
体育器材数据集的构建及分类方法研究
2023-01-16 03:33艾山吾买尔早克热卡德尔王中玉杰恩斯艾力努尔达艾勒
东北师大学报(自然科学版) 2022年4期
石 瑞,艾山·吾买尔,早克热·卡德尔,王中玉,杰恩斯艾力·努尔达艾勒
(1.新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆大学新疆多语种信息技术实验室,新疆 乌鲁木齐 830046)
0 引言
体育器材作为进行体育运动必不可少的一部分,在体育赛事和健身运动中都占有重要地位.近年来,人工智能的飞速发展,为体育发展带来重大的机遇和影响.其中计算机视觉在体育领域中得到了广泛的应用,如体育运动视频分类[1]、体育动作识别[2]、人体姿态分析[3]、体育视频描述[4]和智能健身指导等.在这些技术的影响下,促进了运动与人工智能的有机结合,使得全民健身活动和体育赛事向智能化、多样化和科学化的方向发展.
图片分类作为计算机视觉中重要根基,是图像分割、物体跟踪和行为识别等其他高层视觉任务的基础,所以准确识别体育器材对于体育赛事的发展具有重要应用价值.随着大规模标记数据的产生[5]及计算机计算能力的快速提升,卷积神经网络(CNN)进入快速发展期,基于CNN的图像分类方法无须经过烦琐的预处理、特征提取等中间建模过程,采用端到端的结构,由数据驱动自动提取深层的抽象特征,减少了人工设计特征产生的不完备性.自2012年深度卷积神经网络AlexNet[6]在图像识别中取得巨大成功后,引爆了深度学习的热潮,再到2014 年的GoogleNet[7]、VGG[8]和2015年的ResNet[9]神经网络在计算机视觉任务中也取得越来越好的效果.但目前相关研究没有涉及专门体育器材图像分类,只是在公开的数据集[10]中的部分体育器材进行了探索,对更为复杂多样的运动还少有涉及,这限制了人工智能技术在体育领域的实践和应用.
丰富的图像数据集是进行深度神经网络建立和参数优化的基础,当前体育器材分类算法还没有公开的专用数据集,因此本文构建了一个涉及69类体育器材的数据集SED.对于多类别小规模数据集、单一模型预测效果不能达到预期的准确率,本文提出一种将模型融合与迁移学习相结合的体育器材图像分类方法,使用在公开数据集上完成预训练的经典卷积神经神经网络模型ResNet50和InceptionV3分别进行图像的特征提取.由于不同卷积神经网络在提取特征时表现的学习过程不同,为了利用不同模型之间的互补性,达到更优化的性能,进行双模型融合.然后将该融合的网络用于69类体育器材图像迁移训练.
1 相关理论
1.1 InceptionV3模型
Inception模型是Szegedy等[7]在ImageNet大型视觉识别挑战中,提出的一种深度卷积神经网络架构,并于2014年ILSVRC挑战赛中获得冠军.InceptionV3模型是谷歌Inception系列里面的第三代模型,采用非对称卷积(Asymmetric Convolutions)方式,对较大的卷积进行拆分操作,使得不同卷积核存在不同大小的感受野,模型将n×n的卷积分解成一维的n×1和1×n卷积的串联,这样更有利于图像高维特征的提取,在提高模型参数计算效率的同时,也减少了模型过拟合.为了减少网络的设计空间,采用模块化结构,最后实现拼接,达到不同尺度的特征融合.InceptionV3模块结构图如图1所示.

图1 InceptionV3模块结构图
1.2 ResNet50模型
深度残差网络(Deep Residual Networks,ResNet)在2015年获得ILSVRC比赛冠军.网络深度的增加可以提取更丰富的特征信息,但深度网络会引发梯度消失和梯度爆炸问题,ResNet利用残差学习来解决深度网络的退化问题,使得训练更深层次的网络成为可能.ResNet50网络有50层,首先对输入做卷积操作,之后包含4个残差块(Residual Block),每一个残差块有2个基本的块,分别为Conv Block和Identity Block,其中Conv Block作用是改变网络的维度;Identity Block用于加深网络.每一个残差块结构如图2所示.

