
非独立同分布数据下的去中心化联邦学习策略
2023-01-13 11:59谭荣杰洪智勇余文华曾志强
计算机工程与应用 2023年1期
谭荣杰,洪智勇,余文华,曾志强
五邑大学 智能制造学部,广东 江门 529020
目前人工智能的算法、算力处于快速发展中,数据量的缺失成为了人工智能进一步发展的瓶颈。在实际的情况中,数据分散在许多不同的组织下,出于对数据隐私的保护,组织之间无法共享所有数据来训练人工智能模型,联邦学习[1-2]应运而生。联邦学习让大量边缘设备能在本地上使用私有数据计算自己的模型,并通过聚合算法在云端把边缘设备上传的模型进行聚合得到一个共享模型。联邦学习不需要边缘设备之间的数据共享,这在某种程度上保护了数据的隐私和安全,因此逐渐成为机器学习中的热门研究领域。但传统联邦学习仍存在挑战:中心服务器在聚合边缘设备的本地模型时发挥着重要作用,在中心服务器受到安全挑战的情况下,不稳定的中心服务器会导致系统崩溃。区块链有去中心化,不可篡改等安全特性,能解决联邦学习里中心服务器的安全问题,因此其与联邦学习的结合研究引起了广泛关注。
区块链是一种去中心化的分布式数据库。与传统中心化系统不同,区块链不需要任何中心服务器,由于“最长链法则”和“梅克尔树”结构的存在,它存储的数据是不可篡改的,这两个特性让它成为分布式环境中可靠且值得信赖的系统,也让很多研究工作把区块链作为联邦学习的底层基础,通过在区块链上层设计共识算法或者聚合算法来满足模型聚合的需求。Kim等[3]提出一种基于区块链的联邦学习框架,在本地训练过后将本地模型上传至区块链网络,在经过矿工节点共识后在使用联邦平均(Fedavg)[1]进行聚合,并且可以根据设备的产出速率等参数为设备提供奖励。美国NEC实验室和佐治亚理工学院的研究者提出了基于区块链的自由联邦学习框架(BAFFLE)[4],他们在私有的以太坊框架上实现了一个实用的,生产级别的BAFFLE,并使用大型的深度神经网络展示BAFFLE的优点。在BAFFLE中可以评估每个用户对模型的贡献大小,进而决定用户的奖励。Zhou等[5]提出了一个基于区块链和5G网络的分布式机器学习安全框架,用5G网络的通讯速度解决了联邦学习的可用性问题,同时引入了区块链分片技术和设计了一套梯度异常检测策略。2021年,Li等[6]提出了基于区块链的联邦学习框架BFLC。详细制定了模型的存储方式,重新设计了新的训练过程和新的共识机制。在论文中探讨了BFLC的社区节点管理,防御恶意节点攻击和优化存储问题,通过在联邦学习数据集上的实验证明了BFLC的有效,并通过模拟恶意攻击验证了BFLC的安全性。2021年,Cao等[7]提出了DAG-FL架构,使用DAG区块链架构改进去中心化联邦学习的模型验证机制,有效监测异常节点,并通过实验证明其有效性。
