
仿人表情机器人情感表达技术研究综述
2022-12-25 12:22王玉金
重庆理工大学学报(自然科学) 2022年11期
何 苗,毕 健,王玉金,殷 勤
(重庆理工大学 机械工程学院, 重庆 400054)
0 引言
仿人表情机器人具有逼真的类人外观和表情行为,能够实现人机情感交互,在社会生活各领域扮演着重要角色,应用前景广阔。仿人机器人情感表达技术是机器人与人工智能研究领域中的热点话题之一,也是人机交互领域的一项前沿技术。
本文在分析与总结仿人表情机器人的国内外研究历程的基础上,重点对仿人表情机器人的结构设计与情感控制两个方面进行了综述,并对仿人表情机器人情感表达技术作出展望。
1 研究历程
日本和欧美国家对仿人表情机器人的研究开展得较早,不仅在机构设计、皮肤制作和控制算法方面取得了进展,还对仿人表情机器人的心理模型、学习能力、认知能力等方面进行了研究。随着机器人技术的不断发展,越来越多的国家投入到仿人表情机器人的研究之中。国内的表情机器人研究近20年发展迅速,取得了卓越成绩,产生了许多有代表性的机器人,如H&F robot系列[1-4]和SHFR系列[5-8]表情机器人。
根据表情实现效果与情感表达能力,可将现有仿人表情机器人划分为3个层次,如图1所示。其中,第1层次的仿人表情机器人初步具备类人外观,能产生6种基本表情,并具备简单的交互功能,这里面具有代表性的表情机器人有Kismet[9]、SHFR-Ⅲ[8]、WE- 4RⅡ[10]等。第2层次的表情机器人的仿人外观进一步提升,能产生更加丰富的表情动作,特别是仿真皮肤“Frubber”[11]的应用使表情机器人可以实现面部皱纹的微妙变化,情感表达功能更为丰富。