
基于LDA模型和卡方检验的网络暴力话题挖掘方法
2023-01-17 04:47:40刘玉文
西昌学院学报(自然科学版) 2022年4期
谢 静,刘玉文
(蚌埠医学院 a.公共基础学院; b.卫生管理学院,安徽 蚌埠 233030)
0 引言
随着交互式多媒体网络技术的迅速发展,网络上出现了众多自媒体交互平台(如抖音、快手、小红书等)。自媒体平台的无限上传、转发、评论、点赞等互动功能,使信息交互更加快捷多样,人们只要拥有一部智能手机就能轻松成为一个自媒体人。由于网络的跨时空特性[1],社会热点事件极易在网上形成热点话题,加速了网络舆情的形成。
目前,由于网络缺乏道德约束和有效的监管[2],网络上滋生着大量网络暴力,网络话题是网络暴力的主要载体。由于网络具有无边界性[3],暴力话题一旦形成,围观网民数量会迅速增长,对当事人会造成非常大的心理伤害。网络暴力的存在严重破坏了网络生态环境,阻碍了社会的和谐发展,所以,开展网络暴力话题识别研究有助于对网络暴力进行组织分类,对舆情管控和引导具有十分重要的意义。
从交互式网络技术出现以来,网络暴力就随即出现。随着自媒体技术的普及应用,网络暴力更加盛行。网络暴力的形成涉及网络、社会、心理等多种因素,一直以来都是网络舆情领域研究的重点[4]。为了应对网络暴力给社会生态文明带来的冲击,降低网络暴力危害,众多学者从多个层面开展了相关研究工作。刘绩宏等[5]从道德层面分析了网络暴力演化过程中的影响因素,并以821位网民的上网数据为基础,构建了网民心理和行为的结构方程模型,发现道德焦虑能够使网民对相关主体产生消极的道德判断,从而促使网民实施网络暴力行为;石经海等[6]从法律层面分析了网络暴力刑法规制的困境,建议将网络暴力现象纳入相关法律治理体系中予以立体化治理,增设网络暴力罪,以解决网络暴力刑事责任追究难的问题;田圣斌等[7]从社会管理层面分析法律在应对网络暴力时存在的缺陷,强调网络暴力治理首先要精准识别网络暴力,然后实施阶段性治理举措,加强行政干预,规范网络治理行为,实现网络社会的综合治理。上述研究主要从社会和心理行为角度分析了网络暴力形成原因及治理方式,为网络暴力的管理提出了新思路,但存在的问题是不能从网络大数据上了解网络暴力特性,无法运用技术手段对网络暴力进行引导。为了能及早探测网络暴力,缩短舆情干预响应时间,一些学者从网络本身入手研究网络暴力形成及发展规律,提出了观点演化[8]、主题识别与演化[9]、情感计算[10]、社区发现[11]等相关技术。