
改进目标检测算法在变电站内安全管控的应用
2022-12-22 11:48:04吴宏毅雷景生陈林锋杨胜英
计算机工程与应用 2022年24期
吴宏毅,雷景生,陈林锋,杨胜英
浙江科技学院 信息与电子工程学院,杭州 310000
电力系统的安全、平稳运行,关系到国家安全和经济的发展,变电站作为电力系统的重要一环,有必要确保变电站长期安全可靠地运行。然而在变电站实际生产作业,人员巡检维护过程中,因为作业人员安全意识缺乏,忽视电力系统规章制度,出现各种各样的违章作业行为。在变电站作业场景中未规范佩戴安全帽和未穿着工作服是普遍的违章行为,对作业人员和电力设备都会造成极大的安全隐患。
随着人工智能的发展,运用深度学习方法和计算机视觉技术自动检测变电站作业人员是否佩戴安全帽并提供反馈,对安全生产至关重要[1]。近年来,安全帽佩戴检测取得了一定发展。在传统领域,Feng等[2]在图像预处理的基础上,利用高斯混合模型分离图像前景和背景,通过连通域检测进行人体的判别,对人体的头部进行定位并判断安全帽的佩戴情况。该方法实现了安全帽的自动检测,但算法的操作复杂且对复杂的场景下检测的准确率不高。Dahiya等[3]首先采用背景减法和目标分割检测出骑车的人,之后结合方向梯度直方图(his‐tograms of oriented gradients,HOG)、尺度不变特征变换(scale invariant feature transform,SIFT)和局部二值制模式(local binary patterns,LBP),训练一个二分类的分类器用以判断安全帽的佩戴情况。该方法虽然检测准确率较高,且检测速度快,但若检测场景发生变化,则需要重新设计模型框架。
目前,基于深度学习的目标检测算法发展迅速,现有的目标检测算法主要分有两种,分别是基于区域建议网络的two-stage方法和无区域建议网络的one-stage方法。2015年Girshick等[4-6]分别提出了Fast R-CNN和Faster R-CNN,其中Faster R-CNN改进了R-CNN的暴力检测提出了区域候选网络(RPN)达到了较好的检测效果,但基于候选区域方法的计算复杂度高,故该方法的检测帧率只能达到5 FPS。He等[7]提出了Mask R-CNN,通过并行预测框和掩码,得到检测的最新结果。在one-stage目标检测算法中Redmon等[8-10]提出YO‐LOv1-v3,Liu等[11]提出了SSD多尺度检测算法,取得了一定的效果,算法的基本思想是使用一个卷积神经网络直接预测不用的目标的类别和位置,这种方法计算量少,检测速度快,在视频检测上达到了45 FPS。对比one-stage和two-stage目标检测算法可以发现one-stage的目标检测算法在检测速度上要明显优于two-stage的算法,但在小目标的检测精度上要略逊于two-stage。因此,在安全帽检测领域人们在速度和精度方面权衡考虑下采用one-stage的目标检测算法。Wang等[12]提出了一种安全帽佩戴的实时检测方法(命名为CSYOLOv3),但其在速度及精度上表现并不优秀。Li等[13]提出了一种基于卷积神经网络的工程管理中深度学习的安全帽检测方法,该方法在图像不清晰,如安全帽太小、太模糊时,检测性能较差。
