
基于轻量化网络和注意力机制的智能车快速目标识别方法
2023-01-05 11:33陈志军胡军楠冷姚钱闯吴超仲
交通运输系统工程与信息 2022年6期
陈志军,胡军楠,冷姚,钱闯,吴超仲
(武汉理工大学,智能交通系统研究中心,武汉 430063)
0 引言
智能车在提高行车安全、减轻驾驶员负担方面具有重要作用,并有助于节能环保和提高交通效率,是实现智能交通的关键载体[1]。在复杂行驶环境下,准确高效的实时感知能力可为智能车提供可靠的环境信息,对保障车辆安全性和稳定性至关重要[2]。
在智能车感知领域,主要采用基于深度学习的目标检测方法。经典算法如YOLOv3(You Only Look Once v3)[3]、Faster RCNN (Faster Region Convolution Neural Network)[4]等,国内外学者根据智能车的感知需求对检测算法做了一系列改进,Possatti等[5]将交通灯数据集进行样本增强,同时将感知算法与智能车使用的先验地图相结合,实现对真实场景交通灯的准确识别。Mohd-Isa等[6]通过在YOLOv3框架中集成空间金字塔池化,进一步识别真实环境中的远小交通标志。邵毅明等[7]通过动态路由协议对物体的实例化参数进行表达和传递,保留了各特征对象间的空间层级关系,提高了智能车对道路环境中行人目标检测的准确率。由于智能车对感知实时性要求较高,上述算法网络模型较大,且难以平衡检测速度与精度,无法满足智能车实时感知的需求。近年来,学术界和工业界将研究重点放在感知算法轻量化上,结合轻量化网络改进的目标识别网络在节省计算资源方面效果显著,经典轻量化模型包括MobileNet[8]和ShuffleNet[9]等,MobileNet 提出了深度分离卷积,并使用逐点卷积进行通道间信息融合来实现模型压缩,ShuffleNet利用逐点群卷积和通道混洗实现了参数量的降低。Deng 等[10]采用MobileNetv3 作为特征提取块,利用YOLOv4[11]作为分支来检测车辆和车道线,适用于跟车场景的车辆和车道线多任务实时检测模型。史宝岱等[12]采用特征拼接的方式多支路并行,并将通道注意力机制与深度可分离卷积结合,实现了对道路图像的快速检测。张凡[13]针对现有交通标志检测与识别网络检测速度慢的问题,采用压缩激励模块,提出基于轻量化多尺度特征融合的交通标志识别方法。Chen 等[14]在Tiny-YOLOv3 的网络层结构上进行裁剪,提升了智能车在道路环境中的检测速度,但损失了检测精度。现有智能车轻量化感知方法大多从模型压缩的角度出发,未考虑图像特征之间的关联和冗余性,且存在检测精度下降的问题。