谷学汇[12]针对网络暴力单一模态检测方法精度低等问题,提出了基于文本、视频以及音频多模态融合算法,将文本、视音频分类器当作预分类器完成视频的初始分类,获得候选暴力影视集,随后再运用视音频分类器对候选集进行分类,最终完成对网络暴力的识别;范涛等[13]为了提高负面情感内容识别精度,提出了基于图卷积神经网络和依存句法分析的网民负面情感分析模型,该模型运用双向长短期记忆网络和自注意力机制抽取文本特征作为依存句法图中的节点特征,再应用图卷积神经网络对生成的节点特征邻接矩阵进行训练学习,输出负面情感类别。以上研究成果实现了暴力内容的精确查找,但存在的问题是网络暴力组织属性识别能力较差,无法实现网络事件与网络暴力的关系映射。
针对上述问题,本文提出了一种基于LDA模型和卡方检验的网络暴力话题识别方法。该方法首先运用LDA模型对网络数据进行主题分类,然后再用卡方检验对主题内暴力特征进行识别,最后通过情感计算技术定量计算话题内的暴力密度,依据密度阈值对网络暴力主题进行识别。
1 相关技术介绍
1.1 卡方检验
社交网络中,文本形式的语言暴力(以下简称文本暴力)是网络暴力的主要表现形式,文本暴力语言带有强烈的负面情感特征。本质上说,文本暴力识别是自然语言处理技术的一种具体应用。识别过程包括:文本分词、特征词提取、情感计算、语义关联等,其中特征词提取是关键。目前,文本特征词识别方法[14]主要包括信息增益法、文档频率法及卡方检验法等,其中卡方检验法是常用的文本特征选择方法。
卡方检验[15]是用于度量样本理论推断值与实际观测值相关程度的统计方法,卡方值越大,表明二者相关性越大,卡方统计量用χ2表示,计算公式如(1)所示。

式中:变量Fi表示特征;Cj表示特征类别;m表示训练数据集内文本个数;a表示包含Fi的Cj类文本数量;b表示包含Fi的非Cj类文本数量;c表示不包含Fi的Cj类文本数量;d表示不包含Fi的不属于Cj类文本数量。
1.2 LDA模型
1.2.1 模型描述
隐狄利克雷分配(Latent Dirichlet Allocation,LDA)是一种基于无监督学习的文档生成模型[16]。该模型认为一篇文档包含多个主题,每个主题又对应着不同词汇;一篇文章的构造过程依赖文档、主题、词汇之间的概率假设。首先文档以一定的概率选择某个主题,然后主题又以一定的概率选择某个词,不断重复执行这个过程,直到完成整个文档的生成为止。LDA模型根据文档生成的逆过程,对文档主题特征和主题词汇特征进行学习,把文档建模成主题分布,又把文档中的主题建模成词汇分布。从生成过程来看,LDA模型是一个3层贝叶斯网络,根据概率依赖关系,定义了4个变量:文本-主题分布矩阵θ,主题-词汇分布矩阵φ,主题向量Z以及词汇W。
