
教育考试数字化:模式、特点与启示
2022-12-23 12:50杨志明夏胜俊
教育测量与评价 2022年6期
杨志明 夏胜俊 李 希
随着信息技术的迅猛发展,许多行业都在努力提升各自的数字化水平,以便在节省成本的同时,大幅度提升工作质量和效率,乃至重塑组织结构与工作流程,创新业务模式等。教育考试行业也不例外,人们一直在不断提升考试的数字化水平,并取得了比较好的成绩。从2022 年开始,“教育部决定全面实施教育数字化战略行动,……已经建立起一整套由课程、教材、实验、教研、图书文献、教学资源库、教学质量监测、国际合作、管理决策等十大版块,涵盖了理念、技术、标准、方法、评价等在内的中国特色高等教育数字化新体系……”[1],“教育的全面数字化转型已成必然趋势”[2]。特别是党的二十大以后,国家对数字社会发展提出了新的规划,数字社会加速建设、新一代信息技术快速普及已是大势所趋,与之相适应,教育考试的形式、形态和模式都将发生剧烈变化。
不过,大众对教育考试数字化的认识并不十分准确,给考试服务机构、相关管理部门带来了一些误导,造成了不必要的浪费,给学生的学习和教师的教学也带来了负面影响。比如,不少人以为教育考试数字化就是花钱招聘一些IT 人员,把常规作业、单元测试、期中考试、模拟训练及大型考试等的题目和试卷做成电子版本并实施考试的活动;也有人认为教育考试数字化就是在计算机或某个云服务器上建立海量题库,教师可以随时从题库中随机选题组卷,学生可以随时在计算机上答题,计算机会自动评分并报告结果;等等。显然,这些不准确的观念或做法不利于教育考试的数字化建设。因此,很有必要系统梳理教育考试数字化的常用模式,了解这些模式的优点和缺点,以便不断提升教育考试的数字化水平,更好地为人才选拔和教育教学服务。
一、教育考试数字化概述
教育考试数字化泛指一切以数字化方式储存、呈现信息并付诸实施的教育考试活动。自20世纪90 年代开始,计算机和互联网行业发展势头十分强劲,教育考试很快成为计算机应用的一个重要领域,先后出现了计算机化考试(computerbased testing,CBT)、在线考试(internet-based testing,IBT;或online testing)、计算机化自适应考试(computerized adaptive testing,CAT)、计算机化自适应多阶段考试(computerized adaptive multistage testing, ca-MST),以及计算机化自适应认知诊断考试(cognitive diagnostic computerized adaptive testing,cd-CAT)等教育考试数字化模式。不过,这些模式在发展过程中经历了许多风风雨雨,既有成功的经验,又有深刻的教训。一些在理论上非常美好的方案却在实践中遭受重大挫折。比如,Pearson 公司给美国怀俄明州2009—2010 年度全州统考提供的计算机化自适应考试项目PAWS,就曾经因为考试实施的不顺当等,被用家诉求赔款950 万美元,经过法庭判决赔付了510 万美元。[3]
事实上,在国外,关于教育考试数字化的理论研究很早就有,而实践效果良好的考试项目却不是很多。我国的数字化考试项目起步更晚。这不仅与计算机和互联网技术的发展水平有关,而且与教育考试的理论研究和应用水平有关,更与高校的教育考试与评价学科的建设水平密切相关。高水平教育考试专业人才的数量和质量直接关系到教育考试的数字化建设水平。