
视觉及其融合惯性的SLAM 技术发展综述
2022-12-25 07:46曾庆化罗怡雪孙克诚李一能刘建业
南京航空航天大学学报 2022年6期
曾庆化,罗怡雪,孙克诚,李一能,刘建业
(1.南京航空航天大学导航研究中心,南京 211106;2.先进飞行器导航、控制与健康管理工业和信息化部重点实验室,南京 211106;3.卫星通信与导航江苏高校协同创新中心,南京 211106)
实时精确的导航与定位信息对于运动载体的高效工作和任务实现具有不可替代的重要作用。为了实现运动载体在未知环境中的高精度动态定位和导航,同时定位与建图(Simultaneous localiza⁃tion and mapping,SLAM)技术获得了飞速的发展。该技术实现了搭载传感器的运动载体在未知环境中运动感知并建立环境地图,同时估计自身在所建地图中位置的功能[1],最早由Randall C. Smith 和Peter Cheeseman 于1986 年提出[2],后经Leonard 等扩充[3]。随着传感器类型的扩充以及运动恢复结构(Structure from motion,SfM)技术[4]的出现,基于不同传感器和优化理论的SLAM 技术得到迅速发展[5⁃6],并在增强现实(Augmented reality,AR)/虚拟现实(Virtual reality,VR)、机器人、无人驾驶和无人机[7]等领域得到广泛应用。
SLAM 技术所依据的传感器形式多样,如激光、超声波和视觉等多种形式,目前激光SLAM 和视 觉SLAM 是 两 种 主 流 方 式[8⁃9]。激 光SLAM 主要通过激光雷达直接获得载体相对于环境的距离和方位信息[10],实现环境的建图和载体自身相对位置的确定,该技术理论和工程均比较成熟,但其存在成本较高、探测范围有限等缺陷。视觉SLAM 主要依靠视觉传感器,其价格适中,使用方便[11],因此日益受到重视。随着应用场景和任务的日益复杂化,纯视觉SLAM 也呈现了易受光照变化和运动速度干扰与影响等缺点。因此,多信息融合的视觉SLAM 技术逐渐获得重视。结合多传感器信息和多层次互补滤波,可大大提升载体的SLAM 整体性能。视觉SLAM 分类及里程碑技术发展框图如图1 所示。
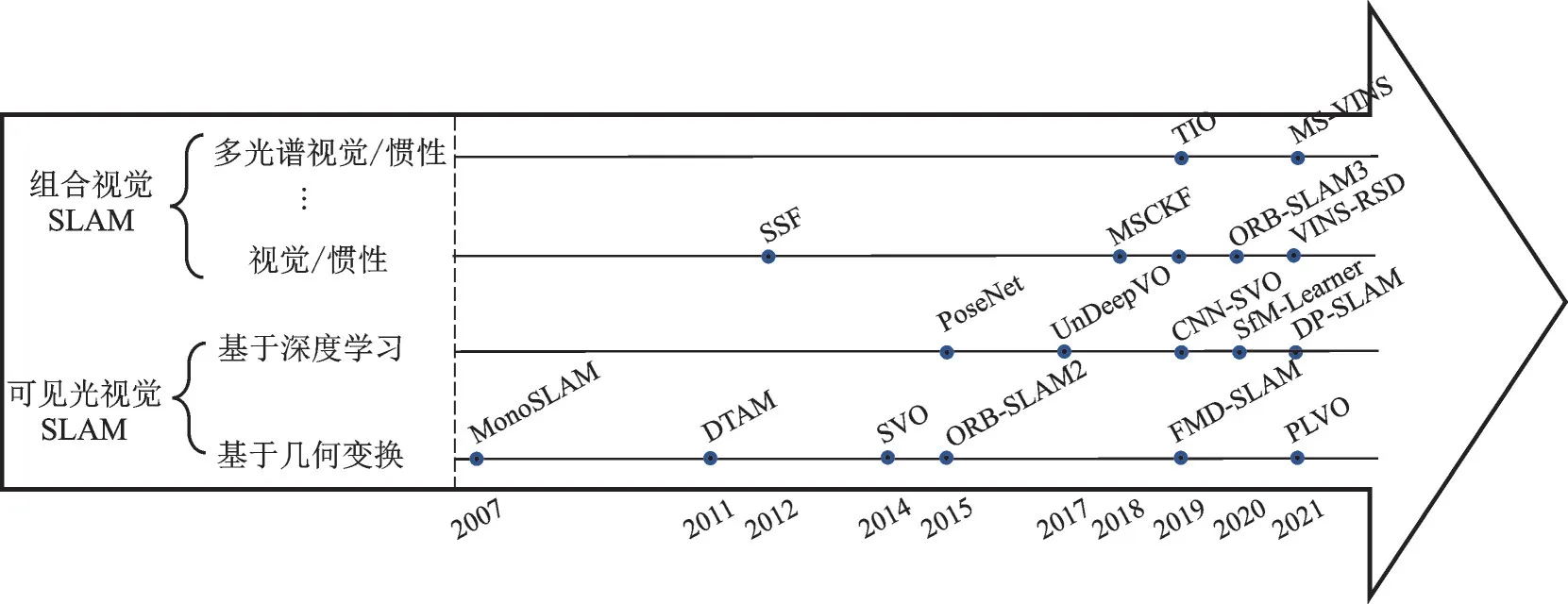
图1 视觉SLAM 分类及里程碑技术发展Fig.1 Visual SLAM classification and milestone technology development
本文集中针对视觉及视觉/惯性SLAM 技术发展进行综述研究,分别从视觉及视觉/惯性SLAM 中的关键环节、纯视觉SLAM 关键技术发展分析、视觉/惯性信息融合SLAM 关键技术发展分析等方面展开。
1 视觉及视觉/惯性SLAM 关键环节
视觉/惯性SLAM 系统框架结构如图2 所示,获取视觉及惯性传感器的数据后,通过里程计算法估计载体运动,结合回环检测结果,在后端优化框架中优化运动估计参数,同时确定自身轨迹并实现周围环境地图的构建。本文以前端里程计技术、后端优化技术、回环检测技术和地图构建技术为代表,对视觉/惯性SLAM 中的关键环节进行归纳整理。去除惯性信息后,即可得视觉SLAM 关键环节。
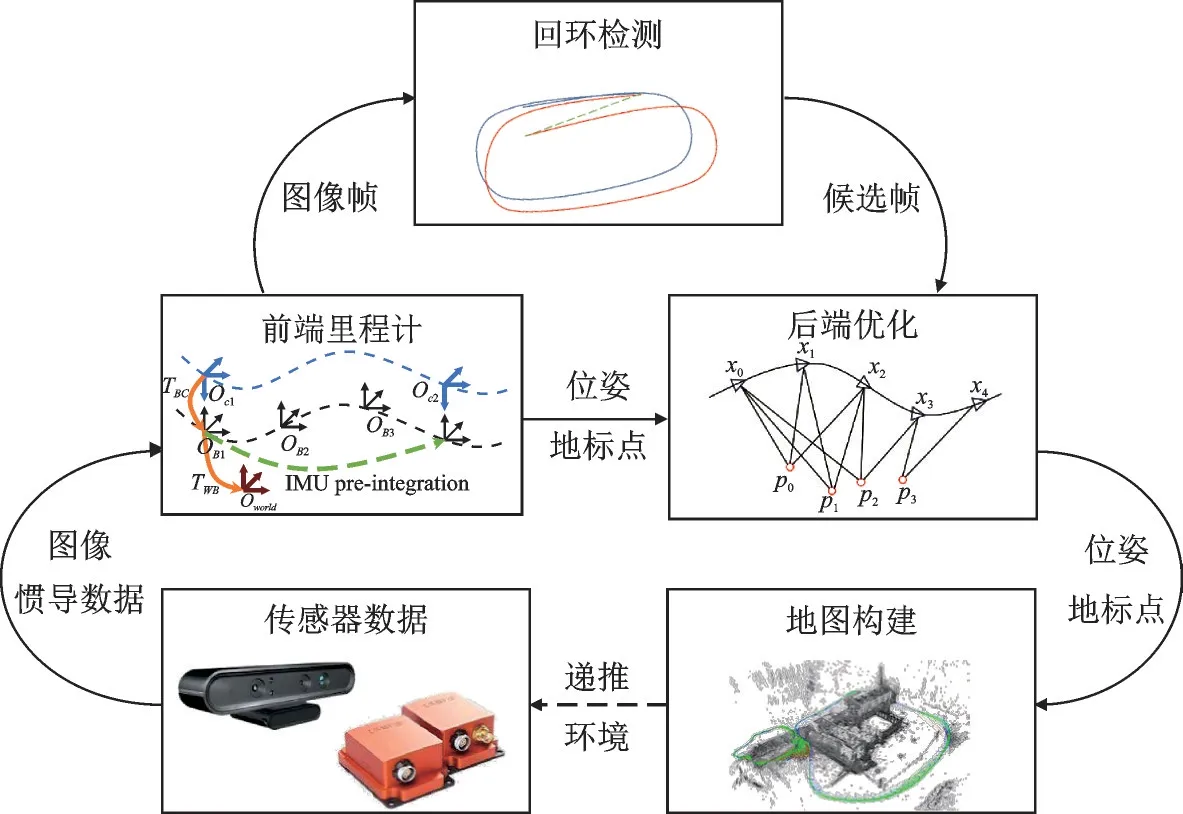
图2 视觉/惯性SLAM 系统框架结构Fig.2 Frame structure of visual/inertial SLAM system
(1)关键环节1:前端里程计技术
