
基于深度学习的眼底图像辅助诊断系统设计
2023-01-11 13:23林静敏魏松林
安徽电子信息职业技术学院学报 2022年6期
林静敏,魏松林
(1.厦门城市职业学院,福建 厦门 361008;2.厦门海洋职业技术学院,福建 厦门 361100)
1 引言
在眼科诊疗中,临床眼科医生可以通过眼底图像对患者的眼部健康状况进行评估和诊断。眼科疾病要想早发现、早诊断、早治疗,最重要的是定期眼底检查。据WHO公布的权威数据显示,截至2021年,中国现存的视力障碍人群总数已高达1.5亿,平均每位眼科专家需要解决超过5000人的眼部健康问题。面对巨量的眼底图像的评估和诊断需求,人工检测速度慢、可重复性差、劳动强度大等缺点显现无疑[1]。因此,研究和发展智能自动化的眼底疾病辅助诊断技术,对于眼科疾病及相关疾病的早期筛查、治疗监控及术后评估具有重要临床意义。
随着大数据发展,基于医疗大数据的人工智能辅助诊断技术不断发展和普及,基于眼底图像的智能辅助诊断系统在糖尿病视网膜病变、青光眼、白内障、年龄相关性黄斑病变等眼底疾病的筛查和诊治工作中展现了良好的灵敏度和特异度,提高了眼科医生的诊断效率[2-6],极大节省了筛查成本。深度学习的概念源自于人工神经网络的研究,它是通过对大量的样本数据进行训练,从而找到数据的内在规律和表示层次关系,这些规律的获取对图像识别、声音处理等都有极大帮助,因此它在语音和图像识别领域取得的效果远远超过其他相关技术。2018年,世界首个获批用于糖尿病视网膜病变的自主诊断人工智能(Artificial Intelligence,AI)在美国上市[7],该设备可用于检测22岁及以上DR患者的视网膜病变程度。2020年,中国国家药品监督管理局审查通过两款DR眼底图像辅助诊断软件产品,产品采用基于卷积神经网络的自主设计网络结构,基于分类标注的眼底图像数据,对算法模型进行训练和验证。
通过对国内外眼底图像辅助诊断系统的调研发现,现有眼底图像分类大多解决的是二元分类问题,集中在对某种疾病严重程度进行分级,对专业眼科医生的初步筛查疾病起到的帮助很小,同时存在网络参数存储量巨大、运行时间长等问题。因此,本文以轻量化的深度学习模型为构建载体,设计并实现一种可用于硬件部署的多分类眼底图像辅助诊断系统,通过降低模型参数量的方式来提高系统的运算效率,以期为眼底疾病的诊断提供参考信息和帮助。
2 基于深度学习的眼底图像辅助诊断系统的数据获取与预处理
基于深度学习的眼底图像辅助诊断系统的一般流程包括数据获取、数据预处理、模型设计、训练和精度评估五大步骤。通常数据的质量决定了深度学习模型和算法所能达到的最佳效果,因此充分收集、理解和挖掘数据,能有效地提高系统精度,提升深度学习模型在眼底疾病智能化诊断中的应用效果。
本文所用数据集来源于2019年北京大学国际眼底图像智能识别竞赛(Ocular Disease Intelligent Recognition,ODIR),其中数据集视网膜眼底图像共5000张,源于北京上工医信科技有限公司合作医院及医疗机构进行眼健康检查的患者数据,数据集标签信息均为专业医生诊断标注,包括患者的ID索引、年龄、性别、医生的诊断关键词以及诊断结果。诊断结果针对患者左右眼一对图片分为八个标签:N表示正常眼(Normal),D表示糖尿病视网膜病变(Diabetic Retinopathy),G 表示青光眼(Glaucoma),C表示白内障(Cataract),A表示年龄相关性黄斑病变(Age-related Macular Degeneration),H表示高血压视网膜病变(Hypertensive Retinopathy),M表示病理性近视(Pathologic Myopia),O 表示其他疾病(Others),对应病症数据集样图如图1所示。

