
基于PCA和XGBoost的D-PMU实时扰动预测研究
2022-12-27 13:14袁智勇葛宁超林跃欢
计算技术与自动化 2022年4期
袁智勇,熊 瑶,葛宁超,秦 拯,于 力,徐 全,林跃欢
(1.南方电网科学研究院,广东 广州 510080;2.湖南大学,湖南 长沙 410082)
结合我国配电网的特点,性价比高且适合故障定位的D-PMU(分布式相量测量装置)在国内得到较为广泛的使用。它被普遍认为是下一代配电系统中必不可少的组成部分[1],其有效地解决了传统测量传感器精度不够的问题[2]。D-PMU不仅包含同步相量信息,还包含有同步录波信息,可以为故障定位奠定数据基础[3]。
如今人们使用越来越多的电子设备,对电能质量的需求也日益增加。电器设备扰动的识别,可以为管理电器设备提供帮助[4]。随着我国电网规模的逐渐扩大,电网中数据的结构变得越来越复杂。这虽然给电网带来了显著的优势,但是也给电网带来了一些风险。电网中一些局部故障,例如短路、切机等,如果处理不及时,就会演变成电网中更大的事故。所以准确并及时对存在的扰动进行在线预测是非常重要的[5]。近年来对电网扰动的研究日益增多,有基于WAMS的在线扰动识别的研究[6],有利用随机森林进行的PQ(电能质量)扰动分类[7],有基于多层极限学习机的PQ扰动识别的研究[8],有利用FFT(快速傅立叶变换)和S变换提取电网中的特征向量的研究,有利用决策树和SVM对PQ扰动进行识别的研究[9]。目前电网中常用的特征提取方法有S变换和小波变换[10],常用的扰动分类方法有马氏距离、神经网络、SVM和随机森林等。
本文提出了一种基于PCA算法和XGBoost算法的D-PMU实时扰动预测分类方法,其能够实时准确地预测设备可能存在的扰动信号,保障智能配电网的实时稳定性。首先建立扰动预测模型,采用滑动平均法对D-PMU时间序列矩阵进行数据清洗,使用PCA算法提取主要特征,根据XGBoost算法对输入的特征进行扰动预测,最终得出不同时间点D-PMU设备是否存在扰动。
1 D-PMU实时扰动预测技术方案
