
基于双向长短期记忆神经网络的水平地应力预测方法
2023-01-03 02:01马天寿向国富石榆帆桂俊川张东洋
石油科学通报 2022年4期
马天寿,向国富,石榆帆,桂俊川,张东洋
1 西南石油大学“油气藏地质及开发工程”国家重点实验室, 成都 610500
2 西南石油大学工程学院, 南充 637001
3 中国石油西南油气田公司页岩气研究院, 成都 610051
0 引言
准确预测地应力对于油气勘探开发具有重要作用和意义[1]。地应力是井壁稳定分析的边界条件,其大小决定了维护井壁稳定所需的当量泥浆密度[2-4],同时地应力也是水力压裂设计的关键参数,其大小直接约束了水力裂缝的起裂和扩展[5-6]。地应力由垂向地应力、最大和最小水平地应力构成,其中垂向地应力可直接由密度测井资料计算得到,而最大和最小水平地应力由于地质环境和技术水平的限制难以实现高效预测。目前,确定最大和最小水平地应力的方法包括直接测量法、测井解释法、数值模拟法及地震预测法等[7]。其中,直接测量法和测井解释法精度较高且技术相对成熟因此被广泛采用。直接测量法包括声发射测试、波速各向异性测试、水力压裂测试、诊断裂缝注入测试等[8-10],直接测量法精度最好,但是测试成本高、耗时长,而且只能获得取芯深度点的地应力,所测得的数据十分有限;测井解释法可以利用声波测井、成像测井及钻井诱导裂缝等资料确定地应力[11-12],相较于直接测量法,测井解释法精度偏低,但是具有纵向分辨率高、相对连续的特点,可以解释得到相对连续的地应力剖面,因而被现场广泛应用。然而,目前的测井解释方法依赖于阵列声波测井资料和实测地应力数据,严重限制了地应力的测井解释。此外,由于地下情况复杂和非均质性较强,测井数据之间表现出极强的非线性关系[13],使得传统的解析模型和神经网络模型难以表达测井数据与地应力之间的空间相关性。因此,亟需寻求一种简单、高效的替代模型用于解决地应力预测问题。
近年来,随着机器学习在科学和工程领域的广泛应用,许多学者提出利用机器学习来解决地球科学问题[14-15]。张东晓等[15]提出了一种串级长短期记忆神经网络,用于补全和生成人工测井曲线;Singh[16]提出了一种模糊逻辑模型进行地层识别;Mehrgini等[17]利用Elman神经网络,通过训练自然伽马、电阻率、中子孔隙度、岩石体积密度及含水饱和度等参数来预测横波速度;Korjani等[18]基于邻井地质资料,构建了一种深度学习神经网络预测岩石物理特征的油藏建模方法,用于构建缺少测井和岩心资料的虚拟测井数据;韩玉娇等[19]采用AdaBoost机器学习算法,开展了大牛地气田储层流体智能识别研究。在地应力预测方面:冯鹏等[20]筛选了井径、补偿中子、自然伽马、密度、深浅侧向电阻率等测井参数作为训练因子,利用支持向量回归方法建立了煤层最小水平地应力预测模型;尚福华等[21]基于改进的BP神经网络模型对岩石力学参数进行反演预测,进而进行地应力预测;HAN和YIN[22]利用人工神经网络(ANN),将井眼形变数据作为特征来预测地应力;IBRAHIM等[23]基于测井参数利用随机森林、功能网络和模糊推理系统等机器学习技术来预测地应力;GOWIDA等[24]利用ANN,通过训练钻压、扭矩及机械钻速等实钻数据来预测地应力;TUNG[25]利用ANN,通过训练垂深、孔隙压力、垂向地应力等数据来预测最小水平地应力;PU等[26]通过决策树,综合考虑岩石弹性模量、泊松比及其他参数的影响来预测地应力;MA等[27]建立了一种混合神经网络模型,用于单井地应力的预测。
国内外学者已经利用机器学方法对岩性识别、测井曲线重构、地应力预测等开展了大量研究,但地应力的机器学习方法大都采用传统全连接神经网络(FCNN),这类方法只能构造点对点的映射,无法有效捕捉测井资料深度上的变异信息,而且,这类方法通常假设数据是低维和线性的,因而难以有效准确地预测地应力。此外,这类方法的泛化能力较差,很难用于新井地应力的预测。为此,采用一种先进的循环神经网络,即双向长短记忆神经网络(BiLSTM),利用常规测井参数来预测地应力。首先,选取工区两口直井作为研究对象,分别对两口井的测井资料进行地应力解释,形成训练和测试数据集;然后,研究数据预处理与样本构造算法,分析测井参数与地应力相关性,建立基于BiLSTM的水平地应力预测模型,并阐述模型的核心算法和流程;最后,结合测井参数相关性与地质学含义,分析不同测井参数组合模式下水平地应力的预测效果。本文研究对于准确预测地应力、推广机器学习在石油工程的应用具有重要的作用和意义。
1 地应力测井解释
本文数据来自于四川盆地CL气田的2口直井,工区位于川中隆起区的川西南低陡褶带,该工区整体表现为由北西向南、东方向倾斜的宽缓单斜构造,且地层平缓,倾角小,断裂不发育。为了获得2口井的地应力测井解释数据集,需要根据工区地层特征建立地质力学模型。