该关键环节在SLAM 过程中处于前端位置,狭义的视觉里程计技术仅指代依据传感器数据进行载体位姿估计的过程,对SLAM 的结果具有重要影响。在对视觉里程计运动估计时,可采用对极几何、迭代最近邻(Iterative closest point,ICP)或n 点透视(Perspective⁃n⁃point,PnP)等原理进行解算。
视觉里程计根据工作原理可分为特征点法和直接法:特征点法通过提取和跟踪解算图像特征获得载体与环境之间的相对位姿,理论较为成熟,鲁棒性较强,且对环境的纹理特征要求较高,计算量较大;直接法利用图像像素信息计算并累积相机的相对运动,具有速度快、实时性好的优点,但需要满足时间连续、灰度不变等假设模型。
特征点法和直接法均需通过图像匹配实现信息跟踪,存在图像难匹配、误匹配问题。针对特征难匹配问题,国内外学者提出结合多源传感器信息的方法,采用惯导、全球导航卫星系统(Global nav⁃igation satellite system,GNSS)、激光雷达等设备信息与视觉信息耦合,提升视觉导航鲁棒性[12⁃13];针对特征误匹配问题,大多数采用改进或挖掘特征匹配结构的方法丰富特征信息,如构建基于双向光流法的特征点环形匹配[14]、提取人造环境结构边缘线特征的运动估计[15]、结合平面与直线关联特征估计位姿[16]、结合深度学习中的语义信息剔除动态特征点[17⁃18]等算法。
通常采用惯性传感器辅助提高视觉里程计的动态适应性,视觉/惯性里程计的前端关键技术主要有惯性预积分和信息联合初始化。具有短期高动态适应能力的惯性器件信息采集频率通常高于视觉相机的图像采集频率,因此使用图像采集频率对惯性观测数据进行预积分[19],实现视觉/惯性信息的频率配准和坐标系转化效率的提升。视觉/惯性联合初始化策略目的在于提升视觉里程计的初始信息的快速性和准确性,如采用观测样本情形评估函数评估状态误差信息矩阵,循环判断是否满足初始化所需精度,从而提升初始化效率[20]。
(2)关键环节2:后端优化技术
后端优化可分为滤波器和非线性优化两类,多源信息松耦合架构常采用滤波器融合方式,紧耦合架构中两种方式均有应用,且基于图优化理论的非线性优化策略更为广泛。
滤波器优化方法通常改进卡尔曼滤波(Kal⁃man filter,KF)模型以适用于非线性系统。如采用联邦滤波将惯性测量单元(Inertial measurement unit,IMU)信息分别与里程计和视觉数据组合,避免视觉失效时组合导航系统无法定位的问题[21];采用不变卡尔曼滤波融合多层ICP 估计的相机位姿与惯性解算位姿,提升相机追踪与重定位效果[22];基于容积卡尔曼滤波(Cubature Kalman fil⁃ter,CKF)框架,融合视觉与惯性信息,避免雅可比矩阵计算过程,提升系统位姿估计精度[23]等。
非线性优化方法通常改进非线性最小二乘问题的求解过程。经典的最小二乘问题求解算法,如高斯牛顿法和列文伯格⁃马夸尔特(Levenberg⁃Marquardt,LM)算法运算时间较长,因而可采用改进dogleg算法减少耗时[24]。此外,部分研究针对于模型的精度优化,如增加模型到模型配准的约束实现大回环局部优化[25];采用卡尔曼滤波器融合全局优化后的高精度视觉估计与IMU 信息,兼顾滤波器的计算效率与优化方法的精度[26]。
(3)关键环节3:回环检测技术
SLAM 中的回环检测技术通过建立当前帧与之前某一帧的位姿约束关系消除视觉里程计所产生的累积误差,进而实现地图优化,主要依赖基于词袋模型的改进算法或结合深度学习的回环检测技术[27]。
词袋(Bag of words,BoW)模型聚类特征描述形成单词,将图像帧转换为单词集合,对比图像帧相似性判断回环,可以加快特征匹配速度,但存在环境适应性弱、难以应对视角变换等问题。因此,部分研究通过优化BoW 模型进行改进,如结合图像均衡化处理实现光照变换场景下的视觉BoW 在线增删,提升算法鲁棒性[28];计算匹配图像的共视区域协方差矩阵距离确定回环[29],实现大视角下的回环检测等[30]。