综上,传统安全帽检测算法优势在于参数量小,计算速度快,但实现主要基于复杂的模型设计,需要大量人工设计特征,对实际光照条件,图像质量的要求较高。因此传统的安全帽检测方法,特征提取不具备鲁棒性,泛化能力较差。基于深度学习的安全帽检测算法,虽然在一定程度上增强了模型的泛化能力,当目前安全帽检测模型都只将安全帽检测任务分为两个类别:佩戴和未佩戴安全帽两个类别。在实际变电站巡检场景安全规范中工作人员不仅需要佩戴安全帽,还要穿着长袖工作服。因此,上述论著并不完全适用变电站工作场景。
针对变电站特定场景,制作了安全帽工作服数据集,解决了在变电站场景中只能针对人员安全帽进行检测的检测内容不完善的问题。同时,虽然通用的目标检测算法在公共数据集上表现良好,然而在复杂的变电站场景下,如变电站中大多数监控场景是广域监视,拍摄到需要检测的目标物体,易出现密集且尺度小、分辨率较低、像素模糊等情况,容易导致漏检现象。另外,变电站内设备繁多,部署大型算力服务器设备成本较高,而一般目标检测算法的计算量庞大需要大型设备支持,使其很难在移动设备上部署。能在移动设备上运行轻量级的检测网络能有效降低使用成本。因此,本文提出了TinyDet针对变电站特定场景的自建数据集平衡了检测的精度和算法复杂度。为了降低参数数量和运算量的同时提高检测效率,构建了轻量级卷积神经网络back‐bone并同时使用Transformer[14]作为模型的颈部。基于YOLOv3的YOLOv3-tiny是一种应用嵌入式平台的轻量级目标检测网络,但其检测精度较低。在目前较强单阶段的目标检测,如FCOS[15]、ATSS[16]等,模型一般会包括三个预测输出,目标的分类表示,检测框表示和检测框的质量估计。在上述模型的训练过程中,分类和检测框的质量估计是分开训练的,在测试阶段却是相乘在一起作为非极大值抑制(non-maximum suppression,NMS)的排序依据,这种操作显然是没有端到端,存在一定的间隙[17]。影响了模型训练效果,导致了数据拟合效果差。因此,使用了质量焦点损失函数(quality focal loss,QFL)作为检测模型的预测头部,解决目标检测模型中预测的分类分数和IOU分数在训练和测试中不一致的问题,进一步提升模型的检测精度。根据以上几点工作,设计出轻量级的目标检测模型在变电站人员安全管控场景得到了较好的检测效果。
1 轻量级目标检测算法
本文采用Anchors-free的目标检测算法策略,如图1所示,使用轻量级的卷积神经网络ShuffleNetv2[18]提取图像特征信息,配合Transformer的编码器进一步提取图像高级语义信息。将QFL作为预测头部解决训练与测试时推理不一致给模型训练结果带来的影响。
