
基于机器学习的学生学习伙伴推荐平台设计
2023-01-11 13:23朱正月余沛文
安徽电子信息职业技术学院学报 2022年6期
吕 婷,朱正月 ,余沛文
(1.安徽电子信息职业技术学院,安徽 蚌埠 233000;2.吉林大学 软件学院,吉林 长春 130000)
1 引言
随着大数据、云计算和移动互联等技术的不断发展以及人们对教育需求的提升,以在线教育平台为主的“互联网+”教育模式得到了广泛的认可与普及。国内在线教育大学生用户规模呈快速持续扩张的趋势[1]。
在线上教育中学习者与学习者、学习者与教师之间处于时空分离的状态,容易产生寂寞、孤独、无助的情绪。若能为学习者提供合适的学习伙伴,通过协作学习则可减轻这种孤独感,并有利于提高学习兴趣、提升学习效果。因此,如何为学习者提供合适的学习伙伴,是当代教育领域的一个重要研究课题[3]。学习者对自己的学习伙伴有着个性化的选择,在网络化学习环境中,由于缺少某种合适有效的技术支持,学习者很难发现与自己兴趣或认知风格相近的学习伙伴,“独学而无友”,成为网络化教育被诟病的重要原因之一[4]。
面对海量的学习资源,个性化推荐在线教育平台大部分都是围绕着用户的特征信息进行分析和建模。例如,通过用户的学习风格、学习兴趣等特征信息构建推荐模型[1,5-6]。但这种推荐的结果往往不精准,很难令人满意,一般适用于一些简单推荐。
KNN(K-Nearest Neighbor)是机器学习中的经典算法,在特征空间k个最近邻样本中,以多数样本的类别来分类,进而找出相似度较高的同类事物,该算法运行效率较高,被广泛应用于科学和工业等领域。为此,很多学者在KNN算法应用上不断尝试,推陈出新。图像分类方面,有学者认为KNN算法是一种理想的分类器,在此基础之上,提出了基于KNN的图像自动分类模型[7];有学者针对在用户给定分类精度需求和低时间复杂度的约束下,提出的自适应加权K近邻分类法,提高了自然图像的分类性能[8]。在文本分类方面,有学者根据文本之间关系重构隶属度函数,引入粗糙集重新定义上下近似概念,定义各类文本的上下近似空间,改进传统KNN,形成基于粗糙KNN算法的加权距离隶属度算法,最终使文本分类准确率和分类效率都得到了有效提高[9]。