针对这些问题,本文兼顾算法检测速度和准确性需求,提出一种基于GhostNet[15]的智能车轻量化目标识别方法。为了降低YOLOv4 算法特征提取过程中图像参数的冗余计算和提高推理速度,使用改进后的GhostNet 网络替换YOLOv4 原始的主干特征提取网络,改变模型的卷积计算方式,使网络参数计算量显著降低;智能车主要关注复杂行驶环境中的车辆和行人等信息,且轻量化网络会造成精度损失,采用结合软阈值化改进的CBAM(Convolutional Block Attention Module)注意力模块[16]使算法获取到更多的关键特征;最终在保证检测精度的同时满足智能车的实时检测需求。
1 基于改进注意力机制的GhostNet轻量化网络
1.1 GhostNet网络模型
GhostNet 是一种基于MobileNet[8]模型改进的轻量化网络结构,通过计算量更小的操作来生成常规特征提取方法中的冗余特征图,避免大量的卷积计算,从而在不影响模型精度的情况下减少模型的计算复杂度。GhostNet 的思想是将传统的卷积分成两步[15]:第1 步使用1×1 卷积核生成输入特征层的特征浓缩,第2步对生成的特征图使用计算量较低的逐层卷积获得另一半特征图,最后将两组特征图拼接在一起,得到与传统卷积层同等特征表达能力的相似特征图。Ghost卷积与传统卷积的计算参数量对比为

式中:m为输入通道数;h为输入特征图高度;w为输入特征图宽度;n为输出通道数;h′为输出特征图高度;w′为输出特征图宽度;k×k为卷积核的尺寸;s为Ghost 特征图的个数,且s远小于m,则理论参数压缩比约等于Ghost 特征图的个数s,因此Ghost 卷积极大减少了网络参数计算量。式(1)分子表示Ghost 卷积的参数量,分母表示传统卷积的参数量。
1.2 基于软阈值化注意力机制改进GhostNet轻量化网络
利用GhostNet 对特征提取网络进行轻量化改进后计算参数显著减少,但由于特征稀疏的影响,会导致部分精度损失。通过加入注意力机制获得需要重点关注的目标区域,相比于原始特征提取方式,注意力机制在仅增加少量计算参数的情况下,获取到目标更多的关键特征,从而提高检测准确率。
本文结合软阈值化机理对CBAM 注意力机制[16]做出改进。在计算机视觉领域,由于图像信息中存在噪声冗余,通过软阈值函数可实现降噪处理,利用神经网络自动选取阈值从而削弱冗余特征对识别任务的影响,避免了阈值难以选取的问题。将软阈值化与注意力机制结合,针对特征的重要程度自适应设置不同的阈值,同时可通过注意力机制进行自动阈值调整,从而实现对图像关键特征的强化和对冗余特征的抑制。软阈值函数和其偏导公式为

