
基于改进EfficientNet的雷达信号调制方式识别*
2023-01-18 02:55苏琮智王美玲杨承志吴宏超
电讯技术 2023年1期
苏琮智,王美玲,杨承志,吴宏超
(空军航空大学 航空作战勤务学院,长春 130022)
0 引 言
近年来,深度学习算法在雷达辐射源信号识别领域获得了广泛应用,卷积神经网络(Convolutional Neural Network,CNN)是最经典的模型之一。CNN利用权值共享、局部感知的思想大大降低了网络的复杂度和计算成本,可以高效地处理多维图像,特别是在二维图像处理上优势巨大[1]。因此,可以直接将对雷达辐射源信号进行一定的变换后提取到的二维图像输入CNN网络,网络将自动提取雷达辐射源信号的深层隐藏特征并进行分类识别。
当训练数据充足时,利用深度学习进行雷达辐射源识别可以达到较高的正确率并具有较强的鲁棒性,相比传统的算法有较大的提升,但同时也存在不足之处:在低信噪比下网络提取深层次特征更加困难,对辐射源的识别准确率还有待提高;许多用于识别的神经网络网络层数较深、参数过多,网络的时间复杂度和空间复杂度较大,因此训练速度慢、计算量庞大。
EfficientNet[2]是用一种新的模型缩放方法构建的网络,相比以前的卷积神经网络在准确性和效率方面更优秀。本文以EfficientNet-B0为基础框架,通过使用卷积注意力模块(Convolutional Block Attention Module,CBAM)替换压缩和激励(Squeeze and Excitation,SE)模块改进网络中的移动倒置瓶颈卷积(Mobile inverted Bottleneck Convolution,MBConv)模块,增强了网络提取多种特征的能力;分析了ReLU和h-Swish相比于Swish激活函数的优势,在网络不同深度使用不同的激活函数以兼顾网络的训练速度和识别精度,添加了标签平滑机制并对时频图进行CutMix数据增强,防止网络产生过拟合,能够对9种不同调制信号进行有效识别,整体平均识别率达到了99.25%。
1 雷达辐射源信号处理
1.1 Choi-Williams分布
时频分析方法结合分析非平稳信号的时域和频域两个维度,可以直接反映信号在这两个维度的映射关系,从而得到信号的相关调制信息,能够更加直观地分析和处理信号。Choi-Williams分布(Choi-Williams Distribution,CWD)[3]是一种典型的二次型时频分布,可以有效抑制交叉项,也能保持良好的时频分辨率。
本文采用CWD对辐射源信号进行时频变换获取时频图,其核函数是指数核函数,即
(1)
