
基于TransUnet的侵彻多层过载信号生成
2023-01-16 03:00房安琪
测试技术学报 2023年1期
李 蓉, 房安琪
(西安机电信息技术研究所, 陕西 西安 710065)
0 引 言
在现代高科技战争中, 为降低大规模杀伤武器的毁伤效能, 各个国家不断将重要军事目标如导弹发射井、 指挥中心、 飞机掩体转移到地下或者深山中, 并配备加固防护层。 常规杀伤爆破弹药仅能在目标表面起爆, 无法进行有效打击[1]。根据统计, 等同当量炸药在目标内部最佳位置起爆与位于目标表层起爆相比, 能量耦合效率可提高20倍~50倍[2]。 为了有效打击这种重要军事对象, 必须使弹药具备相当的侵彻能力, 能够深入目标内部起爆, 以形成更大的毁坏和杀伤力[3]。硬目标侵彻弹作为这类坚固目标的克星, 可通过加速度传感器采集的过载信息实时感知弹丸在碰撞目标、 侵入目标、 穿透目标、 钻出目标的一系列历程, 确认弹丸相对于目标的准确位置, 完成最佳炸点识别和起爆任务, 实现高效毁伤[4]。
硬目标侵彻弹加速度曲线如图1所示, 当战斗部以一定速度v0侵彻靶板时, 侵彻阻力使战斗部开始做减速运动, 减加速度曲线a(t)主要分为4个阶段[5]: 在0~ta期间, 弹丸头部与靶板初步接触, 由于侵入深度小, 锥形弹头与靶板平面相交的横截面较小, 侵彻阻力小, 因而减加速度也较小。 随着侵彻深度的增加, 弹丸头部与靶板平面相交的横截面不断增大, 当该横截面的直径与弹径相等时, 侵彻阻力接近最大值, 如b点所示。当侵彻深度继续增加时, 侵彻阻力的增加只是由于弹丸外表面与靶体的接触面积增大而增大了摩擦力, 因此, 减加速度的增大也是有限的, 即b点的加速度接近最大加速度am。 侵彻过程引起的靶体崩落和碎裂使侵彻阻力迅速下降, 减加速度在达到最大值后很快下降, 如c点所示。 随着侵彻程度的加深, 克服侵彻阻力消耗的能量越大, 使弹丸的运动速度逐渐降低, 当弹丸速度变为零时,侵彻阻力也变为零, 减加速度随之消失, 如d点所示。

图1 弹丸侵彻的加速度时间历程Fig.1 Acceleration time history of projectile penetration
硬目标侵彻弹的主要起爆方式是计层起爆[6],该起爆方式打击精度高, 打击灵活性大[7]。 目前的计层起爆算法均根据侵彻过载信号进行计算与测试, 过载信号是侵彻引信精确计层起爆控制必不可少的数据支撑[8]。 由于侵彻试验成本高昂,在靶场使用测试弹进行目标毁伤获得的真实信号数量非常有限, 只能通过仿真或模拟试验获取过载数据。 然而, 随着动能侵彻战斗部速度的不断提高, 引信也承受着更高程度的冲击过载。 弹丸在高速侵彻多层目标过程中, 作用在弹体上瞬间变化的冲击力激发了应力波, 该应力波沿着弹长方向来回传播和反射, 使得弹体侵彻每层靶板时加速度传感器采集到的过载信号中叠加了这些震荡信息的高频分量。 