比如,美国教育考试服务中心(Educational Testing Service,ETS)的洛德(Lord)和丹麦数学家饶阿喜(Rasch)等学者,早在20 世纪60 年代就发表过一些划时代的研究成果,对经典测验理论(classical testing theory,CTT)和题目反应理论(item response theory,IRT)等的发展做出了重要贡献。[4]美国的许多著名高校,如芝加哥大学、哥伦比亚大学、加州大学伯克利分校、加州大学洛杉矶分校、马里兰大学、爱荷华大学、密歇根大学安娜堡分校、明尼苏达大学、北卡罗来纳大学教堂山分校、伊利诺伊大学厄巴纳-香槟校区、得克萨斯大学奥斯汀分校、麻省大学阿默斯特分校等,都建设有一流水准的教育考试与评价学科,为教育考试的数字化建设提供了大量高素质人才。美国教育研究协会(AERA)、美国心理学会(APA)和全美教育测量协会(NCME)还联合颁布了全国教育与心理测验学术标准。[5]
此外,美国政府(尤其是其军方)和许多非营利性企业,也都对教育考试的数字化建设投入了大量资金和人力物力,极大地促进了教育考试的数字化发展。比如,军人职业潜能成套测验(armed services vocational aptitude battery,ASVAB)就是20 世纪90 年代美国军方推出的一款CAT 产品[6];ETS 在1998 年推出了托福英语考试的CBT 模式(TOEFL-CBT)[7],2005 年把CBT 改成了IBT 模式(TOEFL iBT)[8],2011 年又把研究生入学考试(GRE revised general test)升级成了ca-MST 模式[9]。美国大学考试中心(ACT Program)、美国西北教育评价公司(NWEA)和管理类研究生入学考试(GMAT)等,也一直在大力推行CAT 项目。[10-12]我国近年来也开展了关于CAT,ca-MST 以及cd-CAT 的研究[13-16],推出了少量的CAT 和ca-MST 项目,但相应的高层次测量学人才还十分缺乏,现代考试理论与技术的应用水平也亟待提升。显然,系统梳理这些模式的概念、优点和缺陷,对于提升我国教育考试的数字化水平很有意义。由于cd-CAT 模式大多处于理论研究和小范围实验阶段,本文主要讨论CBT,IBT,CAT 和ca-MST 这4 种应用较广的教育考试数字化模式。
二、CBT模式及其特点
CBT 模式的基本特征是把纸笔测验变成了电子版本的测验,并增加了考生信息管理、题目编写与修改、试卷编辑与制卷、计算机作答、计算机阅卷评分、简单的数据分析、结果报告和信息保存等功能。
CBT 的主要优点包括:(1)可以节省大量纸张等资源;(2)可以灵活、高效地在多个地点和多个时间点实施考试;(3)可以利用多媒体等手段开发新题型和新情境,能完成纸笔考试无法做到的测试任务,如人机对话、软件操作、英语听力考试和口语考试等;(4)互动式考试有助于激发学生的学习热情,提升他们的学习投入水平;(5)方便记录学生问题解决的过程信息,帮助教师精准判断学生的学习困难;(6)可以设置更少或更多、更易或更难试题,考查学生的高阶思维水平;(7)方便阅卷评分和及时获得结果报告;(8)可以满足有残疾考生的一些个性化需求;(9)方便及时了解学生的学习进展以调整教学的方式方法;(10)方便开展追踪研究,强化过程评价,实施增值评价;(11)方便根据测验常模实施横向和纵向的教育评价;(12)可以通过IT技术提高考试的安全性等。
