
考虑尖峰负荷特性指标的用户用电行为分析
2023-01-17 13:48赵爽阮俊枭支刚吴政声万航羽王志敏刘民伟
内蒙古电力技术 2022年5期
赵爽,阮俊枭,支刚,吴政声,万航羽,王志敏,刘民伟
(1.云南电网有限责任公司电网规划建设研究中心,昆明 650000;2.昆明理工大学 电力工程学院,昆明 650500;3.中国能源建设集团云南省电力设计院有限公司,昆明 650000)
0 引言
随着当今社会数字化、信息化的快速发展,智能电网的应用层面进一步拓宽,“十三五”期间国内计划安装2.3亿块智能电能表对用户用电数据进行实时采集,用电采集系统[1]的发展完善使电力大数据量快速增长,为分析电力用户用电特性,提升负荷预测准确率、识别用户用电模式、评估需求响应潜力、指导电价制定等提供了基础[2]。同时,电力大数据也成为国内外研究热点[3-5],且用电负荷规模快速增长,用电结构持续优化调整,三产及居民生活用电比例不断上升,负荷尖峰化特征愈发明显。
电力负荷是典型的非线性时间序列数据,其随时间行进呈趋势性、周期性的波动。电力用户用电行为模式划分是以多用户时序数据为基础的无先验信息及标签类问题,聚类分析属于机器学习算法中典型的无监督学习算法,在用户用电行为分析中得到了广泛的应用[6-8]。在进行负荷聚类时,考虑负荷曲线趋势性和周期性的相似程度,正确衡量负荷随时间变化的形态和轮廓的相似性才能把握用户的用电习惯和特性,从而对同类用户进行聚类并完成用户用电模式的识别[9]。通过分析用户用电行为,电网端可获取多用户用电细节,并制定相应政策方针改善用户用电方案,以提高电网系统运行效率,达到节能减排的目的。当前,负荷聚类分析主要分为直接聚类法[10-11]及间接聚类法[12-13]:直接聚类法直接对原始负荷数据进行聚类分析,包含Kmeans聚类法、层次聚类法及基于密度的聚类法等;间接聚类法先将原始负荷序列进行降维提取其特征,然后再进行聚类分析,降维方法包含主成分分析、奇异值分解及卷积神经网络特征提取等。
在用户用电行为聚类分析问题上,文献[14]将调节潜力指标作为要素对用户用电行为进行了分析;文献[15]建立了峰时耗电率、负荷率、谷电系数及平段用电的时序特征,并结合云计算与并行Kmeans算法对用户行为进行分析;文献[16]提出多元大数据平台融合的改进思路,使用批处理及流处理的方法分析用户用电行为;文献[17]关注聚类个数确定方法及初始聚类中心的选择逻辑两个要素,对K-means