1.1 轻量级特征提取网络
对于图像特征提取任务,选择ShuffleNetv2,因为其在速度和精度之间进行了权衡。选择ShuffleNetv2的通道乘数为×1,如表1的输出通道栏所示。选择此通道乘数是基于其在ImageNet数据集[19]上的精度和速度结果达到较好的平衡。但是,也可以选择较低的输出通道乘数作为超参数的值,以通过牺牲精度的方式来实现更快的推理时间。反之,通过提高通道乘数增加参数量来提高精度,便会相应地消耗更多的时间推理。
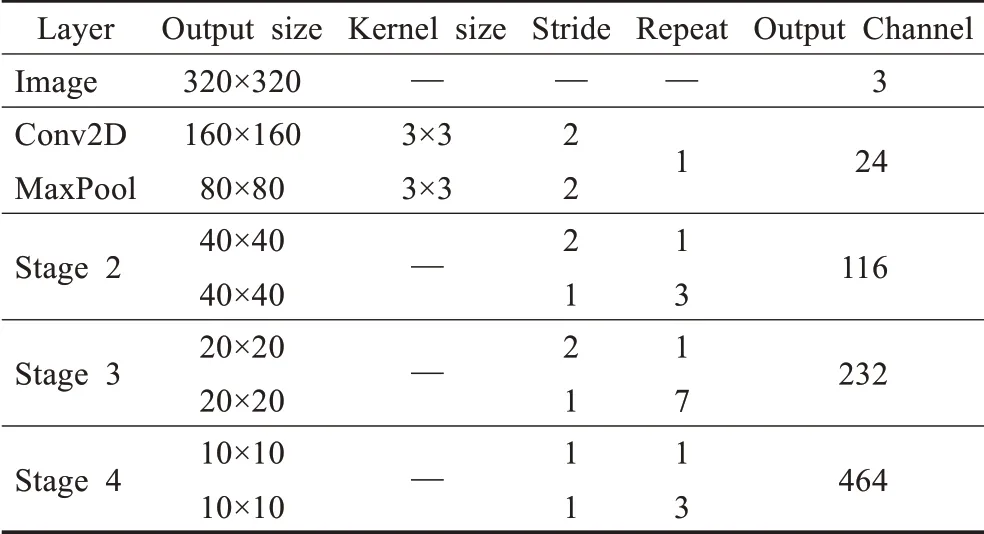
表1 轻量级特征提取网络主干结构Table 1 Lightweight feature extraction backbone network
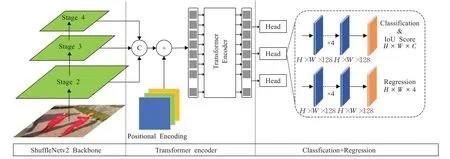
图1轻量级目标检测网络结构Fig.1 Lightweight object detection network architecture
图2 中详细显示了特征提取网络结构的模块单元。每一级由一个空间下采样单元和若干个基本单元组成。如图2(a)所示为网络基本单元,使用“Channel Split”“Channel Shuffle”“Concat”来实现不同通道间的信息交换。而空间下采样单元则是通过调节卷积核的步长来实现特征图尺度的变化,当步长设置为2,输入下采样单元的特征图尺度减少为原来的一半。
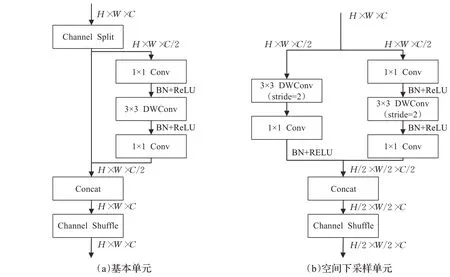
图2 轻量级特征提取网络基础结构Fig.2 Lightweight feature extraction network infrastructure
采用长宽为320×320的RGB图像作为模型的输入特征,通过轻量级特征提取网络ShuffleNetv2将输入特征采样至原始图像尺寸的1/32,以便于提取图像中的高级语义信息。同时,也将表1中所展示的Stage2、Stage3、Stage4中三阶段不同尺度的输出特征图作为颈部结构Transformer的输入。以实现对不同尺度目标的特征信息的保留,提升模型的精度。
1.2 Transformer编码
输入图像ximg∈3为RGB色彩通道,H、W为图像的高、宽)经过轻量级特征提取网络Shuffle‐Netv2,生成三个阶段低分辨率特征图。将三个阶段不同尺度的特征图按通道维度合并成特征图f∈C=812,H0=H/16,W0=W/16)。将 特 征图经过1×1卷积将高水平特征图f的通道维度降低成128维,生成的特征图z0∈Transformer的编码阶段需要序列作为输入,因此特征图z0的空间维度压缩成一个维度,即结果为d×H0W0。每个编码层都有一个标准的体系结构,并由多头自注意力模块和前馈网络(FFN)组成。