1.2.2 模型参数介绍
除了4个变量之外,LDA模型还包含2个超参数α和β。Z是隐变量,W是唯一可实际观测到的文档词汇。各变量在模型中的含义如表1所示,模型结构如图1所示。

表1 LDA模型变量含义
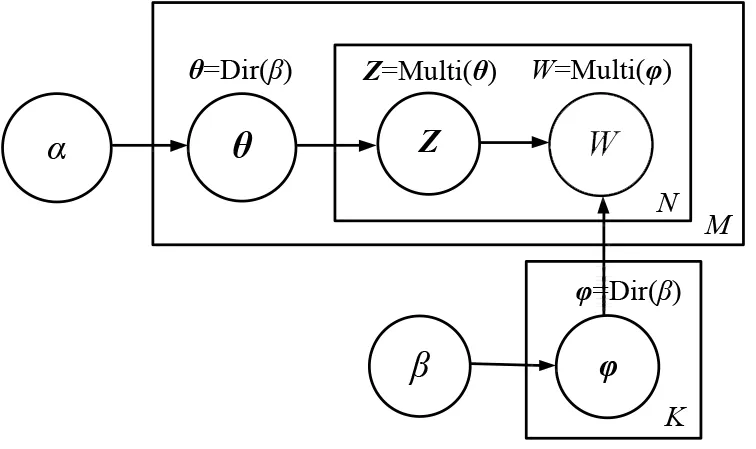
图1 LDA模型的贝叶斯网络结构
1.2.3 文档生成公式
LDA模型先运用超参数α生成一个文档主题概率分布,然后运用β生成N个主题概率分布,最后生成整篇文档的N个词的联合概率,如式(2)所示。

由于θ和Z是隐变量,需要对其进行边缘概率求解,从而消除θ和Z,最后计算得到文本中每个单词的生成概率,计算公式如(3)所示。

通过文档中可观测的词汇,运用吉布斯采样过程对公式(3)进行反复迭代,并利用最大期望算法(Expectation Maximization,简称EM算法)对参数θ和φ值进行估计,最终训练出文档-主题分布矩阵θ和主题-词汇分布矩阵φ。虽然LDA模型存在着运算效率高、建模方便等诸多优点,但也存在着主题数K需要依赖人为经验事先设定等缺陷,大大增加了建模结果的不确定性。
1.2.4 动态话题数计算
为了降低主题数人为设定给建模结果带来的影响,研究者提出了一系列动态主题数计算方法。其中,基于贝叶斯主题数计算方法是最流行的方法,计算公式如(4)和(5)所示。
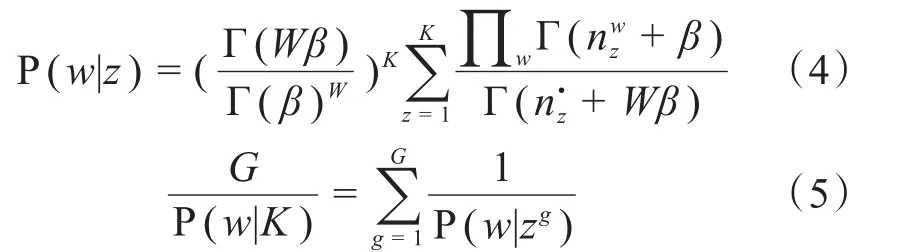
式(4)~(5)中:Γ(x)是伽马函数;nzw表示主题z内词汇w出现的次数;nz▪表示主题z内词汇总数;K表示主题数量;G表示吉布斯采样次数;zg表示第g次采样时的主题。。
结合公式(4)和(5)对P(w|K)进行求解,当P(w|K)达到极值时,选择K值为最优主题数。
2 网络暴力话题识别方法
网络暴力话题识别包括2个步骤:第1步,运用主题模型从语料文本中对主题进行识别,构造出文档-主题和主题-词汇2个分布矩阵;再用主题词与文档进行相似度计算,对文档进行主题文本分类,得到主题文本集。第2步,对每个主题文本集进行暴力特征筛选,运用情感计算技术计算话题的暴力情感值,根据暴力密度阈值对话题的暴力属性进行判断。具体识别过程如图2所示。
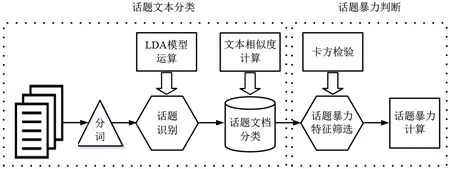
