
融合深度学习和链路预测的交叉性研究主题预测研究*
2022-12-26 03:16:26吴金红黄彩云李问秋王济平
情报杂志 2022年12期
吴金红 黄彩云 李问秋 周 磊 王济平
(1.武汉纺织大学管理学院 武汉 430070; 2.武汉纺织大学会计学院 武汉 430070)
0 引 言
回顾科学发展史,不难发现许多重大科技突破均源于多学科间的交叉融合,如经典物理学与数学的交叉促成了量子物理学、机械自动化和生物学的交叉促成了仿生学科、脑科学和计算机科学的交叉促成了脑机接口研究。2019年4月29日,国家教育部、中央政法委、科技部等13个部门在天津联合启动“六卓越一拔尖”计划2.0,全面推进新工科、新医科、新农科、新文科建设,标志着从国家层面全面推进学科内部、学科门类间的融合性发展。同时,研究领域交叉还进一步影响产业创新链的中下游,通过技术融合方式是促成重大技术创新。既往研究表明技术突破主要出现在多领域交叉地带,潜在新兴技术更多来自于对现有研究领域和专利技术的重组[1-3]统计数据亦表明大部分突破性技术是对现有知识的重新集成[4],同时对外部技术的广泛搜寻分析能够显著促进产业突破性创新[5]。
交叉性研究主题的涌现是学科交叉的一个外在表现,及时发现这些主题将有利于提前布局产业发展战略,赢得先机。情报学、知识管理、技术创新管理等多个学科领域高度重视研究学科交叉主题发现等方面的研究。相关研究提出一些跨界型技术、边缘新兴学科的识别模型与方法。但经典研究范式和传统技术工具面对海量数据时力有不逮,存在模型复杂度激增、结果收敛性偏弱等问题。而深度学习方法在处理大数据方面具有隐藏特征提取能力较强等明显优势。因而,本文将引入LDA模型、链路预测、LightGBM等多种机器学习与深度学习模型,对部分学术领域的主题演化进行分析,以期提升交叉性研究主题预测的效率、精度和泛化能力。
1 相关研究
