
注意力残差密集网络的单幅图像去雾算法
2023-01-19 09:52黄小芬林丽群
福建师范大学学报(自然科学版) 2023年1期
黄小芬,林丽群,卢 宇
(1.福建师范大学协和学院信息技术系,福建 福州 350117;2.福州大学物理与信息工程学院,福建 福州 350108)
雾霾天气导致的室外图像模糊、对比度差,直接影响高级计算机视觉的应用性能,因此,需要用一些算法对这些低质量图像进行去雾处理,提高计算机视觉应用系统的可用性和安全性[1].
近年来,单幅图像的去雾算法主要集中在图像增强、图像复原[2]和深度学习3类.其中,图像增强的去雾方法提高了图像的对比度,却没有考虑成像机理,处理后的图像往往会丢失一些原始图像的细节.以大气散射模型为基础的图像复原的去雾算法通常要利用先验知识.大气散射模型可表示为:
I(x)=J(x)t(x)+A[1-t(x)],
(1)
t(x)=e-βd(x),
(2)
其中,I(x)是雾图图像;A为全球大气光;J(x)是无雾图像;t(x)为透射率;x为该像素在图像中的位置;β是大气散射系数;d(x)为场景深度.
由式(1)和式(2)可知,如果能得到合适的透射率和大气光,雾图图像可以恢复为无雾图像.传统的方法主要采用先验方法估算大气光.如He等[3]的暗通道先验DCP(dark channel prior)算法.该方法在某些情况下可以得到很好的结果,但当实际情况与估计情况相反时,透射率的估计不准确,会导致去雾效果不理想,经常会出现色彩失真等问题.
近年,卷积神经网络CNN(convolutional neural network)被科研人员广泛研究并用在图像复原去雾方法中进行估算透射率和大气光.例如,Cai等[4]提出了DehazeNet,借助卷积神经网络估计透射率;Li等[5]提出的AOD-Net(all-in-one dehazing network)将透射率图和大气光转换为一个统一的变量K,通过CNN直接生成无雾图像.CNN 的应用极大地促进了图像去雾技术的发展.但基于物理模型的神经网络方法高度依赖透射率和大气光,如果这2个参数估计不准确,输出结果将受到很大影响.
也有一些学者将图像去雾过程视为图像转换问题,提出了一些端到端的CNN图像去雾算法.如Ren等[6]基于融合的编码器-解码器结构,设计了多尺度门控融合的端到端网络GFN(gated fusion network),无需估计透射率和大气光就能直接恢复清晰图像.Dong等[7]提出了一种基于U-Net架构的使用反投影反馈方案的密集特征融合模块的多尺度去雾网络MSBDN(multi-scale boosted dehazing network).上述方法虽然避免了大气物理模型,但大多采用了通用的网络体系结构,没有进一步优化网络架构.因此,输出图像经常会出现细节模糊、细节丢失的现象.
针对上述问题,本文提出一种端到端的多模块结合的深度网络,通过融合多个不同尺度的特征图提高捕获输入雾图信息的能力,利用残差提高图像特征表示能力,使用残差密集连接块RDB (residual dense block)提取图像特征,引入注意力机制融合特征图.
1 本文方法
为了解决现有去雾方法去雾结果色彩失真、细节模糊、细节丢失等问题,本文提出一种端到端的深度网络,无需估计大气光和透射率,直接由输入雾图恢复出无雾图像.
输入雾图首先经一个可训练的预处理模块生成输入图像的16张变体特征图.现有手工选择的预处理方法[6]通常旨在增强图像域视觉上可识别的某些具体特征,实际上,可能存在比图像域更适合后续操作的抽象变换域.本文提出的预处理模块是完全可训练的,一个可训练的预处理模块可以自由地识别变换域,利用更多的分集增益,以提供更灵活、更有针对性的图像增强.此外,可训练的预处理模块可以提高特征泛化能力和潜在关键特征的识别速度.如图1所示,预处理模块输出的特征图也可以通过上采样和下采样单元相互连接,形成行和列.通过这些连接,来自低尺度和高尺度的信息可以相互共享,高尺度流可以与低尺度流并行工作,低尺度流在更宽的感受野中携带更多的上下文信息.受Chen等[8]的启发,引入了一种通道注意力机制来消除雾图上的雾霾.为了实现更多的信息交互,通过注意力机制对不同尺度的特征图进行融合.该机制的优点是可以增强模型在特征融合中从不同尺度调整权重的能力.
