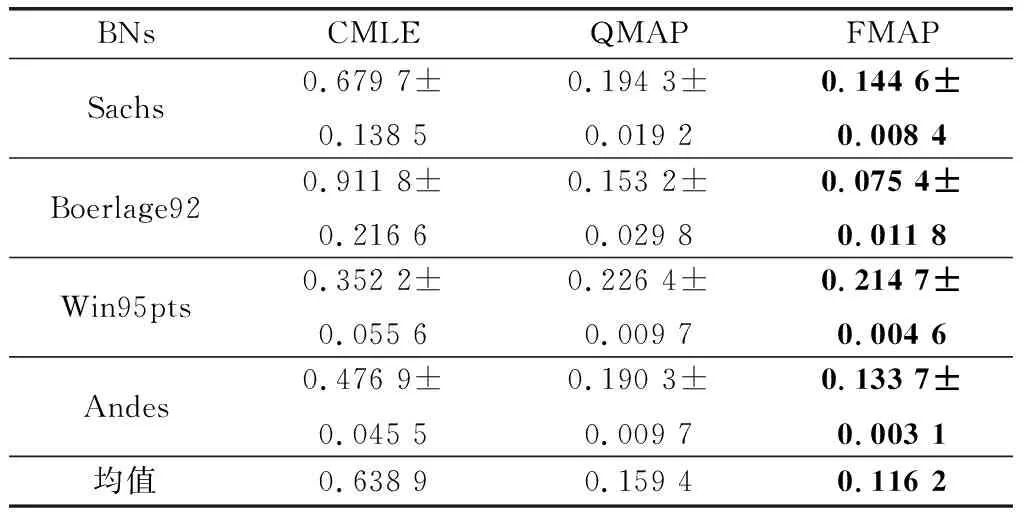
3.2 算法精度验证
本部分实验主要验证在正确约束环境下,即所有约束η=0,FMAP算法是否可以有效提高参数学习的精度。学习结果如表3~表5所示。
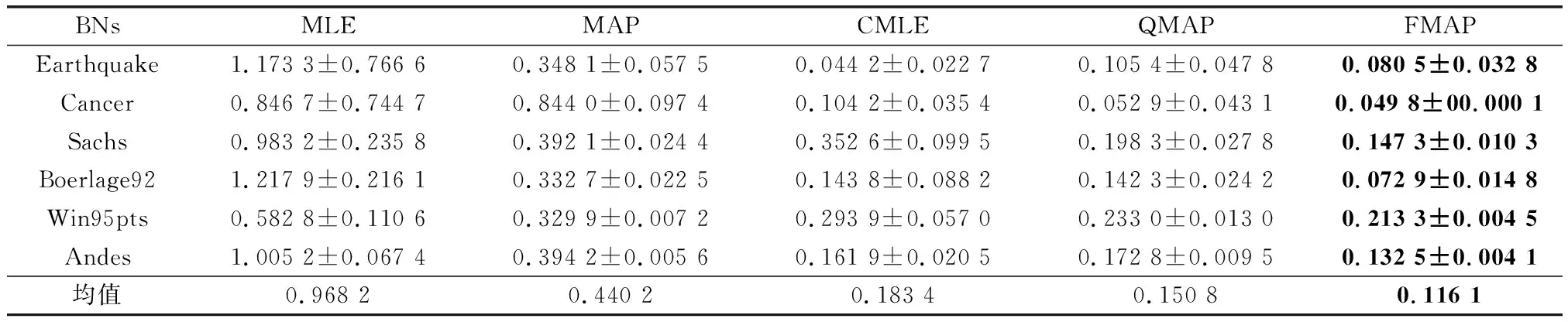
表3 100样本量KL对比
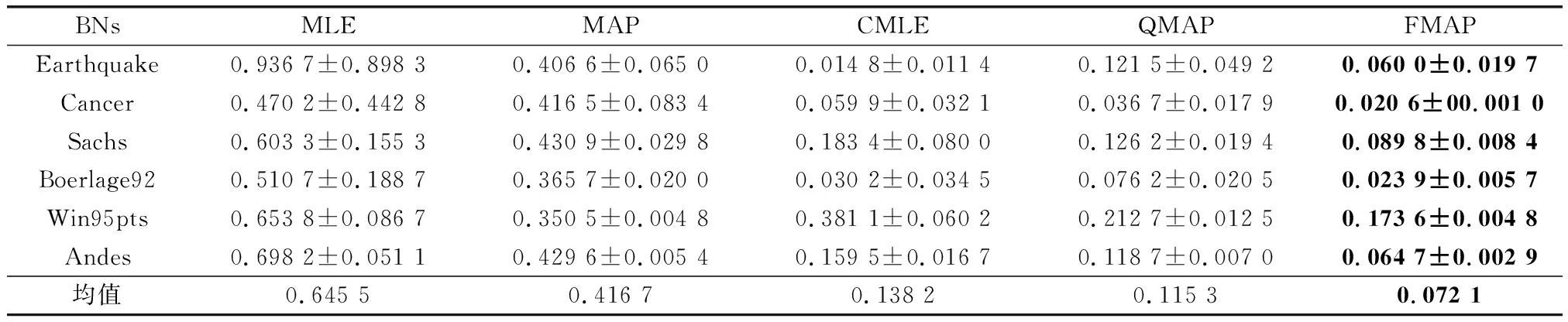
表4 300样本量KL对比
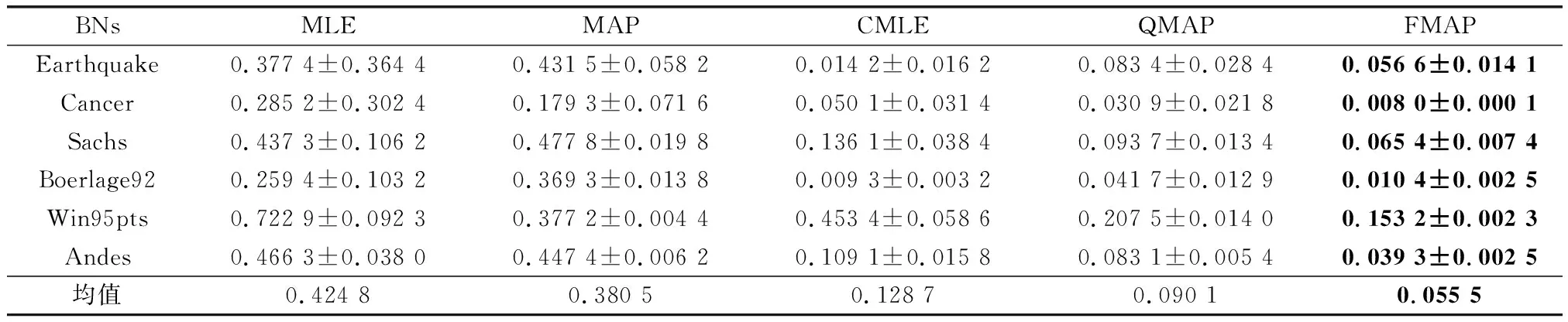
表5 500样本量KL对比
通过表3~表5结果可以发现,在正确约束实验中,FMAP的精度表现最好。增加先验的MAP与纯数据学习的MLE相比,在3个样本量下精度分别提高了54.3%、35.45%、10.42%。MLE虽然有不错的收敛性,随着训练样本量的增加与MAP的差距逐渐减少。但在小样本量下,由于容易出现一些参数没有学习样本的情况,导致参数结果为0,而MAP引入平滑先验,有效地解决了这一问题。结合约束的CMLE与MLE相比,在3个样本量下精度分别提高了81.06%、78.60%、69.70%。同样,结合约束的QMAP与MAP相比,在3个样本量下精度分别提高了65.7%、72.3%、76.3%。由此可以看出,加入先验和结合约束可以提高参数学习的精度。QMAP与CMLE相比,在3个样本量下精度分别提高了17.77%、16.57%、29.90%。构建模糊超参的FMAP与固定超参权值的QMAP相比,在3个样本量下精度分别提高了21.01%、37.47%、38.40%。
