
基于混合神经网络的突发公共卫生事件微博谣言识别研究*
2022-12-26 03:16冯兰萍董陈超徐绪堪
情报杂志 2022年12期
冯兰萍 董陈超 徐绪堪
(1.河海大学商学院 常州 213022;2.东南大学 经济管理学院 南京 211189;3.常州工业大数据挖掘与知识管理重点实验室 常州 213022)
社交媒体的谣言识别现已得到学术界广泛深入的研究,主要采用传统的机器学习方法和深度学习方法,在微博内容特征的基础上融入更多的辅助特征提升实时谣言识别效果[1]。微博谣言特征主要包括用户特征、内容特征和传播特征,突发公共卫生事件微博谣言内容通常具有一些固定的句式[2],同时存在较多与疫情相关的语词,且分布较为分散;用户历史微博情感对谣言识别有辅助作用[1,3],且用户特征和传播特征并不随着领域的不同而产生差别[4],因而用户历史特征对谣言识别亦有一定的辅助作用,而多特征融合中引入用户历史特征的研究相对不多。因此如何充分抽取谣言的关键特征,构建多特征融合的谣言识别模型,提高谣言识别效果;探讨各特征对谣言识别的影响,为政府及相关部门谣言治理、用户谣言识别提供参考,是本文研究的问题。
相对于传统的机器学习,深度学习自动构建特征可进一步提升谣言检测的准确性与稳定性[4]。因此,本文以微博数据为研究对象,提出一种基于混合神经网络的多特征融合谣言识别模型。该模型引入用户历史特征,充分利用BiLSTM和CNN的优势,采用BiLSTM+CNN抽取微博代表性深度语义特征,与其它多特征融合后,使用全连接DNN网络进行谣言识别,在此基础上分析各个特征对谣言识别的影响,为谣言自动识别研究提供新的思路。
1 国内外相关研究
社交媒体谣言识别主要包括模型和方法选取、特征抽取及其基础上的谣言判定[5]。
a.在模型和方法方面。传统的机器学习方法有支持向量机[5-6]、随机森林[7]、决策树[8]等,由于分类算法对谣言的识别效果有很大影响,因此主要集中于分类算法的选择和改进、特征的有效识别[9]。深度学习因其强大的学习能力,不需要人工构建特征在谣言识别领域得到了广泛的关注。Ma等[10]通过构建循环神经网络(RNN)模型首次对微博谣言事件进行检测,提高了谣言事件自动检测的效率。尹鹏博等[3]采用卷积神经网络(CNN)和LSTM分别提取用户特征和微博文本特征,提出基于C-LSTM的检测模型进行早期谣言检测。赵月华等[11]针对小样本领域提出基于BERT虚假信息识别模型。石锴文等[2]构建BiLSTM+DNN模型对多特征向量进行谣言判别。刘勘等[4]将深度迁移网络应用于跨领域谣言识别。Chen等[12]提出注意力机制与RNN相结合的谣言检测模型,能更准确地检测早期谣言。潘德宇等[13]在CNN网络引入了注意力机制,获得较好地识别效果。现有研究多采用单一的CNN、RNN及衍生网络进行谣言识别,或者利用注意力机制作对已提取特征进一步提取关键信息,以提高谣言识别的精度。但是未能充分利用RNN和CNN网络提取文本语义的优势,因而谣言识别效果仍存在一定的提升空间。
b.在特征抽取挖掘方面。通常在社交媒体谣言检测中用到的特征主要有用户特征、内容特征和传播特征[9]。例如,Castillo 等[8]从字符串长度、词语个数、符号(问号、感叹号、微笑和皱眉等)、标签、链接等维度对文本特征细分。贺刚等[14]认为浅层的文本特征难以反映微博文本内容的可信度,在Yang等[15]提出的微博文本内容、用户属性信息和传播深度3个特征的基础上,引入了文本的符号、链接、关键词分布以及时间差四类新特征。首欢容等[16]构建基于情感分析的领域谣言自动识别模型,并运用到“食品养生”“医学健康”两个领域实现领域谣言自动识别。石锴文等[2]运用TF-IDF增强Word2Vec词向量语义特征,利用LDA模型对文本进行主题分析,从多个维度融合文本特征。黄学坚等[1]在谣言识别模型中除了用户基本特征和内容统计特征,从用户历史微博和微博评论中挖掘用户深层特征。现有研究根据不同的需求,从不同的角度对微博特征进行抽取挖掘,主要集中于文本内容特征与其融合其他特征研究,在谣言识别中融合用户历史特征的研究不多。
