
基于数据仓库的网络医学信息资源整合系统
2022-12-28 11:21吴亮
中国新技术新产品 2022年19期
吴 亮
(南京市妇幼保健院,江苏 南京 210004)
0 引言
网络技术、信息技术与医学领域融合发展,推动了医学信息化建设发展。网络中存有大量的有价值的医学信息资源,这些资源不仅量大,而且种类较多,采用最传统的人工方式对其进行整合具有较高的难度,全国各大医院都致力于研发出适合自身需求的信息资源整合系统。随着医学领域和行业信息化建设不断推进,网络医学信息资源整合技术逐渐受到关注。但是国内在该方面起步比较晚,相关技术还不够成熟,虽然已经取得了一定的研究成果,但是实际应用效果并不是很好。文献[1]设计了基于人工智能的分布式多媒体数据库资源整合系统。首先在B/S三层逻辑架构模式的基础上设计系统框架,其次进行系统硬件设计,包括集成芯片、传输设备、整合设备、储存设备和检索共享装置,最后设计系统硬件运行逻辑,即系统软件。但是该系统的丢包率较高,在实际应用中经常出现数据丢失的情况,整合后的信息资源完整性较低,已经无法满足网络医学信息资源整合的需求。
针对上述系统存在的问题,该文设计了基于数据仓库技术的网络医学信息资源整合系统。该文试图利用数据仓库技术对信息资源进行整合,形成一个新的信息资源整合系统设计思路,保证网络医学信息的完整性。该文设计系统的具体细节如下:1)给出数据仓库的定义,并分析数据仓库的特点。2)设计系统硬件部分,包括网络信息采集器、数据收发器和数据转换器。3)根据数据仓库的概念和特点设计系统软件部分。在数据库的设计原则下,根据管理系统选型,利用数据仓库技术设计数据库,并根据信息资源的编码对信息资源分层,进而实现对医学信息资源的整合,完成系统设计。
1 数据仓库的概念和特点
1.1 数据仓库的定义
数据仓库是基于人们对数据库的常年使用而扩展出来的,能够更适应社会需求,具备更高科技以及深层次的应用和数据管理技术。作为数据组织和存储的载体,它更容易建立适用于分析研究的数据模型,其加工出来的数据可用于决策支持系统,并能支持数据的挖掘,该数据的最终作用是为人们提供更具有决策作用的信息,帮助人们进行数据的挖掘和分析。数据仓库之父Willian H.Inmod曾经在《Building the Data Warehouse》一书中对数据仓库做出过这样的描述:“数据仓库是一个面向主题的,集成的,随时间变化的,非易失性的,用于管理人员的决策的数据集合。”从该描述可以发现,数据仓库的作用是在多个异构数据库中把符合主题的提取出来,并重新进行排列组织,保持数据的一致性、全面和贴合主体的特点。并且仓库中的数据是长期保留而非随时变化的,它能够综合反映出历史的变化与发展。数据仓库提高了数据的质量和一致性,同时也保证了数据的稳定性。通过对多个数据来源的数据进行检索可以实现对数据的连续化、存贮与分析,进而实现数据价值的最大化,增强了业务的智能化。
1.2 数据仓库的特点
从数据仓库的涵义来看,数据仓库具有4个特征:以对象为中心、主题化、一体化和相对稳定性。根据企业的需要,可将其分为不同的领域,对其进行分类和储存。通过对现有的数据进行分离、清洗和处理,最后将数据进行处理、转换和整合,进而达到解决数据不一致性的目的。数据一旦被录入数据仓库里面,通常都是长久地存储,每隔一段时间就会增加一次,除非遇到紧急情况,否则很难对其进行改动和删除。因此,在数据仓库中,可以全面地反映企业在不同生产过程中的各种数据,进而为公司提供量化的、动态的发展方向和对发展方向的预测。见表1。

