
面向电力作业的工作票分割与作业信息提取方法
2023-01-14 12:10林翔宇彭博雅
电力科学与技术学报 2022年6期
丘 浩,张 炜,林翔宇,蒙 亮,彭博雅
(1.广西电网有限责任公司电力科学研究院,广西 南宁 530023;2.广西电网有限责任公司,广西 南宁 530023)
电力作业中票证作业制度是保障危险性较大作业(如动火、动电、动土、进入受限空间、高处作业及检查维修作业等)安全性的基本制度。工作票的主要内容是明确工作职责、评估危险作业时可能发生的问题以及应采取的应对措施[1-2]。基于工作票中的作业信息,可以有效引导工作人员规避作业风险。
为了便于传输与打印,电力工作票文件通常以PDF(portable document format)格式存储,需要人为将其内容录入作业前风险评估系统。由于工作票表格结构复杂、内容繁多,人工提取表格信息不仅耗费时间,而且容易出错。光学字符识(optical character recognition,OCR)技术是近年来得到快速发展的一种自动文本提取技术。1929年德国科学家Tausheck首次提出了OCR的概念[1]。1960年后得益于计算机技术的发展,OCR技术逐渐得以实现。近10年来,深度学习算法的发展成熟显著地推动了OCR技术的普及应用。1998年LeCun等人提出了LeNet卷积神经网络框架[3],并首次将深度学习算法用于识别手写数字;为了提高卷积神经网络的特征提取能力,Alex于2012年提出了AlexNet深度卷积神经网络[4]。文献[5]在AlexNet的基础之上提出了VGGNet,增加网络深度的同时使用了更多连续的小尺寸卷积核,可以减小模型的参数量、提高易用性;文献[6]将字符识别看成序列识别问题,提出卷积循环神经网络(convolutional recurrent neural network,CRNN),成为了当下的主流OCR模型之一。OCR技术的识别准确率能较好地满足一般应用,已在交通和贸易等领域得到广泛应用[7-8]。
与简单的字符识别不同,实际业务文档往往包含多个相对复杂的结构性模块,这些模块之间具有相对独立而又关联的复杂关系,从具有复杂结构的文档中提取有效信息仍然是一项具有挑战性的工作。除识别文字外,准确识别复杂表格结构以及单元格信息之间的匹配关系是在实际业务文档中应用OCR技术的瓶颈。
文献[9]提出了一种基于深度学习的表格结构识别方案,该方案可处理结构简单的表格文件,但失败案例也将随结构复杂度的提升而明显增多;文献[10]设计了一个票据字符识别平台,对市场交易中常见票据的采取票据版面分析后,由基于YOLO-v3的目标检测算法提取定位票据中表格区域信息,再采取OCR引擎识别。该模型能泛化不同格式的票据图像,但由于模型参数量庞大,需要有海量的训练数据,对硬件性能的要求也较为苛刻。文献[11]提出使用语义识别的方法进行电力工作票的文字识别与语义分割,但OCR字符检测效果受表格框线影响较大并会导致识别精度低下、影响语义识别的效果。以上方法均基于“深度学习+OCR”的方法实现表格分割,但普遍存在模型训练量大、工作票分割效果受OCR检测准确率影响较大等问题。