1.1 地质力学模型
地质力学模型是根据室内岩石力学实验、矿场实测资料和测井解释建立地层岩石力学参数、孔隙压力、地应力一维剖面的常用方法[27-28],其建模流程如图1所示。首先,确定岩石力学参数,包括泊松比、弹性模量和Biot系数;其次,通过密度测井资料计算垂向地应力;然后,利用声波测井资料确定孔隙压力;进一步,根据室内测试或小型地破试验结果,反演构造应力系数;最后,利用岩石力学参数、孔隙压力、垂向地应力解释结果和构造应力系数,确定最大和最小水平地应力。
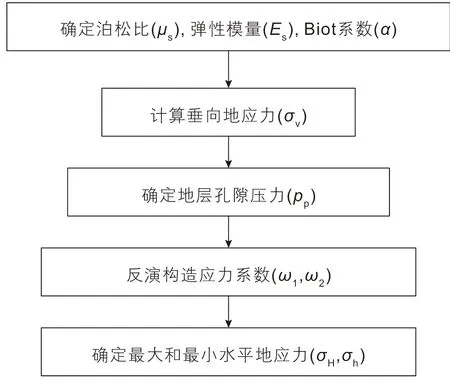
图1 地质力学模型建模流程图[27]Fig. 1 Flowchart of geo-mechanical modeling[27]
大部分油气测井作业中,由于成本限制,一般只进行纵波时差测井,缺少横波时差测井资料[29]。因此,需要采用横波重构来估算横波时差,即利用工区已测井的纵横波时差关系,建立横波时差预测的经验公式。对于目标工区,纵横波时差之间的经验关系为[27]:

式中:Δtp为纵波时差,μs/ft;Δts为横波时差,μs/ft。
进一步,根据弹性介质中纵横波传播理论,建立动态弹性参数与纵波、横波时差的关系[29]:
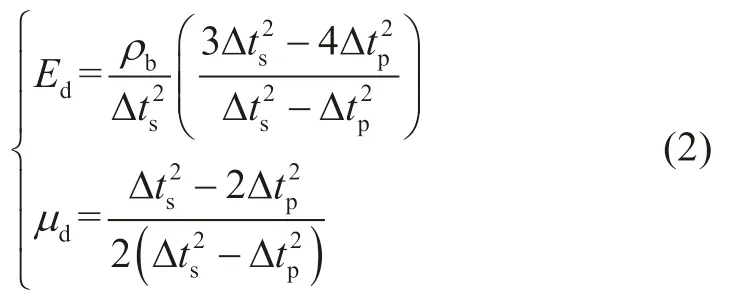
式中:Ed为动态弹性模量,GPa;μd为动态泊松比,无因次;ρb为岩石密度,g/cm3。
在实际工程应用中,需要采用静态弹性模量和泊松比。因此,需要对弹性模量和泊松比进行动静态转换。对于目标工区,弹性模量和泊松比的动静态转换关系为[27]:
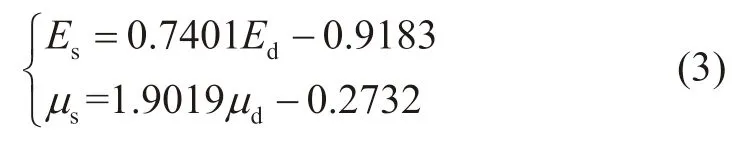
式中:Es为静态弹性模量,GPa;μs为静态泊松比,无因次。
而地层岩石Biot系数可表示为[29]:
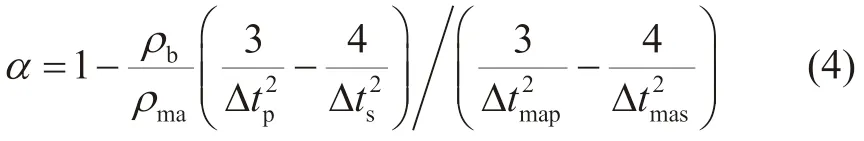
式中:α为Biot系数,无因次;ρma为岩石骨架密度,g/cm3;Δtmap和Δtmas分别为岩石骨架的纵波时差和横波时差,μs/ft。
垂向地应力也称上覆岩层压力,可由密度测井曲线直接积分求得:
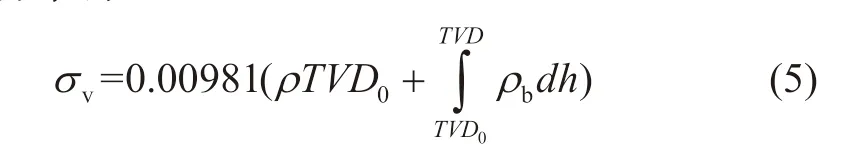
式中:σv为垂向地应力,MPa;ρ为缺少密度测井资料井段的上覆岩层平均密度,g/cm3;TVD0为测井曲线起始点垂深,m;TVD为给定计算测点所对应的垂深,m。
通过对比孔隙压力预测方法及预测效果,优选Eaton法计算目标工区地层孔隙压力。Eaton法以泥岩正常压实理论为基础,因此,先要建立正常压实趋势线,然后才能计算地层孔隙压力。对于目标工区,其正常压实趋势线可表示为[27]:
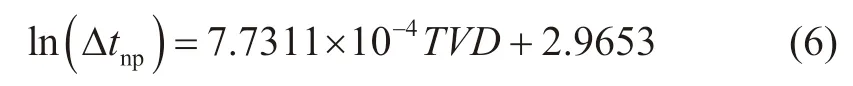
而Eaton法计算地层孔隙压力的公式可表示为[30]:
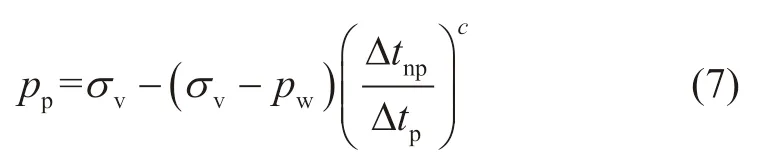
式中:pp为地层孔隙压力,MPa;pw为地层流体静液柱压力,MPa;Δtnp为正常趋势线上对应的纵波时差,μs/ft;c为Eaton常数,无因次,目标工区Eaton常数取值为0.914。
最后,计算最大和最小水平地应力,水平地应力的计算模式主要分为两种[31-32]:一种是单轴应变模式,认为水平方向无限大,地层在沉积过程中只发生垂向变形,水平方向的应力是由上覆岩层重量引起的,主要包括Terzaghi模型、Matthews-Kelly模型、Anderson模型和Newberry模型,这类模式没有考虑构造应力,不符合实际地质条件;另一类是分层计算模式,主要包括组合弹簧模型、斯伦贝谢模型和黄氏模型,该模式考虑了构造应力对水平地应力的影响,因此被广泛应用于油田地应力预测。由于目标工区整体呈低缓构造特征,因此,采用黄氏模型计算水平地应力,黄氏模型可表示为[32]:
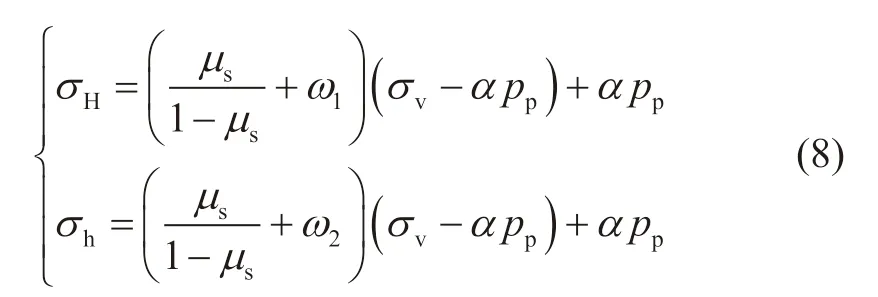
式中:σH为最大水平地应力,MPa;σh为最小水平地应力,MPa;ω1和ω2分别为最大和最小水平地应力方向的构造应力系数,无因次。
在式(8)所示的黄氏模型中,构造应力系数的确定非常关键。对确定的工区,其构造应力系数可视为常数。利用室内地应力差应变测试结果,并结合孔隙压力(pp)、静态泊松比(μs)、Biot系数(α)测井解释结果,可以利用式(8)反演出工区的构造应力系数,目标工区构造应力系数取值为ω1=0.458、ω2=0.364,进而再利用式(8)计算连续的水平地应力测井解释剖面。
1.2 测井解释结果
