
EH-CR IoT系统中基于深度强化学习的多维资源管理算法
2022-12-27 05:25黄师化施赵媛
安庆师范大学学报(自然科学版) 2022年4期
黄师化,施赵媛,刘 奎
(安庆师范大学 计算机与信息学院,安徽 安庆 246133)
随着通信技术和集成电路的快速发展,万物互联的时代已经到来,据思科预计,到2023年,全球将有293亿台联网设备,且人均将有3.6台联网设备[1]。然而,指数增长的设备带来了大量的能源消耗,且现有的有限频谱资源已经很难满足设备的通信需求。
近年来,由于能有效提高系统的频谱效率和能量效率,认知无线电(Cognitive radio,CR)[2]和能量收集(Energy harvesting,EH)[3]技术被广泛关注。在CR系统中,非授权的次级用户(Secondary user,SU)被允许接入授权主用户(Primary user,PU)的频谱资源,提高了系统的频谱效率。EH技术是下一代无线网络中一项关键技术,它可以为通信用户提供可控的能量供应,延长能量受限网络的寿命。而且多种绿色能源都能作为EH技术的能量源,如光能、热能、风能以及射频(Radio frequency,RF)能量。随着物联网(Internet of things,IoT)和无线传感器网络(Wireless sensor networks,WSN)的发展,从环境射频信号中获取RF能量引起了广泛关注,其可以使低功耗通信网络实现能源自给自足[4]。本文将整合CR和EH技术,搭建EH-CR IoT通信系统,并对该系统进行联合资源调度。
在EH-CR和其他EH系统中,如何让用户在能量收集和数据传输之间实现较好的时间分配,以及如何合理应用收集到的能量资源,一直是热点研究课题。在文献[5]中,作者开发了一种用于EH系统的三维匹配算法以最大化系统的能源效率。在文献[6]中,作者针对EH-CR WSN系统,提出了一种基于Lyapunov的优化算法。文献[7]为EH系统设计了一种能量效率优化算法,将Dinkelbach算法用于EH系统中的功率控制以及时间资源分配,并考虑了所有用户具有相同的时间分配因子。文献[8]研究了EH-CR系统中能量收集与数据传输的最优时间分配,让所有用户在数据传输中均会使用当前采集到的所有能量资源,然而,该算法仅仅适用于系统中只包含一个PU和SU的场景。在文献[9]中,作者针对EH-CR系统,研究了一种基于Dinkelbach的资源管理算法以实现系统的能量效率最大化,然而,该算法假设SU能够精准地检测出PU的接入状态,这对SU设备的硬件要求较高。
大部分文献[6-9]采用传统Lyapunov、Dinkelbach优化迭代算法,虽然针对EH系统的资源管理工作均能实现较好的系统性能,但往往需要假设系统中所有的信道信息以及收集的能量信息是完全可知的。然而考虑到EH系统中无线通信系统信道的随机性以及能量收集的不确定性,这种假设是不现实的。另外,假设每个用户能获知整个系统中所有用户的信道信息会带来较大的通信负载,增加了通信系统的负担。
DRL算法[9]作为一种深度学习算法,擅长在动态未知的环境中不断与环境进行交互学习以获得最优决策策略,具有突出的学习能力,近年来被广泛应用于无线通信系统中进行各类优化问题的决策[10-13]。基于此,本文引入DRL算法进行了EH-CR IoT系统的动态资源管理。针对EH系统,已有一些基于DRL的资源管理算法研究[14-17],但这些算法只适用于仅包含一个用户的EH系统,极少有论文研究基于DRL算法的多用户EH系统的多维资源管理。
1 系统模型
针对IoT系统中能量和频谱资源紧缺的问题,本文率先为IoT系统引入了CR和EH技术。具体地讲,CR系统是在不影响PU用户通信质量的情况下,让系统中没有频谱资源的SU用户与PU用户共享频谱资源。所有的SU均配置一个EH装置以吸收通信中PU用户产生的RF能量。与文献[14-17]不同的是,本文系统模型可包含多个用户,如图1所示,更贴近实际应用场景。系统中包含一个基站,m个PU和n个SU,每个SU均配置了一个可充电电池以吸收环境中PU通信产生的RF能量。在每个时隙,PU基于离散时间马尔科夫链模型决策当前是否与基站进行通信,通信和休眠的转移概率分别为P1和P2。SU在每个时隙都会采集一些数据,且假设采集到的数据量服从到达率为λ的泊松分布。为了防止数据丢失,每个SU用户配置一个缓存器用于临时存放采集到的数据包,然而考虑到成本效益且缓存器容量有限,需要尽可能快地让SU将数据传输给基站。
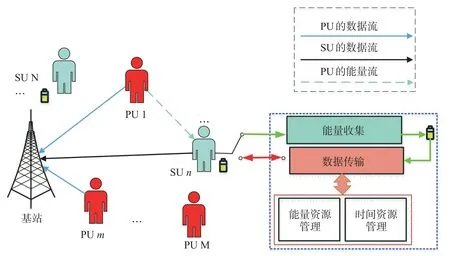
图1 EH-CR IoT系统模型
系统中的信道包含小尺度的瑞利衰落和大尺度的路径损耗。基站与SU之间的信道可以表示为hn=,其中分别表示瑞利衰落和路径损耗,λ*为信号波长,d ns则为SUn与基站之间的距离。同理PUm和基站之间的信道表示为fm=和SUn之间的信道表示为
1.1 能量收集模型
SU采用一种先传输后收集能量的协议,即第n个SU在时隙t中将分别利用αn(t)T和(1-αn(t))T的时间用于数据包的传输和EH,其中,αn(t)为时间分割因子。基站处接收的信号可以表示为