式中:x为输入特征;y为输出特征;τ为阈值。通过注意力机制生成的权重系数自动调整阈值,当输入特征大于阈值时对特征进行收缩;当输入特征小于阈值时,视为冗余噪声,将特征置为0。软阈值化函数的导数只为0 或1,可以有效防止梯度的消失与爆炸问题。
在CBAM 注意力机制中,输入特征依次经过通道注意力模块和空间注意力模块进行强化。其中,通道注意力模块的特点是保持通道维度不变,压缩空间维度,主要关注目标的种类信息;空间注意力模块的特点是保持空间维度不变,压缩通道维度,主要关注目标的位置信息。将从通道注意力机制和空间注意力机制提取的特征依次进行软阈值化处理,利用软阈值化函数改进的CBAM 注意力机制网络结构如图1所示,通道注意力模块和空间注意力模块的具体结构如图2 所示。通道注意力首先沿着空间维度将输入进行最大池化和平均池化;然后利用共享的全连接层对两者进行处理,通道数先调整为原来的1/8,再恢复到原来的通道数,实现特征转换和信息重组;对获取到的新特征进行相加和激活,得到最终的输出。空间注意力首先沿着通道维度将输入进行最大池化和平均池化,并将两者进行堆叠;然后进行卷积和激活,得到最终的输出。
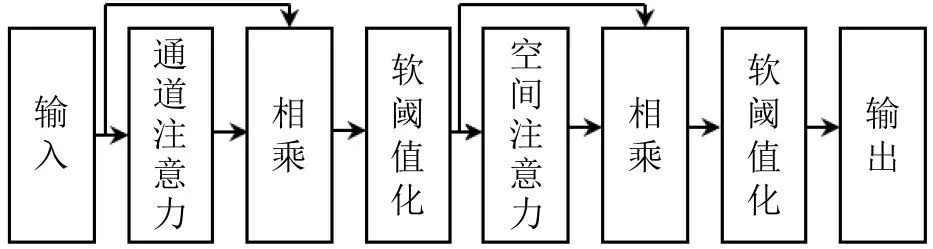
图1 结合软阈值化的CBAM模块网络结构Fig.1 CBAM module network structure combined with soft thresholding
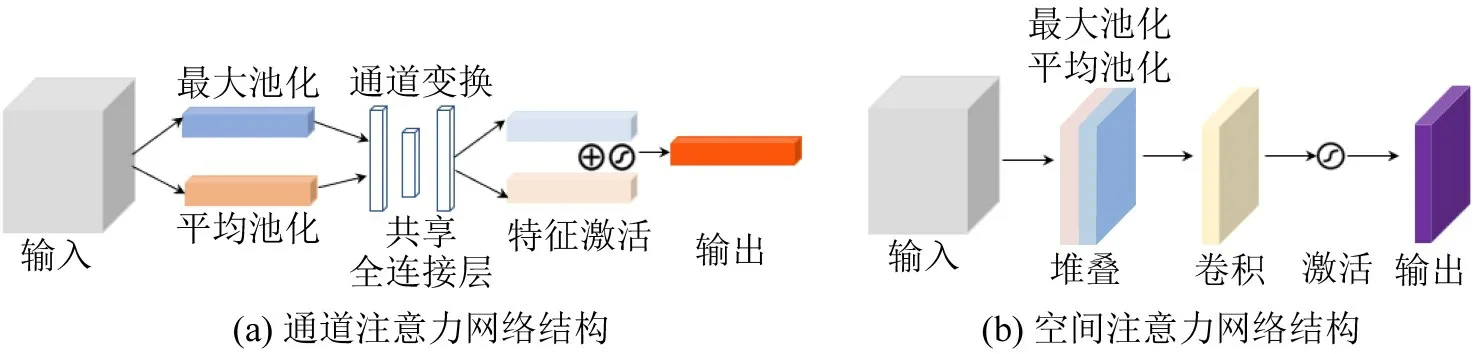
图2 通道注意力和空间注意力结构Fig.2 Channel attention and spatial attention specific structures
将结合软阈值化改进的CBAM 注意力模块SCBAM (Soft-threshold Convolutional Block Attention Module)嵌入到GhostNet 中,SCBAM 模块的部署位置如图3所示,通过在GhostNet中应用注意力机制,实现了在降低计算参数的情况下提取到更多关键特征。
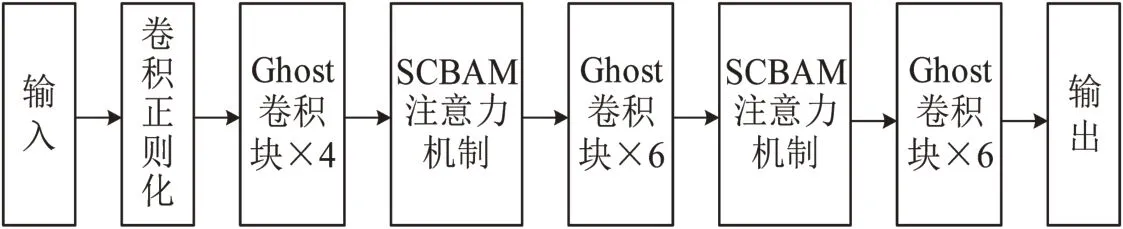
图3 改进GhostNet整体结构Fig.3 Improve overall structure of GhostNet
2 基于轻量化网络和注意力机制的智能车快速目标识别网络