图2 残差学习单元
将学习到的特征记为H(x),这样残差就表示为F(x)=H(x)-x,残差单元可表示为:
yj=H(xj)+F(xj,Wj);
(1)
xj+1=f(yj).
(2)
其中:xj和xj+1分别表示第j个残差单元的输入与输出,f为激活函数Relu.推导得从浅层j到深层J的学习特征可表示为
(3)
在实际操作中残差不等于零,残差函数会使得对堆积层在输入特征基础上学习到新的特征,以此拥有更好的性能.
1.3 迁移学习
在卷积神经网络模型训练中,当训练效果不够理想,训练样本不够丰富,重新调整参数构建CNN模型比较麻烦时,会考虑使用迁移学习的方法[11].Zeiler等[12]让卷积神经网络在ImageNet数据集上进行预训练,然后将网络分别在图像分类数据集Caltech-101和Caltech-256上进行迁移训练和测试.其图像分类准确率提高约40%.Donahue等[13]是把一个大规模数据集学习到的模型,迁移到其他数据集上进行预测.从而来解决某些数据集有标签数据少的问题.由此看出迁移学习可以提高模型的分类能力.除了卷积神经网络在各个领域的迁移学习研究,Razavian等[14]还对卷积神经网络不同层次特征的迁移学习效果进行了探索,发现卷积神经网络的高层特征相对于低层特征具有更好的迁移学习能力.
由于本文中体育器材数据集和ImageNet大规模数据集均由不同类别的图像和类别数量组成,这2个数据集相互关联但又存在一定的差异.因此将经典的预训练CNN图像分类模型与迁移学习相结合来进行体育器材图片分类的研究是可行的.
2 体育器材数据集构建
特定领域的研究需要专门的图像数据集,针对体育器材分类任务,目前尚未有标准的专用数据集,本文按照图像分类任务文件格式构建了一个新的体育器材图像数据集SED(Sports Equipment Dataset),该数据集基本囊括了现在常见的体育器材,包括球类运动器材、田径赛器材、游泳器材、拳击器材和健身训练器材.图3给出了SED部分体育器材样本图.

图3 SED部分体育器材样本
2.1 体育器材数据集的获取
针对提出的数据,数据集的构造过程中主要采用网络爬虫技术(80%)和相机拍摄(20%)的方式获取,具体构造流程:首先统计确定待构造数据集中体育器材种类名单,再根据确定的名单采用网络爬虫技术和人工拍照进行图片的获取,最后通过人工对图片进行筛选.本文设计的数据采集与过滤标准,主要从类别多样性和图片的质量两方面考虑.
2.1.1 图片类别的多样性
为了确保所构建的数据集类别的多样化,我们查阅了有关体育运动所涉及的各种器材、装备及用品,再结合体育赛事和健身运动项目,最后确定69种类别,如表1所示.

表1 体育器材数据集种类统计
2.1.2 图片质量筛选
在图像质量筛选过程中,主要采用人工筛选的方法.通过爬虫采集到的图片存在一些不能很好表征图像的数据,例如按照体育器材名称搜索的图片与实际的体育器材不相符、图片中体育器材的特征不明显和图片中包含多个体育器材无法对图片给出对应的类别,如图4所示.对这部分图像进行筛除.最终构造出一个包含7 728张图片的体育器材数据集.图4(a)名称与实际体育器材不相符,图4(b)图片中体育器材的特征不明显,图4(c)无法对一张图片给出对应的类别

(a)花剑;(b)起跑器;(c)腹肌板
2.2 各类体育器材数据量
大规模和多样化的体育器材数据集是有效训练图像分类模型并且增强其泛化能力的关键,数据集各类运动器材应保持充足的样本数,考虑到体育器材种类繁多,但不同体育器材流行度不一样,对于体育赛事所用的体育器材能够采集到图片数量会稍多,这会导致采集到的体育器材数量层次不齐,因此,通过对比收集难易程度以及筛选出的有用图片数量来确定每一类的样本数.最后确定每一类的样本数量为到100~130张,体育器材数据集采集量的分布直方图如图5所示.

图5 体育器材数据集采集量的分布直方图
2.3 数据集各指标对比
目前没有公开的体育器材识别研究数据集,所以针对现有公开数据集中所包含的体育器材种类进行分析,表2列出公开数据集中含有体育器材种类的数据,显然,它们各自存在着一些问题,包括体育器材种类偏少、图像背景单一、仅含体育器材区域样本,数据样本分布不均匀.本文在构建数据集时,考虑多方面因素如样本的多样性、样本数量均衡性、场景多样化使得数据集更符合真实场景的需要,有利于提高模型的泛化能力.