式中:v表示频偏;τ表示时移。由核函数得到CWD的数学表达式为
(2)
式中:t表示时间变量;ω表示角频率变量;s(u)表示时间信号;*表示复数共轭;σ表示衰减系数,通常设置σ∈[0.1,10],选择合适的数值能够增强时频性能。
1.2 CutMix数据增强学习
CutMix[4]是一种数据增强策略,具体做法是通过对训练图像A进行剪切和粘贴补丁,将一部分区域剪切但不像Cutout[5]方法填充0像素,而是随机选择训练集中的另一张B图像,并以B图像的区域像素值对A图剪裁区域进行填充,其中真实标签的混合与补丁的面积成正比,即两个样本随机加权求和,样本的标签对应加权求和。
图1所示为CutMix方法处理效果。
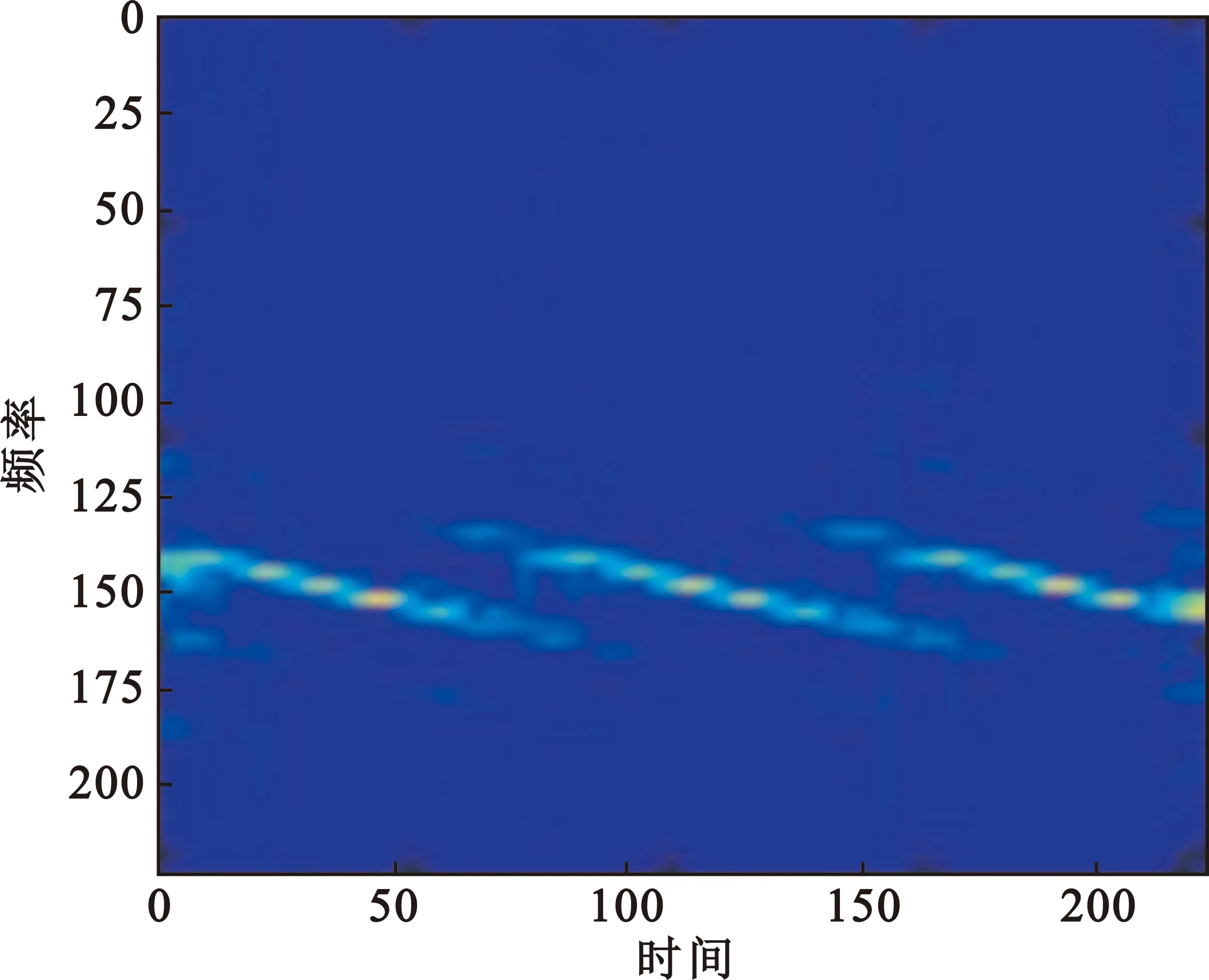
(a)处理前
在对图像做归一化处理以后,在训练集中抽选出的一张调制方式为P2的CWD时频图a,其未经过CutMix方法处理,然后随机选取样本中另一张图像截取对应的剪裁区域对a图剪裁区域进行填充得到b图,随机选取的是一张调制方式为2FSK的图像,可以明显看出b图中的“补丁”,使用该方法时“补丁”面积大小随机生成。
该方法对比于其他数据增强方法如Cutout和Mixup training[6],Cutmix相当于更换某个零件,模型更容易区分样本中的异类,能够增强网络学习局部特征从而增强模型泛化能力,提高训练效率,并且能够保持训练代价不变。
2 基于EfficientNet的改进
2.1 基础网络EfficientNetB0网络
卷积神经网络通常通过增加深度、宽度和图像分辨率中的一个来获得更高的精度,然而这一般也意味这消耗更多资源。EfficientNet提出了一种原则性的复合缩放方法即使用一组固定的缩放系数来均匀地缩放网络的宽度、深度和分辨率来扩大网络的规模,使用一个新的baseline网络并扩展获得EfficientNetB0-B7系列网络,最简单的B0网络的识别效果在ImageNet数据集上也超过了ResNet50、InceptionV2等网络,在5个常用的传输学习数据集上达到了最先进的精度,并且网络的参数拥有数量级的减少。EfficientNet-B0为基线网络,其网络结构如表1所示。
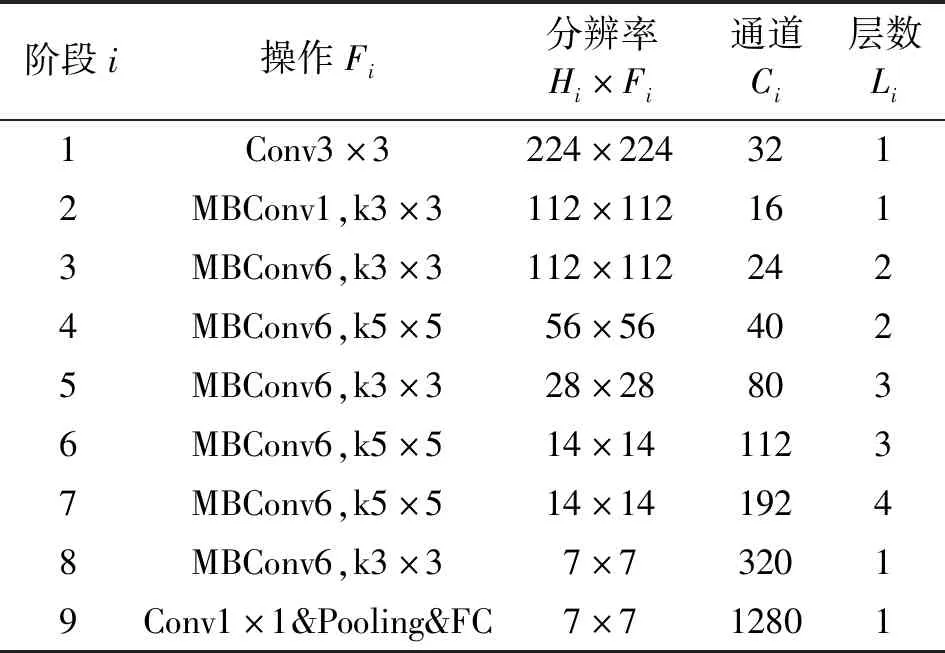
表1 EfficientNet-B0基线网络结构