由于图像数据的像素值之间是有位置信息的,将特征图的空间维度压缩成一个维度便会丢失图像本有的位置信息。因此,为了保留位置信息则需要加上位置编码。因为图像是2-D特征,所以位置编码需要考虑图像宽和高两个方向上的编码才更符合图像的特点。位置编码的输出张量与Transformer结构输入序列维度一致,即d×H0W0。其中d代表位置编码的长度,前d/2维代表H0方向上的编码,后d/2维代表W1方向上的编码。将此位置编码与序列化的特征图z0相加后输入编码器。
由图3所示,图像特征序列分别以fq、fk、fv矩阵形式输入编码器,其中fq、fk需要加上位置编码,然后进入多头自注意力机制(multi-head self-attention)。d维特征M个头部的多头注意力机制的一般简化形式如下:
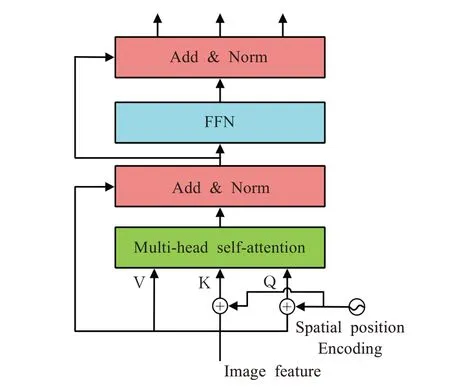
图3 Transformer编码器结构图Fig.3 Transformer encoderarchitecture
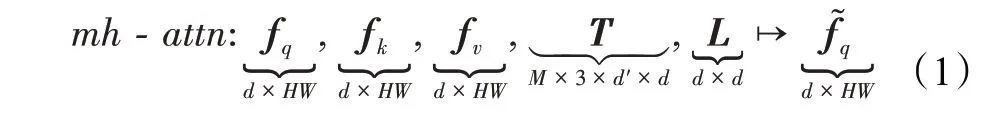
其中,fq为长度HW的查询序列,fk、fv分别为长度HW的键值序列,都有相同的d维特征;T是计算所谓查询、键和值嵌入的权重张量,L则是个映射矩阵。输出的特征大小与查询序列一致。
多头注意力机制就是直接将M个头部的输出合并,然后乘上映射矩阵L得到最终输出。其中通常会采用残差连接,dropout和layer normalization的方式。总的表示形式如下:
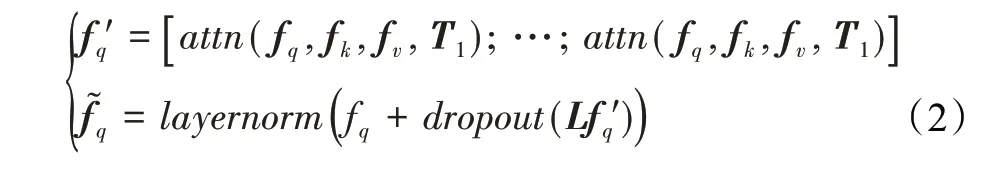
原始的Transformer是交替使用所谓的FFN层和多头注意力,FFN实际上就是多层的1×1卷积操作。在本文的例子中M个头部就有M×d的输入和输出通道。为模型的轻量化考虑使用具有LeakyReLU激活和两层1×1卷积操作来完成FFN的功能。
1.3 质量焦点损失
最初焦点损失(fcoal loss,FL)[20]的提出是为了解决在单阶段目标检测中正负类别样本不平衡的问题,FL的公式表示如下:
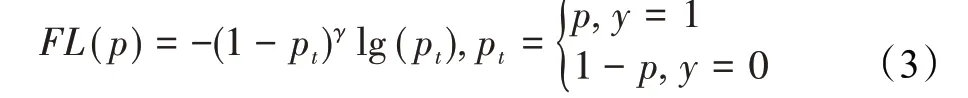
其中,y∈{1,0}表示标签类别,p∈[ 0,1]表示估计为类别y=1的概率。γ表示可调聚焦参数。具体来说,FL是由标准交叉熵部分-lg(pt)和动态缩放因子部分(1-pt)γ组成。其中缩放因子(1-pt)γ在训练期间将降低数量多的简单类别的损失权重,使模型更加关注困难样本。
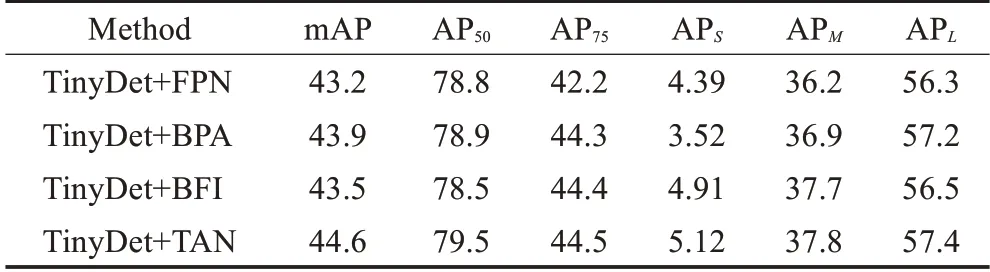
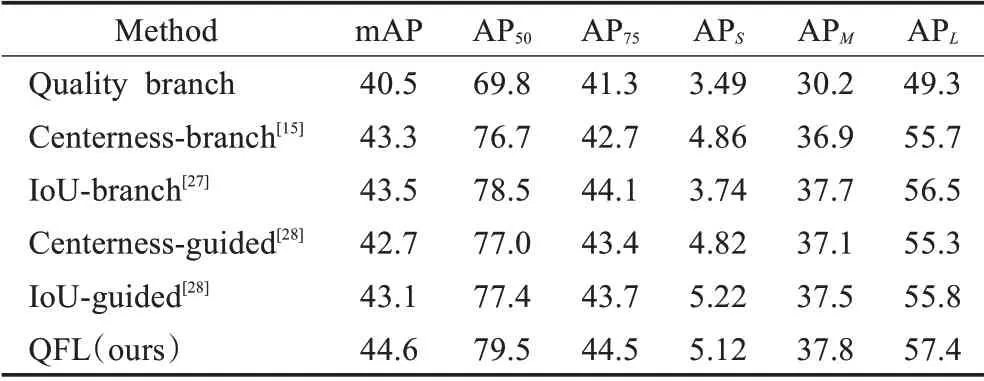
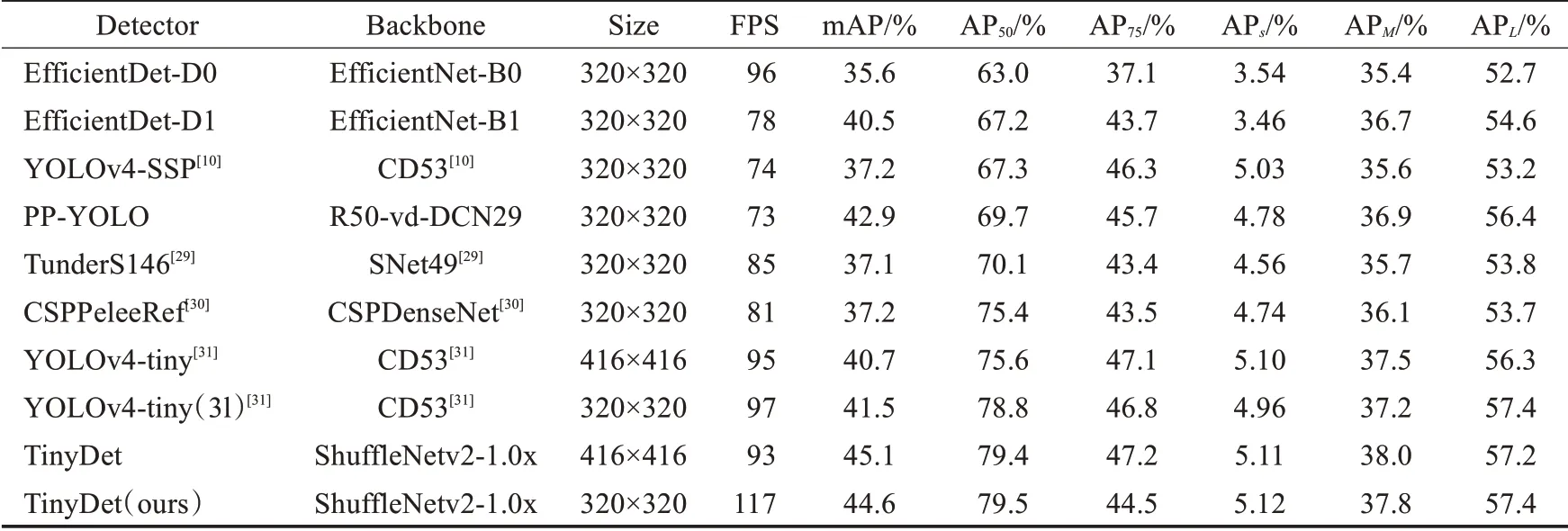