图1 标签对应病症数据集样图
为了使数据更好地适用于网络训练,本文对数据进行了预处理和图片增强操作等,具体的数据集处理流程为:原始数据集—标签重生成—划分训练验证集—调整图片大小—图片增强训练扩充。
2.1 标签重生成
数据集提供的原始标签是针对患者左右双眼,即两张图片对应一个标签,但数据集标签部分提供了左右双眼的医生诊断说明,这为我们重新生成双眼各自对应的标签、有效扩充训练集提供可靠的理论依据。当然,扩充训练集的同时也可以提高算法的识别能力,进而提高深度学习模型的泛化能力。本文采用以下的标签重生成流程。
(1)根据ODIR数据集中的专业医务人员诊断信息建立一个疾病种类—标签映射表,共有98个种类,此外还有4个无归类标签:图片质量差、图片偏位、相机曝光异常和无眼底图片,共计26张照片(可视为数据缺失,进行剔除)。疾病种类主要集中在标签O(其他疾病)上,共87种不同疾病,这87种不同疾病的关联性不大,分类识别特征不明显,故不纳入本文的数据集。
(2)分别提取左右眼单一疾病关键词,根据疾病种类-标签映射表来匹配对应的标签信息,形成对应的标签匹配表。若存在患者疾病类别数量不唯一,则需要多次匹配,以确保疾病种类与标签一一对应。
(3)合并上面的标签匹配表,形成最终的ID索引与标签信息关系。表1为各疾病种类、样本数量及比例统计表,样本总数为10536张。从患者眼底疾病相关性分布上看,正常眼数量和糖尿病视网膜病变数量位居前两位,比例分别为40.45%和24.13%。标签重生成过程是进行数据处理的不可缺少的部分,它是真正理解图片的各个类别的关键步骤。

表1 各疾病样本数量及比例统计
2.2 划分数据训练集
通常,深度学习针对给出标记数据集,通过给定训练集训练模型,检验模型拟合效果,再将模型运用于验证集中,从而给出预测的标记结果。为保证通过训练集得到的算法具有足够的泛化能力,采用设置多组随机数划分训练集。考虑到本文设计的网络框架输入的图片都是单一图片,我们随机采取每个种类的10%作为验证集,其余90%作为训练集。
2.3 图像增强
数据增强(Augmentation)是一种为了使数据更好地适应应用场景,整体对训练图片进行变换的手段[8]。通过数据增强操作,凸显我们感兴趣的信息,抑制造成干扰的那部分,增加相似图像之间的差异性,减少过拟合现象,提高网络的学习能力。本文所采用的数据增强包括形态学变换和cutout等方法。主要有以下几个步骤。
(1)将验证集中心裁剪,去除原始图像多余黑色背景,留存中间眼球图像信息,并把大小统一调整为224×224作为网络模型的输入;缩放训练集图像,按0.6~1.0比率对图片区域随机裁剪,如图2所示,并通过形态学变换随机水平翻转,丰富图像的多样性。
(2)将验证集和训练集图像转化为张量形式(Tensor)并进行归一化处理,以提升网络训练速率及提高实验精度。

图2 对缩放的图像随机裁剪
3 基于深度学习的眼底图像辅助诊断系统的设计与实现
3.1 模型选择
目前的眼底视网膜图像分类方法大多解决的是单一类别疾病,而通过疾病多分类眼底疾病辅助诊断系统的临床应用较少。针对眼底疾病多分类辅助诊断系统,现有的实现方法主要采用基于ResNet为主干网络的深度学习模型。如图3所示,50层残差神经网络由卷积层堆叠而成的残差单元、池化层以及全连接层组成。Purohit[9]设计的一种使用ResNet网络作为主干网络的多分类深层神经网络,用于分类青光眼、糖尿病视网膜病变和年龄相关性黄斑变性,最终的分类峰值准确率和平均准确率分别为91.16%和85.79%。XIE[10]提出的基于SLO图像的交叉注意力多分支神经网络眼底疾病分类,以ResNet作为主干网络提取特征信息,并使用多分支网络和交叉注意力模块,最后实现了95.47%的准确率。以上基于ResNet为主干网络的深度学习模型虽然能够实现较高的准确率,但缺点是网络参数存储量巨大,从而在部署时对存储容量的要求相当高,此外对硬件的算力也有相当高的要求,这对于卷积网络在嵌入式硬件等领域的应用产生了极大的限制。