图2 暴力话题识别流程
网络暴力是网络文本内的一种情感形式,带有强烈的负情感,所以,网络暴力可以借助情感实现定量计算。本文运用话题暴力密度作为判定话题暴力属性的依据,话题暴力密度含义如定义1所示。
定义11:话题暴力密度 设话题z由话题词汇集A={w1,w2,…,wx}表示,话题内暴力词汇集B={wc1,wc2,…,wcy}表示,且B⊆A,则话题z的暴力密度TD(z)指B内词汇情感绝对值之和与A内所有词汇情感绝对值之和的比值,计算公式如(6)所示。
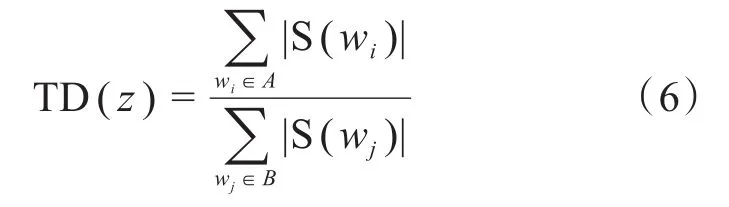
式中:S(w)表示词汇w的情感计算函数。当TD(z)大于设定的阈值时,则判定话题z为暴力话题。
2.1 话题文本分类
话题文本分类的目的是把文本按照话题进行划分,获取话题文本集。话题文本分类需要运用话题识别和相似度计算2项技术。话题识别技术是为了挖掘语料文本中隐含的话题,相似度计算技术是为了计算话题特征词与文本的相似度,从而实现依据主题对文档进行归类。本文运用的话题识别技术是LDA模型,该模型通过对网络语料库D进行建模,分别生成大小为M×K的文档-主题分布矩阵θ和大小为K×N的主题-词汇分布矩阵φ。其中,φ的行代表主题,列代表词汇。对每行词汇生成概率按大小进行排序,选择Top-K词汇作为主题特征词。
从LDA建模原理可以看出,LDA模型本身不能完成话题文本分类,但主题-词汇分布矩阵φ中的话题特征词为文本分类提供了聚类特征。在文本语料中,语义环境是判断词汇相似的重要依据。设主题zi=[w1,…,wK],文本di=[w1,…,wN],对于zi中任意词汇wk和di中任意词汇wn,如果wk和wn在同一语境中共现频次较大,满足设定的相似度阈值时,则wk和wn就具有相关相似性,即可判定wk和wn属于同一主题。由于语境对词汇意义表达影响较大,文本运用基于对称差的KL距离来进行主题与文本的相似度计算。
KL 距离[15](Kullback-Leibler Divergence)用来度量2个概率向量在相同事件空间内分布的差异性。假设X=[x1,x2,…,xn]和Y=[y1,y2,…,yn]是2个概率分布向量,则X和Y差异性计算公式如(7)所示。
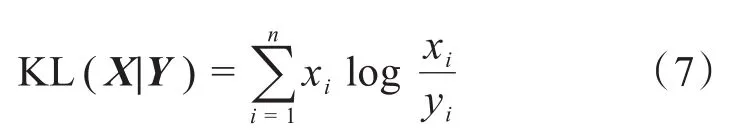
