
基于多因素联合作用的产品评价分析模型
2023-01-12 12:32:22王雨潇战洪飞余军合郭剑锋
计算机集成制造系统 2022年12期
王雨潇,战洪飞+,余军合,王 瑞,郭剑锋
(1.宁波大学 机械工程与力学学院,浙江 宁波 315211; 2.中国科学院 科技战略咨询研究院,北京 100190)
0 引言
分析用户对产品评价的准确性在很大程度上影响企业的决策质量,在产品生命周期缩短、用户使用体验多样化的市场环境下,如何为企业提供准确的产品评价信息至关重要。传统的产品评价通常以问卷调查[1]、在线评论[2-3]等方式获取用户对产品属性的感受,以此获得产品的各方面表现。近年来,随着电子商务的快速发展,用户的评价方式由产品功能评价逐渐向使用体验评价的方面转移[4]。为了更好地反映产品在使用体验上的表现,研究人员开始专注于分析影响用户体验的因素,如林闯等[5]提出基于隐马尔可夫的用户体验质量模型,用于更合理地描述用户体验的过程;SONG等[6]基于在线评论,收集并归纳了影响用户体验的因素,并与产品属性进行匹配,开发了评估框架,用于有效评估产品的使用体验;SETCHI等[7]利用图像模式来表达用户与产品交互时的情感,以系统的方式评估用户体验的影响因素,帮助企业改善产品设计实践。但是,由于使用体验的影响因素由产品属性产生,而属性间存在关联性,使得影响因素间具有边界模糊性[8],这一原因导致了分析结果的准确度下降。为了提高准确性,有学者通过引入专家或用户的意见对指标权重进行修正[9-10],但仍没有解决属性间关联关系问题,因此,更多的研究人员开始考虑多因素间的关联性。传统的关联关系分析通常直接使用专家赋值[11-12]的方法,由于过于依赖专家经验,主观性过强,有学者结合其他方法进行分析,如耿秀丽等[13]基于专家组的打分结果,构建复杂网络来获取多个因素间的关联关系。为了以更加客观的方式进行分析,也有学者通过实验等方式获得关联关系,如EENDEBAK等[14]通过实验分析,利用正交阵列评估两因素相互作用关系,为设计提供支持;也有学者基于历史数据,通过N-K模型对航空运输系统安全脆弱性的多因素进行耦合分析[15]。但这些方法的适用范围较窄,无法广泛应用于其他产品,且没有结合用户观点进行深入研究,而产品评论需要充分反映用户态度,因此无法满足产品评价分析的需要。
本文在前人研究的基础上,结合电子商务时代的特点,以在线评论为数据源,在分析用户对各指标的重视程度的基础上,结合对指标间关联关系的思考,综合两方面因素构建出改进的相互作用关系矩阵,解决评价指标间存在的模糊性问题,以此得到更加准确的评价结果。
1 研究思路