目前,学科发展过程中的融合性特征日益显著。创造力心理学研究表明,对已有知识进行新的组合可能带来科学研究上的突破或新发现[6]。为了发现学科交叉性研究主题、追踪跨学科研究的热点,情报学研究提出了多样化的分析方法。根据分析对象的结构化特征,可将相关方法分为词频统计、引文网络分析、文本挖掘三类。a.词频统计方法是文献计量学的经典方法之一,该方法以词语为分析单元,统计关键词词频或关键词共现关系确定研究热点或交叉性主题。如隗玲等根据情报学学科高水平论文的主题词共现网络的演化特征建立桑基图,使用 Blondel 分区算法和基于核心节点的节点重合度指标,划分情报学学科各阶段研究主题[7]。b.引文网络分析以文献为分析单元,根据文献间的共被引关系确定学科研究基础,统计文献间的耦合关系确定学科研究前沿,统计文献间的直接引用关系确定学科演化的关键路径。如黄鲁成等利用突变词和专利引用关系研究主题的创新性和学科交叉性,来探索和发现跨学科的研究前沿[8]。c.文本挖掘法以自然语言处理为基础,综合考虑文法规则、语义知识、文本背景,建立文本间的语义关联性挖掘模型。常见的技术主题表示模型包括技术主题词模型、词汇链主题词模型、SAO/SVO /SPO主题词组模型、技术功效主题词模型;具体包括本体工程模型、向量空间模型、主题模型、主题图模型等多种形式[9]。如谭春辉等利用LDA模型抽取数据挖掘领域国内外研究主题,进而根据新颖性、支持度两个指标筛选出领域研究的热点主题[10]。
情报学经典研究为探索学科交叉性主题奠定了坚实的理论和方法论基础,但相关研究多为事后回顾,事前预测功能有待提升。针对这一突出问题,新兴研究引入链路预测(Link Prediction)技术,以期从已知的网络节点和连接中预测出尚未存在的、面向未来的连接。如张斌和马费成研究了科学知识网络中链路预测的类型、研究思路和方法[11];Zhang J将链路预测与机器学习算法结合,进一步预测合著网络演化趋势及推荐潜在合作者[12]。同时,考虑到数据量高速增长对传统数据挖掘模型的计算复杂度暴增带来的挑战,研究人员亦尝试将深度学习技术引入到信息预测中。如刘夏等使用随机森林(Random Forest,RF)模型处理大量专利数据,以降低经典决策树模型在专利质量预测中应用的误差[13]。徐璐等为了对金融科技专利进行自动化分类,引入支持向量机、梯度提升决策树、随机森林、决策树、K近邻法5种机器学习算法,最终发现随机森林对测试集的预测效果最佳[14]。
