
特征融合的双目立体匹配算法加速研究与实现
2023-01-03 08:17范亚博王国祥陈海军
导航定位与授时 2022年6期
范亚博,王国祥,陈海军,冯 威
(1. 西南交通大学地球科学与环境工程学院,成都 611756;2. 中铁二院工程集团有限责任公司,成都 610031)
0 引言
立体视觉是机器认识世界的重要手段。立体匹配是双目立体视觉技术中的一个重要环节,其通过左右两幅图像寻找匹配像素点,利用视差信息获取空间物体距离拍摄位置的距离[1]。双目立体匹配因其可靠、简便的特点,使其在机器人导航、自动驾驶、三维重建及距离测量等领域得到了广泛的应用。随着图像分辨率的提高以及实际应用场景中对数据信息实时性需求的愈发迫切,业界对立体匹配算法的实时性和准确性提出了更高的要求。
D.Scharstein等[2]对经典的匹配算法进行了总结,立体匹配算法通常分为以下4步:匹配代价计算、代价聚合、视差计算和视差优化。目前,立体匹配算法根据算法特点可以分为局部、全局、半全局和基于深度学习的立体匹配算法[3]。全局算法通过最小化全局能量函数得到最优视差,但计算复杂度较高,难以满足实时性要求。局部算法精度劣于全局算法,但计算复杂度低,能满足实时的要求。半全局匹配(Semi-Global Matching,SGM)算法结合局部和全局匹配算法的优点,具有复杂度低、效率高和易于实现等优点[4]。近来,卷积神经网络(Convolutional Neural Networks,CNN)[5]被应用于立体匹配算法中,实现了更高的匹配精度,但CNN巨大的计算消耗和密集度,使其很难应用于硬件资源有限的实时立体匹配系统[6]。
Census变换算法凭借其易于并行的优点成为主流的代价计算方法,但传统的Census变换过于依赖中心像素点,且受支持窗口尺寸的影响[7]。为提高Census变换算法的性能,专家提出了很多改进策略,主要有:1)采用变换窗口内所有像素的加权平均值代替中心像素灰度值[8];2)采用中心对称Census变换以及稀疏Census变换[9];3)改变Census变换窗口的尺寸和形状;4)融合其他具有互补特性的代价计算方法[10-11]。这些算法虽然能达到很高的精度,但由于算法的计算复杂度较高,仅依靠中央处理器(Central Processing Unit,CPU)计算难以满足实时性需求。近来,基于图形处理器(Graphics Processing Unit,GPU)并行计算平台对SGM算法进行并行加速取得了不错的效果[1,12]。因此,利用GPU加速已成为实时获取匹配信息的可行途径。基于此,本文提出了利用统一计算设备架构(Compute Unified Device Architecture,CUDA)对双目立体匹配算法进行并行加速,从而满足实时性要求。
1 双目立体匹配算法描述
算法具体实施步骤如下:首先,对校正后的图像对进行直方图均衡化预处理,在此基础上,采用灰度差绝对值之和(Sum of Absolute Differences,SAD)融合传统的Census变换以替代单一的匹配代价计算算法。利用四路径SGM算法进行代价聚合,使用赢家通吃(Winner-Takes-All,WTA)优化策略进行视差计算,最终通过左右一致性检验对遮挡点进行填充以及利用中值滤波剔除异常值,继而得到优化后的视差图。基于CUDA加速的双目立体匹配算法处理流程如图1所示。

图1 本文算法流程图Fig.1 Flow diagram of SAD-Census algorithm
1.1 特征融合初始代价计算
SAD算法具体流程为:用i、j遍历窗口W中每个像素,每进行一轮计算后d的数值增加1,以使右图像中的窗口在视差范围内移动。移动过程中,两个子窗口计算的像素灰度差绝对值之和最小时,即找到了与左图像窗口相匹配的像素块,此时的d为视差值。SAD算法计算公式为

