
基于云计算的数据库安全控制策略分析
2022-12-29 11:02李雪瑶
计算机应用文摘·触控 2022年24期
李雪瑶








关键词:云计算;数据库;安全控制策略
1引言
传统的数据库安全控制策略主要使用底层物理隔离的方式实现对不同用户的数据隔离,通过每个用户使用独立储存服务器的方式建立物理屏障,在此基础上搭建应用服务器、OS和APP等,所以用户和用户之间的数据存储方式为垂直独立储存,不会产生交叉混淆,用户隐私安全风险较低。但云计算的应用将原本独立的储存服务器集成为一个统一的储存集群,同日寸供给多个用户进行使用,隔离方式从传统的物理隔离被迫转变为逻辑隔离。这种一对多的数据存储方式虽然能够节约储存服务器、提升数据处理效率,但在多用户同时使用过程中难免会出现数据交叉混淆的情况,由此导致大量用户隐私数据暴露在公共区域下,频繁的数据存取势必会成为造成用户隐私安全隐患的潜在因素,所以如何在保留云计算便捷、迅速等优势的同时,提升数据库安全性能,成为当前的热门课题。
目前,主流的云计算数据库安全控制策略分为数据加密和数据混淆两种,其中数据加密是将传统的数据库安全控制策略套用到云计算数据库中,通过较为复杂的加密方法对数据库进行编辑,再给云计算用户发放进入数据库的专属密钥,这种数据库安全控制策略虽然安全性较高,但加解密操作较为烦琐,需要大量的计算,并且使用密钥控制的方式给用户带来较多的冗余操作,与云计算的应用优势相悖。数据混淆是使用匿名和泛化的方式,隐藏暴露在公共区域的用户隐私数据,进而实现对数据的保护,这种方式虽然计算速度较快,但在用户读取数据时,需要花费大量时间进行数据重构,与云计算的应用优势相悖。针对这种现象,本文同时考虑数据隐私保护和数据使用效率两方面,提出一种无需加密、匿名和泛化的主动隐私保护数据库安全控制策略,对信息熵大的属性进行主动保护。
2总体方案
本文提出的主动隐私保护的数据库安全控制策略主要分为两部分,一部分是对数据库中的用户数据表进行划分,另一部分是以划分信息熵作为判断条件,实现主动因素保护的策略,总体方案如图1所示。
3主动隐私保护数据库安全控制策略的实现
3.1划分目标
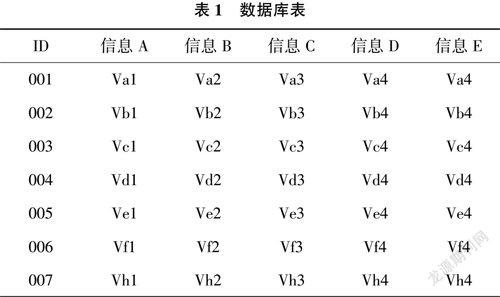
数据库中每个用户的数据都集中存放在同一个数据表中,即划分目标,如表1所列。
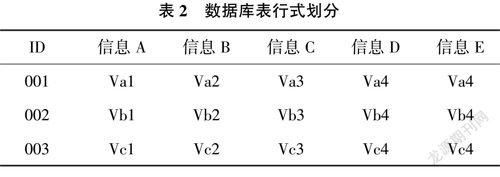
受传统物理隔离的数据库安全控制策略影响,传统方式会将数据表进行行式划分存放,能够通过保留数据的完整性来提升数据存取效率,使用行式划分表1中的数据后可以得到表2和表3。
根据表2和表3可以得知,行式划分后的数据较为完整,仅对用户进行区分,一旦数据库受到攻击,攻击者能够通过行式划分后的数据表轻松得到一个用户的全部信息,所以行式划分方式的用户隐私安全风险较高。针对这种现象,本文提出列式划分方法,通过列式划分表1中的数据可以得到表4和表5。
根据表4和表5可以得知,列式划分将同一用户的多种信息进行切割划分,这样即使攻击者得到部分划分表格,也无法获得用户的完整信息,大幅度提升用户隐私安全性。根据列式划分的理念,将同一用户的信息划分得越细,用户隐私安全性越高,但用户调用信息的效率会越来越低。所以用户隐私安全和信息调用效率之间的平衡是列式划分的关键,找到平衡需要注意以下几点规则。
(1)列式划分需要在保证数据稳定的前提下进行划分,避免由于触碰SLA(Service-LevelAgreement,服务等级协议)导致用户数据丢失。
(2)列式划分后的数据应当保持待响应状态,用户能够立即调用获取、重构原有数据。
(3)列式划分的数据属性不能存在相交状态,在划分过程中应当对数据表中的用戶信息属性进行深人发掘,获得紧密关联的信息属性集合,为后续的主动保护判定提供数据基础。
3.2相关定义
3.2.1隐私约束
隐私约束从约束内容上可以分为三种,分别是组合隐私约束、值隐私约束和依赖隐私约束。其中,组合隐私约束代表两个基本用户信息能够组成关键的用户隐私,如用户的姓名和用户的身份证号码,两个用户信息的单独出现对攻击者没有意义,当组合出现时则能够泄露用户的身份信息;值隐私约束代表用户信息中的某一个取值是关键用户隐私,例如用户的所在地信息,其中所在城市、所在区信息对攻击者的价值较低,但所在小区、所在单元等具体所在地信息对攻击者的价值较高:依赖隐私约束代表能够根据两个基础信息的关联,推断出用户的关键隐私,例如老师的主教学科和学生姓名放在一起,就能推断出学生的所学专业。
3.2.2隐私属性划分