综上所述,分析交叉性研究主题有助于探索学科演化规律、发现新兴核心知识区块。考虑到相关研究的关注点正在从基于已产生的交叉性研究主题的后总结转向对未来可能产生的新交叉研究主题的预测;作为研究对象的相关学术资源的数量也日益增多。
2 交叉性研究主题预测框架构建
为实现交叉性研究主题识别,本文从主题内容关联性出发,构建融合深度学习和链路预测的交叉性研究主题识别模型,基本思路是首先获得文档中的潜在主题,为减少技术主题选择的盲目性,选用LDA概率模型得到主题-主题词分布以及文档-主题分布,从而聚焦技术文档涉及的核心主题;第二步进行潜在技术主题的关联度侧度,利用链路预测算法在从网络结构出发,分析技术主题之间的相似性,已链接的节点对的指标值和预测出的未链接节点对之间的相似度值;第三步进行交叉性研究主题的识别与预测,考虑到链接数量庞大,采用LightGBM算法快速准确地计算对应链接对被判定为强链接的概率值以及影响链接对产生的特征值的重要性排序。该研究框架的具体流程如图1所示。
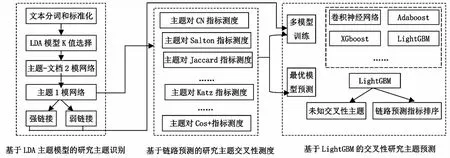
图1 交叉性研究主题预测流程
2.1 基于LDA模型的潜在主题识别
隐含狄利克雷分布模型(Latent Dirichlet Allocation,LDA)是由Blei等在2003年提出的一种文档主题模型[15]。LDA把“文档与词汇”矩阵通过文档-主题-词的层级运算,提炼出“文档与主题”分布矩阵和“主题与词汇”关联矩阵。这两个矩阵生成过程本质上是一种词汇分布概率选择过程,通过概率分布的集成反映出本领域研究主题的焦点,从而识别出潜在的未表征出来的研究主题。
LDA模型的关键在于寻找最优主题数目K的值,本文选择基于相似度的自适应最优LDA模型选择方法,以确定最优主题数。LDA主题模型分布结果输出包含主题-主题词概率分布与文档-主题概率分布。主题-主题词分布中存在K个潜在主题数,每个主题包含Top-N个词组以及它们对应的概率。依照设置的主题概率输出阈值来选取文档-主题分布,能够在每个文档对应的K个主题中选择符合概率阈值的主题,然后根据同一文档对应的主题之间是否存在隐含的联系,评价所有文档-主题分布中的主题之间存在的隐含联系。