(1)
式中,IL(x,y)、IR(x,y)分别为左、右图像中(x,y)位置的像素灰度值;d为视差范围。
Census变换[13]是一种局部非参数变换算法,以某一像素点为中心取一个m×n(一般m、n为奇数)的变换窗口,通过将邻域窗口内的像素灰度值与窗口中心的像素灰度值进行比较,将得到的布尔值连接成一个二进制比特串。对左、右图像得到的两个比特串进行异或运算,统计计算结果为1的个数,即为汉明距离(Hamming distance),最后用汉明距离代替原来中心像素的灰度值。基于Census变换的初始匹配代价计算过程如图2所示。

图2 基于Census变换的初始代价计算示意图Fig.2 Calculation of the initial costs based on Census transform
SAD算法匹配速度快,但对曝光度和光照变化较为敏感。Census变换是基于窗口内的相对亮度差,对整体的明暗变化并不敏感,在重复纹理区域易产生误匹配。因此,将两个算法进行融合不但可以提高匹配精度,而且对光照条件和曝光差异也可以保持良好的鲁棒性。同时,SAD和Census变换都是基于局部窗口运算,每个像素之间互不影响,可以独立运算,该特性使其可以设计多线程并行计算模型,但融合时需要考虑两个算法在不同场景下的权重。为了使得到的初始代价值更可靠,将SAD和Census变换窗口的尺寸考虑进公式中,特征融合后的初始代价值计算公式为
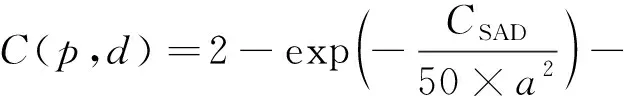
(2)
式中,C是代价值;a是SAD算法窗口的大小;m、n表示Census变换窗口的大小。
1.2 匹配代价聚合
由于初始代价计算只考虑了局部窗口信息,易受噪声的影响。为了获得更准确的代价值,本文采用SGM算法[4]进行代价聚合。算法主要是将二维图像的优化问题转换为多条路径的一维最优问题,使用从整个图像各个方向聚合的路径优化来近似全局能量。聚合路径的数量会影响视差图的质量和算法的性能。对于像素点p,沿着某条路径r在视差为d时的代价聚合公式为
(3)
式中,第一项为初始匹配代价值;第二项为路径r上前一个像素点的最小匹配代价,P1和P2为视差不连续惩罚因子,且P1>P2;第三项是为了防止聚合代价值过大而减去上一像素的最小代价值。
将各个路径上的代价值相加即为该像素点的最终代价值,计算公式为
(4)
1.3 视差计算与视差优化
对代价聚合步骤得到的匹配代价,采用比较经典的WTA算法进行视差计算,即为每个像素选择所有视差下代价值中最小的代价值所对应的视差作为最优视差。
为了对视差计算步骤得到的视差图做进一步的优化处理,获得更加准确和密集的视差图,本文采用左右一致性检验有效地检测遮挡点和误匹配点,遮挡区域大多来自于背景,所以往往用背景视差值填充。由于图像对本身存在噪声以及填充后的视差可能存在异常值,采用中值滤波进行剔除,最终得到优化后的视差图。
2 双目立体匹配算法并行加速
利用CUDA进行算法加速设计时,首先要最大程度地利用GPU多线程的优势;其次合理使用各种设备内存,优化内存访问速度;最后利用多个CUDA流同时启动多个内核,实现核函数之间的并行加速计算。CUDA程序的并行层次主要分核函数内部的并行和核函数外部的并行。
2.1 核函数内部的并行
核函数内部并行的高性能很大程度上取决于对各种设备内存的合理使用。由于设备内存的带宽可能是性能瓶颈,高效的CUDA代码应该促进共享内存和寄存器内存上的数据重复利用。由于图像对数据从CPU传入GPU时需要占据较大的显存空间,一般是存放在全局内存中。非连续的、重复的访问全局内存,会使算法的性能大大下降。
算法优化的思路如下:设图像对的宽、高分别为W和H,匹配窗口的大小为m×n,视差范围为d。计算SAD特征和Census变换时,每个线程对应一个像素点,为每个线程块(Block)分配32×32个线程,考虑到线程块的边缘线程无法通过共享内存访问相邻Block的数据,因此相邻Block之间需要一定的重叠,整张图像被划分为(W-[m/2])/(32-[m/2])×(H-[n/2])/(32-[n/2])个Block([*]表示向下取整运算)。左、右图像每个线程块中需要读入共享内存的数据如图3蓝色矩形所示,红色矩形表示当前操作要处理的线程块,右图中的红色矩形在视差范围内向右移动。利用同步函数进行处理后,线程块内的所有线程都可以从共享内存中读取数据进行计算。算法将大量重复、非连续的访问全局内存改为重复访问速度更快的共享内存,大大地提高了算法的执行效率。