另有学者,依据KNN分类算法和反馈学习的思想,给出基于反馈学习的中文文本分类模型和基于KNN的中文文本分类反馈学习过程,通过实验表明,KNN分类算法可以有效地改善分类效果[10]。
基于在线教育环境下学习伙伴推荐需求及KNN算法应用现状的分析,本文提出基于机器学习的学生学习伙伴推荐平台,具有一定的现实意义。
2 推荐平台的系统设计
推荐平台设计自上而下分为交互界面层、采集数据层、数据分析层、基于机器学习的推荐算法设计及数据应用层。整体的技术方案如图1所示,平台设计整体流程如图2所示。
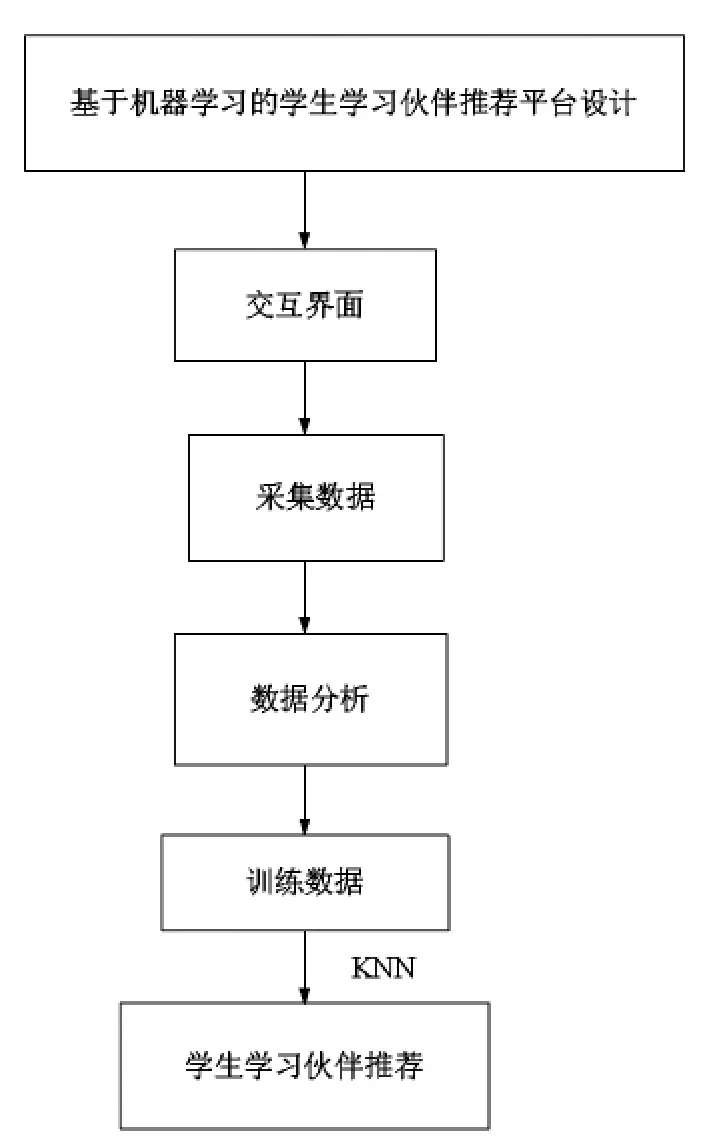
图1 整体技术方案图
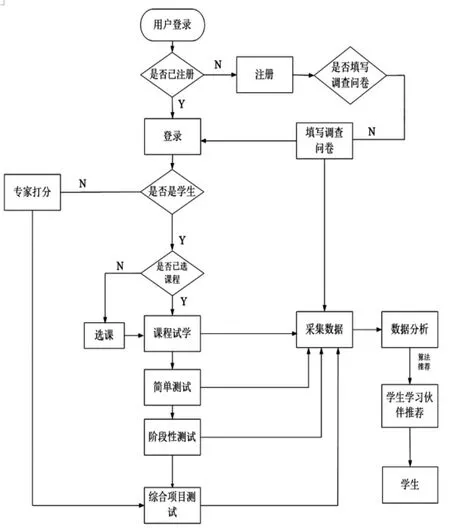
图2 平台设计整体流程图
3 采集推荐平台的数据集
为实现学生学习伙伴推荐预测分类,将分别从平台的交互界面层、数据采集层获取数据,建立丰富的数据集。
3.1 交互界面层的数据获取
交互界面层主要是填写调查问卷,问卷调查可以帮助我们自定义获取一些特殊的数据,通过获取的这些数据,我们能了解学生的兴趣爱好、学习方向及学生的基本信息,问卷调查为项目的数据分析提供了明确的导向性及可靠的数据支撑。
3.2 数据采集层
平台数据采集包括:视频资料学习数据和阶段性测试数据;基于课程的综合项目考核由专家打分数据;考查学生的综合知识运用能力、协作率、技术和知识掌握的熟练程度等数据。
4 算法设计
KNN算法是机器学习典型的算法,本研究的算法设计主要介绍KNN算法理论及应用基础和学习伙伴推荐预测分类的详细算法设计两部分内容。
4.1 KNN算法理论及应用基础
设计的KNN算法,首先是距离计算,KNN算法使用更多的是欧氏距离,以二维空间两个点的欧氏距离计算为例,公式如式(1)。

其中 ρ为(x2,y2)点与(x1,y1)点之间的欧氏距离;|x|为(x2,y2)点到原点的欧氏距离。
拓展到多维空间后,欧氏距离计算公式如式(2)。

