
具有遗忘机制的在线宽度学习算法
2023-01-17 09:00包洋,郭威,2
吉林大学学报(信息科学版) 2022年6期
包 洋, 郭 威,2
(1. 南京工业大学 计算机科学与技术学院, 南京 211816; 2. 盐城师范学院 信息工程学院, 江苏 盐城 224007)
0 引 言
动态数据流挖掘是数据挖掘领域的研究热点之一, 当前动态数据挖掘技术已渗透到许多应用领域中, 如交通流量监控与管理、 电力供应预测与管理、 金融服务分析与管理等均涌现出大量动态数据。这些数据作为一种流式数据存在, 其具有时序性、 快速变化和海量等特点, 被称为动态数据流[1]。在动态数据流环境下, 传统批量学习方法会承受高昂的再训练成本。相反, 在线学习算法可快速有效地进行模型更新, 因此在线学习方法更适合处理动态数据流问题[2]。
宽度学习系统(BLS: Broad Learning System)是由Chen等[3]提出的一种深度学习的替代框架。相较于深度学习算法, BLS有着更快的计算速度并且不会遇到梯度消失或梯度爆炸等问题, 被认为是知识发现和数据工程领域中一种极具前途的技术。BLS具有在线学习的优势, 在因新增训练数据而需要重构模型的情况下, BLS可快速地利用这些新增数据更新原有模型, 从而学习到更接近当前数据变化趋势的规律。由于BLS具有良好的特征提取和在线学习能力, 许多学者陆续提出了众多基于在线BLS的改进算法。Pu等[4]将半监督学习方法与在线BLS相结合提出了OSSBLS(Online Semi-Supervised Broad Learning System), 并将其运用于工业故障检测; Xu等[5]将BLS的增强节点替换为递归结构提出了RBLS(Recurrent Broad Learning System), 从而获得捕获时间序列数据动态特征的能力; Guo等[6]将内核递归最大相关熵引入BLS, 提出OR-ESBLS(Online Robust Echo State Structure Based RBLS)增强了算法的鲁棒性; Fan等[7]提出在线IWBLS(Incremental Wishart Broad Learning System)实现合成孔径雷达图像分类; Cui等[8]提出时空宽度学习网络(ST-BLN: Spatio-Temporal Broad Learning Networks)用于预测交通速度。
尽管上述基于在线BLS的改进算法已应用于众多研究领域, 但到目前为止鲜有针对动态数据流建模的在线BLS算法。动态数据流的属性分布会随时间演变, 要求学习模型能不断学习新的数据样本以获取最新知识, 并保持模型的快速更新, 从而对目标系统的实时状态和后续趋势做出及时、 准确的分析和预测[9]。虽然传统的在线BLS算法会学习所有到达模型的数据, 但不考虑新旧数据的时效性和新旧数据对学习模型的不同贡献。为此, 笔者将遗忘因子和滑动窗口的思想融入到在线BLS中, 提出了一种基于遗忘因子的在线BLS算法(FF-OBLS: Online Broad Learning System based on Forgetting Factor)和一种基于滑动窗口的在线BLS算法(SW-OBLS: Online Broad Learning System based on Sliding Window)。
1 宽度学习系统及其在线学习算法
1.1 宽度学习系统
