
基于ResNet和HOA模型的面部表情识别方法研究*
2023-01-04 09:39王海涛孙新领王佳辉特列吾别克哈哈尔曼
河南工学院学报 2022年6期
王海涛,孙新领,王佳辉,特列吾别克·哈哈尔曼
(1.河南工学院 工程技术教育中心,河南 新乡 453003;2.河南工学院 计算机科学与技术学院,河南 新乡 453003;3.哈密职业技术学院,新疆 哈密 839000)
0 引言
面部表情是人类内心情感的外在表现,在物理上表现为脸部肌肉的不同形态,根据不同的形态可以把人类的面部表情分为愤怒、蔑视、厌恶、恐惧、高兴、悲伤、惊喜等不同类别[1]。面部表情识别作为人机交互和非语言交际的有效方式之一,在情感感知领域有着广泛的应用前景。比如,安全驾驶中的驾驶人状态分析、犯罪嫌疑人心理活动分析、学生课堂状态分析以及教师课堂授课状态分析等。
近年来,深度学习在计算机视觉领域展现出强大的性能,而卷积神经网络作为深度学习的代表算法之一,能够从图像中提取有效的特征信息,被越来越多的研究者应用于面部表情识别[2]。但卷积神经网络关注的是图像的全局特征,而面部表情往往通过脸部局部肌肉的变化来反映,因此使用卷积神经网络进行面部表情关键区域特征的提取还不是十分理想。注意力机制是视觉注意力的一种形式,它使卷积神经网络可以选择性地处理视野内某个区域的视觉信息[3]。但注意力机制是一阶的,只能挖掘简单和粗糙的信息,无法捕获关键区域的相互影响以及由各种视点或姿态引起的面部表情之间的细微差异。亢洁等人提出了基于域适应卷积神经网络的人脸表情识别方法(MMD)[4],该方法引入软注意力机制解决特征的重标定问题,同时利用预适应方法最大程度减少领域差异性来解决缺少训练数据的问题。王倩露等人提取了一种结构化特征融合的面部表情识别方法(SFF)[5],特征提取采用结构化融合的方法,目的是将局部形状特征与局部纹理特征有效结合,提取到更多、更详细的表情特征信息。褚晶辉等人提出了一种基于通道和空间注意力(CSACNN)的11层卷积神经网络[6],通过通道和空间注意力模型对特征图元素进行加强或抑制。
基于上述研究,本文提出了一种残差神经网络(Residual Neural Network, ResNet)与高阶注意力模型(High-Order Attention, HOA)结合的面部表情的识别方法:
(1)通过HOA机制对CNN提取的特征进行建模,以便捕获更多不同关键区域之间相互影响的复杂信息和图像之间的细微差异。
(2)应用残差学习单元使注意力模型获得特征图的梯度流,在保证模型容量的前提下有效缓解过拟合问题。
1 ResNet结合HOA的面部表情识别方法