2.2 基于链路预测的研究主题交叉性测度
链路预测(Link Prediction)可用通过已知的研究主题网络节点之间的链接关系预测尚未产生链接关系的研究主题间产生链接的可能性。链路预测方法可以在交叉领域中寻找未知的交叉研究主题,也可以补全直接观察无法发现的缺失交叉研究主题。因此框架的第二步本文选用链路预测方法对未知或缺失的研究主题链接情况进行研究主题交叉性侧度。基本思路是采用LDA主题模型提取得到的潜在主题,分别统计不同主题之间的链接关系情况;然后去除重复的链接关系,根据剩下的链接关系构建无向网络图,根据已经存在的链接关系作为训练集,计算链路预测中的相似性指标来得到不同指标下对应的未知链接关系之间的值。选用的相似性指标如表1所示。
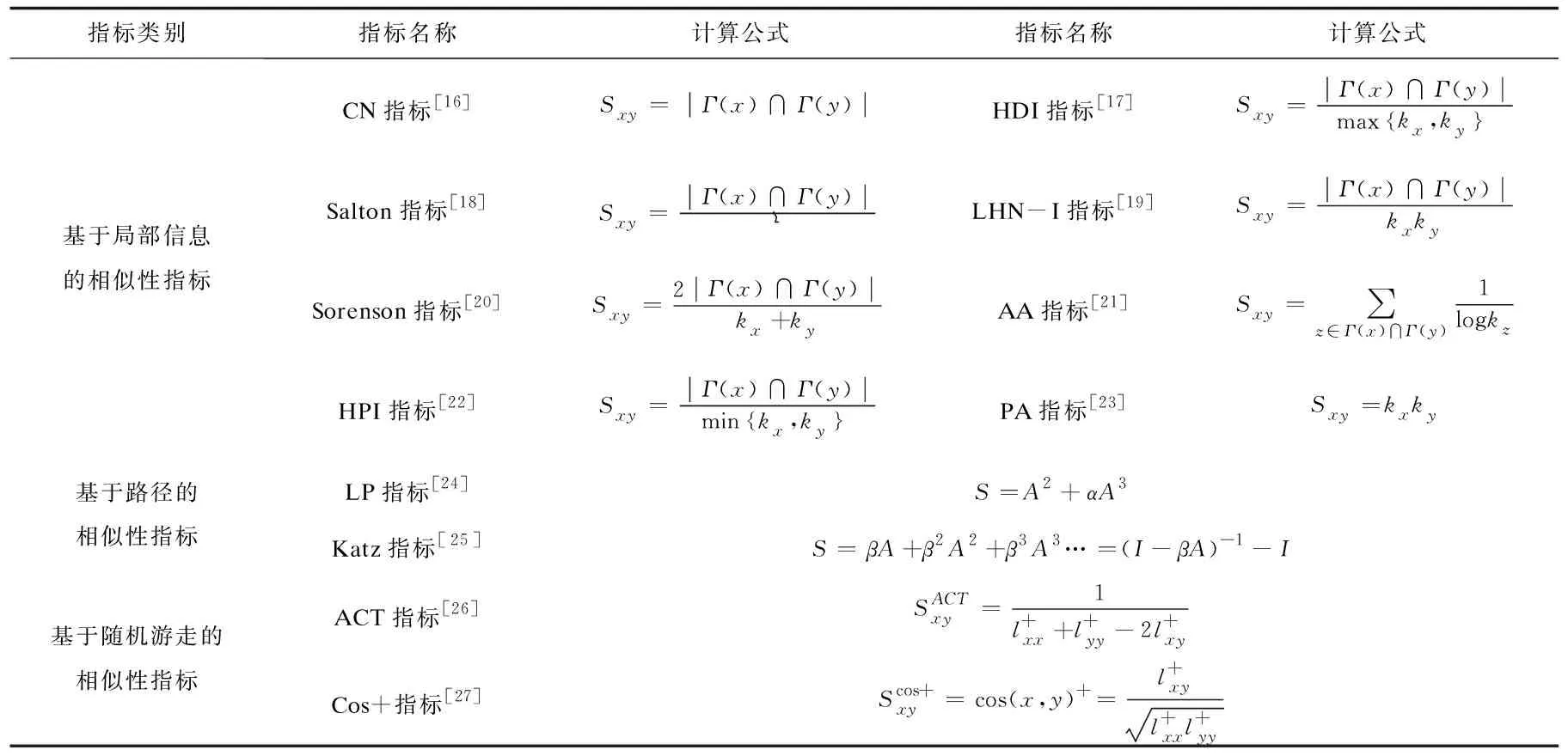
表1 链路预测相似性指标
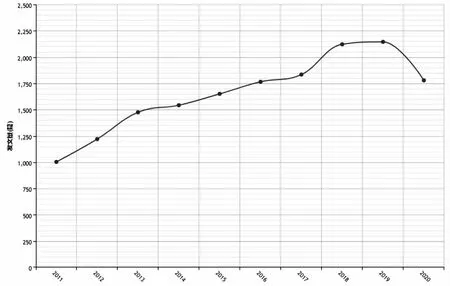
图2 近10年“物联网技术”主题论文发表趋势
2.3 基于LightGBM的交叉性研究主题预测
LightGBM是梯度提升决策树(Gradient Boosting Decision Tree, GBDT)的改进版实现框架。它是由微软提出的一款开源的基于决策树的梯度提升框架,由于选择采用基于直方图的分割算法来代替传统的预排序遍历算法,从而具有更加快速的训练速度、更小的内存消耗、更高的模型准确率、支持分布式快速处理海量数据的特点[28]。
GBDT可以看成是单一决策树的加法模型,具体定义为公式(1)所示:
(1)
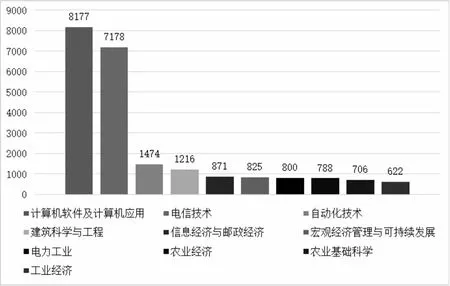
图3 “物联网技术”主题的学科分布
其中,T(x;θm)表示决策树,θm为决策树中的参数,M为树的数量。LightGBM采用的逐叶生长策略从所有叶片的分裂情况的结果中找到分裂收益最高的叶片,然后继续增加最大深度限制,建立循环分裂模式寻找最优决策树。这种模式不仅能够提高效率,而且防止过拟合效果较好。本研究中采用LightGBM算法框架对经过链路预测处理的数据集进行训练和预测,最后输出存在未知强链接关系的交叉领域新兴主题节点对及其相对应的概率。