算法进行改进;文献[18]针对海量用户数据,提出首先对负荷进行局部聚类获取特征,然后再根据局部特征获取整体聚类结果的两阶段聚类方法;文献[19]使用自适应模糊均值算法对电力用户进行聚类,然后使用核极限学习机对各类用户进行负荷预测;文献[20]提出一种负荷特征集优选策略,减少了负荷特征间的分类信息冗余,构建精简的特征子集以达到更好的聚类效果。但不同类型的用户用电波动大、峰谷差明显,未针对其尖峰负荷的特性进行设定、区分,无法有效以尖峰负荷的特征量进行数据挖掘、聚类。
基于此,本文首先对尖峰负荷定义进行描述,并分析尖峰负荷特性指标。然后将尖峰负荷特性指标应用于用户日负荷数据中提取用户用电行为尖峰特性特征[21-23]。最后以美国国家可再生能源实验室开源用户用电数据为研究对象,采用K-means算法进行用户用电行为分析,并对比使用尖峰特性特征与原始负荷的聚类结果。
1 尖峰负荷特征指标
1.1 尖峰负荷定义
随着电力系统发展不断成熟,尖峰负荷已由最初的点负荷发展成为可能影响电力系统安全稳定运行的时段性顶峰负荷。目前,行业内关于尖峰负荷的定义尚未达成共识,其物理含义为:一定时期某区域内,电力负荷在一段持续时间内超过或者达到峰值一定百分比的区域。一般尖峰负荷的峰值百分比取3%、5%、10%,即大于最大负荷的90%、95%、97%部分认为是峰值负荷,周峰值负荷示意图如图1所示。

图1 周峰值负荷示意图Fig.1 Schematic diagram of weekly peak load
1.2 尖峰负荷特性指标
按照负荷本身特征及对电网的影响,尖峰负荷特性指标主要包括尖峰负荷规模、频次、电量、持续时间、利用小时数。其定义分别如下。
尖峰负荷规模:一定时间区间达到或超过某一峰值负荷百分比的负荷值。其时间区间划定根据需要可以是一年,也可以是一个月或几个月等。设需求时间区间内采集的负荷样本为U=[u1,u2,…,uM],其中uM代表采集时间内的第M个负荷值,则尖峰负荷规模表达式如式(1)所示:
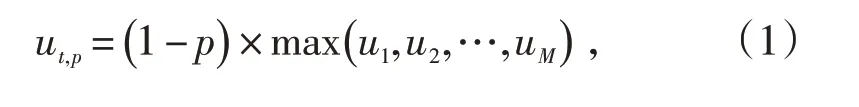
式中:ut,p代表在指定时间区间t内,对应不同峰值百分比p的尖峰负荷规模。
尖峰负荷频次Ct:一定时间区间达到或超过某一峰值负荷百分比的次数。
尖峰负荷电量Wt:尖峰负荷持续时间段内用电量的总和。
尖峰负荷持续时间St:达到或超过某一峰值负荷的时间,持续时间可以分为单次持续时间和累计持续时间。