其中,二进制符号U mp、U ns分别表示第m个PU和第n个SU的接入状态(通信时为1,不通信时为0),pns、pp分别为第n个SU和每一个PU的发送功率,pp为常数,xns和xmp为两类用户发送的信号,z为BS处接收到的0均值,方差为σ2的高斯白噪声。基于EH的概念,可以计算第n个SU收集到的能量为

其中,η为EH效率因子。在第t+1时刻,第n个SU的电池电量可以表示为

其中,Emax为电池最大容量。
1.2 数据传输及缓存模型
假设系统中只有一个带宽为W的信道频率资源,接入的所有PU和SU都是通过该信道与基站通信。为了接入更多用户,所有用户均采用非正交多址接入模式,在接收端,基站对所有接收到的信号按照强度进行排序,并采用连续干扰消除技术解码,以减少用户之间的干扰。然而未解码的用户和解码失败的用户仍然会对正在解码的用户产生干扰。具体地,PU和SU获得的瞬时速率分别表示为

其中,M′、M*分别表示未解码和解码失败的PU的集合,N′、N*分别表示未解码及解码失败的SU的集合。基于CR原理,SU的接入不能对PU造成伤害性干扰,且SU也要满足一定的通信服务质量要求(Quality of Service,QoS),即两类用户的速率需满足RnS≥R0S,RmP≥R0P。
假设第n个SU处采集到的数据包个数为cn(t),每个包的大小均为C比特且被临时存放在缓存器中,则在t+1时刻,缓存器中数据包的长度可以表示为