针对k值的选取,首先k的取值要尽可能取奇数,这样才能确保最后计算结果会产生一个较多的类别;其次k取值不同得到的分类结果也会不同。为避免k取值过大或过小造成的预测误差或过拟合现象,采取交叉验证的方式,然后反复验证集合的方差,以找到一个最合适的k值,最终获得理想的分类效果。
4.2 学习伙伴推荐预测的详细算法设计
4.2.1 样本数据构建
本次平台搭建中数据分为真实数据集和模拟数据集,所有的数据集内都包括学生信息、课程基本信息以及学生学习情况。用于KNN预测的数据主要为学生学习情况数据,包括学生视频得分、作业得分、专家结合学生的平时学习表现对学生打分以及对项目进行评分组成专家评分数据。
其中模拟数据集中的数据在交叉验证一步中用来确定k值,由后台直接提供。真实数据集中的数据通过学生观看视频等交互行为,由平台统计生成。
4.2.2 机械标签生成
在学生学习情况数据的基础上,给每个学生用户打上标签,其中模拟数据集部分的标签由平台自动生成,这里称为机械标签。
标签分为四大类,分别为学习方向、学习成绩、学习习惯、学习能力。学习方向由整型数表示,不同学习方向的学生不参与后续生成真实标签操作。其他三种标签每个基于两种数据生成,学习成绩由专家打分和项目得分组成的专家评分数据生成,学习习惯由视频得分和作业得分生成,学习能力标签在学习成绩标签和学习习惯标签的基础上生成。
在进行机械标签生成操作时,因为学习成绩标签和学习习惯标签由用户数据直接生成,因此先将学生成绩分为 90~100,75~89,60~74 三档,则可生成五等A-E标签,如图3所示。学习能力标签将在成绩标签和习惯标签的基础上生成,并且同样会分成五等。

图3 A-E的标签生成图
4.2.3 交叉验证
首先后台将会生成容量为10000以内的学生模拟数据集1,给数据集1内的每个用户打上机械标签,然后生成容量为1000以内的模拟数据集2作为测试数据集。
对于数据集2,使用数据集1已经生成的标签,通过KNN算法流程,初始情况下k设定为1,对数据集2的每个用户进行标签生成操作。再直接处理数据集2为这些用户生成“准确”的机械标签,计算在不同k值下生成标签的准确率,从而确定最佳k值。