宽度学习系统(BLS)是一种基于随机向量函数型网络(RVFLN: Random Vector Function-Link Network)[10]的快速高效的学习系统, 其基本结构如图1所示。
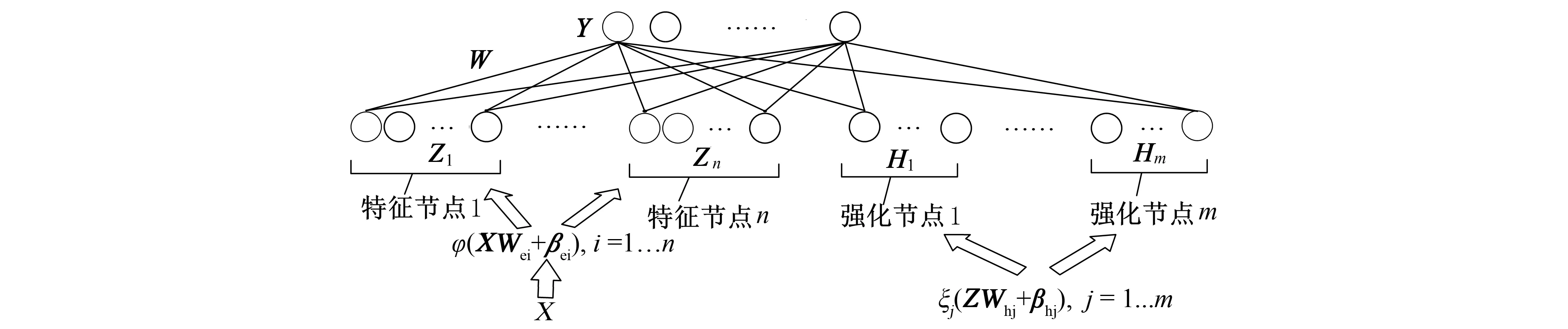
图1 宽度学习系统的结构Fig.1 Structure of broad learning system
BLS模型的训练过程总结如下。
给出训练数据集{X,Y}, 通过线性映射将输入X转换为特征节点上的随机特征, 映射层的输出表达式为
Zi=φi(XWei+βei)∈RN×S,i=1,…,n
(1)
其中φi(·)是线性变换函数;Wei和βei分别是随机生成的权重矩阵和偏置矩阵;n是特征节点组的数量,S是每组特征节点的数量。所有特征映射窗口Zi拼接组成特征映射层为
Z≜[Z1,…,Zn]
(2)
特征映射层Z经过非线性变换形成增强节点, 第j组强化节点的输出如下
Hj=ξj(ZWhj+βhj)∈RN×1,j=1,…,m
(3)
其中ξ(·)是非线性变换函数;Whj和βhj分别是随机产生的权重矩阵和偏置矩阵;m是强化节点的数量。所有增强节点Hj拼接组成增强层为
H≜[H1,…,Hm]
(4)
然后将特征映射层Z和增强层H直接连接到BLS的输出端, 结果为
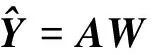
(5)
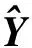
W=(CI+ATA)†ATY
(6)
其中C是正则化参数。
1.2 宽度学习系统在线学习算法
训练样本在在线宽度学习系统(OBLS: Online Broad Learning System)的实际应用场景中通常是按数据流的形式贯序到达。给定Na个新的数据样本ωa={Xa,Ya},Xa对应的特征节点Za和强化节点Ha分别为
Za=[φ1(XaWe1+βe1),…,φn(XaWen+βen)]
(7)
Ha=[ξ1(ZaWh1+βh1),…,ξm(ZaWhm+βhm)]
(8)
定义Aa≜[Za|Ha]为Xa的特征映射层和强化层的输出。增量计算整个输入特征矩阵的伪逆过程如下
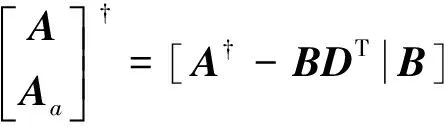
(9)
其中
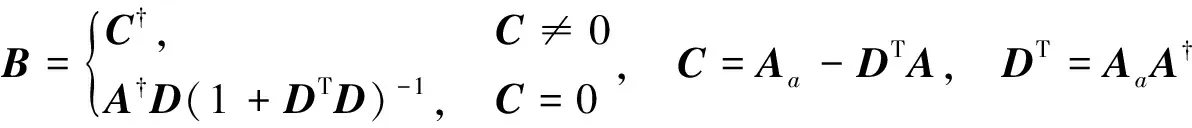
(10)
BLS的输出权值矩阵W的更新公式如下
Wnew=W+B(Ya-AaW)
(11)
2 具有遗忘机制的在线宽度学习算法
当不断有新的数据样本到达模型时, 传统的在线BLS学习算法中的数据样本矩阵会不断增大从而导致计算量的增大。并且传统在线BLS算法认为新旧数据样本的重要性相同, 即该算法不区分新旧数据对模型的贡献, 也不考虑数据样本的时效性。为了使BLS算法更适用于处理动态数据流问题, 首先对原始在线BLS算法进行改写, 并在此基础上提出两种具有遗忘机制的在线BLS算法。
2.1 对在线宽度学习系统的改进
由式(10)、 式(11)可以看出, 原始在线BLS在学习过程中是利用低阶矩阵的逆表示原矩阵的逆。该计算方法是由Grevillet[11]提出的一种分块矩阵阶数递推算法。虽然该递推算法能及时学习新的样本知识, 但递推过程中式(9)中的矩阵A需要存储所有样本信息, 使样本矩阵的存储量不断增大从而导致计算量的增大。对动态数据流环境, 上述递推算法在大量实际应用中难以实现。为克服分块矩阵阶数递推算法的缺点, 根据新的Moore-Penrose广义逆阶数递推公式[12]将OBLS算法进行改进。计算初始化权值