图3 SAD和Census变换算法加速模型Fig.3 SAD and Census transform algorithm acceleration model
2.2 核函数外部的并行
要想使算法获得更高的性能,需尽量减少主机与设备之间的数据传输以及在主机中进行的计算。因此,算法设计时把立体匹配算法比较耗时的4个步骤都放在设备中进行计算。该方式可以减少主机与设备之间数据传输带来的额外开销。同时,利用多个非默认CUDA流(stream)实现核函数之间的并行,进一步提高了设备利用率。
SAD算法和Census变换都是基于输入的图像对进行操作,两者相互独立,可以并行计算,但完成不同的CUDA流彼此间可能需要等待,因此需要同步操作。在核函数的执行配置中必须包含一个流对象,核函数的调用方式为:kernel <<

图4 串行运行和多流并发执行性能对比Fig.4 Performance comparison of serial operation and multi-stream concurrent execution
考虑到每个像素的聚合代价值都是上、下、左、右4条路径下的代价值累加的结果,在一条指定路径下,需按顺序依次执行每个像素的代价聚合,这在一定程度上影响了算法的并行性。但每条路径只是聚合方向不同,其他操作完全相同。因此,几条路径间是彼此独立执行的,所以,为每条路径单独设置一个核函数,利用共享内存且执行同步操作,待所有核函数执行完毕后,把各个路径的代价值相加,得到最终的代价聚合值。
3 实验结果与分析
3.1 测试平台和测试数据集
为了充分测试算法的匹配精度和执行效率,对实验环境进行搭建,实验环境和平台信息如表1所示。采用Middlebury立体匹配算法测试平台[14]提供的Venus、Teddy及Cones标准彩色图像对算法进行实验,以此来评价算法的准确性和实时性。