EfficientNet-B0的网络结构分为9个阶段,第一个阶段为3×3的普通卷积,步长为2,连接批量归一化(Batch Normalization,BN)层和Swish激活函数;第2~8个阶段都是移动倒置瓶颈卷积(Mobile inverted Bottleneck Convolution,MBConv),在每个阶段该模块重复的次数对应层数Li;最后一个阶段为1×1卷积、全局平均池化和全连接层可添加Softmax激活函数进行分类。
原MBConv模块是EfficientNet的核心模块,该模块来源于MobileNetV2[7]中的移动倒置瓶颈模块,并添加了压缩和激励模块[8]进行优化,激活函数选择Swish,其结构如图2所示。
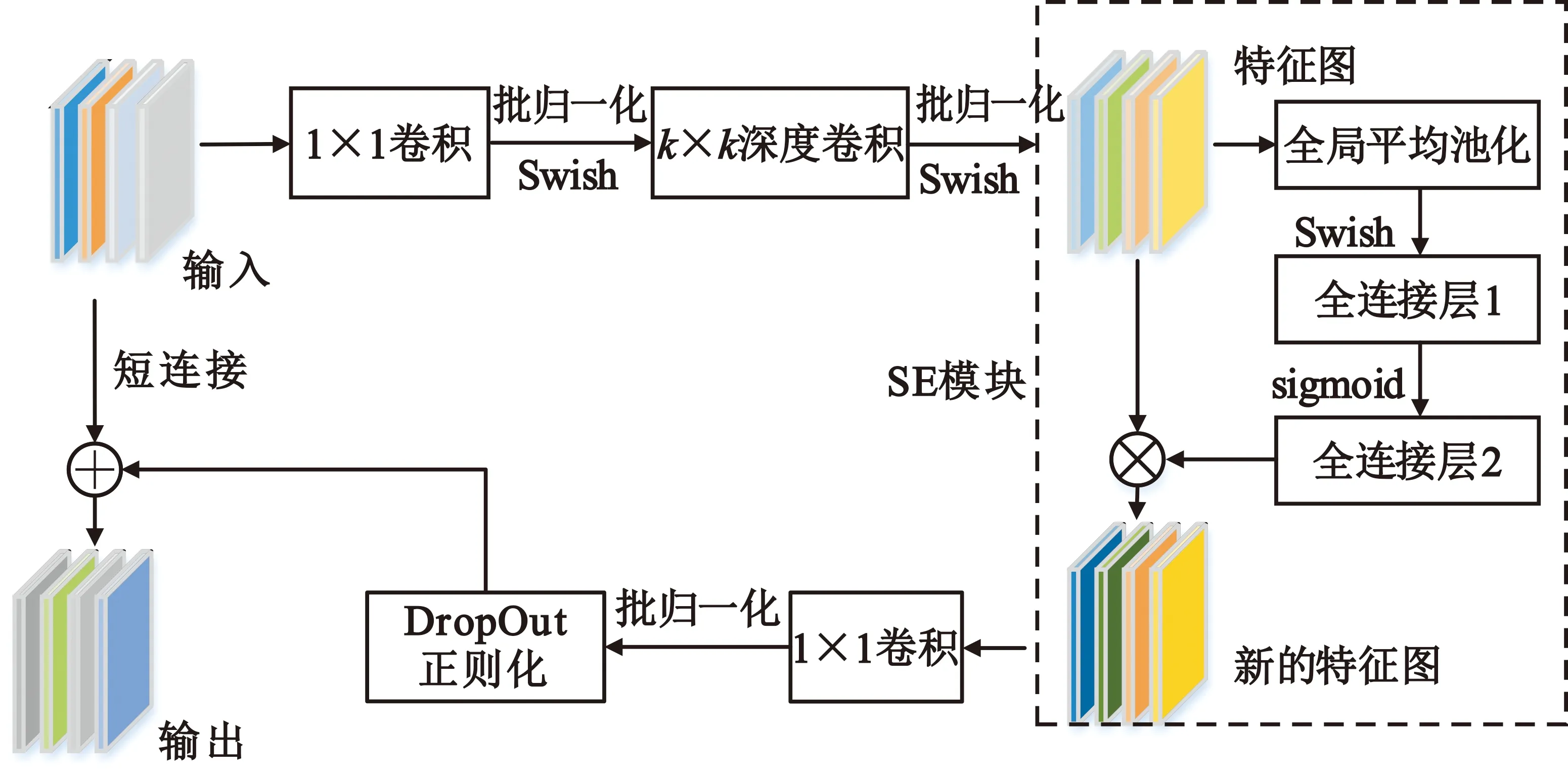
图2 MBConv结构
2.2 卷积注意力模块
SE模块在应用中通过对卷积中的特征图进行处理,只对卷积中不同的通道进行关注,相比之下,卷积注意力模块(Convolutional Block Attention Module,CBAM)[9]依次应用了通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM),通过给予需要强调或抑制的信息不同权重有助于网络内的信息流动,在卷积中有更好的效果,其中CAM和SAM结构如图3和图4所示。CAM模块生成的通道注意力和输入的特征图相乘得到的特征图将作为SAM模块的输入,SAM模块输出的空间注意力和该模块输入的特征图做乘操作,从而得到最终的特征图。
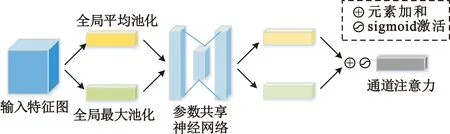
图3 CAM结构
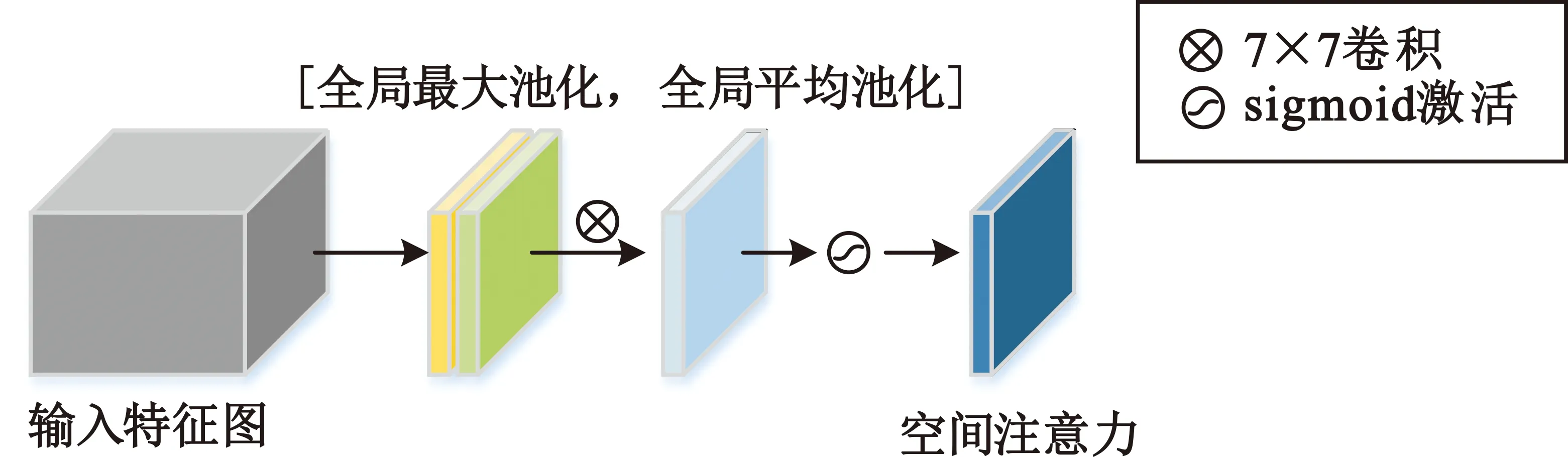
图4 SAM结构
2.3 h-Swish激活函数
在EfficientNet原始网络中,网络第1个和第9个卷积模块以及网络2~8模块对应的MBConv结构中使用的都是Swish激活函数[10]。Swish激活函数在深度神经网络中的效果比ReLU激活函数好,但是计算时间更慢,其函数的表达式如下:
f(x)=x·sigmoid(βx)。
(3)
公式(3)中的β是可训练的参数。Swish激活函数无上界、有下界、平滑、非单调,可以丰富神经网络层的表现能力,但该激活函数计算量比较大,计算和求导时间复杂。
相比于Swish激活函数,h-Swish激活函数求导过程更加简单,在效果影响不大的情况下能够使计算量大大降低。h-Swish激活函数其实就是来自h-Sigmoid激活函数,该函数的表达式如下:
f(x)=x·ReLU6(x+3)/6。
(4)
式中:
ReLU6=min(ReLU,6)。
(5)
在MobileNetV3[11]中,Swish的大多数好处是在更深的层实现的,因此只在网络的后半部分采用了h-Swish激活函数。
