
基于深度网络的汽车配件两级备件决策
2023-01-12 12:31张明蓝孙林夫邹益胜
计算机集成制造系统 2022年12期
张明蓝,孙林夫+,邹益胜
(1.西南交通大学 计算机与人工智能学院,四川 成都 610031;2.四川省制造业产业链协同与信息化支撑技术重点实验室,四川 成都 610031)
0 引言
汽车行业作为中国制造业的行业标杆,经过多年的发展已经成为我国支柱性产业之一[1]。调研统计结果显示,2019年汽车生产量与销售量较上年减少7.5%和8.2%[2],但是汽车配件售后市场依然是汽车企业和汽车零配件企业的主要收益来源之一。当前汽车配件代理商的备件模式是配件代理商企业向整车制造厂或配件供应商进行配件采购,储备在自己的仓库中,再将配件销售给服务商[3]。由于汽车配件种类繁多,需求波动性大,备件过程中容易出现信息不完备与多样性的问题,从而导致供需匹配不及时、库存积压或不足。因此,对于配件代理商企业,如何实时高效地对汽车配件进行备件是一个亟待解决的问题。
目前,国内外学者对汽车备件的研究如下。MALVIYA等[4]运用选择性库存控制技术对汽车备件库存审核与控制进行研究;MEHDIZADEH[5]将ABC分析与粗糙集理论相结合,对汽车零部件供应链中经销商的库存进行控制;SADEGHI等[6]提出了考虑选址—路径问题的绿色闭环供应链网络设计的混合整数线性规划模型;IDRISSI等[7]提出一种基于多Agent系统和多目标线性规划的混合方法,实现环境客户协作过程的自动化和便捷化;任春华等[8]提出了面向多价值链的需求组合预测模型(Light GBM_GRU_AM)与半组合预测模型(LightGBM_GRU_SC);CHANDRIAH等[9]提出了带修正Adam优化器的递归神经网络/长短时记忆方法来预测备件需求量。
在上述研究中,学者们倾向于汽车备件的库存、物流与需求等方面,较少考虑备件决策对汽车配件的影响。目前大多数备件决策主要集中于航天、军工、铁路等领域。王亚东等[10]提出了基于动态进化算法的多阶段备件供应优化决策;何勇等[11]建立了面向分阶段预防性维护与备件弹性订货的联合优化模型;杨志远等[12]建立了系统维修与备件订购决策优化模型;蒋伟等[13]研究的T/R组件维修决策问题可以为装备保障人员提供维修决策支持;张海军等[14]提出一种基于数字孪生的制造资源动态优选决策方法;ANDREW等[15]提出一种利用模糊逻辑和动态调度开发维修计划智能决策方法。但目前的备件决策大多是单一层次的,未对数据进行二级细致划分,可能导致备件决策的制定出现偏差。