本文提出的产品评价分析模型是以B2C网站上的在线评论作为数据源,由于评论数据是用户对产品使用感受最直接的表达形式,以评论数据中的产品属性词作为评价指标能够充分反映用户的观点。在以往的研究中,评价指标重要度的确定仅考虑单一因素的影响,容易造成结果偏差。为了进行准确量化,本文结合用户的重视程度与指标间的关联程度,构建改进的相互作用关系矩阵,通过综合考虑两方面因素来提高分析结果的准确性。最后通过分析评论数据中包含的用户情感态度,确定各属性表现,计算出产品最终的评价得分,整体研究思路如图1所示。
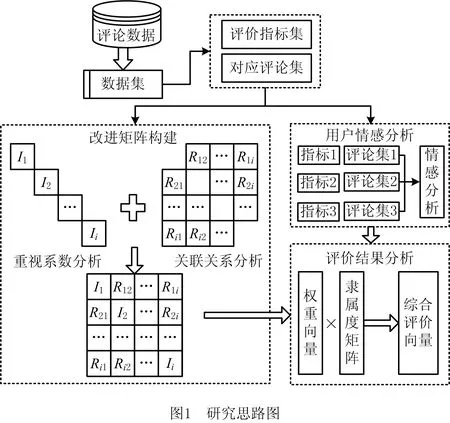
由于在线评论中包含了大量的无效评论,为了保证后续分析结果的准确,首先需要对这些噪音数据进行清理。噪音数据包括重复、字数过少和无效评论,其中重复评论指同一个用户连续进行多次重复且相同的评论,这些评论会影响数据集中的情感比例,对分析结果造成偏差;对于字数过少的敷衍评价文本和网站自动生成的如“此用户未填写评价内容”的无效评论缺少有效信息,无法用于分析,也需要进行删除,以此获得初步预处理完的文本数据形成数据集。
本文以数据集中用户提到的属性词作为评价指标,为了准确识别这些词,采用命名实体识别的方法从数据集中进行抽取,将得到的所有属性词经过词频统计和语义相似度计算进行分类,最终确定评价指标。本文提出的方法既考虑用户对产品属性的重视程度,同时对评价指标间的关联关系进行分析。用户关注的产品属性词出现频率越高,表明用户对该属性的重视程度越高,因此可以以此来反映用户对各评价指标的重视程度。而属性间的关联关系虽然目前缺乏有效的手段直接测量,但是仍可以从评论数据中发现属性间的关联组合。从产品属性影响用户使用体验的角度进行思考,当属性间的关联性越强,对体验产生的影响越接近,在评论中同时出现的概率也就越高。基于这一现象,使得通过对评论数据进行分析,间接获得产品属性间潜在的关联关系具有可行性。
为了有效结合两方面因素的影响,基于两者分析的结果构建形成包含用户观点与属性关联性的综合矩阵,根据该矩阵来准确量化各评价指标最终的权重系数。最后对评论集中所包含的用户情感进行分析,结合评价指标权重计算出产品的综合评价向量,以该向量确定产品最终得分。
2 评价分析模型构建方法
本文提出的产品评价分析模型是从评论数据中挖掘用户情感,并分析属性间的关联关系,建立适应市场要求的产品评价体系,包括评价指标确定、改进矩阵构建和评价结果分析3个部分。
2.1 评价指标确定方法