式(7)中,KL(X|Y)值越小,X和Y的差异性就越小,说明X和Y的相似性就越高。但KL距离公式存在的缺陷是不具有对称性[14],即 KL(X|Y) ≠KL(Y|X),在实际运用时受到时序因素影响较大。为了弥补这个缺陷,本文在KL距离的基础上引入相对熵概念,通过变量之间的双向KL距离计算消除变量次序对计算结果的影响,建立了X和Y对称差异性计算方法,如式(8)所示。
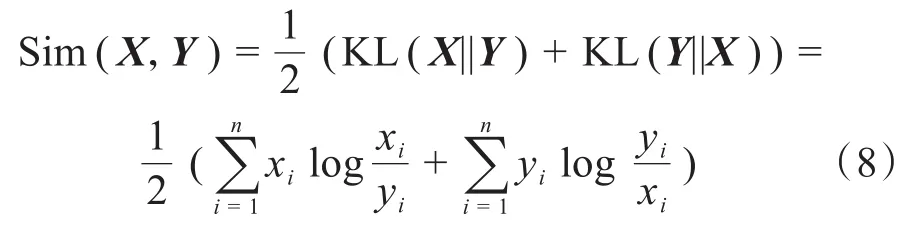
对于主题zi=[w1,..,wK]与文本di=[w1,..,wN],通过公式(8)就可得到zi和di的相似度。运用上述方法,依次把主题-词汇分布矩阵φ中的主题zi与语料库中所有文本进行相似度计算,再把与zi相似度高的文本归类在一起,得到话题zi的文本集,最终完成所有主题的文本分类。
2.2 话题内暴力特征分类器建立
话题文本分类完成后,下一个重要核心任务是在话题文本内进行暴力特征词筛选,为话题暴力定量计算提供特征词组集。如上文所述,从情感角度来说,网络暴力语言带有极强的负面情感,但负面情感不一定都是暴力语言。一般来说,文本集内暴力特征词集是负面情感词的子集。负面情感特征用情感词典很容易计算得到,但如何从负面情感词中筛选出暴力词是本文的难点。本文采用χ2检验作为文本特征筛选方法,以初始的话题暴力词作为种子词对负面词汇集进行反复迭代,并逐步提升每次迭代的检验阈值,直到遍历完所有候选词为止,具体筛选过程如图3所示。
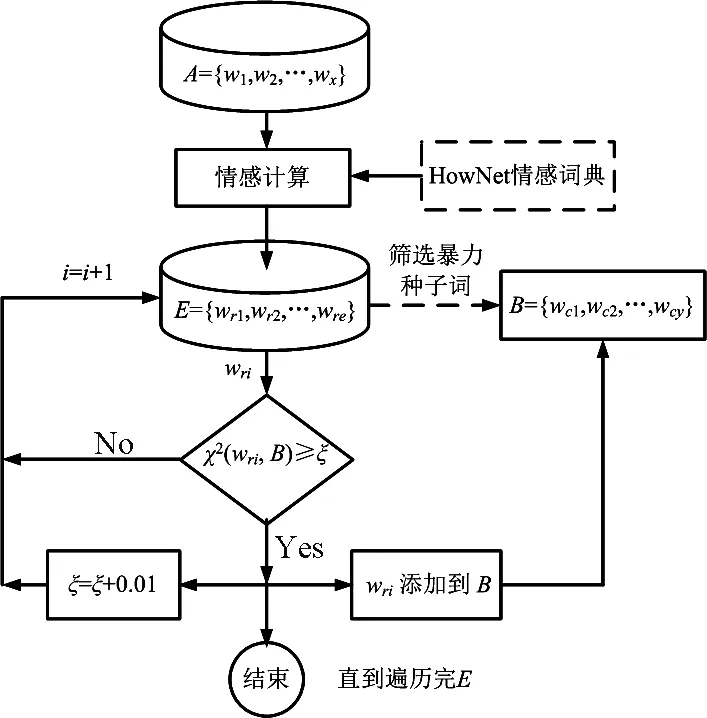
图3 基于χ2检验的网络暴力特征词筛选过程
基于χ2检验的话题暴力特征词筛选过程包括以下几个步骤:
第1步:运用情感词典HowNet对话题词汇集A中的词汇进行情感计算,得到每个词汇的情感值,并筛选出负情感词汇集E。
第2步:在负情感词集E中,按情感值大小对情感词排序,用人工方式挑选出负面情感最强烈的10个词作为暴力种子词存放在暴力词汇集B中。
第3步:遍历负情感词集E中所有词汇,利用卡方检验依次对所有词汇进行特征计算。设定χ2检验阈值ξ=0.90。如果χ2(wi,B)≥ξ,则判定wi为暴力词,并把wi添加到暴力词汇集B中,增加检验阈值ξ,使得ξ=ξ+0.01,并返回到第2步;否则直接返回到第2步。
第4步:反复执行上述过程,直到选不出暴力特征词为止,最终得到暴力词汇集B。
2.3 话题暴力计算与识别