通过测井解释得到了工区2口直井(X-1井和X-2井)的地应力剖面,包括垂向地应力、最大水平地应力和最小水平地应力,结果如图2所示。由图可知,每口井有10条测井曲线,包括自然伽马(GR)、纵波时差(DTC)、井径(CAL)、密度(DEN)、补偿中子(CNL)、横波时差(DTS)、测深(MD)、方位角(AZIM)、井斜角(DEVI)和垂深(TVD)。其中,X-1井测深为2809~3664.3 m,测段总长为855.5 m,;X-2井测深为3218.1~3693.0 m,测段总长为474.9 m。不难看出:该工区垂向应力>最大水平地应力>最小水平地应力,属于潜在正断层应力状态,而且,地应力随井深的增加呈增大趋势。此外,为了验证黄氏模型的准确性,将X-1井地应力解释结果与3663.2 m、3657.3 m和3669.1 m处岩心差应变实验结果进行对比发现,X-1井垂向地应力误差为0.39%,最大水平地应力误差为0.18%~0.64%,最小水平地应力误差为0.29%。因此,测井解释得到的地应力与实测地应力吻合较好,可以将测井解释得到的地应力作为真实地应力。
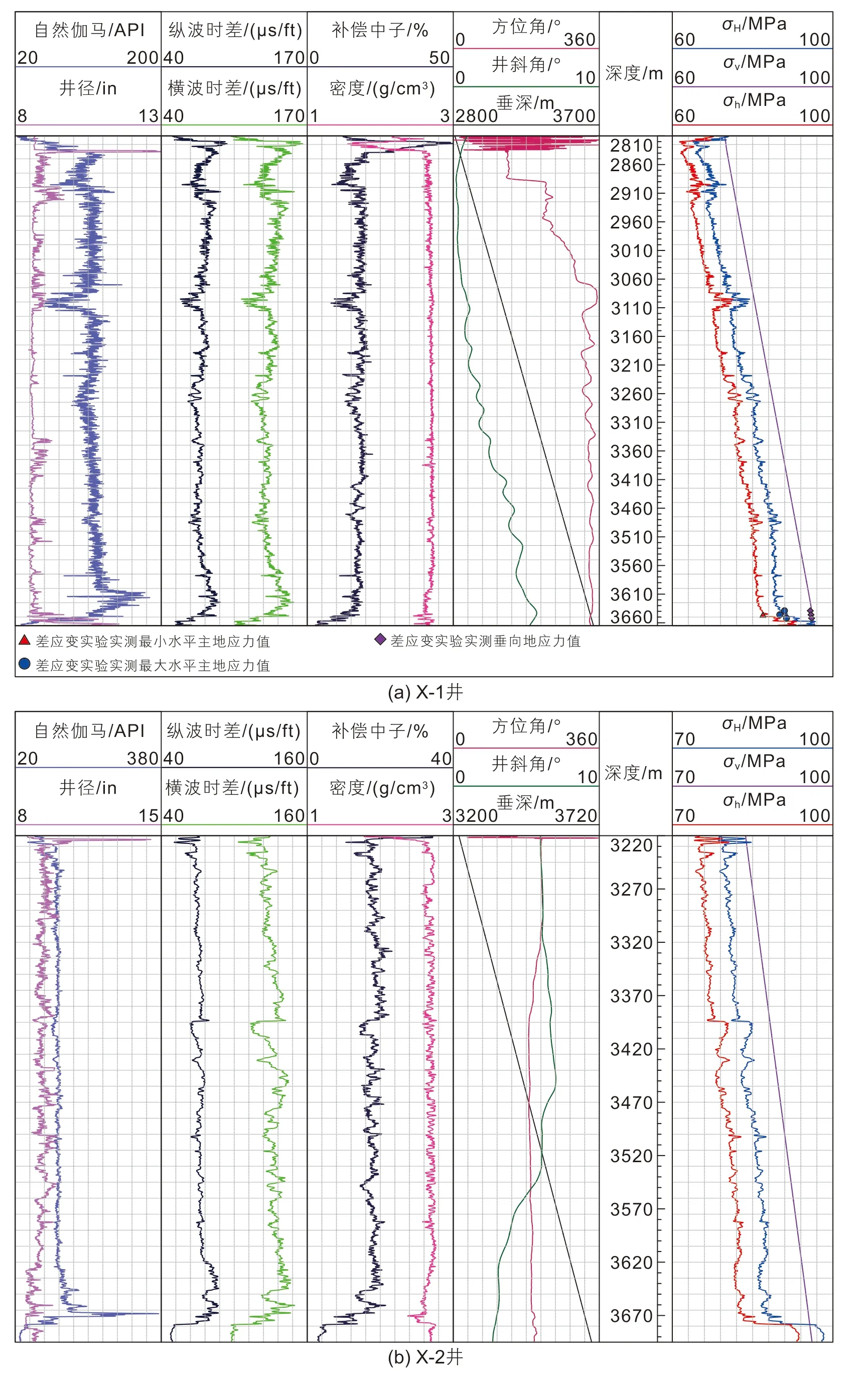
图2 地应力测井解释成果图Fig. 2 Logging interpretation results of in-situ stress
2 数据预处理与样本构造
数据预处理和样本构造是机器学习建模的重要环节,前者决定了机器学习模型预测和泛化能力的好坏,而后者确定了数据输入模型的形式。本文分别将X-1井和X-2井作为训练井和测试井,其中,训练井用于开发机器学习模型,测试井用于验证模型的预测和泛化能力。
2.1 数据处理
测井参数是对井下岩石物性特征的综合响应,不同测井参数能够反映地层岩性、泥质含量、含水饱和度、渗透率等特征[33]。而地应力取决于地质构造、沉积环境、地层岩性等因素,因此,测井参数与地应力之间存在着必然联系,这也是利用测井数据预测地应力的理论依据。同时,测井参数与地应力之间关系复杂,不是所有测井参数都与地应力之间存在关联关系。因此,需要对测井参数进行合理筛选,以消除冗余参数对地应力预测的影响。经典机器学习方法往往采用相关性分析来挖掘数据之间的关联关系。
考虑到测井参数之间一般呈非正态分布,因此,采用Spearman秩相关系数来表征不同测井参数之间的相关性。Spearman秩相关系数是一种非参数的相关性度量准则,通过对变量X和Y求秩后再进行相关性分析,能够满足非正态分布数据的相关性计算,Spearman秩相关系数计算公式为[28]:
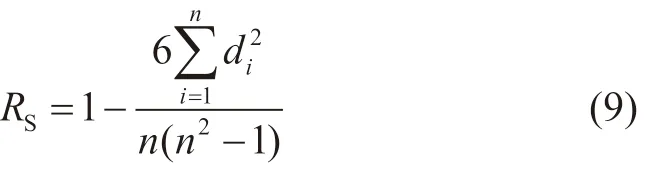
式中:RS为Spearman秩相关系数;n为样本的数量;di为变量X和Y的秩次之差。
同时,根据式(9)计算得到的相关性系数,可以按照以下取值范围判断相关性强弱[34]:0.8≤|RS|≤1.0表 示 极 强 相 关;0.6≤|RS|≤0.79表 示 强 相 关;0.4≤|RS|≤0.59表示中等相关;0.2≤|RS|≤0.39表示弱相关;0.0≤|RS|≤0.19表示不相关。
图3所示为X-1井测井参数相关系分析结果,不难看出:各测井参数与水平地应力之间具有极其相似的相关性系数,但不同测井参数与水平地应力之间的相关性存在较大差异:水平地应力与垂深、密度及自然伽马等测井参数之间表现为正相关,与纵波时差、井径、补偿中子及横波时差等测井参数之间表现为负相关;最大和最小水平地应力与垂深之间的相关性系数最大且均为0.98,其次是井径、密度、补偿中子和自然伽马,分别为-0.38、0.37、-0.36和0.34,纵波时差和横波时差相关性系数相同且最小为-0.27;根据相关性强度判别标准,水平地应力与垂深之间相关性极强,与井径、密度、补偿中子、自然伽马、纵波时差、横波时差之间相关性相对较弱。整体来看,X-1井各测井参数与水平地应力之间均存在一定程度的相关性。
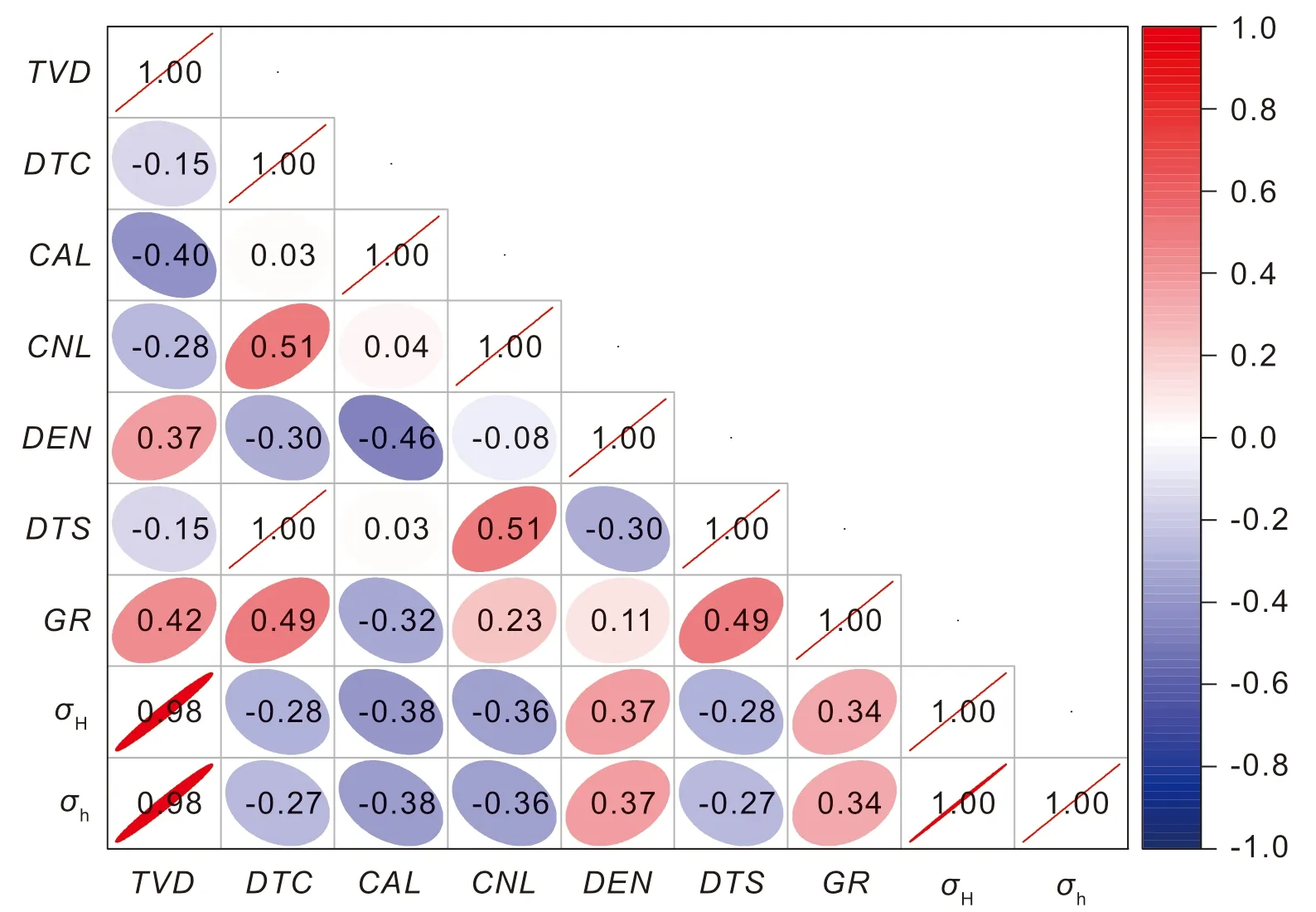
图3 X-1井测井参数相关性分析图Fig. 3 Correlation analysis of logging parameters in X-1 well
原始测井数据受外部环境以及测井仪器自身性能的影响,使得原始测井数据具有较大噪声[35]。考虑到卡尔曼滤波具有无偏、稳定和概率意义上最优的特点[36],采用卡尔曼滤波算法对原始测井数据进行去噪。常规卡尔曼滤波算法包含估计和修正两个过程,估计过程主要依靠时间更新方程,即首先根据式(10)建立当前状态的先验估计值êk|k-1,然后根据式(11)推算当前状态的误差协方差估计值Pk|k-1:
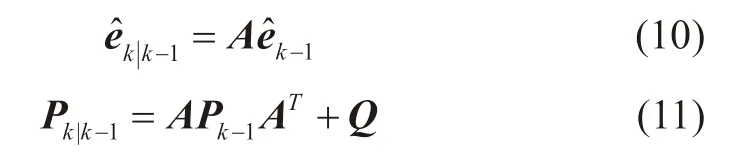
式中:êk|k-1为先验估计状态向量;A为状态转移矩阵;Pk为后验估计误差协方差矩阵;Pk|k-1为先验估计误差协方差矩阵;Q为过程噪声协方差矩阵。