2.4 改进的EfficientNet网络
首先,对EfficientNet-B0网络中的MBConv模块进行改进,用CBAM模块将网络中的原MBConv模块中的SE模块替换,使网络同时关注两个维度上的特征信息,抑制不重要的特征信息,加强对图像深层特征的提取得到改进的MBConv模块。改进后的结构如图5所示。
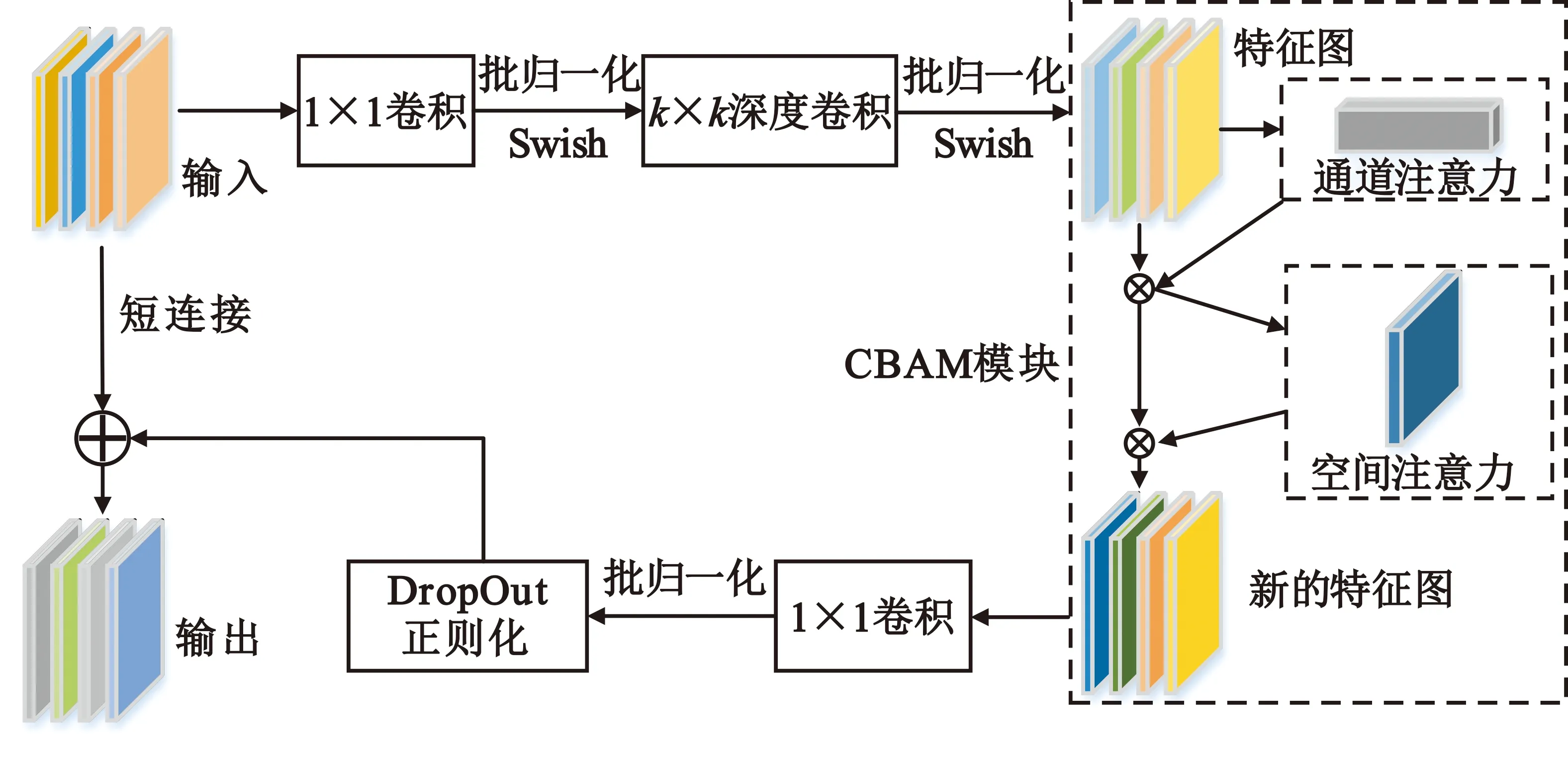
图5 改进的MBConv结构
改进的MBConv包含CBAM模块,CBAM模块的输入是深度卷积后得到的特征图,其中的通道注意力和空间注意力由图3和图4所示的CAM、SAM结构输出得到;分别关注卷积中的通道和空间信息,输出的新特征图经过卷积后若形状不变则添加短连接并使用DropOut正则化,针对原始EfficientNet-B0网络,替换阶段2~8的所有MBConv模块,保持网络的其他结构不变。
其次,考虑到随着网络的加深,特征图分辨率减小,为了减弱应用非线性函数的成本,兼顾不同激活函数对于识别效果和识别速度的影响,而且h-Swish激活函数计算量小于Swish激活函数,在深层表现明显,可以弥补只用ReLU产生的精度损失,在网络前端选择采用ReLU,在网络后端采用h-Swish,通过在不同位置选择不同的激活函数得到多种组合,进行实验和分析以后选择综合效果最好的一组。
通过改进MBConv模块和调整网络的激活函数得到了改进后的EfficientNet网络。
2.5 标签平滑机制
标签平滑[12](Label Smoothing)是一种正则化方法,主要用于分类问题,作用是扰动目标变量,防止网络太过于相信真实标签即网络过度自信,可以将正确类的概率值更接近其他类的概率值,能够改善模型的泛化能力,其公式如下:
(6)
(7)
式中:ce(x)表示x的标准交叉熵损失,例如-lb(p(x));i是正确的类;N是类的数量。标签平滑鼓励网络的输出接近带权重比例的正确类,同时让输出与不正确的带权重比例的错误类保持等距。
2.6 基于改进EfficientNet的信号调制方式识别流程
Step1 建立改进后的EfficientNet网络。
Step2 获取信号时频图像并进行预处理:对雷达信号的仿真数据进行CWD变换得到时频图像,用双线性插值法将图像大小设置为224×224,对图像进行归一化处理,将其像素范围压缩至[0,1],处理后时频图像的维度将变为[224,224,3]。
Step3 为时频图像添加标签,把标签转换为one-hot编码形式。