(12)
其中

(13)
A0≜[Z0|H0]是初始化训练数据集X0的特征映射层和强化层的输出;Y0是给出的初始训练数据集的标签矩阵。
在线学习阶段, 当获得第k个新的训练数据块ωk=(Xk,Yk)时, 可根据
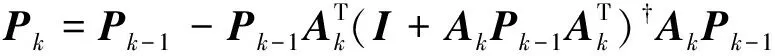
(14)

(15)
递推计算出权值。其中Ak≜[Zk|Hk]是Xk的特征映射层和强化层的输出;Yk是给出的Xk的标签矩阵。
2.2 基于遗忘因子的FF-OBLS算法
对有些时变系统, 新旧数据样本之间具有差异性, 相比之下, 新样本更能反映系统变化趋势。为体现新旧样本的差异性, 笔者将遗忘因子的思想融入BLS并提出了FF-OBLS模型。遗忘因子的核心思想是根据数据样本到达的时间次序赋予每个(块)数据样本不同的权值, 以体现新旧样本的不同贡献。
在BLS模型初始化训练数据块ω0=(X0,Y0)后, 初始的输出权值W0和P0可由式(12)、 式(13)计算得到。进入在线学习阶段时, 当获得一个新的数据样本块ω1=(X1,Y1), 可计算出样本矩阵X1变换后的输入矩阵A1≜[Z1|H1], 其中Z1和H1分别是BLS特征映射层的输出和强化层的输出。由于ω1比ω0更能反映当前数据的特征和趋势, 因此FF-OBLS模型中,ω1的权重应大于ω0, 以反映新旧样本之间的差异。为此引入遗忘因子λ, 0<λ≤1调整ω1和ω0的权重。
定义W1为第1次更新后的输出权值, 通过

(16)
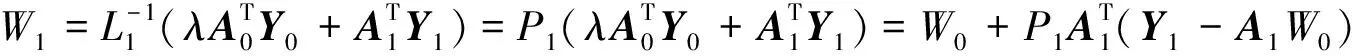
(17)
类似地, 当第k个数据块ωk=(Xk,Yk)进入模型训练时, 可计算出样本矩阵Xk变换后的输入矩阵Ak≜[Zk|Hk], 其中Zk和Hk分别是BLS特征映射层的输出和强化层的输出。由式(17)类推, 输出权值的更新过程如下
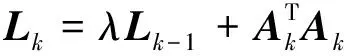
(18)
则Wk可通过