然后,在获得先验估计的前提下,利用观测值对当前状态进行后验估计:首先,根据式(12)计算当前状态的卡尔曼增益矩阵Kk;然后,结合观测向量zk,根据式(13)对先验估计状态向量êk|k-1进行修正,得到状态估计向量êk,即为最优估计;最后,根据式(14)将误差协方差Pk|k-1更新为Pk:

式中:êk为后验状态估计向量;zk为观测向量;R为测量噪声协方差矩阵;S为测量协方差矩阵;Kk为卡尔曼增益。
采用卡尔曼滤波对X-1井和X-2井的井径、密度、自然伽马、纵波时差、横波时差以及最大和最小水平地应力等测井曲线进行了去噪处理,去噪前后的对比曲线如图4所示。不难看出:卡尔曼滤波可以有效消除测井数据中仪器自身噪声和随机性噪声信息,有助于避免后续训练过程中可能会出现的噪声拟合,从而避免噪声引起的过拟合或欠拟合。因此,卡尔曼滤波去噪也是一种正则化手段。
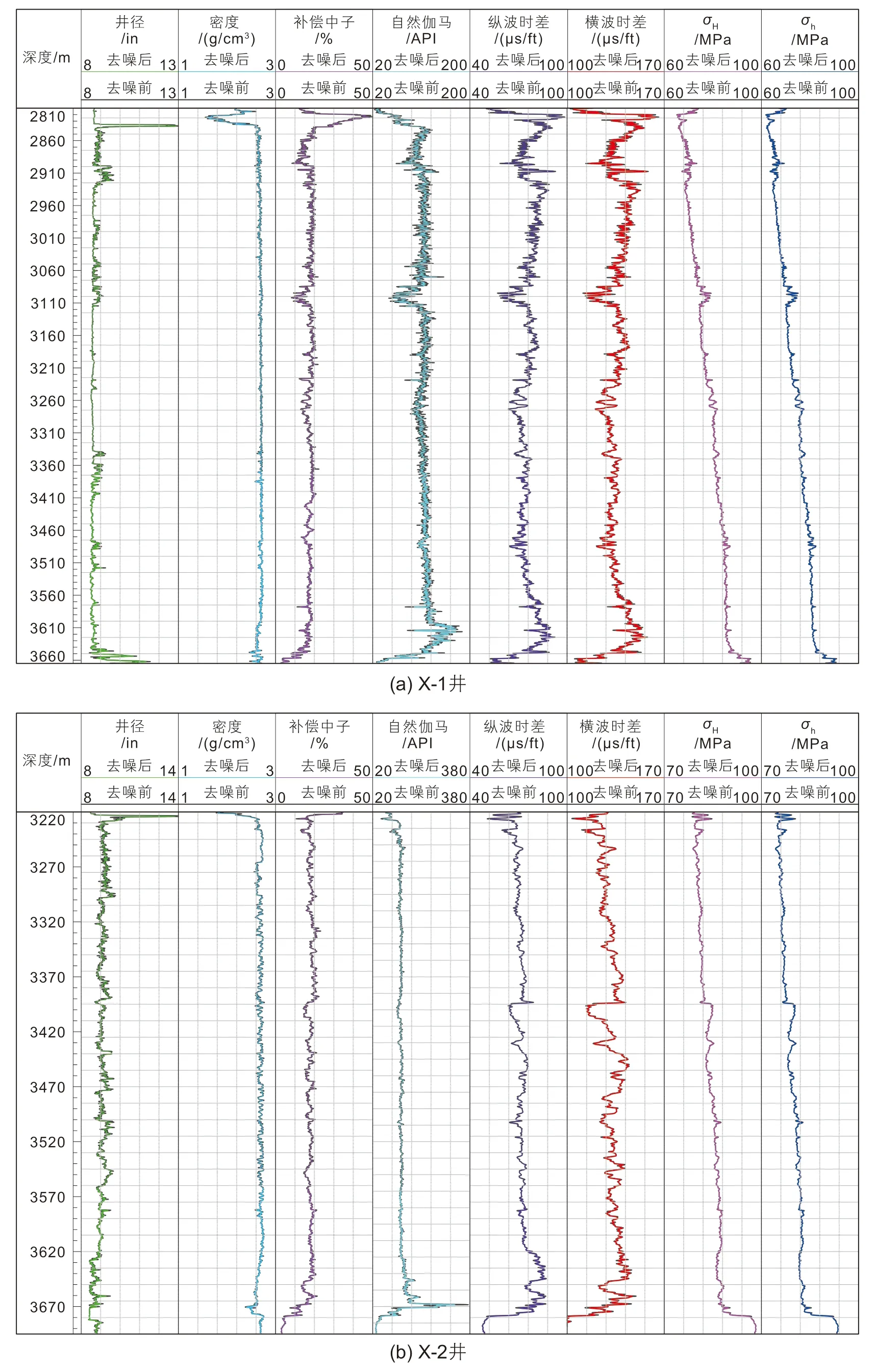
图4 测井参数去噪前后对比Fig. 4 Comparison of logging parameters before and after denoising
完成数据去噪后,需要对测井数据进行归一化处理。归一化处理的目的是将不同类型数据映射到一定范围内,在不影响数据特性前提下,消除量纲对数据的影响,同时,加快机器学习模型的处理过程,从而提高训练速度。本文采用最大最小归一化,将测井数据归一化到0和1之间,最大最小归一化表示为[37]:

式中:x*为归一化之后的数据;x为原始数据;xmax和xmin分别为数据的最大值和最小值。
所有测井参数在输入模型前都要进行归一化处理,值得注意的是最大和最小水平地应力作为输出数据,即目标数据不需要进行归一化,但为了使模型能够快速收敛,将最大和最小水平地应力值缩小100倍。
2.2 样本构造
为有效提取测井数据序列的深度特征信息,采用了一种滑动窗口的样本构造方式[38]。如图5所示,将归一化的测井数据组成二维数据矩阵形式,其中,特征表示相关测井参数,标签表示测井数据点所对应的地应力,n和l分别表示滑动窗口的步长和滑窗的大小,每一个样本由输入和输出样本组成。在样本构造过程中,将左侧彩色实线框中的数据作为输入样本,右侧彩色实线框中的数据作为输出样本。滑窗每次沿着深度方向滑动一个步长,便可构造一个样本,滑窗滑至最深处,即可完成所有样本的构造。考虑到本研究为一个深度序列预测任务,为了保证预测参数在深度上连续,取滑窗步长为1。
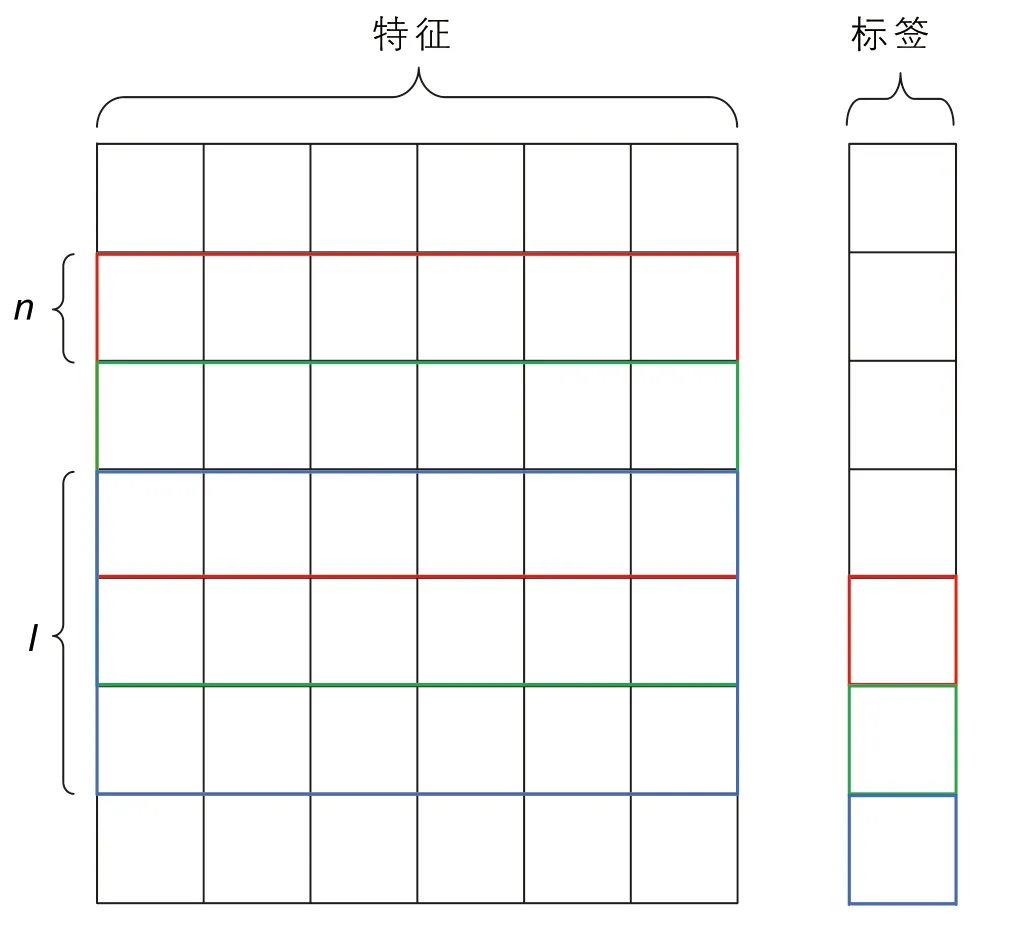
图5 样本构造方法Fig. 5 Sample construction method
3 双向长短期记忆神经网络模型
基于测井参数预测最大和最小水平地应力,可描述为已知某一井段测井参数X={x1, x2,…, xn}以及对应的地应力参数Y={y1, y2,…, yn},其中,n表示样本数量,通过构建模型,由训练得到测井参数X与地应力参数Y之间的非线性映射关系。构建模型的目的在于,当给出新的且未进行地应力测井解释的测井段时,模型能够预测出最优地应力预测结果Yˆ={ŷ1, ŷ2,…, ŷn}。
3.1 模型理论
根据上述水平地应力预测问题的描述,本文使用一种特殊的循环神经网络,即双向长短期记忆神经网络(BiLSTM)[39],BiLSTM网络结构如图6所示。一个完整的BiLSTM网络包括数据输入层、前向LSTM、后向LSTM、激活函数层及数据输出层。
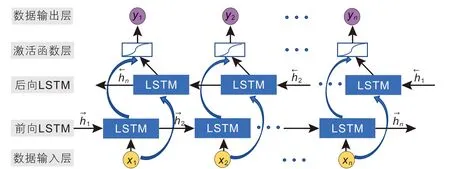
图6 BiLSTM网络结构图Fig. 6 Network structure diagram of BiLSTM
BiLSTM主要由前向和后向长短期记忆神经网络(LSTM)组成[40],通过两个平行的隐藏单元层来捕捉前后两个方向上的序列关系,进一步提高了特征提取的完整性和全局性,使得地应力预测更加准确。LSTM是BiLSTM的基本模块,不同于普通的循环神经网络(RNN),LSTM由于特殊的结构设计使得其能够有效避免时间序列模型在反向传播过程中因为对序列产生长期依赖所导致的梯度消失和梯度爆炸问题[41]。相较于传统的RNN,LSTM结构更为复杂,其包含了四个交互作用门层(遗忘门层、Tanh门层、输入门层、输出门层)[42-43],从而形成了独有的反馈循环结构,LSTM的网络结构如图7所示。
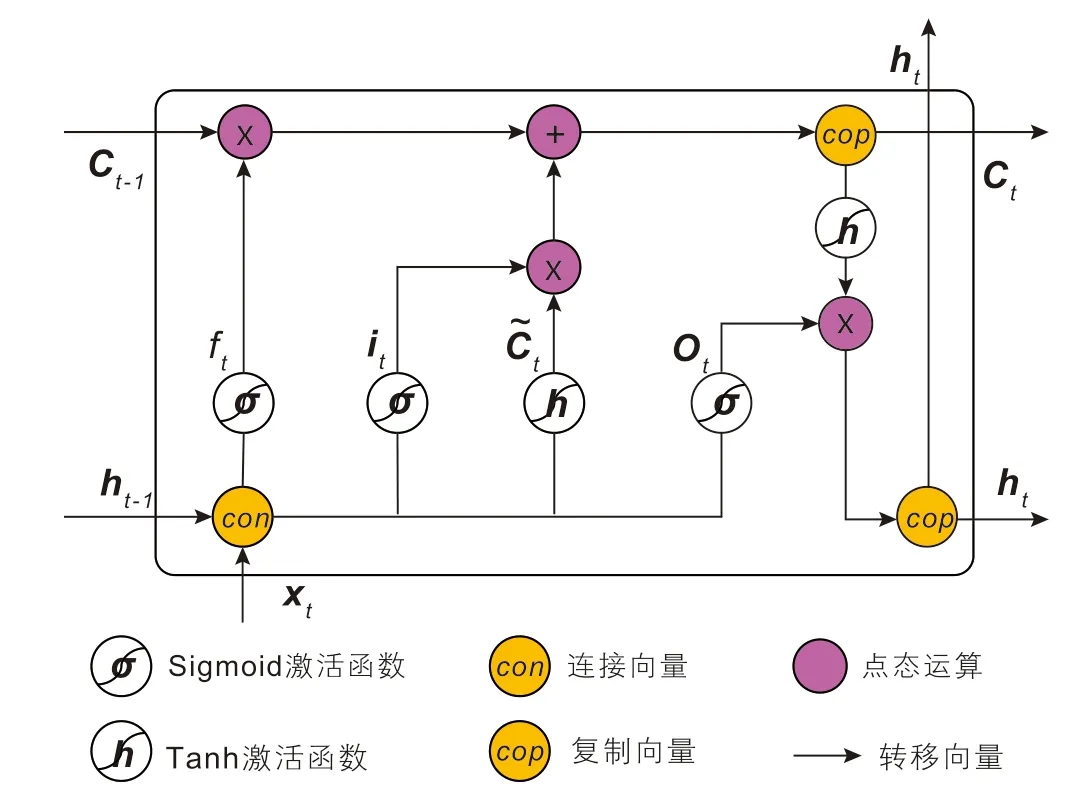
图7 LSTM网络结构图Fig. 7 Network structure diagram of LSTM
LSTM的核心思想是细胞态,其贯穿整个循环过程,在LSTM的处理过程中,通过精心设计的交互作用门层,可根据上一时刻的隐状态和当前时刻的输入,选择性删除上一时刻细胞态中的信息或者添加新信息到当前时刻的细胞态中。具体而言,第一个交互门层称为遗忘门层,它决定了哪些信息该从细胞态中删除,遗忘门层可表示为[39]:
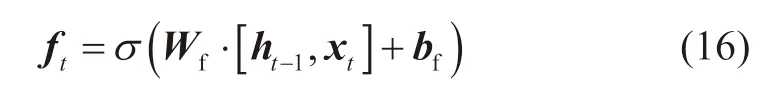
式中:ft为遗忘门;Wf为遗忘门权重矩阵;ht-1为上一时刻的隐状态;xt为当前时刻的输入;ht为当前时刻的隐状态;bf为遗忘门的偏置向量;σ为Sigmoid激活函数。
第二个交互作用门层称为输入门层,它决定了哪些信息将会被细胞态存贮,输入门层可表示为式(17)。接下来便利用第三个交互门层,即Tanh门层生成一个新的候选值,用于描述当前时刻的细胞态,Tanh门层可表示为式(18)[40]:
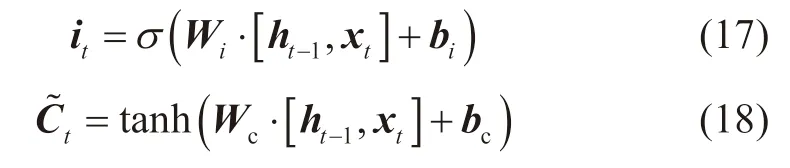
式中:it为输入门;t为新的候选值;Wi为输入门权重矩阵;Wc为Tanh门权重矩阵;bi为输入门偏置向量;bc为Tanh门偏置向量。
当经过上述步骤后,旧的细胞态Ct-1将被更新成为新的细胞态Ct。首先,将遗忘门的值ft与旧的细胞态Ct-1进行点乘以忘记部分信息,保留更为重要的信息;然后,将输入门的值it与新的候选值t进行点乘以决定哪些输入信息将会被保留;最后,将两者的计算结果相加完成对细胞态的更新;该过程可表示为[41]:
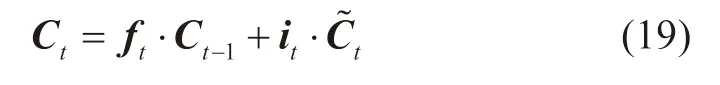
式中:Ct为当前时刻的细胞态;Ct-1为上一时刻的细胞态。
第四个交互门层称为输出门层,决定细胞态的哪些信息将会被输出。在这一阶段,首先会将细胞态的值通过Tanh函数映射到-1和1之间,然后与输出门层的计算结果进行点乘,输出当前时刻的隐状态,该过程可表示为:
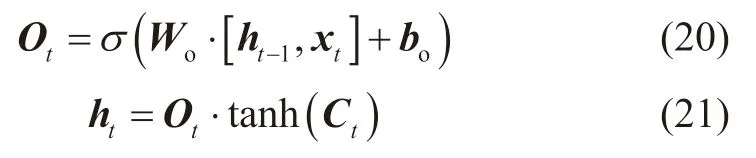
式中:Ot为输出门;Wo为输出门权重矩阵;bo为输出门偏置向量;ht为当前时刻隐状态。
对于BiLSTM模型,其隐状态包含两部分,一部分来自于前向LSTM,一部分来自于后向LSTM,分别用和表示。因此,BiLSTM的隐状态可以被定义为[41]:
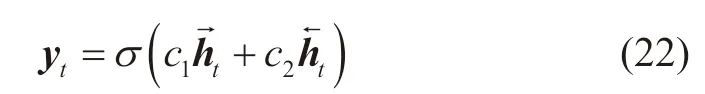
式中:yt为BiLSTM的输出;为当前时刻前向LSTM的隐状态;为当前时刻后向LSTM的隐状态;c1和c2为常数,且c1+c2=1。
3.2 模型构建
由BiLSTM构建的预测模型具有良好的适应性,在解决复杂地质问题方面表现出了卓越的预测能力[40]。本文所构建的地应力预测模型包括2个BiLSTM网络层、1个丢弃层(Dropout)、1个拉直层(Flatten)和1个全连接层(Linear),并分别在BiLSTM网络层和Linear层后面加上双曲正切(Tanh)激活函数层和Sigmoid激活函数层,模型结构和训练流程如图8所示。其中,BiLSTM网络层是模型的核心层,用于捕捉测井参数的序列特征以及不同测井参数之间的内在联系;Dropout层用于避免模型过拟合;Flatten层用于将高维数据特征变换成1维,实现BiLSTM网络层到全连接层的过渡;Linear层则将所学习的特征映射到样本标记空间形成预测值;Tanh和Sigmoid激活函数则完成数据的非线性变换。需要注意的是,在模型构建初期,暂时按照经验将样本构造中的窗口大小设置为30,数据批尺寸设置为16,学习率设置为0.01,迭代次数为50次;模型的训练流程可分为以下几个阶段:
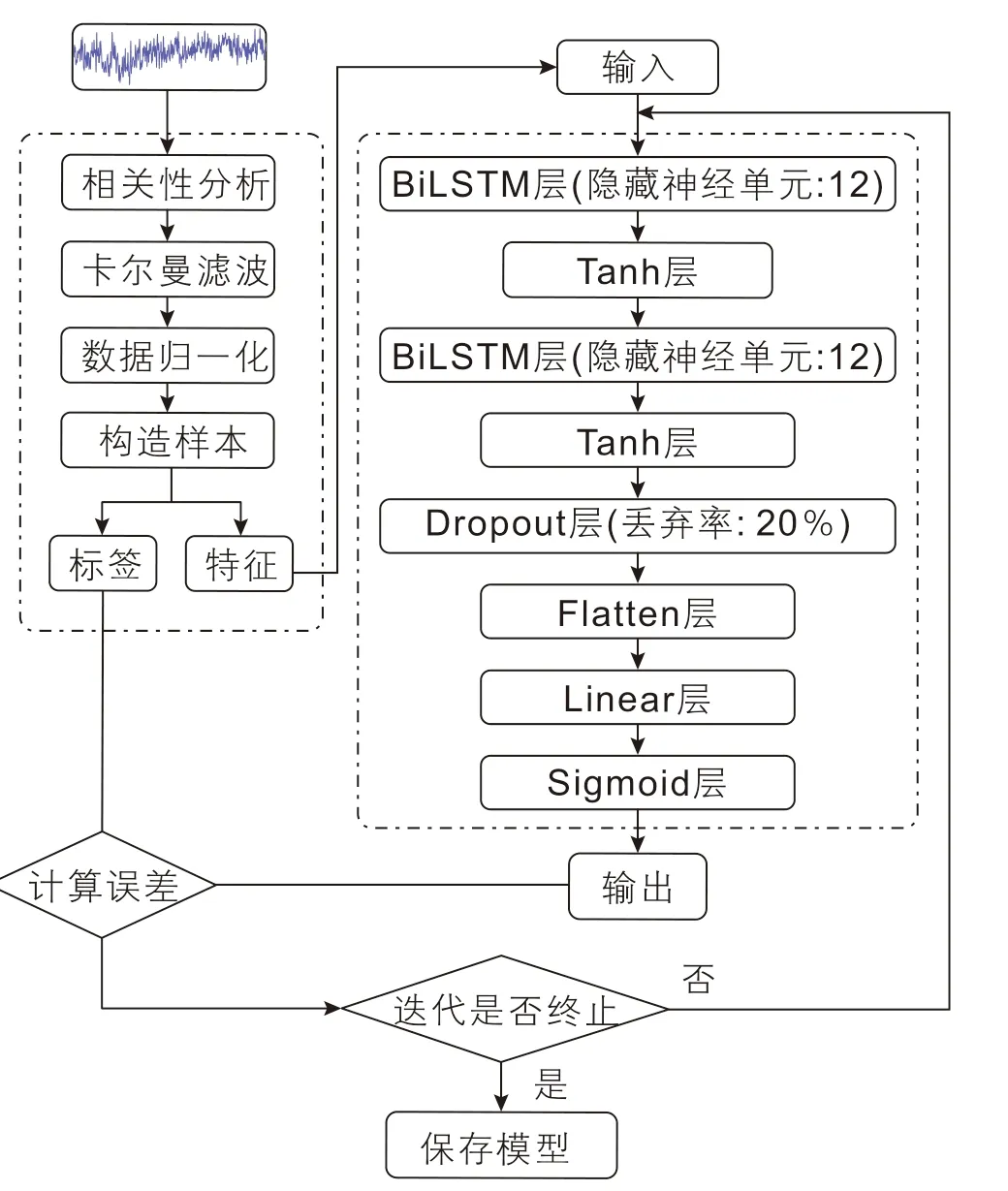
图8 模型结构和训练流程图Fig. 8 Model structure and training flowchart
1) 将测井数据进行去噪和归一化处理后按照2.2节所述样本构造方式构造出特征和标签样本,并将样本进行打乱,然后分批次喂入模型;
2) 样本数据进入模型后首先经过BiLSTM网络,随着数据在网络中的自由流动,预测地应力的关键特征被提取出来,在这一阶段BiLSTM网络的隐状态设置为12维,并使用Tanh函数作为非线性激活函数;
3) 从BiLSTM网络层提取的特征被送入Dropout层,Dropout层按照一定的概率对部分隐藏神经元进行丢弃操作,丢弃率设置为20%;
4) 经过Dropout层后的特征进入Flatten层,这时多维特征变被拉直成1维,使得特征能过渡到Linear层,最后特征经过Linear层,使用Sigmoid函数进行激活后映射成为预测值;
5) 计算预测值与标签之间的误差,并选择自适应矩估计(Adam)算法来调整模型的权值参数,使得训练过程中的误差可以不断减小直到达到迭代终止条件,达到迭代终止条件后保存模型直接用于后续测试集的预测。
4 地应力预测结果及讨论
4.1 结果分析