2 多特征融合的微博谣言识别模型
2.1 模型框架
谣言内容、发布用户以及传播是构成识别谣言和非谣言的关键要素[9],不同特征之间的融合将对谣言识别起到较大作用。突发公共卫生事件具有公众参与度高、负面倾向性强、民众恐慌加剧和极端用语多等独有的特征[2],且用户特征和传播特征对谣言识别的影响与突发事件所属领域无关,用户历史行为对谣言的识别具有一定的辅助作用。由于BiLSTM的双向机制保证了每一个词在充分考虑上下文的条件下获得语义,实现微博文本特征的深度抽取[17]。CNN可提取语义表示和捕获平面结构中的显著特征[18],具有捕获局部上下文的优势[19]。因此本文采用BiLSTM获取微博内容的上下文语义,CNN对提取特征使用不同的卷积核捕获多粒度的局部上下文语义信息,从而获得谣言内容语词间上下文语义结构,以最大池化方式抽取代表性语义特征。BiLSTM+CNN输出语义特征向量为自动构建的高维向量,解释性不强,全连接DNN的多隐藏层可以抽象地表示特征,具有传统的算法所不具备的灵活性,对于大部分非线性函数的拟合能力都较好,只要通过增大全连接神经网络的深度,就可以对函数进行精确地拟合[20]。因而在语义特征与其他特征拼接融合后,可采用全连接型的DNN网络进行谣言识别。综上,结合相关研究成果,在用户基本特征和内容特征、传播特征的基础上引入用户历史特征,本文提出一种突发公共卫生事件下的多特征融合谣言识别模型框架(如图1所示),以实现微博谣言自动有效识别。

图1 突发公共卫生事件下的多特征融合微博谣言识别模型框架
该模型包括数据获取与预处理、特征抽取、特征融合、分类判别等。具体为首先采用相关工具或编程爬取微博相关数据,并对其进行清洗,根据微博数据标签提取用户基本信息、传播信息、微博内容信息,对微博内容文本进行符号统计、Jieba库分词和SnowNLP情感分析[21]、BiLSTM+CNN模型抽取微博内容特征,在此基础上进一步处理获得用户历史特征。接着将所提取特征拼接后,输入DNN全连接层判别谣言的类别。
2.2 特征构建及抽取
2.2.1特征构建
根据上文分析,本文谣言微博特征采用用户基本特征、用户历史特征、内容特征和传播特征4个维度表征。内容特征现有的研究主要包括:统计特征(T1)、情感特征(T2)、语义特征(T3),能够很好地区分谣言和非谣言,因此本文将从这3个维度对内容特征进一步细分。谣言传播者和普通用户的基本特征上存在较为明显的差异,例如谣言用户具有地域差异,为了增加发布谣言的曝光度会在较短的时间内关注大量用户,以获得较多粉丝,话题型用户名具有更高的可信度等[9]。谣言用户发博时间通常选择普通用户刷微博的高峰期,以获得较高的关注度,因此传播特征除了评论数、转发数、点赞数外,发博时间亦是重要的传播特征。另外虽然用户历史发博的领域不定,但用户特征和传播特征与领域无关,因此用户历史特征可用用户历史传播特征(H1)、历史发博特征(H2)、历史情感特征(H3)表征。结合清博指数BCI和相关研究,用户基本特征(U)、内容特征(T)、传播特征(S)、用户历史特征(H)具体如表1—表3所示。

表1 微博内容特征、传播特征

表2 用户基本特征

表3 用户历史特征
2.2.2特征抽取