部分表情机器人还被用于心理疾病治疗,如用于治疗自闭症的表情机器人Alice[12]。第3层次的表情机器人外形逼真,表情细腻,搭载了较完善的情感模型,能与人进行更自然的情感交互,典型代表有仿人表情机器人Sophia。她还是全球第1个被赋予公民身份的机器人。

图1 仿人表情机器人研究历程
为进一步探究仿人表情机器人的研究趋势,表1对3个层次里具有代表性的仿人表情机器人的技术特点与实现功能进行了详细分析与对比。
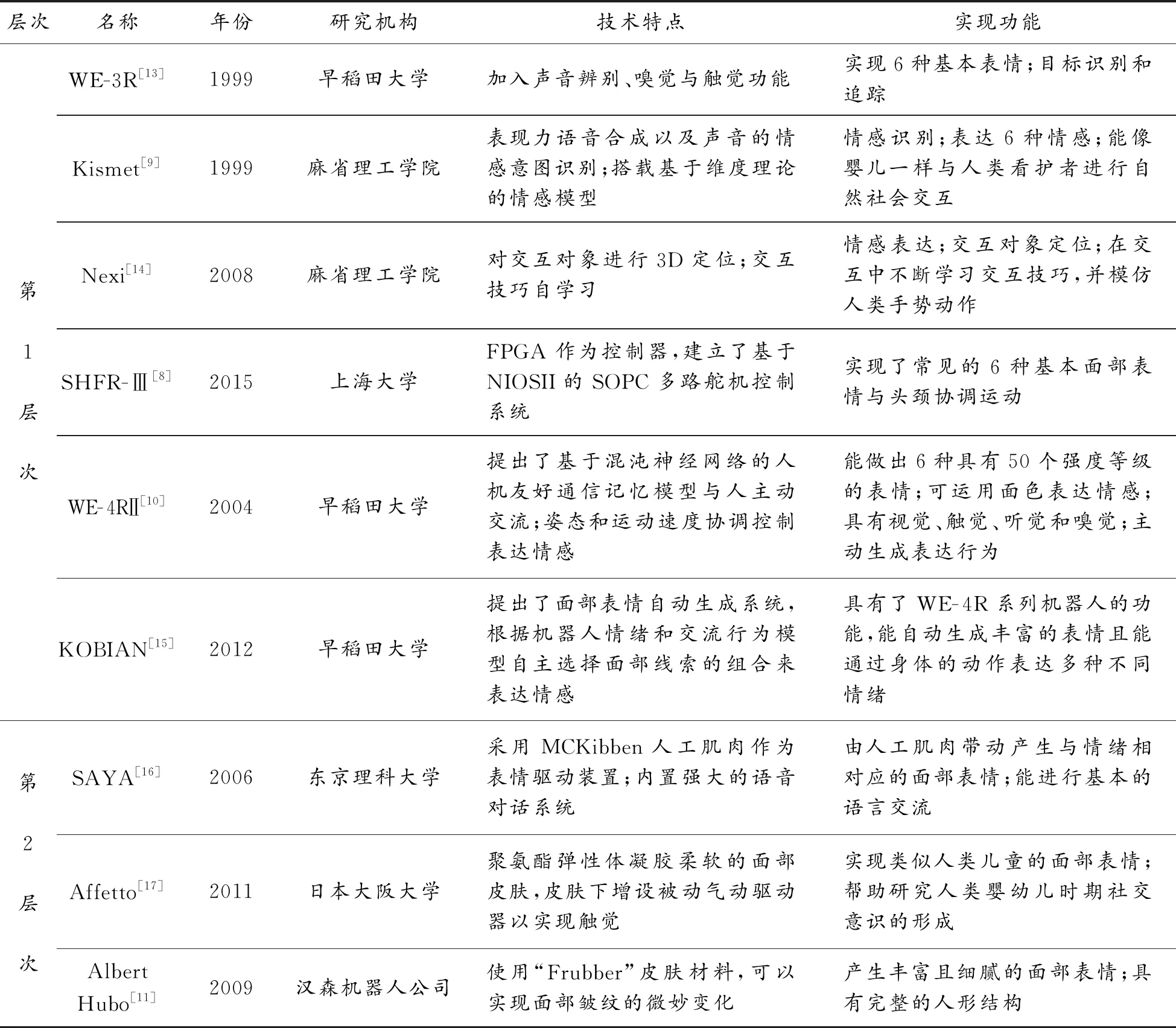
表1 国内外代表性表情机器人的技术特点与实现功能
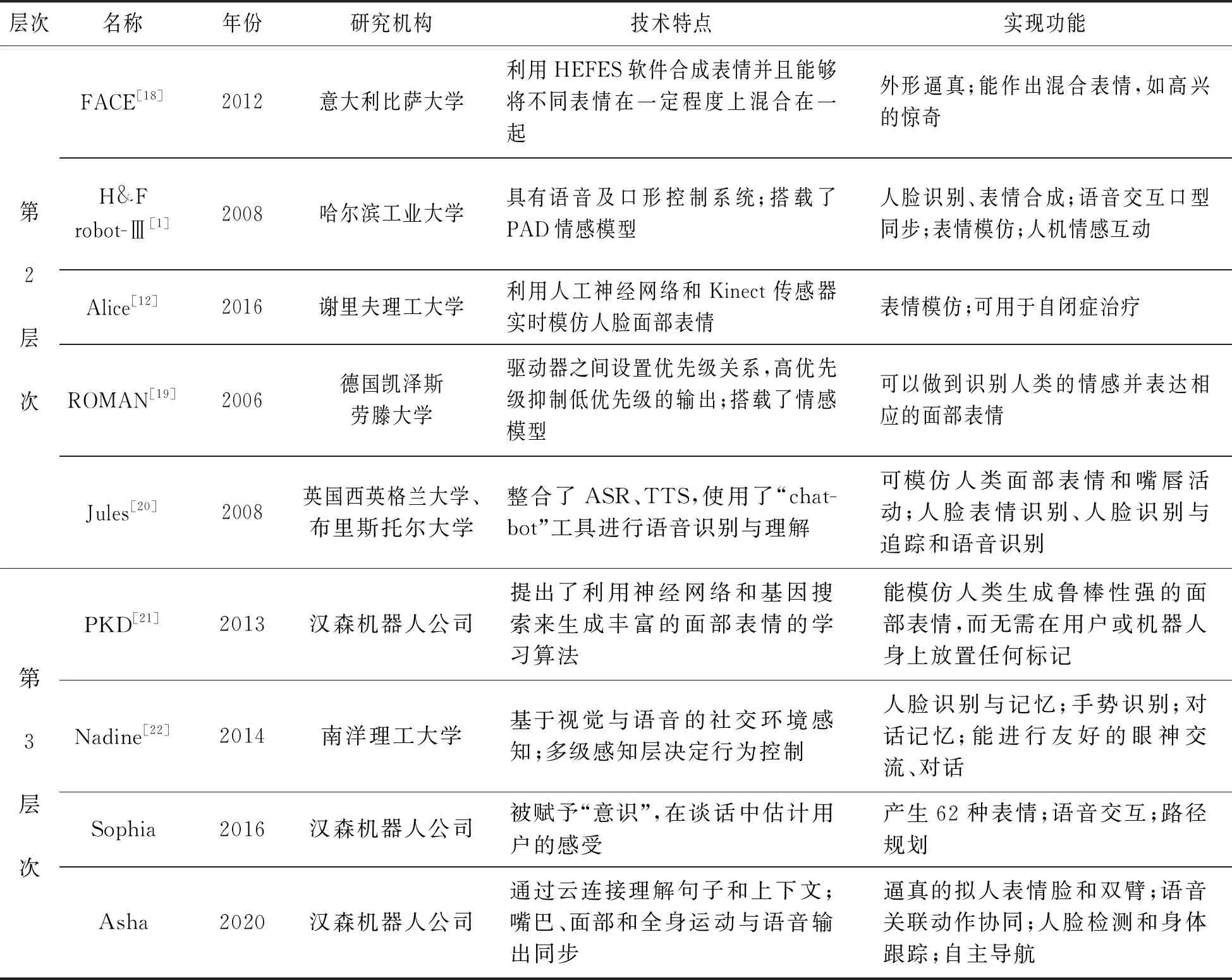
续表(表1)
从上述分析可以看出,仿人表情机器人的情感表达能力主要取决于结构设计与情感控制。结构设计主要集中于机器人面部,情感控制则集中于机器人情感建模与情感表达方式控制。总体来看,仿人表情机器人的情感表达系统示意图见图2。
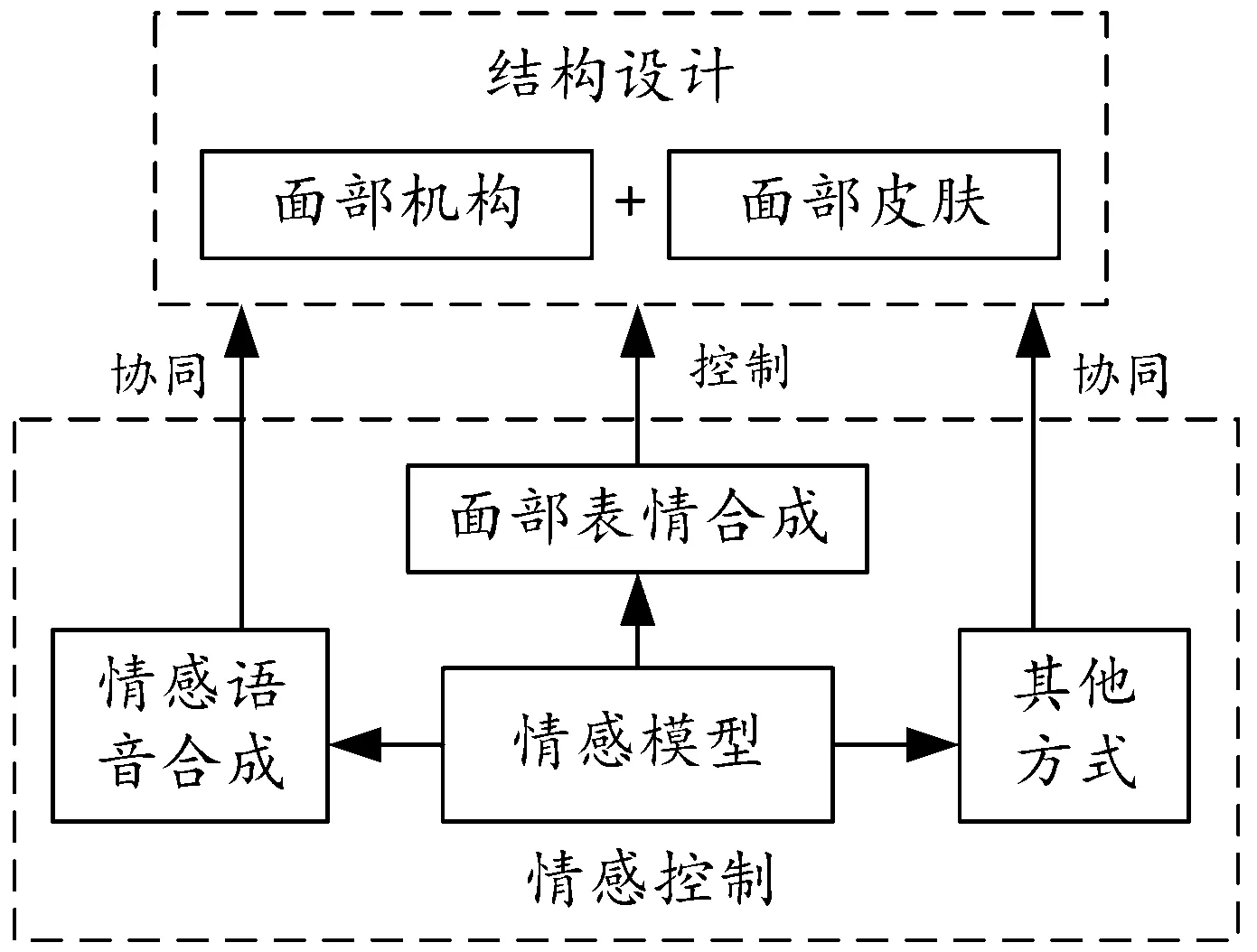
图2 仿人表情机器人情感表达系统示意图
2 面部结构设计
仿人表情机器人的情感表达以面部作为核心表现形式,面部结构以面部行为编码系统(facial action coding system,FACS)[23]为理论基础开展设计,具体分为两部分内容:面部机构设计与机器人皮肤设计。
2.1 面部行为编码系统
目前,最常用的表情划分方法是将其分成7类基本表情,即自然(无表情)、高兴、悲伤、惊奇、恐惧、愤怒与厌恶。FACS将人脸面部划分成46个运动单元(action unit,AU),每个AU由1块或多块肌肉组织组成。在FACS中,有24个AU与面部表情相关,而与基本表情相关的只有14个AU。表2列出了6种基本表情(“自然”表情除外)与AU之间的关系[24-25]。