目前已有的基于区块链的联邦学习框架工作研究主要集中在降低系统通信运算成本,改善资源分配,加强数据的安全性和可靠性,加强联邦学习的鲁棒性等方面。但随着框架的大规模使用,协同数以万计的设备及其私有数据集进行模型训练,还会面临由于场景和用户不同带来的数据非独立同分布问题。联邦学习可以分为横向联邦学习、纵向联邦学习和联邦迁移学习三类,其中横向联邦学习特点为每个客户端的数据特征相同,用户不同,理解为对样本数量的扩充;纵向联邦和联邦迁移学习特点为用户相同,但是数据特征不同,是对样本数据特征的扩充。联邦学习的数据非独立同分布问题研究集中于横向联邦学习分类中[8]。同分布代表着数据趋势平稳,分布没有波动,所有数据的分布都遵循同一个概率。独立性则代表每个样本视作独立的,相互之间无任何联系。对于传统的分布式机器学习来说,每个子数据集都是由总数据集划分出来的,这些子数据集能够代表着整体的分布。但对联邦学习而言,每个设备上的私有数据都并非随机收集或生成的,这导致了其有一定的关联性,因此不具有独立性。而每个设备的私有数据本地数据量不同,因此也违背了同分布性。这种由非独立同分布数据引起的不平衡数据分布会给模型训练带来偏差,并可能导致联邦学习的性能下降。
目前横向联邦学习的非独立同分布数据的问题在进行中心化联邦学习框架上有许多解决方法。Zhao等[8]提出一种策略,创建一个在所有私有数据集之间共享的数据子集来缩小每个模型之间的差距,从而提高非独立同分布数据的训练精度。Yoshida等[9]提出了新的联邦学习机制Hybrid-FL,该机制设计了一种启发式算法,让中心服务器从隐私敏感度低的设备中收集数据来构造独立同分布数据,并利用构造的数据训练模型并聚合到全局模型。Wang等[10]提出了一种模型选择的聚合算法,通过识别并排除对本地更新有偏差的模型来提高聚合后的全局模型精度。但这些方法和算法都是基于中心化的联邦学习框架,利用中心服务器共享一部分数据或者挑选模型进行聚合,去中心化联邦学习框架对非独立同分布数据的精度下降问题依然存在。
因此,针对去中心化联邦学习框架的非独立同分布数据问题,本文受文献[8]启发,提出了一种模型相似度的计算方法,并根据该模型相似度设计新的去中心化联邦学习策略。该策略将一个用少量独立同分布数据训练的模型放于智能合约中,并通过智能合约给每个上传的边缘模型计算模型相似度,本地设备可以根据模型相似度的排序挑选区块链内的模型使用联邦平均算法进行聚合。利用智能合约的测试集,由全局模型不断更新替换用于比较的模型。实验表明,与文献[8]的原模型相似度相比,本文改进后的模型相似度能达到更好的效果,并通过对比实验验证,本文设计的去中心化联邦学习策略在横向联邦学习的非独立同分布数据环境下性能优于传统去中心化联邦学习策略。
1 去中心化联邦学习的框架设计与原策略介绍
1.1 一种去中心化联邦学习的框架设计
本节介绍一种去中心化联邦学习框架。如图1所示,该框架主要由边缘学习层、后端接口层、智能合约层和存储层组成。
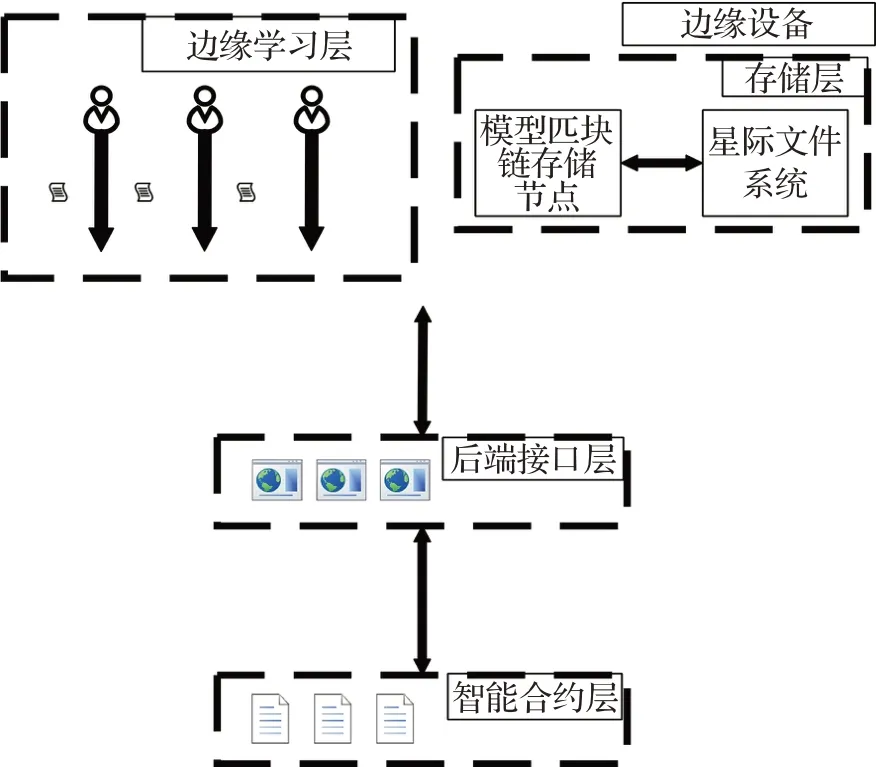
图1 框架架构图Fig.1 Frame architecture diagram
1.1.1 边缘学习层
边缘设备用自己的处理器和私有数据训练模型。每个边缘设备会自行训练本地模型和聚合全局模型。
1.1.2 后端接口层
后端接口层处理边缘设备传输上来的模型数据和http数据并转发至智能合约层。
1.1.3 智能合约层
智能合约层部署超级账本的智能合约节点,超级账本是由Liunx基金会托管和管理的区块链开源框架。可以在智能合约层对联邦学习进行特殊操作,如检验精度,发放模型等。
1.1.4 存储层