汽车配件种类繁多且需求波动较大,针对汽车备件决策过程中信息不完备与多样性的问题,本文基于第三方云平台,提出一种正则化VIT-BiLSTM两级备件决策模型。该模型能够对汽车配件种类进行两级划分,并自适应地提取较为全面的特征信息,为汽车配件代理商提供两级备件决策。首先,利用VIT(vision transformer)模型的多头注意力机制充分融合全局和区域特征,并学习目标特定的信息,提取配件决策数据中的多尺度深层特征。然后,使用双向长短时记忆循环神经网络(Bidirectional Long Short Term Memory, BiLSTM)捕捉特征信息的时间依赖性,对双向全局时间特征进行充分提取,为了防止过拟合,融入组套索正则化模块进而实现二级决策。最后通过实验,并与其他模型进行对比,验证了所提方法的有效性与优异性。
1 问题描述
汽车零部件多产业链业务协同云服务平台(http://www.autosaas.cn/)(简称第三方云平台或平台)[16]是一个为汽车供应链相关企业提供生产、制造、销售和售后维修等信息化系统服务的第三方云平台。平台运行10余年来,已经聚集了上万家制造企业、零部件供应商企业、配件代理商、经销商等中小型企业,积累了大量的整车销售、配件销售、配件采购和售后服务数据。
汽车配件销售情况是备件决策的核心参考依据,经过对第三方云平台上面的配件销售业务的梳理分析,平台上的配件销售模式可以分为以下过程,如图1所示。首先,配件供应商将配件销售给整车制造厂,同时配件供应商也可以向配件代理商直接进行配件销售。然后,整车制造厂根据下游配件代理商或者是直属的服务站的配件订单的订货量,将配件按单发货给配件代理商或者是服务站。最后,配件代理商根据服务站的配件订单按需销售配件给相关服务站。

由图1可知,配件代理商拥有对配件的销售自主权,可以直接向制造厂买断配件并存于自身库存中。这种方式虽然能使代理商摆脱受制造厂控制的局面,快速响应服务商的购买需求,但是代理商对配件自负盈亏就会增加备件成本。由于配件类型多、更新快,配件的需求量波动很大,备件决策过程中将导致信息不完备与多样性的问题,使备件决策的难度大大增加。因而,本文更注重的是在控制现有成本的基础上,提高配件代理商进行备件决策的准确性,防止因库存过多而导致备件积压的情况发生,或是因为缺货而导致备件无法及时供应的现象出现,实现全供应链的库存降低,减少浪费。