表2 基本表情与AU的关系
2.2 面部机构设计
现有的仿人表情机器人的面部机构设计大多是利用FACS在机器人面部合理设置控制点位置及其运动方向(如图3所示),并在有限空间中设计精巧的机械结构以灵活控制机器人眼部、嘴部和脸颊等部位运动或形变,进而产生表情动作。另外,仿人表情机器人的设计不仅需要精巧的结构,还需要柔顺协调的控制算法、美观且尽可能逼真的类人外观,避免陷入“恐怖谷”。恐怖谷理论可以用图4表示[26],图中横轴表示机器人与人类的相似度,纵轴表示人类对机器人的好感度。在恐怖谷的区间内,机器人在动态时比静态时的恐怖感更强。

图3 面部控制点的位置及其运动方向设置
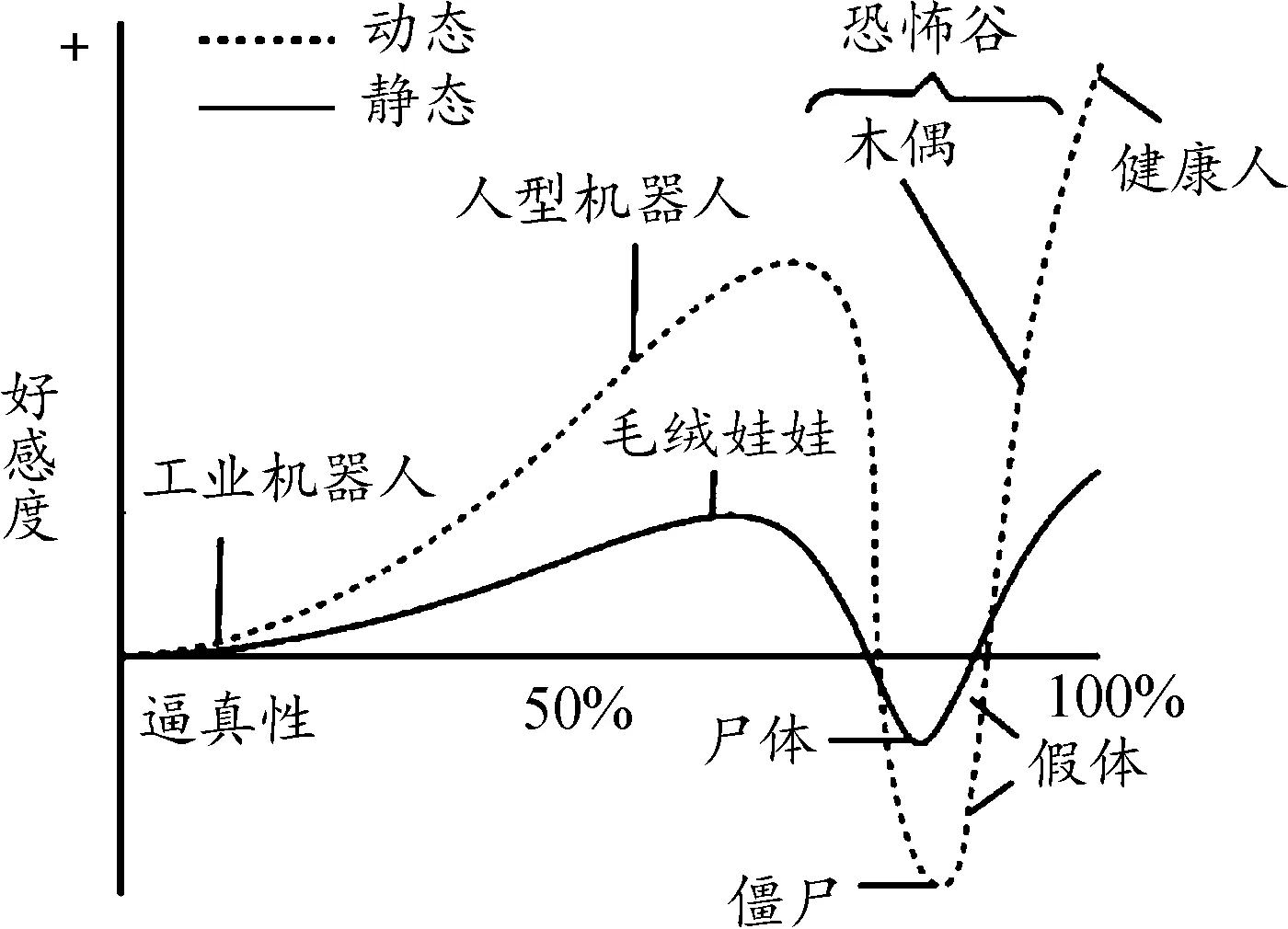
图4 恐怖谷理论示意图
从技术复杂度来看,仿人表情机器人的机构设计可分为纯机械式与仿人皮肤式2种。纯机械式相对于仿人皮肤式设计更加简单,无需考虑柔性皮肤控制问题,各柔性单元均被机械化,但逼真效果不如仿人皮肤式。典型代表有日本的“WE”系列机器人[27],如图5(a)所示。仿人皮肤式即机器人设计人造皮肤以达到逼真的仿人面部效果,如图5(b)所示的PKD机器人[21]。这也是目前大多数仿人表情机器人所采用的方案,除眼球外的其他部位均与柔性皮肤上的表情控制点相连,表情控制的关键在于面部皮肤的柔性控制。这种方案不仅对内部机构设计要求更加严苛,也对控制方式提出了更高要求。

图5 典型仿人表情机器人