(19)
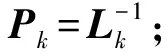

(20)
当λ=1时,P的更新公式与式(14)相同, 此时算法退化为原始OBLS算法。
算法流程如下:
1) 获取初始训练数据集, 并设置合适的遗忘因子λ;
2) 根据宽度学习算法初始化学习模型, 由式(12)、 式(13)分别计算出W和P;
3) 获取新的数据, 根据式(7)、 式(8)计算出Z和H, 令A=[Z|H];
4) 利用式(19)、 式(20)更新W和P;
5) 若有新的数据到达模型, 则重复步骤3)和步骤4)的算法更新W和P。
2.3 基于滑动窗口的SW-OBLS算法
在某些应用场景, 数据样本往往具有一定的时效性, 即样本仅在一段时间内有效。为消除失效的旧样本对模型的影响, 笔者将滑动窗口的思想融入BLS并提出了SW-OBLS模型。滑动窗口策略是一种消除过时样本的方法, 其核心思想如下: 在线学习过程中需要设置一个滑动窗口, 其大小需要覆盖当前有效样本的数量。当新的样本块输入模型训练时, 若此时所有数据样本的数量相加超过滑动窗口的大小, 则需要删除距离当前时刻最远的旧数据块, 以逐步摆脱旧样本对当前学习模型的影响。

P0=P0+P0T(I-P0T)-1P0
(21)

(22)
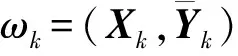

(23)

(24)
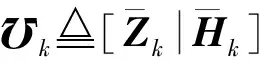
算法流程如下:
1) 获取初始训练数据集, 并且设置合适的滑动窗口SW;
2) 根据宽度学习算法初始化学习模型, 由式(12)、 式(13)分别计算出W和P;
3) 若初始训练数据集的数量大于SW, 则需根据式(21)、 式(22)更新W和P;
4) 获取新的数据, 根据式(7)、 式(8)计算出Z和H, 令A=[Z|H];
5) 若此时模型中的数据和新数据的数量之和小于或等于SW, 根据式(14)、 式(15)更新W和P;
6) 若此时模型中的数据和新数据的数量之和大于SW, 需根据式(23)、 式(24)更新W和P;
7) 若有新的数据到达模型, 则重复步骤4)的算法并且根据条件选择步骤5)或步骤6)更新W和P。
3 实验及结果分析
为验证提出的SW-OBLS和FF-OBLS算法的有效性, 使用一个模拟动态数据集和一个具有结构突变特征的真实数据集进行实验, 并将OBLS算法、 OSELM(Online Sequential Extreme Learning Machine)[13]算法、 FOS-ELM(Online Sequential Extreme Learning Machine with Forgetting Mechanism)[14]算法与提出的SW-OBLS和FF-OBLS进行比较。实验结果采用均方根误差(RMSE: Root Mean Square Error)作为准确性和泛化的度量标准, OBLS、OSELM、FOS-ELM、FF-OBLS和SW-OBLS的所有激活函数均采用“Sigmoid”函数, 并且实验结果均为同一台PC进行30次相同实验的统计结果。
3.1 时变系统的预测
使用人工的非平稳时间序列数据集模拟时变模型中数据的动态性。数据集共包含3 000个数据样本, 每个数据样本的输入包含4个随机变量, 并且这些随机变量是由均值为0和标准差为0.1的正态分布随机生成; 每个数据样本的输出是4维输入向量和相应系数的4维向量的内积。在该时变系统中, 每个样本的系数都随着时间不断变化[15]。设定系数向量的初始值为
a(0)=[0.5 0.2 0.7 0.8]
(25)
随后这些值根据