本文利用电力作业工作票的复杂结构具有框线分割的特点,提出一种电力作业工作票分割与作业信息自动提取方法。该方法首先提取框线来分割单元格,然后使用OCR技术识别各单元格的工作票作业信息,最后基于正则匹配方法对识别结果进行结构化处理。与传统方法相比,该方法不需要额外的模型训练,运算量小,同时可有效避免表格框线对OCR检测精度的影响,提高电力工作票的识别效率。
1 基于CRNN的光学字符识别算法
光学字符识别是模式识别领域的重要分支在图像文档的信息提取中有广泛应用。传统OCR方法采取人工设计的特征,在复杂场景中表现出识别率低、泛化能力弱等缺点[12-13]。因此,对基于深度学习的OCR方法的研究成为主流。在基于深度学习框架的OCR技术中,人工神经网络主要用于提取字符特征以及根据特征进行分类的功能。人工神经网络的加入省去了人工设计特征和训练分类器的步骤,极大地简化了人工设计的过程。
在CRNN应用于字符识别技术之前,文字识别过程分为单字切割和分类任务两步。识别过程高度依赖于字符切分结果,误切分对识别准确率有突出影响。基于CRNN的字符识别模型将文字识别转化为序列学习问题,不再需要字符切割环节,在图像的序列识别上具有良好的表现。CRNN由卷积层、循环层和转录层3个部分组成,其结构如图1所示。
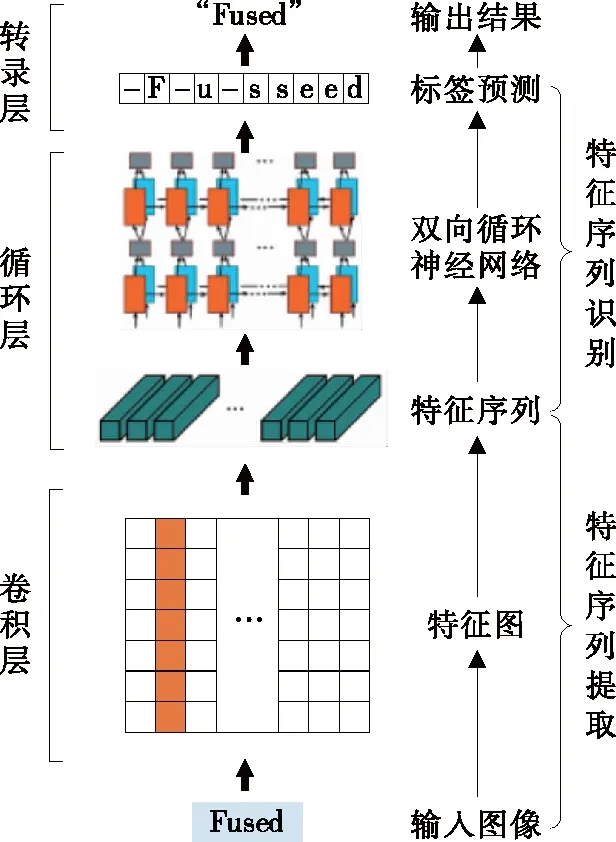
图1 CRNN结构Figure 1 The network architecture of CRNN
CRNN从输入图像提取文字信息的流程可以分为两部分:①特征序列提取,即在CRNN底部,由连续分布的多层卷积神经网络自动从输入图像中提取特征,得到特征图,然后转化成特征序列;②特征序列识别,即循环神经网络对特征序列中的每个特征向量进行学习后输出预测标签分布,由转录层从预测的标签分布中找到概率最高的标签序列,之后转换成最终的识别结果。
1.1 特征序列提取
CRNN的卷积层采用卷积计算层和最大池化层的组合。卷积计算层的核心是一个二维滤波器(卷积核)。卷积操作如图2所示,卷积核中每个元素都代表一个权重值,通过滑动滤波的方式,将输入图像与卷积核中的对应元素依次相乘并求和,进而确定特征图中的元素值[14]。

图2 卷积操作Figure 2 Convolution operation
池化层分布在卷积计算层之间,常用的池化方式有平均池化和最大池化,平均池化选取区域均值作为该区域的值,而最大池化则选取区域最大值作为该区域的值。池化操作可以去除冗余信息,压缩数据和参数的量,对邻域内特征进行聚合[15]。
