
基于HR-MANO的手姿态动作识别算法研究
2022-12-22 01:31:18张睿敏杜叔强刘博宇
陕西理工大学学报(自然科学版) 2022年6期
张睿敏, 杜叔强, 刘博宇
(1.兰州工业学院 计算机与人工智能学院, 甘肃 兰州 730050;2.西安科技大学 计算机科学与技术学院, 陕西 西安 710054)
随着大数据、云计算、人工智能等技术的迅速发展,人机交互也越来越智能和便捷。目前人们主要使用鼠标、键盘、触摸屏进行人机交互,而单目摄像头则是电脑最为常见的配件,利用神经网络手势识别算法进行动态手势识别,在智能驾驶、远程医疗、工业质检、人机交互、虚拟现实等方面都有着广阔的应用前景和市场。目前手势识别有接触式和非接触式识别。接触式识别依赖特殊设备(如数据手套、数据手环等)的识别系统,这类系统由于配有各类传感器(如生物电传感器、磁性传感器等),识别效果良好,专业性强,但是需要复杂的设备,价格昂贵,因此一般应用于受限的特定场景[1-3]。非接触无标记动态手势识别只需使用标准的摄像头捕捉手势视频图像,先对手部图像进行检测,然后对手势进行识别[4-5]。Tome等[6]利用HSV色彩空间训练了肤色的表现形式,通过选取阈值检测手部,但有时背景色与肤色相近,以及光照等条件都会影响检测效果。王强宇[7]通过时空域的图结构来表示骨架信息,选取手上最具运动代表性的骨骼点作为时空域上的关节点,通过图卷积神经网络(Graph Convolutional Network,GCN)卷积运算能对常见的几种手势进行分类和辨别,但它只能对深度图像进行处理。
针对上述问题,本文先使用改进的单次多核探测器(Single Shot Multibox Detector,SSD)算法对普通摄像头拍摄的RGB视频图像中的手部目标进行检测,然后利用HR-MANO对手部姿态动作进行3D估计和识别。
1 手部目标检测算法
1.1 基于端到端学习的目标检测算法
手部姿态动作识别的难点一方面是图像背景有时比较复杂(如背景也有肤色),还受到光照条件等影响。另一方面手部形状变化姿态会影响手部活动的识别,即识别的准确性,并且若要识别能够实时执行,必须考虑识别速度[8]。主流算法会采用非极大值抑制(Non-Maximum Suppression,NMS),它是在很多重复目标框中提取置信度高的目标检测框,得到最终的目标框。在这种机制下,为了增加网络的鲁棒性,往往要尽可能多的设置预测框,而过多的预测框又会引起更多的重复样本[9]。SSD算法是端到端的检测,即检测时一个目标只生成一个预测框,SSD算法框架是在基础网络VGG6(stage1~stage5)上加入辅助结构[10],即2个全连接层Fc6、Fc7(conv6、conv7),4个卷积层(conv8、conv9、conv10、conv11),整体架构如图1所示。

图1 SSD框架
SSD中Anchor Boxes(锚框)的高度和宽度不是固定的,它有固定的纵横比,纵横比根据特征图缩放Anchor Boxes。在每个特征图网格和每个默认框中,预测相对于锚框中心的x和y偏移量、宽度和高度的偏移量以及每个类别和背景的分数[11]。如果对k个检测器、m×n个特征图和c个类别进行分类,则需预测每个网格和检测器的4个边界框参数和c+1个类别[12]。计算锚框尺寸比例的方法如下:
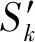
将每个真实边界框与某个预测框匹配,使用二分匹配算法进行匹配。具体为将每个真实边界框与具有最高jaccard重叠的默认框匹配,默认框与任何具有高于阈值的jaccard重叠的真实框匹配可以使许多预测框与特定的真实框相关联,这样有助于检测器专注于特定大小的目标。
