
RVO-DDPG算法在多UAV集结航路规划的应用
2023-01-13 11:59:20杨秀霞高恒杰
计算机工程与应用 2023年1期
杨秀霞,高恒杰,刘 伟,张 毅
1.海军航空大学 岸防兵学院,山东 烟台 264001
2.海军航空大学 作战勤务学院,山东 烟台 264001
在军事应用领域,单无人机往往很难实现任务预期,多无人机编队、有人/无人协同编队等编队形式逐渐引起人们的重视,随着UAV技术的不断发展,无人机自主编队控制技术已经引起了国内外学者的广泛关注[1]。
无人机编队航路规划的重难点在于不确定环境下的动态避障航路规划和多机协同规划,而多无人机编队集结路径规划不仅需要考虑不确定环境、无人机性能约束,还需要满足各UAV之间的时间协同和空间协同约束,是一个约束众多、复杂且相互耦合的多目标优化问题[2]。文献[3]提出了具有合作机制的分布式协同粒子群算法,该方法使每架UAV规划出一条满足机间协同约束的最优安全可飞行路径。文献[4]提出了一种新的路径规划和位置分配方法,通过矩阵迭代得到一组较优的目标点分配方案。文献[5]设计了一种新的快速共识方法,实现了多UAV能够同时到达目标区域。文献[6]提出了GRC-SAS算法将多UAV合作问题分解为连续的单UAV计划问题,满足了多UAV动态规划的需要。文献[7]提出了基于Dubins路径的分层规划方法,该方法相对于多UAV非线性方法提供更优的路径。文献[8]采用粒子群优化算法为UAV设计dubins曲线参数,使得多UAV能够同时到达集结点。文献[9]采用模型预测控制实时调整各UAV航路以实现多UAV集结航路规划。文献[10]提出基于A*算法规划UAV集结航路,并采用B样条曲线对航路进行平滑。文献[11]提出了一种分区集结的控制策略,将集结点分为多个分区,不同分区的UAV按一定规则向分配的集结点航行。文献[12]提出基于定向A*算法的多UAV同时集结分步策略,通过调整各UAV的航路实现多UAV的同时集结。文献[13]将UAV集群集结航路规划问题转化为最优控制问题,并采用Radau伪谱法进行求解。文献[14]提出基于虚拟导引点的三阶段UAV制导律,将UAV与虚拟导引点的距离分为三个阶段并分别设计UAV制导律。文献[15]根据编队集结的要求为各UAV设计Dubins集结路径,并通过一致性控制协议完成多UAV集结航路规划。
尽管上述方法在其各自的环境中都实现了规划的目标,但是仍然存在一些不足,主要表现在以下几点:一是大多算法仅在静态环境中进行多UAV编队集结路径规划,缺乏处理动态障碍的能力,很难应用于不确定环境中。二是上述方法过于依赖环境动态模型和UAV模型,这些模型的准确性很大程度上影响其方法的性能。尤其在不确定环境中,上述方法时刻计算多UAV和障碍的状态并为UAV寻找安全的航路,不但大量浪费计算资源,而且计算时间长不易满足多UAV应用于不确定环境中的需求。因此,设计一种算法能够使多UAV在集结过程中快速避障并安全达到集结点是十分必要的。
针对以上问题,在传统DDPG算法基础上引入互惠速度障碍法,本文提出了一种基于RVO-DDPG的多UAV集结路径规划算法,根据此算法对多UAV在集结过程中的航路进行规划。首先,提出了基于DDPG的多UAV集结航路规划算法,基于马尔可夫决策过程设计了集结航路规划模型。其次,引入互惠速度障碍法指导UAV在避碰过程中有效地选择动作,提高了算法的收敛速度。再次,将多UAV编队中多目标优化问题转化为奖励函数设计问题,设计了一种基于综合代价的奖励函数,有效解决了传统DDPG算法应用于集结航路规划时易产生局部最优路径的问题。最后基于PyCharm软件通过仿真实验验证了该算法的性能并与其他算法进行对比分析。仿真实验结果表明,本文提出的基于RVO-DDPG算法不仅能够为多UAV编队集结任务快速规划出最优航路,而且具有良好的收敛性和实用性。
1 问题描述
1.1 任务描述
假设有N架UAV从起始点出发,在不确定环境中的目标点完成集结。环境内存在多个动态障碍和静态障碍。其中静态障碍主要为禁飞区域、雷达威胁区域,动态障碍主要为非合作飞行器。为简化问题,将不规则静态障碍用其外接圆表示。任务环境如图1所示,图中黑色圆形区域表示静态障碍,红色圆形区域表示移动的非合作飞行器,统一视为动态障碍,三角形区域为UAV的集结点。
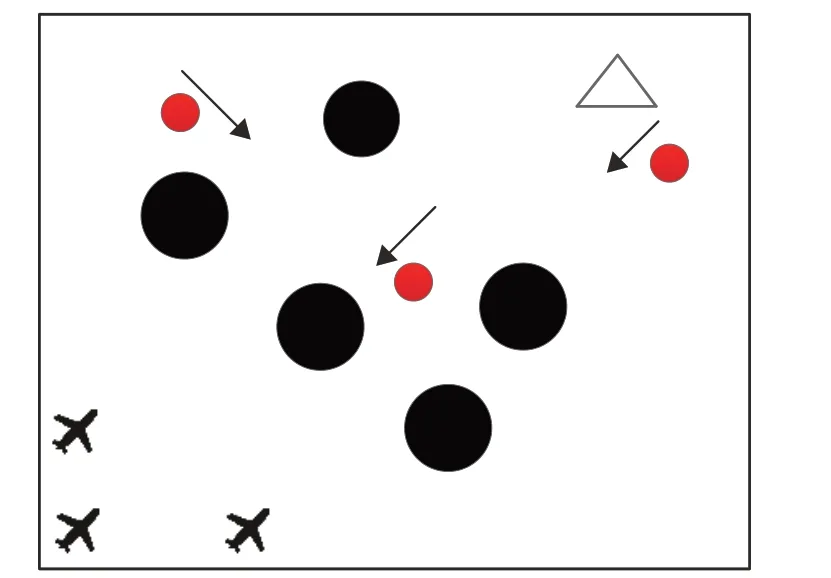
图1 飞行任务环境示意图Fig.1 Schematic diagram of mission environment
本文的研究对象为装备有机载探测器的UAV,UAV的探测能力用以下约束条件表示:

其中,d表示从UAV当前位置到障碍的距离,dsensor为机载探测器的最大探测距离。为研究方便给出以下假设:
(1)研究问题在二维平面内,不考虑无人机的高度。
(2)UAV能够实时探测并获得该范围内的障碍信息,并且获知障碍信息时没有延迟。
(3)UAV和动态障碍的运动方式为匀速直线运动。
综上所述,各UAV在不确定环境中的任务为从起始点出发,在飞行过程中使得总代价J最小的前提下,避免我方UAV和动、静态障碍物并达到集结区域形成编队队形。
1.2 UAV运动学模型
根据前文描述,将航路规划问题中的UAV看作质点运动模型,使用航向角的角速度来控制UAV的运动过程。UAV的运动方程可表示为:

式中,vu表示UAV在XOY平面内的速度,α为航向角,ω为航向角速度。
1.3 多UAV飞行代价约束
1.3.1 UAV运动学约束
在飞行过程中,UAV的航向角、航向角速度都必须在一定范围内变化,以满足UAV的飞行性能约束JUAV。其约束条件为:

1.3.2 航程代价约束
UAV航程代价可以表示为:

式中,c1为比例系数;Li表示第i架UAV的航路长度;JL,i为第i架UAV的航路代价函数。
1.3.3 碰撞代价约束
碰撞代价Jobs,i分为静态障碍碰撞代价Js_obs,i、动态障碍碰撞代价Jd_obs,i以及UAV之间的碰撞代价JUAV,i,即:

在前文中已经说明将各不规则障碍用其外接圆表示,在此设定其安全距离。动态、静态障碍物的安全距离为其外接圆的半径。而对于UAV之间,设定其安全距离为400 m。
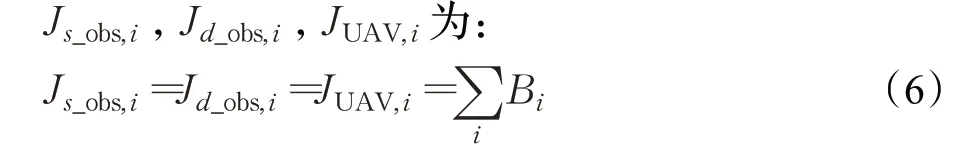
其中:

1.3.4 时间协同代价约束
编队成员间的时间协同代价可表示为:

式中,Li为第i架UAV达到集结点的航行路程,Lc为N架UAV达到集结点的航行路程平均值,N为UAV的数量,Jt为时间协同代价函数。
1.3.5 综合航行代价
多UAV的综合航行代价描述为:

式中,W1、W2、W3分别为航程代价、碰撞代价、时间协同代价的权重,JL,i为航程代价,Jobs,i为碰撞代价,Jt为时间协同代价。多UAV航路规划的目的就是使无人机综合代价最小化。
2 DDPG集结航路规划算法
2.1 算法原理
深度确定性策略梯度算法(DDPG)是一种以确定性策略梯度算法(DPG)为基础、加入深度神经网络的基于actor-critic架构的确定性策略算法。DDPG网络架构由在线actor网络、目标actor网络、在线Q网络、目标Q网络四个网络组成,其四个神经网络更新的方式如下所示。
在线actor网络更新策略梯度为:

在线critic网络通过最小化损失函数进行更新,其损失函数为:

其中:

DDPG算法采取了软更新的方式更新目标网路参数,其目标actor网络、目标critic网络更新方式分别为:

其中,τ≪1。
对于DDPG算法而言,其存在的主要缺陷是探索能力不足。为解决此缺陷,DDPG算法引入了Behavior策略,即在线actor网络输出动作时加入随机噪声ηt,将智能体执行的确定值动作变为随机值动作at。

2.2 马尔可夫模型设计
通过DDPG算法将不确定环境中多UAV路径规划问题建模为马尔可夫决策过程。下面依次对该模型的三个元素,即状态空间、动作空间、奖励函数进行设计。
2.2.1 状态空间设计
状态空间s的设计与多UAV飞行任务密切相关,要对各UAV飞行时的状态变化有所反应。在不确定环境下的多UAV集结路径规划问题中,UAV状态空间设计主要考虑UAV的位置和航向信息以及集结点的位置。结合UAV运动学模型,状态空间s如式(15):

其中,( ux,uy)i为各UAV的位置;(α )i为各UAV的航向;( t arx,tary)i为各UAV的集结点。具体为:
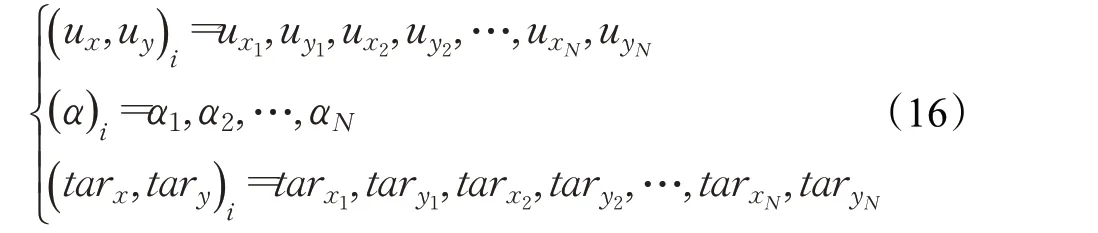
2.2.2 动作空间设计
如前文所述,UAV的飞行通过改变航向角α实现。控制策略每隔一次采样时间δt更新一次航向角速度。考虑到无人机最大航向角速度,并避免航向角的剧烈变化影响无人机的安全飞行,定义航向角速度动作空间a∈A为:

若t时刻无人机航向角为αt,则下一时刻无人机状态为:

2.2.3 奖励函数设计
DDPG集结航路规划算法中,奖励函数是在各UAV做出动作并与环境进行交互后由环境反馈的奖惩信号。针对航路规划中UAV的安全和达到集结点的问题对奖励函数设计如下:

2.3 算法流程
DDPG集结航路规划算法通过对多UAV航向角速度的学习进行航路规划。在进行航路规划时,UAV传感器将获取的环境数据输入在线actor网络,在线actor网络根据环境数据使用策略梯度进行策略学习选择各UAV航向角速度,在线critic网络则根据UAV所处环境状态以及所做动作对价值函数进行评估,根据产生的评估信号评价各UAV航向角速度。
算法与环境交互获得样本数据(s,a,r,s′),并将其存入经验池中。在样本数据中,s为某一时刻各UAV从环境中观测到的状态信息,a为各UAV根据观测到的状态信息s执行的动作,s′为各UAV在执行动作a后从环境中观测到的状态信息,r为各UAV在状态s的情况下执行动作a后获得的奖励值,各UAV根据奖励值的大小选择最优动作策略。DDPG路径规划算法进行更新迭代时,首先对经验池进行样本数据积累直至达到最小批次所规定的数量,然后随机从经验池中采样batch_size个样本数据进行训练并更新其神经网络。最后训练好的神经网络为各UAV规划出集结航路。
2.4 传统DDPG集结航路规划算法不足之处
首先是避障过程中动作调整具有随机性导致算法收敛时间长。在采用DDPG算法的多UAV系统中,在线actor网络由动作空间中每个动作的选择概率和随机噪声的共同作用选择动作。在当前状态下选择此动作的奖励值少,则会降低该动作的选择概率,反之则提高该动作的选择概率。由于算法初期网络训练不充分,UAV在面对障碍时会选择错误航向角速度以降低该动作的选择概率。在很多次试错之后在线actor网络才会在面对障碍时选择正确的航向角速度,此时算法才开始收敛。所以传统DDPG算法应用于多UAV集结航路规划时存在训练时间长、算法收敛速度慢的缺点。
其次是航路集结问题中奖励函数设计不合理,易产生局部最优解。传统DDPG算法通过最大化奖励r计算目标的最优解。在多UAV编队集结问题中,奖励函数R对各UAV的动作决策进行量化评估,为各UAV学习航向决策提供有效的指导。但是多UAV集结航路规划问题的本质为多目标优化问题,而经过RVO-DDPG算法学习后的航路有可能只是使多UAV安全达到集结点的航路,只满足了UAV能够安全避障然后到达集结点,并不满足航路综合代价最小。此时规划出的集结航路为局部最优航路,而非全局最优航路。
3 RVO-DDPG航路规划算法
针对上述问题,本文将互惠速度障碍法与DDPG算法相结合,提出基于RVO-DDPG的多UAV集结航路规划算法,通过互惠速度障碍法指导各UAV在避障过程中的动作选择以加快算法收敛速度。同时设计了一种基于引导和约束的综合型奖励函数,避免产生局部最优航路。
3.1 改进动作选择策略
3.1.1 互惠速度障碍法的引入
假设UAV2突然探测到动态障碍Po( )xo,yo,如图2所示。只要调整α2使v2偏离速度障碍锥VO,即可完成避障。
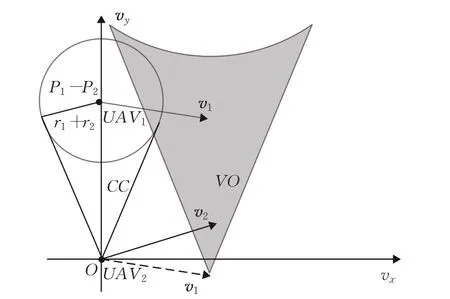
图2 速度障碍法示意图Fig.2 Schematic diagram of speed obstacle method
假设UAV2突然探测到友方UAV1,在UAV2避免碰撞过程中,考虑到UAV1也会进行机动,为了避免路径发生抖动,设定UAV2在避障过程中承担一半的避障任务,即将v2偏转出互惠速度障碍锥RVO即可[18]。如图3所示,互惠速度障碍锥RVO可由碰撞锥CC平移得到。

图3 互惠速度障碍法示意图Fig.3 Diagram of reciprocal speed obstacle method
3.1.2 改进动作选择策略原理
当UAV突然探测到友方UAV或动态障碍时,改进动作选择策略通过互惠速度障碍法和速度障碍法指导其对友方UAV和动态障碍进行避碰。首先UAV在探测范围内获取友方UAV或动态障碍的信息,然后根据碰撞锥判断是否产生碰撞。如果在未来某个时间点发生碰撞,则根据互惠速度障碍法或速度障碍法计算需要避碰的航向角,进而计算此时需要调整的航向角速度范围。如果在线actor网络选择的航向角速度在此范围内,则给予奖励,否则给予惩罚并重新选择航向角。互惠速度障碍法指导流程图如图4所示。

图4 改进动作选择策略原理图Fig.4 Schematic diagram of improved action selection strategy
3.2 改进奖励函数
针对传统DDPG算法奖励函数设计不合理易产生局部最优解的问题,本文提出一种基于UAV综合航行代价的奖励函数设计方法,将多UAV综合航行代价约束转化为奖励函数设计问题。根据UAV不同飞行状态和各种代价约束赋予不同的奖励值:
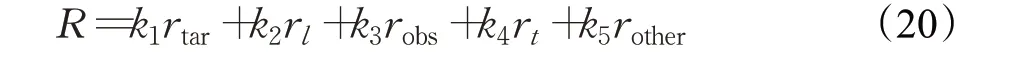
式中,ki(i=1,2,…,5)对应为相应奖励r的权重,rtar、rl、robs、rt、rother分别为UAV到达集结点、航行距离、碰撞、时间协同、其他飞行状态时的奖励。分别为:


其中,α为UAV调整后的航向角,αRVO为互惠速度障碍法计算后需要调整的航向角。需要注意的是,rtar、rl、rt为每一回合结束后计算的奖励,robs、rother为UAV每次选择动作与环境进行交互后计算的奖励。
3.3 RVO-DDPG算法伪代码
使用RVO-DDPG算法对多UAV在不确定环境中的编队集结任务进行训练,算法伪代码如下所示。
RVO-DDPG算法:
1.随机初始化在线actor网络Q(s,a|θQ)和在线critic网络μ(s|θμ)的网络参数θμ和θQ
2.初始化目标网络μ′和θQ′及其权重,θμ′←θμ,θQ′←θQ
3.初始化经验池
4.forepisode=1,max_episodedo
5.为行为探索初始化随机噪声ηt
6.收到初始观测状态s1
7.fort=1,Tdo
8. 各UAV根据式(14)选择动作at
9. 根据动作at、互惠速度障碍法与环境进行交互
10. 产生奖励值R,新的状态st+1
11.将元组数据(st,at,rt,st+1)存放至经验池中
12. 从经验池中随机采样N个元组数据(st,at,rt,st+1)
13. 根据式(11)更新当前critic网络
14. 根据式(10)更新当前actor网络
15. 根据式(13)更新目标网络
16.end for
17.end for
4 仿真分析
为验证本文提出的RVO-DDPG算法在多UAV编队集结路径规划问题的实用性和有效性,本文将以3架UAV从不同起始点出发集结生成V型编队的路径规划为例进行仿真实验。仿真软件为Pycharm2020.1.3,采用Open AI的Gym建立训练环境。
操作系统环境为Windows10 x64,使用软件工具包版本为Python3.6、Torch1.70,硬件信息为Intel i7-9750H,DDR4 16 GB和1.86 TB SSD。算法仿真参数如表1所示。