人脸表情大部分动作来源于面部皮肤的运动。对于仿人表情机器人面部皮肤的控制,研究者们针对不同机构的设计方案研制了诸多具有代表性的面部表情驱动方式,使仿人表情机器人能产生更加自然的类人表情。机器人SAYA的表情由MCKibben型气动执行器进行驱动[16]。该执行器由气囊和外部的尼龙纤维编织网外壳组成,如图6(a)所示。当气囊内部气压升高时,由于编织网壳中尼龙纤维的不可延展性,致动器会根据其体积增加而缩短,使外部的尼龙线刚性体产生驱动位移。这种表情驱动装置质量轻、体积小、运动灵活,可以像人类肌肉一样分布在机器人面部表壳,如图6(b)所示。

图6 SAYA表情驱动装置
H&F robot-Ⅲ采用电机与绳索相结合的驱动方式控制表情,其机构原理如图7所示。其中,舵机6控制绳轮7转动,绳索4随绳轮转动而带动滑块2移动,而滑块在导向槽9内往复运动实现对表情控制点的位移控制[28]。该机构结构简单,集成度高,动作控制平稳,传递效率高。
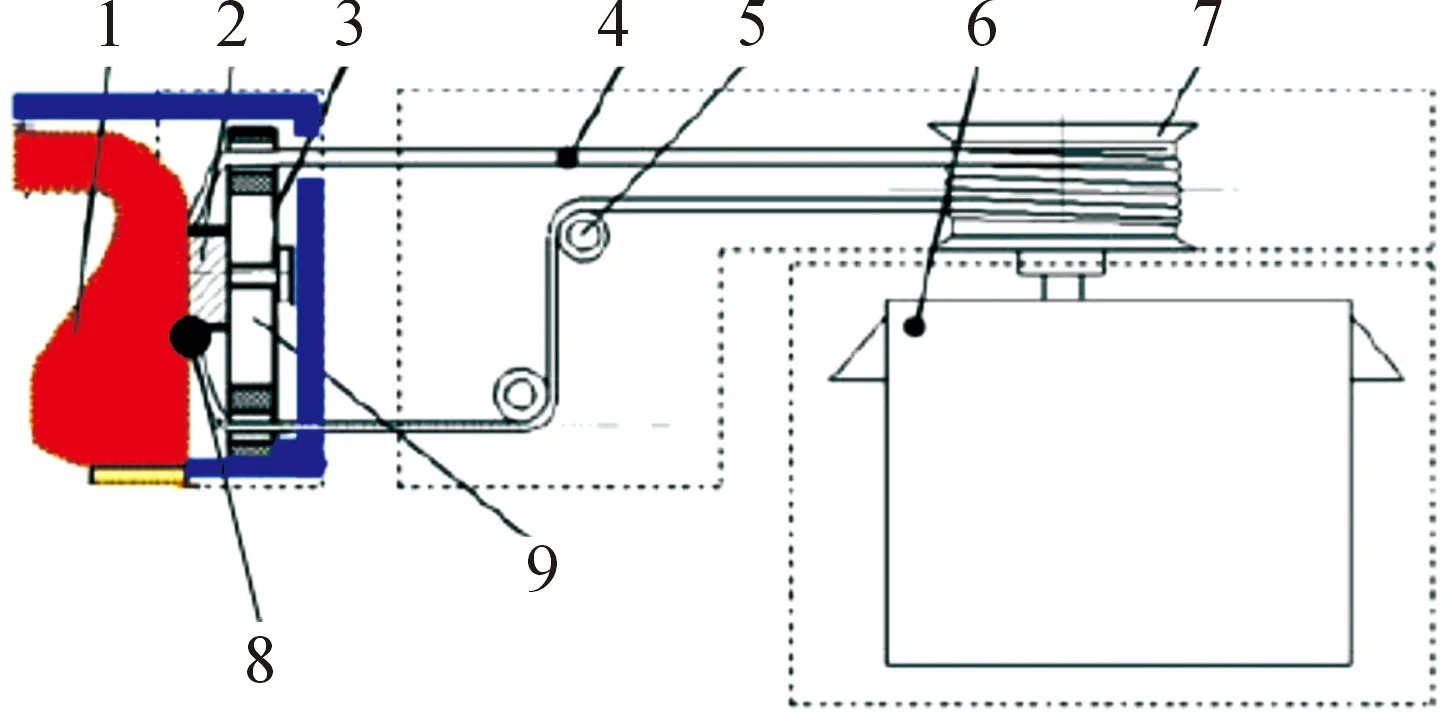
图7 H&F robot-Ⅲ面部表情驱动装置机构原理示意图
2.3 皮肤研究
表情机器人拥有高仿真和高弹性的仿人面部皮肤材料是模拟逼真机器人表情的基础。现有大多数表情机器人的面部皮肤材料采用的都是加工性能良好、易成型的硅橡胶。简易的硅胶皮肤制作流程如图8所示,这种硅胶皮肤的制作工艺简单,但效果一般[29]。逼真的机器人皮肤则需要更为复杂的制作工艺。邹人倜以自身形象制作的机器人,其皮肤可呈现汗毛、皱纹、斑痣等细节[30],但面部动作有限。汉森机器人技术公司利用海绵状人造橡胶与泡沫的混合物研制出了“Frubber”皮肤材料[11],并应用在了Albert Hubo、PKD等机器人身上。该款仿真皮肤逼真度高且能够实现较为自然的皮肤褶皱,同时能在面部驱动器的作用下作出更加精细的表情,仿真度极大提升。