实际应用中,通常会有噪音的存在,这将挑战算法的鲁棒性。本文部分实验,将在约束中混入20%的一般噪音约束(η=0.2)和10%的极端噪音约束(η=0.4)来进行学习,以验证算法的鲁棒性。本部分实验,只针对基于约束的算法进行对比。
通过表6~表8可以发现在噪音约束下,QMAP与CMLE相比精度分别提高了75.5%、67.18%、50.46%;FMAP与QMAP相比精度分别提高了27.1%、39.36%、46.79%。因此,在噪音约束环境中,FMAP依然有杰出的精度表现。通过与正确约束中的3个算法的学习效果比较发现,CMLE受噪音约束影响最严重,QMAP次之,FMAP受到的影响最小。造成这一结果的原因是,CMLE是以约束为导向,构造目标函数来学习,对约束的依赖性极强。因此CMLE容易受到约束质量的影响,而CMLE本身并没有相关的设计来应对这一问题。对于QMAP超参权值使用节点状态的势,设置相对固定,既不能在正确约束中发挥足够的干预效果,也不会过分受到噪音约束影响。而本文提出的FMAP通过引入模糊理论,提高了约束使用的精准度和可解释性,为超参的构建提供了更加灵活的方法。
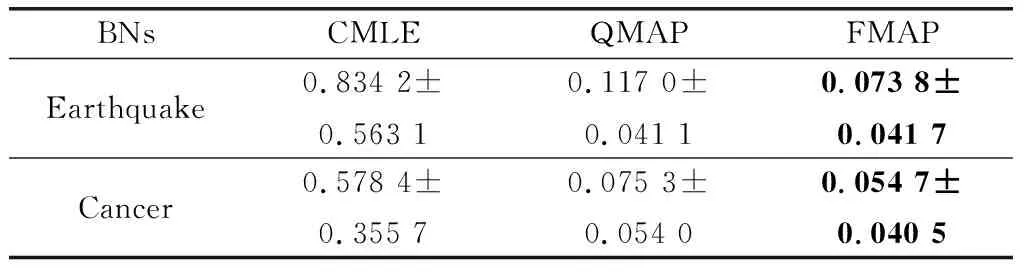
表6 噪音约束下100样本量结果对比
续表6
