
基于注意力机制和多层次特征融合的目标检测算法
2023-01-08 11:29:18周秋艳肖满生范双南
湖南工业大学学报 2023年1期
周秋艳,肖满生,范双南
(1.湖南工业大学 计算机学院,湖南 株洲 412007;2.湖南交通工程学院 电气与信息工程学院,湖南 衡阳 421001)
1 研究背景
目标检测是指从图像中获取感兴趣的目标,确定每个目标的准确位置和类别,并在图像上进行标注。近年来随着目标检测的快速发展,该技术被广泛应用于智能驾驶、医学图像诊断、行人检测和航天航空等领域[1-3]。
基于手工特征提取的传统检测算法主要包括以下步骤:图像预处理、窗口滑动、特征提取和特征数据处理、分类器分类[4]。这些算法在特征提取阶段常用的视觉特征有Harr 特征[5]、HOG 特征[6]、SIFT(scale-invariant feature transform)特征[7]等,但这些特征被用于识别特定的任务时往往存在一些缺陷。如依靠人工的先验知识设计特征提取器,缺乏一定客观性,因此对多样性目标的检测鲁棒性差,在复杂场景下很难取得较好的效果,检测精度和速度较低。近年随着深度学习的迅速发展,许多学者利用深度卷积神经网络(convolutional neural networks,CNN)进行特征提取,该模型的泛化能力较强,目标检测精度和速度得到了较大提升。目前主流的目标检测算法主要分为单阶段和两阶段两种策略,基于候选框的两阶段方法如R-CNN(region-based convolutional neural networks)[8]、Faster RCNN[9]、Cascade RCNN[10]等,其实现过程为:先对感兴趣的区域进行候选框获取,而后利用CNN 网络生成对应的特征图,对候选框进行分类识别和边框回归,完成目标检测,此类方法检测精度较高,但实时性不强。而基于回归的单阶段方法如SSD(single shot multibox detector)[11]和YOLO(you only look once)[12]等,此类方法利用CNN 网络直接预测目标的类别与位置,无需获取候选框,检测的实时性较强,但精度不高。针对这些问题,专家学者提出了许多基于深度学习框架模型以改善目标检测效果,对于不同尺度的目标需要不同大小感受野的特征去识别,而神经网络的高层特征中包含了丰富的语义信息,因此许多方法是通过增加网络层数来获得语义信息更强的高层特征图,从而提升网络性能,但随着卷积层数增加,图像经过大量特征处理后,目标的位置信息变弱。高层特征图的语义信息较强、分辨率较低,而低层特征图的分辨率较高、语义信息较弱,同时相邻层级的特征图间的相关性在此过程中会愈加弱化,导致分类和回归的精度不高。