Step4 数据集制作:将时频图像与标签一起组成数据集,将生成的数据集按照6∶2∶2的比例分为训练集、验证集和测试集。对训练样本图像做CutMix增强处理,对样本标签做标签平滑处理。训练集用于训练网络、优化参数;验证集在训练集迭代训练时验证模型的泛化能力,以此来调整训练选择的各项参数;测试集用来评估模型最终的泛化能力即模型识别能力。
Step5 模型训练:将训练样本输入网络进行训练。
Step6 信号识别:加载模型参数,输入测试集的样本,对信号调制方式进行识别预测。
3 实验和分析
3.1 实验环境
本文实验远程连接服务器进行训练,服务器的操作系统为Ubuntu20.04.1,GPU的型号为NVIDIA Tesla V100,显存16 GB。实验使用python3.6编程语言,选择深度学习模型框架tensorflow2.0.0-gpu。
3.2 数据集
本文按照不同调制信号的信号模型并参考文献[13]的参数设置,使用Matlab生成了雷达辐射源信号的9种不同脉内调制方式(2FSK、4FSK、2PSK、4PSK、LFM、P1、P2、P3、P4)的数据集,实验数据集的结构组成如下:
样本长度:时域信号为2 048个采样点;
信号形式为CWD时频图;
信号维度为[224,224,3];
信噪比范围为-10~8 dB,间隔步长2 dB;
单一信噪比单一调制类型的样本个数为1 024个。
3.3 网络训练
针对本文数据集,设置网络训练各项参数,batchsize设置为32,损失函数选择交叉熵损失函数,优化器选择Adam,因网络收敛快,总的训练轮数设置为50轮次,验证频率设置为1,每训练一轮验证模型一次。初始学习率设置为1×10-3,并设置学习率下降机制,若验证集损失保持3轮不下降则缩小学习率为原来的一半。为节省时间,防止网络过拟合,设置早停机制,当验证集的损失在训练5轮没有下降时认为网络收敛则结束训练,保存模型的最优参数。
3.4 实验结果和分析
实验1为了探究用CBAM注意力机制改进模型的效果,对比分析采用CBAM改进后的EfficientNet-B0网络和原始EfficientNet-B0网络的识别效果,输入数据不采用CutMix数据增强,样本标签都不使用标签平滑只是将其变换为one-hot编码,用不同信噪比的所有调制类型的数据进行测试,两种模型的识别效果如图6所示。
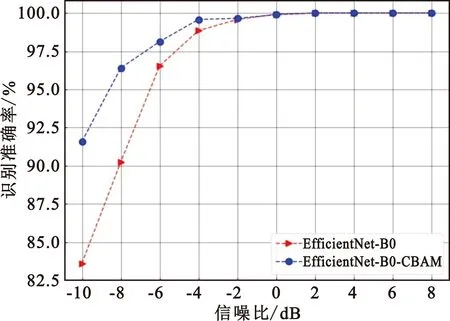
图6 改进前后网络性能对比
由图6可知,两个模型在信噪比高于0 dB时识别准确率都能够达到100%。这是因为信噪比较高时,图像特征信息强,不同调制信号的时频图差别大,更加容易提取特征进行识别。改进后的EfficientNet-B0网络在信噪比-8 dB时识别准确率达到了96.40%,明显高于原始MBConv模块组成的网络,说明本文改进的模型有更好的识别能力。