D-PMU实时扰动预测框架如图1所示分为两个模块:离线模型训练模块和实时扰动模块。离线模块通过提取样本数据中的特征,并对特征进行预处理;然后通过先验知识对样本进行分类,再将特征x和标签y输入至XGBoost模型中训练;最后将训练得到的参数拷贝至实时预测的分类模型中。实时预测模块运用Socket流处理框架进行前置解析,将处理后得到的D-PMU数据进行特征预处理,并输入至完成参数拷贝的XGBoost模型中,完成扰动分类后将D-PMU量测数据和分类结果存储至HDFS中。
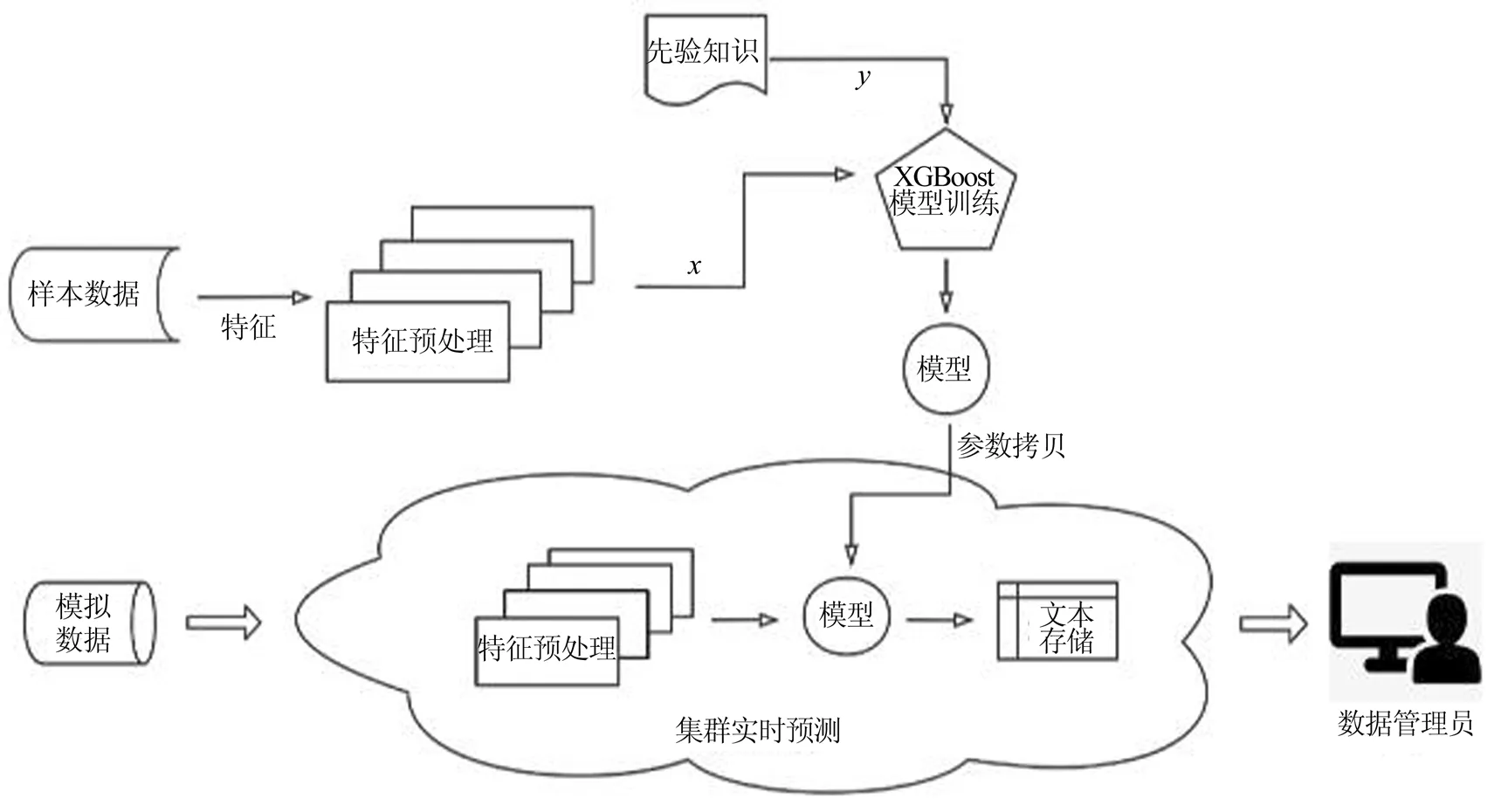
图1 整体架构图
2 实时扰动预测方法
2.1 数据清洗
根据缺省值t所对应的时间戳,往前推m个时间戳,找到前m个时间戳对应的同一测量点的测量记录值,根据滑动平均法的思想:利用以往的数据预测得到未来某一时刻的数据,将预测得到的值对缺省的测量点进行插补。滑动平均法的公式如下:
(1)
若时间t对应的是当前RDD的第一个时间戳,那么就往后推m个时间戳即m*10 ms。根据滑动平均法对D-PMU时间序列矩阵进行数据清洗,对D-PMU时间序列中矩阵的缺省值进行插值填补,实现D-PMU时间序列质量的提高,尽可能地还原D-PMU时间序列的原始信息。
2.2 特征降维
首先取经过数据清洗后的D-PMU时间序列矩阵DpmuRddSeq′,其表达式如公式(2)所示:
(2)
通过函数AVG(Σχij)计算得出每列特征的平均数值,并去掉平均数值。再计算得到协方差矩阵A,协方差的计算公式(3)如下:
(3)
此协方差矩阵表示两个维度之间的关联性,数值越大表示关联性越强。若协方差为0,表示两个维度之间是没有关系的;若协方差的值为正,则表示是正相关;若协方差为负,则表示负相关。协方差矩阵A的表达式如公式(4)所示:
A=cov(νa1,…,νa24,νp1,…,νp24,f,fC,Asyn)=
(4)
并通过下面的公式(5)计算。
Av=λv
(5)
其中λ为特征值,v为特征向量。设置一个阈值,即降维后要保留的信息度,计算满足要保留信息度的维度数k。对特征值进行降序排序,取前k个特征值作为要保留的特征,将其余特征作为噪声特征删除掉。根据特征值的降序排序,将对应的特征向量构建成矩阵,取出前k行构成新的D-PMU时间序列矩阵Q。
2.3 预测分类
2.3.1 离线模型训练