用户基本特征、传播特征根据微博数据标签提取,统计特征采用统计学方法、python编程或EXCEL统计文本中包含的符号数完成,情感特征值直接采用SnowNLP库计算内容情感得分。符号统计和SnowNLP情感计算比较成熟,微博文本语义特征反映微博用户观点、意见、情感的语词表达,具有不确定性,是谣言识别的关键部分,本文使用BiLSTM+CNN抽取语义特征。其结构图如图2所示。

图2 BiLSTM+CNN语义特征抽取模型
该模型包括三层:词嵌入、BiLSTM层、CNN层。
a.词嵌入。将微博内容文本分词后的词转化为词向量以作为BiLSTM层的输入。北师大和人大开源的已经训练好的词向量词典Word + Character + Ngram[22]相比其他全领域的词向量词典更适合微博谣言识别的任务[1]。因此本文选取Word + Character + Ngram (300d)将文本每个词表示为300维的词向量。

(1)
所有词向量的语义特征向量构成文本特征矩阵A。
c.CNN层。针对不同语词在微博内容中分布不同,对文本特征矩阵A进行上下文结构局部特征提取,CNN从上下文语义中捕获结构信息,提取代表性特征,去除冗余信息、消除岐义。本文通过设置不同宽度的卷积核对文本特征矩阵A进行卷积运算、最大池化,选取宽度16对微博中句子进行编码,最大池化后再选取宽度4对句子中四元组作进一步的语义编码,做最大池化。最后将池化后特征向量flatten成一维语义特征向量,形成代表性语义特征向量T3输出。
2.3 特征融合
特征融合是将不同角度的特征结合,为分类提供更多可依据的信息[4]。将用户基本特征、用户历史特征、传播特征、统计特征、情感特征等相关数据归一化后,与BiLSTM+CNN模型提取的256维代表性语义特征向量T3拼接成一个多元特征向量TU,作为DNN网络的输入。特征融合过程如公式(2)—(4)所示。
T=T1⊕T2⊕T3
(2)
H=H1⊕H2⊕H3
(3)
TU=U⊕T⊕S⊕H
(4)
式中⊕代表级联操作,即对各特征向量进行拼接。
2.4 谣言识别
谣言识别采用多层DNN网络进行分类训练,DNN的输入为多元特征向量TU。分类模型训练过程中,先对类别标签进行One-Hot编码,在隐藏层使用tanh作为激活函数,并使用categorical_crossentropy作为模型的损失函数对模型参数进行优化。最后通过softmax层进行分类,输出微博文本为谣言和非谣言的概率,二者概率之和为1,其具体计算过程如公式(5)、(6)所示。

(5)
(6)
式中Wk是第k个类别的权重系数矩阵,xi表示第i个文本的多元特征向量,yi表示第i个文本的类别(谣言或非谣言),χk(xi)为第i个文本在第k个类别上的计算结果值,K为类别总数。
3 实验分析
为了验证本文模型的有效性,首先对本文模型中语义特征采用不同的方法处理,对比实验结果分析本文模型语义特征在谣言识别中的作用及BiLSTM+CNN谣言语义特征学习能力;接着与现有谣言模型实验结果对比分析本文模型谣言识别效果;最后在语义特征的基础上递进融合特征,分析各特征对谣言识别效果的影响。实验数据集训练集比例70%,测试集比例30%。使用准确率(Accuracy)、查准率 (Precision)、查全率(Recall)和F1值作为模型效果评价指标。
3.1 数据来源
本文实验数据为2020年1月15日—2022年2月7日间新冠疫情相关微博数据,谣言数据为微博社区管理中心平台已确认的新冠疫情谣言,非谣言数据根据微博话题#新冠疫情#,采用Python编程爬取,用户历史数据通过循环滚动的方式,获取用户最近50条微博历史特征。最后获取数据为谣言用户基本信息713个,非谣言用户基本信息1 177个,谣言微博数770条,非谣言微博数1 200条(随机选取),谣言用户历史微博数27 939条,非谣言用户历史微博数77 736条。
