
改进Inception-Resnet-V2网络的无人机航向识别
2022-12-22 11:48:00田文斌郑腾龙
计算机工程与应用 2022年24期
成 怡,田文斌,郑腾龙
1.天津工业大学 控制科学与工程学院,天津 300387
2.天津工业大学 天津市电气装备智能控制重点实验室,天津 300387
我国电力供电系统中,电力输送主要由高压架空输电方式实现。高压架空线路由大型基杆塔搭建,基杆塔与线路的巡检是保障高压输电网络安全运行的基本技术保证。输电线路所处地形一般复杂、恶劣,人工巡检时存在安全风险、效率低下等诸多不利因素。因此,无人机逐渐成为电力巡检的主力军[1]。无人机在目前电力巡检工作时,普遍采用人工遥控方式巡检,在某些复杂恶劣的地形情况下难以避障,且人工操作巡检时,不稳定因素较多、危险性高,容易导致巡检过程中无人机与基杆塔发生碰撞或电击穿,为此,基于图像处理的深度学习智能无人机在避障与航向识别方面的研究越来越受到重视[2]。
在深度学习的图像识别与检测领域,Inception-Resnet-V2网络结构优秀、精度较高,被国内外学者广泛研究和应用。北京科技大学邓能辉等[3]在表面缺陷检测的研究中,用Inception-Resnet-V2模型进行迁移学习,提出的检测方法在中厚板表面常见缺陷实现了大于98%的检出率,平均识别率也大于88%。南京农业大学袁培森等[4]利用Inception-Resnet-V2网络的特征提取能力,结合双线性回合操作,开发了基于Flask框架的在线菌类识别系统,实现了较高精度的细粒度菌类表型在线识别。复旦大学王云军等[5]在一次大规模的初步研究中,使用深度卷积神经网络通过组织病理学对甲状腺肿瘤进行多分类。其中Inception-Resnet-V2网络模型可以达到94.42%的平均诊断准确率。华北电力大学朱有产等[6]在一种基于改进的NIC算法的图像字幕生成研究中,利用Inception-Resnet-V2网络更好的特征提取能力和避免网络深化所造成的性能退化的特点,改进后的算法具有良好的图像描述生成效果。
Inception-Resnet-V2网络虽然图像识别精度较高,但网络参数、计算量较大、实时性较差。而无人机在复杂环境下进行电力巡检作业的过程中,避障和航向预测功能对图像识别的精度、时效性都有较高的要求。因此,本文引入深度可分离卷积,研究并优化了Inception-Resnet-V2网络,改进后的网络保证了在对基杆塔图像识别精度基本不变的情况下降低了计算量。在实际电力巡检实验中,验证了提出的无人机航向识别方法的有效性。
1 Inception-Resnet-V2网络结构及其改进
Inception网络[7]通过将稀疏矩阵聚类成相对密集的子矩阵来提高计算性能。使用1×1的卷积把相关性高、同一空间位置不同通道的特征连接在一起,构建出符合Hebbian原理的高效稀疏网络结构[8-9]。
结构更深的网络往往有更好的表现,但普遍存在梯度弥散的问题,且网络结构的参数与计算量较大,消耗计算成本并不利于模型在集成芯片上的搭载。Google提出在Inception模块中加入残差结构的Inception-Resnet-V2网络[10],充分利用了Resnet网络结构恒等映射的特性,提高了网络的精度并解决了网络退化和梯度消失的问题[11],因此可以拓展成更深的模型。为保证网络模型的优越性并进一步降低网络的计算复杂度,本文基于可分离卷积核的卷积形式,引用三层Resnet卷积模块的卷积结构,对Inception-Resnet-V2网络结构中Stem、Inception-Resnet-A、Reduction的各网络模块3×3的卷积层进行卷积核和卷积结构的改进。
当网络结构中的3×3卷积核进行卷积运算时,对应图像区域内的所有通道同时参与运算。深度可分卷积对不同的输入通道采用不同的卷积核,通过先深度卷积后逐点卷积的方法降低了计算复杂度[12]。Inception-Resnet-A模块的部分3×3卷积输入尺寸为h×w×c,卷积层有k个3×3卷积核,输出为h×w×k。计算量为h×w×k×3×3,参数量为c×3×3×k。本文将3×3卷积核改进为深度可分离卷积核,将普通卷积操作分解为深度卷积和逐点卷积两个过程[13],将Inception-Resnet-V2网络结构中3×3卷积层的计算量压缩为:
改进后的卷积模块如图1所示。在可分离卷积核卷积操作之前,使用1×1的卷积核将该卷积层输入进行降维,可分离卷积操作后再次使用1×1的卷积核还原维度,优化了时间复杂度和空间复杂度,并进一步减少计算成本、加深网络结构。