通过卷积与池化操作会将输入图像所包含的原始数据映射到特征空间,形成特征图。从卷积层输出的特征图无法直接送入循环层进行训练,需要转化为特征序列。因此,在CRNN的结构中加入了一个转换层,在该层将特征图中的某列像素顺序连接就形成了一个特征向量,所有的特征向量就构成一个序列。
1.2 特征序列识别
区别于传统的目标检测方法,字符识别的目标通常是一个序列,将字符识别看成序列识别问题,需要引入循环神经网络(recurrent neural network, RNN),RNN以序列数据为输入,具有一定记忆能力,能够存储短时间内输入数据的信息,这是因为在RNN中,当前时刻的输出ht由当前输入xt和前一时刻输出ht-1共同决定,即
ht=f(Uxt+Wht-1+b)
(1)
其中,U、W是权重系数,b为偏差量,这些值都是通过训练得到的。
在传统的RNN中,时间累积会最终导致梯度消失现象。为克服该问题,有学者提出了一种改进后的RNN结构—长短时记忆网络(long short-term memory,LSTM)[16],LSTM单元引入门控机制,通过遗忘门、输入门和输出门来控制细胞状态,实现新信息的加入和无用信息的遗忘,其结构如图3所示,具体步骤如下。
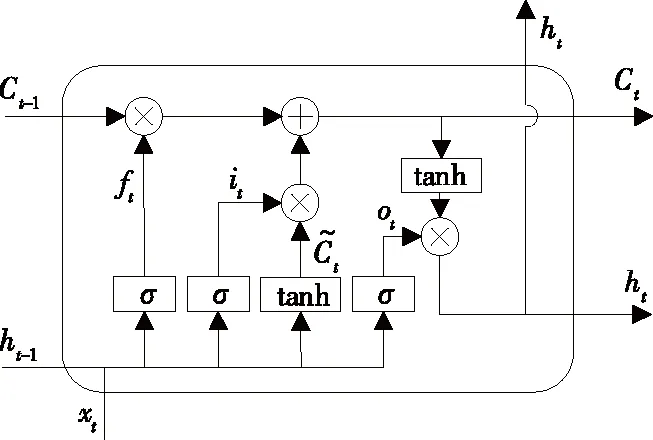
图3 LSTM单元结构Figure 3 The structure of LSTM
1)由遗忘门决定细胞状态,需要遗忘上一个状态ht-1的部分信息,其表达式为
ft=σ(Wf[ht-1,xt]+bf)
(2)
2)经过输入门决定细胞状态添加哪些新的信息。输入门的输出可以表示为
it=σ(Wi[ht-1,xt]+bi)
(3)
(4)
(5)
4)由输出门输出更新后的状态ot,并将其与处理后的细胞状态相乘,获得序列的识别结果ht。
ot=σ(Wo[ht-1,xt]+bo)
(6)
ht=tanhCt
(7)
在LSTM单元中,信息的传递是一个单向过程,因此,单个LSTM单元只能利用文字序列中某一个方向的信息。将一个LSTM向前另一个向后组合,形成一个双向LSTM,就能同时利用上下文信息。当LSTM输出的序列分布输入转录层后,通过去冗余操作,解码即可输出概率最大的文字识别结果。
2 电力作业工作票分割与作业信息提取方法
本文设计的电力作业工作票分割与作业信息提取方法具体工作流程如图4所示。该方法主要包括表格分割和作业信息提取与结构化两部分。工作票表格分割部分包括3个模块:工作票二值化处理、表格框线检测和单元格分割模块。作业信息提取与结构化部分包括:作业信息提取和信息结构化处理模块。

图4 电力作业工作票分割与作业信息提取流程Figure 4 The workflow of proposed method
2.1 工作票表格分割
2.1.1 工作票二值化处理模块