针对这些问题,一系列典型的多尺度特征融合模块被提出,如特征金字塔网络(feature pyramid network,FPN)[13]、神经结构搜索特征金字塔网络(neural architecture Search Feature Pyramid Network,NAS-FPN)[14],以及许多运用了多尺度特征融合方法的网络:如PANet(path aggregation network)[15]、HRNet(high-resolution representation learning for human pose estimation)[16]。Tan M.X.等[17]提出了一种加权双向特征金字塔网络(bi-directional feature pyramid network,Bi-FPN)实现快速的多尺度特征融合。Cao J.X.等[18]通过整合注意力引导的多路径特征,利用了来自各种大感受野的判别信息,提出注意力引导的上下文特征金字塔网络。Xing H.J.等[19]提出了基于双重注意力机制的特征金字塔网络,改善了小目标检测效果,Hu J.等[20]对通道之间的相互依赖性进行建模以自适应地重新校准通道特征响应,提出了SENet(squeeze and excitation networks),极大改善了网络性能。
受上述思想启发,本文提出了一种基于注意力机制和多层次特征融合的目标检测算法,能够有效提高目标检测精度,主要贡献如下:
1)设计了简单的注意力模块(simple attention module,SAM),并将其应用于主干网络,对网络通道关系进行建模以增强网络的表征能力;
2)针对检测中的多尺度问题及网络中不同分辨率的特征对网络性能提升贡献的不同,本文设计了基于深度可分离卷积的多层次特征融合模块(multi-layer feature fusion module,MFFM),对多尺度特征进行融合,在保证效率的情况下丰富了特征信息,同时引入可学习的权重,获取不同输入特征的重要性程度,以更好地平衡不同尺度的特征信息。
2 目标检测算法
2.1 简单的注意力模块
注意力机制是在全局信息中获得需要关注的部分的一种方式。本文融合了SAM,利用通道注意力机制整合特征图来选择性地强调互相关联通道的重要性,增强包含更多关键信息的特征,并抑制无关或较弱关联的特征,以平衡不同通道之间的特征信息。其结构如图1 所示。如图1 所示,SAM 结构主要作用在残差模块的分支,将残差结构的输出作为它的输入,H、W分别表示输入特征图的高和宽,C表示通道数,即输入特征图大小为H×W×C。通过全局平均池化将特征图压缩为1×1×C的向量,将全局空间信息压缩到通道描述子中,使其具有全局的感受野来对通道维度上的特征相关性进行建模。经过1×1 卷积将特征通道数调整为输入通道数的1/r,r为缩放比例,通过实验得出r取16 比较合适(详见3.4 节),可以实现准确度和计算复杂度之间的良好平衡。对压缩了通道数的特征图经ReLU 激活,使其具有学习通道间的非线性交互能力,再通过一个1×1 卷积恢复通道数,最后以Sigmoid 函数进行归一化处理,获得0~1 之间的权重,通过Scale 操作将每个通道赋予权重值。其中涉及的理论过程推导如式(1)所示。