CBT 的缺点主要有5 项。(1)不少CBT 项目的教育测量理论与应用水平不高。许多CBT 项目在题目编制、试卷编辑、考试实施、误差控制、标准设定、测验等值和结果报告等方面比较粗糙。仅有少量的CBT 项目应用了CTT 理论,采用了标准化考试手段。极少数CBT 项目应用了IRT 理论,尝试了基于IRT 的测验等值方法等。(2)不少CBT 项目与教育科学的联结不够紧密。事实上,一些以IT 团队为主开发的CBT 项目,在知识、能力和素养的界定方面非常薄弱,在利用考试结果为教育服务方面出现了一些违反教育科学的做法,混淆了选拔性考试与达标性考试的关系,给学生的成长造成了一些负面影响。例如,国内某著名科技公司为学生提供了数字化错题本服务,但缺少提炼概括(某高中生仅物理一门课程一个学年的错题本就有200 多页),这明显违背了教育规律。部分不够敬业的教师甚至依靠科技公司提供的考试来主导自己的教学工作,根本没有因材施教的意识和措施。(3)不少CBT 项目所依据的题库质量不高。不少考试机构在推介其CBT 项目时,往往以拥有成千上万道题目、可以随机或随意生成试卷为荣耀。殊不知这恰恰是其教育理论缺失和教育测量技术水平不高的表现。那些没有经过严格测验等值处理的、缺乏教育科学理论支撑的试题,实际上对教师和学生都没有好处,浪费了教师和学生的时间和精力。(4)不少CBT 项目缺乏测量学分析报告。根据教育考试学理论,任何考试项目都需要公开其考试公平性、稳定性(测量信度)和有效性(测量效度)等方面的技术报告,以保障考试本身的科学性和公平性。一些缺乏等值处理和考试常模的CBT 项目,其考试结果的解读存在许多缺陷。(5)在落后地区实施CBT 往往会因为机位不足而不得不把一次考试拆分成多次考试,而多次考试又面临着泄密、不同测验版本之间的等值等问题。一些专业化程度不高的考试机构开发的CBT 项目出现的问题更多。
三、IBT模式及其特点
IBT 模式是在CBT 模式基础上运用互联网实施测试的一种考试模式。IBT 的内容和形式与CBT 大体类似,但常见的IBT 项目既使用经典测验理论,又运用题目反应理论。不过,IBT 的实施和结果发放等严重依赖互联网的硬件质量和软件水平,依赖网络的物理通道和网络流速等。
IBT 的主要优点是省时、省力、省钱以及使用起来方便、灵活。具体包括:(1)IBT 能够为考试机构节省大量的人工和时间成本,可以快捷开展考试、快速阅卷评分、及时报告和分发考试结果等;(2)教师可以快速获得考生的作答反应结果,了解学生的长处和短处,并给予及时有效的结果评价和过程评价;(3)学生可以非常方便地作答考试,特别是在低利害考试中,学生既可在学校的网络终端参加考试,又可在家或其他方便的场所使用自己的电子设备参加考试;(4)学生既可以把IBT 作为学习的结果,又可以把它作为学习的手段,还可以把它作为学习的目标。
IBT 的缺点主要有4 项。(1)IBT 特别容易受到网络流畅性的影响。在网速不够快的情况下,IBT 很容易出现计算机对考生的作答没有反应或反应延时等问题。(2)高利害的IBT 很容易出现安全性问题。实际上,大多数高利害的IBT 只能在标准化考场实施,否则,很容易出现考试舞弊等问题。(3)IBT 容易出现考试不公平的问题。IBT往往要求考生的计算机和网络运用水平达到一定程度,一些计算机和网络使用水平不够高的学生(如来自偏远乡村的学生等),其考试成绩很可能会因为自身计算机水平不高等被大大低估,造成严重的考试不公平问题。(4)一些基于先进理念的实时操作方式可能无法实现。比如,基于IRT的在线标定(online calibration)工作是一种很好的考试理念,但考试机构在大规模的远程考试中使用这种在线标定的能力参数估计方式时,几乎都遭遇过重大挫折,有些项目不得不被放弃。因为在线标定对网速的要求特别高,一旦发生网络拥堵,考生的作答界面就会静止不动,甚至出现考试中断等问题,造成无法挽回的重大损失如高额赔偿,甚至引发社会的高度关注等。
四、CAT模式及其特点