表1 数据仓库的特点
2 系统硬件设计
系统的硬件主要由网络信息采集器、数据收发器和数据转换器3个硬件设备组成,系统硬件拓扑图如图1所示。
如图1所示,由网络信息采集器对医学网站和网页上的信息资源进行获取,利用数据收发器接收获取的信息资源,将其发送给数据转换器,并对网络信息资源进行格式转化,再由数据收发器将转换后的数据信息发送到系统数据库存储和整合,以下将对该3个硬件设备的选型与设计进行详细阐述。

图1 网络医学信息资源整合系统硬件拓扑图
2.1 网络信息采集器
网络信息采集器是系统的核心硬件设备,主要是获取医学网页、网站上的信息,该文选取型号为SFOA/55545网络信息采集器。系统根据用户需求,由服务器向网络信息采集器发送医学信息资源获取任务,形成一个任务清单。当采集器任务清单排列满时,根据任务要求形成医学网页、网站检索词条,对医学网页、网站进行搜索。采集器在网页属性中将网址信息记录到历史日志中,并对该网页中的医学资源信息进行评估。评估的主要依据为网页中的医学信息与系统数据库中医学信息的重复率。在采集器上设定一个医学信息资源下载阈值,如果重复率超过该阈值,则自动放弃该医学网页;如果重复率未超过该阈值,则将该网页中的医学信息资源锁定,对其进行自动下载。为了保障系统数据安全,该文为系统配备了一个防火墙,将进入系统中的数据信息来源与采集器自动记录在历史日志中的网址进行比对,如果比对成功,则允许数据包进入;如果比对不成功,则阻挡数据包进入。
2.2 数据收发器
数据收发器的主要作用是接收和发送网络医学信息资源。考虑网络信息资源量较大,该文为系统选择了型号为OSUAF/2344的数据收发器。该收发器由发送器、接收器、缓冲器以及硬盘4个部分组成。硬盘大小为32 GB,可以为网络医学信息资源的接收和发送提供充足的空间[2]。网络信息采集器将获取到的医学信息资源发送给缓冲器,将缓冲器数据列表属性设定为10或者50。当接收到的数据包数量达到设定值时,形成驱动条件,此时停止接收数据包,将接收到的数据包发送给接收器。接收器将接收到的数据包发送给发送器或者发送到硬盘上,然后驱动缓冲器接收下一篇网络医学信息资源。根据系统指令,发送器将网络医学信息资源发送给数据库或者数据转换器。
2.3 数据转换器
考虑医学信息资源来自于不同的网站和网页,其格式会有所差异,因此该文利用数据转换器将网络医学信息资源进行格式转换。该文选择型号为FSAFE-5644的数据转换器,通过标准的网络接口接收到网络医学信息资源。该转换器在遵循数据一致性标准的基础上,为每个数据包设定一个数据存储形态[3]。将原始数据统一转换为ESRI Shapefile,并将数据的编码格式统一。患者信息的编码为40001002010,医疗保险类信息的编码为40001002011,医生信息的编码为40001002012,药品信息的编码为40001002013,治疗信息的编码为40001002014[4]。此外,转换器还将数据的存储格式转换为word(Doc),将转换后的医学信息资源发送给数据收发器,由数据收发器将其发送到系统数据库中。
3 系统软件设计
3.1 基于数据仓库技术的数据库设计
3.1.1 基于数据仓库技术的数据库的设计原则