输入的工作票文件为彩色图像,为去除图像中的冗余信息、提高工作效率,需要对输入的工作票图像进行二值化处理,把大于某个临界灰度值的像素灰度设为灰度极大值,把小于这个值的像素灰度设为灰度极小值,其公式如下:
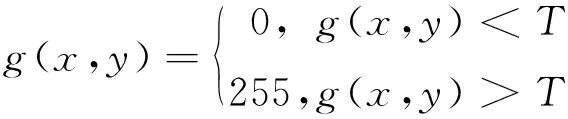
(8)
式中g(x,y)为该点的灰度值,范围为0~255;T为临界灰度值(阈值),工作票文件存在的色系固定且有限,因此阈值T可设为固定值。
对工作票进行二值化处理后的效果如图5所示。二值化仅去除对文字识别无用的部分颜色信息,不会改变图像中的作业信息与表格结构信息。

图5 工作票经二值化处理后的效果Figure 5 Result of binarization of work ticket
2.1.2 表格框线提取模块
表格框线提取实际上是将表格框线像素与非框线像素分离的过程,可以采取基于数学形态学的方法来实现。数学形态学中有2种最基本的运算:腐蚀和膨胀[17]。数学形态学的运算过程需要2个对象:一个是输入图像,记其代表的所有像素集合为A;另一个是结构元素,记其代表的所有像素集合为B。腐蚀和膨胀运算的过程如图6所示。
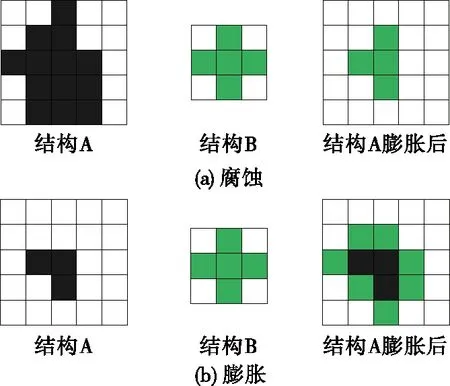
图6 数学形态学基本运算Figure 6 Basic operations of mathematical morphology
腐蚀是一种消除边界点,使边界向内收缩的过程。膨胀是腐蚀的对偶运算,是一种使边界向外扩展的过程。形态学运算可以看成是在目标图像中检测由结构元素所描述的特征形状的过程,这一特性可用来检测图像中的表格框线。采用形态学运算的表格框线提取步骤如下:
1)使用大小为l1×1的水平结构和1×l2的垂直结构元素,对表格区域进行水平和垂直方向的腐蚀,分别获得水平和竖直框线;2)使用大小为l1×1的水平结构和1×l2的垂直结构元素,对腐蚀过的图像进行膨胀,更好地恢复水平和垂直表格框线;
3)将前两步得到的框线在同一坐标系下相加,即得到完整的表格区域以及单元格顶点位置信息。
表格框线提取效果主要取决于结构元素的长度l1、l2。若l1、l2太长,在步骤1)中会腐蚀掉一些较短的表格框线,得到的表格结构不完整;若l1、l2太短,则会保留一些不必要的文字线段,对之后的识别造成干扰。因此,结构元素的长度应满足2个条件:小于最短表格线的长度和大于单个字符的尺寸。
使用本文提出的框线提取方法处理电力作业工作票的结果如图7所示,可以看出,2种表格框线均被完整提取,而在水平表格框线图中存在部分非框线像素,这些像素来自于工作票文档中的文下划线,由于这些下划线不会与垂直表格框线相交,因此不会影响对表格结构的判断。

图7 表格框线提取Figure 7 Table frame lines extraction