存储层部署了超级账本的存储节点和星际文件系统。超级账本框架会为一条联盟链中的成员组建一个子网络,子网络的成员才能看到该链的交易数据和智能合约,以此来保证隐私性。而星际文件系统是一个集成了P2P网络技术、DHT分布式Hash、BitTorrent传输技术、自认证文件系统SFS和Git版本控制系统的文件系统,其分片和哈希存储的特性非常适合用于联邦学习这种模型参数多,读写多的场景。
1.2 普通去中心化联邦学习策略的流程
大部分去中心化联邦学习研究都是基于文献[3]提出的BlockFL架构进行改良,用于横向联邦学习。应用到上述框架中,BlockFL架构的去中心化联邦学习策略步骤如下:
步骤1权威机构设定联邦学习目前的轮数e,初始模型M0。由智能合约发放初始模型M0给边缘节点,边缘节点用自己的私有数据训练初始模型M0得到本地模型Mn
步骤2每个边缘节点上传Mn至智能合约处,智能合约根据自己的测试集对模型精确度进行工作量证明,并发放上链许可。若一轮联邦学习时间到或收集够足够的边缘模型,智能合约给边缘节点发出聚合信号。
步骤3每个边缘节点从区块链处读出一轮联邦学习中的边缘模型队列,对边缘模型队列使用联邦平均算法进行聚合,得到一个全局模型Mg,并存入区块链。
步骤4智能合约发送下一轮学习开始的信号至边缘节点,边缘节点用自己聚合好的全局模型开始下一轮的去中心化联邦学习。
与原论文相比,以上策略将矿工验证改为了智能合约验证,并使用raft[11]算法进行区块链节点的共识。但依然保留了其去中心化的思想和机制。
2 针对非独立同分布数据的去中心化联邦学习策略
前文基于一种框架设计阐述了普通去中心化联邦学习策略的流程,本章介绍一种基于同样框架的去中心化联邦学习的改进策略用于横向联邦学习。
通常来说,如果一个设备的私有数据都具备独立同分布特性,则训练出来深度学习模型参数应该都有一定的相似性,又如果一个设备的模型是由非独立同分布特性的数据训练出来的,其模型与标准模型的相似度一定小于独立同分布数据训练出来的模型。文献[8]中为了研究非独立同分布数据对联邦平均聚合算法的影响,提出并推导了模型的权值差异:
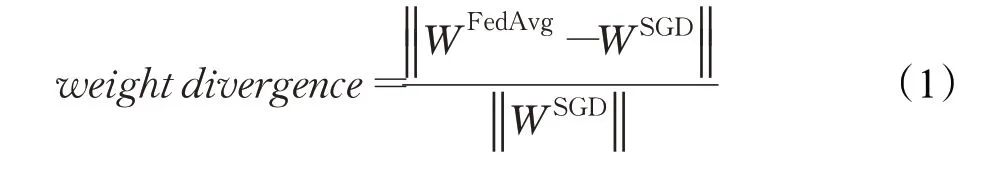
其中,WFedAvg为使用联邦平均聚合算法的联邦学习后得到的全局模型里一层的参数,WSGD为使用随机梯度下降,即传统深度学习后得到的模型里一层的参数。
受此启发,本文在公式(1)的基础上,经过实验比较,放大每一层之间的参数差,并把每一层的权值差异进行求和,作为两个模型的模型相似度,并以此作为筛选模型的指标:

其中,n为模型的层数,Pak为模型a于第k层的参数,Pbk为模型b于第k层的参数。
基于该模型相似度,提出的策略步骤如下:
步骤1权威机构设定联邦学习目前的轮数e,初始模型M0,并用收集或购买来的接近独立同分步数据训练一个比较模型Ms,得到精确度acc0。由智能合约发放初始模型M0给边缘节点,边缘节点用自己的私有数据训练初始模型M0得到本地模型Mn。
步骤2每个边缘节点上传Mn至智能合约处,智能合约接收Mn后,给每个模型计算其与比较模型的模型相似度:,发送模型相似度至边缘节点,边缘节点将Mn和SMnM0存入区块链。若一轮联邦学习时间到或收集够足够的边缘模型,智能合约给边缘节点发出聚合信号。