尖峰负荷利用小时数Ht:尖峰负荷利用小时数指尖峰负荷电量与超过某峰值百分比区域内最大负荷的比值,计算公式为:
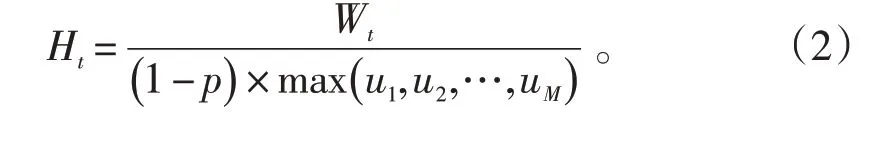
2 基于K-means算法的用户用电行为聚类分析
聚类分析的目的在于从一个无标签的数据集中根据个体相似性识别出不同的组,每个划分组内成员具有相似特征且区分于其他组成员特性。多用户用电数据在初始场景下属于典型的无标签数据集,通过对用户负荷数据进行聚类分析,可划分不同用能特性用户组,例如区分不同产业类型用户、在居民用电数据中区分用能习惯不同的用户,并根据不同用户组制订对应用能调节方案。
2.1 K-means算法原理
K-means是基于原型的聚类算法,算法先对原型进行初始化,然后对原型进行迭代更新求解:首先,指定初始聚类中心,然后将样本集内各点划分至不同簇,计算簇内平均距离,以距离下降为方向迭代循环,当簇内平均距离最小、簇间平均距离最大时,算法终止。算法流程如图2所示,其算法步骤如下。
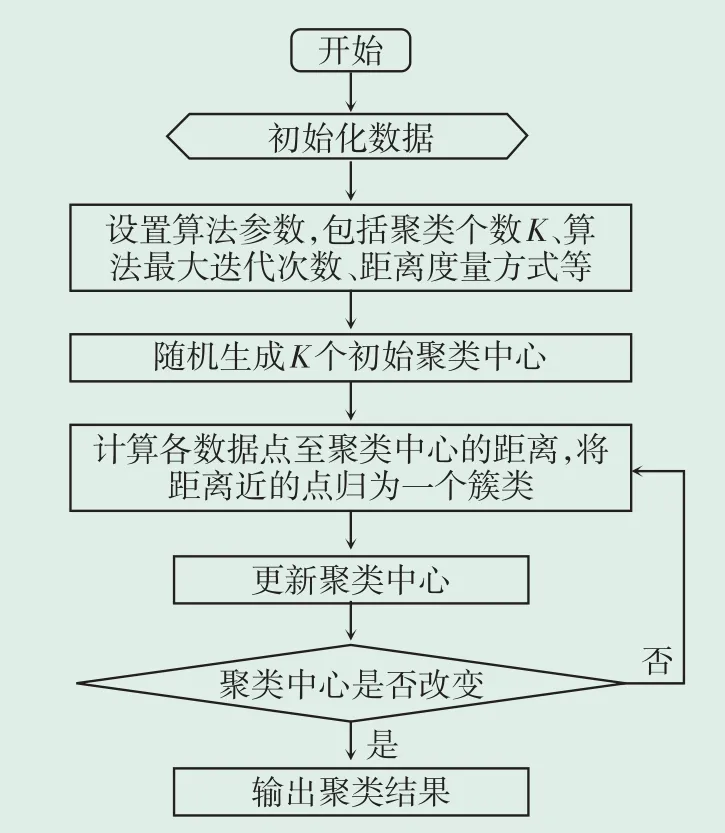
图2 K-means算法流程Fig.2 K-means algorithm chart
(1)步骤1:从长度为N样本数据集X=[x1,x2,…,xN]中任意选取K条数据作为初始聚类中心Y=[y1,y2,…,yK]。
(2)步骤2:计算剩余数据与各聚类中心的距离,并将距离聚类中心最近的数据划分为一个簇类。距离计算通常采用欧几里得距离进行度量,则第(ii=1,2,…,N)个数据与第(jj=1,2,…,K)个聚类中心的欧式距离及计算公式为:
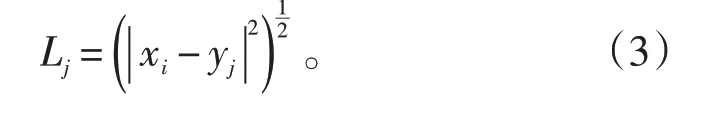
(3)步骤3:根据式(4)重新计算每个簇类的中心。

式中:Dj代表第j个簇类中包含的成员个数;ri为筛选变量,当xi从属于第j个簇类时,ri=1,否则取ri=0。
(4)步骤4:判断函数是否收敛或达到最大迭代次数,若收敛或达到最大迭代次数则输出聚类结果,否则返回步骤2。
算法迭代的目标函数F如式(5)所示:
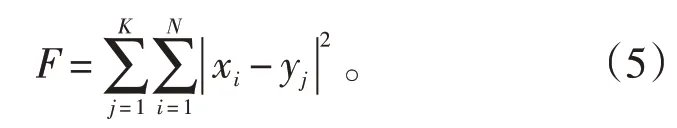
2.2 用电用户行为聚类
本文基于K-means算法,首先对用户日负荷数据进行聚类分析。设包含N个用户日负荷数据的矩阵为Xa,有:

式中:xN,1代表第N个用户的日负荷数据中第l(l∈[1,m])个采集点负荷数据值。根据不同的采集粒度,日负荷数据长度m可为24、48、96等。
对收集的数据集进行缺失值查询,使用近邻插值填补空值以避免缺失值对聚类结果造成影响。为避免不同用户用能尺度差异过大,对所有用户数据采用min-max归一化法进行归一化。

式中:xk,l为第k(k∈[1,N])个用户第l个数据值;xk,min为第k个用户日负荷数据最小值;xk,max为第k个用户日负荷数据最大值。
数据采集过程中难免出现仪器或人为错误,为避免异常点对聚类结果产生影响,使用平滑公式对异常点进行置换,平滑公式见式(8):
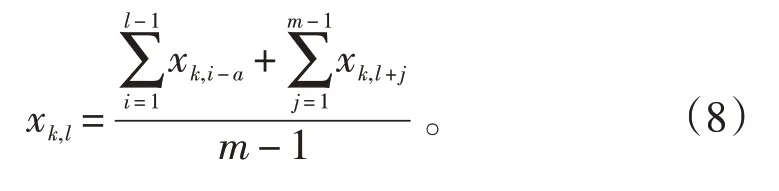
完成数据收集及预处理后,使用K-means对用户负荷数据进行聚类,具有相同负荷特性的用户归属为一个簇类,每个聚类中心可作为该簇类用户的日负荷等效曲线。
2017年的税制修正中,对各类机构纳入税额扣除的经费项目进行扩充,同时对一些繁复的手续予以简化,从而为开放式创新的实施营造条件。
3 算例分析
3.1 数据集
本文使用数据集来自美国国家可再生能源实验室开源用户用电数据[17],自典型气象年模拟的936个用户中任意抽取498个用户任意一日的日负荷数据,随机抽取用户与时序的目的是为了保证算例分析中算法的鲁棒性与适应性。数据采集时间间隔为1 h,一天采集24点,共包含11 952条数据。用户原始日负荷曲线见图3。
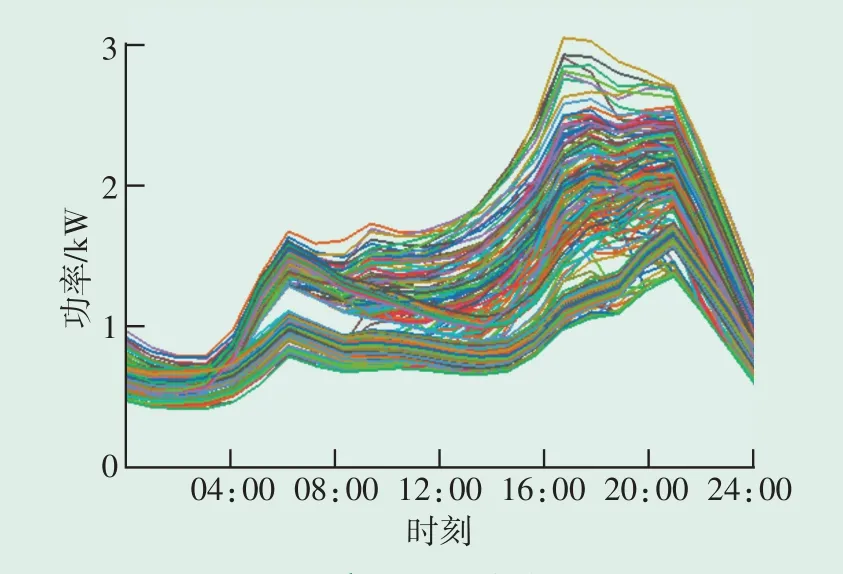
图3 用户原始日负荷曲线Fig.3 User original daily load curve
3.2 尖峰负荷特性指标特征集构建
由图3可见,用户原始日负荷曲线未经聚类时比较杂乱,难以直接提取用户用电模式。直接对原始序列进行聚类,因时序数据序列较长,欧式距离难以完全准确地度量序列之间的特性差异。本文结合尖峰负荷特性指标,构建用户日负荷尖峰特性特征集对用户用电行为进行聚类分析。
尖峰负荷特性指标包含尖峰负荷规模、频次、持续时间、电量占比、利用小时数,因不同数据采集粒度精细度不一致,故按如下方式提取尖峰负荷特性特征。
(1)尖峰负荷规模:使用式(1)计算各用户日尖峰负荷规模,算例统一取10%峰值百分比,即p=10%。
(2)尖峰负荷频次:对一日中用能超过尖峰负荷规模一次的单峰用户取Ct=1,双峰用户取Ct=2,以此类推。
(3)尖峰负荷电量:对尖峰负荷电量采用上取整的计算方式,则第k个用户的尖峰负荷电量Wk,t为:
式中:ci为筛选变量,当xk,i大于或等于尖峰负荷规模时取值1,否则取值0。
(4)尖峰负荷持续时间:对尖峰负荷持续时间同样采用上取整的计算方式。对单次持续时间,在负荷上升段取负荷值大于或等于尖峰负荷规模数值的右侧第一个采集点,在负荷下降段取负荷值大于或等于尖峰负荷规模数值的左侧第一个采集点,根据两个采集点采样时间差计算单次持续时间。累计持续时间等于多个单次时间累加值。
(5)尖峰负荷利用小时数:使用式(2)计算尖峰负荷利用小时数。
3.3 聚类结果评价标准
聚类结果评价标准通常分为有标签及无标签两类,在真实分类情况已知时使用有标签评价方法,分类情况未知时使用无标签评价标准。本文数据集中未提供用户类别划分标签,属于无先验信息的聚类分析场景,故采用轮廓系数(Silhouette标准)对聚类结果进行评价。第k个对象的轮廓系数S(k)计算式如式(10):

式中:b(k)表示对象k与非同簇类对象的平均距离,用以表征分离度;a(k)表示对象k与同簇类对象的平均距离,用以表征凝聚度。
轮廓系数取值范围为[-1,1],值越大说明聚类结果中,同簇类成员紧密度、不同簇类成员分离度越高,聚类性能越优良。
3.4 聚类性能对比及最优类别数量
对构建的尖峰特性指标特征集及原始数据集使用K-means算法进行聚类分析,根据聚类结果计算轮廓系数指标,轮廓系数结果随不同聚类数量的变化如图4所示。
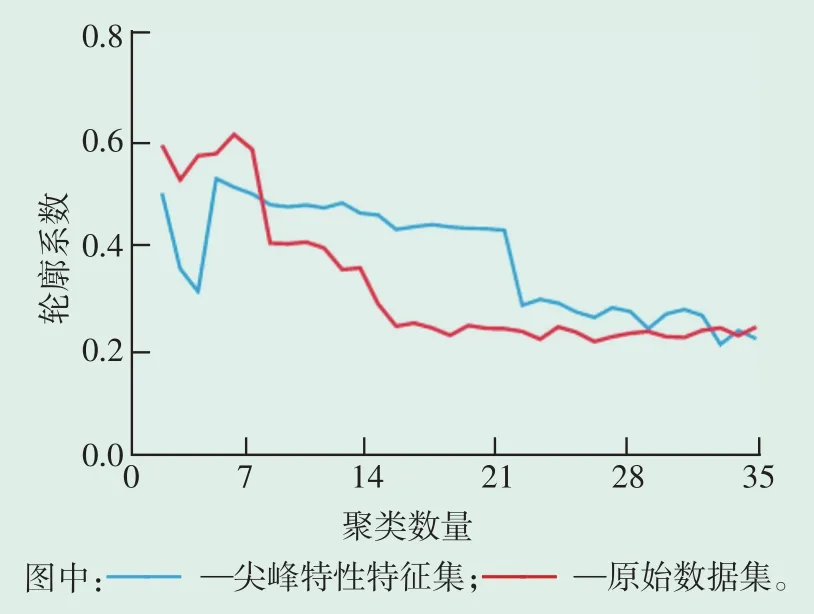
图4 不同数据集聚类性能曲线Fig.4 Clustering performance curves for different data sets
尖峰特性指标特征集在聚类数量为6时取得最佳轮廓系数0.617,优于原始数据集在聚类数量为5时的最佳轮廓系数0.523,说明使用尖峰特性指标特征集时的聚类性能较为优良。
3.5 用户用电行为特性分析
由上述分析可知,数据集中498个用户按用电模式可分为6类,第1类包含235个用户,第2类包含108个用户,第3类包含26个用户,第4类包含47个用户,第5类包含19个用户,第6类包含63个用户。各类用户负荷曲线如图5所示。
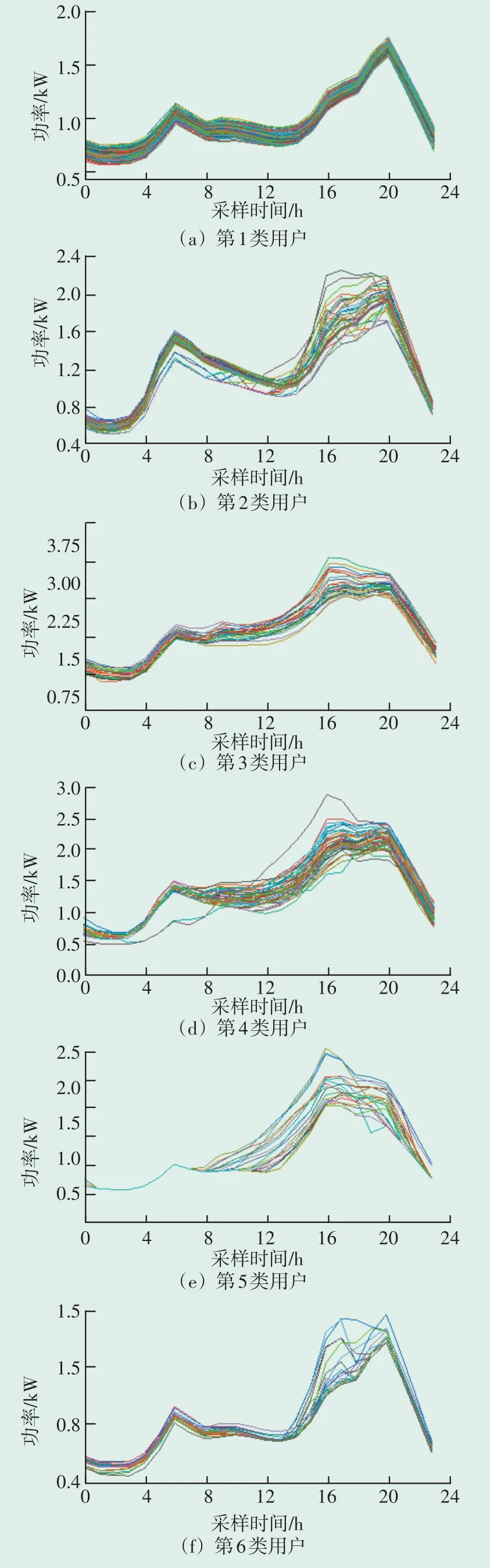
图5 各类用户负荷曲线Fig.5 Load curve of various users