考虑到配件多种类、差异性大的特点,本文从配件代理商的角度,将汽车配件按照不同类型进行两极划分,设计了一种正则化VIT-BiLSTM两级备件决策模型,为配件代理商提供二级备件与辅助采购决策,帮助代理商避免库存积压或者库存不足等问题。
2 正则化VIT-BiLSTM两级备件决策模型
2.1 相关理论
2.1.1 VIT模型
VIT(Vision Transformer)是一种完全基于Transformer[17]的架构,Transformer遵循“编码器—解码器”结构,其核心是自注意力机制,通过建立权重参数来表示输入序列的各个部分与最终结果之间的相关性,能够在不依赖任何循环网络的情况下并行处理顺序数据[18]。与传统卷积神经网络(Convolutional Neural Network, CNN)架构不同,CNN模型关键在于它所采用的局部连接和共享权值的方式避免了传统识别算法中复杂的特征提取和数据重建过程,而VIT主要利用Transformer的编码器模块来执行一些操作,其采用的多头注意力机制不仅关注局部不同区域信息,还整合全局信息,VIT结构如图2所示。
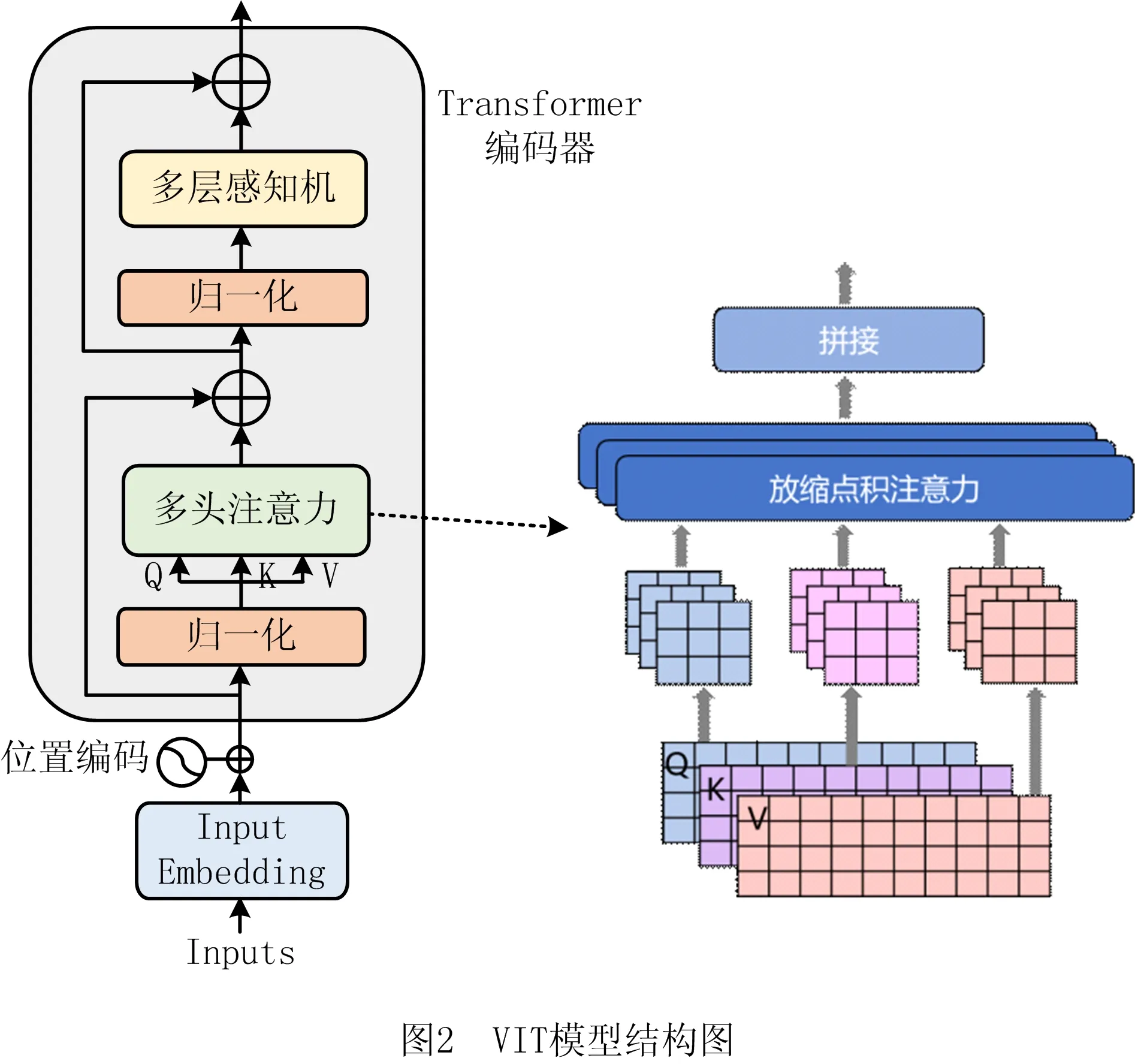
由图2可知,Transformer编码器由两个主要子组件构成:多头自注意力模块(Multi-head Self Attention, MSA)和多层感知机模块(Multi Layer Perceptron, MLP)。多头自注意力模块和多层感知机模块中都含有归一化层(LN),在每个模块前对输入进行归一化,在每个模块后利用残差连接,以降低模型训练的难度。
在多头注意力模块中,文献[17]构造了标准的q,k,v计算方法,其中:q表示要查询的特征,k表示要匹配的特征,v表示要查询和匹配的特征的相关测度值。对经过位置编码处理后的数据进行线性变换可得q,k,v,可表示为:
q=Wqz,
(1)
k=Wkz,
(2)
v=Wvz。
(3)
其中:Wq、Wk和Wv为线性变换的权值;z为经过位置编码处理后的数据。
将q与k的匹配度在D维空间归一化后,通过softmax函数可以得到注意力权值A,T为序列长度。最后,将注意力权重A与相关测度值v的匹配值进行计算,可得到自注意力SA的权重,可表示为:
(4)
SA(z)=Av。
(5)
改变线性变换Wq的随机初始化映射权值,Wk和Wv可以将输入向量映射到不同的子空间,使得模型可以对输入序列进行多角度的解读。将同时计算多个自注意力的方法称为多头注意力机制,其通过对k个SA的取值进行加权得到,可表示为:
MSA(z)=[SA1(z);SA2(z);…;SAk(z)]Umsa。