弹体在相邻两层靶板间行进过程中, 应力波仍在振荡, 尚未衰减完毕, 导致相邻两目标层之间的过载彼此粘连[9]。 而这种信号彼此粘连的现象难以通过计算机仿真进行还原,导致模拟结果与实测数据有较大出入。 因此, 如何生成有效的过载信号成为深度学习在硬目标侵彻引信应用中的关键。 本文尝试将神经网络引入过载信号的生成中, 希望生成更加可靠的数据,以供硬目标侵彻引信的层识别算法进行计算与测试。
1 深度生成模型
深度生成模型是概率统计和深度学习中非常重要的模型, 可以生成一系列可观测数据, 在计算机视觉、 自然语言处理等领域应用十分广泛[10]。
1.1 原始生成对抗网络
生成对抗网络(Generative Adversarial Network,GAN)是Goodfellow 等[11]在2014年提出的一种无监督生成式模型, 该模型受启发于二人零和博弈理论, 由生成器和判别器组成, 结构如图2所示, 生成器主要用来学习真实样本的分布,从而让生成的数据更加真实, 以骗过判别器; 判别器则需要对接收的数据进行真假判别。 在训练过程中, 生成器不断使生成的数据更加真实, 判别器则努力识别数据的真假, 即二人相互博弈的过程。 随着时间推移, 生成器和判别器不断对抗,最终达到动态平衡: 生成器生成的数据接近真实样本分布, 而判别器无法识别出数据的真假, 对于给定数据, 判别器预测为真的概率基本接近0.5(相当于随机猜测)[12]。
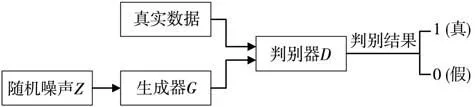
图2 GAN模型结构Fig.2 Model structure of GAN
GAN的目标函数定义为

1.2 InfoGAN
原始GAN由于其无监督过于自由的学习模式, 导致在训练过程中经常出现学习不稳定、 不可控等问题。 从表征学习角度看,GAN 的生成器在输入噪声信号z时没有增加任何限制, 而是以一种高度混合的方式使用,导致z的任何一个维度均没有明确的特征表示[13]。因此,在数据生成中, 无法得知什么样的噪声信号可以用来生成什么样的数据。
为了弥补上述GAN 模型的弊端,Chen等[14]提出了InfoGAN模型, 结构如图3所示。

图3 InfoGAN模型结构Fig.3 Model structure of InfoGAN
将输入的噪声信号分解为不可压缩的随机噪声z和可解释的隐含变量c以表示数据的潜在特征。 以MNIST手写数字数据集为例, 隐变量c包含离散部分和连续部分, 离散部分取值为0~9的随机变量(表示数字), 连续部分包含2个连续型的随机变量(分别表示倾斜度和粗细度)。InfoGAN的核心思想是最大化输入噪声变量的固定子集与观测值之间的互信息, 从而使其与观测值之间产生因果关系, 当因果关系达到一定程度时,固定子集就可以“控制”生成观测值中的重要特征。