步骤3每个边缘节点从区块链处读出一轮联邦学习中的边缘模型队列,对本轮边缘模型的模型相似度进行升序排序,取前η个模型相似度对应的模型组成新的子集mi。对新边缘模型队列mi使用联邦平均算法进行聚合,得到一个全局模型Mg,并存入区块链,且至智能合约。
步骤4智能合约接受边缘节点发来的全局模型后,用自己的测试集得出全局模型的精确度accn,如果accn>acc0,取Mg为比较模型,acc0=accn。
步骤5智能合约发送全局模型的准确率排序和下一轮学习开始的信号至边缘节点,每个边缘节点用准确率最高的全局模型开始下一轮的去中心化联邦学习。
以上步骤如图2所示。

图2 改进策略流程图Fig.2 Improvement strategy flowchart
3 实验及结果分析
本章将对模型相似度的改进进行实验分析,并对非独立同分布下的去中心化联邦学习策略的性能提升进行对比实验。下面从实验环境设置、实验设置、实验评估指标、实验参数、对比实验五个方面展开论述。
3.1 实验环境
实验环境:GPU服务器环境有1个QuadroP5000GPU(16 GRAM),装载centos7系统环境,机器学习功能使用基于python3.7的pytorch框架进行编程。后端编程使用gin框架,并使用golang语言编写超级账本的智能合约。超级账本方面,实验使用hyperledgefabric1.4版本,并把peer节点分为了3个组织,每个组织各有2个peer节点,且每个组织选一个节点部署智能合约,并启用5个order节点执行raft共识服务。联邦学习中每次使用GPU单机训练一个模型并上传到其中一个智能合约节点。
3.2 实验设置
本文总共进行了5个训练任务用于评价该策略的性能。第一个训练任务是用一个简单的CNN[12]模型对FashionMNIST[13]图片数据集进行分类,CNN模型有两个5×5的卷积层,第一个输出通道为20,第二个输出通道为50,两个卷积层都由ReLU函数激活,每个之间使用2×2的最大池化层,再使用linear层和softmax层输出。FashionMNIST具有60 000个样本的训练集和10 000个样本的训练集,里面包括T恤、裤子、外套等10个分类的图片。独立同分布数据组的设置方法为训练集数据平均分给每个客户端,即每个客户端随机分到1 200条数据。非独立同分布数据组的设置方法为,首先,实验对数据标签进行排序,然后把排序后的训练集分为1 200组,每一组有50个图片,然后设置50个边缘节点,每个边缘节点先分到4个组的数据,然后剩余的数据随机分给边缘节点。通过使用这种分配方案,每个节点都被分配一个本地数据集,其中包括两个大的分类和其他一些零碎的分类,而且每个节点的数据数量也不一样。本任务设置每个边缘节点用0.005的学习率训练10轮,比较模型由被分配到最多数据的客户端训练10轮得出。