图3 ResNet50网络结构
基于以上分析,本文采用了一种轻量化卷积神经网络模型SqueezeNet。SqueezeNet是由Iandola[11]等提出的一种轻量级网络结构,它能够在ImageNet数据集上达到AlexNet近似的效果,但是参数比AlexNet少50倍。本文分别对SqueezeNet和ResNet50进行模型保存实验,其中ResNet50占用存储空间为89.9MB,而SqueezeNet仅占用2.78MB,模型文件可比ResNet50小32倍。SqueezeNet是以较少的参数和较小的模型尺寸实现与主流的卷积神经网络模型相当甚至更高的准确率,可以降低内存的要求并提高计算速度,从而更容易部署到嵌入式平台、FPGA(Field Programmable Gate Array,现场可编程逻辑门阵列)以及ASIC(Application Specific Integrated Circuit,专用集成电路)。
轻量级网络SqueezeNet包含卷积层、池化层、Fire模块(SqueezeNet的结构主体)和softmax分类器。Fire模块使用1×1卷积配合3×3卷积进行特征提取,在模块的输入端设置了瓶颈层,可以降低输入特征图的通道数,从而降低特征提取的计算量。一个Fire模块由squeeze部分和expand部分组成,如图4所示。squeeze部分是由一组连续的1×1卷积组成,其作用就是削弱通道数,为后续卷积运算降低成本。expand部分是完成特征的提取工作,由一组连续的1×1卷积和一组连续的3×3卷积共同组成。

图4 Fire模块的示意图[12]
3.2 系统结构
本文设计的眼底图像辅助诊断系统结构如图5所示,为了判定7类状态(6种病症和1种正常),引入了7个独立的轻量化的SqueezeNet深度学习模型,分别单独训练7种二分类状态;7个SqueezeNet模型的输出汇总至“综合分析模块”,进行必要的数据整理、分析工作,并根据分析结果输出多标签病症信息。

图5 系统结构框图
深度学习的训练中,通常需要足够多的训练数据集来不断地训练模型的参数。当数据集较少而模型参数较大时则会出现过拟合现象。为了避免因训练数据集不足而导致的过拟合现象,本文在训练过程中应用迁移学习,将torchvision库中预训练的SqueezeNet权重(设置 weights='SqueezeNet1_1_Weights.DEFAULT')导入到本项目,并通过设置每个分支模型末端的分类模块来匹配本项目的二分类需求,最后在保持前端特征提取模块参数不变的情况下只需要训练分类模块。预训练好的SqueezeNet模型,是通过ImageNet数据集上的1000类物体共计120万张图像进行分类训练得到的模型,可以有效地避免过拟合并提高模型的泛化能力。
3.3 系统性能评估
3.3.1 训练与测试环境
本系统实验训练与测试环境如下:
系统为Windows 10中文版,CPU为Intel i5-8265U(4核8线程)。使用的Python版本为3.9.12,Pytorch版本为1.12.0。模型训练过程设置的参数为:损失函数设置成CrossEntropyLoss(交叉熵损失函数),优化器为SGD(随机梯度下降),学习率为0.001,动量为0.9,批处理大小为64,总迭代次数为50。
3.3.2 评估指标
医学图像分类常用的评价指标为:准确率A(Accuracy)、精确率 P(Precision)、召回率 R(Recall)和F测度(F-Measure)。F测度常用F1测度来进行评价,它的值越高表示方法越有效。具体计算公式如下。
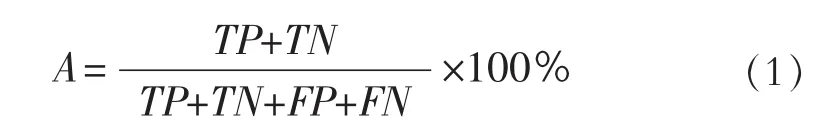