3.2 数据清洗与预处理
首先对爬取到的页面进行初步清洗,根据标签获取本文所需数据,获得用户基本特征、传播特征和微博内容信息,保存为CSV文件。接着主要作如下处理:
a.缺失值处理。用户自己未填写相关特征信息(如性别、所在地等)或者由于微博发布时间过早、用户主动删除了部分已发布的微博,导致部分信息缺失时,本文将缺失值全部填充为-1,以区分缺失值和获取到的真实值。例如某条微博的点赞数为-1表示点赞数缺失。
b.文本内容特征处理。首先对文本中符号进行统计,获得统计特征数据,采用python编程通过正则化表达式去除文本中的表情、标点符号、多媒体等信息,Jieba库对微博文本进行分词,SnowNLP库计算微博文本的情感得分。
c.归一化处理。采用min-max对统计特征、传播特征等相关数据进行归一化处理,将值转化到区间[0,1]。
d.微博谣言时间分布统计分析。以1小时为时间段统计每个时间段内谣言发布量,每个时间段内谣言发布量如图3所示。

图3 微博谣言时间分布统计
由图3可知,24小时内谣言量呈波动状态,谣言量最少的时间段是4-5点, 5条;最高峰是11-12点,63条;每小时平均约32条。谣言量较多的时间段为10-13点、20-24点,2-7点极少。
3.3 主要参数设置
本文实验环境为Python 3.8、tensorflow 2.1.0、keras 2.3.1等。为了保证公平性和合理性,本文采用网络规模和尺寸保持一致,主要参数如表4所示。

表4 主要参数
3.4 不同语义特征抽取模型实验结果分析
为研究本文模型的可行性和有效性,在模型结构与参数不变情况下,与以下3种类别模型对比谣言识别效果,分析本文模型中语义特征的作用及BiLSTM+CNN语义特征抽取的性能。具体类别为:a.类别1,不考虑语义特征,其他特征不变;b.类别2,仅考虑语义特征,采用BiLSTM+CNN抽取语义特征;c.类别3,采用常用深度学习模型及组合抽取语义特征,其他特征不变;谣言识别效果评价各项指标值是按照训练集和测试集的比例进行加权后计算得到的,实验结果见表5。
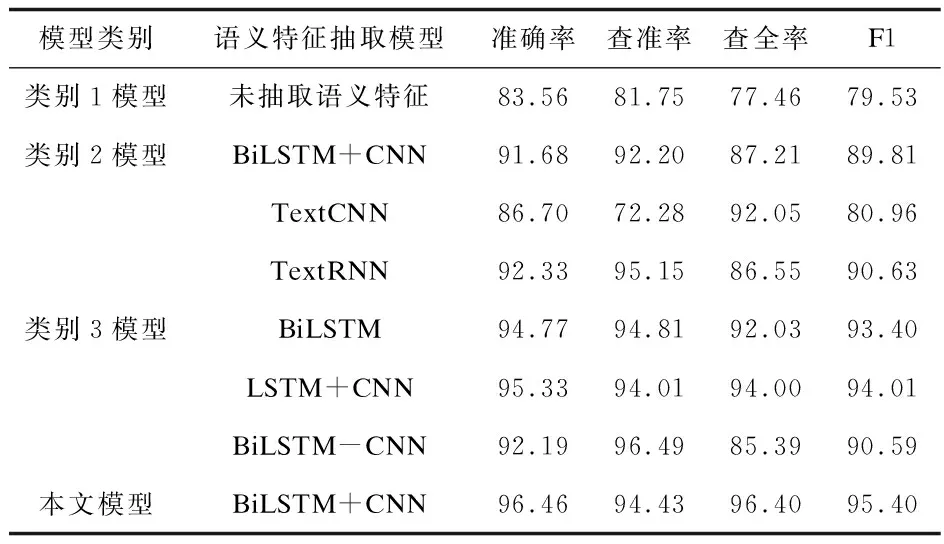
表5 不同语义特征抽取模型实验结果对比分析(单位:%)
3.4.1语义特征的作用分析
由表5可知,语义特征是微博谣言识别的关键要素,其他特征能够显著地提高谣言识别效果。类别2模型与类别1模型相比各评价指标大幅提高。类别1模型准确率为83.56%、查准率81.75%,查全率和F1值不到80%;虽然融合了微博其他特征,但未考虑谣言文本的语义特征,对谣言识别能力相对较弱,因而微博语义特征是识别谣言的重要特征。本文模型与类别2模型相比,本文模型中语义特征融合了其他特征能够显著地提高谣言识别效果。
3.4.2BiLSTM+CNN语义特征抽取性能分析
由表5可知,BiLSTM+CNN谣言语义特征识别能力明显高于其他常用深度学习模型及组合。与类别3模型相比,本文模型的查准率略低于TextRNN、BiLSTM、BiLSTM-CNN模型,但准确率、查全率、F1值都远高于类别3模型,类别3模型(除TextCNN准确率外)与模型类型1相比各指标有显著提高,具有较好地谣言识别能力。
a.BiLSTM与TextCNN、TextRNN相比,谣言深度语义特征学习能力更强。BiLSTM模型准确率(94.81%)略低于TextRNN(95.15%),但其准确率、查全率、F值远高于两者。TextRNN能够抽取深层语义信息,获得较高的准确率,略高于BiLSTM,但明显降低了查全率。TextCNN抽取局部信息,获得代表性语义特征,但明显降低了其查准率,反而低于模型类型1;虽然获得较高的查全率,具有较强的泛化能力,相关指标均低于BiLSTM。
