
非参数建模方法在电厂设备故障预警中的应用研究
2022-12-23 05:15张海峰袁佽先王亚欧
机电信息 2022年24期
张海峰 袁佽先 陈 波 王亚欧
(1.国能常州发电有限公司,江苏 常州 213033;2.江苏方天电力技术有限公司,江苏 南京 210036)
0 引言
随着国家“双碳”目标的确立和相关政策的不断落实深化,可以预见,电网未来对火电机组的负荷承担能力要求将越来越高,目前大部分省份已经要求上网的火电机组能够进行深度调峰,部分机组灵活性改造的试验效果甚至达到了20%满负荷的水平。火电机组的深度调峰运行使得各设备的操作运行突破了常规意义上的运行空间,导致运行不确定因素增加,给运行人员带来了新的挑战。
业内专家指出,在煤电机组灵活性改造的大背景下,做好设备运行维护和寿命管理,提升系统运行弹性,对于确保机组的安全经济运行至关重要。
据统计[1],江西电网1 000 MW机组2019年发生故障导致非计划停运次数为1,600 MW和300 MW机组也都大于0.6,造成了巨大的经济损失和不良影响。
目前,火电机组设备故障的监控处理主要依靠DCS系统中提供的报警和保护跳闸功能。然而,DCS系统的报警跳闸功能侧重于参数的单点阈值判断和事后处理,缺乏对多参数的集中判断和故障早期的提前预警。
为实现机组多参数监控和设备故障提前预警功能,本文提出了一种基于非参数模型的机组参数监控及设备故障预警方法。该方法不需要复杂的训练过程,模型准确性较高,计算简单,也适合工程化实施。
1 非参数建模方法
1.1 非参数自回归估计算法
非参数自回归估计算法[2-3]首先将实时观测的向量值与历史存储的标准值进行比较,通过映射组合得出实时状态向量的估计值。
假设某一状态向量的实时观测值为xobs=[x1obsx2obs…xmobs]T,其对应的标准历史存储矩阵为D,其中的一行代表某时刻的一个状态值,矩阵的行数代表n个标准状态值,列数代表状态向量共有m个参数,矩阵的形式如式(1)所示:

对于一个实时状态向量,非参数自回归估计模型通过标准存储矩阵中的向量组合得出,其计算公式为:

式中:W为权重向量,它的值取决于实时观测值与标准存储向量的距离,一般来讲,距离越小权重值就越大,反之则越小。
根据公式(2)可知,计算状态向量的回归值实质上就是求取权重向量值,以向量间的二范数作为衡量它们之间距离的测度,选取高斯函数作为映射函数,权重值的计算公式为:

式中:xk为历史标准存储矩阵中的第k个状态向量;h为宽度系数。
观测向量与xk的距离一般采用马氏距离算子进行计算:

其中,S为状态向量参数对应的协方差矩阵,若参数之间相对独立,则可以表示为:

利用模型计算前应先将所有的观测值进行标准
化,其计算公式为:

式中:yj为第j个参数标准化后的标准值;σj为状态向量中第j个参数的标准差,一般通过历史数据进行数理统计得出;uj为第j个参数的统计平均值。
回归值和观测值拟合状态指标为:

如式(7)所示,该指标值越小,则表示机组的运行状态越正常;反之,则说明状态出现异常。
1.2 标准历史存储矩阵
与一般的参数建模方法不同,非参数建模方法中不含有模型的训练过程,但模型的准确性受标准历史存储矩阵的影响较大。标准历史存储矩阵中存放的是代表机组或设备历史运行的各种标准状态,一般来讲,标准历史存储矩阵中包含的状态向量种类越多,数量越大,则其涵盖的历史运行工况越全面,模型的回归估计效果越好。然而,标准历史存储矩阵中状态向量的数目也不能过大,否则会导致计算耗费过大,尤其是在工程应用中无法满足计算的实时性需求。
一般通过从海量的历史数据中根据一定的采样规则进行采样获取标准历史存储矩阵,采样的规则根据实际需求进行设计,本文采用聚类与多参数采样结合的规则[4],如图1所示,根据该规则采样得到最终的标准历史存储矩阵。
图1展示了确定标准历史存储矩阵的具体流程,首先按照每个参数的范围和对应的间隔在海量的数据集中选取对应的状态向量,再利用数据挖掘中的聚类方法进行聚类,将类心作为标准状态向量进行选取,将两者结合得到一个总的向量集合,然后按照顺序逐个进行向量的重复性检查,剔除重复的状态向量,得到最终确定的历史标准存储状态矩阵。