为了解决上述模型训练测试不一致问题,如图4中所示,将模型的分类预测分数和检测框的质量预测分数联合起来,也就是将相应类别上的one-hot编码平滑成质量预测分数,即相应类别上的预测值为y∈[0,1]。具体来说,y=0表示质量预测分数为0的负样本,0 图4 模型预测分支表示形式Fig.4 Branch representation of model prediction 由于提出的分类预测分数和质量预测分数联合表示需要对整个模型进行密集监督,并且仍然存在类别不平衡问题,因此还需要继承FL思想。但原始的FL只支持两个离散标签,但是本文的联合标签包含小数。因此基于FL改进了两个部分以保证联合表示的情况下可以实现成功训练: (1)将交叉熵损失-lg(pt)扩展成完整表示-((1-y)lg(1-σ)+y lg(σ))。 (2)将FL中的调节因子(1-pt)γ扩展成估计值σ和标签值y之间的绝对距离,即 ||y-σβ(β≥0)。 将上述两个部分结合起来成为完整的损失目标函数,表示如下: 其中,σ=y为loss的全局最优解。与FL相似,loss中的|y-σ|β也具有调节因子的作用:当实例的质量预测分数不准确且偏离标签y时,调节因子的值较大,因此更关注学习困难实例。当质量预测分数变准确时,即σ→y时因子值趋向于0,对容易预测的类别进行降权。其中参数β平滑地控制降权速率。 本文的实验环境配置:GPU采用NVIDIA TITAN XP,CPU采用Intel i5-7500,内存16 GB,操作系统为Ubuntu16.04。实验基于Pytorch深度学习框架、CUDA 10.1和OpenCV等进行相关代码和参数的训练。 通过截取在变电站大门、配电室、变电站集控室、变电站电力设备等区域监控摄像头的视频图像,得到变电站场景下人员工作服安全帽数据集共5 200张,包括变电站室内室外不同场景以及不同光照条件、摄像头角度下的图片。如图5所示,采集变电站内监控视频图像数据。其中4 000张用来训练人员工作服安全帽检测模型,1 200张用于模型的测试。采用LabelImg标注工具对收集的数据集进行标注,其中每个bounding box的标签:hat表示为佩戴安全帽,head表示未佩戴安全帽,person表示为变电站的作业人员,jacket表示穿着工作服,other-jacket表示未穿着工作服,pants表示穿着工作裤,other-pants表示未穿着工作裤。 图5 变电站工作服安全帽数据集Fig.5 Transformer substation workwear and helmet dataset 通过对检测类别的细化标注,以便于训练模型达到更加适配变电站检测场景的要求。最终转换为PASCAL VOC格式的XML文件。 本文使用精确度(precision rate)、召回率(recall rate)、误检率(false positive rate)、漏检率(miss rate)、交并比(IoU)和平均精度(mAP)来衡量提出的方法在自制的数据集上的有效性,计算公式如下: 其中,TP表示模型预测为正值的正样本;FP表示模型预测为负值的正样本;FN表示模型预测为负值的负样本;TN表示被模型预测为正值的负样本;partAcreage是模型预测出的检测框区域;overallAcreage是数据标注的目标检测框区域。 