b.本文模型查准率略低于BiLSTM模型,但查全率、F1值指标上均有较明显的提升。表明CNN网络对BiLSTM网络抽取的语义特征向量进行二次学习,学习到质量更高的具有代表性语义特征,具有较强的泛化能力。
c.BiLSTM-CNN模型采用BiLSTM、CNN分别抽取微博语义特征并拼接,语义特征向量维度增加提高了语义特征的专指度,查准率高于本文模型,但准确率、查全率和F1值明显低于本文模型。
d.本文模型相关指标均高于LSTM+CNN。说明BiLSTM谣言深层语义特征能力学习优于LSTM。
综上所述,本文模型采用BiLSTM抽取文本内容上下文深度语义特征,CNN进一步捕获代表性上下文语义结构,查全率和综合性能更好,具有更强地泛化能力。
3.5 不同谣言识别模型实验结果分析
为了进一步验证文本模型的有效性,在本文数据集上对现有谣言识别模型S-SVM[6]、TextCNN+Attention[14]、 C-LSTM[3]和BiGRU+Attention[1]进行复现,与本文模型谣言识别效果对比分析。相关评估指标值的计算与3.4一致,实验结果见表6。
a.S-SVM模型较为简单,相关指标均低于本文模型,这是由于S-SVM无法充分学习到谣言的文本特征,将不能确定为谣言的文本统一分类为非谣言文本,导致谣言文本的查准率较低,获得较好的查全率。
b.除S-SVM模型外,本文模型查准率(94.43%)低于现有谣言模型,查全率(96.40%)、准确率(96.46%)、F1值(95.40%)均高于现有谣言模型,说明现有谣言模型提取语义特征相对较深,但本文模型的泛化能力较强、综合性能较高。BiGRU+Attention、TextCNN+Attention模型对谣言文本的查准率较高,结合表5可知,这是由于Attention机制进一步识别了谣言的关键信息,提高了谣言语义特征深度,但明显地降低了查全率,远低于本文模型。
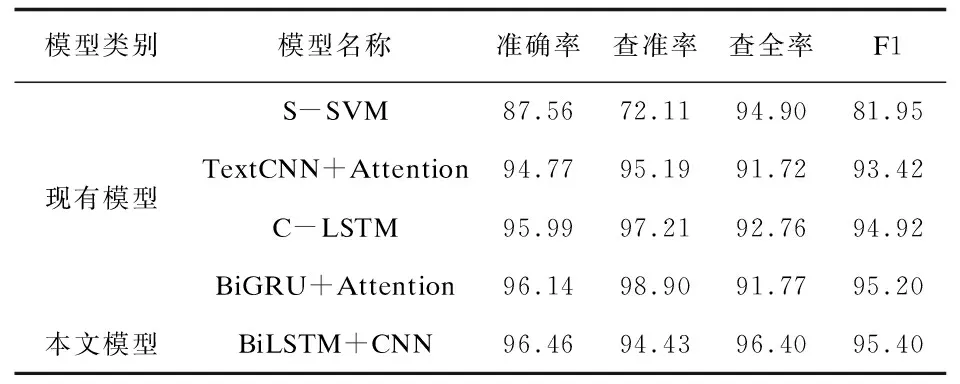
表6 本文模型与其他模型效果对比分析(单位:%)
查准率和查全率是一对矛盾的度量。当查全率较高时,虽然降低了将非谣言识别为谣言的可能性,但降低了查准率,提高非谣言识别为谣言的可能性。突发公共卫生事件谣言滋生后,由于信息不对称、认知、资源、经济等的有限性,公众极易产生恐慌、焦虑情绪[23],严重时甚至对社会安定和民生保障构成巨大威胁。公众、政府及相关机构期望应用平台尽可能识别网络中潜在的谣言,帮助自身快速地识别谣言,从而降低公众自身的损失(例如经济损失、恐慌、焦虑情绪等),政府及相关机构及时采取相应的措施以遏制谣言的传播和消除谣言的影响。而如果误判的话,政府、相关机构及应用平台可能会失去公众的信任等,因此在此背景下不能仅考虑查准率或查全率作为评价模型好坏的指标。F1值表示模型的综合性能,兼容查准率和查全率;准确率兼顾谣言和非谣言的查准率,本文将此作为评价模型的指标。本文模型准确率、查全率、F1值均明显高于现有模型,因此从查全率、F1值和准确率来看,本文模型对谣言的识别效果更佳。
3.6 不同特征融合谣言识别实验结果分析
参考黄学坚等[1]、石锴文等[2]的研究, 本文选取不同的特征组合进行特征消融实验,分析各个特征对谣言识别的影响。 结合3.4,语义特征是影响谣言识别的关键因素,在保持网络结构和参数不变、特征不同的情况下,在语义特征(T3)的基础上,对比分析递进融合特征后模型对谣言识别效果的影响。设极差表示各模型训练集和测试集准确率之差,反映出模型的平均性能和泛化能力。准确率差值、F1值差值为仅语义特征模型与其他模型的准确率与F1值的差值。具体实验结果如表7所示。