CAT 指的是根据考生在考试过程中的前期作答水平,计算机考试系统依据IRT 算法,自动调整其随后所要求作答的题目,使得题目的难度与考生水平逐渐接近的一种个性化考试方式。换句话说,CAT 是能够根据考生在考试前期的作答表现,通过IRT 算法给不同考生推送不同难度试题的考试模式。试题推送的原则是:若考生答对了当前试题,CAT 会给考生推送一道比当前试题更难的试题;若考生答错了当前试题,CAT 会给考生推送一道比当前试题更容易的试题。这个规则反复使用,直到考生作答反应的信息量达到事先设定的某个标准(如考试信度足够高、测量误差足够小、题目数量足够多等),CAT 才会自动终止,报告考试结果。[10-12]CAT 的工作流程如图1所示。

图1 CAT的工作流程
CAT 的理论基础是IRT,其主要优点是考试的个性化和等值化。也就是说,不同考生所要求作答的题目可以在难度和区分度、数量、作答时长等方面不同,但其导出分数(derived score)可以通过测验等值(test equating)技术,被表达在一个共同度量系统(scale,量表)之上。使用CAT 的一个前提条件是必须预先建设好一个优质题库。该题库不仅试题数量要足够多,而且所有题目的IRT 参数都要事先估计好,并通过等值手段被表达在一个共同的度量系统之上;同时,题目的内容要足够覆盖计划测量的知识和能力领域,题库中的题目需要不断更新等。此外,较为复杂的计算机系统建设以及网络运行的质量要求等,也是实施CAT 的先决条件。
CAT 的主要优点包括以下6 项。(1)实现了考试的个性化。不同考生作答的题目不同,作答的时长也不同,而考试分数被表达在一个共同度量系统之上。(2)节省了考试时间,提高了考试的效率。传统的纸笔考试,以及CBT 和IBT 模式一般要求所有考生在相同的时间内作答相同的试题。这样的标准化考试模式往往造成两种浪费:一是所有高水平考生需要浪费大量时间去作答大量容易的题目,而真正能鉴定其水平的题目数量却不多;二是所有低水平考生需要浪费大量时间去作答大量中等和中等以上难度的题目,而真正能鉴定其能力水平的题目数量却不多。(3)提高了考试的区分能力。传统的纸笔考试,以及CBT和IBT 只能提供一个统一的测量误差指标(测量信度的反映),可事实上同一套试卷对不同能力水平考生的能力估计精确度很不相同。基于IRT的CAT 可以通过提供条件测量误差(conditional standard error of measurement,CSEM)的方法解决这个问题。(4)提高了考试的安全等级。由于不同考生作答不同的试题,CAT 从技术层面就大大降低了考试舞弊的机会。(5)可以有效控制考试的天花板效应(ceiling effect)和地板效应(floor effect)。CAT 可以提供很难的题目和很容易的题目,所以,能力水平很高的考生仍然有机会挑战极难的题目,而能力水平很低的考生也有机会答对很容易的题目,避免了标准化考试中常常出现的,因为难题数量不够造成有人得满分而无法估算其真实水平超过“天花板”以上多高,以及容易题数量不够导致有人得0 分而无法估算其真实水平低于“地板”以下多深等问题。(6)为自适应学习提供了技术支持,有助于强化过程评价,提高教与学的效果。