1.1 网络结构
去雾网络架构如图1所示.它由3个模块组成:预处理模块(左边pre-processing方块)、密集注意力模块(中间dense attention module方块)和后处理模块(右边post-processing方块).
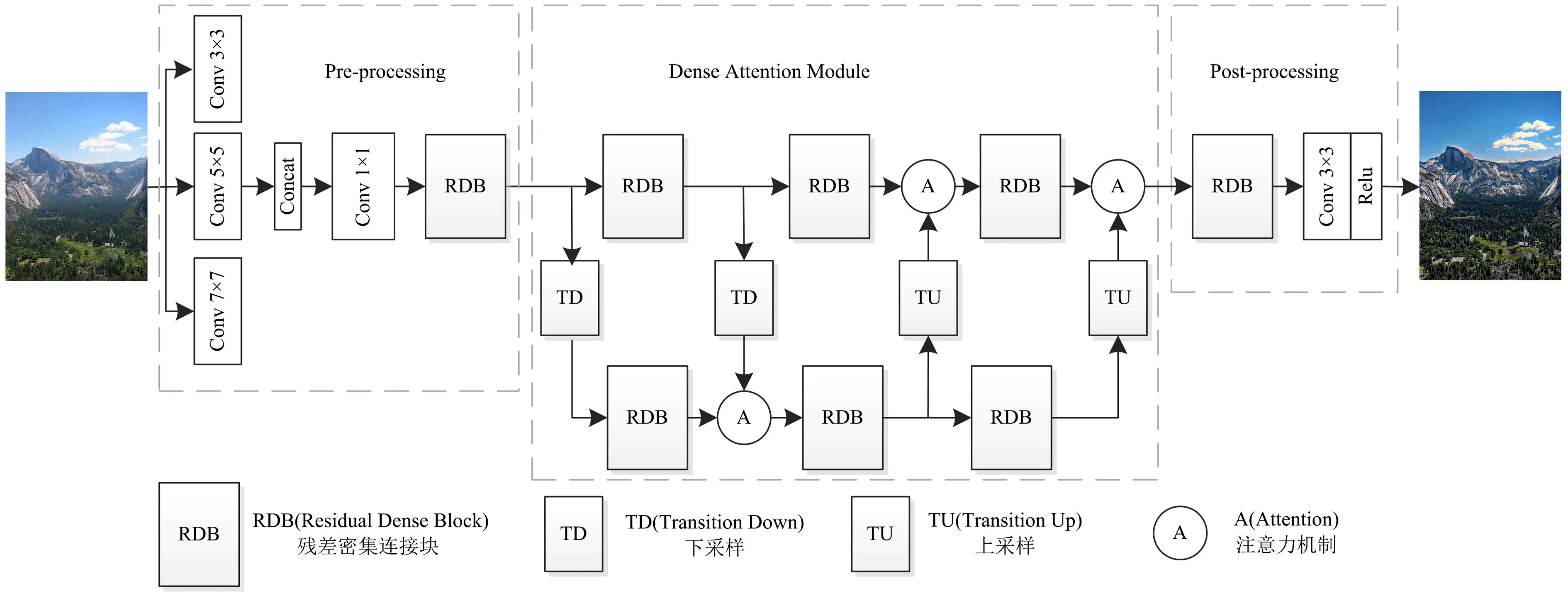
图1 去雾网络结构图Fig.1 Structure diagram of defogging network
在预处理模块利用多尺度卷积来提取模糊图像的特征,进行拼接融合,再经过一个1×1的卷积层将特征图的数量降为16,最后经过RDB块生成16个不同的特征图,经网络浅层获取输入雾图的有效特征,作为密集注意力模块的特征学习输入.