表1 实验环境平台介绍
3.2 立体匹配算法性能分析
本文采用速度评估标准和精度评估标准测试CUDA算法的优化效率和匹配准确性。速度评估标准指算法的运行时间,精度评估标准是与Middlebury数据集提供的标准视差图进行比较,计算出整张图像全区域的误匹配率。
在测试算法的效率优化性能时,对实验过程中的变量进行控制,将各图像对的视差范围依次设置为64像素和128像素。经过多次实验,匹配效果最佳时,其他参数设置如下:SAD窗口尺寸为5×5,Census变换窗口尺寸为9×7,聚合代价路径数为4。利用本文算法对不同分辨率的图像对进行测试,结果如表2所示。
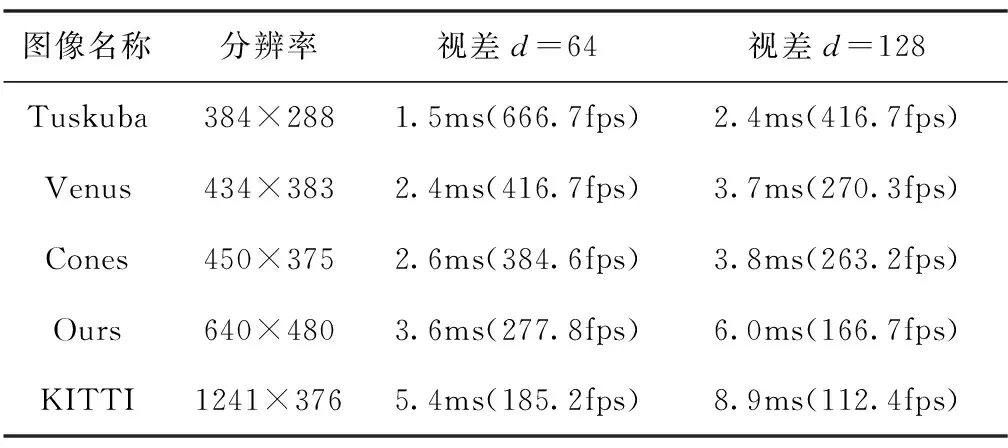
表2 不同视差情况算法匹配耗时
从表2可以看出,本文所提立体匹配算法对于不同分辨率的图像基本上都能实现实时匹配。当图像分辨率为384×288,视差范围为64像素时,帧率最高可达到666.7fps;当图像分辨率为1241×376,视差范围为128像素时,帧率较低,可达到112.4fps。表2中的结果表明,基于CUDA加速的立体匹配算法具有较好性能,在处理较大图像分辨率图像时也可满足实时性要求。
为了更全面地验证本文算法的效率,将该算法与其他加速算法进行比较。虽然不同算法的运行环境均不相同,但平台的性能差异相差不大。实际上算法自身的并行性、算法的优化策略以及算法中涉及的一些参数都会影响运行环境平台的性能。在图像分辨率和视差范围相同的情况下比较算法的测试结果,如表3所示。
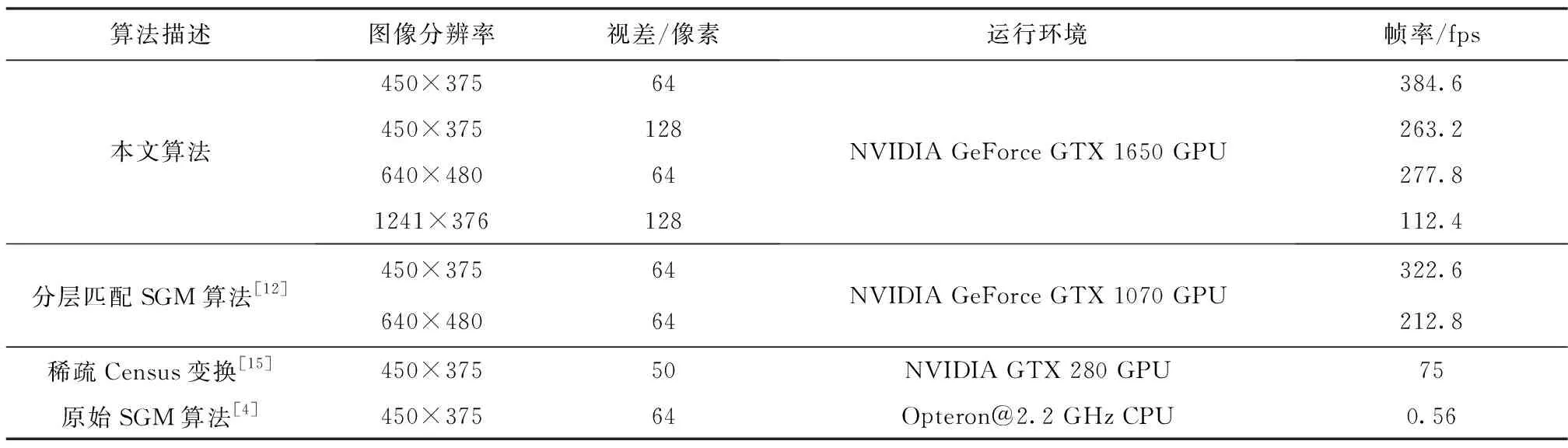
表3 本文算法与其他加速算法的对比
由表3可知:本文所提算法的实时性优于其他算法,在NVIDIA GeForce GTX 1650平台上实现了非常高的实时性能。处理450×375图像分辨率,视差范围为64时,最高可达384.6fps的匹配效率,比原始的SGM算法快687倍。与稀疏Census变换算法相比,可实现5.1倍的加速比。除去平台自身性能优势,加速效果也很不错。
为了验证算法的匹配精度,图5所示为算法的测试结果。由于Venus图像的纹理丰富,生成的视差图边缘较准确;而对于弱纹理较多的Teddy图像,部分叶子连成一体,但能较大程度上恢复出玩具熊和房子的轮廓;Cones视差图中圆锥和面具模型的轮廓都比较清晰,边缘部分略有噪点,这进一步说明融合算法的准确性得到提高。