2 注意力机制
近几年, 注意力机制被广泛使用在自然语言处理、 计算机视觉、 语音识别等各种不同类型的任务中, 是深度学习技术最值得关注与深入了解的核心技术之一[15]。 注意力模型能够实现信息处理资源的高效分配[16], 例如, 当神经网络模型需要寻找图片中的小狗信息时, 会更多注意符合小狗特征的主要区域, 而忽略其他不相关的次要区域, 如图4所示。注意力机制以高权重聚焦重要信息, 以低权重忽略无关信息, 并且据此不断调整权重, 使其在不同的情况下也可以选取重要的信息。 因此, 注意力机制具有更高的可扩展性和鲁棒性[17]。

图4 注意力机制Fig.4 Attention mechanism
2.1 Transformer
注意力机制早在20世纪90年代就已经被提出[18], 研究者们不断分析比较注意力机制的应用领域, 一直以提高效率且克服CNN、RNN等算法的局限性为目的进行探索, 尝试提出新的算法结构。2017年,Google团队提出了基于自注意力机制的Transformer[19]模型, 首次抛弃以往Encoder-Decoder必须结合RNN 或CNN 的固有模式, 使用自注意力结构完全替代LSTM 网络, 在提高并行率的同时取得了非常亮眼的成绩。 随后提出的 Transformer 改进模型如 GPT[20],BERT[21]等更是力压RNN 经典模型横扫自然语言处理榜单, 使得注意力机制得到真正成功的应用, 成为NLP领域的主流模型[22]。 与此同时, 计算机视觉领域也借鉴Transformer的思想相继提出DETR[23],ViT[24],IPT[24]等自注意力模型,将各大图像任务的成绩推向新一轮高峰, 迎来了各学界对Transformer的研究狂潮。
Transformer模型由编码器和译码器构成, 编码器负责把输入序列进行位置编码后映射为隐藏层, 然后解码器再把隐藏层映射为输出序列, 如图5所示。 编码器分为4个部分, 第1部分将输入数据转换为向量, 并对其进行位置编码, 记录数据之间顺序的相关性, 具体操作如式(2)所示。 相较于RNN的顺序输入,Transformer无需将数据一一输入, 而是直接并行送入, 并存储好数据之间的位置关系, 大大提高了计算速度, 减少了存储空间。

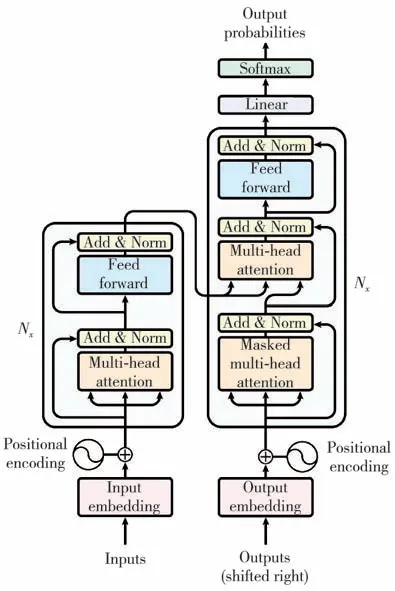
图5 Transformer模型结构[19]Fig.5 Model structure of Transformer[19]
第2部分是Multi-Head Attention, 其计算以缩放点积注意力为基础, 对输入的Query,Key,Value做如式(3)的操作, 获取数据内部之间的相关性, 弥补了CNN方法中数据缺少关联性的缺点。