根据上述组合隐私约束、值隐私约束和依赖隐私约束三种隐私约束,本文将隐私属性划分为多个子集,子集的唯一要求就是不违背隐私约束。
3.2.3属性关联度
属性关联度代表两个或两个以上用户信息之间的关系,可以通过用户访问的频次进行表示,用户连续访问的频次越高,代表用户信息之间的属性关联度越高,反之越低。统计用户访问频次需要建立一个操作频次统计表,通过历史操作记录、操作中的属性集合、操作次数进行频率统计,具体如表6所列。
3.3主动保护策略
根据克劳德·艾尔伍德·香农提出的香农熵(Shannonentropy)定义,表示某一系统的复杂度、香农熵越大,系统越复杂。所以系统中划分出的信息熵越大,说明该信息的价值越高,那么根据信息取值情况,确立一个信息熵阈值,当信息熵超过阈值时主动进行数据安全保护,就能实现主动隐私保护的数据库安全控制策略。信息熵的取值根据两个维度确定,第一个维度是该用户信息本身的价值,本身价值越高,信息熵越高,反之越低,例如用户的“身份证信息”,属于一一对应的关键信息,通过一项信息就能标识一个人,所以“身份证信息”的价值较高、信息熵较高。第二个维度是该用户信息的范围,范围越广泛,信息熵越高、反之越低,例如用户的“就业状态信息”,其中包括“已就业”“未就业”“即将结业”“未毕业”等多种状态,“已就业”更可以划分为“教师”“企事业单位”“个体”等不同职业,当攻击者获取用户的“就业状态信息”后,可以通过对信息的细化分析,推断出用户的就业隐私,所以“就业状态信息”的价值较高、信息熵较高。
根据上述两种信息熵的取值维度,本文提出数据库用户属性信息熵,来表示众多用户属性信息的重要程度,设定信息熵阈值。并对数据库用户属性信息熵超过阈值的信息进行主动保护,将数据库用户属性信息熵较大的信息进行独立划分或者分区划分。基于此,设数据库用户属性信息熵为S,计算方法如下:
(1)根据式(1)计算数据库中每个用户属性信息熵取值。
(2)根据式(2)判断每个用户属性信息熵是否超过阈值。
(3)若用户属性信息熵低于阈值,则按照普通的隐私约束规则进行列式划分:若用户属性信息熵高于阈值,则利用式(3)中的隔离因子a把包含该属性的操作对应的值减去buffering的值,设包含该属性的信息熵值为x1,则隔离后的信息熵值为x2,如下:
3.4划分方法
通过上述方法设定信息熵的阈值,并计算出数据库中用户信息属性的信息熵取值后,可以初步实现数据库主动保护策略,但对数据存取的效率具有一定影响,没有达到用户隐私安全和信息调用效率之间的平衡,所以需要建立划分算法,通过属性关联度,计算出统一数据库中关联程度较高的用户属性信息,再通过列式划分方法将此类属性信息划分到同一数据表中,进而实现信息调用效率的提升。需要注意的是划分到同一数据表需要通过隐私约束规则,具体算法步骤如表7所列。
3.5算例分析
本文以某云计算用户数据库为例,该数据库中的某个用户的属性集为{A,B,C,D,E},按照上述算法计算出该属性集的频繁项集如表8所列。
根据表8可以得知,该用户的操作频繁项,用户的隐私约束确认用户属性A和用户属性B互为依赖隐私约束,所以用户属性A和用户属性B不能划分到同一数据表中。将同时包含用户属性A和用户属性B的候选项集进行删除后得到表9。
通过式(1)计算后得出用户属性A的信息熵为0.6、用户属性B的信息熵为0.7、用户属性C的信息熵为1.7、用户属性D的信息熵为0.8、用户属性E的信息熵为1.3;信息熵为1;隔离因子a设备10。计算后得到用户属性C和用户属性E超过信息熵阈值,所以需要对用户属性C和用户属性E进行隔离划分,隔离后的频繁项集如表10所列。
根据表10可以得知,应该将属性{B,C,D}划分到一个数据中进行存储,剩余的用户属性A和用户属性E之间没有属性约束,则将用户属性A和用户属性E合并放人一个数据划分表中进行存储。这样的划分方式既能避免将属性信息熵高的属性划分到一个表中,又对属性隐私进行了主动保护。由此验证本文控制策略的有效性。
4结束语
本文基于云计算对数据库安全控制策略展开分析,提出一种主动隐私保护的数据库安全控制策略,首先阐述总体设计方案,再从四个方面说明本文数据库安全控制策略的实现路径,并以算例分析验证本文控制策略的有效性。在云计算多用户共享同一个储存服务器集群的场景下,使用本文的主動隐私保护数据库安全控制策略,能够达成数据库用户安全和用户信息存取效率的平衡,避免传统数据库安全控制策略对用户使用舒适度的损害。
猜你喜欢
财经(2017年15期)2017-07-03
财经(2017年2期)2017-03-10
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