(6)
其中Umsa表示加权求和的权重矩阵。
多层感知机模块主要由一个多层感知器组成,其中包含一个激活函数GeLU与两个全连接层。整个VIT模型的编码过程可以表示为:
(7)
(8)
(9)
其中L为线性函数,将多头注意力和多层感知机连接在一起。
本文主要根据不同配件类型对备件决策的数据集进行二级划分,数据特征较多,而VIT模型作为深度网络模型的热点,其多头注意力机制在处理该类数据集的特征时具有一定优势。
2.1.2 BiLSTM神经网络模型
BiLSTM是循环神经网络的一种变体[19],由两个方向相反的长短时记忆循环神经网络(LSTM)神经网络构成。LSTM模型由输入门it、遗忘门ft、输出门ot及记忆单元ct构成,通过这些门控单元对网络中的信息进行选择性的输入、输出以及遗忘操作,能够有效克服一般神经网络所存在的梯度消失问题。LSTM单元的内部结构如图3所示。
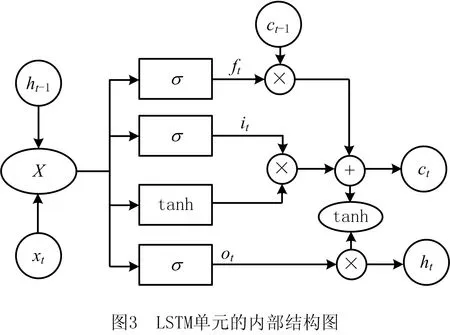
整个过程用数学公式可表示为:
it=σ(Wi·X+bi),
ft=σ(Wf·X+bf),
ot=σ(Wo·X+bo),
ct=ft⊗ct-1+it⊗tanh(Wc·X+bc),
ht=ot·tanh(ct)。
(10)
式中:xt为t时刻输入LSTM的数据;ht为t时刻的隐藏层状态;W和b分别为LSTM的权值和偏置;σ为激活函数sigmoid;⊗为逐点乘积;tanh为激活函数。
虽然LSTM能够解决长期依赖问题,但是它只是利用了过去的信息,并没有考虑未来的信息。BiLSTM由两个方向相反的LSTM层构成,在每个时刻,BiLSTM神经网络可学习到其前后时间点的序列信息,使得BiLSTM神经网络可以综合考虑序列信息的历史数据和未来数据,增加模型可利用的信息,有助于提升模型的性能[20-21]。BiLSTM内部结构如图4所示。
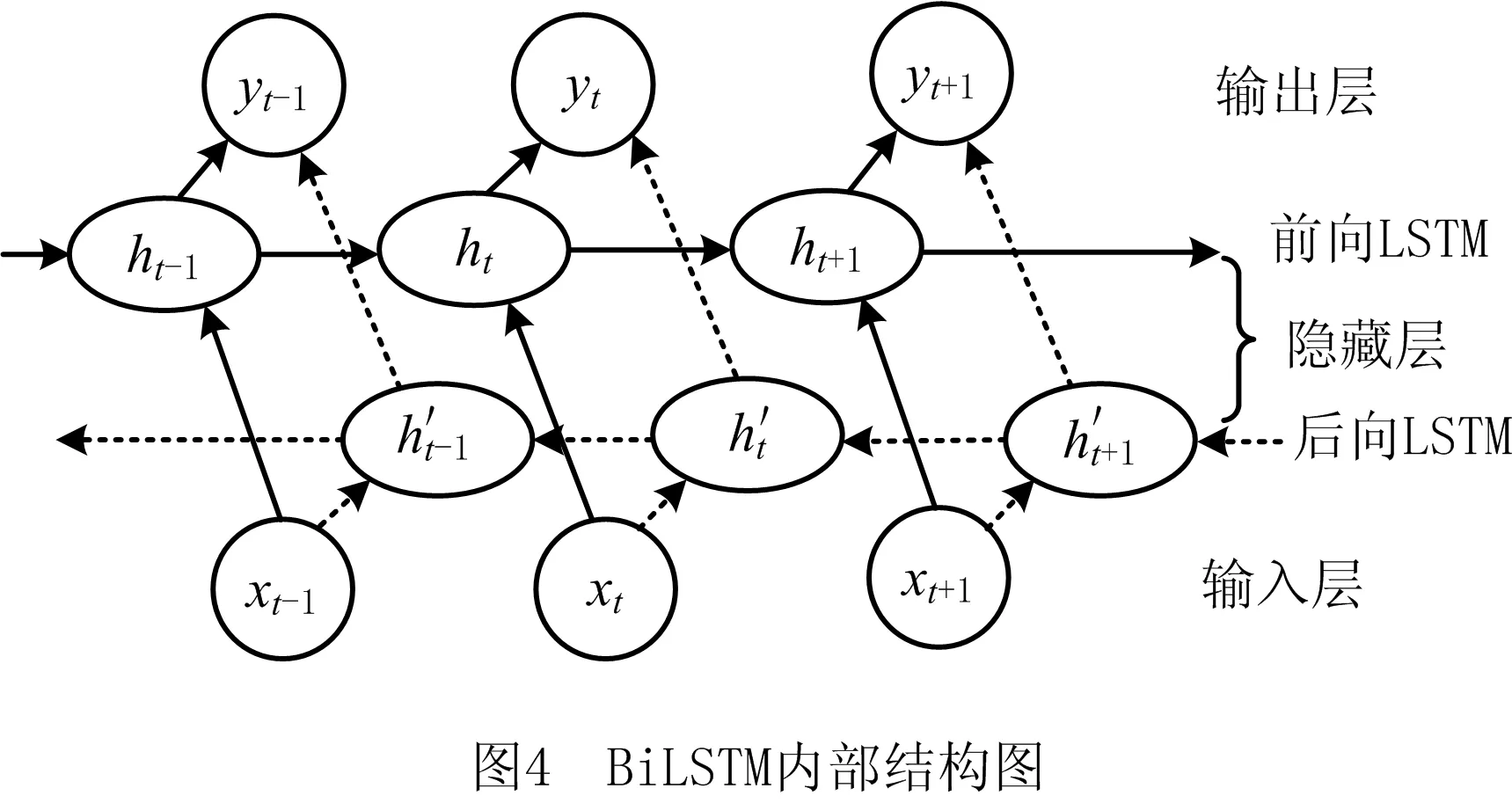
(11)
其中T为序列长度。
本文研究集中在汽车配件的备件决策,由于汽车配件种类繁多,数据量大小不同,决策难度与时间成本会大大增加。BiLSTM作为经典的深度网络模型,利用BiLSTM通过两层相反方向的数据流对配件特征进行处理,兼顾配件的历史特征信息和未来特征信息,从而减少时间成本。
2.1.3 正则化模块