“全病历扫描光盘刻录检索系统”以关系性数据库的设计为基础。数据库设计的基本原则就是在系统总体信息方案的指导下,各个库应当为它的各个用户管理目标服务。设计数据库时应重点考虑以下几个因素:1)数据库必须分布合理,层次分明。2)数据库的组织结构化、规范化和标准化是数据库建设和数据交流的前提。严格地说,数据库是按照数据结构来组织、存储和管理数据的仓库的。数据结构的编制要遵循国家卫生部和广东省卫生部等相关工业规范,需要特别注意代码的使用,以实现数据的标准化和结构化,提高数据的使用效率。3)进行数据库设计时,应尽量减少系统的冗余度,减少内存的使用,并减少数据的相容性问题。同时要注意合理的冗余度,以加快系统的开发效率,减少系统的开发困难。4)数据的准确性和连贯性都要保持。在现实中,多个用户共用一个资料库会造成并行作业和资料的连贯性。5)建立对应的安全措施,因为资料库的资料具有特殊的使用者的保密性,因此需要针对具体的应用提供相应的安全措施。
3.1.2 基于数据仓库技术的数据库模型设计
数据库是系统的核心软件,主要是对网络医学信息资源进行存储管理。根据网络医学信息资源特点,该文选择数据仓库技术对系统数据库进行设计。网络医学信息资源大致可以分为患者信息、医疗保险信息、医生信息和治疗信息4类[5]。利用数据仓库技术设计相应的数据类,即patient_information、medical insurance_information、doctor_information和treat_information,进而形成系统库的概念模型,如图2所示。
将设计好的概念模型通过ODBC接口直接生成数据仓库,对相应的数据表创建,以表格的形式对数据进行分类存储。如图2所示,患者信息表存储患者名称、ID、性别、年龄以及户籍等信息。医疗保险信息表用于存储医疗费用类型、医疗保险号和医疗报销记录等信息。治疗信息表存储就诊科别、医院号、病案号、住院号以及健康记录等信息。医生信息表存储医生名称、医生ID、年龄、级别、医生号以及家庭住址等信息,防止存储的医学信息资源混乱。

图2 基于数据仓库技术的数据库概念模型图
3.2 基于数据仓库技术的管理系统选型
医学信息系统的应用实际上是建立在一个数据库的基础上,在实际应用中,数据库的运行与应用都与之息息相关。所以,如何正确地使用和维护数据库是一个非常关键的问题。这关系到一个整体的性能,关系到系统的应用模式和开发模式。
以客户/服务器计算模式为基础的数据库管理系统种类繁多,包括Microsoft的SQL、IBM的DB2以及oracle、Sybase、Informix等。在数据库服务器的选择过程中要考量SQL的扩展与支持情况,这关系到处理速度、资料吞吐量、交易的完整与可恢复性、并发性与系统安全性、可扩展性及系统的管理工具等。因此,该课题对数据库管理系统的研究选用Microsoft SQL Server 2000。
SQL Server开始于Sybase SQL Server,这是自微软推出后,SQL Server最大的一个版本。该软件具有良好的系统可用性、恢复性以及在线事务处理能力,可提供有效且完全的使用者自定义和高效的程序设计。例如,医学资讯系统需要每周7天、每天24h连续工作,无法设想出现10min的故障会带来什么后果,更不允许出现数据丢失的现象。而 SQL SERVER 2000则可实现镜像硬盘、在线备份以及事务记录还原技术,所以该文采用安全可靠的SQL SERVER 2000,以减少故障造成的损失。
随着资料的快速传递,人们可以更快、更全面地搜集和处理更多资料,同时资料的处理也更复杂化。在系统的运行和应用中很多性能都得到了显著增强,如图像管理、复制、XML集成、数据的转换和数据仓库等方面。应用软件的功能更强大,服务更个性化,进而推动了行业的发展。特别是数据仓库的建立与设定方面,微软设计了整套的完善过程路径,在图形管理、复制、数据转换、分析服务和数据仓库方面的功能也显著增强。尤其是在建设数据仓库方面,已经为它所需的全部过程设定了一条完善的途径,通过将各种技术与业务相融合,可以更容易地建立和设计具有性价比的资料仓储。