话题暴力计算是运用话题暴力词汇集B计算出话题暴力的程度。通常情况下,由于网民存在认知偏差,大多数网络话题内或多或少都存在着暴力成分,但并不是说话题内含有暴力成分就判定该话题一定是暴力话题。只有当暴力成分在话题内占比达到或超过一定比重时才能判定为暴力话题,这个比值用暴力密度来表示。文本暴力与情感具有很强的相关性,所以,暴力计算可以借助情感计算技术来实现。由于修饰词的存在,修饰词对实体情感词的影响较大,在情感计算时需要结合修饰词进行综合计算。
2.3.1 词语的修饰处理
修饰词包括2个属性:一是词性,二是位置。从文本词性语义分析来看,形容词、副词及否定词对实体词的情感表达影响较大。另外,否定词的位置也是影响实体词情感表达的重要因素,比如“很不好”和“不很好”二者表达的情感相差很大。所以,在进行情感计算时一定要考虑实体情感词的上下文语义环境。为了方便计算,文本运用语义词来刻画情感词的上下文关系,具体形式如定义2所示。
定义 22:语义词设一个五元组w=<we, Neg,Adv, Pos, Q>是个语义词,we表示主题内情感实体词,Neg表示we的否定前缀,Adv表示we的修饰前缀,Pos表示否定词位置,Q表示we的极性。
语义词w的情感计算过程如下:按照文本顺序读取一个词we,首先判断we是否为情感实体词,如果是,则根据we在文本中的位置读取出前缀词,并对前缀词进行词性判断,按公式(9)对we进行情感计算;否则读取下个词语,并重复上述过程。
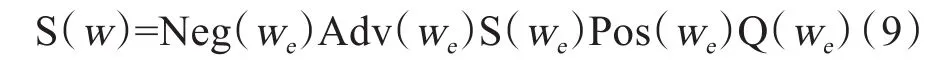
式中:Neg(we)表示we的否定权重;Pos(wn)表示否定词的位置权重;Q(we)表示情感翻转系数;Adv(we)表示we修饰权重。其中,Neg(we)和 Adv(we)可进一步分解,分解公式分别如式(10)和(11)所示。

式(10)~(11)中:t表示否定词出现的次数;V表示修饰词出现的数量。根据文本语义规则,否定词位置影响着修饰词对情感实体词的修饰程度,本文对否定词的位置权重做如下规定:若否定词在修饰词前,则 Pos(wn)取值为 0.5;若在修饰词后,则取值为1。
2.3.2 话题暴力计算
通过卡方检验从话题负情感集E中筛选出话题暴力特征词,按照式(9)计算每个暴力词的情感值,然后再对所有暴力词进行情感求和,得到话题暴力值。由于网络暴力值是负值,为了直观地对网络话题暴力进行描述,文本对话题暴力值进行翻转,把暴力值映射到正数区间内,具体的话题暴力计算公式如式(12)所示。
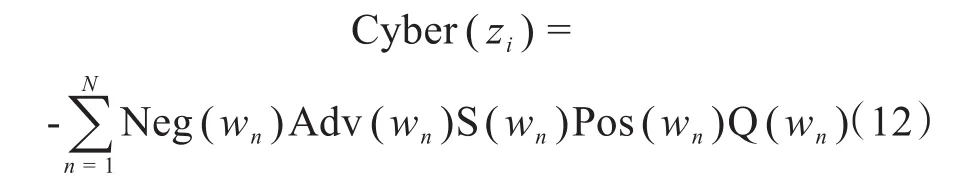
最后,运用式(9)对话题zi内其他非暴力词的情感进行计算,再运用式(6)计算话题zi的暴力密度,如果暴力密度超过设定的阈值即可判断zi为暴力话题。