首先利用IEEE39模拟器生成一定数量的D-PMU原始时间特征序列,利用Spark Streaming将D-PMU时间序列前置解析完成进制转换。解析后的D-PMU时间序列如公式(6)所示:
dpmuTseq={νa1,…,νa24,νp1,…,νp24,f,fC,Asyn}
(6)
根据D-PMU时间序列的特征与扰动情况之间的关系,如电压偏移为±5%时,将该情况定义为正常状态;若电压升高,频率升高则可能会导致切负荷的扰动情况。
根据电力知识将样本数据分为四类(短路、切机、电压突升、正常),并标记为{0,1,2,3}。将处理后的样本数据构建成时间序列矩阵,通过PCA算法根据设定的阈值提取出前top-k的主要特征,将其他冗余特征删除。通过交叉验证的方式,将样本数据分成训练集、测试集,首先通过训练集对模型进行训练,通过测试集来测试基于样本数据的模型训练效果。
首先通过XGBoost算法基于公式(7)对矩阵数据进行训练。
(7)
其中,F(xi)为模型的输出,xi为训练样本集的特征,k为cart树的个数。模型的输出y通过引入softmax函数来实现多分类,选择一个较为合适的学习率,通过交叉验证得到一个最佳的树的个数k。通过模型的不断训练得到最优的参数,例如树的深度、最小叶子的权重、正则项化参数等,来防止过拟合。最后不断调整学习率,得到最优的参数的组合。
2.3.2 实时模型训练
取经过PCA算法提取特征后的时间序列矩阵Q,基于Spark集群和Spark MLlib的机器学习包中的xgboost4j来进行训练。根据前面样本数据训练得到的最优的参数组合,建立一个最优的XGBoost模型,利用xgboost4j来对输入的时间序列矩阵Q进行分类预测,将分类得到的结果添加至时间序列矩阵Q最后一列。
3 实验测试及分析
实验环境:三台Linux云服务器,均为4核、32 GB;一台本地服务器,i7处理器,四核,内存8 GB,256 GB固态,Windows 10操作系统;实验的开发工具:IDEA,Xshell,Xftp,Pycharm。
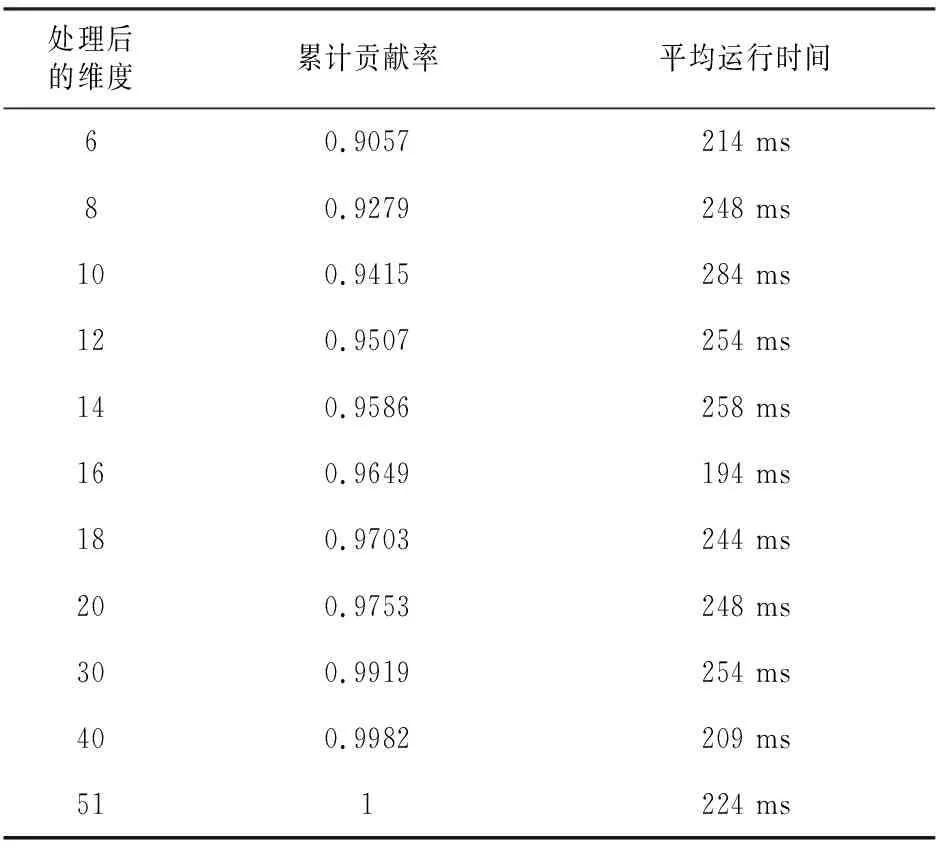
表1 不同维度PCA实验对比表格
根据实验计算结果表可以得到,在不同维度对比试验中,当维度在16时,其累计贡献率达到0.9649,且其计算耗时达到最小值,故选取16维度作为后面实际预测降维值,其预测准确率达到97.23%。
