
下车信息对公交乘客精细化分类影响研究
2023-01-29 12:26李军区静怡赵文婷
深圳大学学报(理工版) 2023年1期
李军,区静怡,赵文婷
中山大学智能工程学院,广东广州510006
随着移动支付方式的多样化发展,公共交通乘客数据得以有效记录,不同计费方式记录着不同的乘客数据[1].针对记录上下车数据开展的乘客分类已有充分研究,由于公交一票制中仅记录乘客的上车信息而不采集下车信息,相关乘客分类研究具有一定难度.因此,作为乘客分类研究的基础工作,评估下车信息缺失对乘客精细化分类的影响对使用一票制的公交部门分析乘客特征、提高服务水平至关重要.
乘客分类研究中,首先需要通过出行行为体现量化的乘客出行特征[2-3],因此,分类需要基于乘客的多维属性.其中,乘客的个人属性是主观分类的重要参考信息[4-9].乘客使用的卡片类型包含其个人社会信息,存在预先对乘客社会属性进行假设的情况.可通过采用客观分类避免乘客个人信息强主观性对分类结果的影响[10],如围绕出行规律、时间和空间规律等维度选取分类指标.指标选取应包含刻画出行规律的出行次数及出行天数[11-12]、刻画时间规律的首次出发时间及乘车耗时[12],以及刻画空间规律的乘车距离、出行起讫点(origindestination,OD)占比、站点相似性[13-14]、站点距离和出行距离阈值等指标[15-16];通勤特征识别研究结合上述维度提出高峰时段下的通勤稳定性和出行频率等指标[17-20].对于缺少下车信息的乘客分类,通常采用出行链匹配或站点吸引权的方法补全下车站点[21-22],推断率可达90%[16].然而,在长观察周期的乘客分类研究中,多次推断所累积的重复误差会降低数据补全的正确率,影响乘客分类效果,仅通过上车信息对乘客作出精准分类结果的有效性需进一步论证.
乘客分类算法是更深入的关键问题,其中,时空规律研究多采用k-means[23-24]或基于密度的噪声应用空间聚类(density-based spatial clustering of applications with noise,DBSCAN)算法[14];多类型指标研究采用二阶聚类算法[12];依托初始聚类中心的优选研究采用k-prototypes 聚类算法[13].然而,以上研究的乘客分类指标相差较大,且都针对包括上下车信息的数据集,其乘客类别数在5类以内,各研究侧重不同的乘客特征,尚无对全群体的精细化分类方法.
为探究下车信息缺失对公交一票制乘客分类的影响,本研究分别构建无下车信息的分类模型O和有下车信息的分类模型W,从各维度的客观因素中选取乘客分类的通用指标和替代指标,针对模型W补充附加指标,采用组合聚类算法精细挖掘乘客类别.选取中国北京市路面公交的大规模乘客上下车刷卡数据作为研究对象,基于所建立模型分析下车信息存在与否对公交乘客精细化分类的影响.研究结果可为精细化乘客行为分析、个性化公交服务政策和多层次公交需求预测提供决策参考.
1 分类模型构建
1.1 分类指标选取
从多维度客观属性提取乘客的乘车特征指标,具体分为出行规律、时间规律、空间规律及高峰规律.为探究有无下车信息对于乘客精细化客观分类效果的影响,基于上车信息选取分类指标组构建模型O,基于上下车信息选取分类指标组构建模型W.围绕模型W和O分别构建有无下车信息的2组分类指标,包含8 项两个模型共享的通用指标,4项两个模型对比的替代指标.此外,包含下车站点信息的模型W 在时间规律和空间规律通过下车信息补充3项附加指标.
1.1.1 通用指标构建
构建通用指标时主要考虑乘客上车信息所呈现的特性,可通过刷卡次数和刷卡时间反映乘客的相关行为特性.乘客的出行规律反映了其对公共交通的依赖性,出行时间和出行天数反映其使用公共交通的时间规律.以下从出行规律和时间规律维度提出适用于模型O 和W 的通用指标,见表1.其中,smax为日均出行次数最大值;ηmax为每周出行天数标准差最大值;σmax为日初次出行时间标准差最大值;下标k表示第k位乘客.