以DR二分类为例,TP(True Positive)是指属于DR样本被正确分类至DR样本的数量;TN(True Negative)是指不属于DR样本被正确分类至其他对应样本的数量;FP(False Positive)是指不属于DR样本被错误分类至 DR样本的数量;FN(False Negative)是指属于DR样本被错误分类至其他样本的数量。
3.3.3 结果与分析
从多标签疾病种类预测角度分析单一疾病,预测结果如表2所示。预测结果最好的是白内障(C)和病理性近视(M),可能是由于这两种疾病的病灶特征与其他存在明显差异。年龄相关性黄斑准确率达到了88.09%,接近文献[13]中用深度卷积神经网络(DCNN)形成的智能识别眼底图像88.4%的准确率。从准确率(A)来看,正常眼和糖尿病预测结果最差,主要因为数据中未患有该病数量较大,假设模型不具有判断能力,全部预测为负样本,那么该指标也将较接近于1,对于这两种疾病种类该指标作评价存在一定的偏差。从精确率及F1测度指标看,模型对于青光眼(G)和高血压视网膜病变(H)的病灶特征最难学习和识别,容易出现漏检。
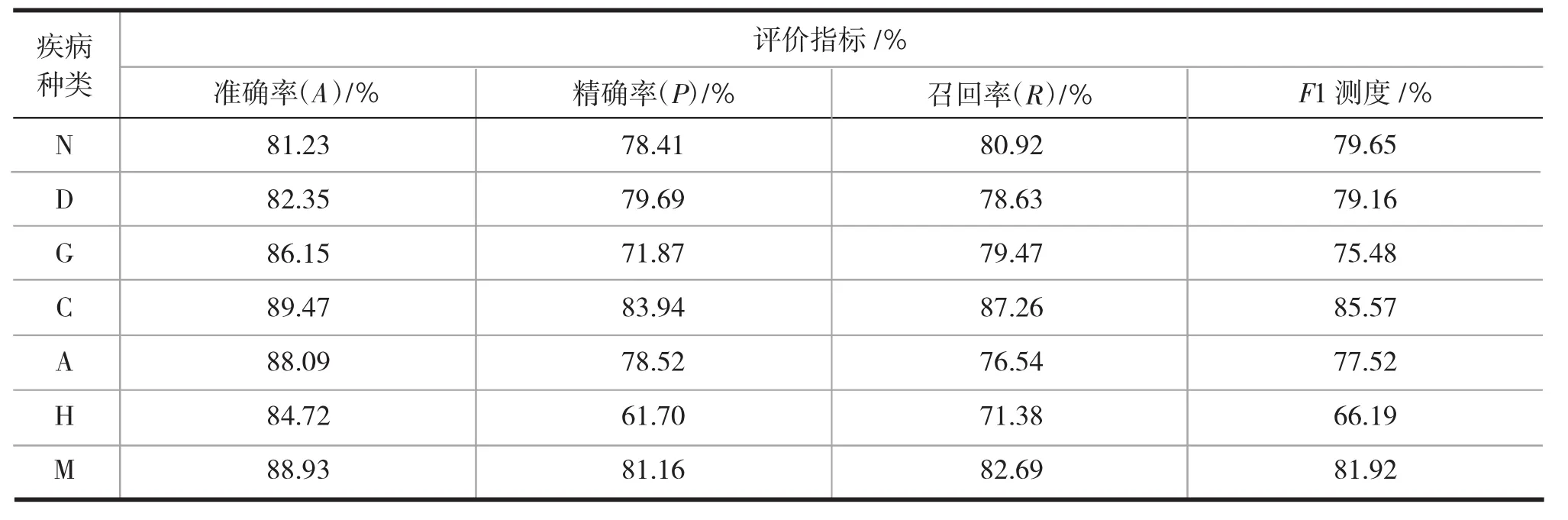
表2 多标签疾病种类预测评价指标
为验证SqueezeNet轻量级深度学习模型的运算速度,本文从单一疾病预测角度,对比了ResNet50和SqueezeNet作为主干网络的系统精度、模型参数占用量和系统运行时间,实验结果如表3所示。从数据上看,SqueezeNet与ResNet50精度相差5.4%;ResNet50占用存储空间为 89.9 MB,而SqueezeNet仅占用2.78MB,模型文件可比ResNet50小32倍;ResNet50在只使用4核CPU训练9000张图像的情况下,单个迭代的运行时间为68.22分钟,而SqueezeNet仅运行8.97分钟,速度上提高6.6倍。即在相差5.4%的精度下,SqueezeNet深度学习模型只用ResNet50模型3.09%的存储量和13.14%的运行时间。因此,在不大幅降低模型精度的前提下,相比于ResNet50模型,SqueezeNet能极大地提高运算速度、提高系统利用率。

表3 SqueezeNet与ResNet50运行指标对比
4 结语
综上所述,本文先通过重新生成ODIR数据集标签的方式得到单眼数据集,采用图片增强扩充数据集,并基于轻量化的SqueezeNet深度学习模型提出了一种实现多标签眼底图像辅助诊断系统。实验结果表明,此网络模型在六种疾病和正常眼底图像的多分类上取得了优异的分类结果,最佳单模型的准确率为89.47%,验证了SqueezeNet强大的特征提取能力;此外SqueezeNet可以在仅仅使用ResNet50模型3.09%的存储量、13.14%的运行时间,即可实现仅相差5.4%的精度,非常适合于硬件部署。本文以轻量化的深度学习模型为构建载体,设计并实现一种多分类眼底图像辅助诊断系统,该系统的模型参数量小、运算效率高、适合于硬件部署。为了提高整个系统的精度,未来可以通过多模型融入技术、引入注意力机制、引入FPGA系统板实现等方向进行优化和完善。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
铁道通信信号(2020年3期)2020-09-21
铁道通信信号(2020年8期)2020-02-06
电子制作(2019年13期)2020-01-14
铁道通信信号(2019年8期)2019-10-10
电子制作(2019年11期)2019-07-04
铁道通信信号(2019年2期)2019-03-26
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