1.2 SSD算法的改进
本项目使用改进的SSD算法直接预测目标定位框,在SSD中将多尺度特征映射定义为
Fn=θn(Fn-1)=θn(θn-1(…θ1(I))),
其中Fn表示第n层的特征图谱,θn表示n到n-1层上的非线性运算(如卷积层运算、池化层运算等),I为输入。若用γn表示能够将第n层特征图谱转换为某尺度范围内检测结果的算法,用f表示对所有中间结果进行运算并生成检测结果的操作,则输出O定义为
O=f(γn(Fn),γn-1(Fn-1),…,γn-i(Fn-i)),
其中0 S={Fn,Fn-1,…,Fn-i}, 0 损失函数分为分类损失函数和回归损失函数。分类损失函数用于类别预测,因为SSD使用softmax来预测类概率[13]时,另外无需预测重叠的类,只有一个类可以分配给特定对象,所以改进算法使用交叉熵损失作为分类损失,其定义如下: 手部姿态估计通过定位手部骨骼关节点的位置来模拟手部姿态的变化,从而进行交互控制,三维手部姿态估计是手势识别技术中难度最大的[14]。随着大数据和神经网络技术的发展,利用神经网络对手部姿态进行估计越来越受到重视。 采用预先训练好的深度神经网络对RGB图像中的手势进行二维关节点检测,得出包含关节点二维信息的特征图。网络从输入的RGB图像中估计手部姿态关节点位置。在网络每个阶段,各分类器输出每个关节点位置的置信度,根据上下文特征映射和,每个关节点的置信度计算估计会越来越精细[15]。第一级网络是基础的全卷积网络,它改变了输入的RGB图像的宽和高,并能从图像上直接预测手姿态部位。第二级网络是在卷积层中增加一个串联层,输入分类器的不是原始图像特征,而是上一阶段的卷积所得的特征图谱,并且定义一个特征函数计算上一阶段置信度的感受野,通过输出足够大的感受野来学习关节点之间的复杂度和关联性,而卷积时增大步长,感受野也随之增大[16]。第三级网络的输入是第二级网络中间的一个特征图,同样在卷积层中加入一个串联层来综合各种因素,输出关节点的预测结果。这样深度网络的每级网络都重复地输出每个关节点位置的置信度,输出后进一步计算损失,作为中间监督损失[17]。 二维关节点的定位由二维得分图的估计c={c1(u,v),c2(u,v),…,cJ(u,v)}来表示。基于二维关节点训练网络以预测J得分图cJ∈RN×M,其中每个得分图包含关于某个关节点存在于空间位置的可能性的信息。多个分类器g对图像位置z所提取特征xz∈Rd及前一阶段的输出Yp信息进行分类,当t=1,分类器g1输出的关节点位置的置信度为 当t>1时,分类器输出的关节点位置的置信度表示如下: ψt>1(·)是置信度Bt-1的上下文特征映射,这样每个阶段对每个关节的置信度的计算会越来越精细。 第一级网络对RGB图像I∈R3×ω×h重塑,以3×800×600大小的图像输入,卷积核是3×3,步长为2,这样通过两层卷积变换使图像大小变为200×150,通道数翻倍增加。第二级网络提取图像手关节点特征信息,卷积核不变,步长为1,滤波个数为32,通过ψ计算各个关节点的特征,加入一个串联层组合特征和高斯约束[18]。第三级网络是并行高分辨率并融合相关特征(空间、纹理、约束等)的卷积运算,最终输出21个关节点图。 2.2.1 RGB图像3D手姿态估计框架 单目RGB图像3D手姿态估计首先通过特征网络来提取MANO模型所需的相关参数,如{θ,β}等;然后通过MANO模型将低维手关节点映射成高维的三维坐标向量;最后通过矩阵变换,使估计关节点映射在图像坐标系上。