3 实证分析:以物联网技术为例
3.1 数据源及数据预处理
本文用来验证模型的数据采集自中国知网,以“物联网技术”为主题进行检索后以自定义格式存储截止于2020年11月4日的13 840篇期刊论文信息,包含标题、关键词、作者、年份、单位和论文背景等信息。总体上看,“物联网技术”主题相关论文呈现上升趋势,如图2所示,主要集中在计算机、电信技术与自动化技术等学科领域(见图3)。
对13 840条数据进行了关键词筛选,首先进行去除停用词操作,例如“开发”、“研究”等与交叉研究主题关键词无关的词汇;经去停用词处理后的关键词数据中会有意思表达相近的词组,例如部分词是通过增加一定的前缀或者后缀进行表达的,因此需要将表达意思相近或者相同的词组进行统一处理,避免出现多对一的情景。在本次验证实验中,经过预处理后的关键词个数为49 618。随后对文本数据进行向量化操作,并对数据特征值及标签处理后对数据进行标准化处理。最后得到了2 133对交叉主题关系,并选用其中的282对隐含关系进行新兴交叉主题预测。
3.2 结果及分析
3.2.1潜在技术主题识别
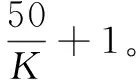

表2 物联网技术研究主题分布
根据设定的主题-文档阈值,保留高于阈值的文档-主题关系,过滤低于阈值的文档-主题关系。若存在一篇文档分属两个主题说明这两个主题交叉。由此建立主题间的链接关系,将文献划分为70个主题领域并同时生成对无向网络图。由于篇幅限制,图4仅展示部分主题间存在强链接关系的网络图。
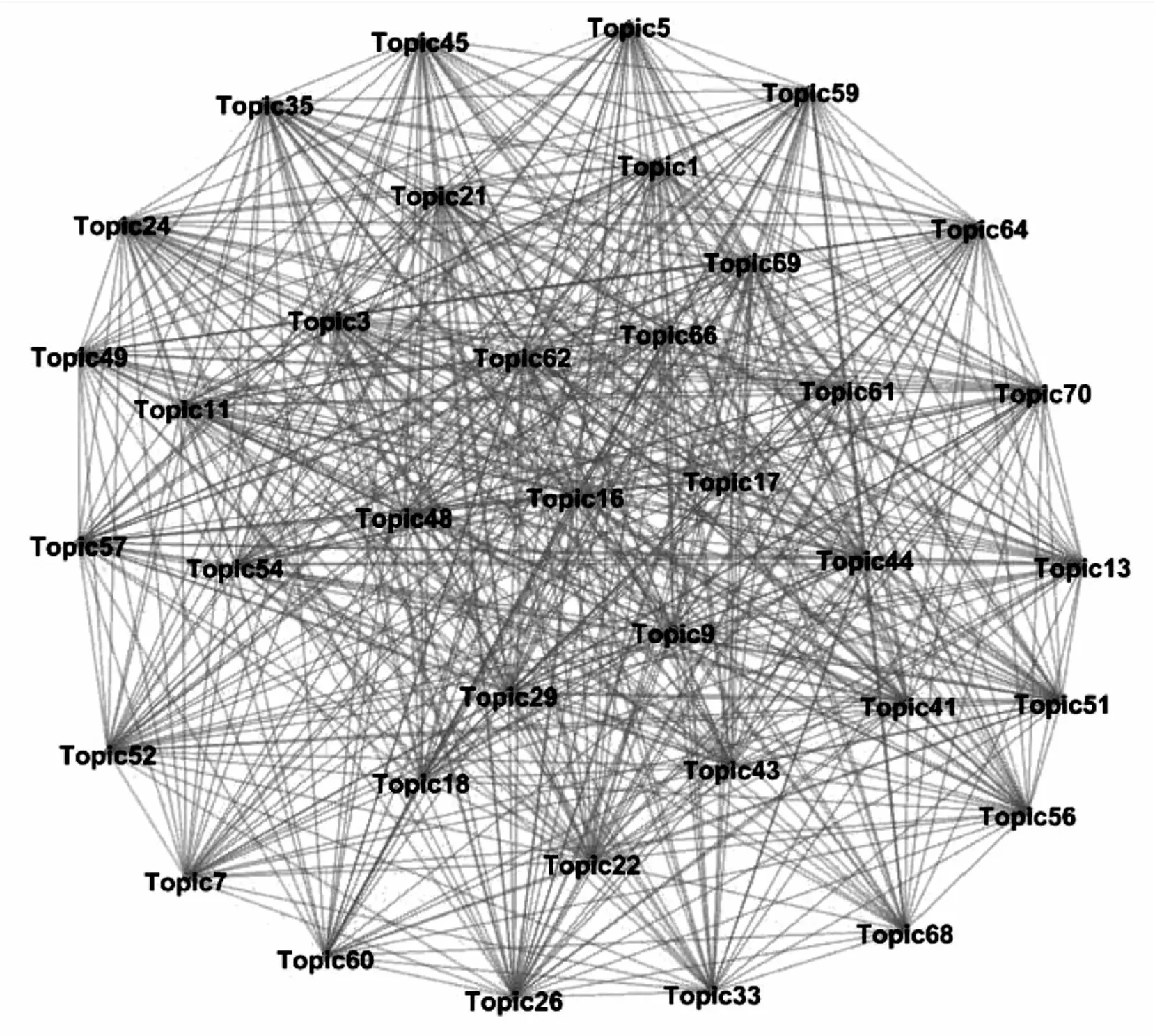
图4 主题交叉的五向网络
3.2.2物联网技术研究主题交叉性测度结合LDA识别到的潜在主题结果,主题间的平均聚类系数为0.994,说明主题间关系较为紧密。基于LDA识别到的潜在主题结果与链路预测的14个相似性指标计算主题间的交叉程度,部分结果如表3示。