由用户原始负荷曲线及分类后用户负荷曲线可以看出,样本集中的用户用电习惯在随着时间波动上具有相似性,用电谷段通常在凌晨02:00—03:00时,在早晨06:00—07:00时出现第一个用电高峰,并在16:00—20:00时达到日最大负荷后逐渐下降。
各类用户典型用能曲线尖峰特性特征汇总如表1所示。由表1可知,第1、2类用户尖峰电量在3~4 kWh、持续时间保持在2 h,属于中等耗能类用户,在样本集中占比最大;第3、4、5类用户尖峰电量在10 kWh左右、持续时间保持在4~5 h,属于高耗能用户,其尖峰规模、电量及持续时间都较其他类用户较高;第6类用户同比尖峰电量与持续时间均较低,则属于低耗能用户。
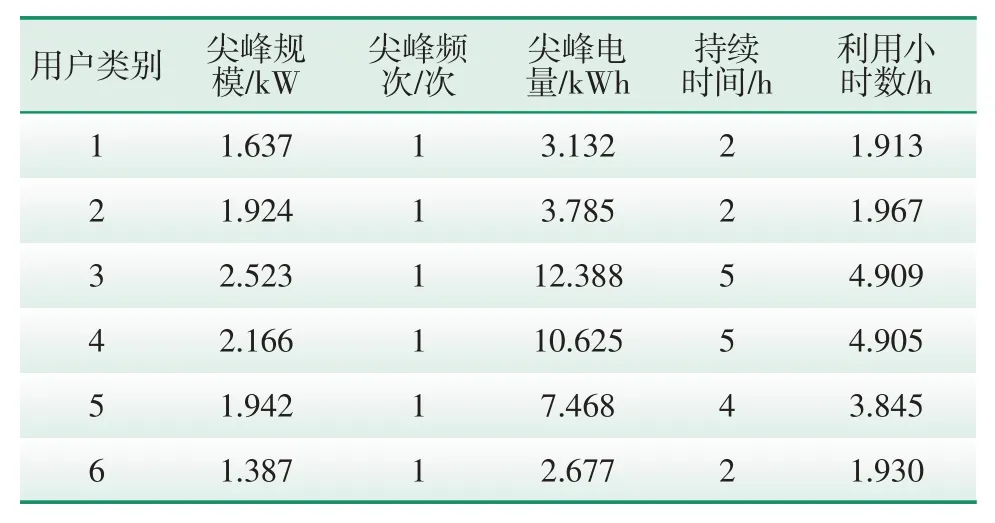
表1 各类用户典型用能尖峰特征汇总Tab.1 Summary of typical peak energy consumption characteristics of various users
通过几类用户的尖峰负荷的聚类,并分析其尖峰规模、尖峰频次、尖峰电量、持续时间、利用小时数,可以有效调整相应的用户定价方式,降低其尖峰负荷大小与持续时间,保证尖峰负荷区域的电量平衡与电压稳定。
4 结束语
针对当前用户用电行为聚类分析对尖峰负荷特性特征挖掘不足的问题,构建了用户日尖峰负荷特性指标特征集,使用K-means算法对特征集进行聚类分析并与原始数据集聚类结果进行了性能对比。算例分析结果表明,使用负荷尖峰特性特征集有效提取了原始负荷波动特征并降低了数据集维度,使聚类性能取得了一定提升。
后续研究将进一步扩充负荷特征类别,构建负荷特性特征库,并使用特征优选策略提取关键特征。同时基于聚类结果,设计相应负荷用户的分时定价方式、需求响应机制,以提高系统电量的平衡稳定。
猜你喜欢
中学生数理化·中考版(2020年12期)2021-01-18
活力(2019年15期)2019-09-25
中学生数理化·中考版(2018年12期)2019-01-31
小学生必读(中年级版)(2018年10期)2019-01-04
百科探秘·航空航天(2017年11期)2017-12-20
NBA特刊(2017年24期)2017-04-10
科技与创新(2016年24期)2017-03-30
现代管理科学(2017年1期)2016-12-26
第二课堂(课外活动版)(2015年5期)2015-10-21
太空探索(2014年4期)2014-07-19