BoW 模型中构建的单词向量近似语义信息,因而可结合语义标注剔除运动物体[31],提高BoW模型鲁棒性;也可以采用神经网络代替BoW 模型获取图像帧的特征向量[32⁃33],提高算法召回率。
(4)关键环节4:地图构建技术
由于SLAM 前端理论差异,其构建地图主要分稀疏点云地图、半稠密点云地图和稠密点云地图3 类,点云稠密程度与检测特征点的密集程度相关。随着语义信息的引入,部分框架构建语义地图[34]以提供更好的视觉感知效果。
地图构建通常依据传感器获取信息及数据处理算法的差异而不同。文献[35]提出构建融合类脑感知信息的三维认知地图,其三维位置误差为总行程的1.56%;文献[36]将图像中的语义标注结果与相机估计轨迹相融合,构建增量式稠密语义地图。
SLAM 建图过程中通常需要包含载体的相对位姿信息以及周围环境景物的三维位置信息,评判算法精度的指标采用绝对轨迹误差(Absolute tra⁃jectory error,ATE)和相对位姿误差(Relative pose error,RPE)。ATE 对比数据序列时间戳中每个相近时刻下算法解算的载体位姿估计值与真实位姿之间的差值,是评估算法定位精度的主要指标。RPE 计算数据序列时间戳中每个固定时间间隔内算法估计位姿变化量与真实位姿变化量的差值,是评估系统漂移的主要指标。由于并行处理技术的应用,算法的实时性评估通常较为独立,可依据研究需要对不同环节分别评估其运行时间,也可以针对前端特征跟踪耗时的问题,评估跟踪线程单帧图像的处理时间。鉴于SLAM 算法影响因素较多,包括前端理论、环境特征点数目、光照变换、硬件配置等,当前的水平为:室内定位精度可达分米级;室外定位精度多为米级;随着动态性能的增大,其定位精度有所下降。图3 汇集了几种常用的视觉SLAM地图结果形式,其中图3(c,d,e)均属于点云地图。
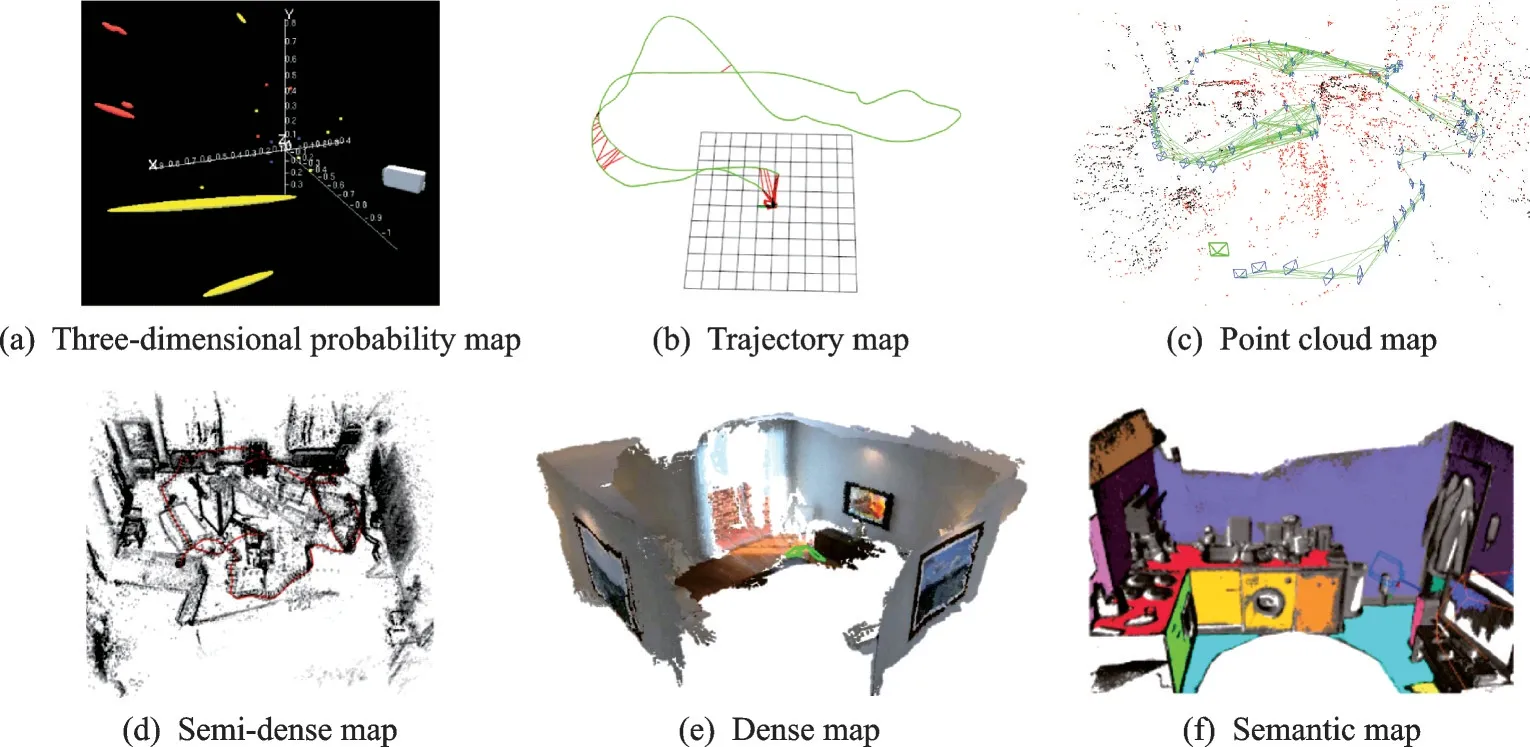
图3 视觉SLAM 构建地图类型Fig.3 Types of maps constructed by visual SLAM
2 纯视觉SLAM 关键技术发展分析
自2004 年Bergen 等提出视觉里程计(Visual odometry,VO)后[37],基于视觉图像序列估计相机运动的方法获得了科研人员的重视。将建图环节引入VO 极大促进了构建环境地图强化数据关联的视觉SLAM 技术的发展。视觉SLAM 通过多帧图像估计自身的位姿变化,再通过累积位姿变化计算载体在当前环境中的位置,其与激光SLAM 技术相比具备低成本、应用方便、信息丰富、隐蔽性强等诸多优势,发展潜力巨大。
近年发展迅速的深度学习技术在视觉SLAM中也得到了重视和应用[38],基于此可以将纯视觉SLAM 分成基于几何变换和基于深度学习这两大类。其中,基于几何变换的视觉SLAM 依据前端原理不同可分为特征点法和直接法两类,基于深度学习的视觉SLAM 依据深度学习在视觉SLAM 中的学习功能形式不同可分为模块替代SLAM 和端到端SLAM 两类。
2.1 基于几何变换的视觉SLAM 关键技术
基于几何变换的视觉SLAM 方法利用二维图像和三维点之间的几何结构映射关系求解导航参数,其主要涉及两类前端理论:特征点法和直接法。
(1)特征点法SLAM