由于配件数据关联性不强且差异性较大,为增强本文模型的泛化能力,采用稀疏化的正则化方法对模型进行优化。组套索正则化可以实现变量组的稀疏,使得变量组别同时为零或同时不为零[22]。将组套索正则化引入到BiLSTM模型中,对输入权重w进行正则化处理。稀疏组套索惩罚RSGL分别由l2,1和l1惩罚项的叠加构成[23]:
RSGL(w)=Rl2,1(w)+Rl1(w)
(12)
式中:w为权重;|g|为传感器向量g的维度,它保证了每个组都得到统一加权。相对于‖g‖2范数的次优解稀疏方法,正则化表示采用的是绝对值的形式。此方法优势在于让更多的系数归结为0,加快收敛速度。稀疏组套索(Sparse Group Lasso, SGL)惩罚与构成它的范数具有相同的性质,通过式(12)即可输出稀疏正则化的最优解。
2.2 正则化VIT-BiLSTM两级备件决策模型
从汽车产业链配件代理商的角度,针对汽车备件决策过程中信息不完备与多样性的问题,本文提出正则化VIT-BiLSTM两级备件决策模型,帮助配件代理商进行不同周期下的多类型备件决策与辅助采购决策。由于多头自注意力机制,VIT模型不仅能够自适应提取配件数据中的局部特征,还考虑了全局信息,减小对先验知识的依赖以及人为选择特征导致的误差。而BiLSTM能够从前后两个方向学习序列的时间依赖性,每个序列单元中融入的正则化方法能对结果进行约束,提升决策结果的准确性。本文结合两种模型的优势,构建了正则化VIT-BiLSTM两级备件决策模型,模型结构如图5所示。
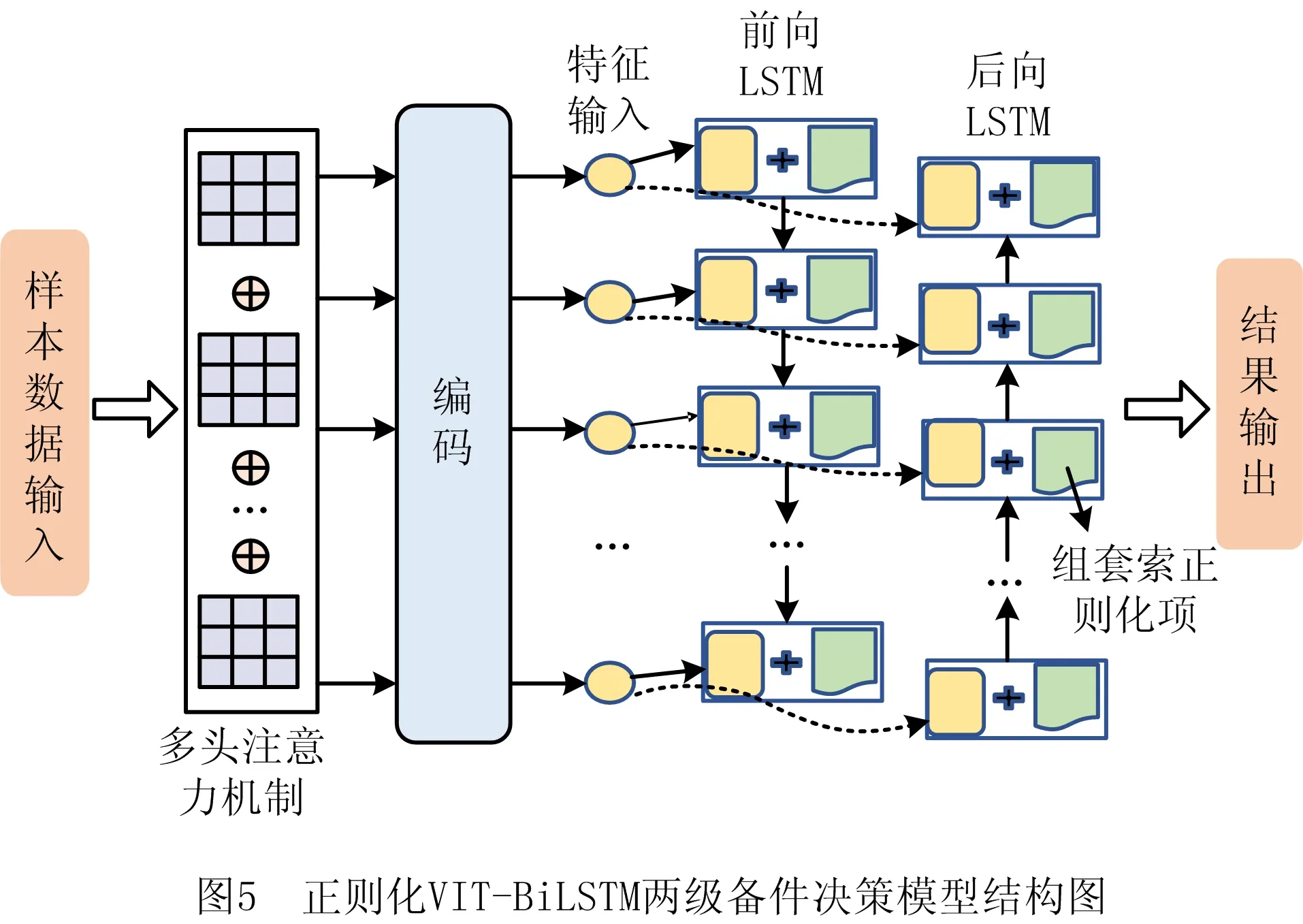
正则化VIT-BiLSTM两级备件决策模型将从第三方平台上获取的配件相关数据作为样本数据,由VIT模块提取多尺度抽象特征,之后利用BiLSTM从前向和后向对其进行序列建模,充分学习特征在时间上的前后依赖性,同时对每个序列单元加入正则化项对结果进行约束,将结果进行输出。算法实现流程如图6所示。
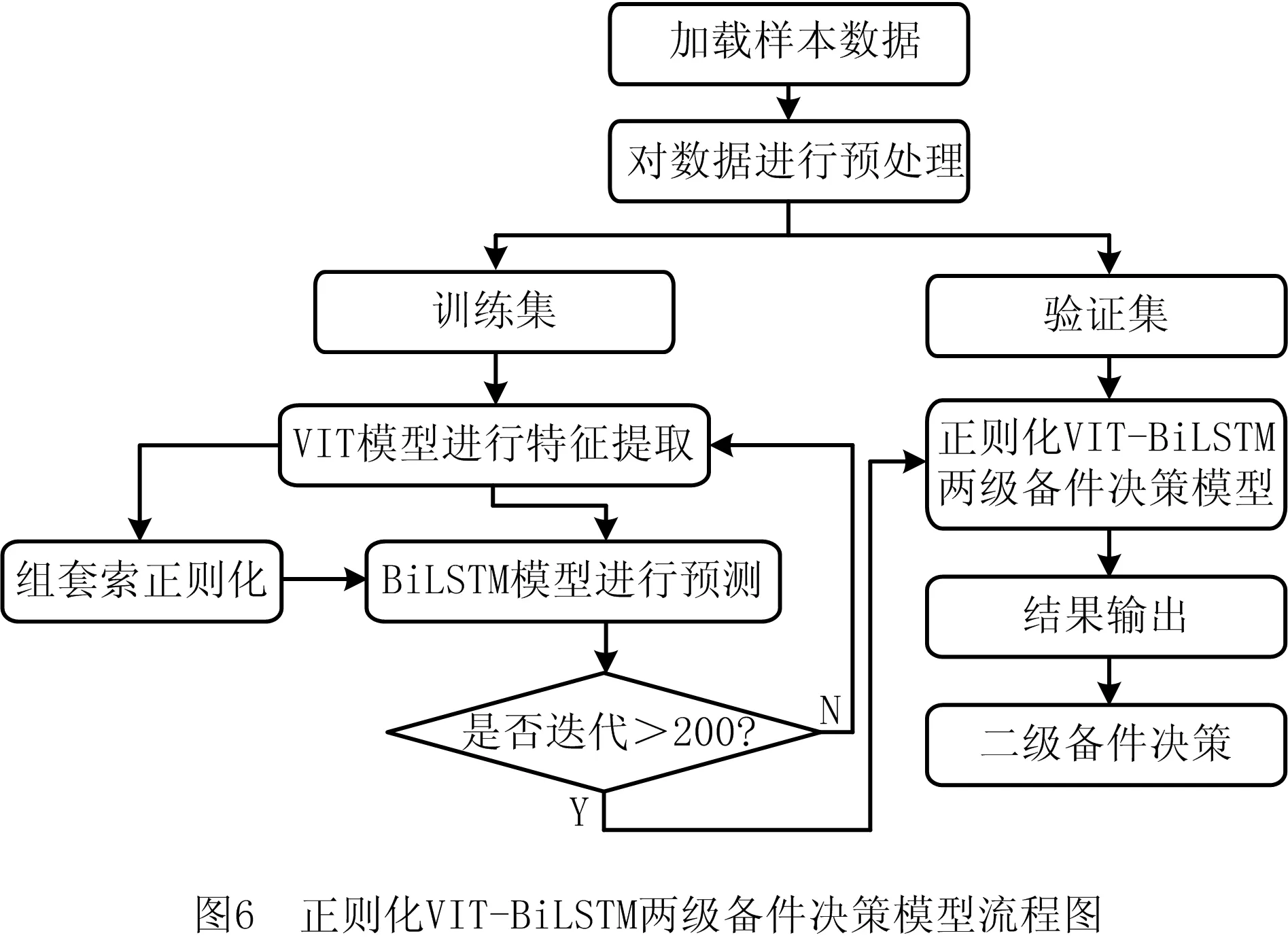
由图6可以看出,正则化VIT-BiLSTM两级备件决策模型具体实现步骤如下:
步骤1将配件销售数据根据配件类型按照一级指标与二级指标进行分类,一级指标分为7类,二级指标分为20类;
步骤2输入样本数据{x1,x2,…,xn},对数据进行预处理;
步骤3将处理后的数据经过VIT模型进行特征提取,得到特征数据{z1,z2,…,zm};
步骤4将特征数据{z1,z2,…,zm}输入BiLSTM模型,得到结果{p1,p2,…,pt},即一级指标与二级指标下的配件备件概率;
步骤5在BiLSTM模型的每个时间序列中融入组套索正则化项,通过正则化项对BiLSTM模型进行修正与约束;