图8 硅胶皮肤制作
人类皮肤具有灵敏的触觉功能,用于机器人触觉感知的电子皮肤的研究也一直备受关注[31-33]。通过触觉电子皮肤的设计,机器人能够辨别交互对象对它进行的是抚摸还是按压、打击等行为,进而可以从一个新的维度去分析交互对象情感。
3 仿人表情机器人情感控制
仿人表情机器人的情感来源于人为建立的情感模型。情感模型决定不同时刻机器人的情绪状态,不同的情绪则对应这不同的情感表达方式下的不同表现形式。现有的仿人表情机器人的情感表达方式则主要为面部表情合成和情感语音合成。
3.1 机器人情感模型
人类的情感受诸多因素的影响而复杂多变,因此让机器人具备类人情感极具挑战。要实现具有情感的智能系统,需要建立一个合适的计算模型来描述情感[34]。早期的情感模型以人工规则与简单情绪维度实现对人类情绪的推理,如PAD模型[35]、OCC模型[36]等,这种情感建模方式虽能表示较为丰富的情感状态但没有考虑不同情感状态之间的切换关系,进而难以实现自然的情绪变换。随着统计学习与机器学习的不断发展,情绪状态转移的设计方案不断涌现,同时情绪状态的触发与自适应体系也在不断完善。表3按发展历程对一些典型的机器人情感模型进行了总结概括。
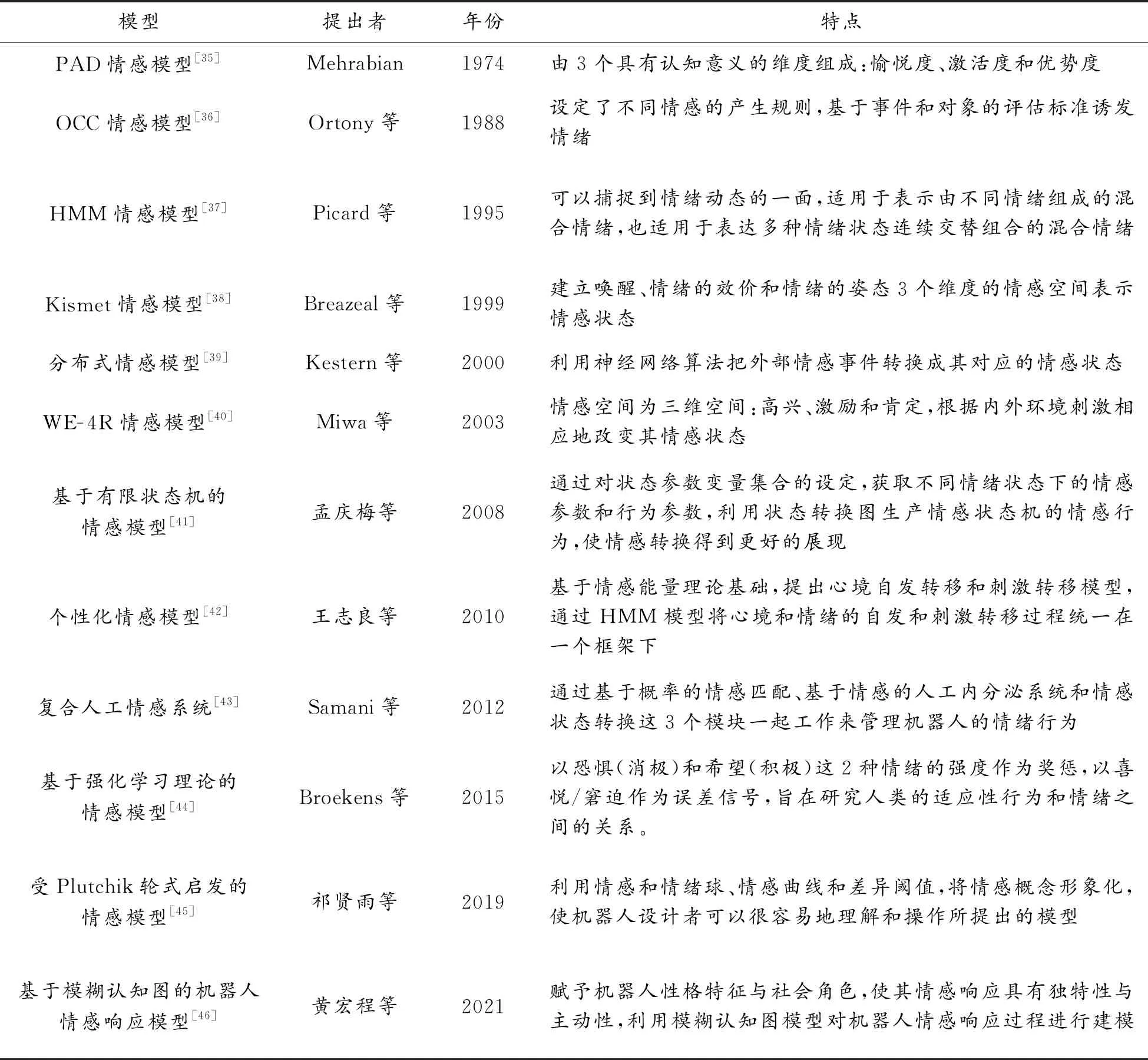
表3 典型情感模型概括
3.2 面部表情合成
仿人表情机器人的面部表情合成即控制其面部表情驱动器协同运动。为使表情机器人合成的表情更加自然,实现更好的交互效果,研究者们探寻了诸多表情合成方法,大致可分为人工设置和表情模仿2种。