3 实验分析
3.1 数据来源及预处理
本文使用“八爪鱼”网络数据采集器在腾讯新闻中下载了4个话题文本数据,数据包括正文内容和评论,具体数据详情如表2所示。为了模拟真实网络环境以便验证本文方法,把所有下载的话题文章混合放在一起,并随机加入20个无主题文本,组成一个混合主题文本集,构造一个小规模网络环境。然后再把主题文本与评论文本建立对应关系。随后使用Python软件中提供的Jieba分词工具对每条新闻文本及评论进行分词,去除停用词、介词、语气词、转折词等无用词后,分别建立新闻文本语料矩阵D和评论文本语料库C。运用动态主题数计算方法获取D中的主题数K,再对LDA模型进行参数设置:α设置为0.5/K,β设置为0.1,话题特征词数量T=15,抽样次数为1 000。

表2 实验数据集
3.2 实验结果及分析
运行LDA模型前,运用动态主题数识别方法对主题数K进行运算,计算结果为4,与D中事先混合的主题数相同,说明动态主题数计算方法的精度较高。运用LDA模型对语料库D中的话题进行识别,再用相似度计算公式对语料库D中的文本按话题进行分类,得到话题文本集;然后,对每个话题对应的评论文本集进行情感计算,并用卡方检验从负面情感词中筛选出暴力特征;最后,通过暴力密度判定话题的暴力属性。话题特征词、评论暴力词及话题暴力密度计算结果如表3所示。
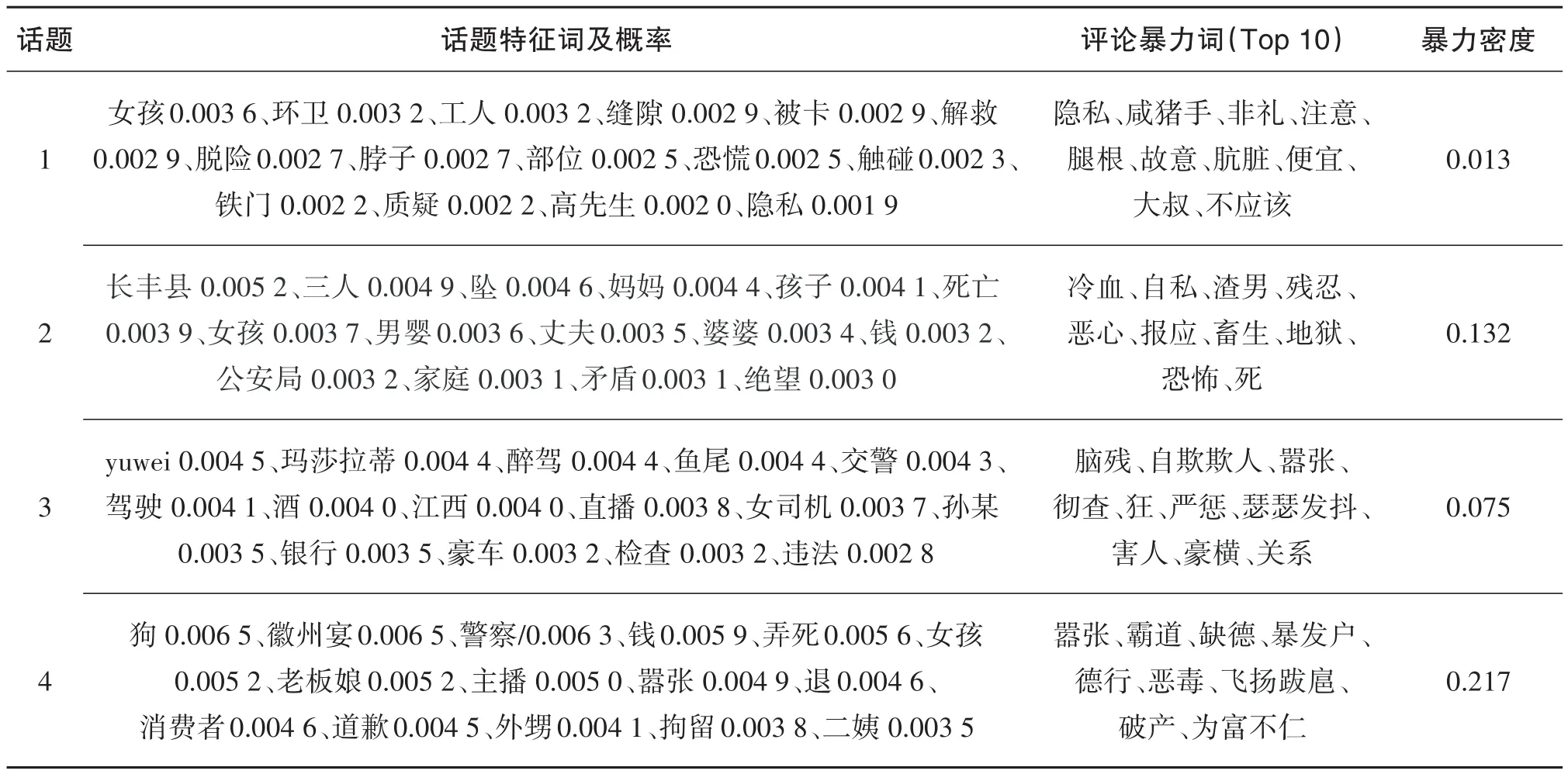
表3 网络话题特征词及暴力特征词识别结果
表3给出了对4个话题特征词及评论暴力词的识别结果,根据式(4)计算出每个话题的暴力密度。暴力话题密度阈值设置为0.1。话题2和话题4的暴力密度分别为0.132和0.217,根据规则,判断出话题2和话题4是暴力话题。对实际网络文本分析可以发现,在话题2评论中,网友对坠楼女子、女子丈夫及家庭均进行了大量的指责,语言尖锐,负面情感很强;话题4是全国“臭名昭著”的“徽州宴”事件,不仅大量网民对徽州宴老板娘实施网络暴力,而且全国网红也围堵了徽州宴实体店,消费者纷纷退订,导致徽州宴经营受阻,线上线下都遭受了暴力对待。