4.3 真实标签生成
真实数据部分给每个学生用户打上的标签,现在k值已知,通过KNN算法可以为每个学生用户生成各自的标签,即通过k个近邻,以最多近邻的标签为该用户标签,这里称为每个学生用户的真实标签。具体步骤是首先使用模拟数据集,对部分真实数据集进行真实标签生成操作,在足量部分数据标签生成完成后,使用该部分数据对后续真实数据进行标签生成操作。
4.4 学习伙伴推荐
基于已经生成的标签,计算每个学生之间的欧式距离,为每个学生推荐欧氏距离最近的五名同学,从而完成学生推荐操作。以学号20180645学生为例。随机抽样十名学生作为样本,通过平台采集视频得分成绩、测试得分成绩、专家评分数据,根据欧氏距离分别计算这10名学生的学习习惯标签、学习成绩标签、学习能力标签,最后计算出学号20180645学生与这10名学生的欧氏距离,找出匹配的最佳学习伙伴,如表1、表2所示。
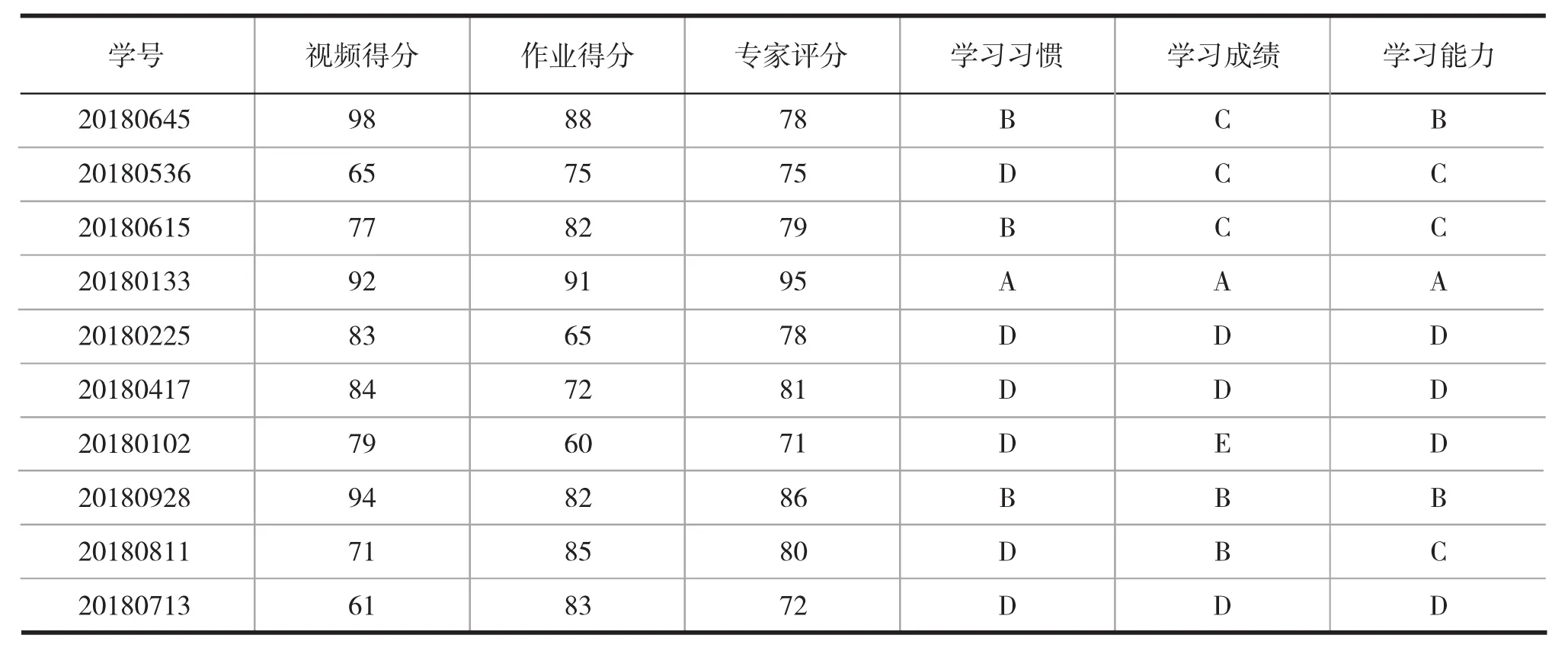
表1 随机抽样十名学生情况
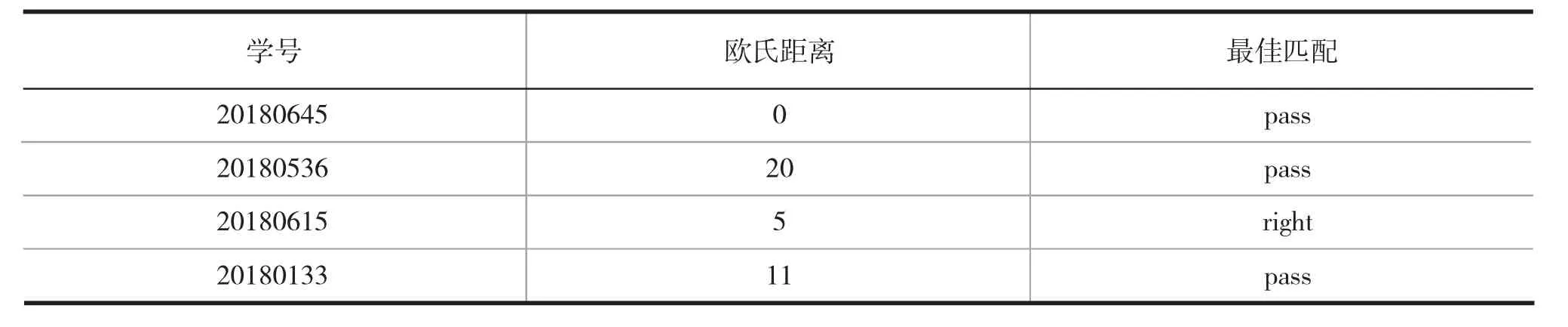
表2 与学号20180645学生匹配情况

表2 与学号20180645学生匹配情况(续)
5 结语
笔者基于机器学习的学生学习伙伴推荐平台,依托课程平台采集数据,建立数据集,分析学习者的兴趣特征和个性化的学习特征,帮助学生有效地找到学习伙伴。最后以平台随机选取十名学生,进行实验,为学生推荐学习伙伴,实验结果验证了平台预测的准确性。
猜你喜欢
数学年刊A辑(中文版)(2022年3期)2023-01-05
电讯技术(2022年3期)2022-03-27
新农村(浙江)(2021年6期)2021-07-07
海峡姐妹(2020年12期)2021-01-18
四川大学学报(自然科学版)(2020年1期)2020-01-10
作文成功之路·小学版(2019年8期)2019-09-18
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