以往的研究通常采用基于统计的方法和基于语义的方法抽取评论中的属性词,由于这些方法只能提取出特定词性的词语,使得抽取结果中包含了大量无效的词语。而BiLSTM(bi-directional long short term memory)结合条件随机场(Conditional Random Fields, CRF)的命名实体识别方法是一种专用于从文本中识别出特定类型词语的方法,如人名、地名等。该方法以BIO(begin, inner, other)的形式对训练集进行逐字标注,以B和I分别标注需要类型词的首字和非首字,以O标注其他不需要的词和标点。将标注完的训练集映射成词向量并作为BiLSTM的输入,通过神经网络的不断训练自动提取句子特征,最后以CRF层为预测的结果添加约束,保证预测的准确性。本文通过此方法抽取评论数据中包含的属性词,通过词频统计选取频次较高的几种属性词作为候选词,根据语义相似度合并同义词,确定最终的评价指标。该方法可以进一步过滤未包含属性词的评论文本,提升数据的准确度。
2.2 改进矩阵构建方法
在以往的相互作用关系矩阵中,对角线上的元素代表产品属性,每个属性所在的行和列上的其他元素,分别代表该属性对其他属性的影响与被影响关系。该方法的原理是,某一属性对于产品的重要程度,与该属性对其他属性的影响程度和被影响程度成正比关系。本文通过将用户的重视系数引入该矩阵的主对角线,形成包含用户观点与指标间关联关系的改进矩阵,结构如图2所示。
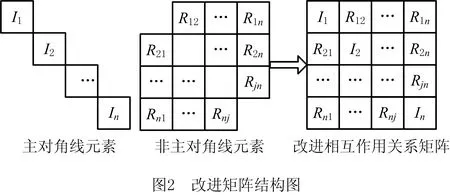
由此结构图可知,为了构建出该矩阵,需要分别对用户重视系数与指标关联程度进行分析。
2.2.1 用户重视系数确定
用户重视系数基于评论数据中的属性词频率,通过层次分析法(Analytic Hierarchy Process, AHP)计算获得,首先需要确定各指标所对应的属性词数量。本文利用FastText将所有提取的属性词按照评价指标进行分类。FastText是一种用于训练语义模型和分类任务的方法,其特点是快速,且在词汇表征上有着很好的效果。将所有评论数据作为语料训练语义模型,通过训练得到的模型对所有属性词与评价指标进行语义相似度计算,将属性词归于相似度最高的指标,形成属性词集Ck={ck1,ck2,…,ckm}。其中:Ck表示第k个评价指标的属性词集,ckm表示该指标所包含的第m个属性词。以属性词集中的元素数量作为依据,参照比例标度表,建立判断矩阵A,通过式(1)和式(2)计算最大特征值λmax与对应的特征向量W。
(1)
(2)