将X-1井常规测井数据和测井解释得到的水平地应力数据作为训练集,在训练过程中随机选取训练集30%的数据作为验证集,将X-2井常规测井参数和测井解释得到的水平地应力数据作为测试集,以验证该方法的泛化能力。其中,训练集和验证集用于建立和评估模型,测试集用于测试BiLSTM模型预测精度。为了分析不同测井参数组合对水平地应力预测的影响,根据相关性分析结果,按照相关性系数的大小顺序,设计了7种不同的测井参数组合方式:组合1仅使用1种测井参数:TVD;组合2使用2种测井参数:TVD和CAL;组合3使用3种测井参数:TVD、CAL和DEN;组合4使用4种测井参数:TVD、CAL、DEN和CNL;组合5使用5种测井参数:TVD、CAL、DEN、CNL和GR;组合6使用6种测井参数:TVD、CAL、DEN、CNL、GR和DTC;组合7使用7种测井参数:TVD、CAL、DEN、CNL、GR、DTC和DTS。
为了评价模型预测效果,采用均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)作为评价指标,其计算公式如下[33,38]:
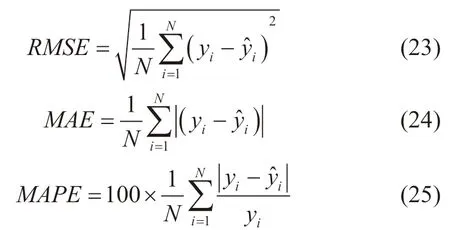
式中:N为样本数量;yi为真实地应力值,MPa;ŷi为预测地应力值,MPa;RMSE为均方根误差,MPa;MAE为平均绝对误差,MPa;MAPE为平均绝对百分比误差,%。
利用X-1井训练机器学习模型,然后按照7种测井参数组合方式,分别对X-2井3218.1~3693.0 m井段地层的最大和最小水平地应力进行预测,同时进行了超参数优化,优化前后预测结果如图9所示。图9a为实际和预测最大水平地应力对比,图9b为实际和预测最小水平地应力对比,其中,红色实线代表实际水平地应力,绿色实线代表预测得到的水平地应力,蓝色实线代表超参数优化后得到的水平地应力。
不同测井参数组合下预测结果的评价指标如表1所示,结合图9分析不难发现:1) X-2井预测井段实际最大水平地应力介于78.5~98.3 MPa,平均值为84.4 MPa;最小水平地应力介于74.1~93.7 MPa,平均值为79.7 MPa。2) 7种不同测井参数组合模式下,组合6的预测结果与实际水平地应力最为接近,最大和最小水平地应力的平均绝对百分比误差(MAPE)分别为1.39‰和1.76‰;组合2的预测效果最差,最大和最小水平地应力的平均绝对百分比误差(MAPE)分别为4.26%和4.33%。3) 组合4~7的预测效果明显优于组合1~3;从组合3到组合4,在增加了补偿中子作为输入参数之后,预测误差大幅下降,最大和最小水平地应力的平均绝对百分比误差(MAPE)分别由38.48‰和40.93‰下降至10.37‰和11.35‰,说明在增加了补偿中子后,模型学习到了预测地应力的关键信息,分配给了补偿中子更大的权重;另一方面,补偿中子用于指示岩石的孔隙度,对地层孔隙压力极为敏感,说明水平地应力与孔隙压力关系较为密切。
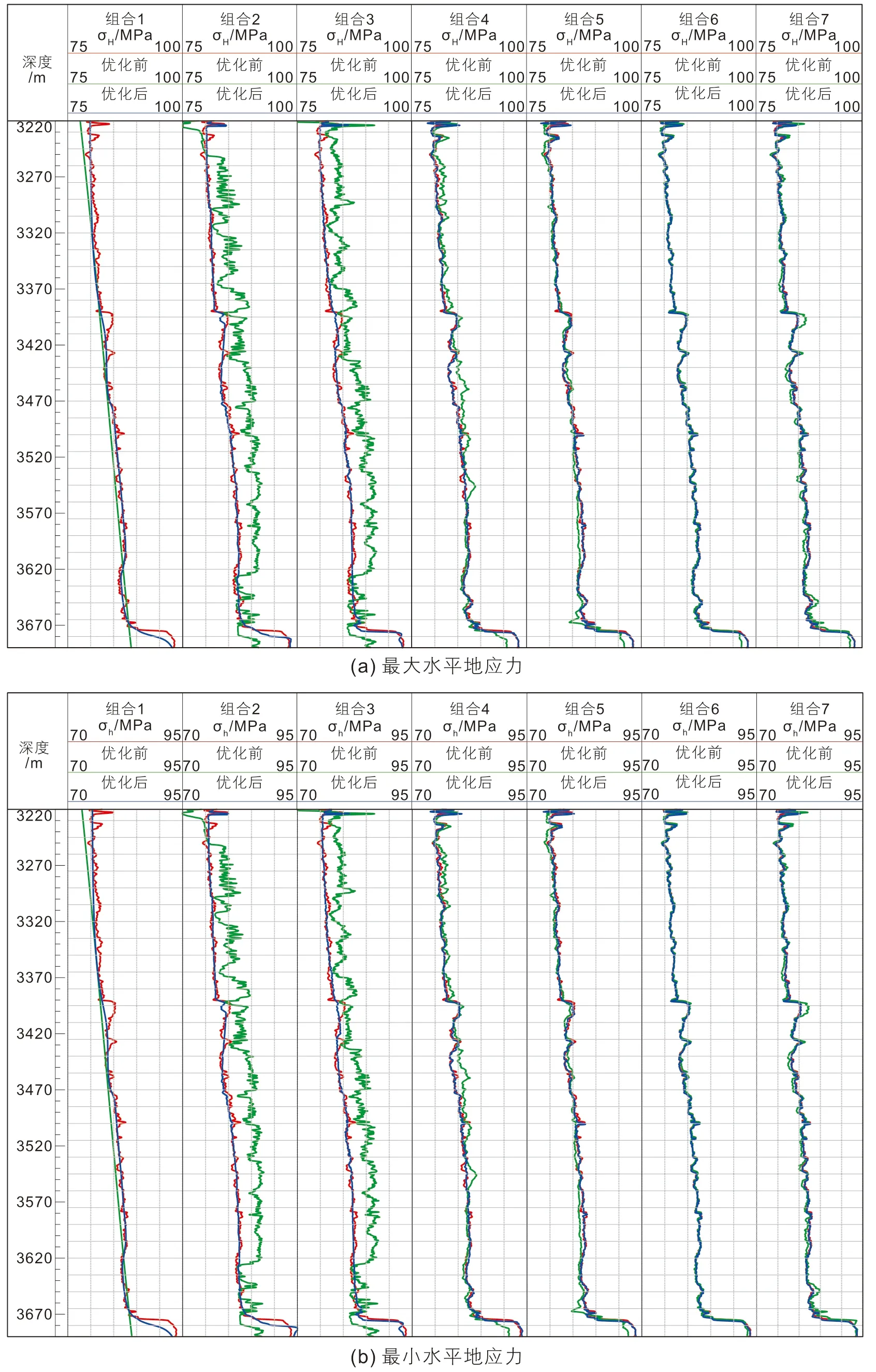
图9 不同参数组合下超参数优化前后X-2井最大和最小水平地应力预测结果对比Fig. 9 Comparison of prediction results of maximum and minimum horizontal in-situ stress in X-2 well before and after hyperparameter optimization under different parameter combinations
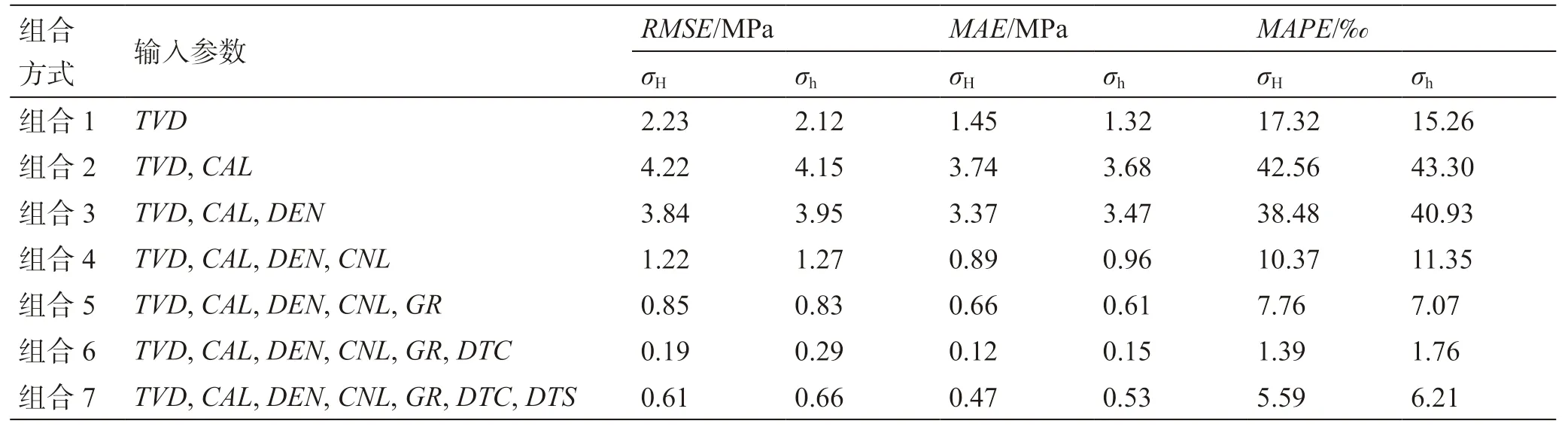
表1 不同参数组合下X-2井水平地应力预测效果评价指标Table 1 Evaluation indices of horizontal in-situ stresses prediction for X-2 well under different parameter combinations
由于机器学习模型超参数的选择与估计对模型的预测与泛化性能具有重要影响[45],很多研究学者在模型超参数优化过程中将模型学习率、批尺寸、迭代次数等超参数作为主要影响因素,利用网格搜索、随机搜索和贝叶斯优化等方法对模型进行优化[46]。为此,将模型学习率、批尺寸、迭代次数三种超参数作为主要影响因素来研究其对模型性能的影响,此外,考虑到样本构造方式对的特殊性,将滑窗的窗口大小也作为主要影响因素进行研究。针对多因素的交互影响,普通实验设计方案需要大量重复实验且耗时长,为此,采用正交设计实验方法,该方法适合于多因素、多水平的研究,能够从众多实验数据中选取适当具有代表性的数据进行测试,这些实验数据具有分布均匀、齐整可比的特点[44]。此处以学习率(A)、批尺寸(B)、迭代次数(C)以及窗口大小(D)等四个超参数为因子,选取各因子的典型值作为水平值,每个因子选取四个水平值,其中,学习率分为0.005、0.01、0.015、0.02四个水平值,批尺寸分为16、32、64、128四个水平值,迭代次数分为50、100、150、200四个水平值,窗口大小分为10、20、30、40四个水平值,从而形成了四因子四水平的16组正交实验方案,如表2所示。此外,正交实验采用的输入特征参数组合为组合6,计算了不同实验方案预测得到的最大和最小水平地应力的评价指标RMSE、MAE和MAPE,结果如表2和图10所示。