CAT 的缺点主要有7 项。(1)大多数考试题库达不到实施CAT 的要求。这不仅表现在题目编写不容易等方面,而且表现在新题目在无法试测的情况下无法精准估计题目参数、实现题目参数等值等方面。(2)CAT 所依据的题目反应理论比较深奥,非专业人士不太容易明白其中的算法原理,因此在考试项目的推广应用方面存在较大困难。(3)早期CAT 所依据的考试信息量最大化的选题策略很容易高估或低估考生水平,还容易造成高区分度题目被过度使用,而大量区分度不高但仍然合格的题目很少被使用等方面的浪费。(4)根据测验信息量最大化原则来设定CAT 的选题规则和终止规则,可能导致考生能力水平主要取决于他们在最初3~4 题的作答表现,以及题库中所有优秀试题被很快过度曝光等困局的出现。(5)在线标定的理想往往因为网速不够快等而无法实现,这为试测新题带来了一定的麻烦。(6)依赖于高水平IT专业团队的强力支持。没有高超的软件开发水平,不理解IRT 的算法,CAT就无法实现。(7)考生在作答过程中不允许检查或修改前期作答过的试题的答案。
五、ca-MST模式及其特点
ca-MST 是CAT 的妥协版本。[13-15]CAT 的运行规则建立在单个试题层面,而ca-MST 的运行规则建立在题目组层面,在其他方面ca-MST 与CAT 差别不大。图2 呈现了一个三阶段ca-MST的测试模式。
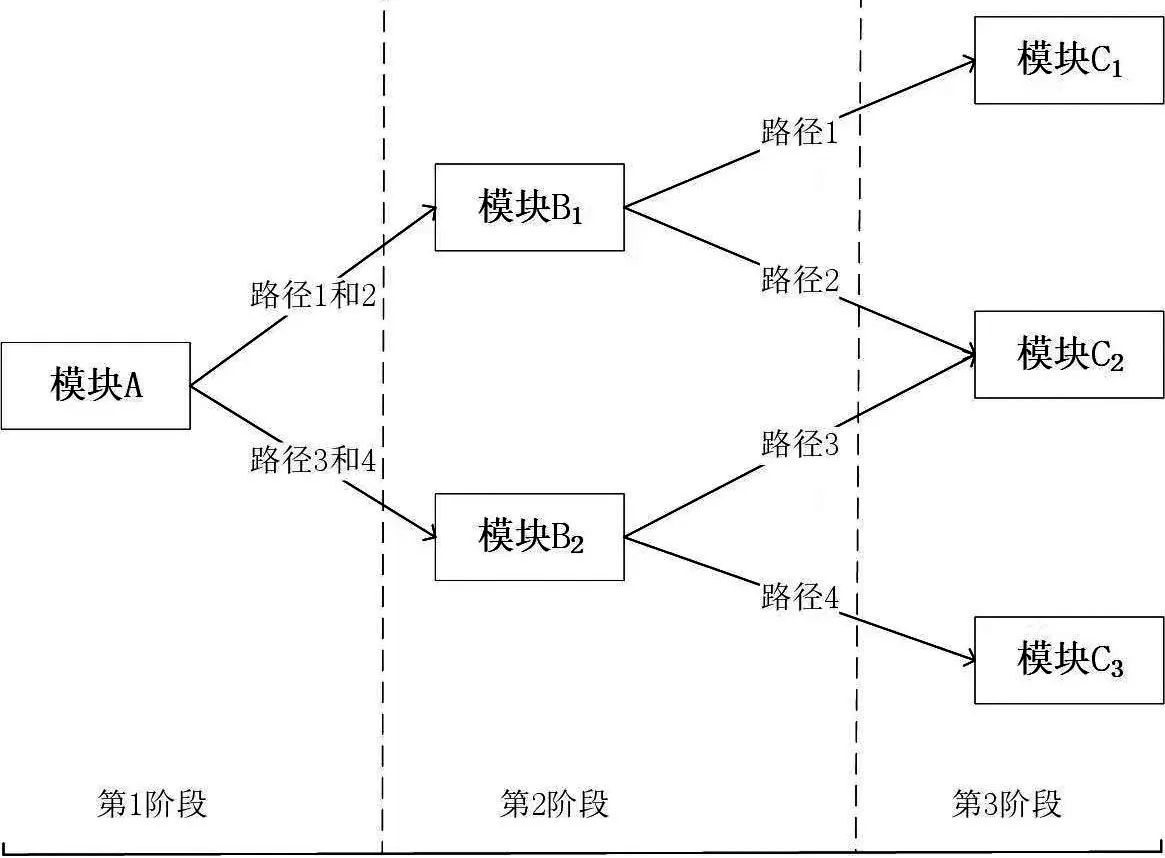
图2 三阶段ca-MST测试模式示意图[13-14]
其中,模块A 为第一阶段题组,扮演着“路径甄别”(router)的角色,试测新题一般隐藏在这个模块中。 模块B1和模块B2属于第二阶段的题组,分别代表“较难”和“较易”模块,二者之间的难度范围和题目可以部分重叠。模块C1、模块C2和模块C3属于第三阶段题组,分别代表“较难”“中等”和“较易”模块,相邻模块之间的难度范围和题目可以有部分重叠。
每个模块一般包含20 道试题,第一阶段“路径甄别”模块的题目难度范围一般要求能有效覆盖考生群体的能力范围,其他阶段模块的题目难度范围一般要与相应考生能力范围一致,每个模块中题目所覆盖的知识和能力内容必须与考试蓝图完全一致。实施ca-MST 的基本逻辑是:若考生在第一阶段的原始得分超过某个临界值(比如预测时受测总体的某个代表性样本的平均分),则ca-MST 会自动给考生推送“较难”题组模块B1;否则,ca-MST 会自动给考生推送“较易”题组模块B2。依此类推,在第三阶段,ca-MST会根据考生第二阶段的作答表现,推送“较易”和“中等”题组中的一个(第二阶段作答的是“较易”模块),或者推送“中等”和“较难”题组中的一个(第二阶段作答的是“较难”模块)。事实上,在图2 所示的ca-MST 设计中,每个考生可能的作答路径(path)总共有4 种,每条路径(题目组合)类似于传统意义上的“一份试卷”,其内部构成必须符合考试蓝图的要求,测评精确度必须达到事先设定的信息量或测量信度或测评误差等标准。
ca-MST 的优点主要包括以下5 点。(1)具有一定的自适应功能,能够满足一定程度的个性化需求。事实上,ca-MST 仍然具有CAT 的大部分优点,只不过对CAT 做了一些限制,是CAT与传统的标准化考试间的一种折中。(2)考试安全性比较高。根据GRE 的实践经验,完全使用CAT 容易受到考试辅导机构的冲击,这些机构能够通过派选考生记忆试题等方式获取大量高质量的真题,损害了考试的科学性和公平性。改进后的ca-MST 综合了IRT 算法与人为管控的优势,有效防止了泄题。(3)ca-MST 较好地解决了新题试测这一难题,其中的细节需要另外专门讨论。(4)有助于实现自适应学习,提高教与学的效率。(5)部分克服了CAT 不允许返回修改答案的缺点,即ca-MST 允许在同一个阶段内部返回修改前期答案。