3.3 信息资源分类分层整合
资源整合是系统主要功能之一,该文运用分类分层技术对网络医学信息资源进行整合处理,便于用户对信息资源的提取。假设待整合医学信息资源为k,其提取公式如公式(1)所示。

式中:g为网络医学信息的特征;n为网络医学信息的特征数量;kn为医学信息资源第n个单项特征[6]。
通过调整、校对提取的信息特征,得到的信息特征偏差如公式(2)所示。

式中:rg为网络医学信息资源的特征偏差;S为信息特征的纵向微调系数;S0为信息特征的横向微调系数[7]。
按照公式(2)对网络医学信息资源k相邻的信息资源特征偏差进行计算,并将特征偏差标记在数据属性上。按照偏差的大、小对医学信息资源进行排序,将相邻的2个信息资源归为一类。并根据信息资源的编码对信息资源分层,进而实现对医学信息资源的整合,完成系统设计。
4 试验论证分析
该文以南京市妇幼保健院为试验对象,利用该文设计系统与传统系统对该医院网络医学信息资源进行整合。将该院所有医学信息网站作为数据来源,对近7天的该医院信息网站上的医学信息资源进行采集、转换、分层、分类和整合,原始数据公700 GB,为了保证试验结果的可信度,2种系统均以windows 2010为操作系统。试验准备了网络信息采集器、数据收发器和数据转换器各1台,服务器3台,显示器1台。系统组装完毕后,对网络信息采集器参数进行设定,将其数据采集频率设定为1.16 Hz,数据采集周期设定为0.25s,缓冲器缓冲列表数据参数为10个。将丢包率作为该文试验的唯一指标,使用OSDYA软件监测2种系统的数据丢失量,即整合前、后网络医学信息资源差值,计算出2种系统丢包率,并使用电子表格对其进行记录,具体数据见表2。
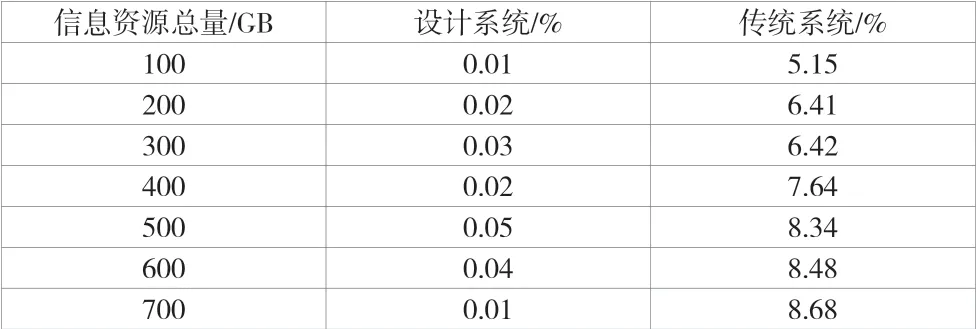
表2 2种系统丢包率对比
通过对表2中的数据进行分析可以得出以下结论:该文设计系统在试验过程中丢包率最大仅为0.05%,并且不会受信息资源量多、少的影响而发生变化,丢包率较低,说明该设计系统在对网络医学信息资源整合过程中,很少出现数据丢失现象。而传统系统在试验过程中丢包率最大可以达到8.68%,并随着网络医学信息资源量的增加,丢包率也随之增大,远远高于该文设计系统。因此试验结果证明,在数据安全方面,该文设计系统优于传统系统,能够有效保证整合后的医学网络信息资源的完整性和安全性。
5 结语
该文在传统系统基础上,融入了数据仓库技术,形成了一个新的网络医学信息资源整合系统设计思路,为网络医学信息资源采集、存储、整合和共享等管理工作提供了便利,同时还能保证资源的完整性,具有一定的现实意义。
猜你喜欢
动漫星空(兴趣百科)(2020年12期)2020-12-12
自然资源信息化(2019年4期)2019-03-29
计算机测量与控制(2017年6期)2017-07-01
计算机测量与控制(2017年6期)2017-07-01
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
新校长(2016年5期)2016-02-26
中国教育信息化(2015年10期)2015-08-23
科学中国人(2015年13期)2015-02-28
电子设计工程(2014年12期)2014-02-27