本文选用YOLOv4[11]算法进行改进,结合GhostNet 和注意力机制提出一种智能车轻量化目标识别方法,整体结构如图4所示。
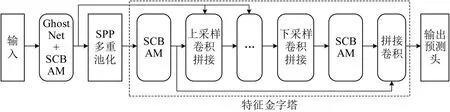
图4 改进YOLOv4整体网络结构Fig.4 Improve overall network structure of YOLOv4
使用改进后的GhostNet 轻量化网络替代YOLOv4的原始特征提取网络,在不影响提取特征的情况下,实现算法的轻量化目标。输入特征首先经过常规卷积、正则化和激活函数,保留足量特征;然后,经过多个Ghost 模块实现轻量化的特征提取。SPP(Spatial Pyramid Pooling)多重池化代表将从GhostNet输出的特征进行多尺度最大池化,然后将特征拼接后输入到特征金字塔部分。上采样卷积拼接和下采样卷积拼接代表特征金字塔中的一些特定模块,将这些模块通过不同的级联方式进行连接,获得不同尺寸的预测头输出,从而实现对不同大小目标的精确识别。
结合GhostNet轻量化网络和SCABAM注意力机制改进后的YOLOv4 算法具体结构如图5 所示。使用GhostNet 作为YOLOv4 新的特征提取网络,同时将SCBAM注意力模块添加在GhostNet的第4层和第6层,获取到更多图像特征;将GhostNet的第6、7、8三层分别输入到特征金字塔网络PANet(Path Aggregation Network)和SPP 多重池化结构中。SPP 结构中包括4 种尺度的最大池化,池化核大小分别是1×1、5×5、9×9和13×13,这种结构可以有效增加感受野,从而分离出最显著的目标上下文信息。
在特征金字塔PANet部分,添加了深度可分离卷积和结合软阈值化改进的注意力模块,即SCBAM。 通过深度可分离卷积(Depthwise Separable Convolution)进一步降低网络计算参数,深度可分离卷积在MobileNet[8]中首次提出,极大降低了模型的参数量,适合部署于计算资源有限的设备中。特征金字塔PANet 的核心思想是对特征进行反复提取,将PANet的特征从上到下视为一、二、三共3层。从GhostNet主干网络第6层输出的特征视为第一层,其经过卷积和来自PANet中第二层上采样的特征拼接之后,再在后面叠加SCBAM注意力模块,最终输出一个YoloHead预测头,预测框尺寸大小为76×76;从GhostNet 主干网络第7 层输出的特征视为第二层,其经过卷积和来自第三层上采样的特征拼接之后,再将特征叠加第一层下采样的特征,经过拼接和深度可分离卷积后输出一个YoloHead 预测头,此预测框尺寸大小为38×38;从SPP多重池化输出的特征首先进行拼接和卷积,视为第三层,然后在其后添加一个SCBAM注意力模块,然后将其与来自第二层下采样的特征进行拼接,经过深度可分离卷积后输出YoloHead预测头,此预测框尺寸大小为19×19。