第二个训练任务是用Alexnet[14]模型对cifar10数据集进行图片分类。cifar10数据集有50 000个训练样本和10 000个测试样本与FashionMNIST数据集的区别在于,cifar10是3通道的彩色图片,而且是现实世界中的真实物体,噪声大,物体比例和特征都不同,这让识别更加复杂困难。同FashionMNIST的实验设置相似,独立同分布数据组为平均分给50个客户端,即每个客户端随机分到1 000条数据。非独立同分布数据组的设置先对cifar10的标签进行排序,然后把排序后的训练集分为1 000组,每一组有50个图片。设置50个边缘节点,每个节点分到两组数据,剩下的组随机分配。本任务设置边缘节点用0.000 1的学习率训练10轮,比较模型由被分配到最多数据的客户端训练10轮得出。
第三个训练任务是用TextRNN[15]模型对THUnews[16]数据集进行新闻分类。THUnews数据集有74万篇新闻文档,并划分出了财经、彩票、房产等14类类别。本任务随机抽取50 000条数据作为训练集的和,抽取了10 000条数据作为测试集,并设置了50个边缘节点。在独立同分布数据组设置上,把训练集数据平均分给50个客户端。在划分非独立同分布数据方面,本任务先对10 000条数据的标签进行排序,并平均分配到边缘节点中,剩下的数据进行随机分配。本任务选择使用TextRNN模型,边缘节点以0.001的学习率训练5轮,比较模型由被分配到最多数据的客户端训练5轮得出。
第四个训练任务是用Resnet18[17]模型对SVHN[18]数据集进行图片分类。SVHN数据集包含20多万张由谷歌街景车拍摄的房屋门牌号的RGB图像。每幅图像中均包含有1到3位0~9的数字。本任务设置了50个边缘节点。在独立同分布数据组设置上,把73 257张训练集数据几乎平均分给50个客户端,即每个客户端分到1 465或1 466张图片。在划分非独立同分布数据方面,实验对数据标签进行排序,然后把排序后的训练集分为1 465组,每一组有50个图片,然后设置50个边缘节点,每个边缘节点选4组数据,剩下的组随机分配到不同节点。训练参数方面,本任务设置每个边缘节点以0.1的学习率用残差网络Resnet18训练1轮,比较模型由被分配到最多数据的客户端用同样学习率训练1轮得出。
第五个训练任务是用LSTM[19]模型对sentiment140[20]数据集进行情感分类。sentiment140包含了1 600 000条从推特爬取的推文,并有正面、中立、负面3种标签。本次任务随机挑选30 000条作为训练集,10 000条作为测试集,并设置50个边缘节点。在独立同分布数据组设置中,把训练集数据平均分给50个客户端,即每个客户端有600条数据。在划分非独立同分布数据方面,本任务先对10 000条数据的标签进行排序,并平均分配到边缘节点中,剩下的数据进行随机分配。本任务设置每个边缘节点使用传统的LSTM模型,以0.001的学习率训练一轮,比较模型由被分配到最多数据的客户端用同样学习率训练一轮得出。
3.3 评价指标
模型相似度的性能评价指标为每轮联邦学习之中边缘模型与标准模型之间的模型相似度的方差,求方差是为了观测每个边缘模型与标准模型之间的模型相似度的离散程度,从而判断该模型相似度计算方法的性能。公式如下:

其中si为一轮中每个边缘模型与标准模型的相似度,sˉ为该轮中边缘模型与标准模型的相似度的平均数,n为该轮中参与联邦学习任务的设备数。
