
基于Apriori算法与MapReduce优化模型的并行式数据聚类方法*
2023-01-18 12:06吕立新
九江学院学报(自然科学版) 2022年4期
吕立新 杨 帆
(1安徽商贸职业技术学院信息与人工智能学院 安徽芜湖 241000;2菲律宾科技大学工程技术学院 菲律宾马尼拉 0900)
数据聚类结合了智能算法、计算机科学等综合性技术,将数学理论知识应用在现实生产领域,能够将海量数据整合集中,挖掘出其中的隐含规律,为社会各领域发展提供信息支持[1]。Apriori算法是关联规则挖掘技术的重要分支,帮助研究者找出各种数据之间的相互关系,已经在数据聚类领域展现了优势[2]。传统Apriori算法虽然在数据聚类方面有所成效,但是容易对系统节点负载造成负担,且数据聚类时间开销不理想等问题凸显。为了高效率、高精度聚类大规模数据挖掘一个事件与另一个事件的相互关联[3],该研究将Apriori算法与分布式的MapReduce框架模型结合,且分别对其实施改进,形成一种崭新有效的并行式数据聚类方法,起到辅助决策作用。
1改进Apriori算法与MapReduce优化模型在并行式数据聚类中的应用
1.1 MapReduce模型的开源实施框架
研究中的MapReduce优化编程模型采用Apache Hadoop开源实施框架,其优点是营造了应用程度与数千个独立计算的计算机与PB级数据工作同步展开的环境,是一种被Apache允许的、数据密集型、分布式应用程序。MapReduce优化模型的Apache Hadoop开源实施框架操作呈现显著的周期性特征[4],其运行机理如图1所示。
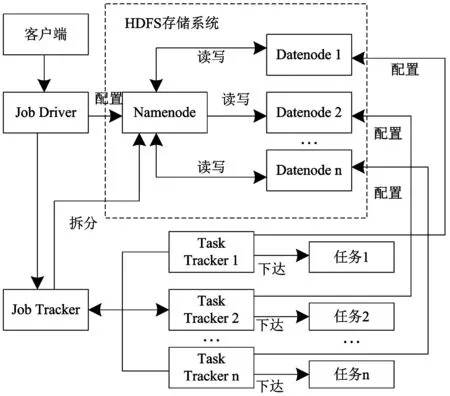
图1 Apache Hadoop开源实施框架运行机理
由图1可知,Apache Hadoop的核心包括HDFS存储系统、MapReduce处理组件两部分,其中,HDFS组件既能为目标数据块创建多个副本,也能高吞吐量提取数据,满足了Apriori算法挖掘海量数据关联规则的高性能需求。其中,Reduce阶段包括Sort,Shuffle和Reduce3个子阶段,Shuffle阶段运行数据花费的时间超过Reduce阶段三分之一[5],优化潜力较大。
1.2基于W-DPC策略的Apriori候选项集结合方法