最终,得到3 种尺寸大小的预测框,从而可以对图像中不同大小的目标进行有效预测。算法整体的输入特征、提取的关键特征和输出特征参数如表1 所示,其中特征的3 个维度代表长度、宽度和通道数,输出特征里的通道数k随数据集中的目标种类数而变化。

表1 DwGhost-SCBAM-YOLOv4算法关键参数Table 1 Key parameter setting of DwGhost-SCBAM-YOLOv4
为解决YOLOv4 模型在轻量化后准确率损失的问题,在模型的特征金字塔层添加4 个SCBAM注意力模块,由于特征在经过拼接或采样处理后不够突出,因此主要将4 个SCBAM 注意力机制添加到经过拼接的特征层后和上下采样处理的特征层后,具体位置如图5所示。对特征金字塔提取的特征进行多次注意力机制强化,使输入到预测层的特征更聚合,增强预测层的特征表达能力,最终实现算法检测速度和精度的提升。
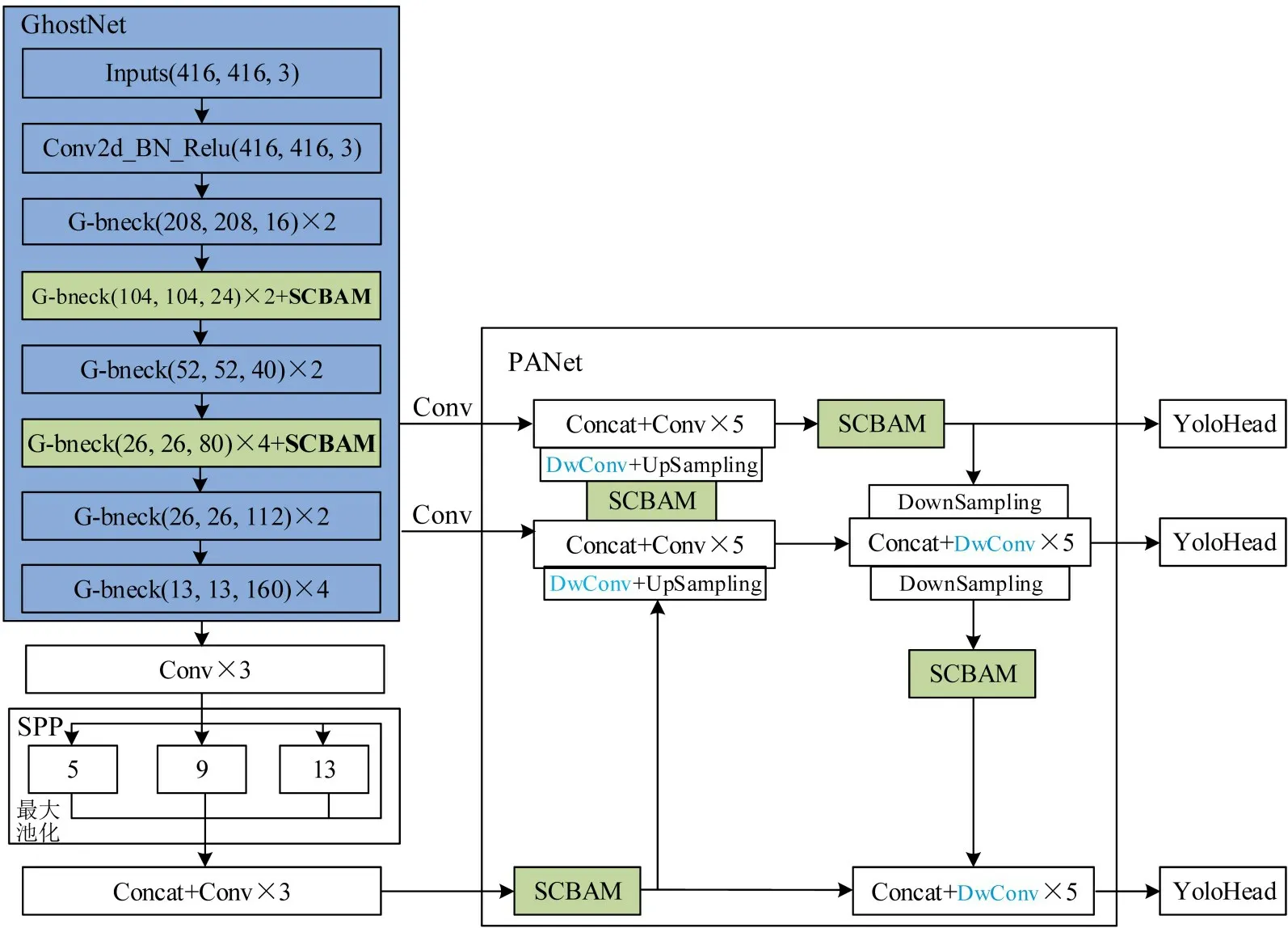
图5 DwGhost-SCBAM-YOLOv4算法具体结构Fig.5 Specific structure of DwGhost-SCBAM-YOLOv4 algorithm
3 实验与分析
3.1 数据集和实验平台
本文选择公开数据集PASCAL VOC2007、KITTI 和自制武汉市城市道路实车实验数据集用于训练测试。VOC2007 数据集共包含21504 张带标签的图片,分为20个种类,每张图片内的目标特征区分度明显;KITTI数据集是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集,包含7481张带标签的图片,本文对数据集中的汽车、卡车、行人和自行车进行训练与识别;自制城市道路实车实验数据集采集于夜晚武汉市的城市道路,包含3000张图片,标签包含汽车、行人和大巴车这3 类。3 个数据集采用相同的比例划分方法,训练集和测试集的划分比例为9∶1,并在后期实验中使用K 折交叉验证和多种比例划分方法测试算法的稳定性,数据集部分图片如图6所示。

图6 3个数据集部分样本图像Fig.6 Partial sample images of three data sets