本文采用准确率作为该去中心化联邦学习策略在五个深度学习任务的性能指标。本文用acc表示,计算如下:

其中TP为模型正确标注的数据,FP为模型错误标注的数据。
3.4 模型相似度性能测试
在实验中,分别测试原模型相似度与改造后的模型相似度的性能,原模型相似度计算方法与改造模型相似度计算方法如下:
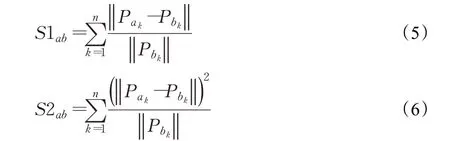
首先测试原模型相似度和改造模型相似度在非独立同分布数据组下的方差,然后测试改造模型相似度在独立同分布数据组下的方差。其中模型a为边缘模型,模型b为标准模型,标准模型由每个任务的全部训练集数据,并采用与边缘设备相同的训练参数得出。测试中5个任务中边缘设备训练参数相同,结果如图3~7所示。然后使用两个不同的模型相似度计算方法应用于本文去中心化联邦学习策略中,在数据集分配,训练模型相同,训练参数相同的情况下,5个任务设置50个节点使用不同的模型相似度计算方法的策略在非独立同分布数据集上进行50轮联邦学习,设置模型聚合数量为η=25,展示每轮区块链中存在的准确率最高的全局模型在测试集上的准确率变化,结果如图8~12所示。
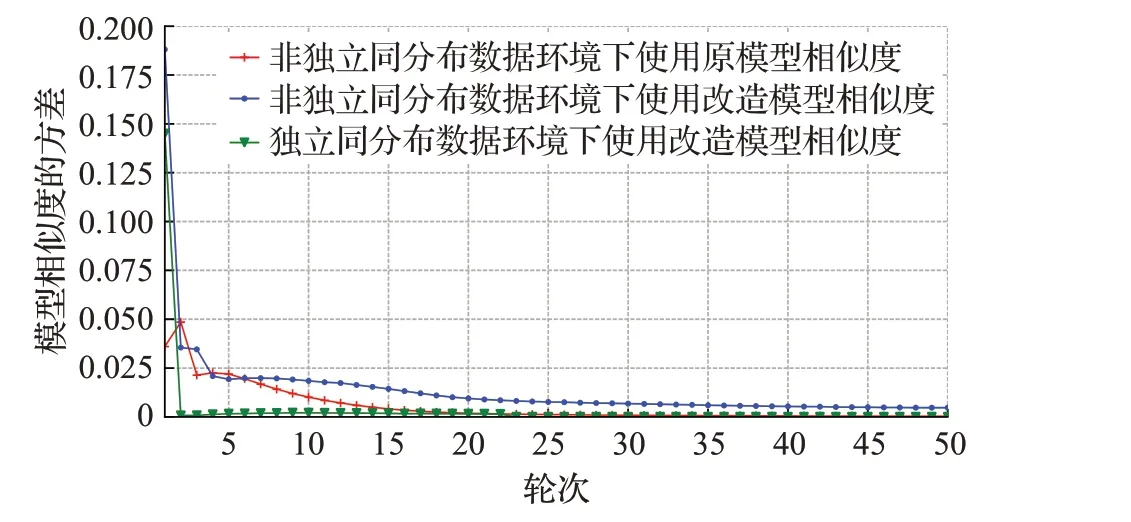
图3 CNN模型相似度方差Fig.3 CNN model similarity variance
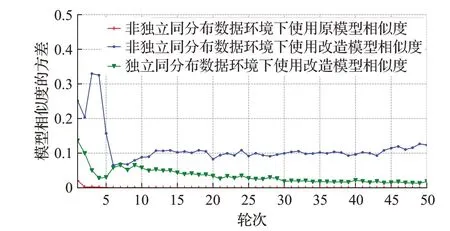
图4 Alexnet模型相似度方差Fig.4 Alexnet model similarity variance
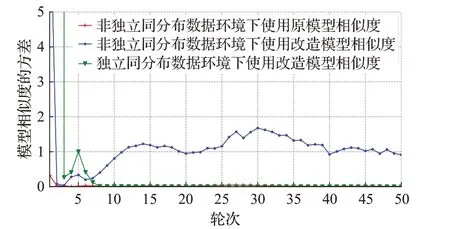
图5 TextRNN模型相似度方差Fig.5 TextRNN model similarity variance
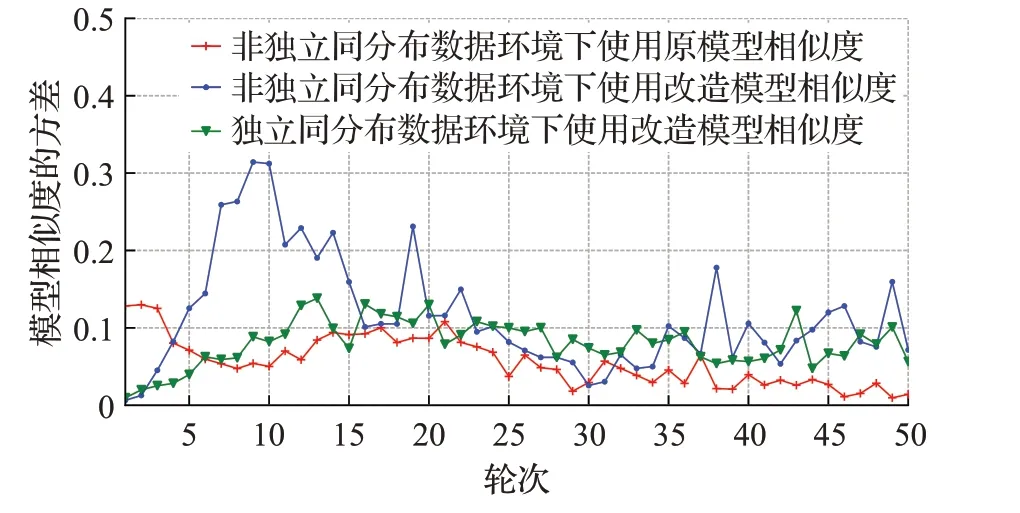
图7 LSTM模型相似度方差Fig.7 LSTM model similarity variance

图8 CNN模型训练准确率变化Fig.8 Changes in training accuracy of CNN model
观察图3~7,在同样的非独立同分布数据集上进行联邦学习,开始的时候由于每个边缘数据的不同,所以边缘模型差别大,对应模型相似度的方差也高。随着轮数的增加,经过几次模型聚合,边缘模型的差别越来越小,模型相似度的方差也趋于比较稳定。
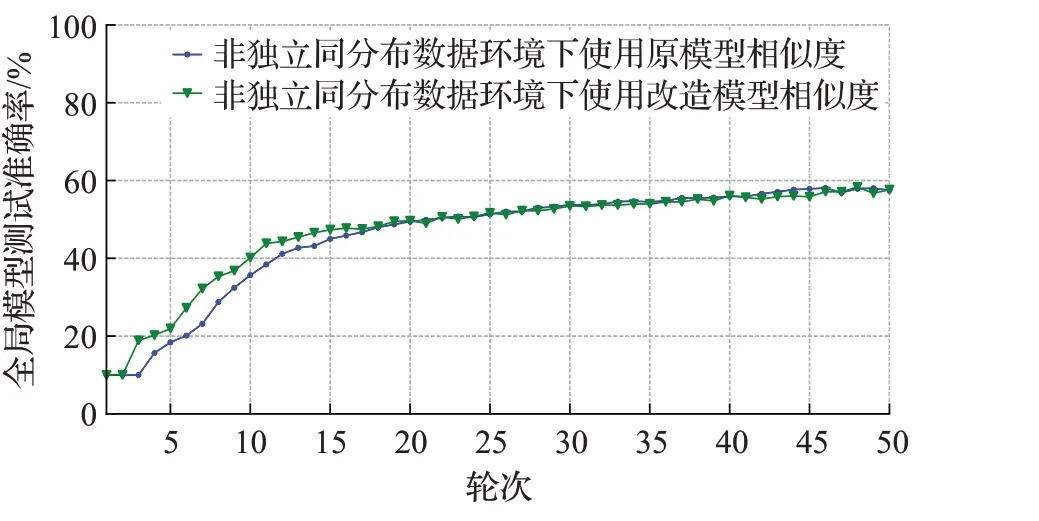
图9 Alexnet模型训练准确率变化Fig.9 Changes in training accuracy of Alexnet model
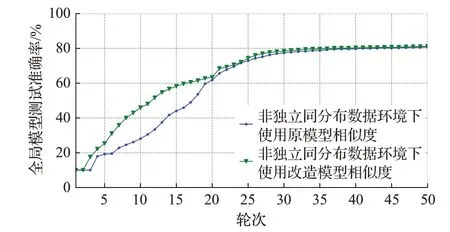
图10 TextRNN模型训练准确率变化Fig.10 Changes in training accuracy of TextRNN model
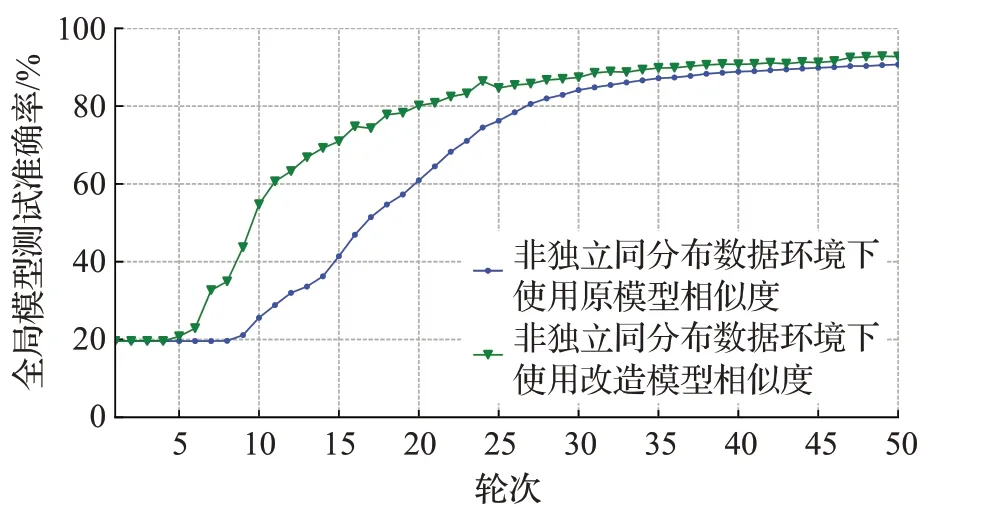
图11 Resnet18模型训练准确率变化Fig.11 Changes in training accuracy of Resnet18 model