式(1)中:ϖij表示判断矩阵A归一化之后第i行的各元素;wi表示第i行元素之和。式(2)中:(AW)i和Wi表示向量的第i个分量。通过式(1)得到的向量W′={w1,w2,…,wi}归一化处理之后,即为所求的特征向量W。为了检验该特征向量是否能够表示为权重,需要检验一致性条件。根据式(3)和式(4)分别得到一致性指标和检验系数,当检验系数CR<0.1时,满足一致性条件,特征向量W中的元素可以作为评价指标的权重。
(3)
(4)
式(4)中RI表示随机一致性指标,可通过标准取值表获得。
2.2.2 属性间关联关系分析
由于目前仍未有客观有效的普适性方法度量产品属性间的关联程度,以往的属性间影响程度通常以经验法和专家半定量取值的方法获取[16],也有学者提出通过建立模糊语义与三角模糊数之间的映射关系来量化关联关系[17];还有学者采用因子分析从专家评价集中获取维度与产品模块之间的关联[18]。但上述方法仍依赖于人员的知识与经验,带有较强的主观性。
FPGrowth是一种用于从数据集中挖掘出事物间潜在关联的算法,如从交易记录中发现商业规律,分析用户的购买行为。该方法将每条评论中所包含的属性词作为一个项集,利用这些项集构建树状结构,从而分析项集中词语之间的互相依赖和条件先验关系。通过支持度和置信度来度量事物间的关联关系,得到一种数值化的度量描述,分别如式(5)和式(6)所示。
support(A⟹B)=P(A∪B),
(5)
(6)
其中,A⟹B表示A为B的先验条件;支持度表示某一项集出现的概率;置信度表示项集中提到A的同时提到B的可信度。本文将A⟹*作为属性A对其他属性的影响,并以支持度进行表示。基于此思路对所有属性进行分析,最终可以获得各属性间的影响与被影响关系,并通过属性间的影响与被影响关系来共同反映属性间的关联性。由于存在个人评价习惯等因素的影响,使得评论中存在一些无关联或低关联的词对。为了减弱它们的影响,本文利用置信度来修正支持度,当属性A与属性B关联较小或无关联时,其支持度值与置信度值较小,通过两者相乘可以进一步减小属性间的影响关系,以此获得更加准确的分析结果。最终影响程度的计算如式(7)所示。
(7)
原有通过相互关系矩阵确定权重的计算方法如式(8)~(10)所示。
(8)
(9)
(10)
其中:Wi表示第i个属性的权重系数;Ci表示第i个属性对其他属性的影响程度之和;Ei表示第i个属性被其他属性的影响程度之和。
根据式(8),属性权重是通过某一属性对其他属性的影响与被影响程度之和与2倍的所有属性间影响与被影响程度之比确定。在此过程中,可以认为原有矩阵的对角线元素作为某一影响因子n参与计算,该影响因子与上述比值相乘,得到最终权重分配(如式(11)),其中n=1时即为式(8)所述情况。
(11)