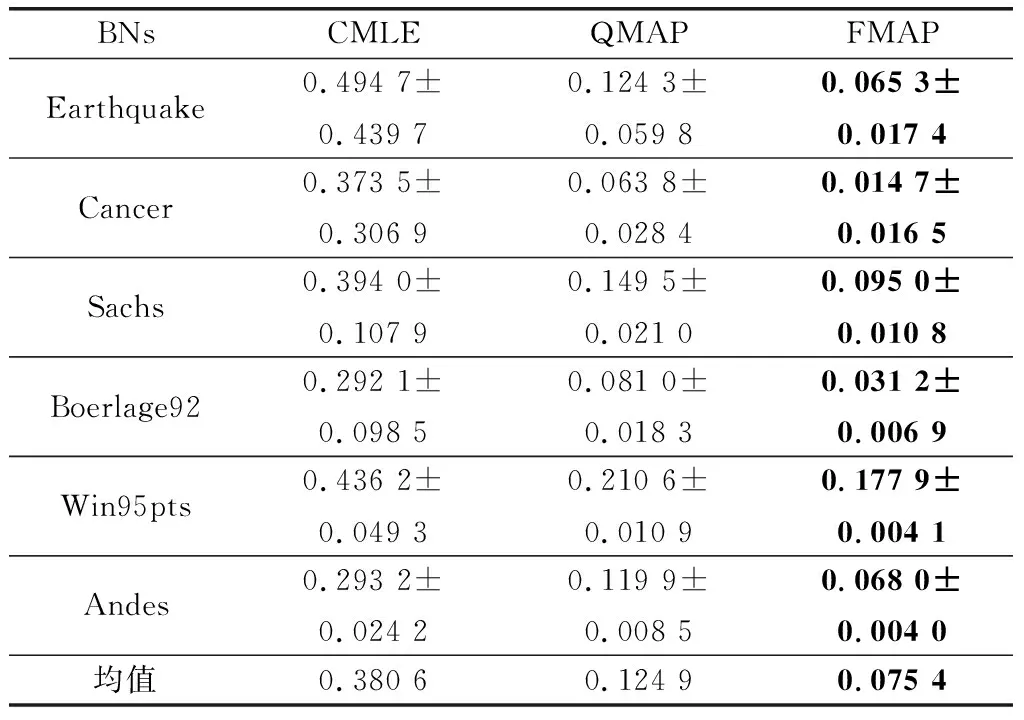
表7 噪音约束下300样本量结果对比
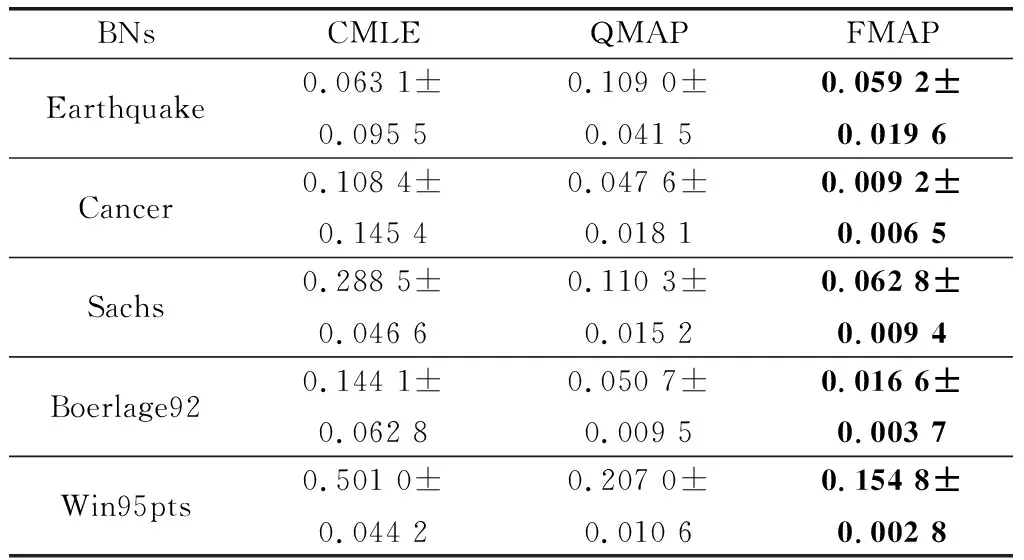
表8 噪音约束下500样本量结果
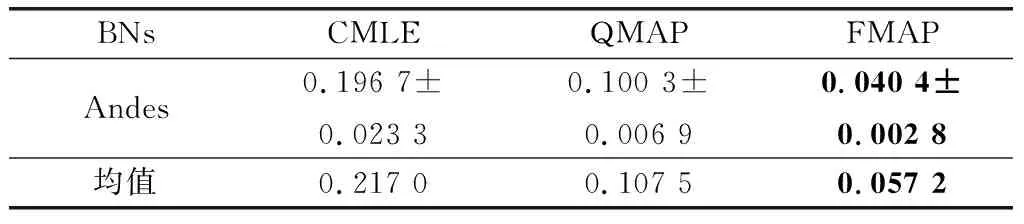
续表8
3.3 算法时间验证
精度和时间是检验算法常用的指标,上文对算法的有效性和鲁棒性进行了验证,本部分将对算法运行时间进行分析。为节省篇幅,本文只展示最有代表性的最小样本量和最大样本量的结果,如表9和表10所示。通过表9和表10可以看出,对学习过程不做任何干预的MLE运行时间最优,本文提出的FMAP算法排在第4位,消耗时间最多的算法是CMLE。CMLE更多的时间消耗在构建CO和求解上,QMAP在先验参数的量化过程中消耗了一定的时间,FMAP需要更多的时间来处理交叉验证和模糊超参求解。而本文是解决小样本下的参数学习问题,在实验样本为500时,即使对于最大的标准网络Andes的算法运行时间,FMAP也仅为2.38 s,运行时间虽然为MLE的1.98倍,但也是仅多消耗了1.18 s,比QMAP多消耗了0.77 s。对于小样本下参数学习这一特殊的问题,多数算法的运行时间都在可接受范围之内,因此FMAP所多消耗的时间是可以接受的。
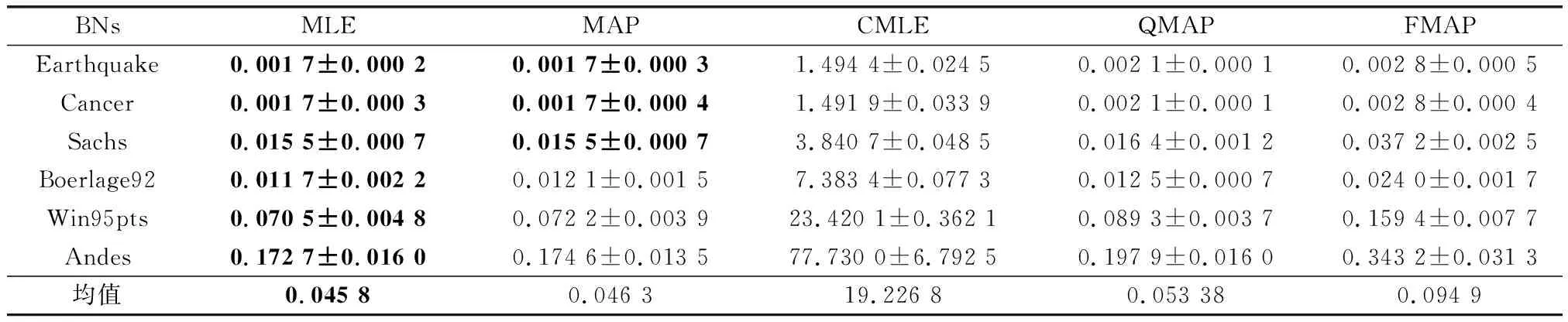
表9 100样本量下各算法运行时间