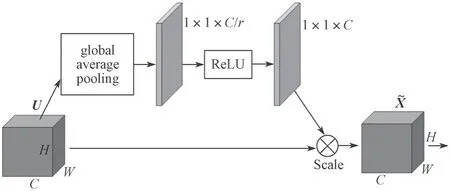
图1 SAM 结构Fig.1 SAM structure

SAM 完成了通道相关性的构建,自适应地为不同通道学习到不同的通道注意力权重,让网络专注于有更多贡献的通道,增强判别能力。
2.2 多层次特征融合模块
在目标检测网络中,深层特征语义信息强但分辨率低,浅层特征分辨率高但语义信息弱[21-22],本文融合了不同分辨率的特征,利用深层特征图中含有目标丰富的语义信息和浅层特征图的局部位置信息来提高网络的性能,解决多尺度问题。
经过主干网络自底向上路径特征提取输出的5层特征图中,每层最后一个残差块输出的特征图为P1~P5,由于P1语义信息较弱、分辨率过大不利于计算,因此采用P2~P5作为加权特征融合网络的输入,用1×1 的卷积核对原始特征横向连接,统一修正特征图的通道数为256,进而进行自顶向下与复用的低层特征进行第一次融合,第一次只对P3和P4特征图做此操作,得到过渡特征集合。此时过渡特征中高层的特征信息较低层特征来说更弱,底层特征分辨率高,包含了更多小目标检测的细节信息,因此对过渡特征进行二次融合。采用1×1 的卷积核对过渡特征图进行横向连接,对每层特征图利用下采样操作使其与更高一层特征图具有相同尺寸。再将低层特征自底向上与复用的高层特征融合,由于P2特征图包含更多空间位置信息,因此将P2参与二次融合,与过渡特征图P3融合,P5特征图含有丰富的语义信息,也参与二次融合中。这种对同一层的原始输入特征直接连接到输出特征参与自底向上特征融合的做法能够充分利用高层特征的强语义信息和底层特征的空间位置信息,最终得到输出特征,送入RPN 网络进行后续处理,MFFM 结构如图2 所示。

图2 MFFM 结构Fig.2 MFFM structure
为了降低其复杂度,本文利用深度可分离卷积代替3×3 普通卷积,深度可分离卷积通过两次卷积操作实现,先分别对通道同时进行3×3 卷积,批量正则化后,通过1×1 逐点卷积,较之普通卷积,参数量大大减少。此外,不同的输入特征具有不同的分辨率,通常它们对输出特征所作出的贡献有所不同[23],因此引入权重让网络学习每个输入特征的重要性,更好地平衡不同尺度的特征信息。权重计算如式(3)所示:式中:wi(wi≥0)为可学习权重,用ReLU 函数将权重归一化,表示每个输入特征的重要性程度;ε为一个很小的值,设置为0.000 1,避免数值不稳定;L为计算的权重结果值。