激活函数作为CNN的重要单元,能够给网络带来非线性的特征,激活函数的大量使用对模型效果影响较大。实验2为了选择适合的激活函数,进行不同组合和实验,其中的1~9阶段如表1所示对应改进型EfficientNet-B0的网络结构,其中的MBConv模块都添加了CBAM后的改进模块,根据激活函数的特点,固定第一层卷积层使用ReLU,最后一层卷积层使用h-Swish,通过改变2~8阶段所有MBConv模块使用的激活函数,得到8个不同组合,网络原始的激活函数全部都是Swish,组合0就是用没有改变激活函数的改进型网络,激活函数应用于对应的整个阶段i,在卷积层和BN层以后使用,对8个不同组合所对应网络进行训练,然后对测试集进行测试。每个组合使用的激活函数以及测试结果可扫描本文OSID码查看。
由实验结果可知,使用h-Swish激活函数能够保持网络的识别精度但比Swish计算更快,使用ReLU激活函数能够加快网络训练速度,但是一定程度上会带来精度损失。组合4网络在第5阶段之后才使用h-Swish激活函数,此时特征图大小为14×14,应用非线性函数的成本减弱,对比于ReLU提高了网络精度。实验结果表明,组合4网络对比于仅用CBAM改进后的网络能够保持识别精度并且很大程度上加快了网络的训练速度,因此选择组合4对应的网络作为本文最终的改进EfficientNet模型。
模型改进前后的参数和识别准确率如表2所示。由表2可知,改进后的网络参数增加很少,这是因为引入了CBAM模块带了少量的参数增加。改进后的模型在不断训练时能够同时关注通道和空间两个维度上的特征信息,训练速度比原始MBConv组成的B0网络略慢,但是识别效果提升显著,在-10 dB时,改进后的网络识别准确率提高了7.97%;通过改变网络的激活函数,与单独改进网络结构相比网络训练速度加快62 ms/step,训练效率提升了23.7%,在一轮迭代训练中,可以减少107.1 s时间,并且不会影响识别准确率,证明通过改变激活函数,网络得到了有效的改进。
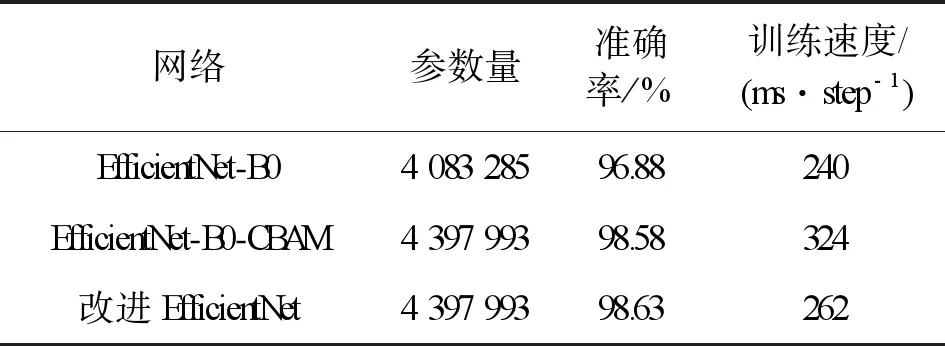
表2 改进前后模型的对比
实验3为了进一步了解标签平滑机制、CutMix数据增强对对模型泛化能力的影响,以测试集的正确率和损失为评价标准进行多次消融实验,实验结果如表3所示。由表3可知,模型在添加了标签平滑机制和使用CutMix数据增强以后,识别准确率都得到了提高,加入了标签平滑机制以后识别率提升了0.2%,加入了CutMix数据增强识别准确率提升了0.54%,同时加入两种方法识别率提升了0.62%,最终整体的识别率达到了99.25%。