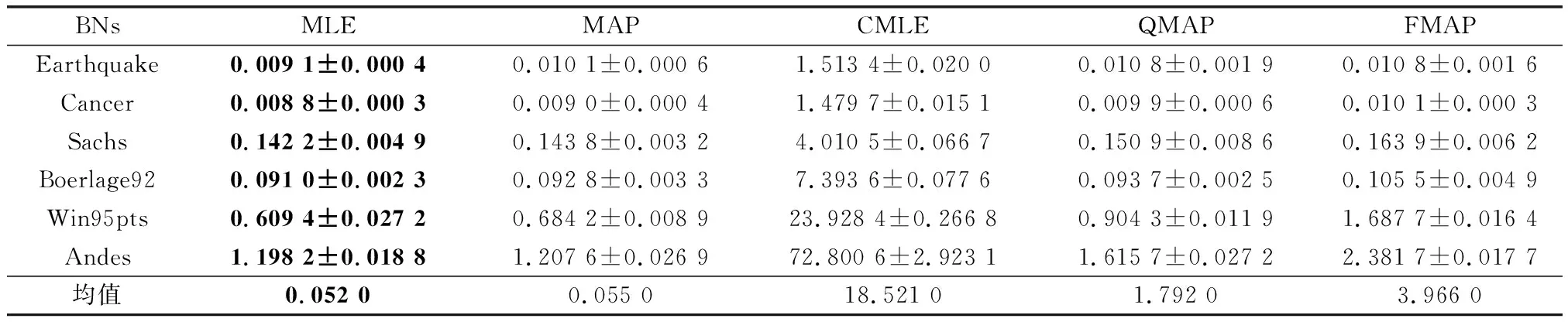
表10 500样本量下各算法运行时间
4 基于FMAP的网络安全评估
4.1 基于FMAP的网络安全评估方法
BN在网络安全领域中的应用,主要是结合攻击图模型,进行网络安全预测评估。但由于待评估目标网络中历史数据获取困难,网络参数基本依靠专家经验来得到。参数主观性强,导致之后评估结果的客观性不足,如何获取更加客观准确的参数是目前网络安全评估领域所要解决的问题之一[29-31]。网络攻击主要通过漏洞来进行,但各种因素导致网络漏洞无法完全修复,从而为攻击的发生提供条件。网络的拓扑图可以认为是确定的BN结构,网络中的漏洞为BN中的节点,节点间的因果关系由物理连接所确定。
迁移学习[23]是将已得到的知识,应用到新的问题上,核心是找到已有知识和新问题之间的相似性。迁移学习可以分为基于样本的迁移、基于特征的迁移、基于模型的迁移,以及基于关系的迁移。本文使用的是样本迁移,将相同漏洞的数据迁移进行学习。BN攻击图中只考虑迁移样本和节点参数为Πi=1的情况,对于网络攻击图而言,Πi的特殊之处为任意父节点为1即可,即Πi节点状态或关系为1,并不考虑Πi=0的情况,即Πi所有节点状态与关系为0。若Hi为网络中的节点,对于P(Hi=0|Πi=1)和P(Hi=1|Πi=1)两者符合概率的公理约束,对节点的危险性预测仅对P(Hi=1|Πi=1)进行分析即可。