使用ShuffleNet v2作为模型backbone,加载官方提供的在ImageNet上训练好的权重参数进行初始化网络。使用随机梯度下降(SGD)优化算法训练网络60 000次,初始化学习率为0.01,训练批次为16幅图像,图像输入为320×320。在迭代次数为30 000和50 000时,学习率分别降低10倍。权重衰减和动量分别设置为0.000 1和0.9。为了使Transformer编码器的自注意力来学习图像全局信息,在训练期间使用了随机裁剪数据增强。也就是输入图像以0.5的概率被裁剪成随机的矩阵块,然后将该矩阵的尺寸大小调整成输入图像大小。训练使用dropout比率为0.1。 为了评估本文设计的模型结构在目标检测任务中的性能表现,在自制的工作服安全帽数据集实验测试了效果。 通过对比不同的特征提取器在数据集中的精度和速度的表现,证明使用ShuffleNet v2作为该场景下模型的特征提取器是有效的。只将模型的主干网络进行替换,同时遵循相同的训练和测试方案。替换成最近提出的轻量级网络Xception[21]、MobileNetv1、MobileNetv2[22]和ShuffleNetv1[23]等,通过在本文工作服安全帽数据集上测试,采用COCO评价指标评价,得到结果如表2。 表2 不同主干网络评估指标对比Table 2 Comparison of different backbone network evaluation indexes 如表2所示,在只替换模型主干网络的情况下,使用ShuffleNetv2作为本文目标检测模型的主干特征提取网络,在工作服安全帽数据集上精度和模型计算量达到最优的效果,满足模型轻量化和模型检测精度的平衡。可以观察在使用MobileNetv2与ShuffleNetv1作为模型的主干特征提取网络时,模型的检测精度与采用Shuf‐fleNetv2相近,但模型参数量却较大。在ShuffleNetv2中每个基本单元开始前都采用了“Channel Split”,将输入特征通道c分离成c-c'和c',其中一个分支直接保留通道信息,另一分支经过三个输入和输出通道相同的卷积操作其中只使用一个分组卷积操作。将特征通道分割两个部分有利于网络的并行提升运行速度,使用输入与输出通道相同的卷积和减少使用分组卷积有利于减少模型参数量。最后通过“Channel Shuffle”实现通道之间的特征交互,达到提高模型精度的目的。因此使用ShuffleNetv2作为轻量级目标检测模型的主干特征提取网络是较优的选择。 