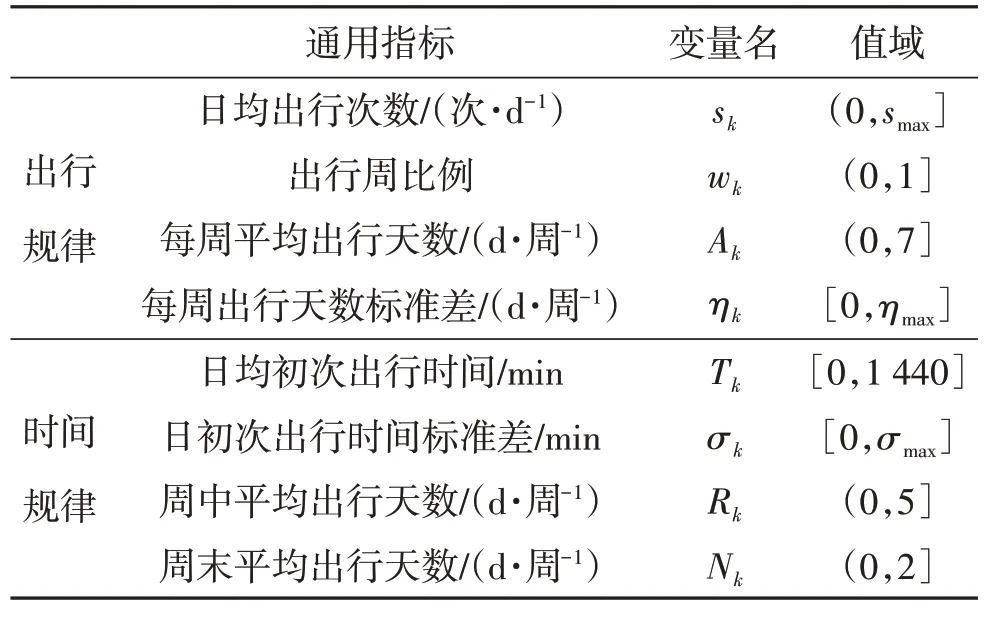
表1 模型O和模型W的通用指标Table 1 Shared classification indexes of transit riders between model O and model W
1.1.2 替代指标构建
由于一票制下的乘客数据通常包括上车信息,对下车信息的采集并不统一,不包含下车信息时难以刻画乘客出行的空间规律.选取出行日初次乘车和末次乘车的站点关联性揭示空间规律,选取周中工作日的早高峰和晚高峰时段初次乘车关联性刻画高峰规律.在空间规律和高峰规律维度下,针对模型O和W提出替代指标.
在替代指标中,针对模型O 和W 的数据差异,分别提出上车站点邻近度和常OD 对比例,刻画乘客多次出行的上车站点关联性和上下车站点关联性.定义指标范围为出行日初末次出行和周中工作日早晚高峰出行,分别表征乘客出行的空间规律和高峰规律.
上车站点邻近度表征乘客多次出行间的站点间距邻近程度和出行集中程度.乘客k的上车站点邻近度指标包括:日初次上车站点邻近度、日末次上车站点邻近度、周中早高峰初次上车站点邻近度和周中晚高峰初次上车站点邻近度
上车站点邻近度计算中,若乘客在目标范围内任意两个乘车站点间距在预设的判断值内,可视作乘客的出行站点选择集中.站点邻近度为


其中,X为目标指标范围,包括日初次出行F、日末次出行L、周中早高峰初次出行M和周中晚高峰初次出行E;为乘客k在目标指标范围X下的总出行天数(单位:d),且为乘客k在第i和j个目标指标范围内的站点间距(单位:m);为乘客k的站点间距判断0-1变量;ε为给定的站点间距判断值(单位:m).
常OD 对比例为乘客多次出行的OD 对,表征乘客出行起止点的专一性,其指标包括日初次出行常OD 对比例、日末次出行常OD 对比例、周中早高峰初次出行常OD对比例和周中晚高峰初次出行常OD对比例
常OD 对比例计算以出行的上车站点和下车站点作为1个OD对.乘客k在目标指标范围X下的总出行天数为,目标指标范围出行OD集合中出现频率最高的OD 对出现次数记为Ck,常OD 对比例计算为

当乘客k在X下的总出行天数为0 d 或1 d,上车站点邻近度和常OD 对比例指标需作额外标定,分别记为-2和-1.总出行天数>1 d时,上车站点邻近度和常OD 对比例指标取值范围为[0,1].因此,上车站点邻近度和常OD 对比例指标为分类型和数值型结合的组合型指标.
模型O和模型W中,乘客在空间规律和高峰规律下所选取的上车站点邻近度和常OD 对比例等对比分类指标见表2.

表2 模型O和模型W的对比指标Table 2 Subsitude classification indexes of transit riders between model O and model W
1.1.3 附加指标构建
针对模型O 和W 选取替代指标、模型W 选取附加指标,考虑到下车的时间和地点信息可呈现一定的乘客特征,有利于刻画乘客的日常活动时长和活动距离广度.因此,在时间规律和空间规律中围绕下车信息,针对性提出模型W 的附加指标,包括日均出行时长、日出行时长标准差及日均出行距离,如表3.其中,Hmax为日均出行时长最大值;θmax为日出行时长标准差最大值;Lmax为日均出行距离最大值.