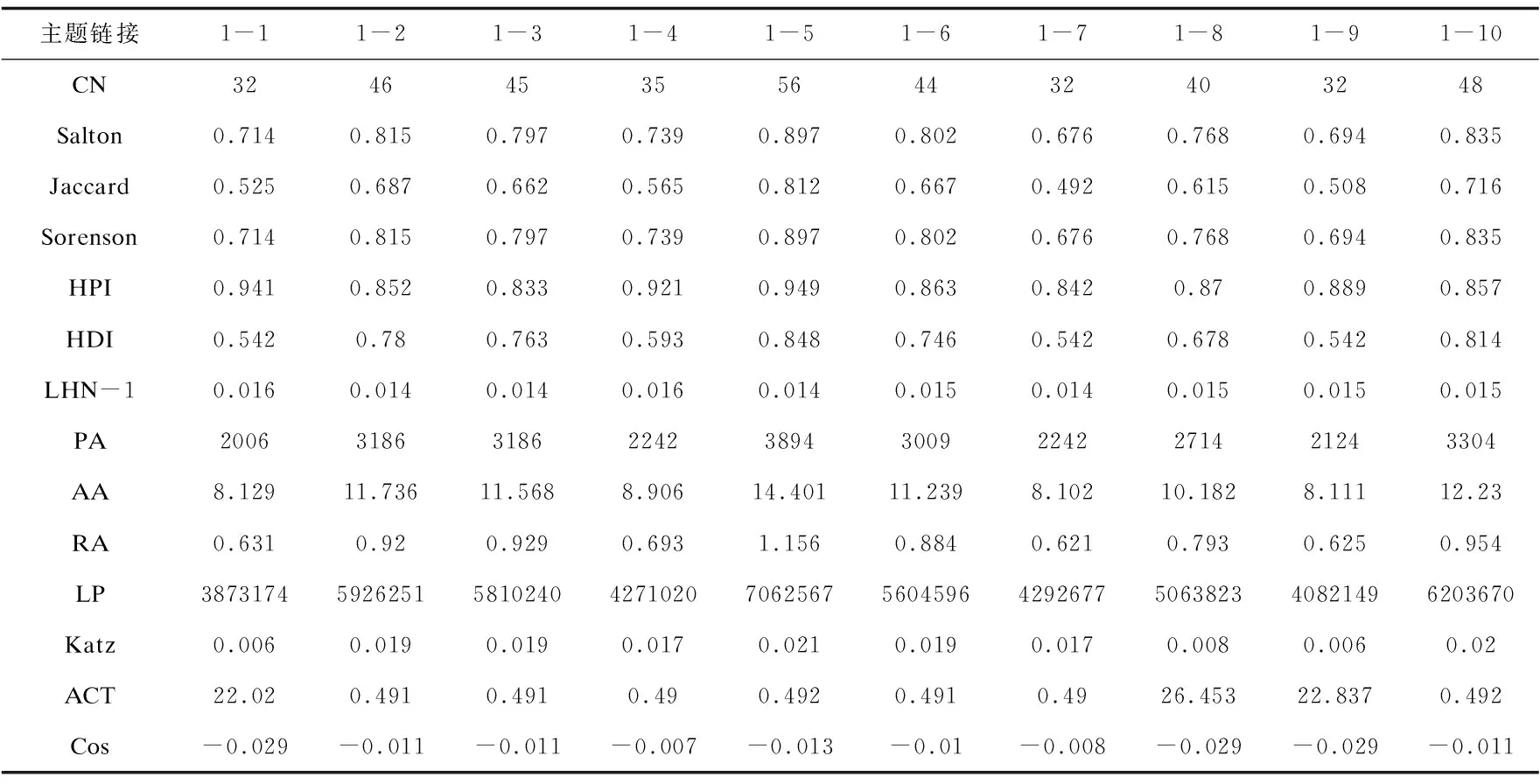
表3 各链路指标下部分主题间的交叉程度
结合后续章节的主题交叉性预测分析分析,本文选取了后续表现最好的LightGBM下各指标的重要性情况做出分析。对14个链路预测指标在LightGBM算法中的重要性进行排序,发现重要性最高的前三个指标分别是基于路径的Katz指标、基于局部信息的HPI指标、基于随机游走的Cos+指标。具体来看,LightGBM建模中各链路预测指标的重要性排序为Kazt、HPI、Cos+、LHN-I、HDI、RA、LP、ACT、Salton、PA、CN、Jaccard、AA、Sorenson。由此说明,在基于LightGBM算法的对主题交叉性的预测过程中,路径相似性指标的影响力大于局部信息相似性指标,基于随机游走的相似性指标影响力相对较低。指标重要性排名的结果在一定程度上说明从发展路径中预测交叉领域中可能出现的新兴研究主题是可行的。
3.2.3物联网技术研究主题交叉性预测
根据以主题为节点构成的主题链接无向网络图与研究主题的交叉性测度计算结果可得到如下数据:有关物联网技术的研究主题中存在2133对主题链接关系;根据LDA模型中的阈值进行标注后,存在强链接关系的研究主题链接关系有483对,具有弱链接的链接关系有1 650对,可能存在的隐含研究主题关系有282对。为了选择合适的预测学习模型,笔者使用卷积神经网络、Adaboost、XGboost,与LightGBM进行对比试验。初次试验时,由于数据分布存在不均衡(强链接:弱连接=1:3.4),各方法的准确率均低于80%,因此需要对数据分布进行采样调整。本文通过人工少数类过采样法(Synthetic Minority Over-Sampling Technique, SMOTE)对少类别数据进行人工合成实现采样均衡,保证训练过程中两类样本数据量处于均衡状态,得到的各模型的准确率为卷积神经网络(82.50%)、Adaboost(82.00%)、XGboost(83.80%)以及LightGBM(85.12%)。