表2 数据集各指标对比
3 基于ResNet50和InceptionV3模型融合的体育器材图片分类
3.1 基本思想
不同模型具有不同卷积核大小和体系结构,从而能学习不同方面的图像表示,于是考虑通过2个有差异的网络来分别提取特征,融合后构成组合特征,再利用组合后的特征构来建体育器材图片分类器.残差网络ResNet50通过跨层特征融合提高了其网络特征提取能力,InceptionV3采用不同结构的 Inception 模块堆叠,提高多种尺寸图片的特征提取能力,并将不同尺寸的特征进行融合,丰富每层所提取的图像特征.基于此将这2种模型作为特征提取器.
在深度学习中,经常会用到特征融合来提高模型性能[16],当前流行的融合方式主要有Add(Addition)和Concat(Concentrate).Add操作是信息之间的叠加,对输入特征相对应的像素进行数学相加,增加每一维度下的信息量,不增加特征的数量,如ResNet网络.Add操作公式为
(4)
其中:X={X1,X2,…,Xcx},Y={Y1,Y2,…,Xcy}分别为输入的两路特征,用Cx表示输入特征X的通道数,Cy表示输入特征Y的通道数,*表示卷积,1c表示1*1*c的张量,经过Add操作后,特征图的通道数不变,C=Cx=Cy,Add操作要求两路输入特征维度一样.
Concat经常用于特征的拼接,它可以将多个卷积层的特征或者是将输出层的信息进行拼接,增加特征的数量,保留更多的特征信息,从而提高模型性能,如DenseNet[17].对输入的两路特征X,Y进行Concat操作,Concat操作也要求两路输入特征维度一致,但是Cx与Cy可以不相等,经过Concat操作后,特征图的通道数为Cx+Cy.本文主要采用Concat融合方式来对提取的特征进行融合.公式为
(5)
3.2 模型融合
由于所构建的SED数据集中体育器材图片数量远不及训练深度卷积神经网络模型所需要的大规模数据集,仅依赖本文构建的数据集无法获得性能较好的分类模型,因此采用迁移学习方法,为了防止模型过拟合且最大化保证迁移的知识不被破坏,冻结CNN模型全连接层之前的卷积层,来提取图像的特征,对提取到的特征进行融合拼接,再利用数据集对新分类器参数进行训练微调.对新信息的适应体现在迁移模块后面的全连接层网络上.具体的融合方法如图6所示.
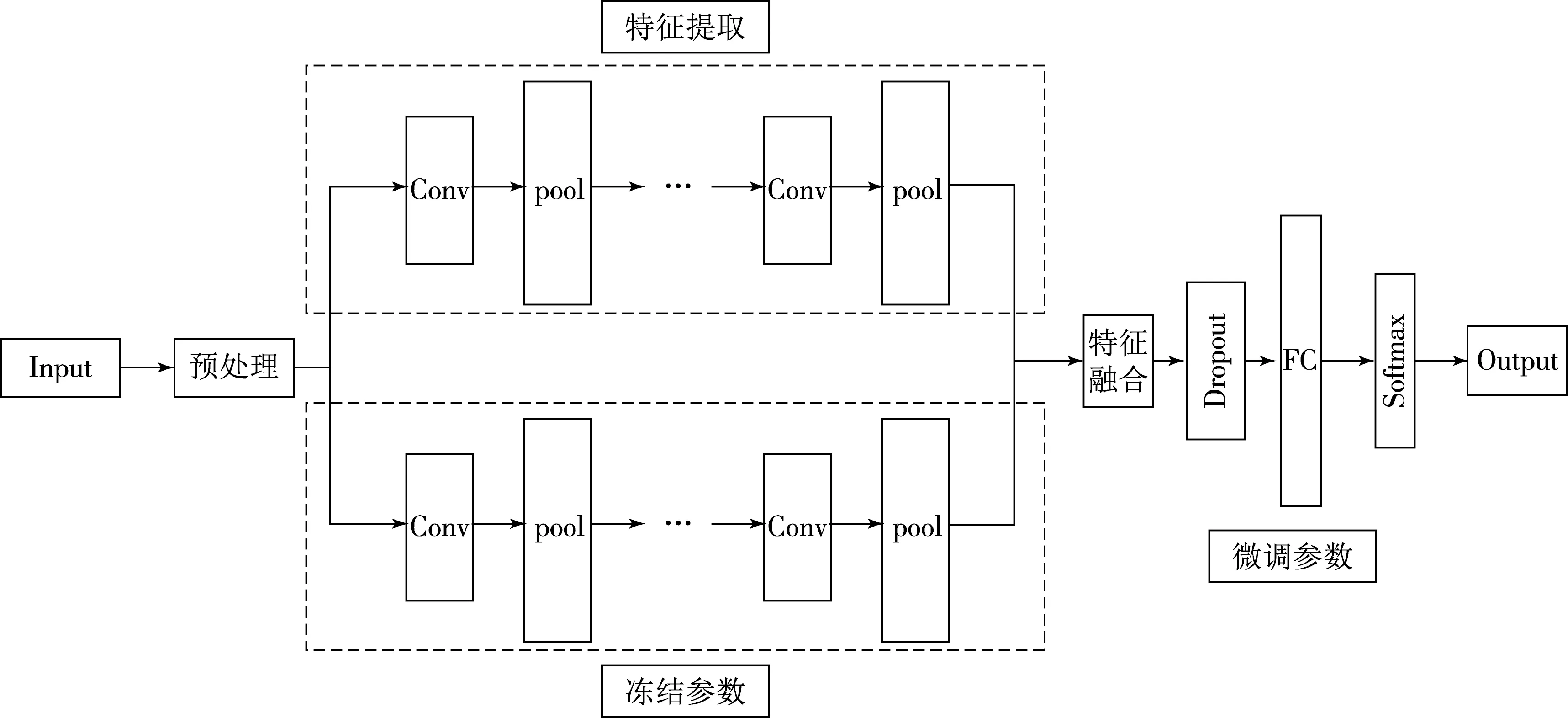
图6 基于ResNet50和InceptionV3模型融合算法框架图
本文提出的模型融合包括以下4个部分:预处理、特征提取、特征融合以及图片分类.
(1)数据预处理:InceptionV3和ResNet50对输入图片尺寸大小要求不一致,所以设计两种预处理方式,针对InceptionV3模型,将图像尺寸标准化为299×299像素;对于ResNet50模型,将图像尺寸标准化为256×256像素.对两种尺寸的图片再进行随机旋转和水平翻转,最后分别对图像进行归一标准化,输入到特征提取网络中;
(2)特征提取:将预处理后的图片分别作为两个卷积神经网络模型的输入,并删除网络模型的全连接层,冻结两个网络全连接层之前中的卷积模块参数,对图片进行特征提取;
(3)特征融合:将两个网络模型提取的特征进行融合;
(4)图片分类:通过一层全连接层将融合的特征输入到分类器中,完成分类.
4 模型训练和实验分析
4.1 实验环境与参数设置
本文使用Pytorch框架作为体育器材图片分类模型搭建和训练平台,表3为实验的软件及硬件配置.