人工设置即根据机器人面部AU与驱动器机械特性间几何关系预先设置好实现不同表情的驱动方式,具体包括各驱动器的位移、速度、优先级等。如 Mazzei等[47]为FACE表情机器人研制了一种用于生成和控制表情机器人和3D虚拟人物面部表情的混合引擎HEFES(hybrid engine for facial expressions synthesis),其结构如图9所示。HEFES利用FACS将表情标准化,基于情感笛卡尔空间合成基本表情和混合表情。用户可以通过HEFES直接创建机器人面部表情,而不需要艺术或动画技术。
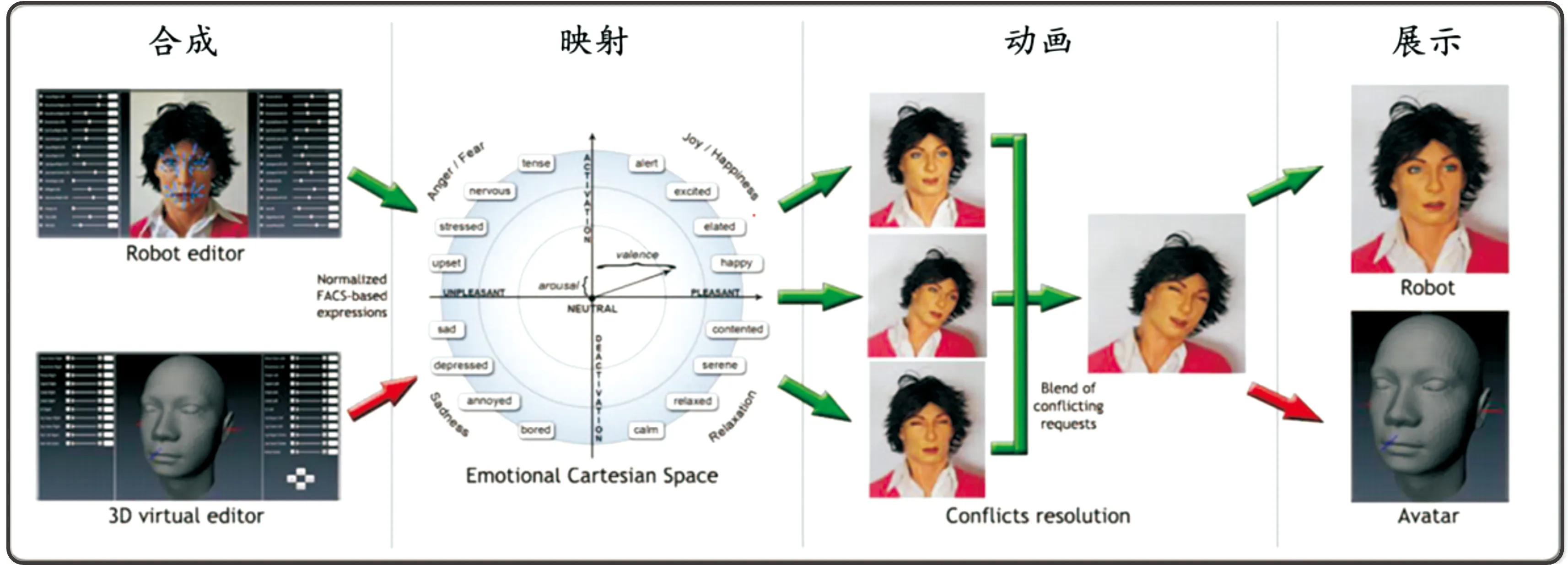
图9 HEFES结构组成
表情模仿即表情机器人通过视觉传感器获取当前用户的实时表情信息并将其再现。与动画表情模拟[48]不同,仿人表情机器人的表情模仿还需要根据解析的AU强度对机器人头部电机进行控制。随着机器人头部电机数量与自由度的增多,非线性机械模型逐渐被引入到多电机协同控制中。Magtanong等[49]基于反向传播神经网络实现了单帧表情的模拟。Ren等[50]基于能量守恒的前向机械模型和多目标优化完成在线表情迁移。针对机器人表情再现时空一致性和电机抖动的问题,黄忠等[51]基于双LSTM(long short-term memory)网络融合方法实现仿人机器人表情再现。该方法利用多层LSTM网络保障表情再现的时空一致性,并通过面部特征时序到电机控制时序端到端的映射提升了表情再现的柔顺度与自然度。
3.3 情感语音合成
目前有多种方法可以有效合成情感语音,主要包括波形拼接合成[52]、 韵律特征修改[53]、统计参数语音合成[54-55]和基于深度学习的情感语音合成[56-57]4种。在波形拼接合成方法中,需建立一个大型情感语料数据库,并以增加语料样本的方式提升情感语音合成质量,但大型数据库的获取通常较为困难。