步骤6将数据{p1,p2,…,pt}与平均销量进行计算,得到备件辅助采购量{y1,y2,…,yt},为汽车配件备件提供二级决策。
3 实验与分析
3.1 数据和参数调优
3.1.1 数据和实验环境
汽车配件的历史销售数据对备件决策有着极为重要的参考价值,本文以第三方云平台上某配件代理商的相关配件销售数据作为实验数据集,基于平台提取相关数据。通过对数据进行清洗、筛选、整理等操作,可得到用于配件备件决策的数据集。实验平台为Inter®CoreTMi7-9750H CPU,16G RAM,Inter®UHD Graphics 630以及Windows 10 64位操作系统。软件平台采用Pycharm,编程语言采用Python 3.6。
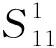
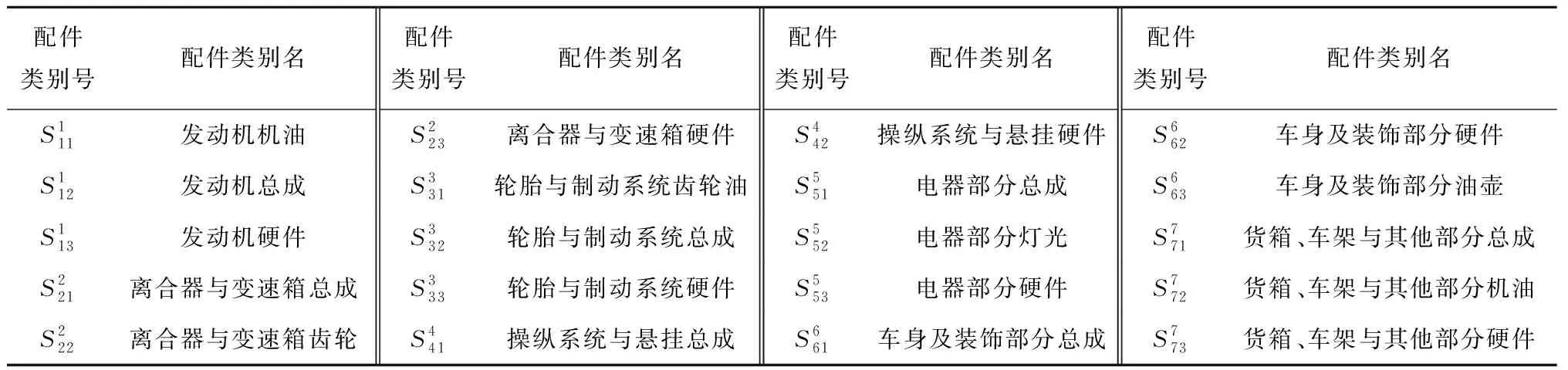
表1 不同配件的配件类别号
本文选取的数据时间范围为2018年3月~2021年3月,该数据集按7:3比例划分为训练集与验证集。为了得到准确的备件决策,全面挖掘多类型配件的深层关系,将汽车配件20个类型的销售数据作为数据集的特征。这些配件相关数据构成了配件的备件决策数据集,部分数据如表2所示。

表2 部分备件决策数据
对于模型而言,本文采用混淆矩阵(Confusion Matrix)计算实际样本值和模型输出的精准率、召回率和F值作为评价指标[24],并根据这3个指标的结果对算法模型的有效性以及精准度进行判断。精准率(Precision)、召回率(Recall)和F值的具体计算公式如下:
(13)
(14)
(15)
其中:C为样本总数;c为配件类别总数;TPi为被正确分到第i个类别上的正样本;TNi为被正确分到第i个类别上的负样本;FPi为被错误分到第i个类别上的正样本;FNi为被错误分到第i个类别上的负样本。
3.1.2 参数调优
在本文的模型结构中,VIT模块使用Adam优化器[25]对网络进行训练并提取配件数据抽象特征,设置学习率为0.001,批量大小为50。BiLSTM模块从双向提取时间序列信息,设置其隐藏层为40。经过多次实验后,最终确定的模型参数如表3所示。

表3 正则化VIT-BiLSTM两级备件决策模型参数
3.2 两级备件决策模型实验
3.2.1 两级备件决策模型有效性分析