表3 实验环境配置参数
网络模型的超参数设置如下:对收集来的数据按照8∶1∶1的方式划分训练集、验证集和测试集.训练时采用动量梯度下降法优化模型,动量大小为0.9,正则化系数为0.001,初始学习率大小为0.1,同时采用等间隔调整学习率方法来更新学习率大小.每50次学习率下降10%,模型训练次数为100.Batch_size设置为64.
4.2 模型的评价标准
准确率是最常见的评价指标,通常来说,准确率越高,分类器越好.但是使用准确率评价模型存在一个问题,即当数据的类别不均衡时,准确率就不能客观评价模型的优劣.鉴于此,又采用平均精确率P、平均召回率R和平均值F1指标来对模型做进一步比较.P是指预测为正例的数据里,预测正确的数据比例;R是指真实为正例的数据里,预测正确的数据比例;F1值又称F1分数,同时兼顾分类模型的P和R,可看作是模型P和R的一种加权平均,计算公式分别为:
(6)
(7)
(8)
(9)
式中:TTP表示真正例,即真实类别为正例,预测类别为正例;TTn表示真负例,即真实类别为负例,预测类别为负例;TFP表示假正例,即真实类别为负例,预测类别为正例;TFn表示假负例,即真实类别为正例,预测类别为负例.
为了测量多分类任务中不同模型之间的性能差异,采用平均值,即所有类别的每一个统计指标值的算数平均值进行评价[18].首先,计算每个混淆矩阵的精确度Pi和召回率Ri,将其表示为(P1,R1),(P2,R2),…,(Pn,Rn).再通过计算各精确率和召回率的平均值,得到平均精确率P、平均召回率R和平均F1值,计算公式通过公式(10)—(12)给出.
(10)
(11)
(12)
4.3 实验结果与分析
4.3.1 基于ResNet50和InceptionV3模型融合实验结果对比
本文实验均在自建的SED数据集上进行,使用经典CNN模型AlexNet、Vgg16、ResNet50、InceptionV3与本文方法进行实验对比,对比结果如表4所示,本文算法相较于单个CNN模型在A,P,R,F1上都有较为明显的提升.与单模型ResNet50相比A,P,R,F1分别提升2%,1.6%,1.7%,1.5%.和单模型InceptionV3相比A,P,R,F1分别提升6.8%,7.6%,7.5%,7.8%.这验证了将模型特征的融合确实能对图片分类有提升效果.
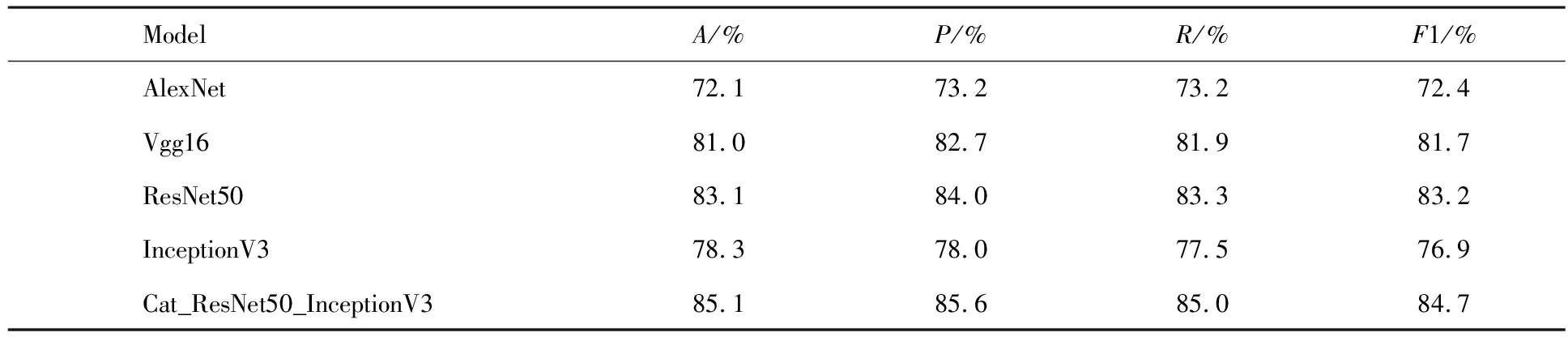
表4 各模型在自建数据集中测试结果对比
4.3.2 迁移学习对实验结果的影响
为了验证迁移学习对CNN在SED数据集上的必要性和有效性,进行了迁移学习和不使用迁移学习的对比实验,实验结果如表5所示.实验结果表明,基于迁移学习的融合模型在测试集上的A,P,R和F1值较不使用迁移学习融合模型分别提升21%,18%,20%,20%.采用迁移学习方法后,数据限制就不再明显,这对于小数据集而言,提升效果非常显著.