表1 算法训练参数设置Table 1 Algorithm training parameters setting
各UAV初始状态与性能如表2所示。本文将UAV、障碍物的速度和环境距离同比例缩小,在实际应用的过程中将其按比例放大即可。
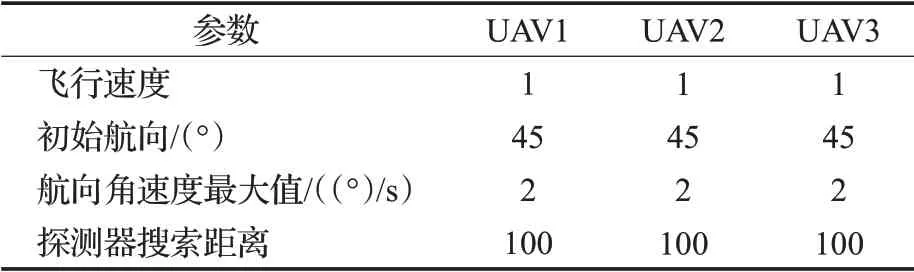
表2 各UAV初始状态与性能参数Table 2 Initial state and performance parameters of each UAV
4.1 不确定复杂环境实验仿真
为验证RVO-DDPG算法的可行性,在不确定复杂环境中验证和分析算法的有效性。不确定复杂环境包含多个静态、动态障碍且障碍信息均未知,其参数如表3、表4所示;UAV初始位置为(100,100)、(250,118)、(550,80),集结点位置、航向为(370,550,90°)、(400,580,90°)、(430,550,90°)。