图12 LSTM模型训练准确率变化Fig.12 Changes in training accuracy of LSTM model
在原模型相似度和改造模型相似度的对比实验中,CNN任务改造模型相似度的方差比原模型相似度的方差平均高0.008 4,Alexnet任务改造模型相似度的方差比原模型相似度的方差平均高0.111 5,TextRNN任务改造模型相似度的方差比原模型相似度的方差平均高1.139 9,Resnet18任务改造模型相似度的方差比原模型相似度的方差平均高7 968,LSTM任务改造模型相似度的方差比原模型相似度的方差平均高0.053 4。在不同任务中,改造模型相似度的方差都比原模型相似度的方差高,即改造模型相似度的分离度比原模型相似度所得分离度大,这种更大的分离度更有利于策略中对模型相似度进行比较。
观察图6~8的准确率变化趋势,虽然最后结果的相差并不大,但本文策略使用改造模型相似度后,节点能挑选出更多接近于独立同分布数据训练的边缘模型进行聚合,导致训练准确率的收敛速度显著快于使用原模型相似度的策略。因此可以认为改造的模型相似度计算方法效果更佳。

图6 Resnet18模型相似度方差Fig.6 Resnet18 model similarity variance
本文也测试了在非独立同分布数据集与独立同分布数据集下改造模型相似度的性能,CNN任务非独立同分布数据集下改造模型相似度方差比在独立同分布数据集下使用改造模型相似度的方差平均高0.010 6,Alexnet任务改造模型相似度的方差比原模型相似度的方差平均高0.078 7,TextRNN任务改造模型相似度的方差比原模型相似度的方差平均高1.164 9,Resnet18任务改造模型相似度的方差比原模型相似度的方差平均高7 967,LSTM任务改造模型相似度的方差比原模型相似度的方差平均高0.017 8。在不同任务中,非独立同分布数据集下改造模型相似度方差都比在独立同分布数据集下使用改造模型相似度的方差高,即改造模型相似度在非独立同分布数据集下分离度更大,这也符合非独立同分布数据集下每个边缘模型差异度大的现象,因此可以选用公式(2)作为本策略的模型相似度计算方法。
3.5 去中心化联邦学习策略改进实验
本节使用文献[3]中BlockFl的原始去中心化联邦学习框架的策略与本文的改进策略在不同任务,不同设置模型聚合数下的性能对比。在数据集分配,训练模型相同,训练参数相同的情况下,展示5个任务设置50个节点使用原始策略和使用本文的策略在非独立同分布数据集,独立同分布数据集上进行50轮联邦学习中每轮区块链中存在的准确率最高的全局模型在测试集上的准确率。同时为了明确选择模型数量与该策略精度的关系,分别进行设置模型聚合数量为η=40,η=35,η=30,η=25和η=20的实验,结果如图13~17及表1所示。

表1 各任务精度比较Table 1 Accuracy comparison for each task 单位:%
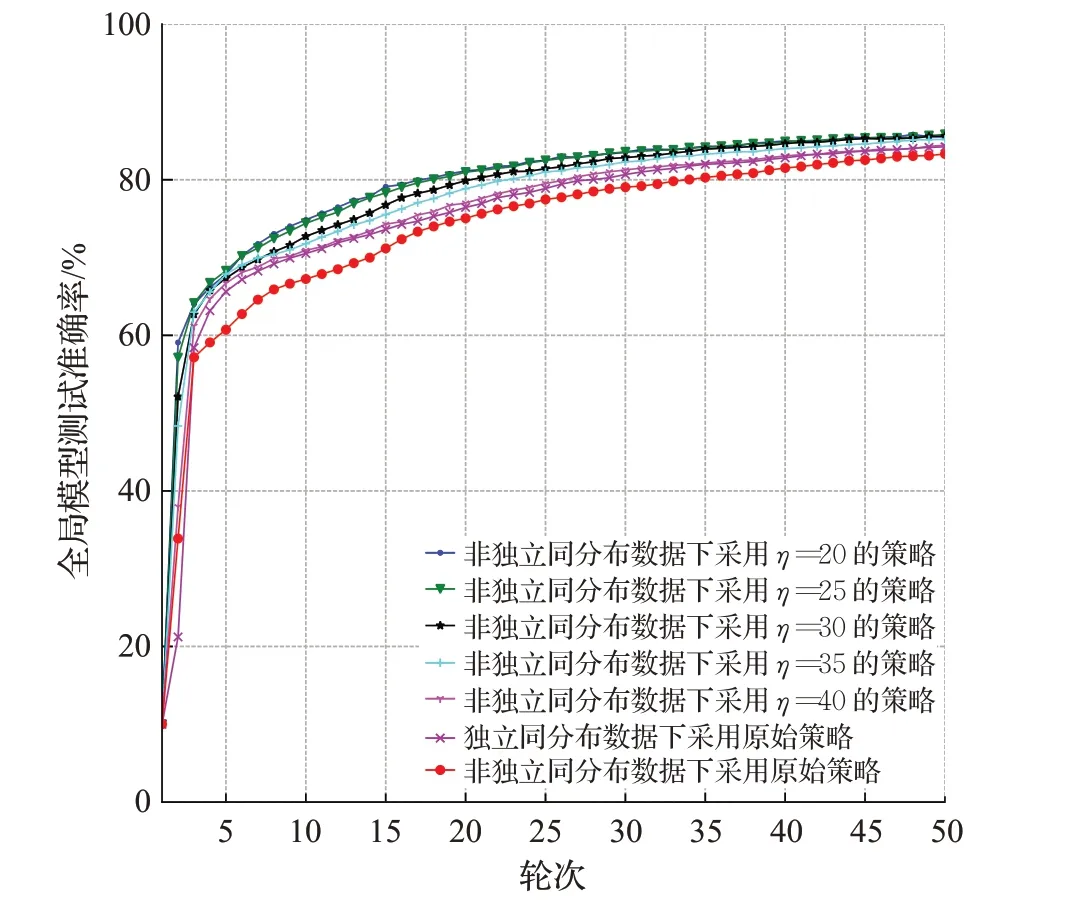
图13 CNN模型训练准确率Fig.13 Training accuracy of CNN model