表3 模型W的附加指标Table 3 Additional classification indexes of the transit rider in model W
1.2 乘客分类方法
1.2.1 指标筛选
为提高分类效率,降低计算冗余,在选取分类指标后,需对已有指标进行相关性分析.考虑到模型的输入指标包含数值型和组合型指标,采用斯皮尔曼相关性系数进行计算筛选.对于相关性系数落在[-0.6,0.6]以外的指标对,可认为其相关性较强,予以剔除.
1.2.2 组合聚类
为深入挖掘乘客在不同维度下的规律与特征,考虑到同时存在组合型指标和数值型指标,本研究采用二阶聚类和k-means 聚类相结合的方法,分别对模型O 和模型W 的乘客指标组进行精细化分类,具体步骤如下.
步骤1采用二阶聚类对乘客进行客观分类,采用聚类特征(clustering feature,CF)树提高聚类效率并根据贝叶斯信息准则(Bayesian information criterion,BIC)选取最优聚类数.由于空间规律和高峰规律下存在组合型指标,首先将该类组合型指标视为分类型,类型包括无出行、单日出行和多日出行.类别中心在该类指标的表现为单一类型时,视作表现清晰;反之则为非清晰.根据分类型指标表现的一致性与否,将乘客划分为清晰组乘客和非清晰组乘客.
步骤2对在空间规律和高峰规律下清晰度不明的非清晰组乘客类别应用二次二阶聚类,并同样选取CF树和BIC,得到细化类别;对在空间规律和高峰规律下的清晰组乘客类别应用k-means 聚类(k=2,3,4,…,10),并计算不同k值下的聚类误差平方和作为k值选取参考,选取误差平方和变化幅度大的点作为k值.
2 案例分析
2.1 案例概况
中国北京市的路面公交采取分段计费制,通过自动售检票系统(automatic fare collection,AFC)进行数据采集,票务信息包括乘客出行的上下车时空数据.选取2018-04-02 至2018-04-29 的4 个完整且连续的星期作为研究周期.将数据中存在的数据空值、重复记录和不合理数据予以清洗.在经过刷卡数据清洗和空间信息匹配后,采取等比例分层抽样方法,选取周期内乘客票务数据共27 192 981 条,包含付费乘客共2 245 561 位.票务数据包括乘客身份标识号(identity document,ID)、上车时间及站点、下车时间及站点、线路编号等,采用数据库管理系统Structured Query Language Sever(SQL Server)进行存储管理,作为乘客分类模型的数据应用基础.
2.2 乘客分类结果
结合乘客票务数据,计算乘客在各模型指标组下的表现,利用SPSS 软件工具予以分析分类指标的相关性.考虑到北京市面积辽阔,为了尽可能覆盖相邻站点,并保证公交站点服务半径500 m覆盖90%人口的要求,指标计算过程中将站点间距判断值取1 000 m,分别以06∶00—10∶00和17∶00—21∶00作为早晚高峰时段.
进行斯皮尔曼相关性分析并经过指标筛选后剔除冗余指标.其中,模型O指标中,剔除乘车周数和周均乘车天数;模型W指标中,剔除乘车周数、周均乘车天数及日乘车时长标准差.模型O 和W中,各分类指标间的相关系数见图1,以颜色深浅表示相关系数大小.

图1 (a)模型O和(b)模型W的指标相关系数Fig.1 Correlation coefficients of(a)model O and(b)model W.
分类过程中,模型O 和W 分别输入10 项和12项分类指标后,对数据集进行聚类处理.先采用二阶聚类对目标乘客进行客观分类,得到多类规律清晰的乘客和规律较不清晰的乘客.将清晰度较低的非清晰组乘客类别统一应用二次二阶聚类,得到细化分类;对清晰组乘客类别应用k-means 聚类,选取聚类误差平方和下降幅度变化最大值作为k值.聚类后模型O采用缺少下车信息的数据集,可将乘客分为10类.模型W采用包含下车信息的数据集,可将乘客分为12类.
分析模型O和W下的乘客分类情况,可将出行规律初步分为高频用户、中频用户和低频用户.其中,模型O下的高频、中频和低频用户又可各自细分为4 类、3 类和3 类,共计10 类;模型W 下的高频、中频和低频用户可各细分为4类,共计12类.