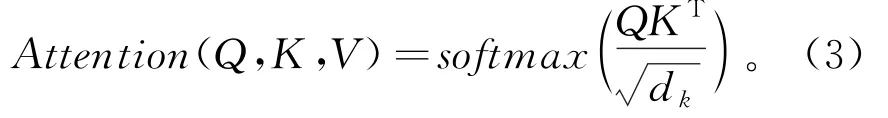
第3部分是Add&Norm, 即残差连接和层归一化。 神经网络在映射关系的转换过程中, 往往存在计算产生的残差, 而残差的存在会随着网络层数的增加越来越不精确, 因此, 通过第3部分的Add&Norm 可以有效提高模型的学习能力, 加快收敛速度。
第4部分是由2个全连接层组成的Feed Forward, 将学习得到的数据进行非线性映射, 如式(4)所示, 增大强的部分, 减小弱的部分, 最后进行标准化, 使学习结果更加精准和具有代表性。
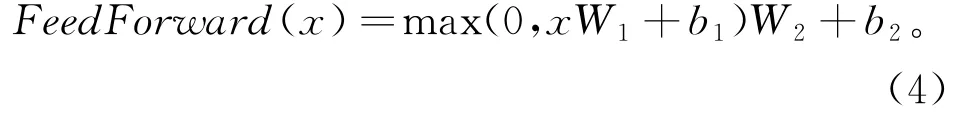
2.2 TransUnet
2016年,Olaf Ronneberger等[25]针对医学图像分割任务提出了U-Net结构, 采用长短跳跃连接将网络的第i层拼接到第n-i层, 将浅层卷积核提取的局部特征通过Channel维度连接到深层卷积核提取的抽象特征中, 使神经网络可以同时学习到高级和低级特征, 极大改善了模型生成数据的效果, 且在医学图像这种小规模数据集中表现非常突出。
2021年,Chen等[26]将风靡学术界的Transformer与U-Net相结合, 提出TransUNet模型,结构如图6所示, 该模型兼具Transformer和UNet的优点, 同时克服了CNN 处理远距离关系的局限性, 又能很好的弥补Transformer只专注于全局而缺失详细定位信息的精确特征。
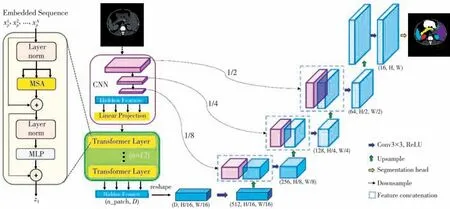
图6 TransUNet模型结构[25]Fig.6 Model structure of TransUNet[25]
3 基于TransUnet的侵彻多层过载信号生成
3.1 生成器
过载信号虽然是一维序列, 但与NLP领域中的数据在输入长度方面有极大差别, 这是因为过载信号的长度通常在6 000以上, 而自然语言处理的数据集为单词或句子, 一般不会超过1 000。 因此, 不能简单移植NLP领域中表现非凡的Transformer模型, 否则会因序列过长而产生爆炸性的计算成本。 另一方面, 过载信号与CV领域的数据在长度方面有所相似, 但在维度方面又有较大差异, 也无法直接使用图像任务的处理方法。 因此,本文针对侵彻多层过载信号的特殊属性设计生成器, 如图7所示, 该生成器借鉴TransUNet架构,由4组上/下采样模块和1组深度特征提取模块构成。 其中, 下采样模块包含3个卷积层, 前2个卷积层步幅为1, 用于提取样本的细节特征, 增强生成数据的细腻程度, 第3个卷积层步幅为2, 将数据压缩为原始尺寸的一半, 扩大网络感知域, 用于提取更加抽象的高级特征, 容忍某些特征的微小位移, 实现尺度不变性, 提高网络的泛化能力。模块中每层卷积核大小均为3×3, 使用Same填充, 在每个卷积层后添加Batch Normalization批标准化操作, 加速模型的收敛速度, 同时加入Dropout, 增加生成数据的随机性与多样化, 使用LeakyReLU 函数激活。