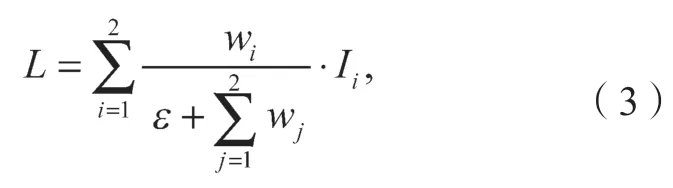
以两个特征图融合为例进行说明,如式(4)(5)所示。
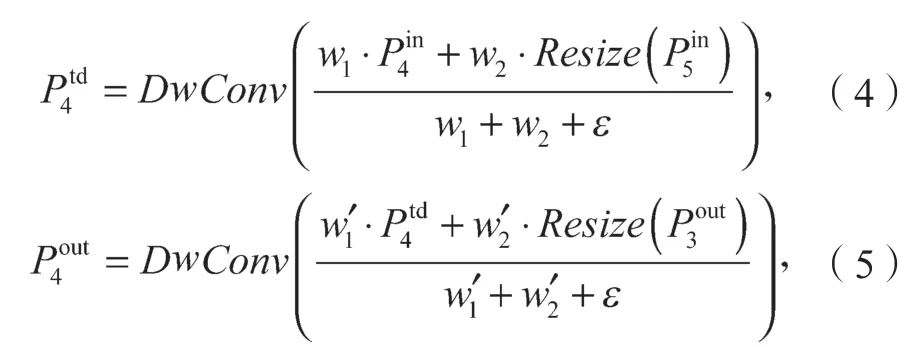
式(4)(5)中:为第4 层的输入特征值;为自顶向下路径上第4 层的过渡特征值,为便于区分同一层上不同类型的特征,本文采用上标in、td、out区分该层的输出特征、过渡特征、输出特征;为自底向上路径上第4 层的输出特征;Resize为用于分辨率匹配的上采样或下采样;DwConv为用于特征处理的深度可分离卷积操作。
2.3 分类网络
经过特征融合的特征图通过3×3 的卷积运算去除混叠效应后送到RPN 网络。RPN 网络的详细介绍见文献[9],图3 所示为RPN 网络结构图。首先,在特征图上初步提取检测目标候选区域,本文采用4 种不同尺度面积{642,1282,2562,5122}、3 种不同长宽比{1 ∶2,1 ∶1,2 ∶1}生成12 种不同大小的anchor,进行1×1 卷积,输出24 维的向量,输入到Softmax 进行二分类。其次,RPN 对分类后舍弃背景的anchor 进行边界框回归操作,得到检测目标的一系列候选区域。需要将这些候选区域映射到原图中,由于得到的候选区域大小不同,本文采用ROI Align方法获得固定尺寸的特征图,通过全连接和Softmax激活函数,并结合边界框回归进行精确地分类识别和回归定位,获得检测目标所属类别的概率和边框的准确位置。
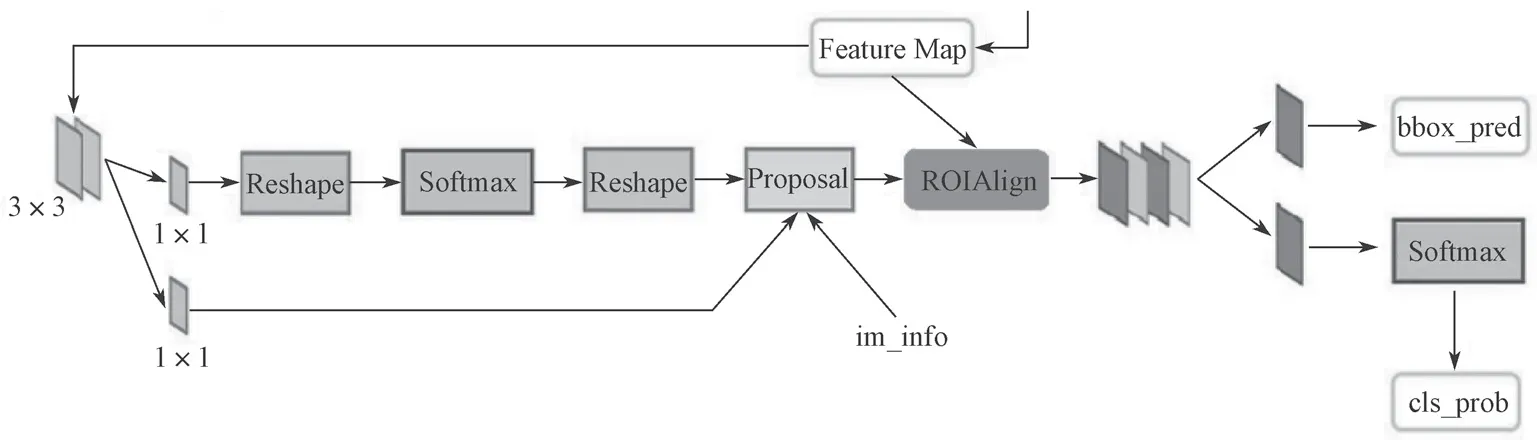
图3 RPN 网络结构图Fig.3 RPN network structure
2.4 目标检测算法模型
前面设计了SAM 和MFFM 结构,本文基于此,提出了基于注意力机制和多层次特征融合的目标检测算法,整体框架如图4 所示。

图4 目标检测模型框架图Fig.4 Target detection model frame diagram
如图4 所示,其基于Cascade RCNN 改进,采用ResNet50 作为主干网络,利用SAM,旨在通过它能使网络执行动态通道特征重新校准以提高网络的表征能力,从通道维度方面提高目标检测精度。将原始图像输入主干网络完成图像特征提取,具体改进工作和实现细节详见2.1 节。其次,本文设计了MFFM,将主干网络提取到的不同层次特征图进行多尺度融合,实现语义特征和位置特征的有效融合,得到融合后的特征图,具体的多尺度特征融合思想和实现细节详见2.2 节。最后利用改进的RPN 网络[24]在特征图上获取包含面积种类更多的区域建议,利用ROI Align 方法进行特征映射,用softmax 进行分类和边框回归,其实现过程详见2.3 节。至此完成目标检测,得到含有目标类别、目标框和置信度的图像。