Apriori算法的基本描述如下:定义数据库D用于存储关联规则挖掘所需的事务t,t包含多项属性i;假设X与Y是事务的属性,X⟹Y则表示二者的关联规则。关联规则拥有支持度与置信度,分别描述为Support、Confidence,计算方法如公式(1)与公式(2)所示:
(1)
(2)
公式中,事务总数用M表示,属性X与属性Y相同时间出现的事务的次数为Count(X∪Y),属性X出现的次数为Support(X)。不难看出,支持度是事务同时拥有两个属性的数量同事务总数量的比值;而置信度是支持度与属性之一X的支持度的比值。通过设置最小支持度与置信度的方式约束数据关联规则的最低标准,进而完成数据聚类。
Apriori算法进行关联规则挖掘过程中需多次扫描数据库、生成候选项集,提高了数据聚类的冗余程度。Shuffle阶段是MapReduce模型与Apriori算法结合运行的关键步骤,其特点是产生大规模的计算数据和较长的候选项集,passes过程的运行负载提升,影响数据聚类的运行效率。不仅如此,map计算任务执行完毕reduce才能开始其合并value的运算,再一次延长了整个Apriori算法进行关联规则挖掘的效果[6]。为了增强Apriori算法在MapReduce模型框架下的适应能力、挖掘有效的数据信息,优化了Apriori候选项集结合方法,步骤如下:
Step 1:设定阈值,将阈值之上的一项集输出生成下一阶段候选项集,经过阈值对比获得频繁二项集,循环操作Step 1生成第三候选项集;
Step 2:确定固定数量的passes量。将候选二项集与候选三项集的时间展开比较确定passes量:结合三个passes的前提是候选二项集生成时长多出候选三项集生成时长3/2倍;结合两个passes的前提是候选二项集生成时长多出候选三项集生成时长不足3/2倍[7]。
通过以上方法可以确定MapReduce模型框架下Apriori算法执行的passes量,reduce无需等待map任务执行完毕再开始工作,节省了等待时间,提升了Apriori算法在MapReduce模型中并行式聚类的效率。
1.3 二项频繁集快速生成策略
Apriori算法执行效率慢的原因之一是候选集过多,非频繁项集耗费大量时间。为进一步加快频繁项集生成速度,对Apriori算法频繁2-项集生成策略进行改进:提取数据中的一项频繁集定义为Q,合并Q与每一个事务集,以此得到各事务集中频繁性低的数据,将其剔除,得到数据集K;定义二项子集为E,从K集中生成,再在二项子集中生成二项候选集;创建h表存储关键值形式的二项候选集,当存入的关键值是第一次存入则需实施正规的数据存储处理步骤,且关键值对应的v为1,反之存入的关键值已经存在则对表中的关键值加1[8];存储完毕将表中关键值转换为二项候选集,Apriori算法二项候选集挖掘关联规则的支持度即为关键值对应的v。