ca-MST 的缺点主要有4 项。(1)支持ca-MST的题库数量要大、内容要全,所有题目不仅要有参数估计值,而且必须事先实现题目参数等值,否则无法设计不同的测试路径。(2)每个考试周期需要事先准备好几百种作答路径组合(类似固定测试中的试卷),并针对每种作答路径组合,事先完成测验等值工作,为每一种组合设定原始分数与量表分数之间的转换关系。比如,某著名考试每半个月就需要事先准备好200 多种作答路径组合,并利用IRT 等值技术为每个组合事先确定原始分与量表分的转换关系。这项工作要求同时控制很多变量(因素),不得出现任何差错,否则前功尽弃。(3)每种作答路径组合背后的原始分数与量表分数之间转换关系的确定,需要极为高超的测量分析水平。这项工作一般涉及标准设定、常模研发和测验等值3 种核心技术,非考试专业人士一般无法完成。(4)依赖于高水平IT 专业团队的强力支持。没有高超的软件开发水平,不懂得IRT的算法,ca-MST 无法实现。
六、关于教育考试数字化建设的若干启示
1. 教育考试数字化应采用何种模式需要因地制宜,不必做出全国性的统一规定
由国内外CBT、IBT、CAT 和ca-MST 的发展历程可知,教育考试数字化是未来发展的重要方向,特别是在抗击新冠肺炎疫情的过程中,无论是大众,还是专业人士或相关管理者,都已经高度认同了这种发展趋势。不过,目前常用的4 种教育考试数字化模式各有优点和缺点,不恰当的数字化考试不仅达不到预期,反而会带来很多副作用,例如,损害学生眼睛;教师过分依赖考试系统逐渐丧失教学的主导性;对不善于自主学习的学生不仅没有帮助,反而变成学习负担等。所以在不同条件下,最好因地制宜地采用不同模式,不必做出全国性的统一规定。
2. 提升教育考试数字化水平需要大批高水平测量学人才
从国外的发展情况看,大量高水平教育测量学人才的参与是实现教育考试数字化的重要保证。我国在这方面的提升空间比较大,需要鼓励高校建设一批高水准的教育测量与评价学科,为教育考试的数字化建设培养高素质的人才队伍,包括在经费上扶持、建设教育测量与评价博士培养项目、提升教育测量与评价类型学术杂志的地位等。相对于国外来说,我国设置教育测量与评价博士培养项目的高校数量几乎可以忽略不计,而且几乎没有高级别的教育测量与评价类别的学术期刊。结果,专攻教育测量与评价方向的博士研究生,往往因为没有本专业高级别期刊可以发表论文而毕业困难,使得稀缺的考试科学人才的培养工作雪上加霜。
3. 政府指导、学术支撑和市场运作的运行机制值得尝试
从我国的实际情况出发,要想提升教育考试的数字化水平,相关部门的有力支持必不可少,否则无法推进这项工作。从提升教育考试的质量来看,必须建立高水平的理论创新和技术改进机制,依靠科技进步来带动教育考试的数字化建设;脱离教育理论支撑和教育测量学支撑的数字化考试质量无法得到保障,甚至可能带来更多的副作用。此外,可以适当 参考国外教育考试行业的市场化运作机制,因为这种机制有助于形成良好的竞争环境,有助于鼓励学术创新,有助于提高产品的竞争力,并可能获得更多社会资源的投入与支持等。
4. 理论上完美的方案往往需要结合现实条件做出一些妥协
在实施CAT 项目时,IRT 理论强烈建议使用更为科学的包含了题目区分度(a)、难度(b)和猜测度(c)的三参数logistic 模型。但运用这种模型曾经导致测验等值中致命的量表漂移(scale drifting)问题,甚至糟糕到题库中所有新题经过等值处理后都达不到测量学要求的地步。迫不得已,目前国外的许多著名考试项目转为采用双参数IRT 模型、广义分步计分模型(generalized partial credit model,GPCM),甚至是Rasch 模型。另外,有专家曾经建议采用在线标定方式来实时估计题目和考生参数,但在线标定方式在网速不匹配的情况下很容易导致大量考生无法作答等麻烦。故此,ca-MST 这种妥协模式在当今很受考试机构的欢迎。