本文算法训练过程使用的显卡为NVIDIA GeForce RTX 3080,显存大小为10 GB,CPU 型号为Intel Core i7-10700KF,所使用的深度学习框架版本为Pytorch1.2-GPU,Cuda 版本为11.1;在RTX3080显卡上进行训练时,算法训练的初始学习率为0.01,采用余弦退火技术对学习率进行动态调整;优化器采用SGD随机梯度下降方法,算法共训练150个epoch,BatchSize设置为8。
3.2 实验结果
对算法性能进行测试和对比:首先,将原始YOLOv4 算法、使用原始GhostNet 轻量化改进的Ghost-YOLOv4 和引入注意力机制的轻量化DwGhost-SCBAM-YOLOv4 算法进行对比;然后,将本文的DwGhost-SCBAM-YOLOv4 算法与业界主流目标检测算法进行对比。
实验主要从算法检测速度和精度方面对各项指标进行对比。使用的评价指标包括平均准确率mAP(mean Average Precision)和对数平均误检率lamr(log average miss rate),其中lamr代表对数平均漏检率,其定义为检测错误正样本的数量与图片中全部正样本的比例,经过对数平均调整后,可体现算法对负样本的特征抑制和对正样本持续稳定的筛选能力,体现了算法的检测稳定性;在检测速度方面,使用平均单张图片的处理时间FPS(Frames Per Second)和模型权重大小作为评价指标。在VOC2007数据集、KITTI数据集和自制夜晚城市道路数据集上对本文所采用的优化方法和原始方法进行评估和对比,结果如表2所示。
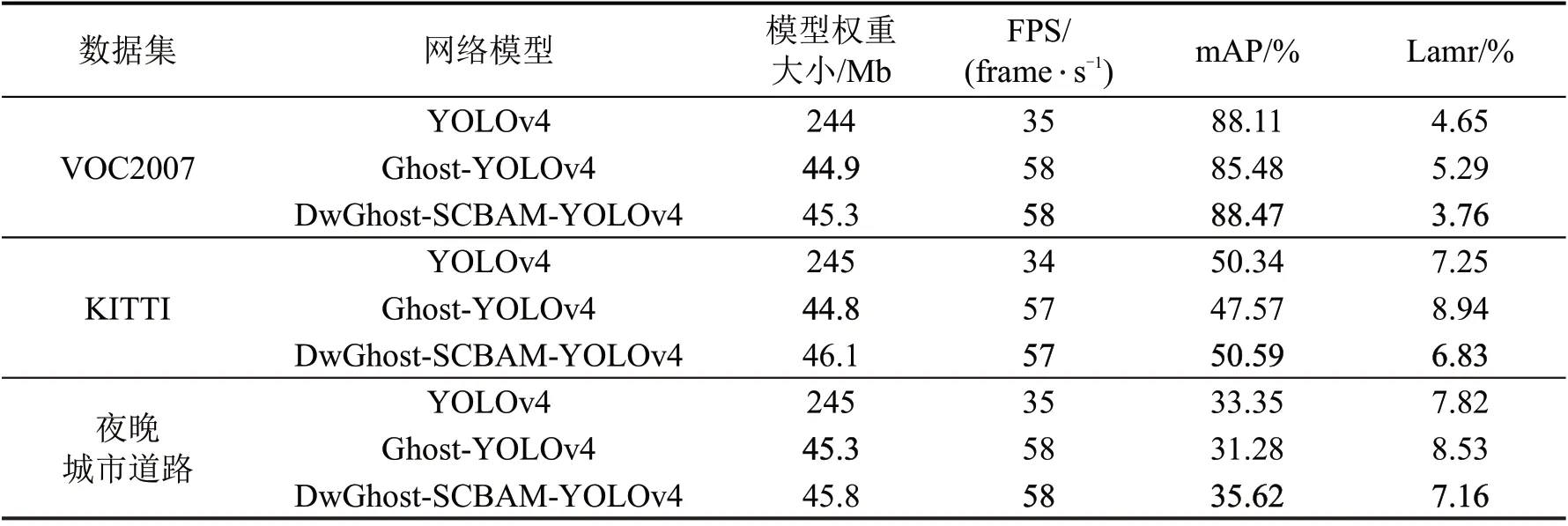
表2 本文方法与原始YOLOv4方法在各数据集上的性能对比Table 2 Performance comparison between this method and original YOLOv4 method on each data set
由表2 可知,在不增加注意力机制的情况下,Ghost-YOLOv4算法的模型权重在3个数据集上平均降低到18.4%,检测速度FPS平均增加了66%,显著提升了算法检测速度,但是检测精度有所下降。添加SCBAM注意力机制和深度可分离卷积后,提出的DwGhost-SCBAM-YOLOv4方法平均检测准确度相比Ghost-YOLOv4 增加6.3%,相比原始YOLOv4 增加1.7%,且算法的稳定性指标lamr 也有所优化,同时模型大小降低到18.7%,检测速度FPS 增加了66%,在保证精度的情况下,实现了算法的轻量化目标。在VOC 和KITTI 公开数据集上的检测效果优于原始YOLOv4 方法和数据集官方指标,3个数据集具体的检测准确率如图7所示,图像检测效果对比如图8所示。