以上对Apriori算法挖掘关联规则的过程进行了优化,明显降低Apriori算法生成二项频繁集的时间复杂度,从而降低Apriori算法挖掘时间开销。MapReduce优化模型下改进算法获得频繁项集的过程为:
(1)输入原始数据集D,将数据集划分为 h个规模相当的数据块,并将h个数据块转换为
(2)运行Map程序并扫描数据块,通过Map函数获取频繁1-项集。
(3)以减少节点之间的通信量为目的,编写 Combiner基于W-DPC策略确定待结合的passes项集数量,reduce无需等待map任务执行完毕再开始工作,节省等待时间。
(4)以获得的频繁1-项集为基础,基于二项频繁集快速生成策略获取频繁2-项集。减少频繁集生成过程中无效候选项集带来的负载与干扰,降低算法时间复杂度。
(5)利用Reduce函数合并符合最小支持度的局部频繁项集,高效率、低开销生成全局候选频繁项集。
(6)以Reduce阶段的全局候选频繁项集为基础并行式产生候选项集:频繁项集分割为相同的数据块并执行Map函数处理;Map函数处理数据块实现频繁项集向键值对的转换,Map函数独自处理输入的数据块;全部Map节点将具有相应键的键值对传输至Reduce函数,由Reduce分离键与值得到符合支持度阈值的候选项集。
(7)频繁项集为空集时终止运算,反之,循环操作步骤(3)~步骤(5)。
2实验与分析
2.1实验环境设置

2.2负载均衡测试
实验以V3数据集为样本进行数据聚类测试,利用方法挖掘数据集的关联规则。在此过程中记录了每个计算节点的事务数,绘制成条形图如图2所示。
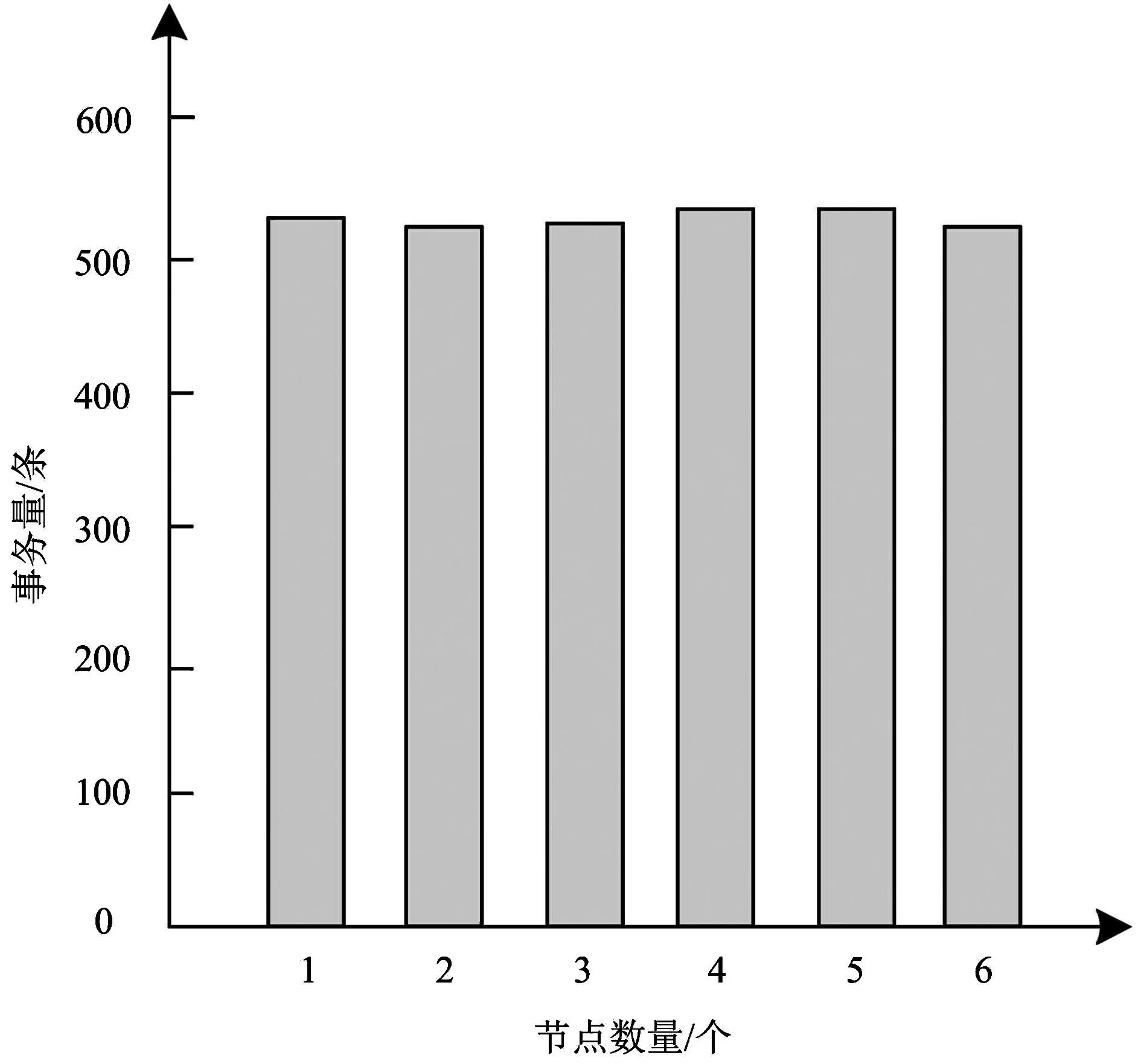
图2 各节点事务数分布统计
由图2不难看出,方法在各节点上的事务数分布约在533条上下,没有出现过多或者过少的情况。可见在分布式挖掘阶段,每个计算节点的计算数据量接近,说明数据聚类任务呈现均衡的分布式状态,实现了较好的负载均衡。
2.3时间复杂度测试
实验在6个数据集下展开数据聚类,各方法独立运行10次后取其时间开销均值,统计了包括方法在内的三种数据聚类方法的时间复杂度情况,结果如表2所示。