面部表情识别的关键是寻找表情变化突出的表情特征区域[7]。注意力机制是被广泛认为有助于解决这类问题的方法,而一阶注意力模型主要包含空间和通道注意力,提取到的特征信息比较粗糙,不够丰富,因此通过构造高阶表征的注意力模型可以捕获面部表情中特征间的细微差别和面部关键区域之间的相互影响。
1.1 一阶注意力机制模型
在卷积神经网络中,通常使用注意力机制来调整网络的权重,用以突出显示图像的关键区域,并抑制噪声部分。具体来说,将卷积神经网络的输出张量记为X,则有X∈RC×H×W,其中C表示输入图像的通道数,H表示输入图像的高度,W表示输入图像的宽度。注意力机制在卷积神经网络中的作用是对卷积输出进行降维处理,因此可以将这个过程描述为[8]:
Y=A(X)·X
(1)
式中,A(X)表示注意力模块的输出,·表示矩阵的哈达玛积。
基于式(1),A(X)可以有不同的表现形式。例如:如果A(X)=rep[M]|C,M∈RH×W,则公式(1)表示为空间注意力模型,rep[M]|C是指沿通道尺寸将该空间掩模M扩充C倍;如果A(X)=rep[V]|H·W,C∈RC,则公式(1)表示为通道注意力模型,rep[V]|H·W是指将这个特征向量沿着高和宽的方向分别扩充H倍和W倍。图1为一阶注意力机制模型结构图[7]。
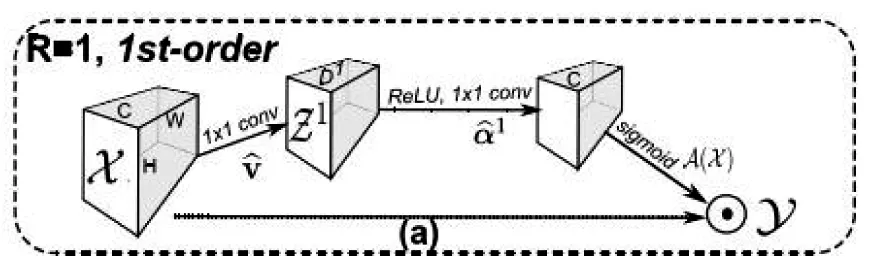
图1 一阶注意力机制模型结构图
尽管这个注意力机制可以突出关键区域的特征,但却不能反映各个关键区域之间的相互影响和高阶关系,因此,本文提出了高阶注意力模型。
1.2 HOA模型
考虑到HOA内部变量的交互和建立模型的复杂性,首先在x的高阶统计量上定义一个线性多项式预测器,公式如下所示[9]:
(2)
式中,x∈RC,〈,〉表示两个相同大小尺寸张量的内积,R表示阶数,⊗rx表示x的r阶向量积,wr表示要学习的权重。进一步分解,wf可以近似表示为:
(3)
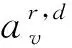
(4)
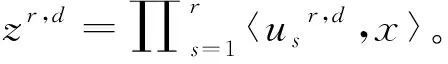
(5)
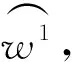
(6)
当r>1时,合并公式(6)的两项,可以得到:
(7)
在公式(7)中,a(x)是能够建模并使用局部描述符x的高阶统计量,因此可以通过在公式(7)上使用Sigmoid激活函数来获得高阶向量非线性映射,即:
A(X)=sigmoid(a(x))
(8)
此外,为了进一步改善高阶注意力机制的性能,引入ReLU激活函数[9],即:
(9)
共享不同位置空间A(X)的权重值,则有:A(X)={A(x(1,1)),…A(x(H,w))},结合公式 (1)Y=A(X)·X即为得到的HOA模型。图2为高阶注意力机制的网络结构图[7]。