通常攻击者为达到攻击目的,一般需要通过对多个漏洞的连续利用,用已占有资源节点作为跳板,去占有其他资源,直到完成攻击目的形成攻击路径。因此,路径可达概率通常作为路径评估的标准,路径可达概率θPath计算方法如下所示:
θPath=P(H1)×P(H2|Π2)×…×P(Hi|Πi)×…×P(Hn|Πn)
(21)
4.2 案例验证分析
由于网络安全领域缺乏验证数据集,因此为了验证本文所提的安全评估方法,本文构建以归一化通用漏洞评分系统(common vulnerability scoring system, CVSS)[32]的评分为BN参数的仿真平台,来进行闭环验证。CVSS是权威的漏洞严重性评估系统,作为行业公开的评分标准,为网络安全评估的量化提供了一个开放的计算框架。CVSS将漏洞被利用的严重程度归于一个[0,10]数值区间,分值越高说明漏洞的危险程度越大。图3是一个BN攻击图,图中除H1和H17之外,每个节点代表网络中的漏洞,H1为攻击者的攻击发起节点,H17为攻击者最终要到达的目标节点。表11为图3中除初始节点和目标节点外,节点的漏洞信息表。表11中包括通用漏洞披露(common vulnerabilities & exposures, CVE) 标号、CVSS评分归一化近似约束。假设漏洞对于攻击者为可用状态时标记为1,不可用为0。P(H6=1|Π6=1)表示节点H6被“攻占”成功的概率,其中Π6=1表示节点H6的前序节点已经被“占领”,即H2或H3关系为1。
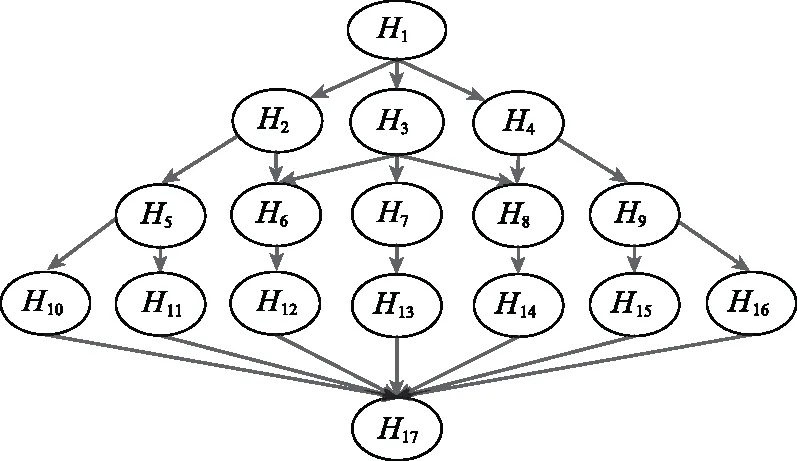