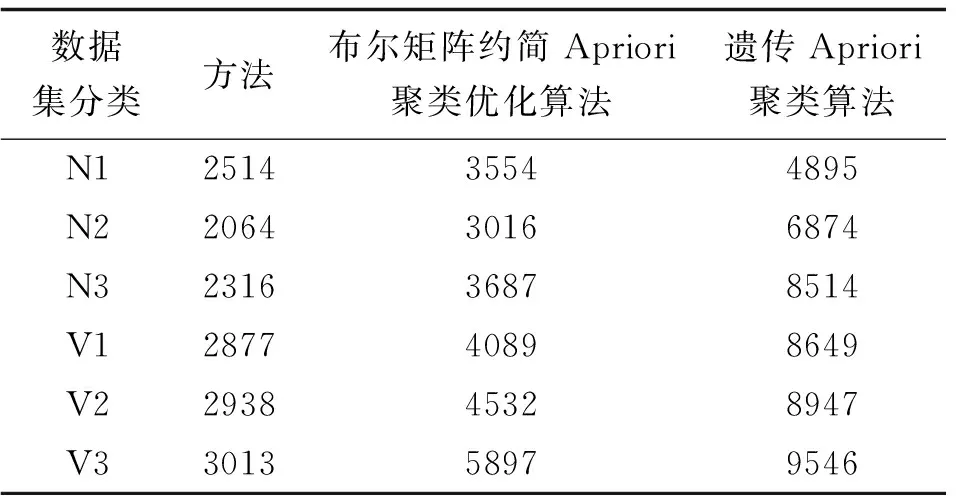
表2 三种数据聚类方法的运行时间统计/s
分析表2可知,在不同规模数据集之下,完成相同聚类目标的前提下,方法的运行时间最少,时间复杂度最低。处理N2数据集800事务数仅花费了2064s,当数据集事务数增加到3200时,时间开销达到最高为3013s,可见该方法的聚类时间花费较为平稳、波动不大,时间复杂度较低。相比之下,布尔矩阵约简Apriori聚类优化算法聚类时间高出方法约1/3甚至更多,时间波动幅度相对较大。遗传Apriori聚类算法时间复杂度表现亦是如此,聚类运行效率更低,处理3200事务数时花费9546s。
总体而言,通过上述方法降低了MapReduce模型运行之下的数据聚类时间复杂度,这是因为上述方法分别对Apriori算法与MapReduce模型运行策略进行了优化,基于W-DPC策略设计了崭新的Apriori候选项集结合方法,确定了MapReduce模型框架下Apriori算法执行的passes量,reduce无需等待map任务执行完毕再开始工作,因而passes阶段的运行负载有效降低,聚类的整体时间复杂度有所降低。
3结论
提出的基于Apriori算法与MapReduce优化模型的并行式数据聚类方法,可有效解决海量数据的分类问题,降低了聚类的时间复杂度、实现了各节点的均衡负载。一方面,基于W-DPC策略设计Apriori候选项集结合方法,预先确定MapReduce模型框架下Apriori算法执行的passes量,reduce无需等待map任务执行完毕再开始工作;另一方面,引入二项频繁集快速生成策略,及时剔除无效候选集,降低Apriori算法生成二项频繁集的时间复杂度。综上,文章方法展现了良好的大规模数据聚类性能,为提升社会各领域信息数据智能分析效率提供了有效参考。
猜你喜欢
河南水利年鉴(2020年0期)2020-06-09
中国惯性技术学报(2019年6期)2019-03-04
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
计算机技术与发展(2017年8期)2017-09-01
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
职业技术(2012年8期)2012-08-15