根据模型训练效果看来,LightGBM模型在对交叉性主题识别的过程中,测试效果最佳,因此本文选择LightGBM模型对交叉性研究主题进行预测。LightGBM潜在主题关联度计算模型的具体评价指标如表4所示。

表4 LightGBM模型测试指标
随后将训练好的LightGBM模型用于可能存在的隐含研究主题关系的282个主题对进行预测试验。预测结果中,概率>80%的强链接23对,80%>概率>60%的链接25对,概率<60%的链接234对。可能存在的隐含研究主题关系中经过LightGBM模型预测后,可能发展为热点新兴交叉领域研究主题的主题关系间概率值Top10结果如表5所示。
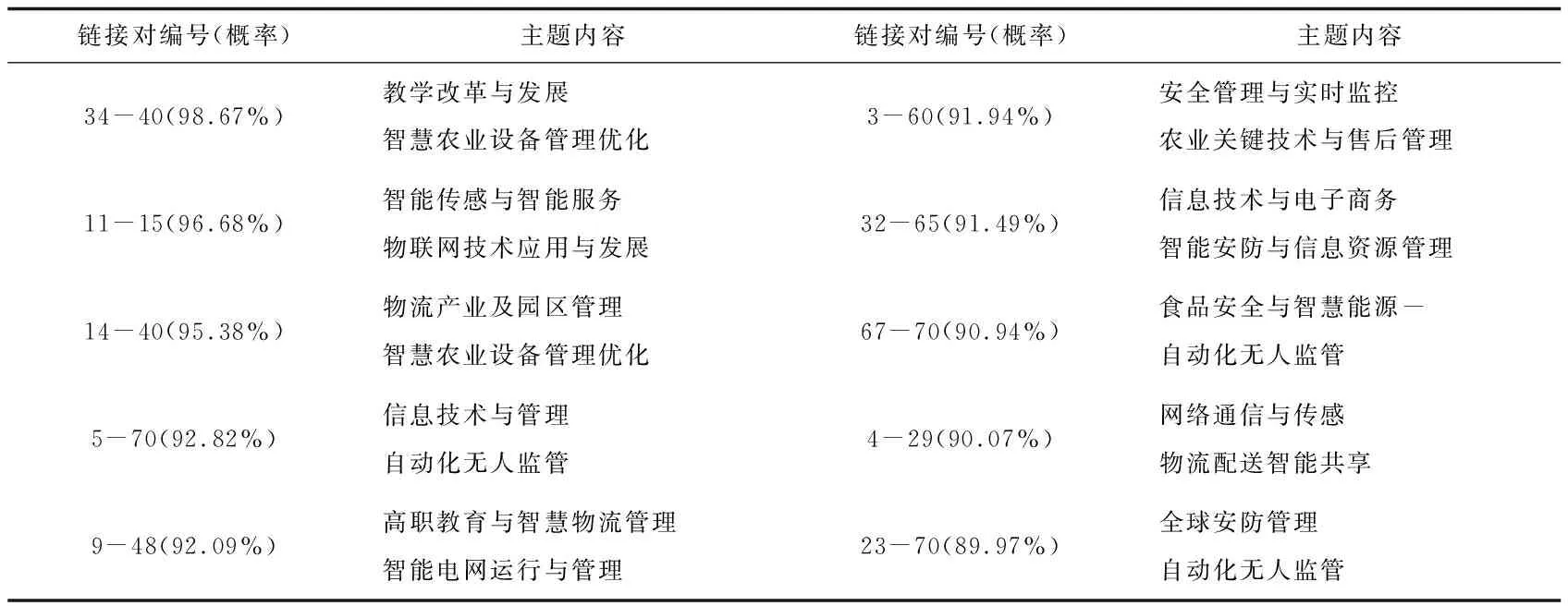
表5 LightGBM模型预测的前十个强链接主题
由表6可知, LightGBM模型预测出的未来物联网技术交叉性主题的两个可能重要发力点分别是主题40(智慧农业设备管理优化)、70(自动化无人监管)。围绕主题40(智慧农业设备管理优化)形成的未来交叉性主题有2个:一是与主题34(教学改革)与发展共同组成的智慧物联网农业相关的教学改革[30];二是与主题14(物流产业及园区管理)共同形成的智慧物联网农业物流园区管理[31];并且这两个主题的发生概率分列第一和第三,笔者以“智慧农业+物联网”为关键词在知网上进行搜索,获得了1 995篇论文,从时间分布上来看,都是近10年来涌现的论文。同时,在我国十四五规划中,提出“强化农业科技,建设智慧农业”,也反映出这个主题必将是今后一个发展和研究热点。围绕主题70(自动化无人监管)形成的未来交叉性主题有3个:一是与主题5(信息技术与管理)共同组成的基于物联网技术的自动化IT监管技术。二是与主题67(食品安全与智慧能源)共同形成的基于物联网技术的无人监管技术在食品安全与智慧能源中的应用[32]。这与近年来人们关注的食品溯源有很好的契合度。如京东、阿里巴巴等大型电商平台推出“步步鸡”等基于区块链的食品溯源项目,就离不开物联网技术的支持。三是与主题23(全球安防管理)共同形成的物联网安防自动化监管技术。结合两个可能热点分析,未来物联网技术研究主题的交叉路径主要有两类:首先是物联网技术与产业应用场景的深度融合,如物联网+智慧农业、物联网+食品安全、物联网+能源管理等;其次是物联网核心技术的精细化发展,如智能传感器技术、信息分析技术、无人监控技术等。