取打上标签后的506条数据,对XGBoost模型进行准确率评估。其中Label 0有30条,Label 1有326条,Label 2有80条,Label 3有70条数据。对应的混淆矩阵图如图2所示,行代表的是预测的标签类别,列代表的是实际的标签类别。横纵坐标的交叉点表示该类别预测的准确率。由图可以看出Label 0,Label 1,Label 3基本分类正确,Label 1 有少数样本错分类为Label 2。
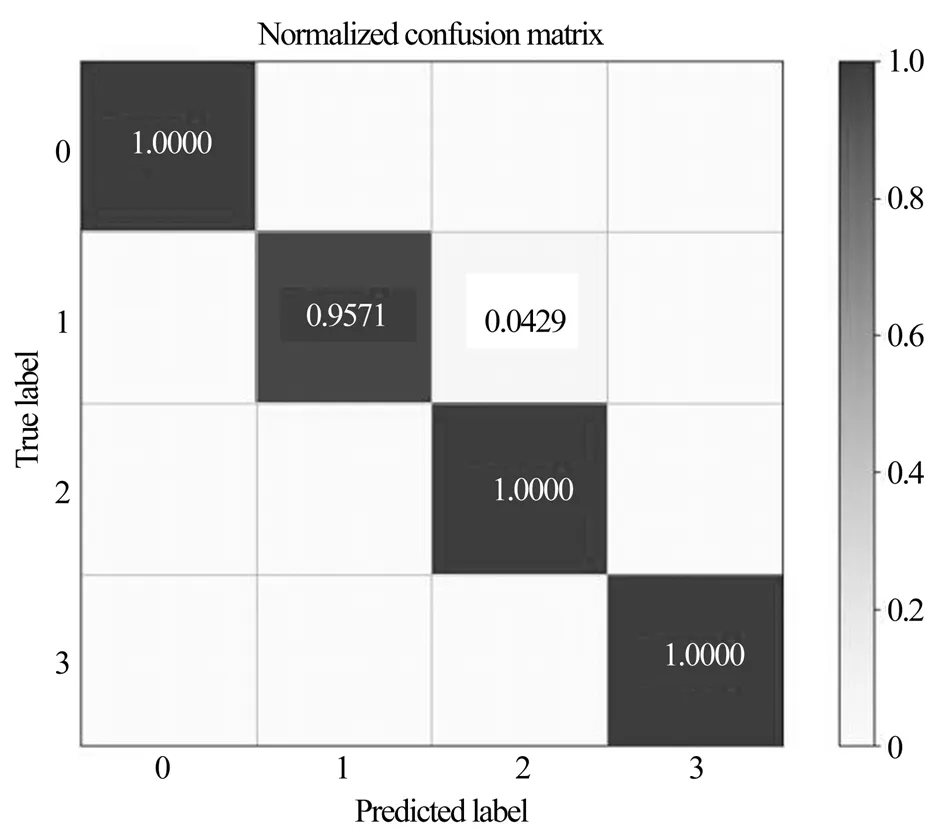
图2 混淆矩阵图
取上述506条测试数据,进行XGBoost扰动分类实验,实验结果如表2所示:

表2 PCA处理前后分类效果比较
由表2可以看出,经过PCA降维后,分类准确率没有明显下降,且分类时间远小于降维前。这说明PCA能够提升计算速度,且不影响分类性能。
基于以上实验环境、样本数据和数据处理过程,使用五折交叉验证,分别基于LR、SVM、DT、RF进行准确率评估,并与XGBoost算法准确率进行比较,得到实验结果如表3所示。

表3 多个分类算法分类效果比较
由表3可以看出,分类效果最弱的是逻辑回归LR算法,其准确率是71.344%;XGBoost的扰动分类性能最好,达到97.233%;其次是随机森林RF算法,其准确率达到96.047%。
4 结 论
本文提出了一种基于PCA算法和XGBoost算法的D-PMU实时扰动预测分类方法。实验结果表明,该方法不仅可以实现D-PMU的扰动分类,还能保证其实时性能。搭建集群环境,使用价格低廉的服务器来代替昂贵的服务器,可以使得智能配电网的成本的降低。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学小灵通(1-2年级)(2021年4期)2021-06-09
数学物理学报(2019年4期)2019-10-10
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
贵州师范学院学报(2016年3期)2016-12-01
考试周刊(2016年54期)2016-07-18
自动化学报(2016年8期)2016-04-16