表5 迁移学习与不使用迁移学习结果对比(*代表不使用迁移学习)
4.3.3 消融实验
为了进一步验证选取ResNet50和InceptionV3模型进行融合的有效性,再次做了相关的消融实验,比较不同模型融合的检测性能,实验结果如表4所示.其中将A和B融合的模型用Cat_A_B表示,例如Cat_AlexNet_Vgg16代表将AlexNet和Vgg16模型进行融合.
对于模型融合来说,通常可获得比单模型更好的泛化性,至少对于较弱模型来说能有一定的提升(见表6),表6中,Cat_AlexNet_Vgg16、Cat_AlexNet_ResNet50、Cat_Vgg16_InceptionV3、Cat_ResNet50_InceptionV3相比于表现较弱的单模型性能都有一定提升.但也发现Cat_AlexNet_InceptionV3和Cat_Vgg16_ResNet50没有明显的提升.分析原因,通过表4中的单模型结果来看,对于ResNet50和Vgg16在SED上表现较好,这2个模型虽然在结构上有一定的区别,但本质上是通过不断加深网络结构来提升性能.对于我们自建的体育器材数据集涉及种类较多,其中超类中的很多子类别差异性较小,所以通过较深的网络模型来提取更丰富的特征从而达到较好的分类效果.模型的融合一般是来做信息互补的,将2个较为相似的网络进行融合,效果并不会变好.所以Cat_Vgg16_ResNet50效果提升并不明显.