图3 BN攻击图Fig.3 BN attack diagram

表11 漏洞信息及约束
通过FMAP算法分别进行4个样本量下的学习,P(Hi=1|Πi=1)结果如表12和表13所示。
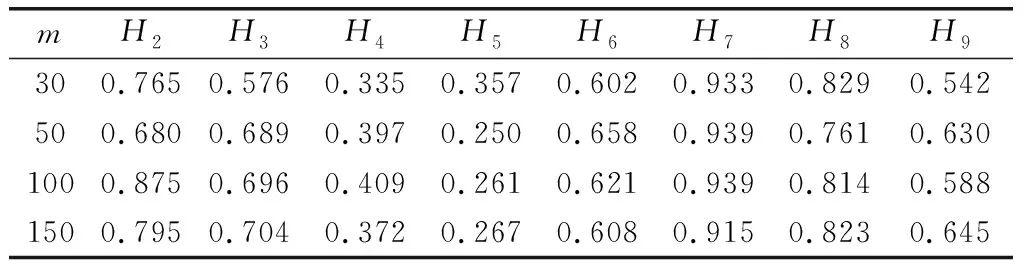
表12 节点H2~H9参数学习结果
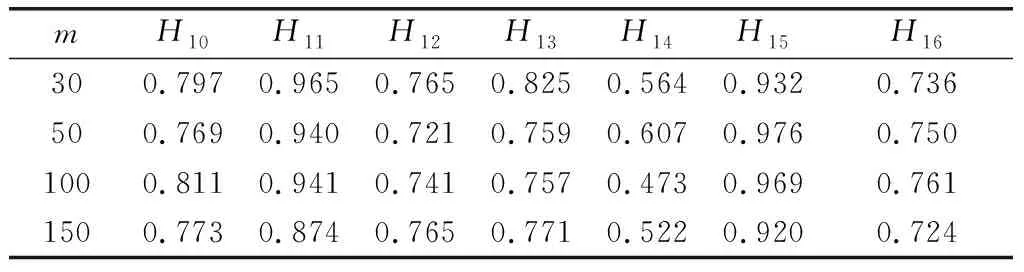
表13 节点H10~H16参数学习结果
由于网络中漏洞很多,在有限时间内,安全管理员难以完全处理每一个漏洞。因此,如果能有效地预测出高危节点,即P(Hi=1|Πi=1)最大的节点,将会为网络安全管理员提供有益的帮助。本文将各样本量下的P(Hi=1|Πi=1)学习结果进行排序,并和CVSS评分的前10节点对比,来验证学习结果的有效性。由表12和表13可以看出,在样本量为30时,预测正确率为90%,其他样本量下为100%。
路径可达概率是网络攻击预测重要参考指标,本文假设H17为网络中目标节点,攻击者可选择通过网络中不同的路径进行攻击从而到达目标节点,实现攻击目的。图4所示为9条路径分别在不同样本量下参数计算出的路径可达概率。可以看出,4个样本量评估出得分最高的5条路径结果和CVSS一致,在30样本量下的预测成功率为80%,而其他的样本量下完全一致,同时随着样本量的提高,评估结果和CVSS更加相近。