图1 标准历史存储矩阵确定方法
2 四管泄漏故障诊断机制
2.1 四管泄漏故障专家知识库
专家知识库是故障诊断的基础,它描述的是各征兆参数与具体故障之间的隶属关系,文献[5]总结出了与锅炉四管泄漏相关的特征参数,并通过模型计算指出各征兆参数与故障类型间的变化关系。采用一种五值型的函数描述四管泄漏故障下的征兆参数变化特性,如式(8)所示:

五值型征兆集描述方式综合考虑了参数变化的幅度和方向,综合各文献所述的专家知识,得到表1和表2所示的故障专家知识库。

表1 四管泄漏征兆参数集

表2 四管泄漏专家知识库
2.2 基于模糊隶属度的故障诊断
故障诊断实际上是基于故障诊断专家库,根据一定的模糊隶属计算规则对当前的故障状态进行判定和识别。
本文根据极限学习机的回归误差提出一种新的模糊隶属度判定方法,其基于距离函数[5]:

式中:dj(u0,uj)为待识别故障u0与典型故障模式uj之间的距离,显然数值越小,发生该类故障的可能性就越大;zi为第i个征兆参数的故障征兆值;zij第j个典型故障下第i个征兆参数的征兆值。
隶属度函数为:

如式(10)所示,隶属度越大、越接近1,说明发生这类故障的可能性越大。
3 仿真验证
3.1 非参数模型自回归估计
利用国内某1 000 MW火电机组仿真系统进行工况的仿真,在机组正常运行状态下进行负荷升降操作,采样周期为1 s,共3 600组数据,其中前1 800组用于矩阵确定,后1 800组用于测试。图2列出了几个典型参数的模型回归效果。
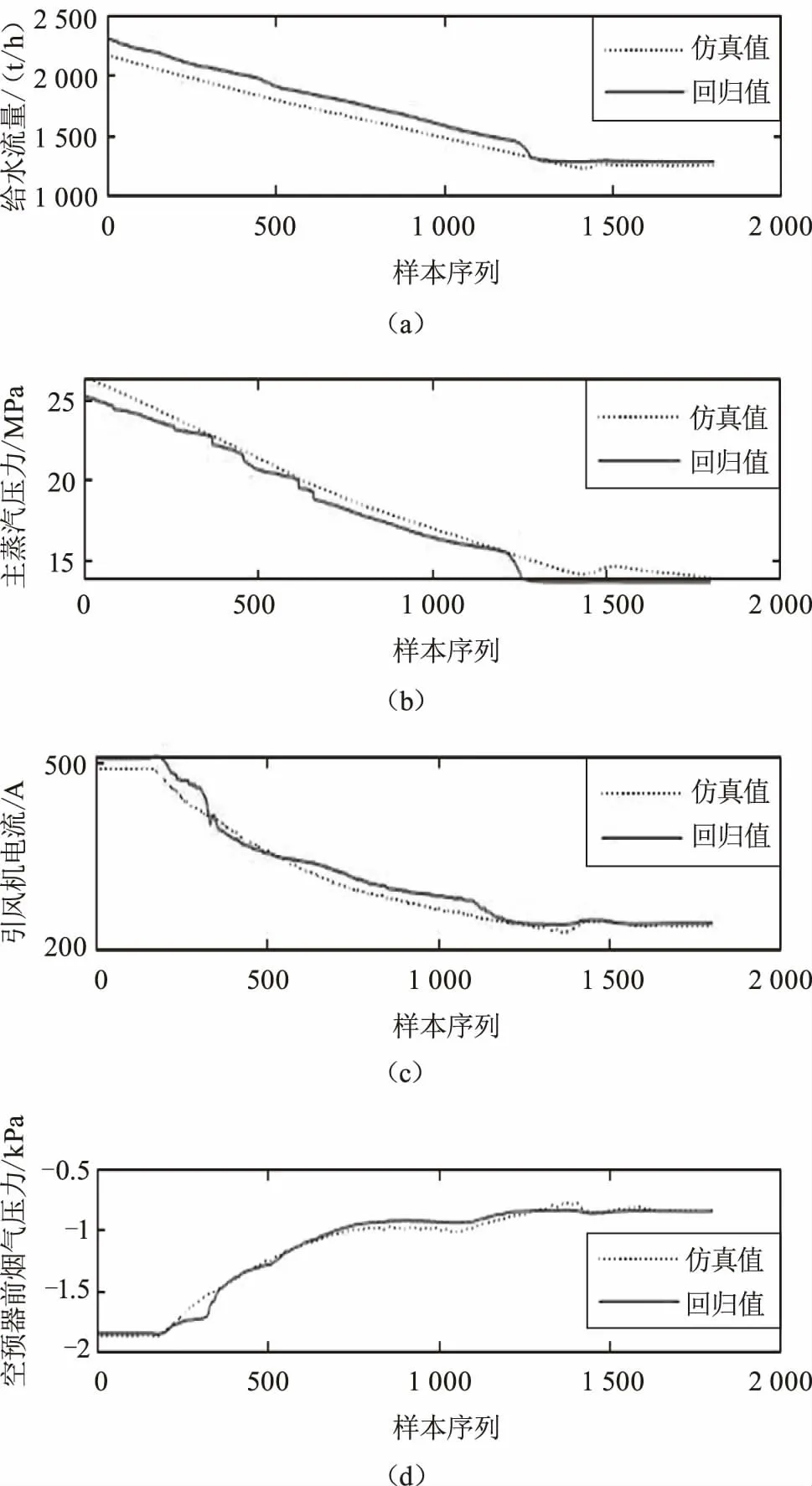
图2 非参数模型自回归估计
如图2所示,与四管泄漏故障相关的征兆参数包括给水流量、主蒸汽压力、引风机电流、烟气压力等,图中虚线表示仿真模型降负荷过程中各参数的仿真值,实线表示回归值。从图中可以看出,回归模型对各参数估计的结果较为准确,各参数的平均相对误差均小于5%。在机组变负荷过程中模型回归值能够及时地跟踪参数的变化,准确地反映机组运行状态。反之,若机组的运行状态发生异常变化,则回归误差增大,趋势曲线也必然呈现一定程度的偏离。
3.2 基于模型的故障诊断
从第31 s起模拟A侧高温过热器泄漏故障,图3是状态指标在A侧高温过热器泄漏故障后发生的变化趋势。
如图3所示,实曲线代表指标的变化趋势,可以看出,状态指标值在第33 s达到预警限值,此时处于故障早期,泄漏量较小,各征兆参数的波动小且未超DCS的报警限值,运行人员难以发现异常。在故障后56 s左右,DCS系统才发出超温报警。显然,预警信号对微小劣化的敏感度较高,对故障具有提前预警的作用。