表7 不同特征融合的模型实验结果对比(单位:%)
3.6.1不同特征融合对谣言识别效果的影响分析
a.单个特征的融入模型能够不同程度地提高谣言识别效果。由表7可知,根据准确率和F值,单个特征影响程度由高到低,依次为统计特征、传播特征、用户基本特征、用户历史特征和情感特征。其中统计特征和用户基本特征全面提升了谣言预测查准率和查全率,传播特征、用户历史特征和情感特征提升了谣言预测的查全率,而查准率略有降低。查准率贡献最大的是统计特征,用户历史特征贡献其次,最后是传播特征和情感特征。查全率贡献最大的是传播特征,其次为用户基本特征,最后是传播特征和用户历史特征。单个特征分别融合后,F1值都明显的提升,提高了模型的综合性能。
b.内容特征仍然是谣言识别的主要特征。由表7可知,T3融入T1、T2后,即内容特征(T1+T2+T3)明显提高谣言识别预测的查全率(92.27%)、查准率(91.86%)、F1值(92.06%)。
c.基于内容特征,随着融入特征增加,模型谣言识别能力越强。由表7可知,融入S,模型查准率持平,查全率持续提升;递进融入U后,模型查准率、查全率显著提高;递进融入H后,模型查准率持平,查全率提升,所有指标达到最高,准确率和F1值分别达到了96.27%和95%。
因此,公众或政府部门相关机构及应用平台等可根据微博特征对谣言识别的影响程度采取相关的措施,例如关注和识别微博文本特征,尤其是在谣言高发阶段10—13点和20—24点(见图3),重点关注微博语义特征(例如语词表达)、情感表达(符号、情感词的使用等),及其引起的传播效果;同时建立用户信息数据库保存用户基础信息和用户历史信息,以辅助谣言识别。在谣言爆发初期,其他信息较少的情况下,可充分利用用户的历史信息对谣言进行识别。
3.6.2特征融合对谣言识别模型性能影响分析
随着融合特征递进增加,模型平均性能、泛化能力越强,预测效果更好。由表7差值可知,仅使用T3模型在训练集和测试集上的准确率之差最大,达到1.91%。而融入了任一单特征后,模型极差明显下降,表明模型的泛化能力得到明显提升。而递进融入2个以上特征后,极差大幅下降,泛化能力大幅提升,预测能力更强。
4 结 语
在公共卫生事件发展过程中准确、高效的谣言自动识别模型能够辅助公众、政府及相关部门更早地发现谣言并阻断谣言传播。本文在现有研究的基础上,从用户基本特征、用户历史特征、内容特征、传播特征4个维度,构建基于混合神经网络的多特征融合的公共突发事件谣言识别模型。该模型采用BiLSTM+CNN网络抽取代表性的语义深度特征、DNN网络对谣言进行分类。实验结果表明:a.本文模型取得了较好地识别效果,综合性能优于常用的深度学习模型和现有的谣言识别模型;b.文本语义特征是影响谣言识别的关键要素,统计特征、传播特征、用户基本特征和历史特征都能够不同程度地提升谣言识别效果。
本文研究还存在一些局限性,例如未考虑谣言评论内容特征的影响、本文提出模型仅使用新冠疫情数据验证等,下一步将在此基础上做进一步探讨,以更好为相关部门的决策参考提供依据。
猜你喜欢
环球时报(2022-04-13)2022-04-13
中国盐业(2018年17期)2018-12-23
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
新高考·高一数学(2016年10期)2017-07-06
计算机应用(2016年10期)2017-05-12
民间文化论坛(2016年2期)2016-12-01
中国管理信息化(2009年10期)2009-06-19