本文通过对SU时间分割因子αn和发送功率pns进行联合调度以最小化系统丢失的数据包个数(即同时满足两类用户QoS要求及公式(1)中的缓存机制。
2 基于深度强化学习的资源调度算法设计
2.1 深度强化学习算法框架设计
强化学习算法因其在动态环境中具有突出的学习能力,近年来被广泛应于无线通信系统的动态决策研究。强化学习的原理是智能体通过不断地与系统环境进行交互以获得经验。具体地讲,在时间t中,智能体的探索过程为:观察本地的系统环境以获得当前的系统状态s(t),并基于该状态和已经获得的经验来采取动作a(t),将a(t)作用于系统,智能体获得对应的奖励R(t),然后让系统进入下一个状态s(t+1),获得经验数据[s(t),a(t),R(t),s(t+1)],该条经验数据将被存放在存储器中,当经验数据达到训练门限时,将会被采样用于神经网络的训练,直到神经网络学到系统所需的决策策略。
在本文中,分布式多智能体的深度强化学习算法被采用,即每一个SU都是独立的智能体,其根据本地观察到的状态信息,进行自身的资源管理决策,无需和其他智能体进行任何的协作和信息交互。系统的状态被设置为
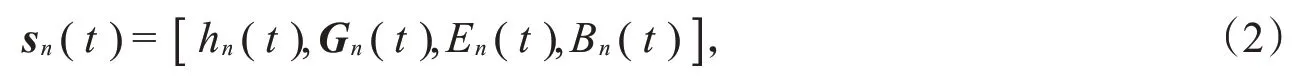
其中,Gn(t)=[g1n(t),g2n(t),…,gMn(t)]为所有PU与第n个SU之间的信道信息。由于需要决策的资源问题为时间资源及能量资源分配,可设计动作空间为

其中,αn(t)表示t时刻第n个SU的时间分割因子,pns(t)表示其归一化的发送功率。需要注意的是,为了智能体的学习效率更高,需要对子动作pns进行归一化处理,处理后两个子动作的动作空间均为[0,1]。同时,为了让每个智能体学习到有效的决策策略,需要设计合理的奖励函数,由于优化目标为故可设计智能体n的奖励函数为

其中,Γ为大于零的常数,其可保证当用户n的丢包数较少时,智能体可获得一个正向反馈,ξ是惩罚因子也为大于零的常数。
2.2 基于深度强化学习算法的资源管理算法
考虑到动作空间的连续性,本文采用了在连续动作空间决策问题中有较强学习能力的深度确知策略梯度算法(Deep deterministic policy gradient,DDPG)[18]。基于设计的状态、动作和奖励函数,智能体可以实现与EH-CR IoT系统的交互。具体地讲,作为独立的智能体,每个智能体处配置一个参数为θμ的Actor网络,在时刻t,每个SU首先观察本地的状态sn(t),且将其输入Actor中并输出动作an(t),作用于EH-CR系统后,获得奖励Rn(t)并使得系统进入下一个状态sn(t+1)。每个智能体获得的经验[sn(t),an(t),Rn(t),sn(t+1)]将被集中存储在存储器D中,当存入的经验数据达到一定数量后,将规模为Ω的经验数据采样用于中央训练器Critic网络的训练。训练中的损失函数定义为