将Transformer注意力颈部(TAN)与最先进的多尺度特征融合模块进行比较,包括feature pyramid net‐work(FPN)[24],PANet[25]中的bottom-up path aggregat(BPA),和bi-direction feature interaction(BFI)[26]。在保持该基准模型其他模块不变的情况下,将目标检测模型的多尺度特征融合模型分别替换为上述模块,在自制工作安全帽数据集上评估效果。使用标准平均精度mAP、AP50、AP75、APS、APM、APL来评估对比模型的性能,结果如表3所示。 表3 不同多尺度特征融合方法对比Table 3 Comparison of different multi-scale feature fusion methods 单位:% 如表3所示,在使用TAN作为目标检测模型的特征融合模块,比使用传统的特征金字塔(FPN)的平均精度提升了1.4个百分点。Transformer注意力颈部先将不同尺度的特征图信息进行聚合,同时通过多头注意力机制充分利用跨空间和尺度的特征相互作用,增强对检测目标的注意力。TAN整体对大目标的检测效果较好。可以观察到表3中各模型针对面积小于322的小目标检测效果不佳,其中32是为图像的像素数量。一部分原因是因为在自制的工作服安全帽数据集中面积小于322的小目标所标注的训练样本不足,所占比例太少,因此模型对此类目标拟合效果较差。但使用TAN模块还是能小范围地提升对小目标的检测精度。 为了评估质量焦点损失(quality focal loss,QFL)的使用是否在工作服安全帽检测任务上有效。将分类预测分数和检测框的质量预测分数联合表示与单独分支或隐式分支对应部分进行比较。实验中采用了两种表示检测框定位质量的代替方法:IoU[27]和centerness[15]。从4个对比维度,在构建目标检测模型中进行实验,自制的工作服安全帽数据集上实验结果如表4所示。 表4 不同目标检测模型预测头部对比Table 4 Comparison of different target detection models for predicting head 单位:% 根据表4中的结果所示,使用分类预测分数和检测框的质量预测分数联合表示的损失函数QFL,相比其他所有对应项可以获得更好的性能。同时,使用IoU做为检测框定位质量的衡量标准的效果要优于使用中心点做为检测框定位质量的衡量标准。其中表5所示,表明β=2是损失函数最优的调节参数。通过将模型的预测分类分数和IoU分数分支与本文的联合表示分支进行对比。表明使用QFL训练的联合表示由于其可靠的定位质量估计而更有利于检测,并且在分类分数和检测框质量分数之间表现出强相关性。因为本文模型预测的分类分数与检测框质量分数相等。 表5 调节因子超参数对比Table 5 Comparison of hyperparameters of regulating factors 单位:% 最后将本文的模型与现有表现性能最好的几个轻量级目标检测模型在自制的工作服安全帽检测数据集上进行对比实验。