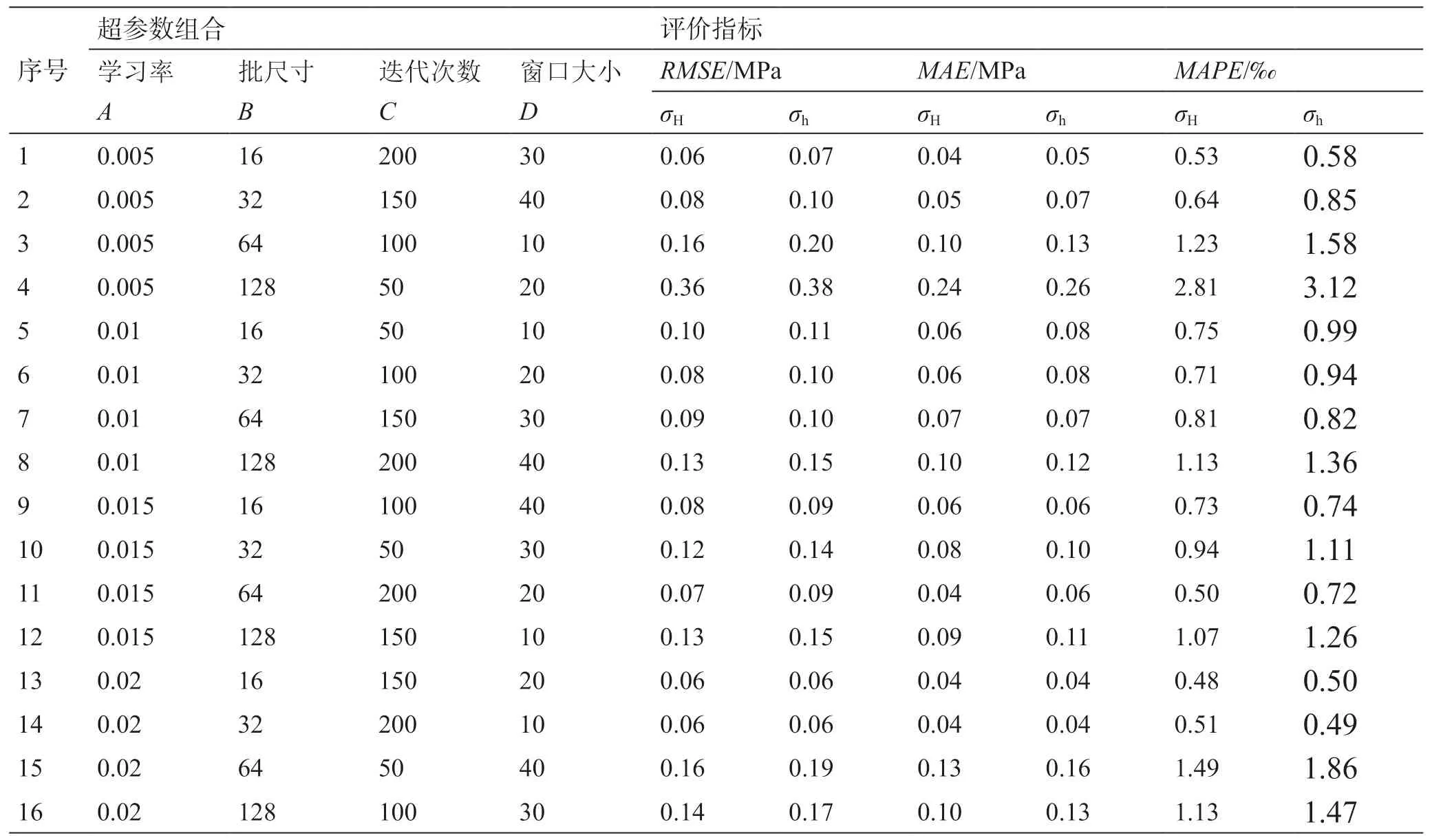
表2 超参数正交设计实验表及其对应的误差结果Table 2 Orthogonal design experiment table of hyperparameters and the corresponding errors
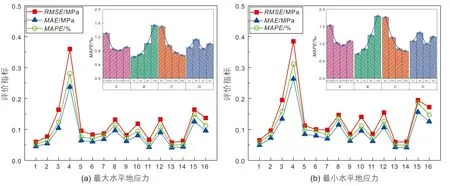
图10 不同实验方案预测结果的误差对比Fig. 10 Comparison of prediction errors in different experimental schemes
结合表2和图10不难看出:1) 不同超参数条件预测的最大和最小水平地应力误差总体相似,且最小水平地应力的预测误差略大于最大水平地应力;2) 除了第4组实验外,其余实验方案均能够将水平地应力预测误差控制在较小的范围内,其中,最大水平地应力预测结果的RMSE介于0.06~0.16 MPa、MAE介于0.04~0.13 MPa、MAPE介于0.48~1.49‰,最小水平地应力预测结果的RMSE介于0.06~0.20 MPa、MAE介于0.04~0.16 MPa、MAPE介于0.50~1.86‰,说明超参数对水平地应力的影响相对较小;3) 第13组实验预测得到的水平地应力误差最小,其中,最大水平地应力预测结果的RMSE、MAE、MAPE分别为0.06 MPa、0.04 MPa和0.48‰,最小水平地应力预测结果的RMSE、MAE、MAPE分 别 为0.06 MPa、0.04 MPa和0.50‰,因此,推荐采用学习率、批尺寸、窗口大小和迭代次数分别为0.02、16、20和150。
根据正交设计实验计算结果,分析了不同超参数对水平地应力预测误差的影响规律,结果如图10子图所示,不难看出:1) 随着学习率的增加,MAPE逐渐降低,当学习率为0.02时候,MAPE小幅增加;2) 随着批尺寸的增加,MAPE逐渐增加,与之相反,随着迭代次数的增加,MAPE逐渐下降;3) 窗口大小对MAPE的影响无明确规律,在模拟参数条件下窗口大小10或30的MAPE更低;4) 不同超参数影响下最大和最小水平地应力预测结果的MAPE变化趋势基本一致,但最小水平地应力预测结果的MAPE略高于最大水平地应力。
此外,按照方案13的超参数组合,对表1所述的7种输入特征参数组合的水平地应力进行了预测,预测结果如图9所示。图9a为参数优化前后最大水平地应力预测结果与测井解释结果的对比,图9b为参数优化前后最小水平地应力预测结果与测井解释结果的对比,其中,红色实线代表实际水平地应力,绿色实线代表预测得到的水平地应力,蓝色实线代表超参数优化后得到的水平地应力,通过分析不难发现:1) 按照第13组超参数对模型进行优化后,不同输入特征组合方式预测得到的最大和最小水平地应力的精度均得到了不同程度的提升,尤其是输入特征参数组合1~4提升最为明显,说明第13组超参数优化效果好且非常稳定;2) 超参数优化后,输入参数组合6预测的水平地应力误差最小,即输入参数组合6的预测结果仍然是最优的,而且,优化前后最大水平地应力预测结果的RMSE、MAE、MAPE分别降低了0.13 MPa、0.08 MPa和0.91‰,最小水平地应力预测结果的RMSE、MAE、MAPE分别降低了0.23 MPa、0.11 MPa和1.26‰,说明最小水平地应力的预测精度提升更加明显;3) 不同输入参数组合方式下,在增加或减少某一测井参数后的预测效果与超参数优化前的结论基本一致,也进一步说明输入参数组合6是最优的。
4.2 讨论
首先,分析了7种不同测井参数组合对预测水平地应力的影响。对于组合1,只加入了垂深作为输入参数,其预测结果表现为1条斜线,这是可以预见的,因为垂深本身呈线性,所以模型也只学到了这种线性关系;对于组合2,在增加了井径作为输入参数之后预测结果反而变差,常规测井解释中井径用于指示地层岩性和判别地应力方向,但对于最大和最小水平地应力的大小而言并无直接关系,因此,井径的增加给予了模型错误的权重配比,反而使预测效果变差;对于组合3,在增加了密度测井曲线作为输入参数之后,模型预测效果好转,因为密度测井曲线与最大和最小水平地应力的计算有直接关系,所以增加密度测井曲线有利于模型进行预测;对于组合5,在增加了自然伽马作为输出参数之后,预测误差进一步减小,说明自然伽马对水平地应力的预测也起到了一定作用,通常自然伽马用于识别地层岩性和确定泥质含量,显然也构成了计算地应力的积极要素;对于组合6,在增加了纵波时差之后,预测效果有了进一步提升,事实上纵波时差与地层构造应力之间有直接关系,通常当地层受到额外的构造应力时,纵波时差会偏离正常趋势线,因此,有学者利用这种关系建立起了预测水平地应力的经验关系式[47];对于组合7,当增加横波时差之后误差反而增加,可能是因为横波时差主要反映地层的岩性、孔隙度特征,与补偿中子、自然伽马、纵波时差等测井参数互为同质参数,说明过多的同质参数会使数据维度增加,一定程度上降低模型的学习效果,从而增加预测误差。