受Wang等[9]的启发,主干密集注意力模块网络采用网格网络结构.网格网络相对于编解码网络和广泛用于图像恢复的传统多尺度网络具有明显的优势[6-7].它通过采用上采样、下采样块跨不同尺度的密集连接,解决了编解码网络或传统的多尺度网络由于层次化结构引起的瓶颈效应问题.密集注意力模块基于预处理模块生成的特征图进行特征提取与融合,它由2行4列构成,每一行对应不同的特征图尺度大小,由3个RDB块组成.第一行感受野小,主要提取局部特征.为了提取全局特征,通过2次下采样得到2个全局分支,扩展了感受野.具体来说,在每次上采样TU(transition up)或下采样TD(transition down)中,特征图(通道)的数量减少或增加2倍,而特征图的大小增加或减少相同的倍数,每一列都保证了不同尺度之间的有效信息交换.详细的TD及TU结构如图2所示.为了有效地融合这些局部和全局特征,提出一种视觉注意力机制特征融合方法,如2.2节.经过多次特征融合后,从2个分支提取的最终特征覆盖了丰富的颜色、结构和雾霾信息,可以有效缓解过度去雾和颜色失真.一个RDB由4个卷积层组成,前3个含批标准化(batch normalization,BN)和激活函数Relu的卷积层用于增加特征图的数量,经级联融合操作后再经过一个1×1的卷积层融合这些特征图,同时将要输出的特征图数量降低至与RDB输入一样的数量,减少信息冗余[10].后处理模块由1个RDB和1个带Relu的卷积层构成,可以对去雾后的图像进行细化,去除残余伪影,提高输出图像的视觉质量.

图2 TD和TU模块的详细结构图Fig.2 Detailed structural drawings of TD and TU modules
1.2 通道注意力机制
鉴于不同通道对最终去雾结果的影响是完全不同的,为了有效融合不同通道、不同尺度上的特征,受Li等[11]的启发,提出一种生成可训练权值的特征融合方法即通道注意力机制融合方法.权重生成实现2个可训练参数对2个尺度的局部和全局特征进行权重计算.因此,在每个通道中,有效地将有用信息(如颜色、纹理、雾密度等)组合成一张特征图.文中采用权值求和方法,既降低了模型运算量,又很好地融合了水平方向和垂直方向的残差特性.最终输出可以表示为:
(3)
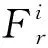
1.3 损失函数
已有研究表明[12],结合SSIM损失和像素损失可以显著提高恢复图像的质量.因此,本文提出将像素到像素的欧几里得损失、SSIM损失和感知损失相结合,构建去雾网络的总损失函数.欧几里得距离用来测量两样本数值的差距,距离越大样本区别越大;距离越小样本间的相似程度越高,并且在不同的表示域变换后特征性质保持不变[13].因此,欧几里得损失用于保持去雾图像的自然度.感知损失用于增强生成图像的对比度,SSIM损失用于保持去雾图像的结构.给定带有c通道、宽度为W、高度为H的图像对{x,y},x是输入雾图,y是对应的无雾清晰图,LE表示估计残差分量的逐像素欧几里得损失.表示为:
(4)
其中φ(x)是产生去雾输出的已训练网络.SSIM损失[12]在图像恢复任务中被广泛采用,它结合了结构、对比度和亮度来估计两幅图像之间的差异.因此,本文提出将SSIM损失作为另一个可微损失函数来生成更美观的图像.SSIM损失函数定义为:
LS=SSIM(φ(x)-y),
(5)
此外,感知损失[14]已经被证明比深度学习中使用的逐像素损失有更好的视觉性能.定义为:
(6)
其中V为非线性神经网络变换,采用预训练的VGG16权重来计算特征损失,以达到最小化高层特征图之间的距离.最终的损失函数可表示为:
Lloss=LS+LE+λLP,
(7)
其中λ是一个用于调整感知损失组件的相对权重的参数.经实验测试,文中将λ设置为0.02.