韵律特征修改方法利用韵律特征分析和参数调整手段实现情感语音的合成,但合成的情感语音自然度和情感表达度不佳。统计参数合成方法利用小型情感语料数据库进行说话人自适应训练得到情感语音模型,并通过情感模型修正实现情感语音合成。该方法综合了语音合成方法的诸多优点,但依然存在自然度低、韵律特征平淡等不足。基于深度学习的情感语音合成方法利用深度神经网络对情感语料库进行训练,进而合成高质量情感语音。这种方法进一步提升了情感语音合成的自然度与情感表达效果,成为当前研究热点。
3.4 其他情感表达方式
面部表情和语音是使机器人情感表达最直观生动的2种方式。考虑到表情合成与语音合成技术的复杂度高,一些研究者提出了其他机器人情感表达方式。为了提高互动效率并降低成本,Song等[58]利用颜色、声音和振动3种互动方式及其组合,通过简单的方式表达机器人的情感。另外,颜色和震动可以和其他情感表达方式结合以增强机器人情感表达效果。
4 结论
对仿人表情机器人的情感表达进行了综述,并将现有国内外仿人表情机器人按表情效果与情感表达划分为3个层次。重点从结构设计与情感控制两方面总结分析仿人表情机器人情感表达技术的研究现状与趋势。仿人表情机器人未来的主要研究重心应集中于以下3个方面。
1) 动态表情姿态更自然。表情行为是一个连续的动态过程,仿人表情机器人的表情合成不仅需考虑整体姿态的协调性,还需注重表情动作的动态过程研究,具体包括表情动作产生过程研究、表情维持过程研究、表情切换过程研究和表情强度变化过程研究。另外,在仿人表情机器人处于自然无表情时,也需考虑其当期面部状态的自然表现,映射出机器人当前的心理活动状态。当机器人在需要与人进行情感交互时,从无表情状态切换到其他表情就会显得更加自然。