表3 动态障碍物参数Table 3 Dynamic obstacle parameters
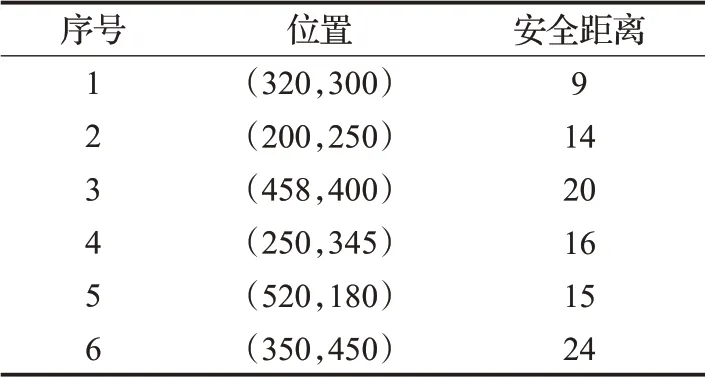
表4 静态障碍物参数Table 4 Static obstacle parameters
如图5为3架UAV在不确定复杂环境中进行航路规划的情况。从图中可以看出,各UAV在未知环境中各障碍信息的情况下,能够利用互惠速度障碍法调整自身航向角进行避障,还能够得到平滑且安全的规划航路。
图6、图7为各UAV在规划航路中的航向角、航向角速度速度变化图。由图6可知,各UAV到达集结点时航向角速度一致,达到了预期的效果。从图7中可以看出,各UAV的航向角速度变化范围均在[-2(°)/s,2(°)/s]之间,能够满足UAV航向角的约束。结合图5中平滑路径可知,改进DDPG算法能够为各UAV规划出安全的集结航路。同时,其航路平滑、所需航向角速度变化范围小的优点能够更有利于UAV飞行。
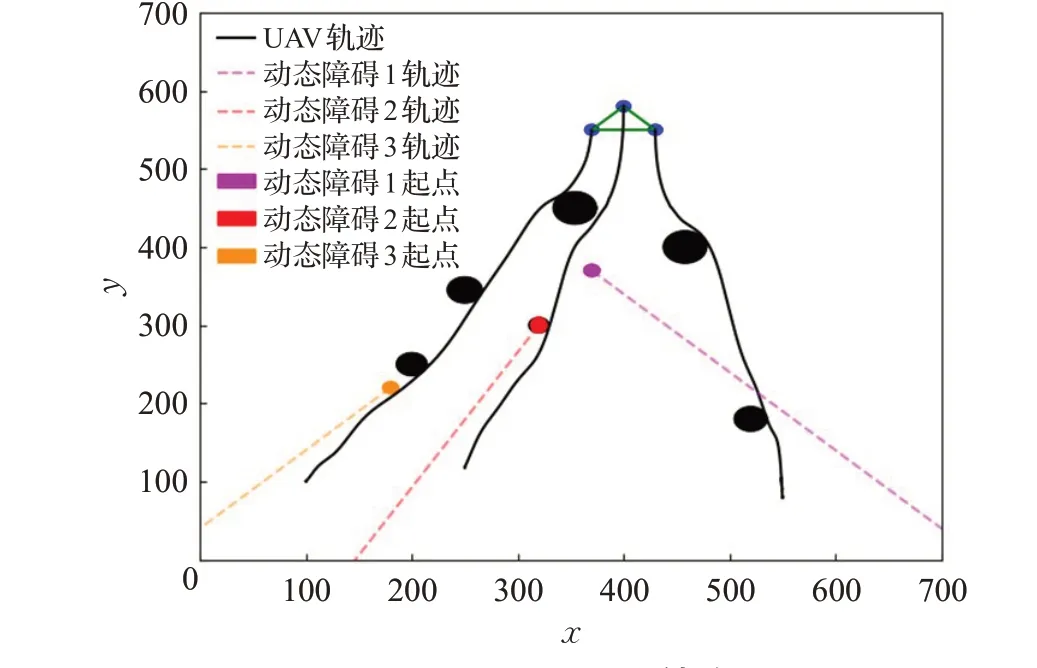
图5 UAV编队协同集结路径Fig.5 UAV formation collaborative assembly path
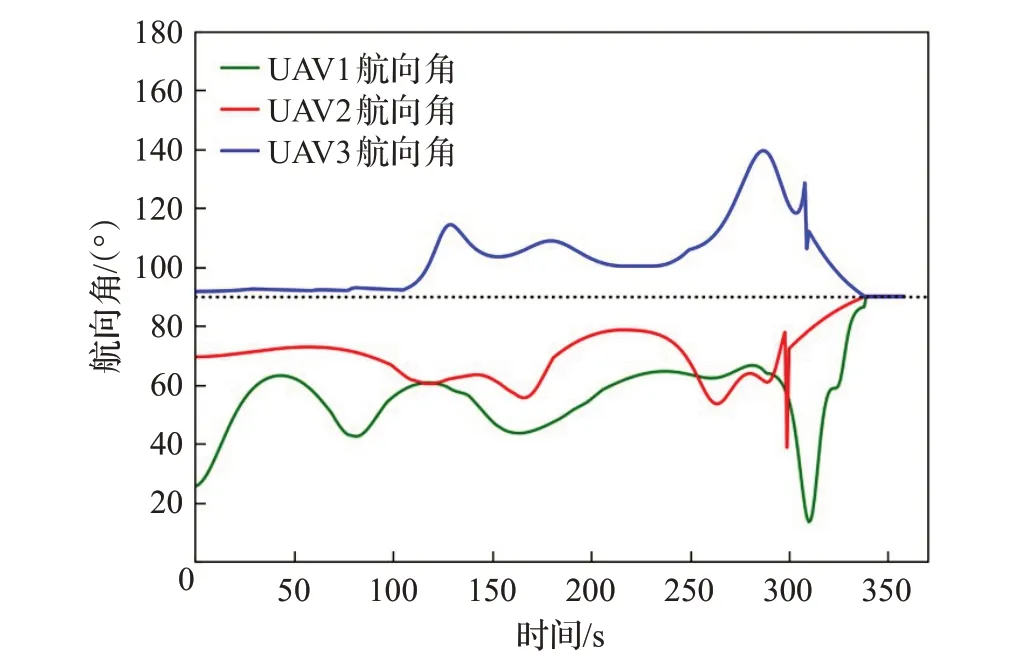
图6 各UAV航向角变化Fig.6 Change in heading angle of each UAV
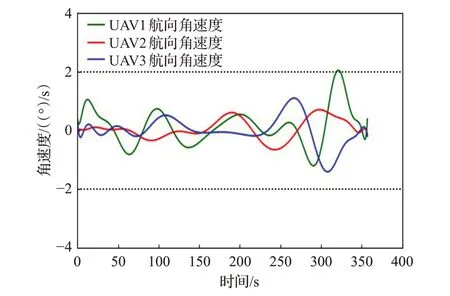
图7 各UAV航向角速度变化Fig.7 Changes in heading angular velocity of each UAV
如表5为集结航路中各UAV与障碍的最小距离。当UAV在探测范围内获取到动态障碍运动信息并判断可能发生碰撞后,通过速度障碍法快速调整其航向角进行避碰。由表5可知,航路中各UAV与动态障碍的最小距离均大于动态障碍的安全距离,说明UAV能够安全避开动态障碍。同理,当UAV探测到静态障碍的位置时,通过障碍锥判断是否会发生碰撞,当可能发生碰撞时,UAV立刻调整其航向角进行避碰。同时,在航程奖励函数的作用下,各UAV选择最小机动方式调整航向角,即UAV与静态障碍的距离稍大于静态障碍安全距离。此时,得到的集结航程奖励最高,航程代价最小。