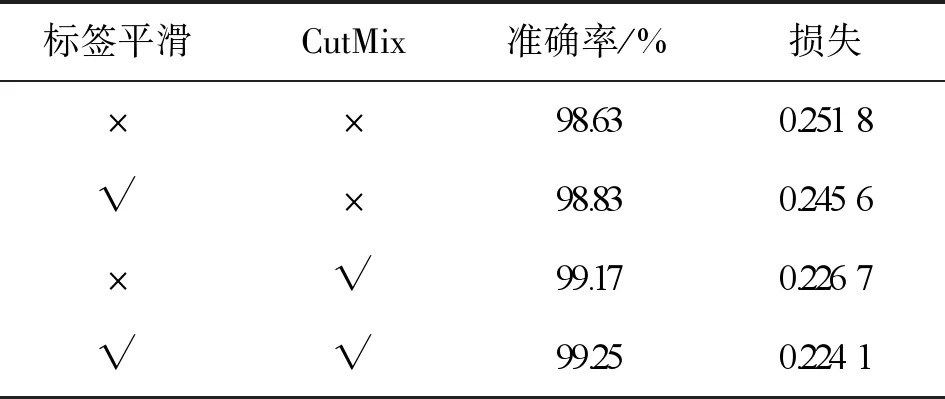
表3 不同方法对模型识别率的影响
为进一步分析模型的识别效果,利用训练保存的最终模型在信噪比-10 dB的测试集进行测试识别,识别率达到了94.24%,其混淆矩阵如图7所示,可以看出识别错误主要发生在多相码调制类型中,特别是P1和P4码;P1、P2码信号是对线性调频波形的阶梯型近似,当信噪比降低时时频图像中的阶梯型特征会逐渐消失,因此会影响识别效果。
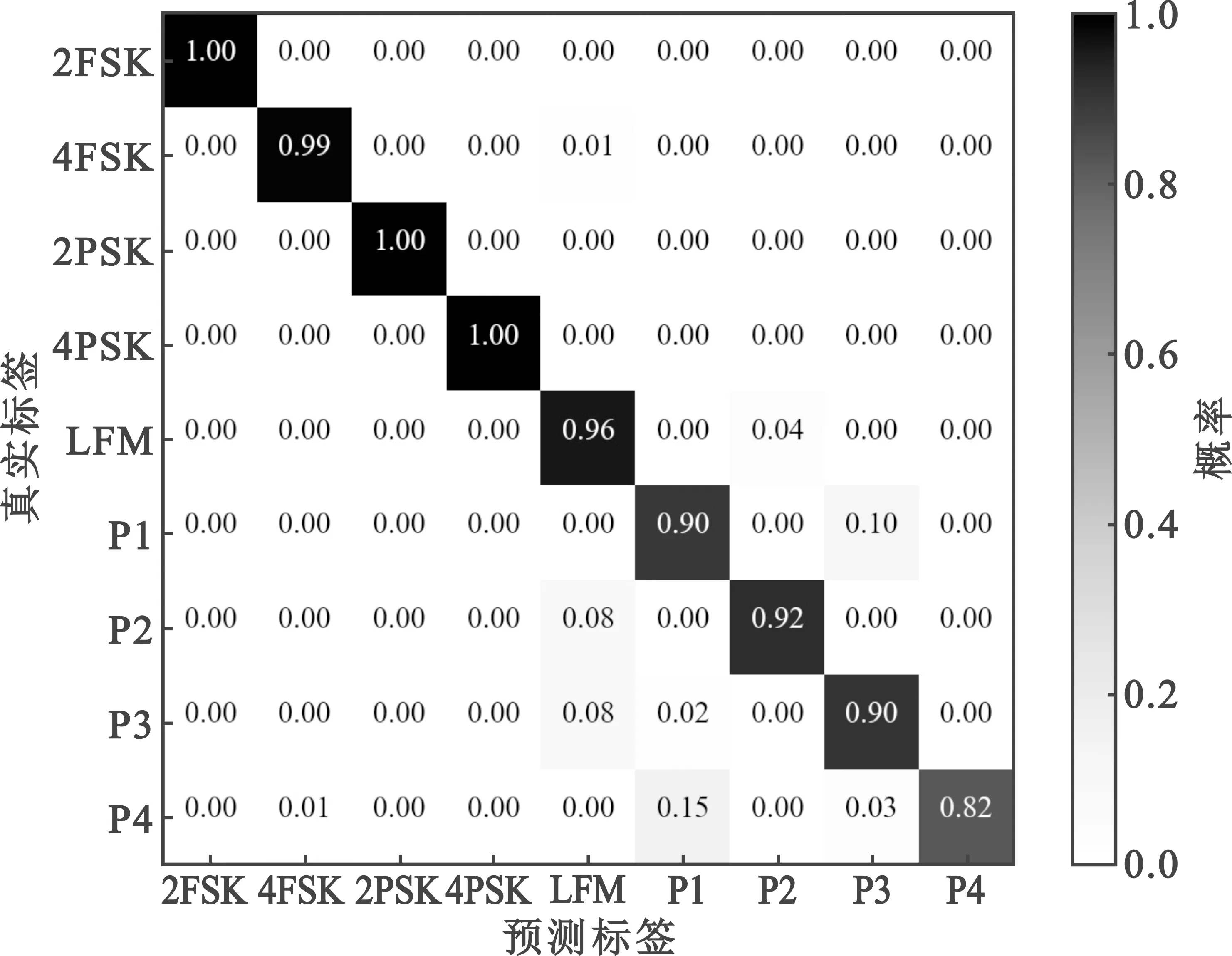
图7 -10 dB条件模型识别结果混淆矩阵
实验4为了验证本文提出的改进EfficientNet网络模型性能,选取了在图像分类识别中常用的网络模型AlexNet、InceptionV3、SE-Resnet50、DenseNet121、VGG19进行对比,除InceptionV3网络数据输入大小为299×299外,其余网络输入均为224×224。数据集预处理和训练设置相同,用混合信噪比的数据进行测试,测试结果如表4所示。
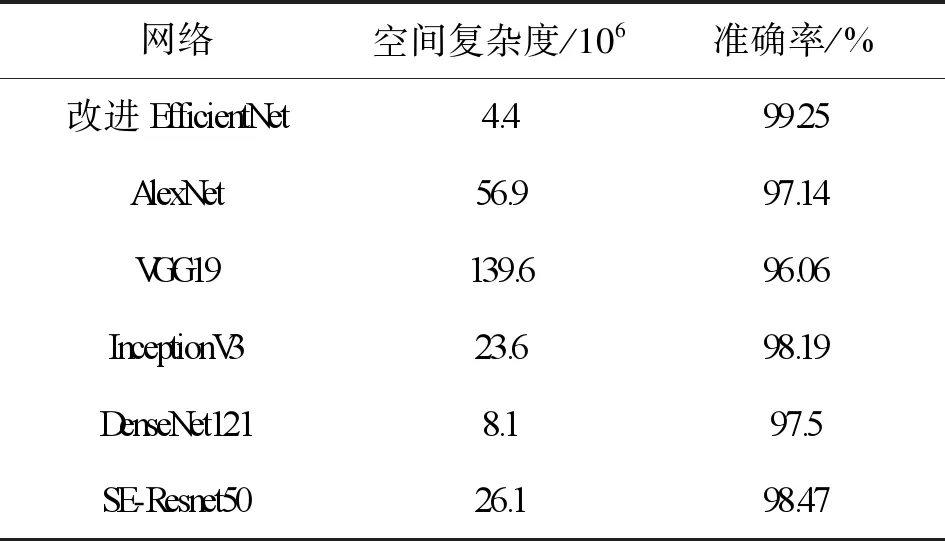
表4 网络对比
表4中显示了各个网络空间复杂度和模型识别准确率的对比,网络的空间复杂度一般指模型的参数数量,体现为模型本身的体积,模型参数越多,训练该模型时就需要更多的数据。本文构建的改进EfficientNet网络模型空间复杂度很小,模型参数量相比于其他网络呈倍数减少;VGG19的参数量达到了改进EfficientNet的31倍之多,所选取的6个网络的整体准确率都达到了96%以上。这是由于本文构建的数据集数量充足,参数量大的模型拥有足够的数据进行训练,并且进行了数据增强,识别性能有所提高。相比于SE-Resnet50,改进EfficientNet参数约为SE-Resnet50的1/4,SE-Resnet50的识别准确率也达到98.47%,是因为在Resnet50的基础上添加了SE模块,残差连接和通道注意力增强了模型的泛化能力。总的来说,本文改进EfficientNet模型参数更少,识别准确率也更高,能够更好地识别雷达辐射源信号。