2.1.3 单元格分割模块
该模块接收来自表格框线检测模块输出的表格框线和交点位置,然后对工作票表格进行单元格分割,其流程如图8所示。具体步骤如下:
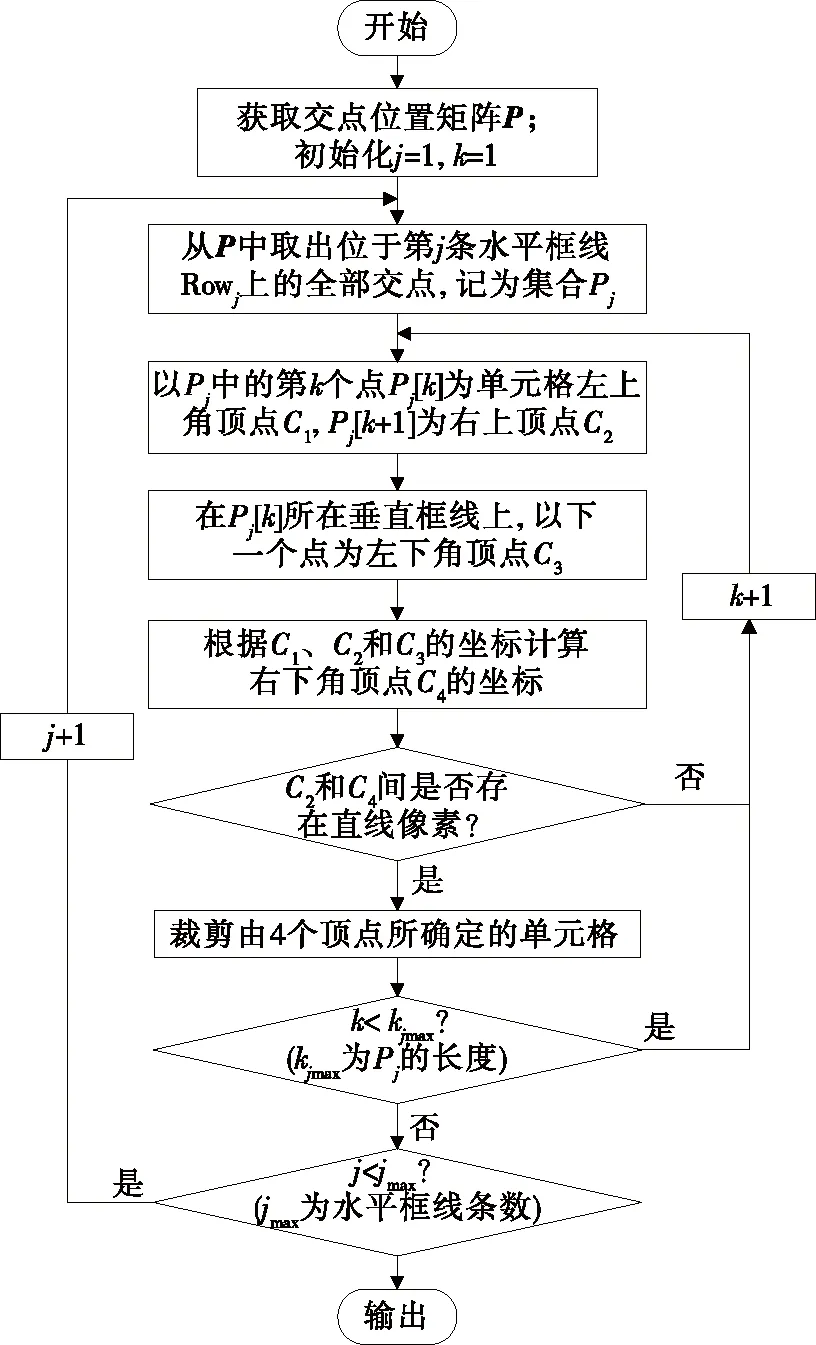
图8 单元格分割流程Figure 8 Flow chart of cell segmentation
1)从图片最上方开始,记录下第1条水平表格框线上所有点的位置,从第1个点开始,以它为一个单元格的左上角顶点,然后判断该点下方是否存在构成直线的连续像素;若存在,则该点为一个单元格的左上角顶点;2)在同一水平位置上向右寻找该单元格的右上角顶点,找到右上角顶点后,判断该顶点下是否存在构成直线的连续像素;3)在与左上角顶点同一垂直位置的直线上寻找该单元格的左下角顶点,最后一个顶点可以根据已知的3个顶点位置推断确定,只需验证在对应位置是否存在第4个顶点即可;4)通过4个顶点的位置信息,可确定对应单元格所在区域;而后可将该单元格所在区域裁剪、保存并进行编号,保留其所在的行信息与列信息;5)对处在同一水平位置的顶点重复步骤1)~4)中的操作,可分割出该行所有的单元格;6)跳转到下一行重复上述所有操作,直至所有单元格分割完毕。
单元格分割结果如图9所示。对单元格进行编号时应当保留单元格在原表格中的行列信息,统一命名格式为“0i_0j_0k”,表示该单元格在工作票文件的第i页,第j行,第k列。

图9 单元格分割结果Figure 9 Result of cell segmentation
2.2 作业信息提取与结构化处理
分割单元格可将复杂表格的识别任务分解为多个单元格图像识别子任务。对所获得的单元格图像只需要通过CRNN模型就能准确提取其中的作业信息。进行本次电力作业风险评估只需要全部作业信息中的部分关键信息(如工作任务,工作地点,单位和班组等)。为此,需要对文字识别结果进行结构化处理,通过正则表达式检索和匹配符合所需模式(规则)的文本以提取所需信息。
3 实验验证
为评估所提方法的性能,训练一个卷积循环神经网络,并对100份实际的工作票文档进行信息自动提取。
3.1 训练过程
基于MXNet深度学习框架搭建CRNN模型,具体结构如表1所示。在特征提取阶段共包含6层卷积计算,均采用3×3大小的卷积核,0~5层的卷积神经网络滤波器数量分别为64、128、256、512、512、512。循环层为2层各256个隐藏单元的双向LSTM。转录层使用CTC(connectionist temporal classifier)作为损失函数,对序列进行解码。表中k表示卷积核大小,s表示卷积核滑动时的步长,p表示可用于填充的零元素列数。

表1 CRNN网络参数Table 1 Network parameters of CRNN