2 实验结果与分析
2.1 实验设置
由于从真实世界中很难获得无雾和带雾的图像对.实验中,采用一个大规模合成数据集Reside[6]进行模型的训练和测试.Reside数据集包括室内和室外场景的图像,其中室内训练集(ITS)包括1 399张无雾图像,每张无雾图用式(1)、式(2)的大气散射模型取散射系数β∈[0.6,1.8]和大气光值A∈[0.7,1.0]合成10张雾图,形成13 990张模糊室内图像.并选取室外训练集(OTS)10 000张模糊雾图,共23 990张雾图进行训练.采用综合合成测试集(SOTS)进行测试,由500张室内模糊图像和500张室外模糊图像组成.另外收集了100张真实世界雾图进行测试.
本文算法基于pytorch框架实现模型,所有实验(训练/测试)均在一台带有11 GB的 GPU显存的NVIDIA GeForce RTX 2080Ti服务器上进行.实验中,模型训练的图像大小为256×256,训练100轮次.在每个轮次(epoch)中,迭代次数设置为200次,总迭代次数为20 000次.算法训练过程使用Adam[15]进行网络优化,采用其默认设置:beta1 = 0.9,beta2 = 0.999,epsilon = 10-8.网络的初始学习率设置为0.001,每10个轮次学习率降低1/4,共训练100轮次.当训练结束时,模型的损失函数降至0.000 5,得到了很好的收敛指标.
2.2 实验对比
本节介绍算法在合成和真实数据集的实验细节和评估结果.对合成数据集,因为有雾图和无雾图的图像对,采用有参考评估指标:峰值信噪比PSNR(peak signal-to-noise ratio)和结构相似度指数SSIM(structural similarity index)来评价算法的去雾性能.对真实图像数据集,由于不存在真实无雾图像与其雾图的图像对,所以采用通过直观视觉评估及盲评价指标的信息熵H评估.将本文所提算法与以下最经典和效果较好的方法进行比较:He[3]的DCP、Cai[4]的DehazeNet、Ren[6]的GFN、刘广洲[10]的密集连接扩张卷积神经网络.
2.2.1 合成数据集
从合成测试集(SOTS)的室内(Indoor)和室外(Outdoor)测试集选择比较典型的样本,包括Indoor测试集中色彩比较明亮的偏红色系和偏橘色系及色彩偏暗的室内合成雾化测试图;Outdoor测试集中带有人物的色彩丰富的场景、前景与背景色差不大的及带有大片天空区域的室外合成雾化测试图.各种方法去雾结果对比图如图3所示,对于合成数据集He的DCP方法对图3(1)、图3(3)和图3(6)的去雾结果色彩增强过甚出现色彩失真,而对图3(2)、图3(4)和图3(5)的处理结果图像偏暗;Cai的DehazeNet方法在多个合成雾图的去雾结果图中都存在去雾不彻底的问题;Ren的GFN方法、刘广洲的密集连接扩张卷积神经网络都能较好地去除雾霾,但还是存在细节模糊、细节丢失等问题;相比较而言,本文所提方法能够保留更多细节,视觉上色彩与清晰度和原始无雾图像最接近.
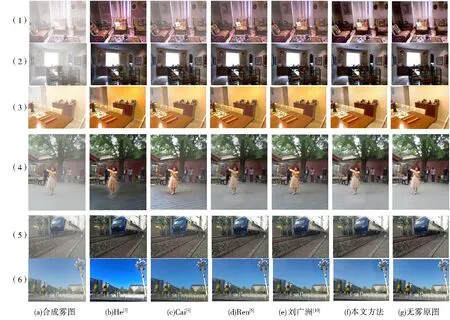
图3 合成数据集去雾结果对比Fig.3 Comparison of defogged results on the synthetic dataset
为了验证本文所提算法的有效性,除了主观评价,另外文中参考了基于深度学习算法的其他文献[4,6,10],接着从客观评价指标PSNR和SSIM来比较各种方法的去雾性能.表1为各方法在合成测试集SOTS上的PSNR和SSIM指标的结果平均值.