针对汽车备件决策过程中信息不完备与多样性的问题,本文提出正则化VIT-BiLSTM两级备件决策模型。模型训练集与验证集的损失函数曲线如图7所示。可以看出,验证集与训练集都有较好的收敛效果,迭代30次后趋于平稳,未出现过拟合现象,表明了网络训练过程有效。

3.2.2 两级备件决策模型准确率分析
为了验证模型对多类别配件的决策准确性,将训练得到的模型应用于测试集,结果如图8所示。便于展示,只选取了前100天的数据进行分析。可以看出,本文模型的决策准确率高达98%,可以为配件代理商提供准确的多类型汽车配件的备件决策。

汽车配件种类繁多,正则化VIT-BiLSTM两级备件决策模型从一级指标与二级指标对汽车配件进行实验与分析,结果如表4所示。可以看出,正则化VIT-BiLSTM两级备件决策模型的一级决策准确率为99%,二级决策准确率为97%。虽然二级决策准确率稍低于一级决策,这主要是由于在二级指标的划分下,汽车配件差异性逐渐增大,但是模型的决策准确率依然优于VIT模型与BiLSTM模型。本文模型具有较高的决策准确率,说明其能为配件代理商提供下一阶段的需要采购的配件类型,帮助其了解不同类型下的配件备货情况。
表4 正则化VIT-BiLSTM两级备件决策模型准确率

续表4
汽车配件具有周期性,配件代理商在备件时必须要考虑周期性的问题,因此需要分析周、月、季、年的模型准确率。不同周期下的正则化VIT-BiLSTM模型、VIT模型与BiLSTM模型准确率如图9所示。

由图9可知,在短周期的情况下,三个模型的汽车配件备件决策率稍有波动,随着周期逐渐增大,尤其是到了季、年以上的周期时,模型的准确率都出现了下降。这主要是因为汽车配件是消耗型物品,几乎每天都有销量,所以周期为天或者周时,数据量是比较大的,随机性较小,因而决策准确率高。而当周期为月、季、年时,数据量会减少,随机性增大,所以准确率较低。尽管如此,本文正则化VIT-BiLSTM模型在不同周期下的准确率依然维持在97%左右,高于VIT模型与BiLSTM模型。
3.2.3 两级备件辅助采购决策分析
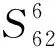
3.3 对比实验
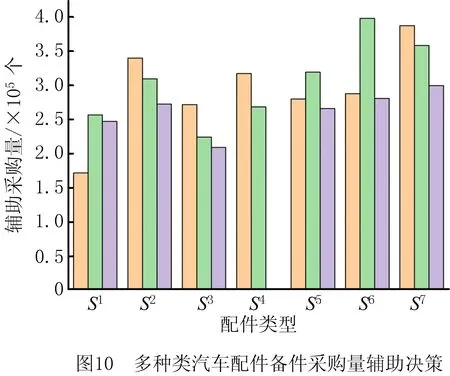
为进一步体现本文所提正则化VIT-BiLSTM两级备件决策模型的有效性,本文选择VIT模型、BiLSTM模型、CNN模型、VIT-LSTM模型、VIT-CNN模型与本文模型进行比较,结果如图11所示。