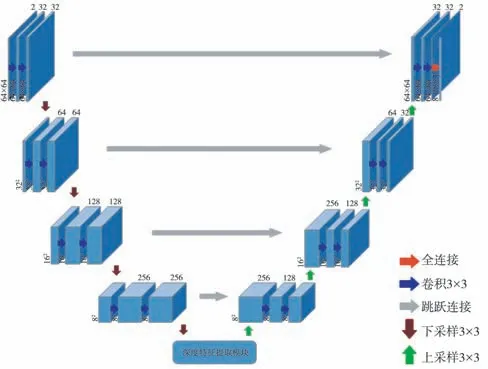
图7 生成器模型Fig.7 Generator mode
下采样结束后, 数据将被送入深度特征提取模块, 结构如图8所示。 二维数据首先进入Flatten层线性映射为一维序列, 然后与可学习的位置编码相融合, 接着通过3个Transformer Encoder进行深度特征学习。 其中,Transformer Encoder由Multi-Head Attention模块和MLP模块交替构成, 每个模块之前使用层归一化(Layer Norm)避免梯度消失或爆炸, 每个模块之后使用Dropout和残差连接, 加强特征之间的传递。

图8 深度特征提取模块Fig.8 Depth feature extraction modul
深度特征提取结束后,数据最终被送入上采样模块, 其结构与下采样模块相似, 不同之处在于上采样模块的第3层为转置卷积层, 用于恢复特征图尺寸。 区别于二维图像生成任务, 过载数据的生成样本是一维向量, 因此, 生成器的输出层为全连接层, 将卷积层输出的三维数据重塑为8 192×1的一维序列, 并使用Tanh函数激活。 最后, 将尺寸相同的下采样模块和上采样模块进行跳跃连接, 共享不同层之间学习到的特征信息。
3.2 判别器
判别器作为鉴别数据真假的二分类器, 不像生成器那样精细, 因此, 使用较为简单的注意力机制以降低生成对抗式网络的整体复杂度。 判别器结构如图9所示, 参考Transformer模型并做了一些简化, 其中,Attention模块使用缩放点积注意力。
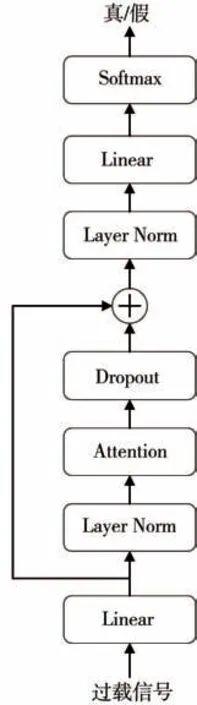
图9 判别器模型Fig.9 Discriminator model
3.3 损失函数
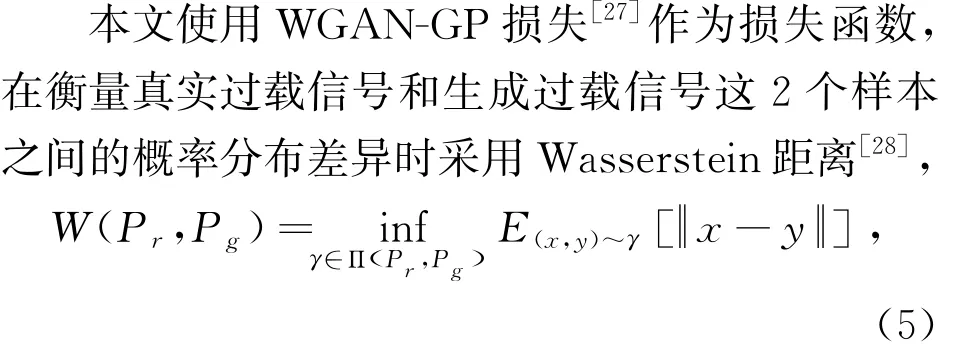
式中:Pr为真实过载信号的概率分布;Pg为生成过载信号的概率分布;Π(Pr,Pg)为Pr与Pg联合概率分布的集合;γ(x,y)为在Pr中出现x的同时在Pg中出现y的概率。 在这个联合分布下可以求得所有x与y距离的期望E, 存在某个联合分布使该期望最小, 而这个期望的下确界(infimum)就是真实过载信号与生成过载信号的最优Wasserstein距离。 为使神经网络模型可以优化迭代到最优Wasserstein距离,WGAN-GP 损失采用梯度惩罚方法, 只要梯度的范式大于1就会产生损失,