2) 多模态情感表达能力提升。现有的仿人表情机器人虽然能通过表情和语音等方式实现情感表达,但是想要实现自然的人机情感交互仍存在一定局限性。人与人交互中情感的表现不仅在于面部表情与语音,还包括肢体动作、下意识行为等,总体来说是一种多模态的融合。仿人表情机器人采用单一模态的情感表达方式与人进行情感交互会让人们感到生硬与不自然。因此,需要进一步研究如何更好地融合情感表达相关的多模态特征,而人类行为学、社交心理学等学科将有助于这项研究。与此同时,多模态情感表达对仿人表情机器人的控制系统提出了更高要求。如何提升控制系统多单元协作的稳定性与实时性也将是未来工作的研究重点。
3) 完善恐怖谷测试研究。现有的仿人表情机器人研究者往往会忽视对所研发机器人的恐怖谷效应测试问题,导致目前没有一套相对完善的标准体系去评判仿人表情机器人是否具有广泛认可性、是否符合实际应用标准。而恐怖谷的社会性方面研究更少,导致难以评估仿人表情机器人的行为自然度表现,研究者们难以针对具体标准去改善表情机器人,大多数情况下仅凭主观判断。因此,开展恐怖谷测试研究对仿人表情机器人的研究具有重要意义。
猜你喜欢
现代装饰(2022年3期)2022-07-05
中老年保健(2021年10期)2021-11-30
皮肤病与性病(2021年3期)2021-07-30
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
少儿科学周刊·儿童版(2016年2期)2016-03-19
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