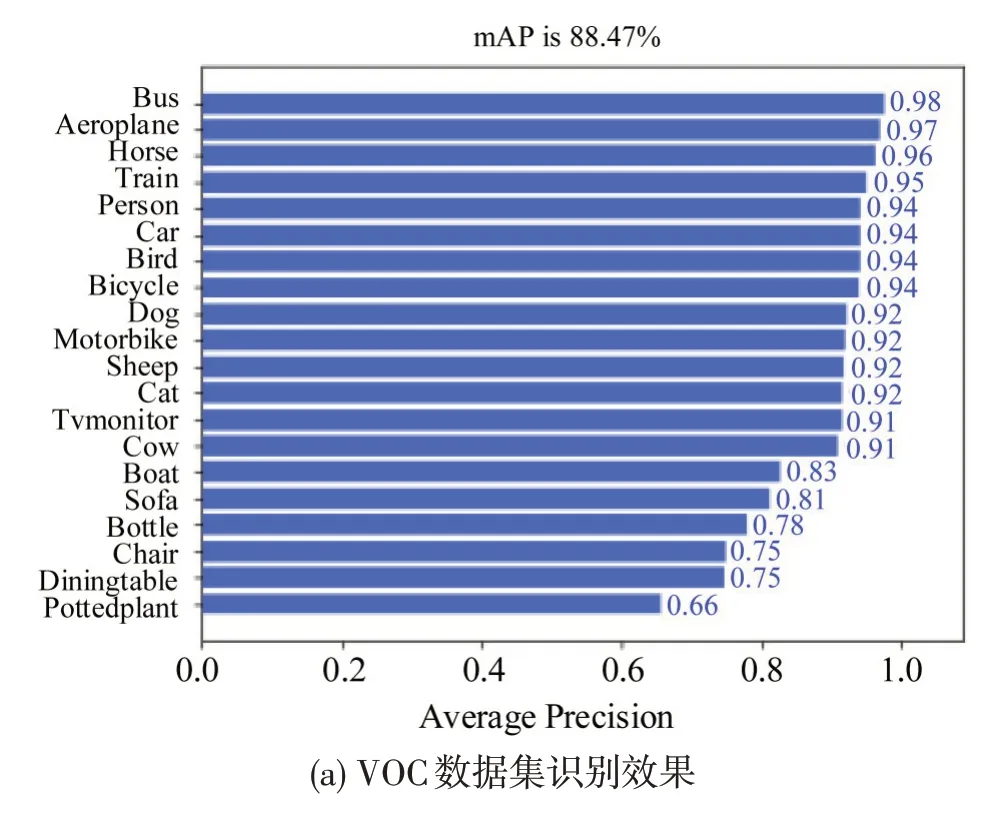
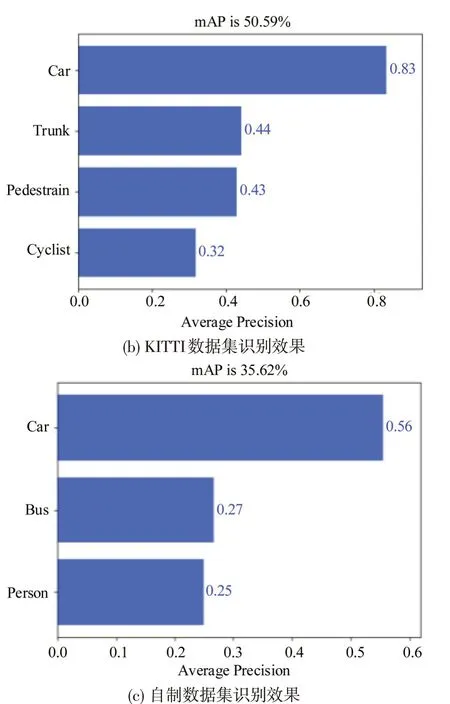
图7 不同数据集检测准确率Fig.7 Detection accuracy of different data sets

图8 算法检测效果对比Fig.8 Comparison of algorithm detection effect
在图7 中,本文提出的DwGhost-SCBAM-YOLOv4 算法在VOC 数据集上的平均检测准确率达到88.47%,其中,汽车、大巴、火车和行人等常见交通目标的检测准确率均在90%以上;在KITTI数据集上进行检测,汽车的检测准确率达到83%;在自制夜晚城市道路数据集上进行检测,由于黑暗环境下目标特征难以提取,汽车的检测准确率为56%,仍优于大部分专为黑夜环境设计的车辆检测方法,证明了本文方法在检测精度上的有效性。
为进一步验证本文方法在检测速度和精度上的有效性,选取目前主流的目标检测算法进行对比,其中主流常规检测算法包括Faster Rcnn[4]、SSD[17]和YOLOv3[3],轻量化目标检测算法包括MobileNet[8]、ShuffleNet[9]和YOLOv5s。将这些算法在VOC 数据集和相同软硬件环境下进行训练,训练集和测试集的比例为9∶1,结果对比如表3所示,不同算法检测速度对比如图9所示。

图9 不同算法检测速度对比Fig.9 Comparison of detection speed of different algorithms
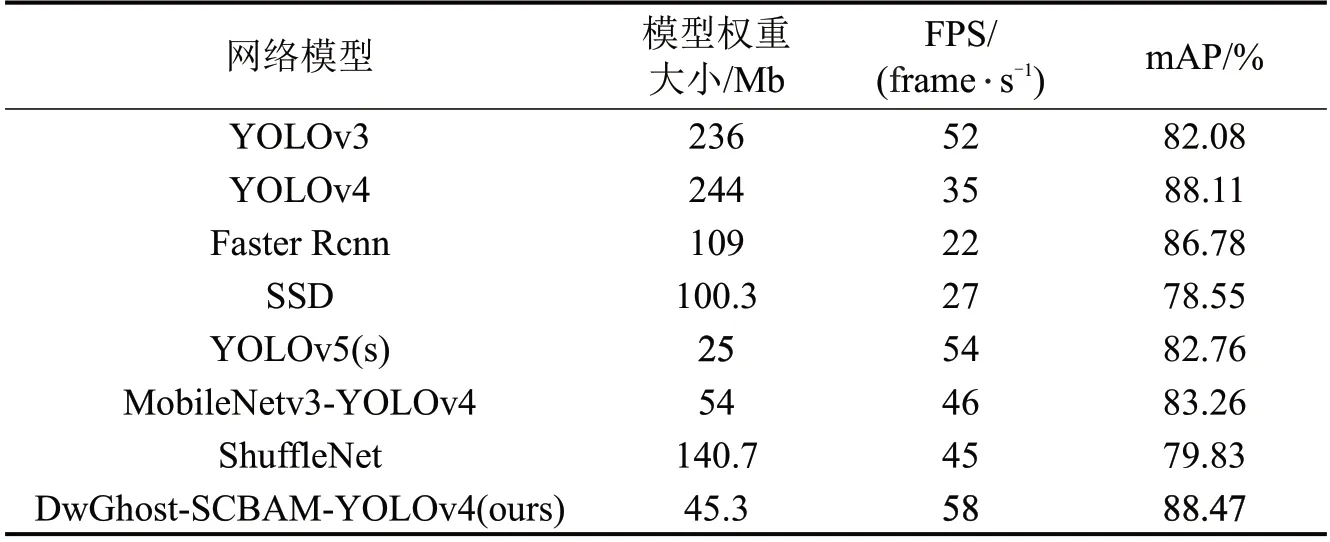
表3 本文方法与其他目标检测算法性能对比Table 3 Performance of this method is compared with other target detection algorithms
由表3可知,本文算法模型大小是YOLOv3和YOLOv4 的1/5,是Faster Rcnn 和SSD 的1/2,是ShuffleNet 的1/3,小于MobileNetv3-YOLOv4,仅比YOLOv5最轻量化的s模型略大;在检测速度方面,仅YOLOv3 与YOLOv5s 可接近本文方法,但这两者检测精度较低,相比于Faster Rcnn 等其他算法,本文方法在检测速度方面具有较大优势;在VOC数据集上的检测精度对比显示,本文方法仍优于其他目标检测算法。证明了所提出方法的有效性,兼顾了检测速度与精度,能够满足目标实时检测需求。