表6 不同模型融合测试结果对比
对于单模型AlexNet和InceptionV3在SED上效果较差,分析原因可知,AlexNet的深度只有8层,且SED数据集涉及样本较多但数据数量较少,学不出较好的特征,从而导致效果较差.对于InceptionV3网络,其目标并不是精准化特征提取,而是通过使网络变宽,提高特征张量宽度,复用更多的特征,来提高分类性能.这种网络更适合于图像中目标大小差别很大的图片.对于本文的数据集,涉及的场景较丰富,同种器材在不同场景下的大小也不一致,这给InceptionV3网络带来一定挑战,将这两个较弱的模型融合后,并不能取得很好的效果.因此要选出好而不同的模型进行融合才能达到更好的效果,对于本文的数据集,选取选取2个网络结构差异较大的网络ResNet50和InceptionV3结合,ResNet50在深度上有优势,InceptionV3在网络的宽度上有优势,将二者的优势进行互补.从而达到提升分类性能的效果.
此外还比较了两种特征融合方式,结果如表7所示,由表7可发现基于Add操作的融合方式的性能低于基于Concat操作.分析原因:(1)直接Add操作会对信息造成负面影响.如果两个被加的向量不具备同类特征含义时,通过Add操作,会得到新的特征,这个新的特征可以反映原始特征的一些特性,但是原始特征的一些信息也会在这个过程中损失,Concat是将原始特征直接拼接,让网络去学习如何融合特征,在这个过程中信息不会损失.(2)逐元素加和的方式要求不同层的特征具有完全一致的通道数量.Concat不受通道数量的限制,拼接为横向或纵向空间上的叠加.虽然会改变维度,但能够保留更多的特征信息.

表7 不同融合方法的模型性能比较
4.3.4 基于ResNet50和InceptionV3模型融合的F1值分析
为进一步验证本文方法的有效性,对ResNet50、InceptionV3和Cat_ResNet50_InceptionV3 3种模型在所有超类上的F1值进行比较.如表8所示.
由表8可知,该体育器材图片数据集在单模型上训练时,ResNet50在所有的超类中能表现出较好的结果,再次证明了ResNet50网络的性能优势.利用Concat的融合将ResNet50和InceptionV3模型融合后,融合模型在球类、冰雪器材和健身器材类的F1值比ResNet50的F1值分别提升了3.6%,5.9%,2.0%.相比较于InceptionV3,F1值在所有超类中都有提高,幅度在1.7%~11.4%之间.虽然InceptionV3在总体超类上的性能低于ResNet50,但是对于超类中的子类,与ResNet50融合后还是有一定的优势,为了更直观的说明这种优势,列举了通过融合InceptionV3和ResNet50模型后F1值提升较为明显的类别,如表9所示.针对下述举例的类别,虽然在每个单模型表现的性能不是很好,但是在模型进行融合后上,效果有很显著地提升.

表9 提升效果明显类别的F1值
4.3.5 识别结果测试
测试了6张图片,分别将图片传入Resnet50和Cat_ResNet50_InceptionV3模型中进行分类识别,结果如图7所示,可以看出,模型的融合能够提升一定的识别效率.因此本文提出模型特征融合方法对体育器材图像识别是有效的.

图7 体育器材图片识别效果
5 总结与展望
针对现有基准体育器材图像数据集的种类较少、缺乏实用性等问题,本文构建了体育器材数据集SED.相比之下,SED数据集在种类数量和可拓展性方面具有较大的优势.当样本的种类增加但数量却不足时,会带来分类精确率和泛化能力弱的问题,基于此本文提出模型融合与迁移学习相结合的体育器材分类方法,通过模型融合结合多方位信息来获取更准确的分类,再利用迁移学习来解决体育器材数据有限的问题.最终在测试集上得到A为85%,P为85.6%,R为85%,平均F1值为84.7%.相比于单独使用卷积神经网络模型的方法准确率有所提升.但是目前仍然有一些尚待解决和值得研究的问题:(1)目前采用的融合方法,仅仅是对两个模型提取出的特征进行单纯地融合,下一步希望探索尝试更有效的特征融合方法.(2)需进一步扩建数据集,并尝试将目标检测功能添加到模型中,进一步提高模型的识别率和实用性.(3)目前仅仅是在实验室搜集的图片集上达到不错的分类效果,还需要其他的图片进行验证.
猜你喜欢
文体用品与科技(2022年20期)2022-11-20
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年13期)2020-01-14
魅力中国(2019年7期)2019-12-18
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
初中生世界·七年级(2017年9期)2017-10-13