其中,βc为Critic网络的学习效率。另外中央训练器中的Actor网络参数可根据以下梯度进行更新,

基于DDPG的EH-CR IoT系统的多维资源管理算法的具体流程如下。
初始化:清空存储器D,初始化中央训练器和每个用户的Actor网络,设置d=0
1)For探索回合数k=1,2,3,…,K执行:
2) 初始化EH-CR IoT系统
3) 每个智能体获得初始状态sn(0)
4) For每一步t=1,2,3,…,T执行:
5) For每一个智能体n=1,2,3,…,N执行:
6) 每个智能体从中央训练器复制网络参数到本地Actor网络
7) 每个智能体根据公式(2)观察本地状态sn(t)
8) Ift>1执行:
9) 将经验数据[sn(t-1),an(t-1),Rn(t-1),sn(t)]存入D
10)d=d+1
11) End If
12) 每个智能体将sn(t)输入Actor网络,输出动作an(t)并执行
13) End For
14) 根据公式(3)计算每个智能体的奖励Rn(t)
15) Ifd>1/3D执行:
16) 从D中采取经验数据集Ω,并根据公式(4)、(5)更新中央训练器参数
17) End If
18) End For
19)End For
在中央训练器Actor参数更新后,通过广播的方式发送给每个智能体,智能体将其复制并用于自身Actor网络的更新。当所有智能体对EH-CR IoT网络进行充分的探索后,中央训练器就有足够的经验数据进行参数训练,网络参数将会收敛,即可得到最优的资源管理策略。
2.3 算法复杂度分析
DRL算法的计算复杂度往往是通过统计DRL训练过程的浮点运算总数来衡量的[19]。本文使用的DDPG算法包含4个神经网络,分别为Actor网络、Critic网络,以及两者的目标网络。其中,Actor网络是基于输入的状态信息,维度为M+3,输出对应的动作维度为2。目标Actor网络则是和Actor网络具有相同的网络结构,其输入也是当前的状态信息,而输出是目标动作。Critic网络则是用于评估Actor网络输出的动作,其输入为当前的状态信息以及动作,维度为M+3+2,输出为对应的评价Q值。目标Critic网络具有和Critic网络一样的结构,其主要用来计算目标评估Q值。
中央训练器的4个网络均采用全连接4层结构,其中,第1层为输入层,第2层和第3层为隐藏层,最后一层为输出层,两个隐藏层中的神经元个数分别为32和64。对于全连接的第Li层,若其输入维度为Ii,输出维度为Oi,则该层在一次训练中包含的浮点运算个数为

因此,在两个Actor网络中的浮点运算的个数均为

两个Critic网络的浮点运算个数均为
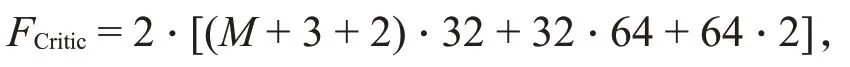
整个DDPG算法训练一次的计算复杂度可表示为2·FActor+2·FCritic,即18 432+256·M次的浮点运算。
3 仿真分析
本文通过仿真实验验证所构建算法的性能,仿真使用的深度学习框架基于TensorFlow 1.14.0,PU的个数m=4,次级用户数n取[10,15,20,25],SU采集的数据到达率λ=1,EH效率因子η=0.9,惩罚因子ξ=15,奖励常数Γ=20。将几种基准算法进行对比:(1)贪婪算法:在每次发送数据包时,发送功率为电池能量支持的最大功率,EH的时间通过DDPG算法计算得到;(2)随机算法:发送和功率均为可支持范围内的随机值;(3)对半算法:发送功率为可支持的最大功率的一半,EH时间为总时隙长度的一半。