综上所述,结合测井参数实际含义,当增加或减少某些测井参数后,由于不同参数对地应力的指示作用不同,使模型在学习过程中发生权重偏移,进而对不同参数组合模式下的预测结果表现出差异性。因此,综合考虑测井参数的实际含义和参数获取的难易程度,推荐使用垂深、井径、密度、补偿中子、自然伽马和纵波时差6种测井参数作为水平地应力的输入参数组合。
其次,采用正交设计实验方法设计了16组实验,研究了不同超参数对BiLSTM模型预测性能的影响。结果发现在输入参数组合6条件下16组超参数组合的精度都比较高,一方面是因为输入参数组合6为最优输入组合,可以确保模型训练效果和预测精度;另一方面,超参数取值范围通过经验设置在常用范围内,避免了因为梯度爆炸或者梯度消失而引起的精度降低。将输入参数组合6条件下优化获得得超参数用于其它6种输入参数组合,结果发现不同输入特征组合方式预测得到的最大和最小水平地应力的精度均得到了不同程度的提升,而且输入参数组合6的预测结果仍然是最优的。从预测结果来看,适当减小批尺寸和增加迭代次数可以增加模型预测精度,但减小批尺寸将导致模型学习效率的下降,增加迭代次数不仅增加训练成本而且增大了过拟合的可能性,因此,需要针对不同数据集,按照实际情况进行合理调参。对于本研究推荐学习率、批尺寸、窗口大小和迭代次数等超参数分别取值为0.02、16、20和150。
训练数据集数量限制,数据集样本获取途径单一,都是造成预测精度低的重要原因。考虑到工程中实际条件的限制,通常无法获取足够的测井数据集进行训练,因此,采用滑窗采样的样本构造方式和特征组合筛选实验来优化输入特征,并引入BiLSTM这一特殊循环神经网络来优化模型结构,另外设计了正交实验对超参数取值进行优化,以提高模型的预测精度和泛化能力。但是,本研究尚存在一定的局限性:首先,本研究仅对CL气田两口直井的测井数据进行测井解释、训练和验证,所建立的模型数据来源较为单一,因此有必要加入地震、岩心实验、矿场实测等多源、多态、多尺度的数据扩充训练样本集,从而构建出普适性和稳健性更好的地应力预测模型。其次,神经网络模型是基于经验风险最小化原则,在小样本预测问题中存在过度拟合的风险,因此在后续建模过程中可以尝试以结构风险为原则或以结构和经验风险相结合为原则的机器学习模型,强化模型在理论方面的引导,避免因纯数据驱动造成的模型可解释性和泛化能力降低的问题。
5 结论
1) X-1和X-2井地应力测井解释结果表明,地应力排序为垂向地应力>最大水平地应力>最小水平地应力,属于潜在正断层应力状态;对比测井解释和岩心差应变测试结果发现,垂向地应力解释误差为0.39%,最大水平地应力解释误差为0.18%~0.64%,最小水平地应力解释误差为0.29%,说明测井解释得到的地应力与实际地应力吻合较好。
2) 水平地应力与垂深、密度及自然伽马等测井参数之间表现为正相关,与纵波时差、井径、补偿中子及横波时差等测井参数之间表现为负相关;水平地应力与垂深之间相关性极强,与井径、密度、补偿中子、自然伽马、纵波时差、横波时差之间相关性相对较弱。
3) 不同测井参数蕴含了不同的地质信息,不同测井参数对地应力预测起到了不同的指示作用。通过对比7种不同测井参数组合模式发现,组合4~7的预测效果明显优于组合1~3,最优输入参数组合为组合6,即包括垂深、井径、密度、补偿中子、自然伽马、纵波时差;进一步,通过正交设计实验对超参数取值进行调优,最佳的超参数取值为学习率0.02、批尺寸16、窗口大小20,迭代次数150,预测得到的最大和最小水平地应力平均绝对百分比误差分别为0.48‰和0.50‰。
4) BiLSTM模型是一种可以实现水平地应力精准预测的机器学习方法,得益于BiLSTM对时间序列出色的处理能力,使得其能够有效捕捉测井参数随深度的变化趋势以及测井参数的前后关联信息。因此,推荐使用BiLSTM模型进行水平地应力的预测。
猜你喜欢
测井技术(2022年3期)2022-11-25
石油钻探技术(2022年5期)2022-10-17
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
能源与环保(2021年4期)2021-05-07
今日中国·法文版(2020年7期)2020-07-04
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