(26)
随时间变化。其中sig(·)是“Sigmoid”函数,i是样本序号,j是系数向量的分量下标, 即j=1,2,3,4。为使实验更具真实性, 在该数据集中添加了均值为0和标准差为10-5的高斯噪声。
采用OBLS、OSELM、FOS-ELM、FF-OBLS、SW-OBLS 5种算法对时变系统进行在线建模和预测。BLS的结构由4个参数决定: 特征映射节点的组数N1, 每组中特征节点个数N2, 强化节点的组数N3和每组中强化节点的个数N4。为使各宽度学习系统既有较好的特征提取能力又不会使结构过于复杂, 令各宽度学习系统的N4=1, 即各宽度学习系统只有一组强化节点。使用人工的非平稳时间序列数据集在BLS模型上对N1、N2、N3遍历取值实验后, 选取预测精度较优的结构参数作为各宽度学习系统的结构参数, 因此设置OBLS、FF-OBLS、SW-OBLS算法的结构参数N1=8;N2=4;N3=32;N4=1。OSELM与FOS-ELM的隐藏层节点数设置为30。初始化模型所需的训练数据数量均为300个, 在线学习阶段每次训练的样本数量为5。由于上述算法在运算过程中可能会产生病态矩阵, 需要对病态矩阵进行正则化处理, 实验中所有正则化参数c均取2-20。对SW-OBLS模型多次选取不同的Sw值进行实验, 再分别对在线学习阶段的前500、1 000、1 500、2 000、2 700个数据样本求均方根误差(RMSE), 实验结果如图2所示。对FF-OBLS模型, 需要确定其遗忘因子λ的大小。该实验采用静态遗忘因子方法, 分别多次选取不同的遗忘因子λ进行实验, 再分别对在线学习阶段不同预测步长的数据求均方根误差(RMSE), 实验结果如图3所示。

图2 SW-OBLS在不同滑动窗口下的平均RMSE 图3 FF-OBLS在不同遗忘因子下的平均RMSE Fig.2 Average prediction RMSE of SW-OBLS Fig.3 Average prediction RMSE of FF-OBLS under different sliding window under different forgetting factor
根据滑动窗口策略可知, 当SW-OBLS算法的Sw设置为3 000时, SW-OBLS退化为原始OBLS算法, 即在线学习过程中没有任何数据样本被“遗忘”。由图2可以看出, 当Sw设置合理时, SW-OBLS在各预测步长下的预测精度均优于OBLS。但是Sw不宜设置得过小或过大,Sw=100时的预测精度明显不如Sw=300时的预测精度。当Sw设置过小时, 甚至会出现SW-OBLS的预测精度比原始OBLS的预测精度更差的情况。这正是由于滑动窗口策略的局限性导致的, 因为滑动窗口越小, 模型中包含的数据样本知识就越少, 当数据流随时间的波动性不强时, 学习模型会过快“遗忘”样本知识, 从而导致算法欠拟合。当Sw设置越大, SW-OBLS算法的预测精度会越趋近于OBLS, 算法性能不能达到要求。对FF-OBLS模型, 当λ设置为1时, FF-OBLS退化为原始OBLS。由图3所示,λ的取值不能太小, 当λ=0.95时, FF-OBLS算法已经开始有发散的趋势。这是由于算法在迭代过程中旧的数据样本矩阵会乘以λk,k表示算法迭代的次数。λk会随着迭代次数的增加逐渐趋近于0, 算法中正则化项的功能会逐渐被减弱直至完全消失, 从而导致算法产生病态矩阵引起发散。
将Sw设置为330的SW-OBLS模型、λ设置为0.96的FF-OBLS模型和原始OBLS模型、 OSELM模型和FOS-ELM模型进行比较, 其中FOS-ELM的滑动窗口设置为300。实验结果如表1所示。各算法的在线训练阶段时间开销如表2所示。由表1可知, 在选择合理参数情况下, SW-OBLS和FF-OBLS不同预测步长下的预测精度都小于OBLS。这说明基于滑动窗口的SW-OBLS和基于遗忘因子的FF-OBLS能更准确捕捉数据的变化趋势并且做出更精确的预测。同时OBLS的预测精度优于OSELM的预测精度, SW-OBLS和FF-OBLS的预测精度也优于FOS-ELM, 可以看出基于BLS的算法性能的优越性。虽然ELM与BLS都通过求伪逆获得输出权重, 但BLS的隐藏层构成比ELM更丰富, 它包含了输入数据的线性特征(特征节点)和非线性特征(增强节点), 这意味着BLS具有更好的特征提取能力。由表2可知, SW-OBLS和FF-OBLS的时间开销要明显小于OBLS。