由表1可见,本文方法相比现阶段其他效果较好的去雾方法指标最优.其中,PSNR值在Indoor、Outdoor两个测试集的平均值分别达到30.38和30.08;SSIM平均值也分别达到比较方法中的最好结果:0.973 2和0.980 5.

表1 合成数据集上去雾结果的平均PSNR和SSIM值Tab.1 Average PSNR and SSIM values of defogged results on the synthetic dataset
2.2.2 真实数据集
对于真实雾图,由于没有可比较的雾图与无雾图像的图像对,所以采用主观评估及盲评价指标的信息熵H进行评价.信息熵表示去雾图像所包含的信息量,熵越大表示算法的去雾效果越好.现从100幅真实世界雾图中随机选择3幅进行测试,各算法在真实图像数据集的去雾结果对比图如图4所示.
由图4可知,He的DCP去雾方法中图4(1)前景模特的皮肤从白色变成了红棕色,产生了比较大的颜色失真,图4(3)石制材料建筑的部分色彩被增强,且其去雾图像整体偏暗;与传统的DCP方法比较Cai的DehazeNet方法基本克服了颜色失真,但依然存在去雾不彻底问题,如图4(2)仍存在淡淡的雾,且整幅图清晰度一样,没有了景深的感觉,图像不够真实;Ren的GFN方法去雾效果整体较好,但也存在对比度过增强等问题,如图4(3)的石制建筑部分,且其色彩不够自然,存在色彩失真;刘广洲的密集连接扩张卷积神经网络的个别结果(如图4(3))去雾不够彻底;相比较而言,本文方法去雾结果比较自然,清晰度也好.

图4 真实图像各算法去雾结果对比Fig.4 Comparison of defogged results of different methods on real-world images
接着进一步用信息熵H对各算法进行评估.上述3幅图的去雾结果信息熵比较见表2.
由表2分析可知,Cai的DehazeNet在3张样例图像的去雾结果图的其中两个信息熵值都是最小的,表明DehazeNet网络的去雾性能对真实图像的去雾性能在所给比较方法中是比较差的;Ren的GFN方法在3张样例都得到了最高的信息熵,表明其对真实图像的去雾性能表现良好;本文方法的全部3张图像的处理结果均获得接近最好性能的结果.总体而言,本文方法对真实数据集的去雾处理,不管是主观视觉感受还是客观指标都获得较好的性能.

表2 真实数据集去雾结果的信息熵HTab.2 Entropy H of defogged results on real dataset
3 消融实验
为了验证各模块网络的有效性,本文通过消减网络各组成部分,形成不同网络变体结构来进行消融实验.如图1,本文提出的分模块去雾网络结构包括了3个核心模块,即预处理模块、密集注意力模块和后处理模块.第一,网络模型消减了基于注意力机制的通道特征融合;第二,网络消减了后处理模块;第三,网络消减了感知损失.这3个变体结构网络按之前的方式进行训练,并在相同的数据集上进行测试,测试结果如表3所示.实验结果表明,每个部分对整个网络模型的性能都有自己的贡献,证明了本文整体设计的有效性.

表3 去雾网络消融实验结果Tab.3 Results of ablation experiment
4 结束语
本文提出了一种新的用于单幅图像去雾的端到端的深度卷积神经网络.该网络采用模块化的设计思想增强去雾网络的鲁棒性和通用性.利用多尺度卷积获取输入雾图的更多重要特征,将残差密集网络结合注意力机制,实现了更多的图像上下文信息交互.利用视觉注意力机制有效融合特征信息,提高泛化能力.实验结果表明本文方法可以有效去除不同条件下图像中的雾霾,生成更清晰、自然的无雾图像.在合成数据集上的性能优于其他对比的先进方法,去雾的结果图像更接近原始无雾图像,在真实数据集上性能良好,色彩自然,但还有一定的性能提升空间,这是下一步研究的重点.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
时代英语·高三(2014年5期)2014-08-26