4 结 语
本研究结合多种机器学习模型,建立交叉性研究主题预测框架。首先,利用LDA模型建立主题-文档间的映射关系;接下来,利用链路预测技术实现主题间交叉性的测度;最后以LightGBM模型提升交叉性主题预测的精度和效率。面向物联网技术的实证研究表明,该领域的研究主题可以划分为70个;利用14个链路预测指标分别计算各链接对和非链接对的相似性,并利用LightGBM模型预测可能的基于物联网技术的未来交叉研究主题。本文的贡献主要体现为两点:一是针对文本内容的信息组织特征和信息预测的功能需求,充分发挥LDA主题模型、链路预测、LightGBM等方法的优势,构建基于机器学习的交叉性研究主题预测框架。二是基于实证研究预测出物联网技术研究主题未来交叉的两条路径:物联网技术与产业应用场景的深度融合和物联网核心技术精细化发展。本文存在一些不足之处,如采用LDA主题识别的精度方面不是很高,数据量相对较少,得出的结论需要进一步验证。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:18:10
党的生活(黑龙江)(2022年4期)2022-04-25 22:14:17
移动通信(2021年5期)2021-10-25 11:41:48
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
通信世界(2018年27期)2018-10-16 09:02:56
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
计算机工程(2015年8期)2015-07-03 12:19:54
风能(2015年10期)2015-02-27 10:15:34
中国交通信息化(2014年3期)2014-06-05 03:07:09
单片机与嵌入式系统应用(2014年9期)2014-03-11 15:35:12