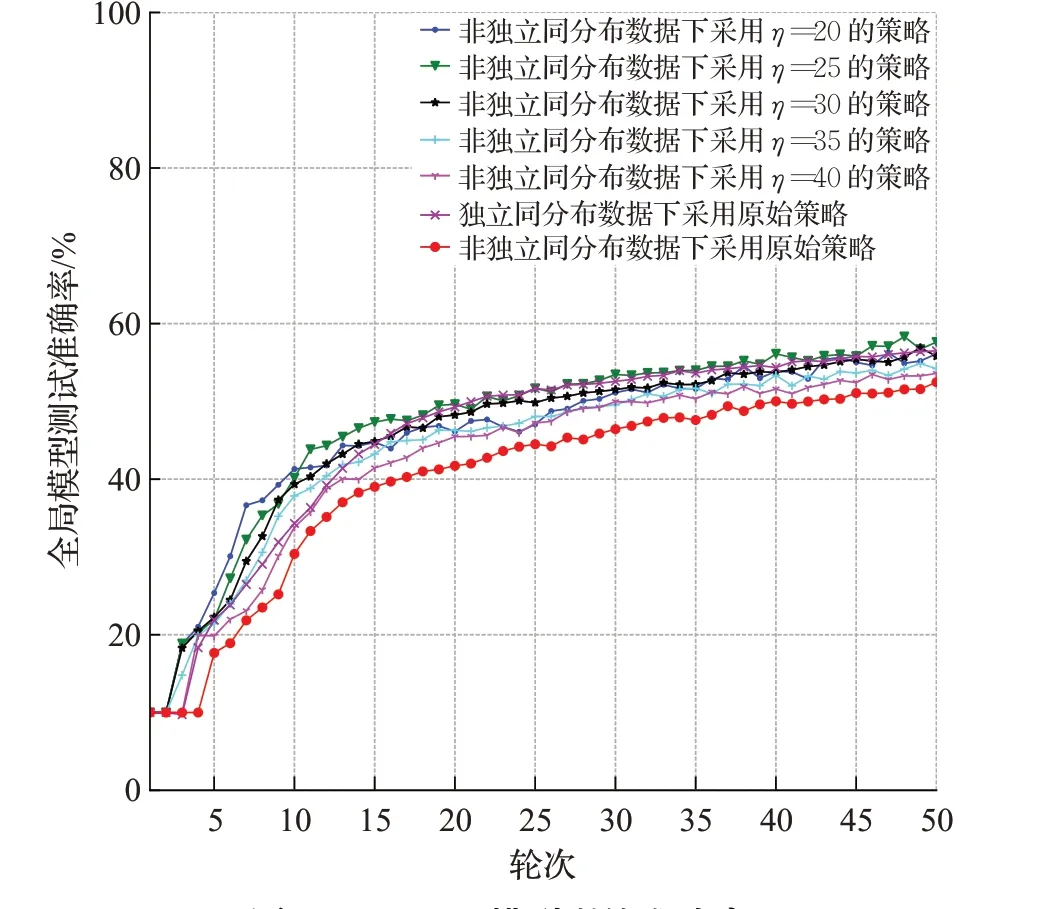
图14 Alexnet模型训练准确率Fig.14 Training accuracy of alexnet model
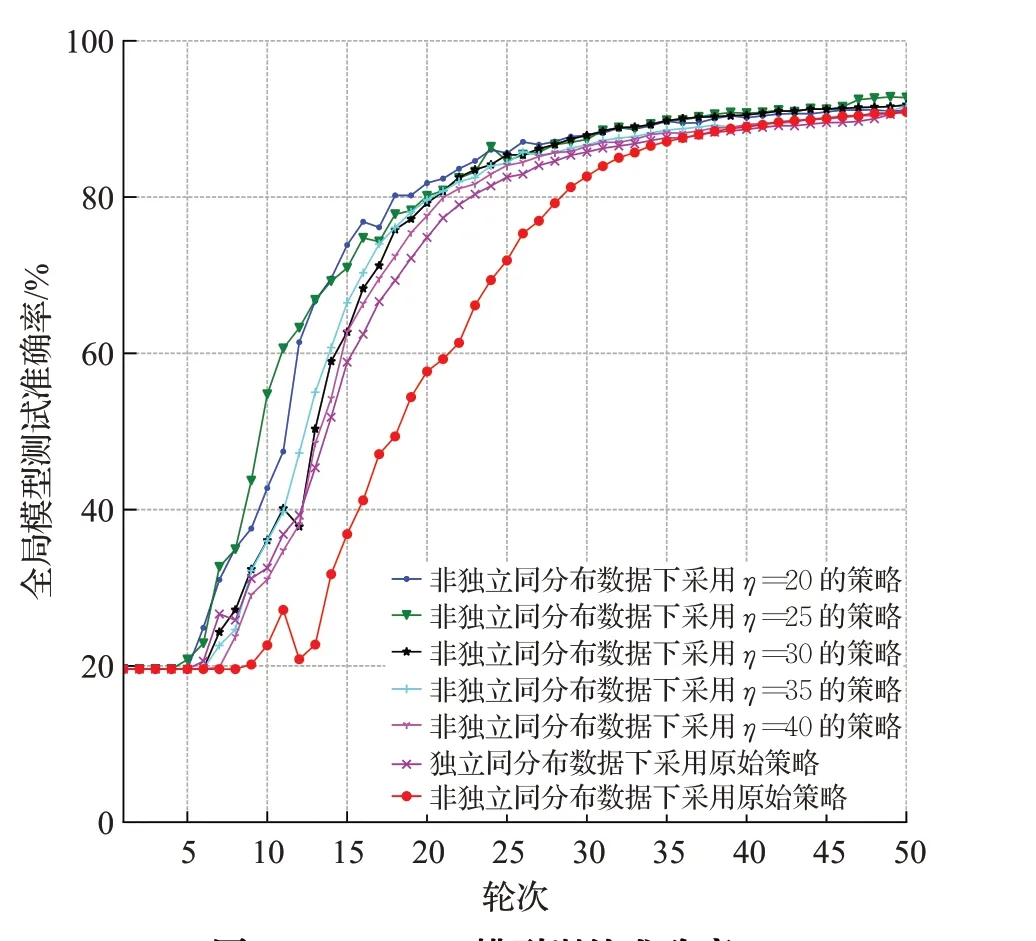
图16 Resnet18模型训练准确率Fig.16 Training accuracy of Resnet18 model
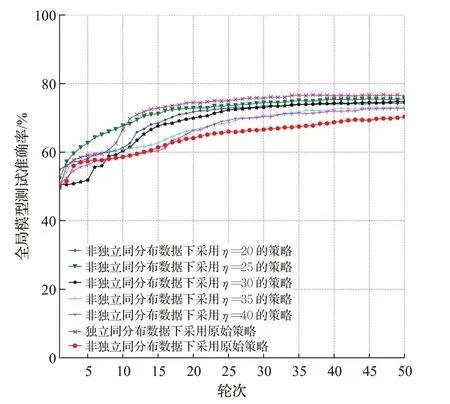
图17 LSTM模型训练准确率Fig.17 Training accuracy of LSTM model
实验结果表明,采用本文提出这种去中心化联邦学习策略比起原始策略在5个不同领域任务的非独立同分布数据集下的去中心化联邦学习精度都有不同程度的提高,在使用简单CNN模型训练FashionMNIST的任务中准确率最高提升了2.51个百分点,在使用Alexnet模型训练cifar10任务中准确率最高提升了5.16个百分点,在使用TextRNN模型训练THUnews任务中准确率最高提升17.58个百分点,使用Resnet18模型训练SVHN任务中准确率最高提升2.46个百分点,使用LSTM模型训练sentiment140任务中准确率最高提升5.23个百分点。证明该策略不同的任务下都能通过改造的模型相似度挑选数据非独立同分布程度更高的边缘模型进行聚合,不让独立同分布数据训练的边缘模型聚合时污染全局模型,从而提高去中心化联邦学习性能。值得注意的是,并非选择的边缘设备数量越少越好,如实验所示,η太小会让联邦学习任务的数据不足,从而也会使全局模型收敛的速度降低。这启示了该策略的劣势为某些极端情况下,可能存在训练数据不足从而影响联邦学习性能。因此在使用该策略时需要选择合适的η值。
4 结束语
本文提出了一种非独立同分布数据下的去中心化联邦学习策略,该策略可以使去中心化联邦学习克服横向联邦学习中非独立同分布数据的挑战,尽量逼近单机深度学习的精度。其能在不处理训练数据的情况下,筛选出近似独立同分布的联邦学习模型集进行聚合,并以此提高联邦设备的数据质量。基本思想是在智能合约处使用改进的模型相似度比较模型训练所用数据的非独立同分布程度。实验表明,使用该策略的去中心化联邦学习性能在不同任务上都能得到了明显提高。下一步研究方向为智能合约动态选择策略中的参数问题,并加入基于模型相似度的激励机制等内容,来加强区块链在联邦学习中的作用。
猜你喜欢
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
家庭影院技术(2020年10期)2020-12-14
家庭影院技术(2019年7期)2019-08-27
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
初中生世界·九年级(2017年10期)2017-11-08
通信产业报(2016年44期)2017-03-13
俄罗斯问题研究(2013年1期)2013-03-11
中国宪法年刊(2012年0期)2012-03-25
雕塑(1999年2期)1999-06-28