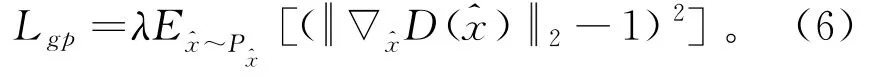
对于上述惩罚项中的采样分布P^x,其范围是真实过载信号概率分布中间的分布。 具体操作为对真实过载信号分布和生成过载信号分布各进行1次采样, 然后在这2个采样点的连线处再做1次随机采样得到惩罚项Lgp。
4 实验与结果分析
4.1 数据集
本文使用靶场实测侵彻弹穿透2层~14层硬目标的加速度信号作为数据集, 单个样本为8 192×1的序列, 标签共12个, 分别对应上述的12种层数。
由于不同工况下不同靶板的过载幅值差别很大, 若直接使用原始数据训练可能导致模型在学习过程中出现不稳定、 不收敛等问题, 因此, 本文首先对每个过载数据做均衡预处理

4.2 实验结果
本文使用Py Torch平台进行训练与测试, 将随机噪声输入生成器, 通过下采样压缩维度, 减少过载信号超长序列的计算量。 然后对其进行深度特征提取, 再利用上采样逐步恢复原始序列长度, 生成侵彻多层过载数据, 将该生成数据与经过均衡和归一化处理的真实过载信号同时输入判别器, 输出真假判别。 使用WGAN-GP损失计算Wasserstein距离, 将生成过载信号与真实过载信号的相似程度反馈给生成器, 实现生成器与判别器的相互迭代优化。 每次训练结束后, 调整模型的超参数, 优化算法, 实验确定最优值, 并在此基础上尝试不同重复次数的跳跃连接与卷积核个数,寻找最适合生成侵彻过载数据的神经网络。
训练结束后确定的超参数如表1所示, 其中G和D前缀分别表示生成器和判别器,initial_learning_rate、decay_steps、decay_rate为指数衰减学习速率的初始学习速率、 衰减步长和衰减速率。
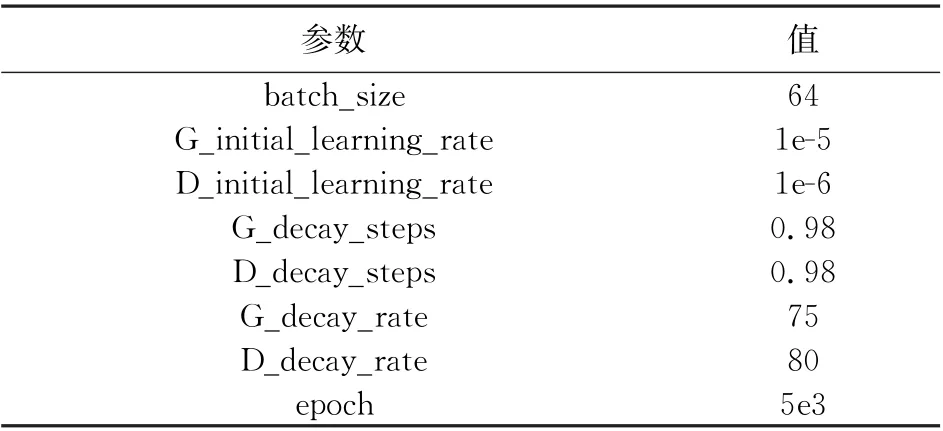
表1 超参数设置Tab.1 Hyperparameter setting
过载信号生成结果如图10所示, 出于保密性考虑, 本节过载信号的生成效果与4.3验证分析仅以三层过载信号为例进行展示, 均经过归一化处理, 且不标注具体速度, 而是分为低速、 中速和高速3种描述。

图10 过载信号生成结果Fig.10 Overload signal generation results
4.3 验证分析
过载信号的本质是减加速度信号, 对过载进行一次积分运算便得到速度变化曲线, 如图11所示。 通过对比可以看出生成信号与真实信号的速度随时间变化趋势一致, 且在细节处又各有不同,在保证有效性的同时丰富了过载信号的多样性。


图11 速度变化曲线Fig.11 Velocity curve
归一化相关系数主要用于描述2个波形之间的相似程度, 定义如式(9)所示,