由图11可知,随着迭代次数的增加,本文模型与对比模型的二级决策准确率都有逐渐上升的趋势。VIT-LSTM模型与VIT-CNN模型的准确率稍低于本文正则化VIT-BiLSTM两级备件决策模型,且当迭代次数到达25时,本文模型准确率预先达到最高值,接近99%,突出了本文模型备件决策的优异性。另外,相较于BiLSTM模型与CNN模型,VIT模型的准确率较高,这主要归因于VIT模型的多头注意力机制在提取特征时具有优势。

表5 不同模型实验结果对比
从表5可以看出,无论是精准率、召回率或F值,本文正则化VIT-BiLSTM两级备件决策模型的各项指标均具有较好的表现,一级决策性能略优于二级。在前3种单模型中,VIT与BiLSTM的精准率与召回率都远远高于CNN模型。另外,相较于VIT-LSTM与VIT-CNN模型,本文模型精准率高达98%,F值高达96.4%,具有更优的可信度。这主要得益于本文正则化VIT-BiLSTM模型有效利用了VIT模型的多头注意力机制,既关注局部信息又考虑了全局信息。本文所提正则化VIT-BiLSTM模型决策准确率高,且不需要专家经验与物理背景知识,具有较强的实时性与适用性,能够帮助汽配企业进行二级备件决策。
4 结束语
本文站在配件代理商的角度,针对汽车备件决策过程中信息不完备与多样性的问题,提出一种正则化VIT-BiLSTM两级备件决策模型。模型先对汽车配件种类进行两级划分,然后采用VIT模型的多头注意力机制以提取数据中的多尺度深层特征,再通过BiLSTM模型对双向全局时间特征进行充分提取,同时在序列单元中融入组套索正则化模块防止过拟合。通过第三方云平台的数据进行算例验证,本文模型一级与二级决策准确率、召回率与F值均高达96%以上,说明模型能够有效地帮助汽车配件代理商进行备件决策,同时满足一级与二级指标下的多类型汽车配件辅助采购。尽管本文提出的二级备件决策模型能为配件代理商提供实时备件参考与采购依据,但模型在训练过程中增加了一些时间开销。未来也将进一步降低模型的时间成本。
猜你喜欢
水泥技术(2022年4期)2022-07-27
怀化学院学报(2021年5期)2021-12-01
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
科学家(2021年24期)2021-04-25
汽车电器(2019年9期)2019-10-31
活力(2019年15期)2019-09-25
上海师范大学学报·自然科学版(2018年3期)2018-05-14
火力与指挥控制(2017年10期)2017-11-17
中国核电(2017年1期)2017-05-17