为了在产品评价过程中结合用户对属性的重视程度,本文将重视系数引入原有矩阵的对角线中作为影响因子,形成改进矩阵。通过用户对属性的重视系数和属性的影响与被影响程度相结合的方式综合考虑主客观因素,以此确定各属性最终的权重分配。
i,j=1,2,3,…,m。
(12)
式中Ii为用户对第i个属性的重视系数。
2.3 评价结果分析

B=W·R。
(13)
为了直观地表现产品综合评价结果,建立值域为0~10的满意度量表来直观地反映用户对产品的满意度,其中结果为0时表示用户极不满意,为10时表示用户极满意。将用户态度为满意所对应的元素b1通过式(14)映射到该区间内,得到最终的产品评价得分。
(14)
3 实例分析
为了验证本文提出的评价分析模型的可行性,以电动牙刷为例进行实例验证。通过对比本文所提方法得到的分析结果与传统方法得到的结果,分析其中形成权重分配结果不同的原因,验证本文提出的评价分析方法在考虑属性间关联性方面的有效性,并根据调研访谈结果分析形成该结果的原因。
3.1 电动牙刷的评论数据获取及清理
本文选取京东商城的飞利浦HX6730电动牙刷作为分析对象,使用八爪鱼采集器,按照评价时间顺序爬取该产品的评论数据,共获取5 000条评论文本。获取的评论文本中包含大量重复、无效等噪音数据,为了保证数据的有效性,首先通过Python编程语言对这些评论数据进行清理,最终获得初步处理后的数据3 165条。
3.2 构建电动牙刷的评价分析模型
3.2.1 产品属性词抽取及指标确定
将标注了产品属性词的语料集通过BiLSTM结合CRF的方法训练出一个判断模型,利用该模型从在线评论中提取属性词,并通过词云图展示,如图3所示。

由于数据来源于B2C网站,提取的属性词中包括部分对网站服务的词,如“物流”、“包装”和“服务”等。因此本文仅选取该款产品自身的属性词,通过词频统计分析,并剔除网站服务的词语,选取词频数前十的属性词作为评价维度,初步确定评价维度为{清洁,质量,声音,刷头,振动,性价比,包装,价格,噪音,充电}。合并同义词后,最终确定8个评价维度,分别为质量、刷头、声音、振动、价格、电池、外观、清洁能力。
3.2.2 用户重视系数确定
将所有评论文本作为语料,通过FastText训练出语义模型,根据此模型将所有属性词与评价指标进行语义相似度计算,最终得到7个属性词集,各指标对应的属性词集如表1所示。
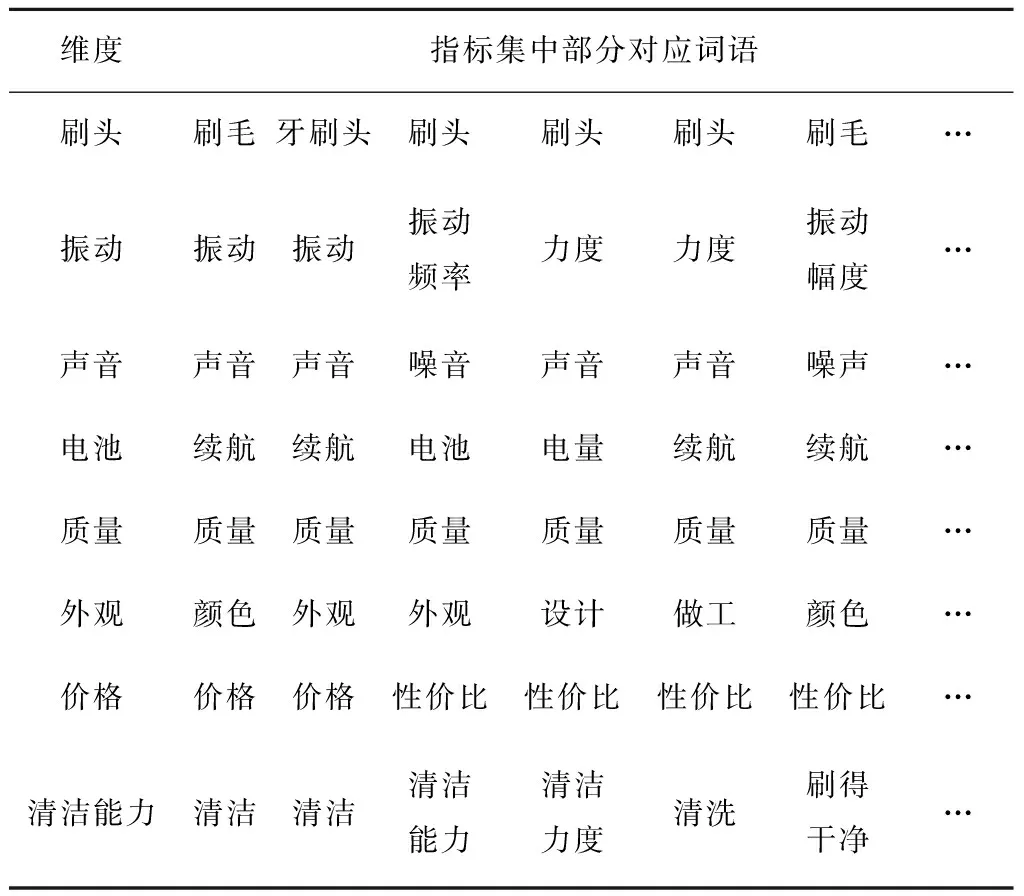
表1 部分分类结果表
通过统计属性词集中元素的数量,对照比例标度表,建立判断矩阵A,如表2所示。
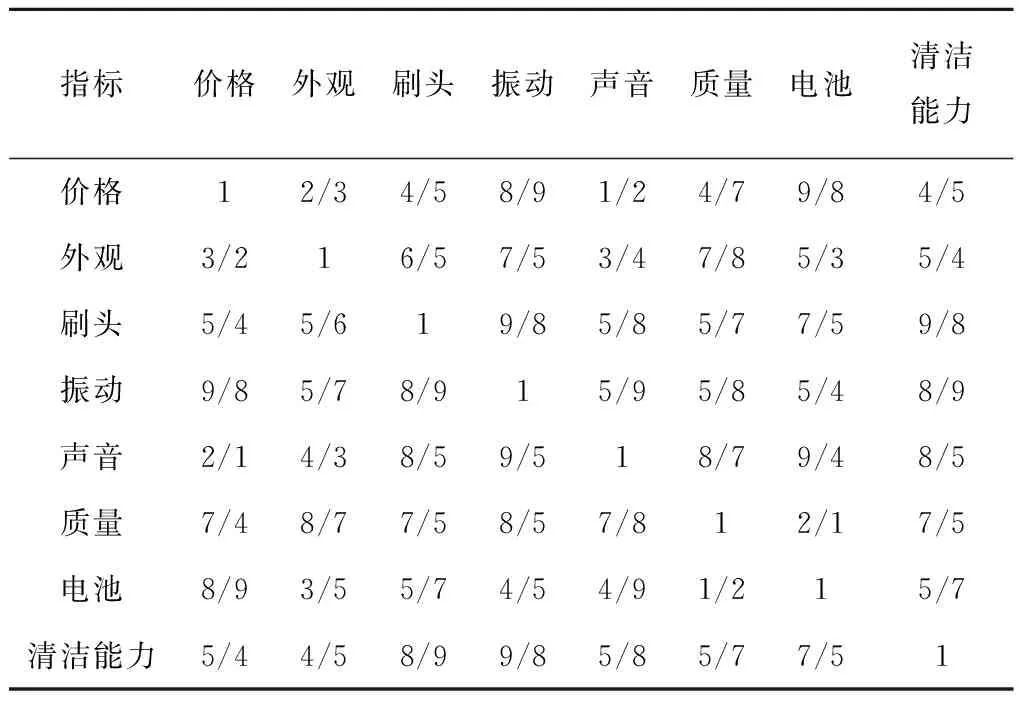
表2 判断矩阵A