(a)左图像
为了更好地评估生成视差图的效果,图6所示为各图像在不同算法下的全区域误匹配率。通过计算所有区域下各个测试集图像的误匹配率的平均值,得出本文算法的平均误匹配率为10.4%。由图6也可知,本文算法的立体匹配精度高于Edge-Gray算法[16]和V-SAD算法[17],平均误匹配率分别下降了8.05%和3.22%,并且Edge-Gray算法和V-SAD算法在执行高分辨率图像时,实时性效果远不如本文所提算法。

图6 不同算法的视差图误匹配率Fig.6 Disparity map mismatching rates of different algorithms
此外,为了进一步验证算法在复杂道路场景下的准确性和实时性,本文测试了KITTI 2012数据集中自动驾驶场景下的图像,得到的视差图如图7所示(未对孔洞插值补全)。面对不同的光照和遮挡环境,本文算法得到的视差图可以清楚地看到路上行人、街道两旁树木以及汽车的轮廓。由上文可知,对于1241×376分辨率的室外道路图像,在128视差范围下能达到112.4fps的实时性能。由此可以得出该算法在复杂的室外道路场景下仍具有较好的适用性。

(a)左图
4 结论
针对传统双目立体匹配算法计算复杂度高且难以满足实时性要求的问题,本文提出了将SAD和Census变换特征融合的结果作为初始匹配代价,并对立体匹配算法耗时的4个步骤设计了基于CUDA的并行计算加速模型。算法分析与实验结果表明:
1)利用SAD和Census变换特征融合计算代价可以改善Census变换过于依赖中心像素点带来的影响,并且它们都是基于局部窗口运算,每个像素之间独立运行,使其可以设计并行计算模型。
2)数据传输过程中,最大化地利用共享内存、寄存器内存以减少全局内存的读取次数,使用多个CUDA流操作实现了不同核函数之间的并行。将本文算法与相关加速算法进行对比实验,结果表明,所提算法平均误匹配率下降了8.05%,且比原始SGM算法快687倍。
3)算法在运行高分辨率图像(1241×376)时依然能够达到很好的实时显示性能(112.4fps)。同时,面对复杂的室外道路场景时,本文算法的准确性和实时性也表现突出。
猜你喜欢
小型微型计算机系统(2022年1期)2022-01-21
计算机与数字工程(2020年11期)2020-12-23
疯狂英语·新悦读(2020年6期)2020-06-28
北京航空航天大学学报(2017年12期)2017-04-23
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年24期)2016-11-14
科教导刊·电子版(2016年23期)2016-10-31
现代计算机(2016年3期)2016-09-23
电脑知识与技术(2016年15期)2016-07-04
哈尔滨理工大学学报(2016年1期)2016-05-31