表1 时变系统上不同预测步骤下各模型平均RMSE

表2 时变系统上各模型的时间开销
3.2 结构突变数据的预测
实验使用具有结构突变特性的空气质量数据集评估提出的SW-OSBLS和FF-OSBLS的有效性。该数据集收集于2004年3月-2005年2月, 收集地点位于意大利一座污染严重的城市。经过预处理后的数据集包含6 900个数据样本, 数据样本包含9个属性, 包括平均每小时检测到的PT08.S1(氧化锡)、 苯浓度、 PT08.S2(二氧化钛)、 PT08.S3(氧化钨)、 PT08.S4(二氧化氮)、 PT08.S5(氧化铟)、 温度、 相对湿度和绝对湿度。使用传感器每小时平均检测到的PT08.S3 (氧化钨)作为输出, 其余属性作为输入进行预测实验。
使用该真实数据集在OSBLS、OSELM、FOS-ELM、SW-OSBLS和FF-OSBLS上进行多次不同预测步长实验, 再选取预测精度较优的结构参数进行对比实验, 设置各宽度学习系统的结构参数N1=4,N2=7,N2=61,N4=1, SW-OSBLS的Sw设置为400, FF-OSBLS算法的λ设置为0.986。初始化模型的训练集数量为500个。各模型在不同预测步长下的RMSE如表3所示, 在线训练阶段的时间开销如表4所示。