3 实验和结果分析
3.1 数据集和实验环境
本实验使用2 个数据集,一个是图像分类和目标检测中常用的标准数据集PASCAL VOC 2012,在实验过程中将其xml 标签文件转换为json 格式,该数据集中共有11 540 张已标注好的图像数据和27 450个目标物体,其中训练集含有5 717 张图像数据,测试集有5 823 张,数据集中包含行人、汽车、狗、雨伞等20 个类别。另一个数据集是针对深度学习技术在医学图像诊断领域的应用,收集了胃肠道息肉图像数据(GP Images)。胃肠道息肉是常见的消化系统疾病,可发生于胃肠道内多个部位,会随着病情的发展出现癌变的情况,因此及时诊断发现胃肠道息肉非常重要。本文采用改进后的目标检测算法对采集到的胃肠道息肉图像进行检测和识别,协助医护人员准确捕捉到胃肠道息肉的精确位置。此数据集共有1 000 张标注好的图像数据,包含一个类别:polyp。本实验运行环境配置:操作系统Ubuntu 16.04,显卡GeForce RTX 2080Ti,2.50 GHz CPU,CUDA 版 本10.2,基于Pytorch 框架和Python 编程语言实现。
3.2 评价指标
为了验证本文所提算法的性能,选用目标检测任务中的平均精度AP(average precision)作为本文算法的评价指标,其中涉及到的精度p(precision)和召回率r(recall)的计算公式如式(6)所示,以检测结果框与真实框的交并比(IOU)来判定正负样本。
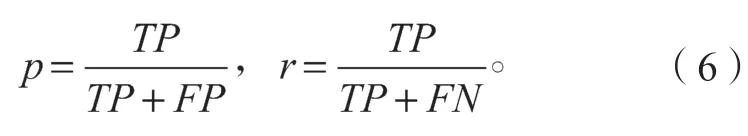
式中:TP为被模型预测为正类的正样本数;FP为被预测为正类的负样本数;FN为被预测为负类的正样本数。
平均精度AP则为PR曲线下的面积,计算公式如式(7)所示。
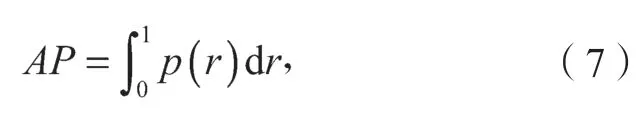
式中p(r)为以r为参数的函数。
实验中涉及的AP(平均值)、AP50、AP75分别表示当IOU 为0.50:0.95,0.50,0.75 时的AP值,APS、APM、APL分别表示像素面积小于322,322~962,962的目标框AP值。
3.3 数据预处理
在进行目标检测时不仅要改善网络模型结构,往往还需关注数据集的质量,可对数据集进行数据增强,即对输入图像的像素点的分布、值的大小进行一些根本性的变换,同时保证图像的标签数据与之对应。本文采用在线数据增强技术中常用的随机翻转,本质上目标本身类别在翻转后未发生改变,但能增加数据集的多样性,训练过程中先对每个批次的训练数据进行数据增强,设置随机翻转概率flip_ratio=0.5,即每张图像有0.5 的概率进行翻转操作,如图5 所示为训练集中图像数据进行翻转后的部分图像,通过对图像数据进行变换可以得到泛化能力更强的网络,能一定程度上避免网络训练过拟合的情况。