各类别乘客的分类特征中,以类别的聚类中心表现对类别特征进行描述.其中,出行规律分为高频、中频和低频,分别对应日均乘车次数sk≥1.7,1.5 ≤sk<1.7 及sk<1.5.时间规律分为晨、早、午、午后和晚,分别对应日均初次出行时间08∶00前、08∶00—10∶00、10∶00—12∶00、12∶00—16∶00及16∶00后.模型W中的日均出行距离以短距、中距与长距表征,分别对应日均出行距离[0,20)、[20,60)和[60,∞]km.以是否存在空间规律和高峰规律表征乘客在这两项规律下的表现.表4为模型O和W的乘客分类特征及其占比.

表4 模型O和模型W的乘客分类特征及其占比Table 4 Passenger classification results by model O and model W
2.3 分类效果讨论
乘客分类中包含高频用户、中频用户和低频用户,其中,高频用户在各维度的分类指标均有表现,类别聚类中心的出行规律更明显.本研究以高频用户为例,分析模型W的小样本乘客分类原因,探讨模型W 中下车信息对于乘客分类的影响,并通过雷达图分析模型O 和W 在分类区分度方面的表现.
不含下车信息的模型O和包含下车信息的模型W 中各类高频乘客在各指标下的聚类中心见表5.由表5可见,相较于模型O,模型W在分类时包括含下车信息的2项附加指标.为探究两种模型的分类结果差异是否由附加指标引起,分别分析模型W中仅隐去日均乘车时长和仅隐去日均乘车距离的分类情况差异.在模型W 的分类变量中仅隐去日均出行时长并经过再次聚类,高频用户分类结果与原模型W 的分类结果较为接近,仅0.01%的乘客类别发生变动;而仅隐去日均出行距离再次聚类后,高频用户分类结果与原模型W 的分类结果产生较大差异,引起65.36%的乘客类别变动,而与模型O 的分类效果十分接近,乘客相同类别重复率为98.80%.由此可见,乘客的日均出行距离是模型W与O在分类结果中产生差异的重要指标.

表5 模型O和模型W中高频用户的聚类中心Table 5 Clustering centers of high-frequency transit riders by model O and model W
高频用户中,模型W 的乘客各类别占比相差较大,由表4 可见,类别1 和类别4 的乘客占比仅0.25%和1.33%.对其聚类中心分析可见,由于北京市跨区公交出行行为高发,这部分乘客的日均乘车距离远高于其他2个类别的高频乘客,此指标取值的强差异性使样本量极低的乘客在聚类中被识别.而模型O中高频乘客分类占比相对均衡,类别平均占比标准差相对模型W 仅占30.76%,模型O中类别最高占比(20.86%)是最低占比(3.36%)的6.21 倍,而模型W 中类别最高占比(20.86%)是类别最低占比(0.25%)的83.44 倍.模型O 中高频用户的4个类别中,均有较大比例的乘客可在模型W中被分至出行距离更短的类别3中,而模型W的高频用户各个类别在模型O中分布相对均匀,两个模型的乘客分类结果仅有34.45%维持一致.图2 给出模型O和W中各高频用户类别在模型W和O中的高频乘客数占比情况,横坐标O-1表示模型O中的类型1乘客,其余同理.
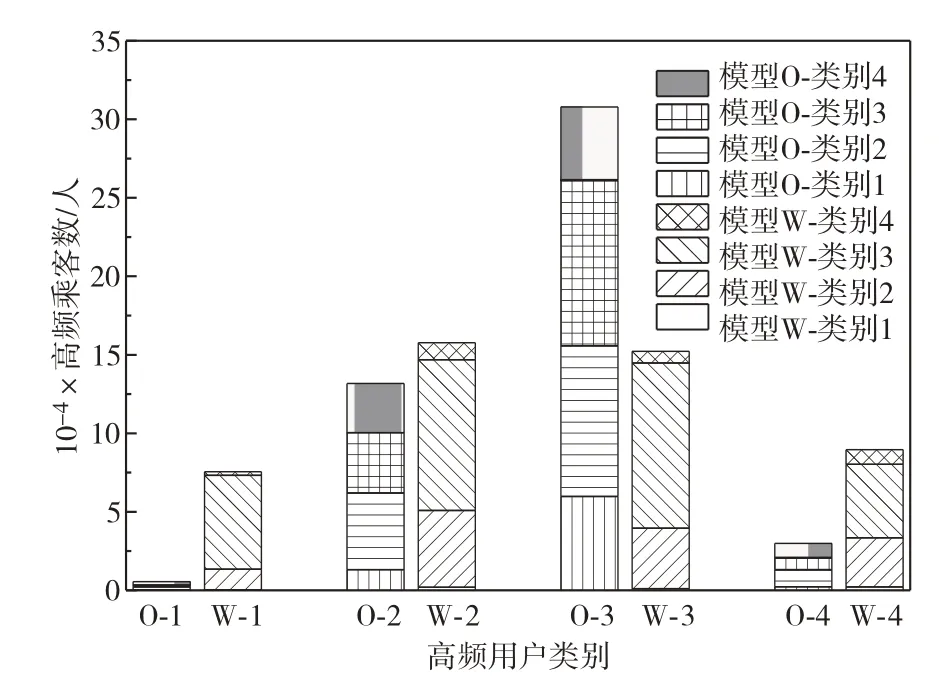
图2 高频用户中模型O和模型W的类别和占比情况Fig.2 Clustering results of high-frequency transit riders by categories of model O and model W.