分别在精确度、模型的输入尺寸和FPS三个维度对比,如表6所示。 表6 不同轻量级目标检测模型对比Table 6 Comparison of different lightweight object detection models 通过在自制的工作服安全帽数据集上对比效果发现,本文设计的模型在320×320尺寸的输入图像达到的mAP为44.6%以及117 FPS,在输入图像为416×416达到的mAP为45.1%和93 FPS,综合考虑,本文的模型结构可以达到目标检测的速度与精度上的更好平衡。将本文的检测模型在变电站场景内对人员安全措施佩戴情况进行识别,如图6所示,轻量级目标检测模型可以准确将人员的工作服穿着以及安全帽佩戴情况准确地检测出,但也有对远距离小目标存在漏检的不足。 图6 变电站实地场景检测效果Fig.6 Substation field scene detection effect 本文通过将轻量级特征提取网络ShuffleNetv2、Transformer注意力特融合模块和质量焦点损失函数(QFL)相结合,构成一种轻量级的目标检测网络,运用在变电站场景中巡检人员工作服安全帽佩戴情况。通过使用Transformer注意力特融合模块在降低模型复杂度的情况下,融合多尺度特征信息,提取目标注意力,保证精度的提升,使用QFL在不改变模型参数量的情况下,解决单阶段检测模型训练与测试中不一致问题,改善了训练效果,提升了模型精度。同时制作了工作服安全帽相关数据集,将提出的模型在该数据集上实验验证。实验结果表明,提出的轻量级目标检测模型,在自制的工作服安全帽佩戴数据集中mAP值都得到提升且较为稳定,FPS值可以达到117。该算法训练出的模型在变电站人员安全措施佩戴检测上更具有使用价值。未来将继续研究网络结构的调整,使模型的精度进一步提高。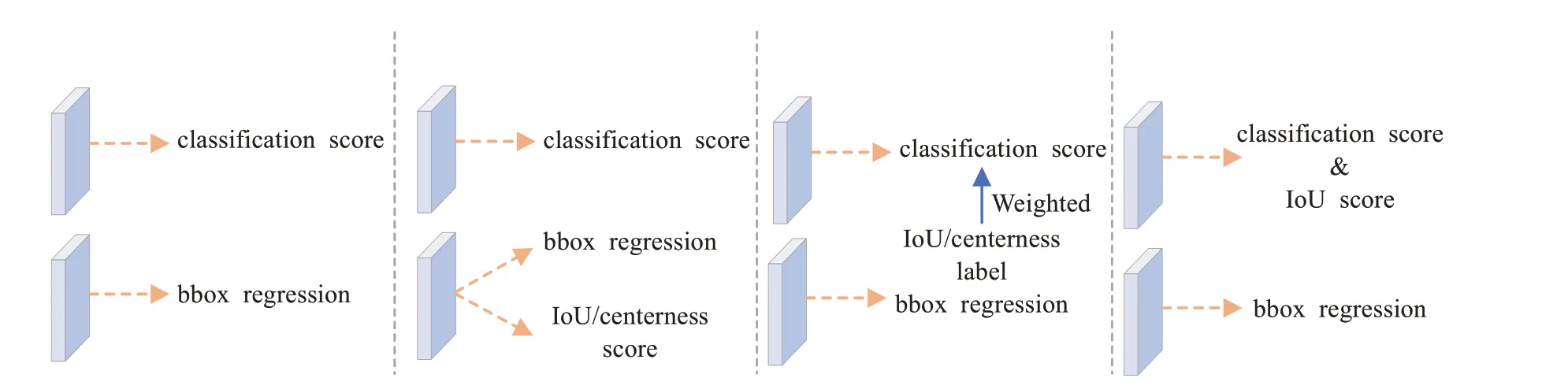
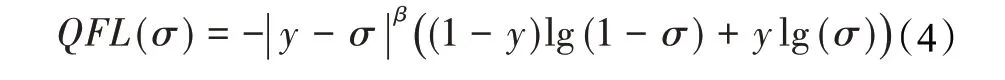
2 实验
2.1 数据集构建

2.2 评价指标

2.3 模型训练细节
2.4 消融实验与分析



3 结束语
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
电子制作(2018年11期)2018-08-04 03:25:38
电子制作(2018年8期)2018-06-26 06:43:34
电子制作(2017年8期)2017-06-05 09:36:15
现代工业经济和信息化(2016年5期)2016-05-17 05:35:57
测绘科学与工程(2016年5期)2016-04-17 06:51:15
河南电力(2015年5期)2015-06-08 06:01:45
电子设计工程(2015年3期)2015-02-27 12:03:45
河南科技(2014年14期)2014-02-27 14:11:53