该方法是VO 早期的主流方法,主要地图形式如 图3(a,c)所 示。第 一 个 视 觉SLAM,Mono⁃SLAM 于2007 年提出[39]。首次通过移动端相机获取三维运动轨迹,在个人电脑(Personal computer,PC)上可以30 Hz 的频率实时工作,但其单线程结构与实时性要求限制了前端特征跟踪数量。因此Klein 等[40]提出具备跟踪和建图双线程结构的并行跟 踪 与 映 射(Parallel tracking and mapping,PTAM)方法,首次通过非线性优化,即光束法平差(Bundle adjustment,BA)方式计算相机轨迹和全局一致环境地图[41]。2013 年,Labbe 等[42]提出了基 于 实 时 外 观 建 图(Real⁃time appearance⁃based mapping,RTAB⁃MAP)的方法,基于BoW 模型将图像表示为视觉词汇的集合,实现回环检测[43]。2015 年Mur⁃Artal 等[44⁃45]进 一 步 提 出 含 有 跟 踪、局部建图及回环检测多线程的ORB⁃SLAM2 算法,视觉SLAM 的多线程框架基本完善。
近几年基于特征点法的视觉SLAM 主要针对前端特征结构进行改进,如2021 年哈尔滨工业大学[46]提出点线特征融合的方式,结合线特征约束提升线特征估计准确性,降低了3D 线特征引入的冗余参数对运动估计的影响。南开大学[16]结合平面和直线之间的几何关系,提出基于平面⁃直线,即采用直线段检测算子(Line segment detector,LSD)特征 混 合 关 联 的 约 束 方 法PLVO(Plane⁃line⁃based RGB⁃D visual odometry),解决相机位姿估计时的退化问题。同时,简化跟踪特征,直接依据图像像素信息估计运动的直接法得到广泛研究。
(2)直接法SLAM
该方法构建的地图形式主要如图3(c,d,e)所示。2011 年,Newcombe 等[47]提出了首个基于单像素的直接法SLAM,稠密跟踪与建图(Dense track⁃ing and mapping,DTAM)方法,结合单个RGB 相机可在商用图像处理器(Graphics processing unit,GPU)中实时定位与跟踪。为了在一定程度上保留关键点信息,随后Forster 等[48]提出用稀疏特征点代替像素匹配的半直接法视觉里程计(Semi⁃direct visual odometry,SVO)方法,Engel 等提出构建大尺度全局一致性半稠密环境地图的大范围直接同步定位与建图(Large⁃scale direct SLAM,LSD⁃SLAM)算法[49],以及通过最小化光度误差计算相机位姿与地图点的位置,将数据关联与位姿估计统一在非线性优化中的直接稀疏里程计(Direct sparse odometry,DSO)方法[50]。
为兼顾特征点法与直接法的优势,部分学者针对半直接法SLAM 深入研究。南京邮电大学[51]提出了基于半直接法的单目视觉SLAM 算法,结合KLT(Kanade⁃Lucas⁃Tomasi)光流跟踪与ORB(Ori⁃ented fast and rotated brief)特征匹配方法,可处理复杂环境下的低纹理、运动目标和感知混叠等问题。
研究结合几何信息的直接法也获得了进一步的推进,如2019 年中国科学院大学[52]提出的融合多视图几何和直接法的同步定位与建图(Fusing MVG and direct SLAM,FMD⁃SLAM),结合多视图几何和直接法估计位姿信息,并利用最小化重投影误差优化位姿结果。表1 中梳理了基于几何变换的视觉SLAM 代表性成果。
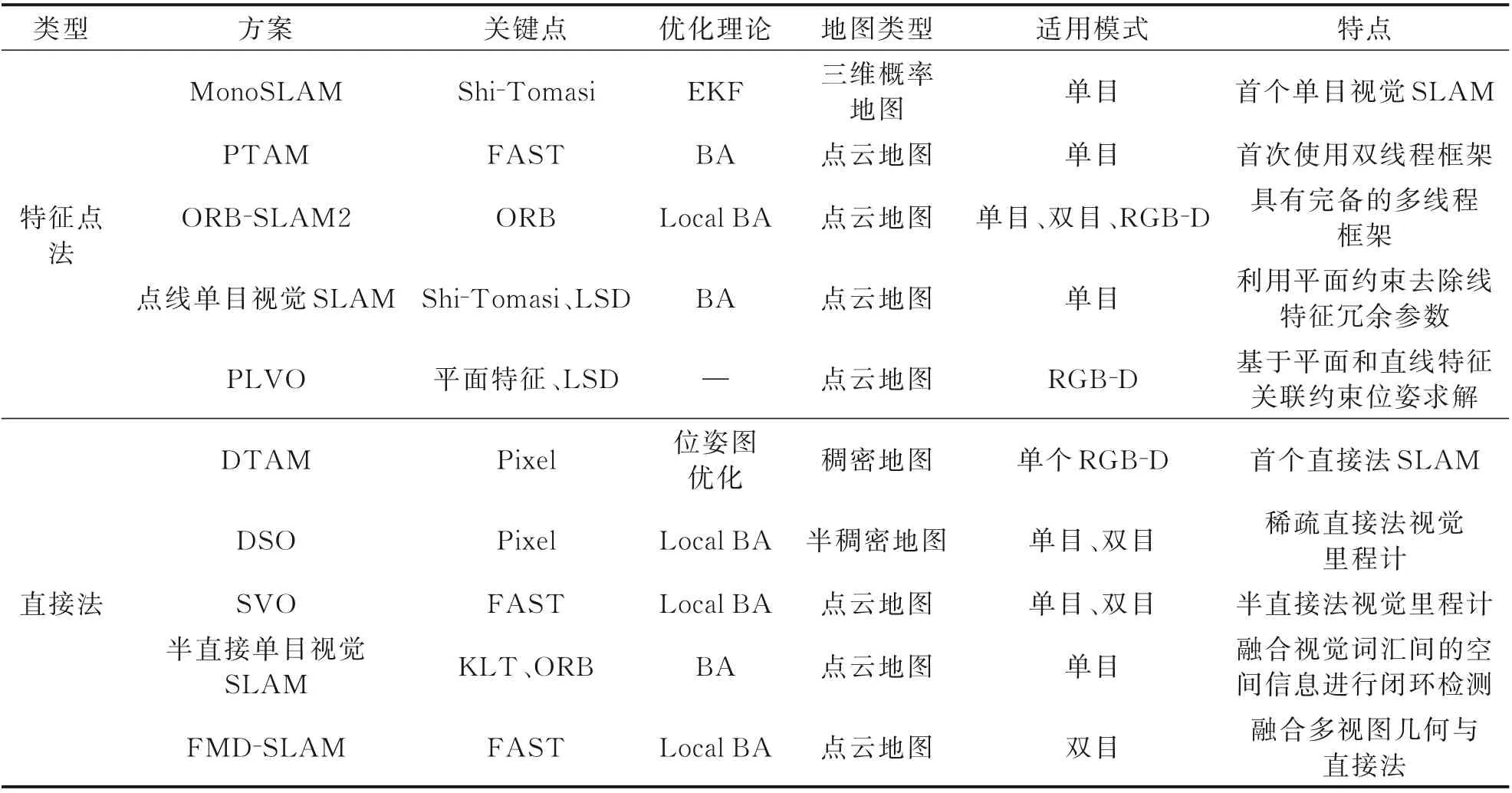
表1 基于几何变换的视觉SLAM 研究成果Table 1 Research results of visual SLAM based on geometric transformation