为验证算法的稳定性和泛化能力,采用10 折交叉验证,数据集按照8∶2 和7∶3 划分训练集和测试集的保留法进行验证。本文10折交叉验证使用云服务器GPU并行实验,在3个数据集上对改进后的DwGhost-SCBAM-YOLOv4算法进行测试,结果如表4所示。表4中,最佳mAP和最低mAP分别代表在10折交叉验证中表现最佳一轮和最差一轮的算法准确率,平均mAP 代表10 次训练结果的准确率平均值,由3个数据集的10折平均mAP可看出:算法的平均准确率与单独一次训练测试的准确率基本相同,证明算法训练未出现过拟合;当训练集和测试集划分比例为8∶2和7∶3时算法准确率与划分比例为9∶1 时基本相同,说明算法鲁棒性强,检测效果稳定。

表4 交叉验证与多种比例划分后的DwGhost-SCBAM-YOLOv4算法准确率Table 4 Accuracy of DwGhost-SCBAM-YOLOv4 algorithm after cross-validation and multi-scale partition
4 结论
本文提出一种基于轻量化网络和注意力机制的智能车快速目标识别方法。为了提高算法速度引入GhostNet 轻量化模型替换YOLOv4 的主干特征提取网络;为了提高算法精度在GhostNet和特征金字塔部分加入结合软阈值化改进的SCBAM 注意力机制。为验证所提方法的有效性,本文选取公开数据集VOC、KITTI和自制城市道路数据集进行算法测试。实验结果表明:本文方法相比原方法使算法模型大小降低到18.7%,检测速度增加了66%,同时检测精度提升了1.7%;对算法进行交叉验证和数据集的多种比例划分实验,结果证明算法检测效果稳定;与其他主流目标检测算法相比,本文方法在检测速度和精度上均优于其他算法。证明了优化后的算法能够在保证检测准确率的情况下显著提升检测速度,满足智能车的实时感知需求。
猜你喜欢
汽车实用技术(2022年11期)2022-06-20
建材发展导向(2021年19期)2021-12-06
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
临床骨科杂志(2020年1期)2020-12-12
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
专用汽车(2016年1期)2016-03-01