图5 PASCAL VOC 2012 数据增强图像Fig.5 PASCAL VOC 2012 data image enhancement
针对胃肠道息肉数据集难以找到充足数据的问题,本文采用一些离线数据增强方法对数据集进行处理,如旋转、亮度调整、平移变换、裁剪、镜像变换。如图6 所示为部分训练集图像原图和经过离线数据增强后的图像效果,以此增加了训练样本的数量、丰富了训练数据的分布,能够提升模型的鲁棒性。
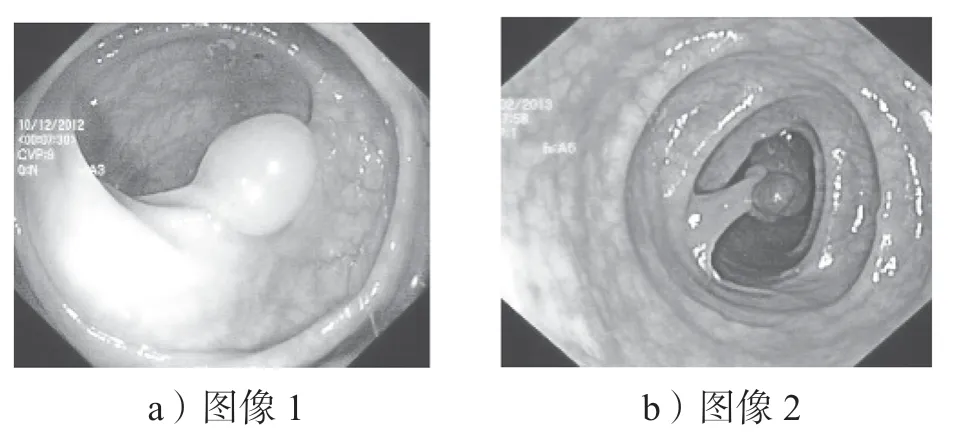
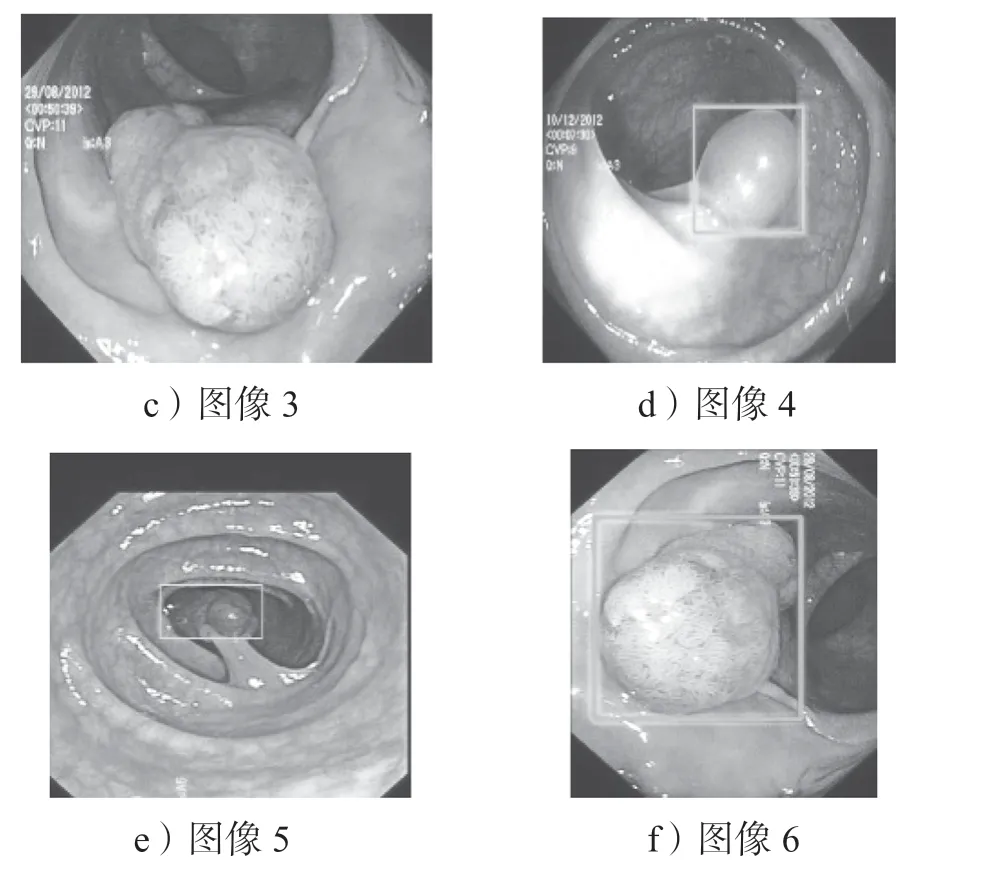
图6 GP Images 数据增强图像Fig.6 Images data image enhancement
3.4 实验结果分析
网络训练时,设置初始学习率为0.002 5,权重衰减系数为0.000 1,优化动量参数为0.9。且训练时RPN 网络中IoU(intersection over union)阈值选为0.7 和0.3 来区分正负样本,测试时采用SoftNMS 对区域建议进行分支预测,设置阈值为0.7。为了对本文提出的检测算法的有效性进行评估,选取目标检测领域中常用的几种经典检测算法:YOLOv3、SSD、CornerNet、faster RCNN 和Cascade RCNN,其中包含了单阶段和两阶段的方法,将其与本文提出的算法在相同的实验环境下进行训练和测试。基于所给出的评价指标,对实验结果进行对比和分析,如表1 所示。
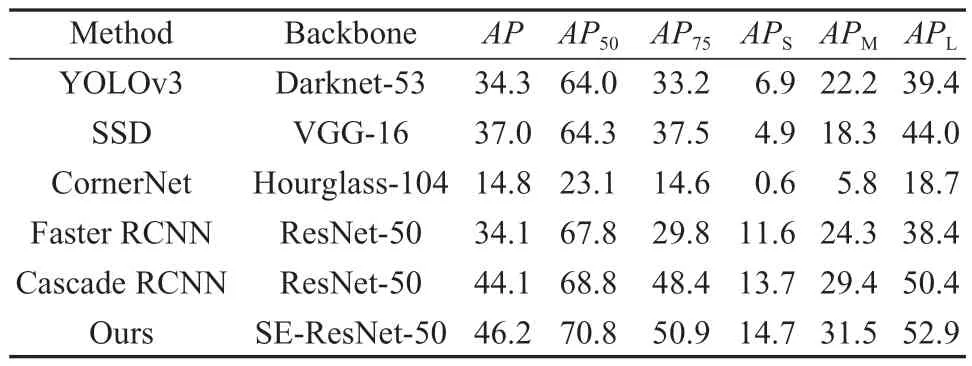
表1 不同算法在PASCAL VOC 2012 的性能比较Table 1 Performance comparison of different algorithms on PASCAL VOC 2012
对比不同IoU 阈值对应的平均精度和目标框不同像素面积对应的平均精度,可以看出,本文提出的方法明显优于其他检测算法。相较于Cascade RCNN,分别在AP、AP50、AP75得到了2.1%,2.0%,2.5%的提升,对不同像素面积的目标检测精度APS、APM、APL也分别提升了1.0%,2.1%,2.5%,实验证明,该方法可有效提升目标检测精度。对于数据集的20 个类别,进一步比较了不同算法在每个类别上的平均精度AP,结果如图7 所示。
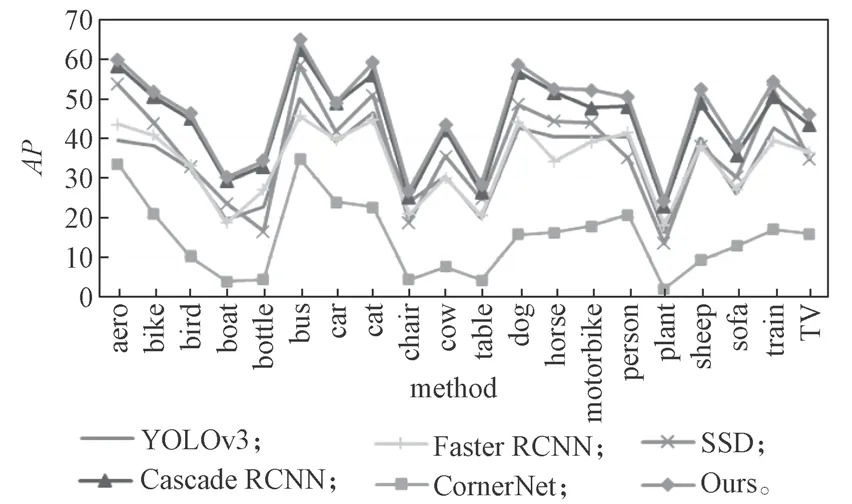
图7 不同算法在PASCAL VOC 2012 数据集上的检测结果Fig.7 Detection results of different algorithms on Pascal VOC 2012 dataset