其中判断矩阵A的阶数n=8,根据随机一致性指标RI标准取值表,其随机一致性指标RI=1.41,根据式(1)和式(2)计算得到最大特征值λmax≈8,CR=0<0.1,满足一致性条件,因此计算得到的特征向量可以作为用户对各属性的重视系数,最后结果为W={0.093,0.141,0.118,0.103,0.186,0.163,0.082,0.114}。
3.2.3 属性间关联关系分析及权重确定
通过FPGrowth算法对评论中包含的属性词进行分析,计算得到各属性词对的支持度,根据式(6)计算出置信度,将两者相乘后得到属性间的关联程度。将属性的重视系数代入矩阵对角线,最终得到的改进相互作用关系矩阵如表3所示。由式(5)可知,支持度是由属性词对共现的次数与有效评论数之比得到,而作为分母的有效评论数远远大于分子的数量,因此与置信度相乘后计算得到的关联程度数值较小,为了便于展示,均以科学计数法表示,即×10-4。
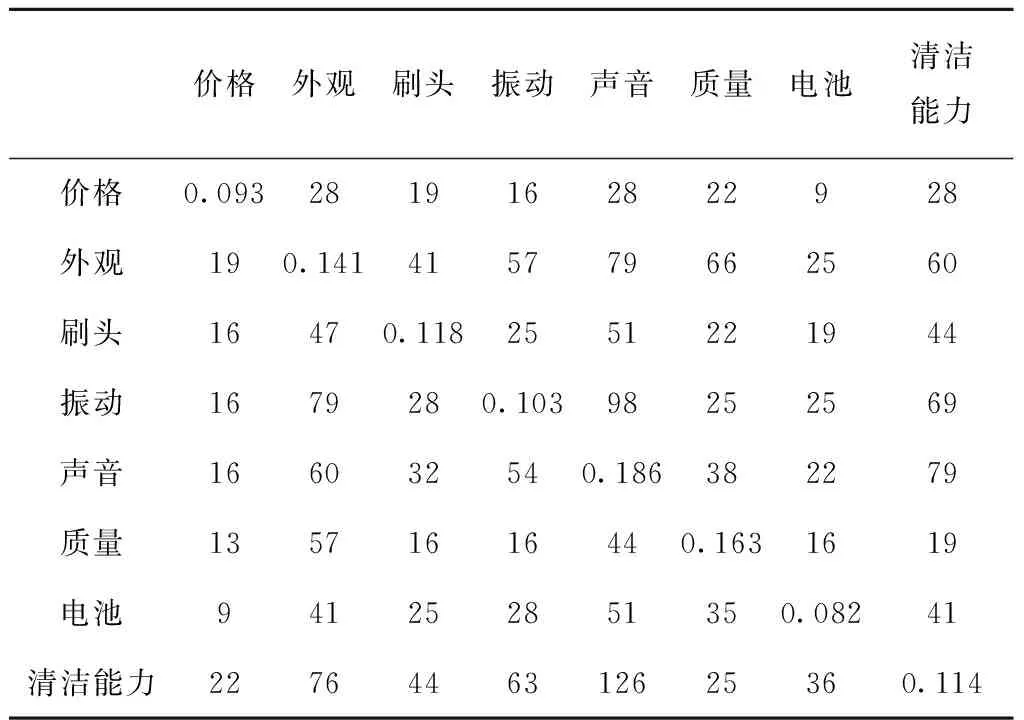
表3 改进的相互作用关系矩阵表 ×10-4
基于该矩阵,通过式(9)、式(10)和式(12)的计算,将结果归一化后得到产品属性最终的权重分配,如表4所示。

表4 最终各指标权重分配表
3.3 评价结果对比及产品表现分析
将上述分析的结果与传统未考虑属性关联性的结果进行对比,结果如图4所示。
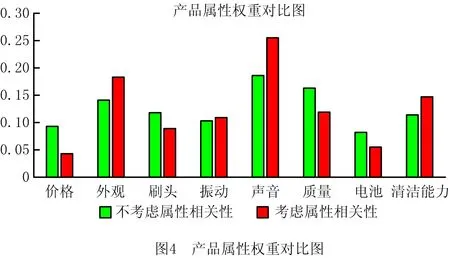
由图4不难发现,在考虑了属性间关联性后各指标权重发生了变化,以“外观”指标为例,大量的用户在提及“外观”的同时还对其他属性进行了评价,则认为“外观”与其他属性存在较多关联,分析结果表现为其权重值升高。
为了确定产品的评价等级,本文以综合评价向量来确定。上述步骤中已经获得了评价指标的权重分配,还需要确定隶属度矩阵。使用FastText进行属性词分类的同时,也将这些属性词所对应的评论数据进行了分类。由于好评与中评的边界模糊,无法准确区分,而评论的正负倾向有着明确的区分,因此本文对评论文本仅分为满意与不满意两类。通过Bert预训练模型与正负训练语料集,对评论数据进行极性判断,得到积极评论数量与消极评论数量,归一化之后作为隶属度矩阵的元素,得到隶属度矩阵
R=
将上述结果代入式(13),归一化后得到产品综合评价向量B={0.915,0.085}。将用户态度为满意所对应的元素根据量表映射为0到10的值域,最终评价得分为9.15分,根据满意度量表,该结果表明用户的该款电动牙刷的满意度较高。
3.4 调研结果分析