它的主要过程如图2所示。 图2 3D手姿态估计框架 特征网络由高分辨率网络(HRNet)和残差网络(ResNet)组成,负责学习MANO模型参数。HRNet通过逐步增加高分辨率到低分辨率的子网将多尺度信息融合,这样能够保留高分辨率图像信息。而ResNet结构可以构建深层次网络而实现高度复杂的非线性映射,从二维的图像像素到MANO参数也是高度复杂的非线性映射,因此使用ResNet来学习这种映射。通过在ResNet中额外加入一层1×1的卷积层来确保维度上的一致性,并且将ResNet接在HRNet之后来进一步利用HRNet保留的高分辨率信息,进一步提升拟合MANO参数的准确性。通过特征网络获取参数{θ,β}和空间特征参数F,其中θ是关节点相对其父节点的旋转角度,β是形状空间系数。然后将参数{θ,β}输入到MANO模型,由模型映射为三维手部关节点J∈R21×3。 2.2.2MANO算法模型改进 式中β为形状参数,β∈R10,θ为姿态参数,θ∈R48。接着进行M(θ,β)操作,对M(θ,β)定义为 M(θ,β)=W(T(θ,β),θ,ω,J(θ)), 式中W表示线性混合蒙皮(LBS),即根据16个关节点的位置牵动手部网格T,ω(·)是混合权重,J(θ)表示关节点回归函数,可以从mesh中回归出3D关节点。 式中θ*是初始的姿态,Rn(θ)是R(θ)的第n个元素,β=(β1,β2,…,β|β|)T,|β|是线性形状个数,Sn∈KV×3是形状位移正交主分量,Pn∈KV×3是顶点偏移量。 2.2.3 损失函数 损失函数有3个: 3D joints损失L3D、手部mask损失Lmask、参数回归损失Lreg。它们的定义如下: 式中Lmask是本文引入的一个新的损失函数。在训练之前,先使用Crabcut算法计算出手部的分割区域,在网络得到手部的mesh顶点后,将其投影到3D平面,Lmask会惩罚那些落在分割区域外面的顶点,这样可以加快收敛并提升手部形状预测的效果。其他两个损失函数功能与HRM(Human Mesh Recovery)模型的损失函数一样。 实验硬件环境:CPU,Amd Ryzen 3600 @4.2 GHz;GPU,NVIDIA Geforce Rtx 3060;内存32 GB;普通单目摄像头(后期进行视频图像读取);ASUS TUF-GeForce RTX3080TI-O12G-GAMING 12 GB 显存的显卡。软件开发工具有python3.7.10、pycharm、TensorFlow1.15.0-GPU、cuda10.1.105、cudnn7.6.4、pytorch1.5.0。 本项目训练过程中分别用FreiHAND数据集和普通彩色图像进行训练,而最终的任务是从单幅彩色图像估计三维手部姿态。FreiHAND免费版本中包含32 560个独特的训练样本和3960个独特的评估样本。训练样本以绿色屏幕背景记录,便于去除背景。本实验使用不同的处理策略为每个训练样本提供了3个额外的样本版本,产生了130 240个样本的总训练集大小,实验过程如下: (1)下载FreiHAND数据集并进行相关环境配置,数据集所在路径是d:/project/training/evaluation/FreiHAND_pub 。 -p python3.7./venv venv/bin/activate // 激活 install numpy matplotlib scikit-image transforms3d tqdm opencv-python cython //安装相关基础包和库 http://mano.is.tue.mpg.de // 从MANO网站下载模型和代码 python setup_mano.py // 安装mano pip install opendr //安装OpenDR python view_samples.py d:/project/training/evaluation/FreiHAND_pub //使用渲染的MANO形状可视化样本 (2)在FreiHAND数据集上按照算法模型进行姿态估计。 python pred.py d:/project/training/evaluation/FreiHAND_pub_v2 //对评估数据集进行预测估计。 训练时的部分关键代码如下: def print_args(args): opts = vars(args) cprint("{:>30} Options {}".format("=" * 15, "=" * 15), ′yellow′) for k, v in sorted(opts.items()): print("{:>30} : {}".format(k, v)) cprint("{:>30} Options {}".format("=" * 15, "=" * 15), ′yellow′) def main(args): if not os.path.isdir(args.checkpoint): os.makedirs(args.checkpoint) print_args(args) print("
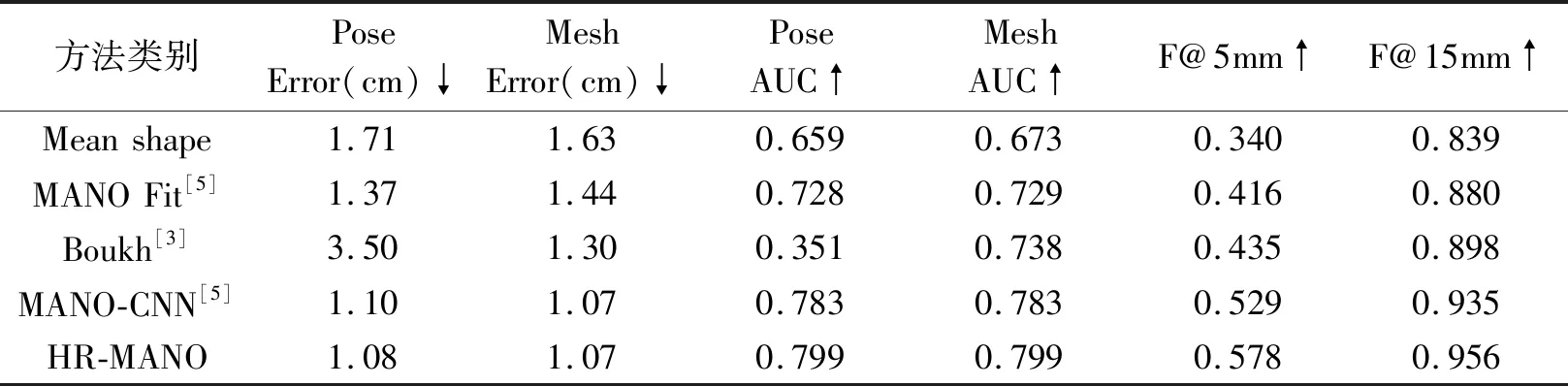
CREATE NETWORK") model = shape_net.ShapeNet(_mano_root=′mano/models′) model = model.to(device) train_dataset = SIK1M.SIK1M( data_root=args.data_root, data_split="train" ) val_dataset = SIK1M.SIK1M( data_root=args.data_root, data_split="test" ) train_loader = torch.utils.data.DataLoader( train_dataset, batch_size=args.train_batch, shuffle=True, num_workers=args.workers, pin_memory=True ) val_loader = torch.utils.data.DataLoader( val_dataset, batch_size=args.test_batch, shuffle=False, num_workers=args.workers, pin_memory=True ) 输出结果如下: Pose error 1.08cm Pose error aligned 1.13cm Mesh error 1.07cm Mesh error aligned 1.09cm F@5mm=0.578, F@15mm=0.956 F_aliged@5mm= 0.001, F_aligned@15mm=0.031 将在FreiHAND数据集上的结果参数与传统的Mean shape、MANO Fit、Boukh、MANO-CNN方法的实验结果参数进行对比,见表1。 