归一化相关系数的取值范围为-1≤ρ≤1,当信号与自身进行相关计算时值为1。对生成信号与真实信号速度曲线的相关性进行定量分析, 结果如表2所示, 可以看到两者相关系数均在0.9以上, 呈高度正相关。
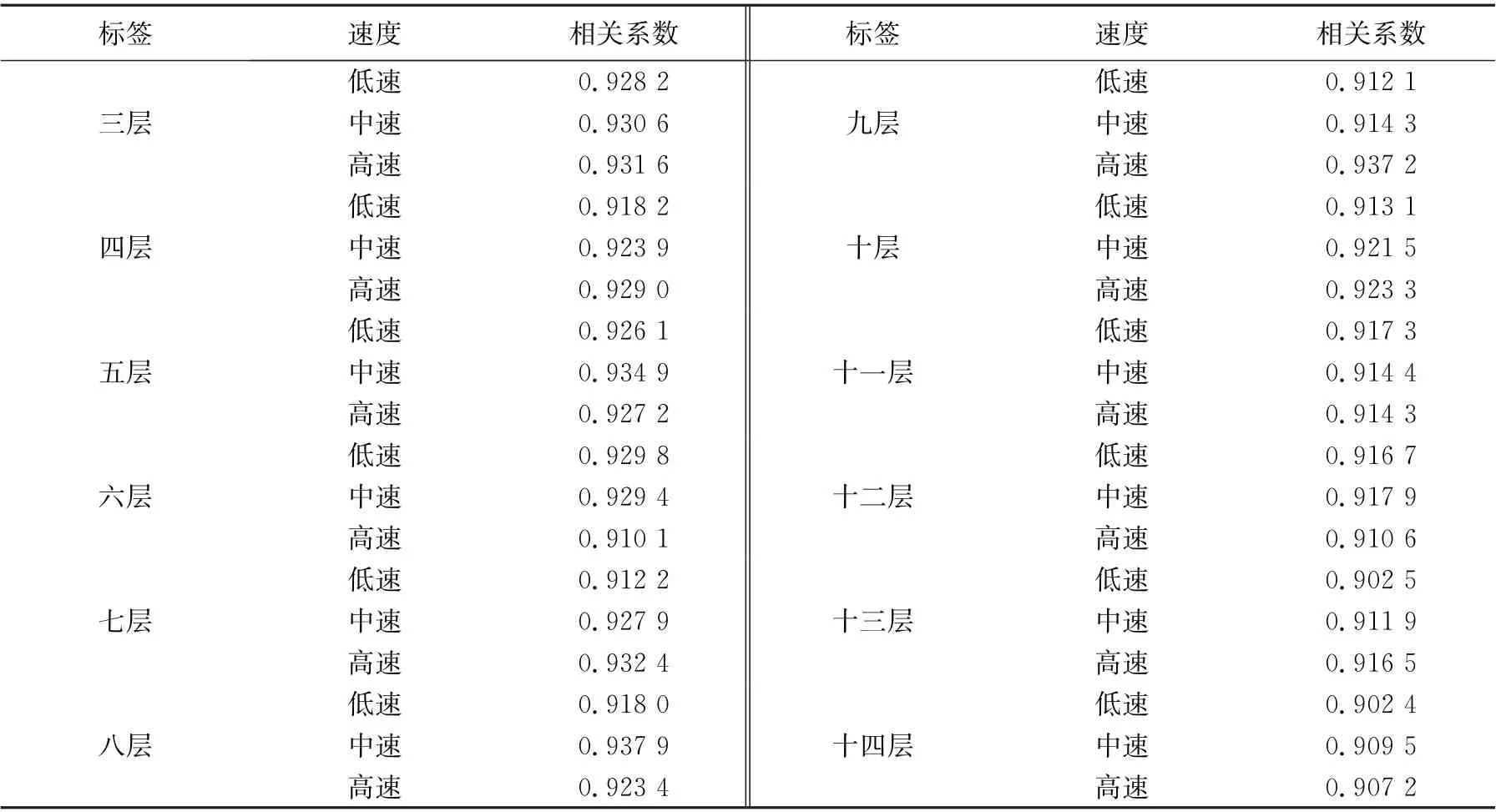
表2 生成信号与真实信号速度曲线的相关系数Tab.2 Correlation coefficientbetween generated signal and real signal velocity curve
过载信号作为随机振动信号在时域内的波形千变万化, 但在频域范围内, 其主要频率组成是相对稳定的。 针对时域信号使用快速傅里叶变换(FFT)得到生成信号与真实信号的频谱图, 如图12所示, 通过对比可以看出, 生成信号与真实信号的频谱波形相似, 优势频率均分布在0~0.1区间内, 符合过载信号的频域特性。 另外, 侵彻计层算法需要实时处理过载数据, 而生成信号与真实信号频点间隔的一致性可以保证生成过载信号在侵彻过程未结束时其特征与真实过载信号的特征一致, 如表3所示(表中数据均经过归一化处理), 其中, 频点间隔为中心频率与一次谐波的距离。 可以看出生成信号与真实信号的中心频率偏差范围仅为±0.001, 一次谐波的偏差范围为±0.005, 频点间隔偏差范围为±0.005。 因此, 生成过载信号无论是用于侵彻计层算法的实时处理还是事后分析都可以保证其有效性。

表3 生成信号与真实信号的主要频率成分Tab.3 Main frequency components of generated signal and real signal

图12 生成信号与真实信号的频谱Fig.12 Spectrum of generated signal and real signal
5 结 论
本文针对侵彻多层过载数据量不足的问题,结合InfoGAN模型, 提出基于TransUnet的侵彻多层过载信号生成方法。 对于过载数据这种超长序列的特殊属性, 生成器使用Transformer Encoder和U-Net的融合结构, 使模型具有强大的特征提取和信息共享的能力, 且在过载信号这类小规模数据集中表现优异。 判别器使用较为简单的注意力模型, 以降低整体模型的复杂度。 最后分析验证了生成过载信号在不同速度与不同层数的有效性, 可在一定程度上为解决侵彻多层过载信号的缺乏问题提供新的启示。
猜你喜欢
当代水产(2022年6期)2022-06-29
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
汽车观察(2018年12期)2018-12-26
金桥(2018年4期)2018-09-26
劳动保护(2018年8期)2018-09-12
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