表5 各UAV与障碍最小距离Table 5 Minimum distance between UAV and obstacle
如图8为改进DDPG算法在训练回合下的平均奖励值变化情况。从图8中不难发现,随着训练的不断进行,RVO-DDPG算法给出的航路使得奖励值不断提高,最终趋于平稳,说明多UAV集结航路综合代价奖励值收敛到最优值,即多UAV集结航路综合代价最小、规划的航路最优。

图8 奖励值变化图Fig.8 Change graph of reward value
4.2 对比仿真实验
为验证RVO-DDPG算法的实用性和有效性,将在3.1节环境下,分别采用改进DDPG算法和传统DDPG算法以及合作粒子群(CPSO)算法[9]进行航路规划实验仿真,其仿真结果如图9、图10和表6所示。
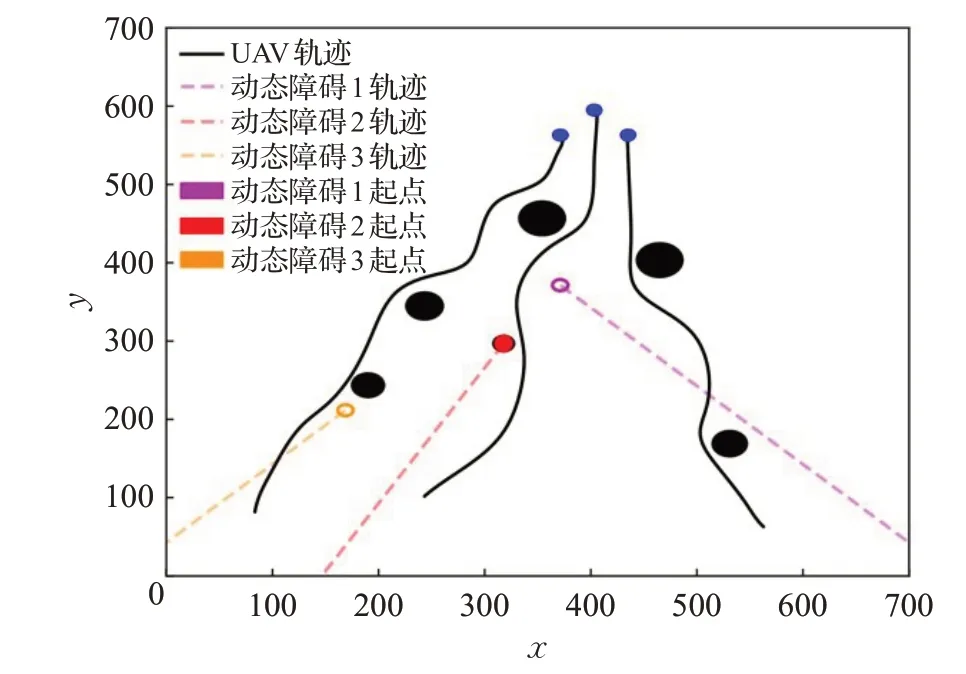
图9 传统DDPG算法规划航路Fig.9 Traditional DDPG algorithm for route planning
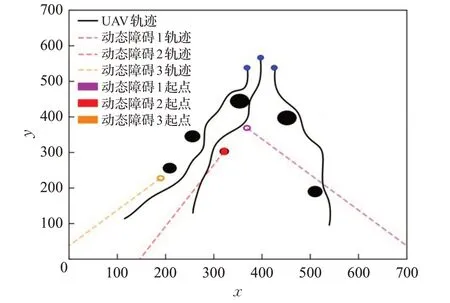
图10 CPSO算法规划航路Fig.10 CPSO algorithm for route planning
由表6可知,在3.1节环境下,采用RVO-DDPG算法对多UAV进行编队集结航路规划后,相比于DDPG算法和CPSO算法,航程代价减少了8.38%、3.12%,时间协同代价减少了47.65%、12.01%,综合代价减少了23.15%、4.08%,航路规划时间减少了13.89%、86.75%。由此分析可知,在相同条件下,RVO-DDPG算法在为多UAV集结规划出合理、安全航路的同时,也能够使航程代价、时间协同代价、综合代价大大减少,提高了多UAV在不确定复杂环境下执行任务的效率,保证了多UAV在不确定复杂环境下的安全。
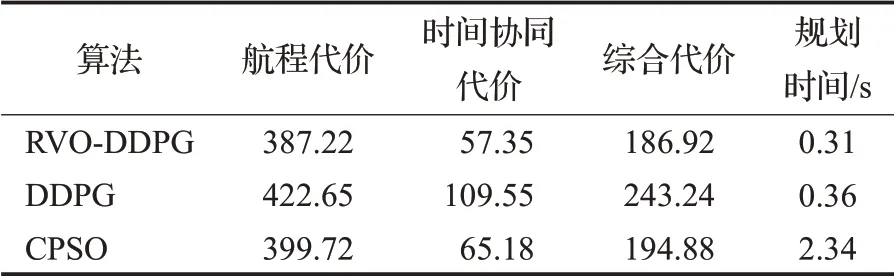
表6 三种算法的航路规划数据Table 6 Route planning data of three algorithms
如图11为3.1节环境中改进DDPG算法前后奖励值对比图,奖励值越高,表示UAV能够在当前状态下选择更优的航向角。从图中可以看出,改进奖励函数后DDPG算法奖励收敛值明显提升,这是因为将航路综合代价设计为奖励函数后,算法规划的航路更优。同时,改进动作选择策略后的DDPG算法奖励值收敛速度明显优于传统DDPG算法,说明引入速度障碍法、互惠速度障碍法后的DDPG算法避障效率更高。