为了验证本文所述方法得到的分析结果的可信度,通过对用户进行调研来获得较为客观的评价数据。调研采用在线问卷的形式进行,为了确保问卷内容的有效性,参考国内外文献进行设计,并满足分析对比的需求,最终形成本研究的调研问卷。
调研问卷包括用户关注的产品属性、关注这些属性的原因以及用户的情感态度3个部分。其中,第一部分的产品属性确定来自于上述分析中获取的产品属性词;第二部分的关注原因包括用户对产品的使用体验、使用效果和使用寿命等因素,用于分析影响用户做出选择的主要因素;第三部分的用户情感态度采用Likert五分量表进行打分,从而获得用户对各属性的情感态度。通过对这些调研数据进行统计分析,将其结果与本文的分析结果进行对比,进而验证分析结果的准确性。
本次调研共收到215份调查结果,通过筛选,使用过该款电动牙刷或相近产品的结果为189份。根据数据统计分析,用户关注的产品属性比重如表5所示。
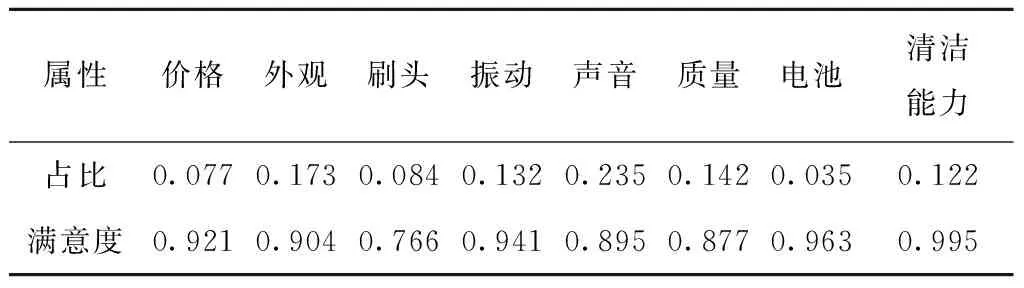
表5 各属性满意度表
从表5可以看出,消费者最关注的指标是“声音”,其原因是电动牙刷相比普通牙刷会产生更大的声音,成为影响体验的主要因素,该结果与调研结果中69%的用户选择的主要考虑因素为“使用体验”相符,同时也符合本文所述方法的分析结果。用户的满意度分析结果如表5所示,该结果与本文所述方法分析的结果差距小于5%,与本文分析结果相近,验证了本文提出的方法的可行性与可信度。
4 结束语
产品评价需要准确反映出用户对产品各方面的情感态度,而在线评论中包含了大量用户的真实使用感受。本文在分析在线评论数据与产品评价方式的基础上,提出一种将AHP与相互作用关系矩阵结合的方法,该方法通过引入对产品属性间关联关系的分析,解决评价指标间的模糊性问题,最后以电动牙刷为例进行了验证。实验结果表明,从评论数据中可以挖掘出用户关注的产品属性,且通过文本构建的改进矩阵,在产品评价过程中综合考虑了用户观点与属性间的关联关系,从而更加准确地分析出各属性的表现。因此本文所提方法可以为企业改善产品使用体验、进行产品优化升级提供支持。本文仅从用户的评论中所提及的产品属性词中分析属性间的关联关系,存在一定的片面性,在后续的研究中,考虑将专利与评论两种数据进行融合,实现更加全面的关联性分析。
猜你喜欢
当代陕西(2019年15期)2019-09-02 01:52:00
计算机应用(2018年12期)2019-01-08 01:55:48
商周刊(2018年26期)2018-12-29 12:56:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
集美大学学报(自然科学版)(2015年1期)2015-02-28 01:13:33