图7 中数据表明,相较于其他目标检测算法,本文提出的基于注意力机制和多层次特征融合的检测方法,在精度上有显著提升,该方法在每个类别上的平均精度都优于其他方法,证明了该方法的有效性。
除了和目标检测方法中经典算法相比之外,本文还选取了近年来采用其它注意力机制和特征融合方式的算法,在PASCAL VOC 2012 数据集上训练和测试,并将测试结果与本文提出的算法进行比较,结果见表2。表中PANet、HRNet、NAS-FPN 采用了其它多尺度特征融合方法,DANet、ACNet 中则是引入了其它注意力机制方法。由表可知本文提出算法与上述算法相比,检测精度都有所提升。其中HRNet、ACNet 在APS上的检测结果分别为14.9%,14.8%,虽然本文提出的算法在APS上略低,但在AP、AP50、AP75、APM、APL上的检测结果远优于其它算法,总体上本文的算法能够实现较好的检测效果。
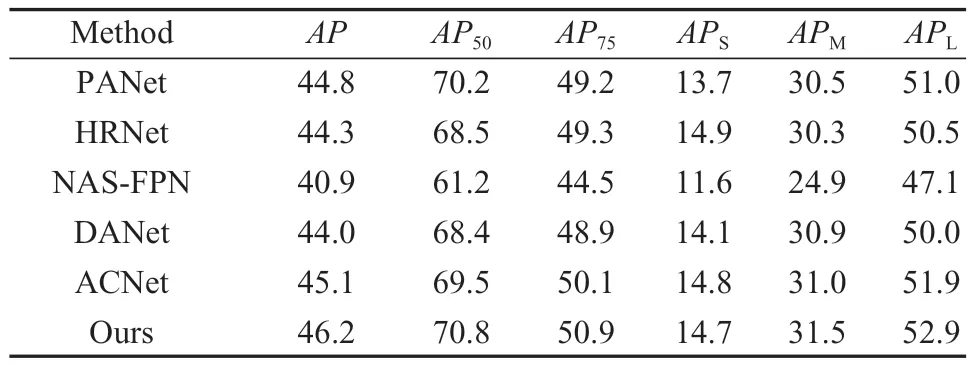
表2 相似算法在PASCAL VOC 2012 上的性能比较Table 2 Performance comparison of similarity algorithms on PASCAL VOC 2012
为了验证本文所提出的方法中各个模块对检测性能的优化作用,分别对SAM 和MFFM 的有效性进行评估,并基于相同的实验环境和参数配置,在PASCAL VOC 2012 数据集上进行消融实验,分析实验结果。具体实验方案如下:1)在模型中单独验证SAM;2)在模型中单独验证MFFM;3)在模型中同时验证SAM 和MFFM。
消融实验的数据结果如表3 所示,本文提出的方法是在Cascade RCNN 模型的基础上进行改进,因此相较于表1 中未添加SAM 和MFFM 的Cascade RCNN 的检测结果,单独添加通道注意力模块后的模型在AP50、AP75上分别得到0.7%,0.8%的提升,单独添加了多层次特征融合方法的模型在AP、AP50、AP75上分别得到0.2%,1.0%,0.8%的提升,当SAM和WFFM 都运用到模型中时,精度的提升效果最明显,实验结果表明使用SAM 和MFFM 能够有效提升模型检测精度。
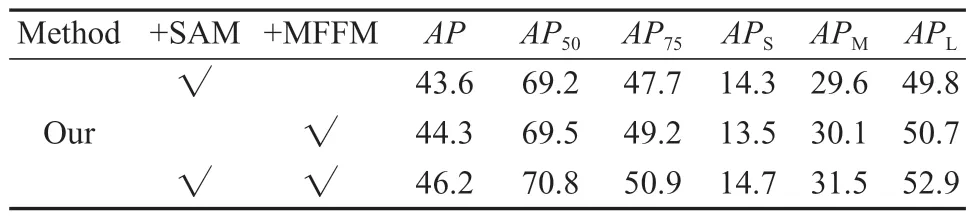
表3 在PASCAL VOC 2012 数据集上的消融实验结果Table 3 Ablation experimental results on PASCAL VOC 2012 dataset