从以上基于几何变换的视觉SLAM 方法的演化趋势可知:特征点法主要对前端关键点进行改进优化,直接法的前端则由基于像素估计趋向结合特征点法的半稠密方式,后端优化部分由滤波器过渡到非线性优化为主,地图类型也由点云地图扩展为半稠密/稠密地图,适用模式由单目逐步扩充为双目和RGB⁃D 模式。
2.2 基于深度学习的视觉SLAM 关键技术
由于在光照变化、场景更替和物体运动时,基于几何变换的视觉SLAM 方法的性能下降[53],且具有计算量大、计算流程模式固定等问题。因此,随着深度学习技术的蓬勃发展,基于深度学习的视觉SLAM 研究也逐渐成为视觉的一个研究热点。基于深度学习的视觉SLAM 方法,主要用深度学习代替了SLAM 的部分或者全部的模块,其地图形式多如图3(c,e,f)所示。
(1)利用深度学习替代传统SLAM 模块的方法
该方法常用深度学习过程替代特征提取、特征匹配和深度估计等模块[54⁃55],而语义分割大多结合语义信息对前端里程计过程进行改进。2008 年Roberts 等[56]首次将机器学习应用于VO。2017 年佳能公司[57]提出的CNN⁃SLAM,将LSD⁃SLAM 中的深度估计和图像匹配模块都替换成基于卷积神经网络(Convolutional neural network,CNN)的方法,提升系统场景适应性。2018 年帝国理工学院[58]提出的CodeSLAM 使用U⁃Net 神经网络提取图像特征并估计图像深度的不确定性。2019 年博特拉大学[59]提出一种利用单张图片进行深度预测的方法CNN⁃SVO,可提升半直接法视觉里程计的建图效果。2020 年阿德莱德大学[60]提出基于CNN 实现深度预测和特征匹配的融合深度与光流的视觉里程计(Depth and flow for visual odometry,DF⁃VO)方法,将深度学习与对极几何和PnP 成功结合。2021 年中国科学技术大学[61]提出结合几何约束和语义分割去除动态环境中移动对象的DP⁃SLAM方法,结合移动概率传播模型进行动态关键点检测,有助于虚拟现实的应用研究。
(2)利用深度学习实现的端到端SLAM 方法
该方法利用端到端的训练方法可直接估计图像序列的帧间运动,在线计算速度快,具有较强的算法迁移能力[62],其计算速度相比替代传统SLAM 模块的方法更快。2015 年,剑桥大学[63]基于图像识别网络GoogleNet[64]开发基于单张图像信息的绝对位姿估计网络PoseNet。2017 年埃塞克斯大学[65]提出的UnDeepVO 采用无监督深度学习训练双目图像,可通过单目图像估计相机位姿并实现绝对尺度的恢复。弗莱堡大学[66]提出的De⁃MoN 利用连续无约束的图像计算深度及相机运动,还可对图像间的光流和匹配的置信度进行估计。2019 年 伦 敦 大 学 学 院[67]提 出 的Monodepth2是一种基于CNN 的自监督方法,通过在运动图像序列上训练一个建立在自监督损失函数上的架构实现深度及位姿预测。2020 年北京大学[68]提出一种单目深度、位姿估计的无监督学习网络SfM⁃Learner,可从无标签视频序列中进行深度和相机姿态估计卷积神经网络的训练。表2 整理了基于深度学习的视觉SLAM 代表方案。
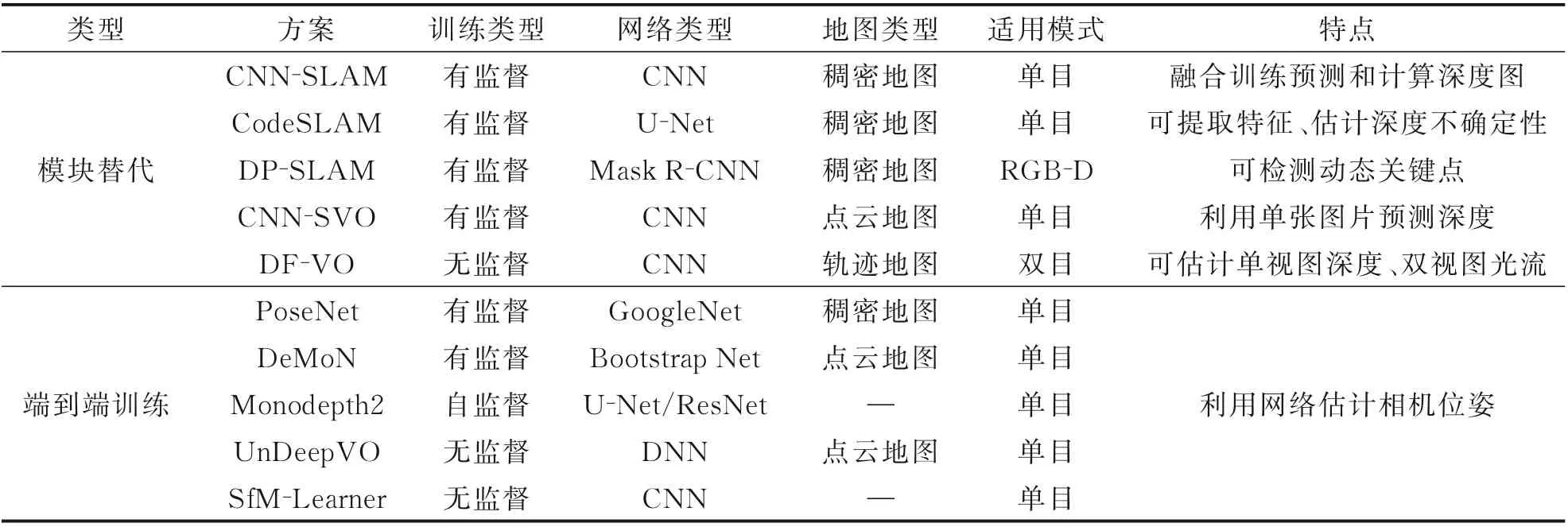
表2 基于深度学习的视觉SLAM 研究成果Table 2 Research results of visual SLAM based on deep learning