表1 在FreiHAND数据集上实验结果参数对比 从表中的性能指标参数看,HR-MANO方法取得了更高的AUC值和较低的平均误差,证明了HR-MANO算法模型优于其他方法,能有效用于手姿态动作识别。最终算法检测结果部分实例如图3所示。 (a) 手部自遮挡 (b) 手部高度灵活变形 (c) 背景有肤色 图3 算法检测实例 从算法实例结果可以看出,本文算法能够对普通摄像头采集到的视频RGB图像的手姿态进行准确的估计,并且在手部自遮挡时(图3a)、手部高度灵活变形时(图3b)以及图像背景有肤色时(图3c)等这些复杂情况下,也能够对手部姿态进行准确的估计。在提高算法性能的基础上,下一步计划将研究如何减小手部姿态估计算法对数据集的依赖性,进而提高算法的泛化性。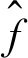
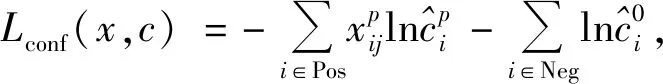
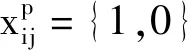
2 手部姿态估计
2.1 二维手关节点估计
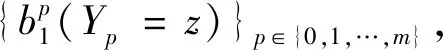
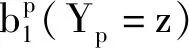
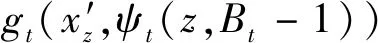
2.2 单目RGB图像3D手姿态估计算法改进
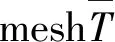
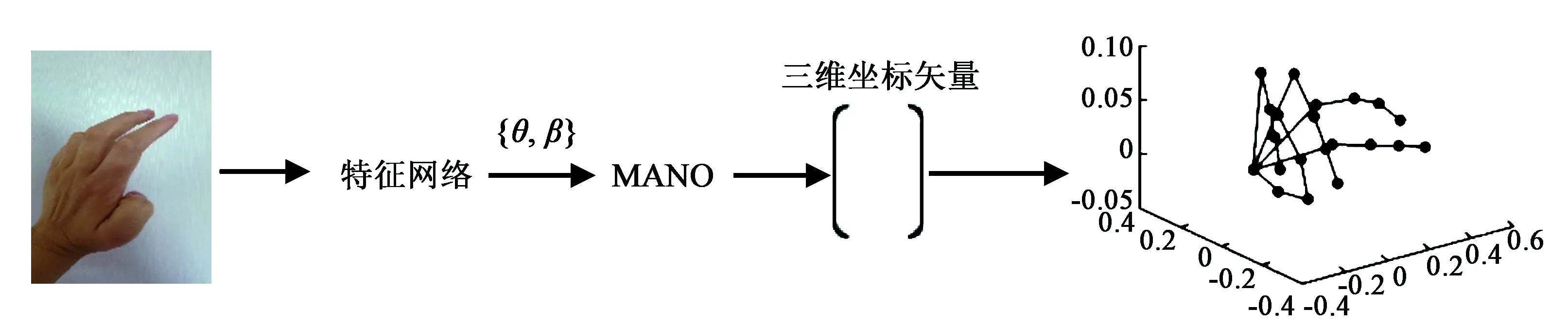
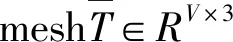
3 实验结果及分析
3.1 实验环境
3.2 数据集和实验过程
3.3 实验结果分析
 猜你喜欢
实用手外科杂志(2022年2期)2022-08-31 09:48:02核科学与工程(2021年4期)2022-01-12 06:30:22科学技术创新(2021年19期)2021-07-16 10:07:04沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30计算机应用(2018年5期)2018-07-25 07:41:26军营文化天地(2017年6期)2017-06-28 11:30:19实用手外科杂志(2015年4期)2015-08-27 01:54:14轴承(2015年2期)2015-07-25 03:51:04中华皮肤科杂志(2014年4期)2014-12-19 12:56:00中国药业(2014年21期)2014-05-26 08:56:48
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31 09:48:02核科学与工程(2021年4期)2022-01-12 06:30:22科学技术创新(2021年19期)2021-07-16 10:07:04沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30计算机应用(2018年5期)2018-07-25 07:41:26军营文化天地(2017年6期)2017-06-28 11:30:19实用手外科杂志(2015年4期)2015-08-27 01:54:14轴承(2015年2期)2015-07-25 03:51:04中华皮肤科杂志(2014年4期)2014-12-19 12:56:00中国药业(2014年21期)2014-05-26 08:56:48