对于GP Images 数据集经过同样的策略训练和测试,表4 给出了不同像素面积的目标检测精度。表4中实验数据表明,相较于Cascade RCNN,本文提出的算法在AP、AP50、AP75上分别提升了5.8%,1.5%,1.1%,能够实现较好的检测效果。
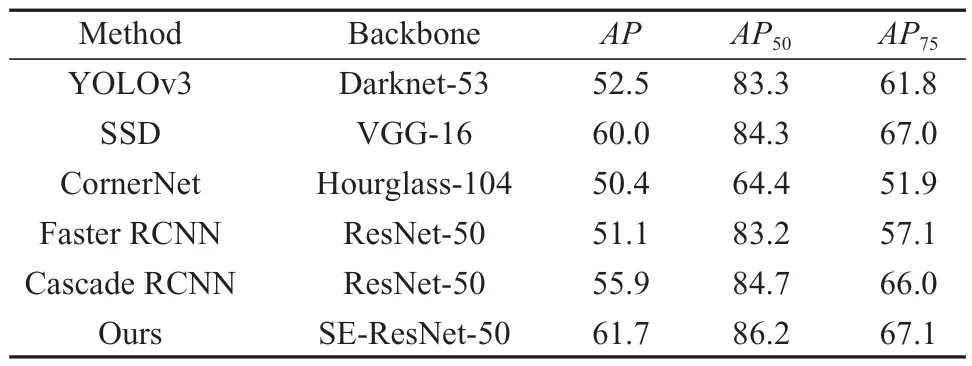
表4 不同算法在GP Images 上的性能比较Table 4 Performance comparison of different algorithms on GP Images
为了验证对GP Images 数据集采取数据增强策略的作用,本文将所提出的模型在原GP Images 数据集和采取了数据增强策略的GP Images 数据集上分别进行训练和测试,以不同像素面积的检测精度作为评价指标,实验结果如表5 所示。由表中数据可知,采取了数据增强策略得到的检测效果有一定的提升,在AP和AP75上分别提升了3.4%和0.8%,对网络模型的检测精度具有优化作用。

表5 数据增强策略在GP Images 上的性能对比Table 5 Performance comparison of data enhancement strategies on GP Images
最后,对2.1 节简单的注意力模块(SAM)中涉及的缩放比例r的取值进行实验验证,本实验在Cascade RCNN 模型中添加SAM,且r的取值分别为4,8,16,32,在GP Images 数据集上经过训练测试,实验结果如表6 所示。由表可知,当r=16 时,模型在精度和速度方面较好平衡,故本文r取16。

表6 不同缩放比例r 对模型性能的影响Table 6 Effects of different scaling ratios r on model performance
4 结语
本文提出了基于注意力机制和多层次特征融合的目标检测算法,通过在主干网络中融合SAM,利用通道注意力机制有选择的突出作用性更强的通道特征信息,从而提高网络的判别能力;其次,本文针对目标检测算法中的多尺度问题,改进了FPN,结合深度可分离卷积,设计了MFFM,充分融合深层特征丰富的全局语义信息和浅层特征的局部空间位置信息,使网络提取的特征更具表征能力,并为不同层次的特征引入权重,更好地平衡不同尺度的特征信息。实验结果表明,本文提出的算法在一定程度上大大提高了目标检测精度,改善了检测效果。接下来将进一步优化模型,致力于在保持精度的同时提升网络的效率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
电子制作(2018年11期)2018-08-04 03:25:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
电视技术(2014年19期)2014-03-11 15:38:20