基于深度学习的视觉SLAM 方法在2015 年之后兴起,近年来研究成果越来越丰富,其训练类型以有监督为主,并逐步改进为自监督、无监督方式。采用替代传统视觉SLAM 模块的形式,构建地图类型较为多样,适用模式丰富,但仍以单目模式为主;端到端的学习则主要集中在单目视觉模式。
综上,基于几何变换的方式和结合深度学习的方式都存在其优势和不足。几何变换方法理论成熟,特征点法适用于尺度较大的运动,鲁棒性更好,但特征提取耗时;直接法速度快,适用于特征缺失场景,但灰度不变假设不易满足,不适合快速运动。基于深度学习的方法对光线复杂环境的适应性强,对动态场景识别更加有效,可结合语义信息构建地图,但同样存在训练时间长、计算资源大、可解释性差等问题。因此无论是理论成熟、具有可解释性模型的传统方法还是可移植性强的深度学习方法都亟待进一步深入研究。
3 视觉/惯性SLAM 关键技术发展分析
由于纯视觉SLAM 存在受环境光照影响大、动态适应性差等问题,基于视觉的多信息融合SLAM 技术成为新的重要研究方向,如:视觉/惯性、异源视觉/惯性等[69]组合方式。作为一种常见的自主导航方式[70⁃71],传统的可见光视觉与惯性信息融合SLAM 技术,在研究成本和隐蔽性方面均具有较大优势。针对可见光图像在弱光照条件下适应性差的问题,可结合不同成像传感器和图像处理技术获得的异源图像进一步丰富视觉导航信息。下文将在阐述传统视觉/惯性SLAM 的发展历程及经典算法的基础上,对融合异源图像的视觉、视觉/惯性SLAM 方案进行综合分析。
3.1 传统视觉/惯性SLAM 关键技术
纯视觉导航对环境特征跟踪较为精确,但在载体快速运动以及低纹理、含有光照变化等场景中应用效果不佳;纯惯性导航则不受运动场景和速度限制,但长时间运行会产生累积误差[72]。因此,融合视觉与惯性传感器优势,并可规避劣势的视觉/惯性组合SLAM 技术成为视觉SLAM 领域的主流组合方式,并依据视觉与惯性信息的耦合方式分为松耦合和紧耦合两种组合形式[73⁃74],构建地图形式主要如图3(b,c)所示。
(1)视觉/惯性松耦合SLAM
视觉图像与惯性数据的松耦合模式多应用于早期理论探索阶段,如2012 年,苏黎世联邦理工学院[75]提出的一种基于光流(Optical flow,OF)和惯性约束的惯性与单传感器融合(Single sensor fu⁃sion,SSF),其具有良好的可扩展性。但由于视觉/惯性松耦合方式通常以惯性数据为主,视觉测量信息则用于修正惯性传感器的累积误差,因而会引入视觉量测所产生的误差,因此在后续研究中多采用紧耦合方式。
(2)视觉/惯性紧耦合SLAM
相较于松耦合方式,紧耦合SLAM 可以更紧密地联系视觉特征与惯性传感器的量测数据,提升视觉/惯性组合SLAM 系统的精度,因而形成诸多以图优化理论为主的视觉/惯性紧耦合SLAM成果。
2015 年Bloesch 等[76]提出一种单目视觉/惯性里程计鲁棒视觉/惯性里程计(Robust visual iner⁃tial odometry,ROVIO),直接利用图像块像素强度误差实现精确跟踪,使用EKF 实现优化。Leute⁃negger 等[77]提出基于滑动窗口的非线性优化紧耦合双目视觉/惯性里程计OKVIS。2018 年宾夕法尼亚大学[78]提出一种基于多状态约束卡尔曼滤波(Multi⁃state constraint kalman Filter,MSCKF)的双目视觉/惯性里程计MSCKF⁃VIO。弗莱堡大学[79]提出将基于ORB⁃SLAM2 的视觉姿态解算与惯性、GPS 测量值相结合的姿态测量算法,并在无人机救援任务中得到应用。2019 年香港科技大学[80⁃81]提 出 基 于 优 化 的 多 传 感 器 状 态 估 计 器VINS⁃Fusion,支持多种视觉/惯性传感器类型,可实现自主精确定位[82]。