话题1和话题3的暴力密度分别是0.013和0.075,均没有达到设定阈值,判定不是暴力话题。从网络文本分析看,虽然话题1中的环卫工人在前期遭受到较强的网络暴力,部分网民指他触碰女孩隐私部位,但随着真相的逐步披露,紧急关头救助被卡女童的高尚行为还是被绝大多数网民所赞同,使得先期的暴力语言逐渐被正能量语言所稀释,暴力密度逐渐降低,大众对环卫工人的态度符合大众的理性认知。对于话题3,从表面上看应该会成为暴力话题,但计算结果却“出乎意料”,它并不是暴力话题。从网络文本分析中可以推断出它没有成为暴力话题的原因可能有2个:一是女子酒驾行为没有对其他人造成伤害,没有激怒网民;二是大多数网民在酒驾女子的“滑稽表演”中完全充当吃瓜看客,评论语言既委婉又讽刺,负情感不是非常强烈,也体现出了网民“吃瓜群众”的天然属性。
3.3 性能评价
文本的实验数据集是事先用4个话题文本集与20个无主题文本混合而成,为了验证本文方法(LDA-χ2)的话题暴力识别性能,把实验运算得到的话题内暴力特征词与混合前4个原始话题内标注暴力特征词进行对比,再以黄瑞[14]提出的方法(NVLD)做对比,2种方法对4个话题内暴力特征词的识别性能如表4所示。从表4可以看出,在4个话题的混合文本集上,文本方法的暴力特征词组识别性能(F值)好于NVLD方法,说明文本的话题暴力特征词识别效果达到了良好的水平。

表4 暴力特征识别性能对比
4 结语
为了在复杂网络环境中精确挖掘网络暴力话题,本文提出了一种LDA模型和卡方检验网络暴力话题识别方法,该方法首先运用LDA模型识别出网络文本语料库中存在的话题,并运用相似度计算方法对话题文本进行分类;然后运用卡方检验筛选出话题文本中的暴力特征词,并用情感计算技术得出话题暴力的值;最后运用暴力密度对话题的暴力属性进行判断。经过实验验证,本文方法在网络话题网络暴力特征识别方面达到了较好的性能。
本文方法认为暴力特征词都具有强烈的负面情感,对于其他情感属性的暴力词识别较为困难,如何在多情感分布下提高暴力特征识别精确是下一步需要研究的方向。
猜你喜欢
环球时报(2022-03-09)2022-03-09 22:44:18
中国新闻周刊(2021年26期)2021-07-27 04:02:12
作文成功之路·小学版(2020年3期)2020-04-21 08:17:34
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
小学生必读(低年级版)(2017年11期)2017-03-15 07:53:41
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中文信息学报(2015年4期)2015-04-21 08:29:12
中国卫生(2014年12期)2014-11-12 13:12:38