提取高频用户中各类别乘客在出行规律、时间规律、空间规律及高峰规律的聚类中心表现并进行标准化处理,同时选取初次出行时间作为补充表现,各类别的聚类中心表现通过雷达图进行可视化.图3为模型O和模型W的高频用户类别聚类中心.可见,基于模型O 和W 的高频用户在出行规律、时间规律、初次出行时间、空间规律和高峰规律上均表现出较强的出行特性.模型W 中包含下车信息,加入了出行时长和距离指标,各类别间仅在出行规律上具有强差异性,更能有效区分特殊群体,如长距离出行乘客,但在时间规律、空间规律和高峰规律等维度上的区分度不及模型O.

图3 模型O和模型W的高频用户类别聚类中心(a)至(d)分别为用户类别1至类别4Fig.3 Clustering center of high-frequency transit riders by(a)category 1,(b)category 2,(c)category 3 and(d)category 4 of model O(black rectangular)and model W(grey triangular).
因此,加入下车信息的模型W 虽然在小样本群体识别上具有一定优势,但是长距离出行等特殊群体在全群体中的比例较小,影响其他群体的人数分布及挖掘区分.模型O中不考虑下车信息的乘客分类分布较为均等,本研究提出的空间规律和高峰规律指标可有效呈现乘客规律;在时间规律、空间规律和高峰规律等维度上,各类别具有显著强差异性,能有效区分不同群体乘客在各维度上的特性.此案例有效验证了在仅采用上车信息等数据的情况下,模型O可实现对乘客的精细化分类.
结语
为研究下车信息缺失对公交乘客分类的影响,利用公交数据特征,从多维度构建无下车信息模型O与有下车信息模型W的分类指标组,包含通用指标、替代指标和附加指标.根据模型O和W的乘客分类指标体系,采用组合聚类并分别从2种数据集对乘客分类进行精细化挖掘.北京市公交因其采用分段计费而采集下车信息,成为挖掘有无下车信息对乘客精细化分类影响的理想对象.以北京市2018年4月中28 d的分段计费制公交用户刷卡数据作为研究对象,分别以隐藏及包含下车信息的数据作为模型O和W的数据集,通过分类指标体系进行乘客精细化分类并进行对比研究.
结果表明,①针对有无下车信息数据所构建的分类指标组可有效刻画乘客多个维度的出行特性,结合两种聚类方法的乘客分类模型在有无下车信息的情况下均可实现乘客的精细化分类;②应用包含下车信息的模型,乘客分类在各类别的比例及乘客出行距离上具有较大差异,小样本的长距离出行乘客群体易于被挖掘得到,类别间的乘客出行规律特征差异更明显;③应用缺少下车信息的模型,其分类结果占比相对均衡,在时间规律、空间规律和高峰规律上均在类别间呈现出显著的强差异性,分类效果更体现宏观特征.
因此,包含下车信息的乘客分类模型能识别低占比的小样本群体,缺少下车信息的乘客分类模型则在乘客特征差异性上表现更优.对于广泛采用公交一票制的城市,在不采集下车信息的情况下,直接利用票务信息对公交乘客进行分类,也可获得全面宏观的分类效果,为乘客行为分析、公交服务优化及公交需求预测等提供参考.后续研究可考虑以多个不同规模的城市公交作为研究案例,并以多源数据拓展数据集,改进分类方法与聚类模型,在乘客分类的基础上探究乘车数据生成.
猜你喜欢
今日农业(2021年8期)2021-07-28
书香两岸(2020年3期)2020-06-29
电子制作(2019年14期)2019-08-20
国际呼吸杂志(2019年1期)2019-01-28
民族古籍研究(2018年1期)2018-05-21
中国自行车(2017年1期)2017-04-16
故事会(2016年21期)2016-11-10
卫星与网络(2016年12期)2016-02-05
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