上海交通大学[83]提出一种在人造环境中利用结构规律的视觉惯性里程计StructVIO,基于结构化线特征完成VIO 设计。慕尼黑工业大学[84]提出了一种利用非线性因子恢复法提取相关信息,进行视觉/惯性建图的里程计Basalt。2020 年萨拉戈萨大学[85]提出适用于单目、双目、RGB⁃D 相机的视觉、视觉/惯性多种模式的ORB⁃SLAM3,在部分测试场景中定位精度可达分米甚至厘米级,实现了传统视觉SLAM 算法在定位精度上的突破。2021 年,武汉大学[86]提出一种适用于卷帘快门RGB⁃D 相机的视觉/惯性SLAM方法VINS⁃RSD,利用深度相机直接获得深度,解决了初始化特定运动状态的需求。表3 整理了视觉/惯性组合SLAM 的代表性方案。
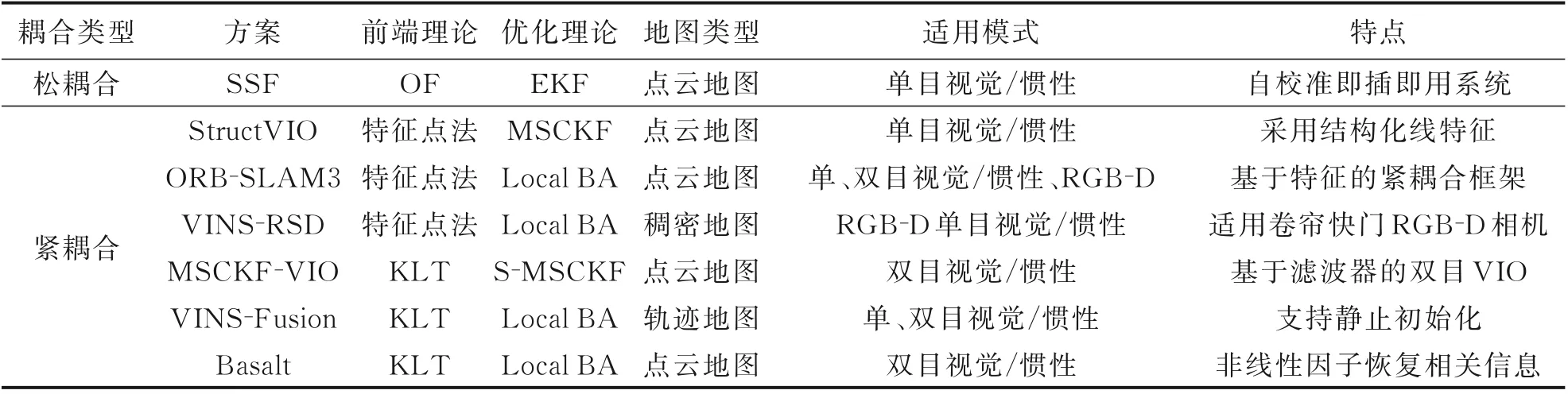
表3 视觉/惯性SLAM 研究成果Table 3 Visual/inertial SLAM research results
目前具有代表性的传统视觉/惯性SLAM 方案多采用紧耦合方式实现多信息融合,前端常采用特征点法和KLT 光流法,优化理论以非线性优化方式为主。构建地图的类型较为丰富,主要为点云地图和轨迹地图。由于视觉/惯性组合的方式有效解决了单目视觉无法恢复尺度的问题,因此单目及双目视觉/惯性组合模式均得到了广泛研究。
在近几年的多信息融合导航领域,出于全天候全时段导航任务的需求,研究人员深入挖掘了视觉图像信息,通过融合不同模态的视觉图像信息提升视觉解算性能,基于异源图像的视觉导航技术得到发展。
3.2 融合异源图像的视觉及视觉/惯性SLAM 关键技术
传统可见光视觉导航方式存在光谱范围受限、低光照环境不可用等问题,异源图像则既保留了视觉导航自主抗干扰的优势,又对单色图像信息进行有效补充,在地形勘探、目标提取和精确导航方面具有实用前景,融合异源图像的视觉导航技术也在低光照环境及复杂地形场景中得到应用。早期异源图像多作为信息辅助测量手段应用于导航领域,用于提高视觉感知[87⁃88]、实现双目测距[89]等功能。近年来则涌现了更多融合异源图像信息的视觉导航方案,基于其融合的传感器数据分为异源视觉SLAM 和异源视觉/惯性SLAM 方案,地图形式主要为图3(b)的轨迹地图。
(1)异源视觉SLAM
2018 年新加坡国立大学[90]提出了一种多平面红外视觉里程计,采用激光设备辅助消除尺度恢复中的测量误差,提升了无人机在多平面复杂地形中昼夜飞行的鲁棒性。2021 年大连理工大学[91]提出一种偏振光/双目视觉仿生组合导航方法,利用仿生偏振定向传感器输出的角度信息修正航向角。克兰菲尔德大学[92]提出多模态纯视觉里程计GMS⁃VO,分别对姿态和尺度进行估计,提升了系统整体定位精度。
(2)异源视觉/惯性SLAM
2017 年克兰菲尔德大学[93]提出了一种融合惯性和多光谱信息的导航系统,适用于载体快速运动及寒冷环境场景。2018 年新加坡国立大学[94]提出了适用于无人机昼夜飞行的红外视觉惯性里程计算法,采用扩展卡尔曼滤波(Extended Kalman filter,EKF)框架实现视觉及惯性测量信息融合,消除尺度恢复和运动估计误差。2019 年加州理工学院[95]提出了一种热像惯性里程计,分别将惯性数据与夜间的热图像或白天的视觉图像紧耦合以适应不同光照条件,并集成在运动规划和控制的自主框架中实时运行。2021 年克兰菲尔德大学[92]提出视觉/惯性里程计MS⁃VINS,采用误差状态卡尔曼滤波器融合视觉姿态与惯性数据。表4 整理了融合异源图像的视觉SLAM 代表性方案。