图3 故障前后状态指标趋势
当出现预警信号后,利用专家知识库和模糊隶属度函数求取各故障的隶属度,由此确定具体的故障模式。表3是故障后各类故障隶属度的计算结果,从中可以看出,随着故障劣化程度的增大,当前故障对u3的隶属度呈现明显的增加趋势。实际上在预警信号出现后,诊断机制已经正确判断出发生了过热器泄漏故障,随着时间的推移,诊断结果的确定性加大,第39 s的计算结果则进一步确认了故障模式。
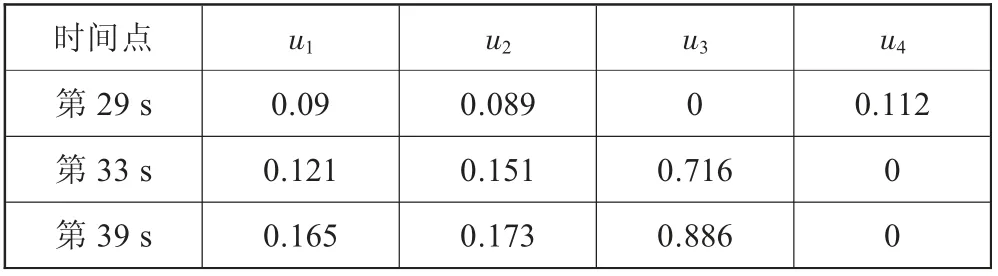
表3 故障诊断隶属度计算
4 结语
本文利用非参数建模方法建立了锅炉四管的状态参数回归模型,拟合出状态指标用于状态预警,并结合故障诊断专家知识库和模糊判别方法实现了故障分离。某1 000 MW机组仿真模型计算表明,非参数自回归模型能够对状态参数进行准确的回归估计,在故障发生早期,就能够提前给出准确的故障预警信号,验证了该方法的正确性与有效性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
一重技术(2021年5期)2022-01-18
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2018年10期)2018-08-04
青年文学家(2016年34期)2017-03-31
北京航空航天大学学报(2016年6期)2016-11-16
小星星·阅读100分(高年级)(2016年5期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
小星星·阅读100分(高年级)(2016年4期)2016-04-28
新高考·高二数学(2015年11期)2015-12-23