图11 改进DDPG算法奖励值对比Fig.11 Comparison of improved DDPG algorithm reward values
如表7为改进DDPG算法奖励值收敛时的迭代次数。由表7可知,改进动作选择策略的DDPG算法和RVO-DDPG算法在第3 654、4 352次迭代时开始收敛,相比于传统DDPG算法在第6 528次开始收敛的迭代次数分别提高了44.03%、33.33%,说明改进动作选择策略能够提高算法的训练效率,加快网络的学习效率。同时,由收敛时的奖励均值可以看出,改进奖励函数的DDPG算法和RVO-DDPG算法的奖励均值远远大于传统DDPG算法,说明RVO-DDPG算法能够使多UAV避免陷入局部最优航路,更能满足不确定复杂环境下多UAV集结航路规划的任务需求。
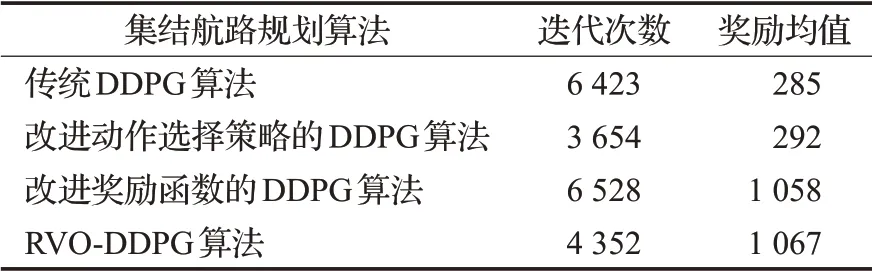
表7 改进DDPG算法收敛迭代次数Table 7 Improved DDPG algorithm convergence iteration times
5 结论
针对传统智能算法难以处理不确定复杂环境下多UAV集结航路规划的问题,本文将传统DDPG算法与互惠速度障碍法相结合设计了RVO-DDPG算法。为提高传统DDPG算法的收敛速度,采用互惠速度障碍法调整UAV航向,使多UAV成功躲避不确定复杂环境中的动态、静态障碍物。设计了一种基于综合代价约束的奖励函数,将多UAV航路规划中的多约束问题转化为奖励函数设计问题,使算法规划出的集结航路综合代价最小。最后通过仿真实验验证了该算法的实用性和有效性,并与传统DDPG算法和CPSO算法进行对比用于验证RVO-DDPG算法的先进性,实验结果表明RVODDPG算法能够快速为各UAV在不确定环境中规划出安全有效的航路。
猜你喜欢
新世纪智能(高一语文)(2021年3期)2021-07-16 08:30:16
装备制造技术(2020年9期)2021-01-26 00:14:34
民用飞机设计与研究(2019年4期)2019-05-21 07:21:26
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
电子制作(2017年24期)2017-02-02 07:14:16
海军航空大学学报(2015年3期)2015-11-11 17:18:49
中学历史教学(2015年11期)2015-11-11 07:09:09
中学生(2015年12期)2015-03-01 03:43:53
中国民航大学学报(2015年3期)2015-03-01 01:57:13