表4 融合异源图像的视觉及视觉/惯性SLAM 研究成果Table 4 Visual and visual/inertial SLAM research results fused with heterogeneous images
异源图像逐渐由辅助导航手段转为视觉导航的主要信息来源,视觉图像也由红外热像图转变为可见光/红外组合图像,并扩展为视觉/惯性组合导航模式,利用多信息融合优势提升SLAM 系统精度。虽然在异源传感器数据处理、硬件配置等方面仍需进一步探索,但随着异源图像信息的引入,视觉SLAM 的环境适应性逐渐增强,呈现出在全天时复杂环境应用的发展倾向。
综上,视觉及视觉/惯性SLAM 在不同领域得到了不同程度的应用。
基于几何变换的视觉及视觉/惯性SLAM 整体研究已较为成熟,现已在多个领域得到实际应用,如iRobot、Dyson、科沃斯、小米等公司推出的具备自主导航功能的扫地机器人,应用视觉SLAM 技术实现室内定位感知及建图任务;Skydio公司推出的自主飞行无人机,具备厘米级定位精度,可用于高压线塔、桥墩、盖梁等场景检测;特斯拉公司研发的无人车辆智能驾驶,可实现L2 级别的部分自动化车辆自动驾驶;Nreal 公司推出的增强现实眼镜,结合SLAM 技术联通虚拟环境与现实世界,提升用户感知体验。
基于神经网络或融合异源视觉的定位导航技术虽然为视觉SLAM 带来了新的变革,但主要处于理论研究与实验验证阶段,凭借神经网络良好的学习能力及异源视觉的环境适应性,多应用于移动机器人巡检、无人机矿井探测、无人驾驶目标识别及导航等自主任务。
4 结 论
本文以视觉及视觉/惯性SLAM 技术为主,归纳整理了前端里程计、后端优化、回环检测和地图构建关键环节,系统综述了纯视觉SLAM 的关键技术发展情况,并对视觉/惯性SLAM 导航方案进行梳理分析,结合异源图像的研究应用情况,探讨了融合异源图像的视觉导航技术研究进展情况,为融合异源图像的视觉及视觉/惯性SLAM 研究提供参考。结合现有研究成果,视觉及视觉/惯性SLAM 技术主要呈现以下3 点发展趋势。
(1)理论优化改进:由于应用场景需求的多样化,结合惯性、异源图像等多传感器的信息融合模式成为SLAM 主流,促进了以紧耦合为主的信息融合理论发展,而随着大场景SLAM 应用需求及图优化理论的推进,逐步形成了基于扩展卡尔曼滤波框架的改进滤波器优化架构,和以光束法平差为主的非线性优化架构两种研究趋势。
(2)新型技术引入:随着深度学习技术在计算机视觉中的广泛应用,视觉SLAM 呈现出由传统几何变换方式逐步转向结合深度学习的智能融合趋势。一方面视觉图像与语义信息的紧密联系,使得集成语义信息的视觉SLAM 得到更多探索;另一方面为减少对传统方式依赖,利用神经网络架构替代SLAM 的部分模块或端到端强化学习的模式得以广泛研究。
(3)应用领域推广:视觉SLAM 目前在智能家居、自动驾驶、无人机等领域得到了不同层次的应用,随着硬件性能的提升,视觉SLAM 的应用范围逐步由室内小空间转向动态目标丰富的复杂大空间场景,应用的广度和深度得到较大提升。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2022年6期)2022-07-02
现代信息科技(2020年22期)2020-06-24
山东工业技术(2019年16期)2019-07-19
电子技术与软件工程(2019年6期)2019-04-26
软件导刊(2019年12期)2019-02-07
科技与创新(2018年12期)2018-06-22
火力与指挥控制(2018年1期)2018-03-02
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