此外,通过残差神经网络融合高阶注意力机制来获得更丰富的特征和更好的梯度流,在保证模型容量的前提下有效缓解过拟合问题[10]。图3为ResNet结合HOA网络结构图。
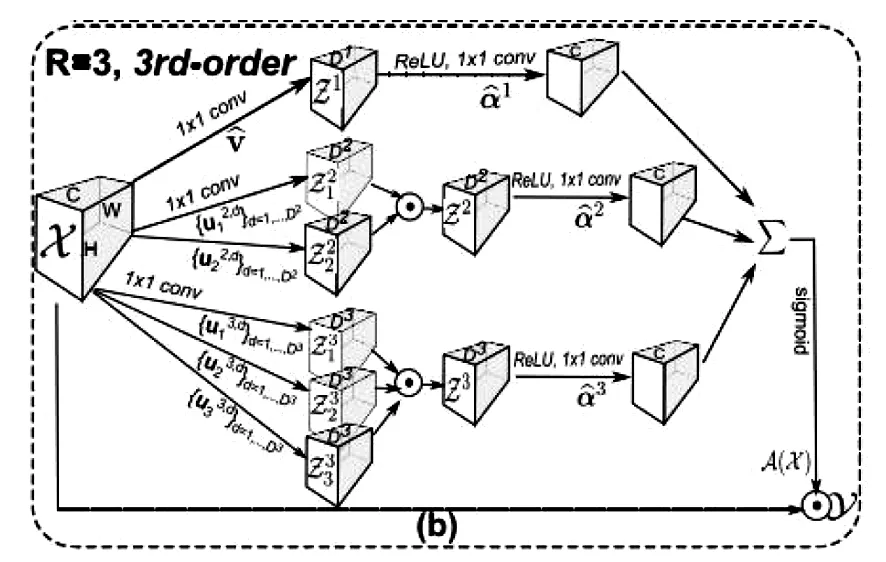
图2 HOA高阶注意力机制的网络结构图
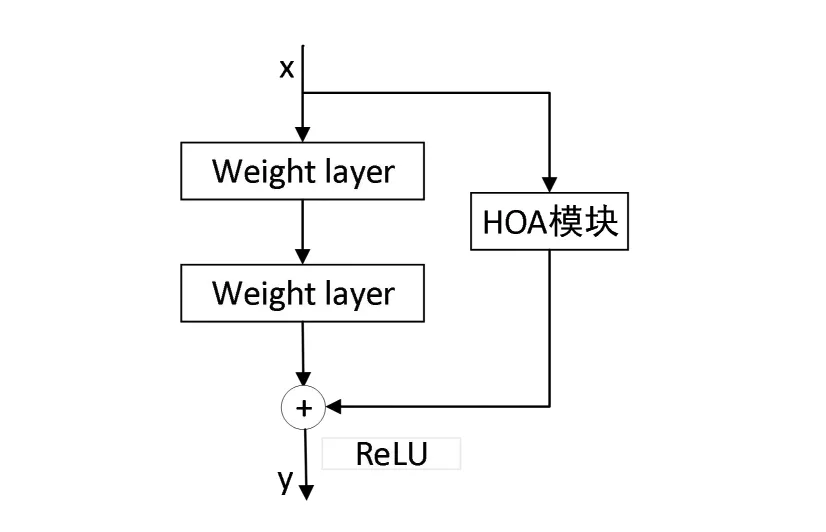
图3 ResNet结合HOA网络结构图
2 实验
2.1 实验数据集介绍
为了验证所述方法的有效性,本文在两个表情数据集(CK+和Fer2013)上进行了实验。
CK+数据集是发布于2010年的开源数据集[11],采集了123个人的表情视频,共计593个图像序列。参与者年龄在18到50岁之间,其中69%是女性;81%是欧美人,13%是非裔美国人,6%来自其他群体。每个序列从中性表情开始,到表情峰值结束,每个序列包含八个表情,即中性、愤怒、蔑视、厌恶、恐惧、高兴、悲伤、惊讶。本实验经过选择处理,形成10720张图片的样本数据,并按照8:2的比例划分样本为训练集和测试集。
Fer2013数据集发布于2013年[12],该数据集包含共26190张48*48灰度图,图片的分辨率比较低,共7种表情,分别为中性、愤怒、厌恶、恐惧、伤心、开心、惊讶。
2.2 实验环境和实验细节
实验在Ubuntu 18.04系统环境下进行,基于PyTorch深度学习框架构建的高阶注意力机制面部表情识别模型。在所有实验中,将所有批大小设置为32,并使用一个1080Ti GPU。模型采用ResNet50作为骨干网络,将ResNet的第一层卷积层原始输入通道为3修改输入通道为1,即可处理灰度图像。在训练时,采用动量因子为0.9的SGD优化器,在训练开始时,将学习率设置为0.01,设置训练的循环次数为200次,每50次循环将学习率降为原来的十分之一。
2.3 数据预处理
为增加训练集的多样性,对数据集使用数据扩充手段,对图像进行翻转、旋转等操作,以扩大训练样本的数量,增加训练样本的多样性。首先将所有面部区域图像水平翻转得到水平翻转图像。然后,每个图像分别旋转-15°、-12°、-9°、-6°、-3°、3°、6°、9°、12°、1°,得到旋转图像之后对旋转图像进行水平翻转得到旋转图像的水平翻转图像,最终得到22倍于原数据的实验数据集:原始图像1倍、水平翻转图像1倍、旋转图像10倍、旋转图像的水平翻转图像10倍[5]。实验只对训练数据进行扩充。
2.4 实验结果分析