5. 教育考试的数字化需要加强考试与教学、考试与学习的联结
从目前一些考试项目的运行情况来看,考试与教学、考试与学习的联结不算理想。尤其是我国一些数字化考试项目或智慧教育项目,经常发生一些违反教育规律的事情,如在节省教师命题和阅卷时间的同时,可能使得教师更加不了解学生的学习过程和困难,这不仅增加了学生“刷题”的频率而且收效有限。要解决这类问题,就要加强IT 专家、教育专家和一线教育工作者的紧密联系。国际上的成功经验是:考试研发和使用机构(如政府相关管理部门或从事考试项目的企业)建立一个联合实验室或非营利性考试中心,以方便IT 专家、教育测量学家(psychometrician)、教育专家(research scientist)和考试使用方的合作互动。其中,教育专家负责题目研发和结果解读指导,教育测量学家负责研究设计、数据整理、参数估计、常模研发、测验等值、分数报告、质量评估等工作,IT 专家负责实现教育专家和教育测量学家提出的教育考试数字化要求,考试使用方负责提出考试需求、考试目标并做好用后反馈等工作。
6. 建立行业标准狠抓考试质量是提升考试数字化水平的关键
要保障教育考试数字化建设的健康发展,可以参考国外的成功案例,建立国家级的学术标准和教育测量与评价教学指导委员会等,以规范教育考试数字化服务活动,确保考试的质量,减轻教育考试数字化所带来的负面影响。考试的学术标准和行业规范主要包括以下一些内容:考试的公平性、可靠性(信度)和有效性(效度)都必须达到学术界所规定的标准;所有题目的参数估计都必须满足测量理论所规定的质量要求;考试分数的表达和解释不仅要与知识、能力、学科素养的要求一致,而且必须有高质量的常模参照分数或等值分数以及掌握分数等,而不能只报告没有明确含义的卷面原始分数;所有考试项目在使用之后,都必须对考试项目从内容到测量学要求等方面进行深入分析,并形成一份技术报告给考试使用方或公布给大众。
7. 深度结合人工智能技术,构建“互联网+”服务大平台,全面提升考试服务质量
教育考试的服务对象是广大考生,考生能否从数字化考试转型中获得良好的体验感和获得感,是数字化转型成败的关键。一是构建更加完善更加智能的数字化考试系统。以考试更智能、数据更集中、流程更优化、体验更美好为目标,构建功能强大的智慧教育考试服务大平台。二是开发多渠道系统接入平台。通过开发App、小程序、公众号、“快应用”等平台,实现“桌面测”“掌上测”和“指尖测”的高效结合,提升考生对数字化考试过程的体验感。
总之,教育考试的数字化建设是大势所趋,目前常用的4 种数字化模式既有显著优点,也有一些需要改进和完善之处。其中,数字化考试题库、数字化标准考场、数字化阅卷评分、数字化结果分析、数字化结果发送、数字化结果解读等是教育考试数字化建设的主要内容。只有加强政府指导,大力培养教育测量学专业人才,融合IT与教育行业,规范行业行为,才能提升教育考试的数字化水平,提高教育考试对教学工作的服务质量。
猜你喜欢
纺织科学研究(2021年6期)2021-07-15
文苑(2020年7期)2020-08-12
宁夏医学杂志(2020年3期)2020-02-27
中学生数理化·八年级数学人教版(2019年11期)2019-09-10
福建基础教育研究(2019年1期)2019-09-10
福建基础教育研究(2019年1期)2019-05-28
中学科技(2017年5期)2017-06-07
中国卫生(2016年2期)2016-11-12
新高考·高二数学(2014年12期)2015-10-16
中学科技(2015年6期)2015-08-08