图2不同SU数目下所提算法的性能
图2 展示了在SU数目不断递增的情况下本文算法的性能,其中,图2(a)展示了系统的平均丢包数目,而图2(b)展示了系统的平均奖励。可以看出,所提算法具有较好的收敛性,在25次探索后,系统的两种性能基本都趋于平稳。另外观察到,随着n增加,系统的性能在缓慢变差,这是因为SU数目越大,用户间造成的干扰将会越大,其成功通信的概率将降低。但可以看出,即使当n=25时系统也能获得约17的奖励和0.2的平均丢包数目,这验证了所提算法的鲁棒性。
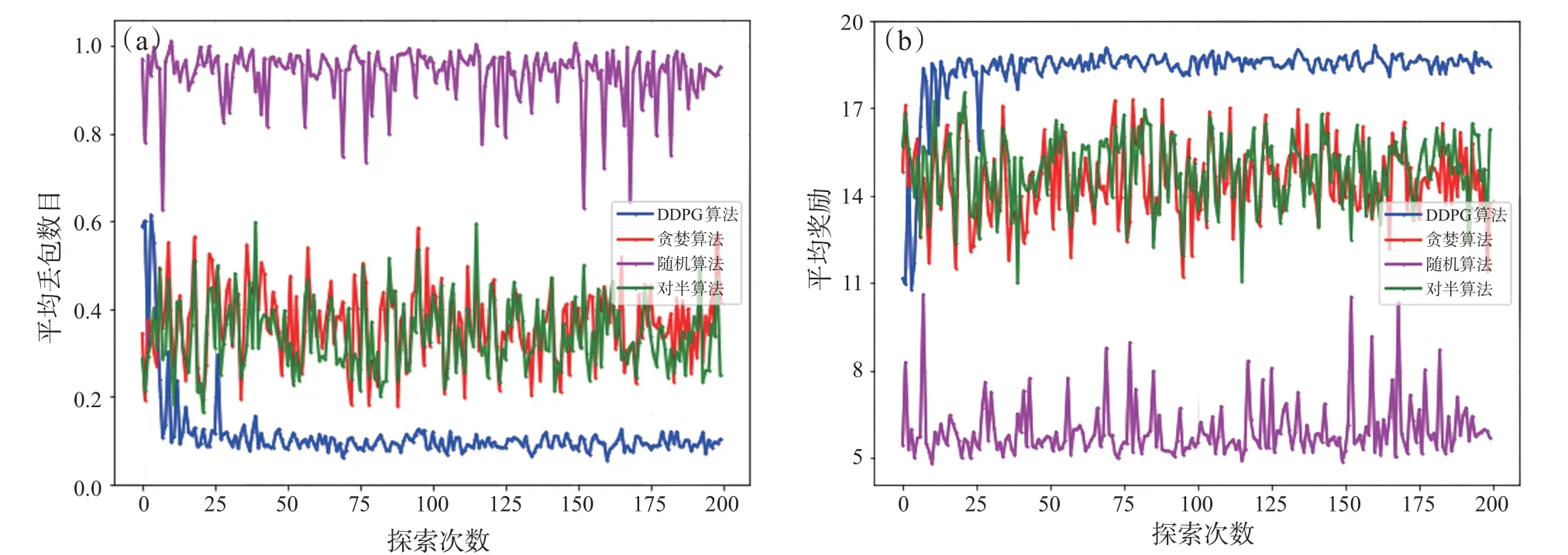
图3不同算法的性能对比
图3 对比了本文算法和其他三种算法在n=15,m=4时的平均丢包数目和平均奖励值。可以看出,基于DDPG的资源调度算法可实现的性能明显优于其他三种算法,其中随机算法的性能最差;相对于随机算法,贪婪算法和对半算法能获得更好的性能。尽管贪婪算法发送功率是贪婪的,但收集能量的时间是基于DDPG算法的智能决策获得的,可以基于当前系统的环境状态智能地决策需要进行多久的能量采集才能保证通信成功。而在对半算法中,发送功率为可提供功率的一半,能量收集时间也为整个时隙的一半,其本质就是一种复杂度较低的折衷算法,当系统参数不太苛刻时,才能收获相对较好的系统性能。另外,随机算法的发送功率和能量收集时间完全是随机的,其做出的决策与当前的环境状态完全无关,这种完全随机的决策很难获得理想的系统性能。从仿真实验可以看出,本文算法较其他算法有明显优势,能够有效减少EH-CR IoT系统数据包的丢失。
4 结束语
针对IoT系统因频谱和能量资源受限而导致的大量丢包问题,本文率先引入EH和CR技术以搭建EH-CR IoT系统,并研究了一种基于DRL的联合资源调度算法对应问题。具体地讲,采用DDPG算法对EH-CR IoT系统进行了能量和时间资源联合调度算法,通过设计合理的状态、动作和奖励函数,智能体可基于本地状态做出智能的资源决策。最后,论文分析了基于DDPG资源管理算法的复杂度,并通过仿真实验验证了本文算法能实现更少的丢包数。
猜你喜欢
商品与质量(2021年43期)2022-01-18
大众投资指南(2021年23期)2021-12-06
口腔护理用品工业(2021年4期)2021-11-02
现代园艺(2018年2期)2018-03-15
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
中国交通信息化(2016年8期)2016-06-06
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
移动通信(2015年17期)2015-08-24