图4 网络路径可达概率Fig.4 Network path accessibility probability
5 结 论
本文提出一种基于模糊先验约束的BN参数学习方法,来解决小样本下BN参数学习问题。将隶属度函数和实际样本量引入到构造超参的构建中,从而平衡参数学习过程中的过拟合与欠拟合问题。实验证明,本文算法可以有效地提高参数学习结果的精度,并拥有杰出的鲁棒性。同时,将本文方法引入到网络安全评估中,将CVSS评分作为专家先验,利用漏洞编号迁移样本进行参数学习。本文算法虽然可以有效地提高小样本下参数学习的精度,但本文提出的模糊超参构建过程相对复杂,需要消耗更多的时间。
猜你喜欢
今日农业(2022年13期)2022-09-15 01:21:08
内蒙古统计(2021年4期)2021-12-06 02:49:20
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
测控技术(2018年4期)2018-11-25 09:46:52
上海精神医学(2017年5期)2017-11-29 06:03:10
自动化学报(2017年5期)2017-05-14 06:20:44
中国卫生(2016年5期)2016-11-12 13:25:28
儿童时代(2016年6期)2016-09-14 04:54:43
探测与控制学报(2015年4期)2015-12-15 15:00:56
中国卫生(2015年12期)2015-11-10 05:13:38