表3 空气质量数据集上不同预测步骤下各模型平均RMSE

表4 空气质量数据集上各模型的时间开销
由表4可以看出, SW-OBLS和FF-OBLS在时间开销上明显优于传统OBLS。根据表3可知, 基于OBLS的改进模型在精度上优于基于OSELM的模型, SW-OBLS和FF-OBLS在预测步长1 500内的预测精度相差不大, 但SW-OBLS在预测步长3 000及以后的预测精度都明显优于其余算法。由此可以看出, SW-OBLS更适用于处理结构突变特征的时变应用场景。
3.3 SW-OBLS与FF-OBLS的比较分析
虽然SW-OBLS和FF-OBLS都是基于BLS的改进算法, 但其算法思想的不同也导致了它们在计算复杂度、 使用灵活度、 稳定性等方面存在差异。从算法计算复杂度分析, 由于OBLS算法在线学习过程中需要存储所有样本信息, 因此样本数据的储存量和计算量都在不断增大。SW-OBLS通过一次较为复杂的迭代计算完成, 而FF-OBLS的模型更新公式与Moore-Penrose广义逆阶数递推公式同样具有简洁性。从使用灵活性角度分析, 对于FF-OBLS, 若将旧数据样本的遗忘因子设置为0, 将有效数据样本的遗忘因子设置为1, 则SW-OBLS可看作是FF-OBLS的一种特例。这表明基于遗忘因子的SW-OBLS具有更高的灵活度。在稳定性方面, 由于遗忘因子的引入, FF-OBLS的计算过程中会更容易出现病态矩阵从而造成算法的发散。虽然引入正则化技术可有效缓解病态矩阵的出现, 但当遗忘因子过小时, 该稳定性也无法持续。对于SW-OBLS, 若滑动窗口设置越大则越稳定, 但将牺牲算法遗忘机制的性能。
综上, SW-OBLS算法简单直观, 在结构突变特征的时变应用场景中有较理想的效果。FF-OBLS在计算效率的灵活性上更具优势, 适合处理一些复杂时变特征的应用场景。
4 结 语
由于动态数据流具有连续性和变化性, 传统宽度学习算法不能对目标系统的实时状态和后续趋势做出及时、 准确的分析和预测。笔者提出了两种具有遗忘机制的在线宽度学习系统算法, 通过将遗忘因子思想和滑动窗口策略分别运用到传统在线宽度学习算法中, 使FF-OBLS算法能区分新旧数据样本的不同贡献, SW-OBLS算法能根据数据的时效性丢弃旧的数据样本。相比于传统宽度学习系统, 笔者提出的方法可以更精确、 更及时地捕捉动态数据流的变化趋势, 并且能有效提升模型的训练速度。
参考文献:
[1]翟婷婷, 高阳, 朱俊武. 面向流数据分类的在线学习综述 [J]. 软件学报, 2020, 31(4): 912-931.
ZHAI Tingting, GAO Yang, ZHU Junwu. Survey of Online Learning Algorithms for Streaming Data Classification [J]. Journal of Software, 2020, 31(4): 912-931.
[2]HOI S, SAHOO D, LU J, et al. Online Learning: A Comprehensive Survey [J]. Neurocomputing, 2021, 459: 249-289.
[3]CHEN C, LIU Z. Broad Learning System: An Effective and Efficient Incremental Learning System without the Need for Deep Architecture [J]. IEEE Transactions on Neural Networks & Learning Systems, 2018, 29(1): 10-24.
[4]PU Xiao, LI Chunguang. Online Semi-Supervised Broad Learning System for Industrial Fault Diagnosis [J]. IEEE Transactions on Industrial Informatics, 2021, 17(10): 6644-6654.
[5]XU M, HAN M, CHEN C, et al. Recurrent Broad Learning Systems for Time Series Prediction [J]. IEEE Transactions on Cybernetics, 2020, 50(4): 1405-1417.
[6]GUO Yu, YANG Xiaoxiao, WANG Yinuo, et al. Online Robust Echo State Broad Learning System [J]. Neurocomputing, 2021, 464: 438-449.
[7]FAN Jianchao, WANG Xiang, WANG Xinxin, et al. Incremental Wishart Broad Learning System for Fast PolSAR Image Classification [J]. IEEE Geoscience and Remote Sensing Letters, 2019, 16(12): 1854-1858.
[8]CUI Ziqiang, ZHAO Chunhui. Spatio-Temporal Broad Learning Networks for Traffic Speed Prediction [C]∥2019 12th Asian Control Conference (ASCC). Kitakyushu, Japan: IEEE, 2019: 1536-1541.
[9]郭威, 于建江, 汤克明, 等. 动态数据流分析的在线超限学习算法综述 [J]. 计算机科学, 2019, 46(4): 1-7.
GUO Wei, YU Jianjiang, TANG Keming, et al. Survey of Online Sequential Extreme Learning Algorithms for Dynamic Data Stream Analysis [J]. Computer Science, 2019, 46(4): 1-7.
[10]CHEN C L P, WAN J Z. A Rapid Learning and Dynamic Stepwise Updating Algorithm for Flat Neural Networks and the Application to Time-Series Prediction [J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 1999, 29(1): 62-72.
[11]GREVILLET N E. Some Applications of the Pseudoinverse of a Matrix [J]. SLAM Review, 1960(2): 15-22.
[12]ZHOU Jie, ZHU Yunmin, RONG X, et al. Variants of the Greville Forumula with Applications to Exact Recursive Least Squares [J]. SIAM Journal on Matrix Analysis & Applications, 2002, 24(1): 150-150.
[13]LIANG N, HUANG G, SARATCHANDRAN P, et al. A Fast and Accurate Online Sequential Learning Algorithm for Feedforward Networks [J]. IEEE Transactions on Neural Networks, 2006, 17(6): 1411-1423.
[14]ZHAO J, WANG Z, DONG S P. Online Sequential Extreme Learning Machine with Forgetting Mechanism [J]. Neurocomputing, 2012, 87(15): 79-89.
[15]PEREZ-SANCHEZ B, FONTENLA-ROMERO O, GUIJARRO-BERDINAS B, et al. An Online Learning Algorithm for Adaptable Topologies of Neural Networks [J]. Expert Systems with Applications, 2013, 40(18): 7294-7304.
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
数学学习与研究(2017年3期)2017-03-09
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
中国老区建设(2016年1期)2016-02-28
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
人生十六七(2015年5期)2015-02-28
西南学林(2011年0期)2011-11-12
销售与市场·管理版(2009年21期)2009-09-03