从中文语料库抽取文字后,通过计算机合成文本图像样本作为数据集。该数据集共包括约200万张图片,涵盖了汉字、英文、数字和标点4大类共3 870个字符。按9∶1将数据集分成训练集和测试集。在搭载Intel Xeon Gold 6240 CPU(2.50 GHz)和NVIDIA GeForce GTX 1650 显卡(4 G)的计算机上完成训练,训练准确率如图10所示。
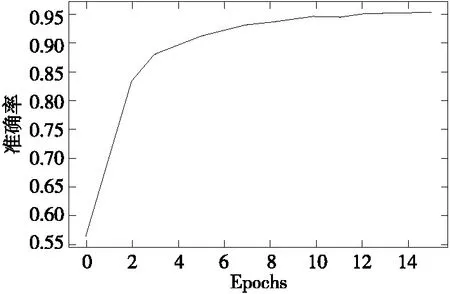
图10 识别准确率Figure 10 Training accuracy
3.2 实验结果与分析
分别采用本文所提方法与市面常见的商业文字识别软件对工作票文档进行信息提取,如图11所示。

图11 文字识别结果Figure 11 Results of character recognition
在图11(b)中,当商业软件对标题“计划工作时间”及其对应字段值“自2020年06月30日09时30分至2020年06月30日18时30分”进行识别时,由于没有正确处理表格结构出现了识别错误,标题与字段值无法保持正确的匹配关系,导致后续数据结构化时提取“工作时间”项信息失败。本文所提方法采用单元格分割算法将复杂表格文档的文字识别拆分为多个单元格图像的文字识别,识别结果正确保留了原表格中各个标题及对应字段值的逻辑关系。对该结果进行结构化处理得到的效果如图12所示。

图12 数据结构化处理Figure 12 Data structure processing
对100份实际工作票文档进行信息提取的实验统计结果表明,本文所提方法文字识别准确率达95.18%,略低于文字识别模型在测试集上的识别准确率。单次信息提取过程平均耗时为22.41 s。
4 结语
本文着眼于实际应用场景,提出了一种电力作业工作票分割与作业信息提取方法,能够从工作票文档复杂的表格结构中快速且准确的提取电力作业的关键信息,提升了电力作业风险评估效率。在框线提取过程中,由于有少量下划线像素保留,可能会造成文字识别错误,因此,本文的研究工作还可以进一步完善。之后的研究也将关注自然语言处理领域[18],对识别结果进行查错和纠错,以进一步提升输出的工作票信息的正确程度。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
现代临床医学(2022年1期)2022-02-12
电脑爱好者(2021年12期)2021-06-22
电脑爱好者(2021年8期)2021-04-21
数学大王·趣味逻辑(2020年6期)2020-06-22
数学大王·趣味逻辑(2020年5期)2020-06-19
文化创新比较研究(2020年13期)2020-01-01
红领巾·萌芽(2019年8期)2019-08-27
高中时代(2017年7期)2018-02-24
小天使·六年级语数英综合(2017年10期)2017-10-20