实验5对本文提出的方法和其他识别雷达信号的深度学习方法进行了比较,选取了近两年来的文献采用的识别方法。文献[14]构建了改进型AlexNet网络,调整了卷积核的大小和全连接层的节点数,网络参数量相比于原始AlexNet网络有所减少,但同样较多达到了3.365×107;文献[15]构建了扩张残差网络DRN,减少了原始残差网络的每一组卷积的通道数,但设置每层的残差单元数只为1,网络层数较少,因此参数量为1.24×106;文献[16]构建了SE-ResNeXt网络,在残差结构中用分组卷积替换分支结构,同时添加了SE模块,并对每层的残差单元数进行调整,参数量达到了3.951×107。三篇文献中都使用了CWD时频分析方法,网络最后都使用Softmax分类器输出。在相同实验条件下进行训练,图8显示了三篇文献中的方法和本文方法对9类雷达辐射源信号在不同信噪比条件下的识别准确率。
如图8所示,四种方法在信噪比大于-4 dB时识别准确率都到了98%,但是随着信噪比的降低,文献[14]和文献[15]的识别效果降低较多,特别是文献[15]识别效果最差。因为其模型DNR虽然参数量较少,但是模型设计过于简单,仅包含9个卷积层,特征提取能力低于其他三个模型,总体识别率也最低。本文提出的方法识别效果好于其他三种方法,在信噪比-10 dB时,对9种调制信号的综合识别率达到了94.24%,比文献[14]和文献[15]的方法分别高出了7.65%和9.59%。文献[16]提出的方法识别效果略低于本文方法,体现了SE-ResNeXt网络在低信噪比条件下同样可以有效识别雷达信号,但是网络参数多,达到了本文模型参数的8.9倍。总体来说,对雷达辐射源信号调制方式进行识别中,本文提出的方法相比于其他深度学习方法参数量少,识别效果好,具有一定的优越性。
4 结束语
本文针对雷达信号调制方式的在低信噪比条件下的识别问题,搭建了基于EfficientNet的改进网络模型,使用卷积注意力模块改进模型加强模型对雷达信号时频图的通道、空间有用特征的关注,通过对非线性激活函数的效果分析优化网络训练,采用CWD分布进行时频分析,对得到的时频图做CutMix数据增强处理以增强模型对困难样本的识别能力。经实验证实,本文提出的方法网络空间复杂度低,参数量大大低于经典图像识别网络,与现有的利用深度学习的方法相比,在低信噪比条件下对信号的多种调制方式具有更高的识别准确率。在模型的时间复杂度的优化方面,还可以继续研究。
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
宇航计测技术(2018年3期)2018-09-08
北京航空航天大学学报(2018年1期)2018-04-20
雷达学报(2017年3期)2018-01-19
西南石油大学学报(自然科学版)(2015年5期)2015-04-16
舰船科学技术(2015年8期)2015-02-27