模型训练好后,在测试集上对模型的准确率进行评价。表1和表2是在两个数据集上的实验结果。N、A、C、D、F、H、Sa和Su分别表示中性、愤怒、蔑视、厌恶、恐惧、快乐、悲伤和惊讶八种基本表情。
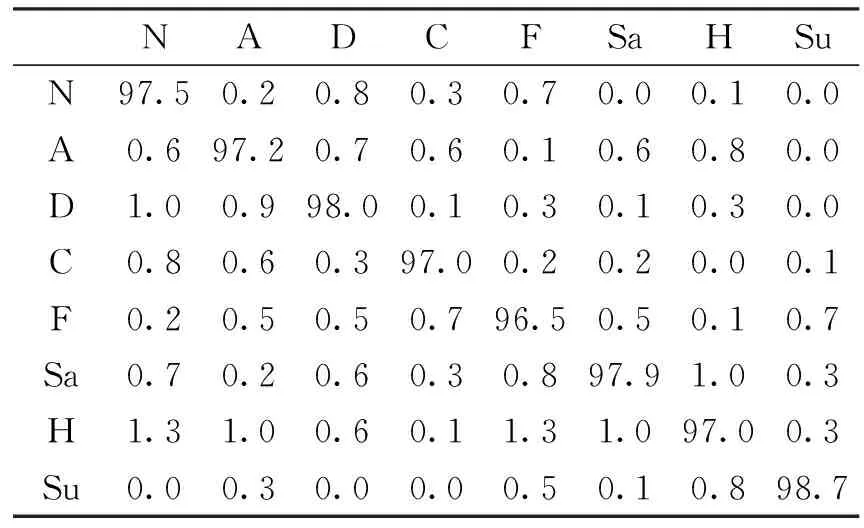
表1 CK+数据集表情识别准确率(%)
CK+数据集中,该方法对惊讶、厌恶的识别率分别为98.7%和98.0%,对恐惧、蔑视和快乐的识别率分别为96.5%和97.0%,识别率较低。识别率的中位数为97.5%,总体识别率为97.5%。
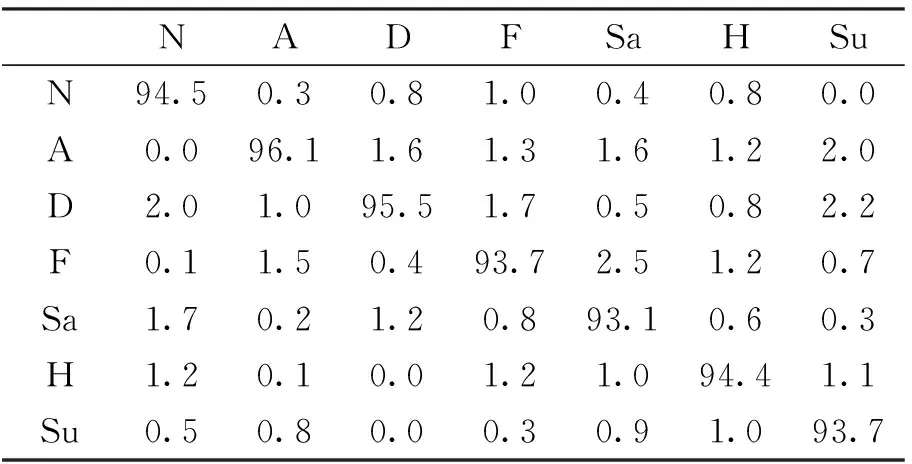
表2 Fer2013数据集表情识别准确率(%)
Fer2013数据集中,该方法对愤怒的识别率为96.1%,对厌恶的识别率为95.5%,对中性和快乐的识别率分别为94.5%和94.4%,而对悲伤、惊讶和恐惧的识别率较低,分别在93.1%、93.7%和93.7%。识别率的中位数为94.4%,总体识别率为94.4%。
2.5 与其他方法的对比
表3和表4显示了提出的方法和其他方法在CK+数据集和Fer2013数据集中获得识别率的比较。
从表3和表4中的数据可以看出,与其他方法相比,残差神经网络融合HOA模块获得了更高的识别率,从而提高了识别精度。

表3 CK+数据集中不同算法识别率比较

表4 Fer2013数据集中不同算法识别率比较
3 总结
本文基于ResNet和HOA模型提出了一种新的面部表情识别方法。利用复杂的高阶统计信息,对残差网络提取的特征进行建模,提高表情识别的准确率;利用HOA机制对CNN提取的特征进行建模,以便捕获更多不同关键区域之间相互影响的复杂信息和图像之间的细微差异;通过对ResNet模型进行改造,使其适用于灰度图像。在Fer2013数据库和CK+数据库测试集上的实验表明,表情识别率分别达到94.40%和97.50%。对比实验验证了该方法的有效性。下一步可以在表情识别中面部细微差别的捕捉、面部关键区域之间的相互作用的计算方面进行研究,从而进一步提高表情识别精度。
(责任编辑王 磊)
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
北京航空航天大学学报(2019年9期)2019-10-26
中国听力语言康复科学杂志(2019年3期)2019-06-24
福建基础教育研究(2019年7期)2019-05-28
上海师范大学学报·自然科学版(2018年3期)2018-05-14
中国高新技术企业(2017年5期)2017-05-05
物联网技术(2016年11期)2017-01-12
北京航空航天大学学报(2016年7期)2016-11-16
电脑知识与技术(2016年24期)2016-11-14