图1 改进后卷积结构Fig.1 Improved convolution
本文的提出的卷积层计算量压缩为:
本文用提出的卷积层代替了Inception-Resnet-V2网络中Inception-Resnet-A模块的3×3卷积层,并在Resnet-A模块中,通过添加layer-add,将layer2中改进3×3卷积层卷积后的特征进行融合,增加图像特征下的信息量,再进行layer3改进3×3卷积层的卷积操作,加深网络结构、减小计算量,从而有利于网络模型的识别效果。
2 改进网络的性能测试与分析
为验证改进后的Inception-Resnet-V2网络模型的特性,本文选取VGG的Fine-Grain Recognition Datasets数据集中的四个类别进行图像识别,其中每个类别由800张图片组成,验证集每个类别160张图片,测试集每个类别160张图片,共计3 200个样本。Inception-Resnet-V2网络模型定义的输入尺寸大小为299×299,故本文将数据集中的所有样本像素大小预处理为299×299。将预处理后的数据作为输入数据,训练改进的网络模型。训练网络策略中关键的参数设置及其说明,如表1所示。
表1 训练网络策略中关键的参数设置及其说明Table 1 Key parameters and instructions
训练结果如图2所示。改进后的网络在迭代次数达到一定数量时训练和验证的精度都开始大幅提升,经过多次迭代后网络最终收敛。模型在验证集上的损失值逐渐衰减,最后稳定在0.69,验证精度最终达到0.88,训练精度达到1.0。
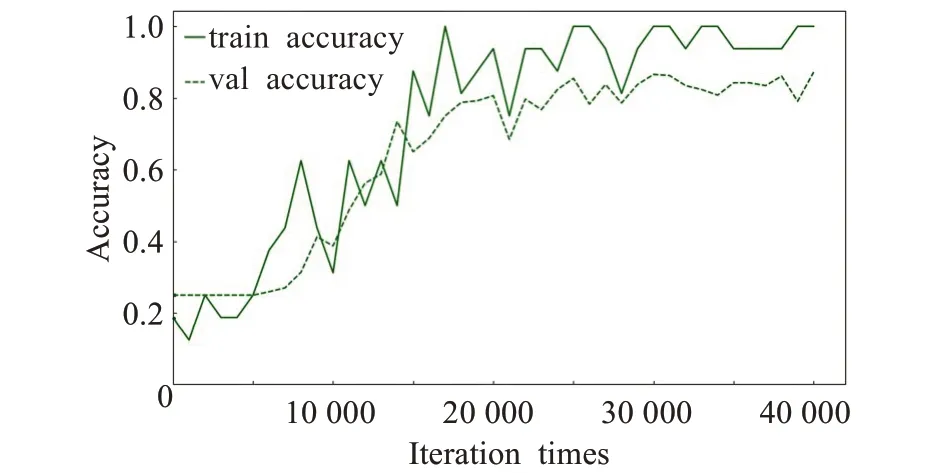
图2 改进网络模型训练结果Fig.2 Improved training results
训练后的改进Inception-Resnet-V2网络模型,在Fine-Grain Recognition Datasets测试集中的样本识别结果示例如图3、图4所示。
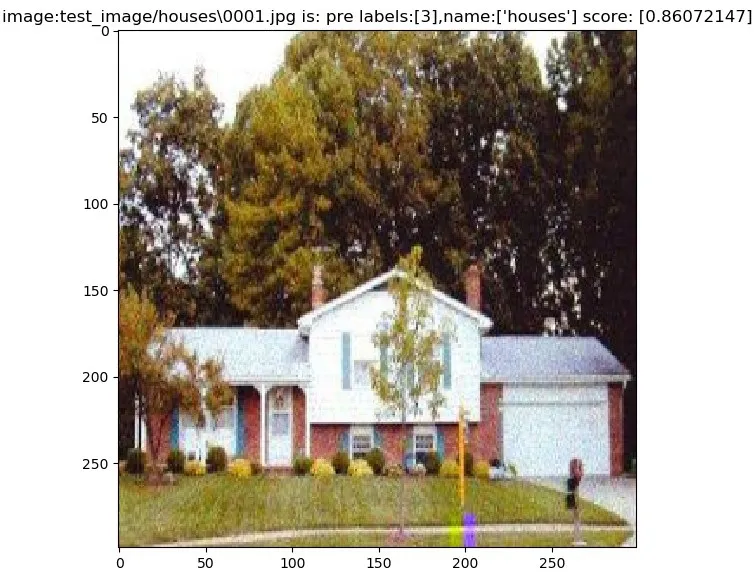
图3 对房屋样本数据的识别Fig.3 Recognition of housing sample data

图4 对雕塑样本数据的识别Fig.4 Recognition of sculpture sample data
由图3可知,改进后Inception-Resnet-V2网络模型对测试集中房屋测试样本能够准确地预测标签值,得分约为0.86。图4中改进的网络模型能正确地识别测试集中雕塑类别,预测得分约为0.99。改进后的模型对测试集其他样本类别也成功识别并获得了较高的预测得分。
为了测试与分析改进网络结构与其他网络结构的识别结果,本文采用准确率、召回率、F1_score、参数量、计算量指标对网络模型的识别性能进行分析。其中准确率为识别正确的样本数与总样本数之比,召回率的公式为:

其中,TP表示预测为正且判断正确,FP表示预测为负且判断错误。
F1_score是模型精确率和召回率的一种加权平均数,F1_score的计算公式为:

其中,FN表示预测为负且判断错误。本文选取Alexnet[14]、VGG[15]、Inception-V4、Inception-Resnet-V2、X-ception[16]网络与改进后的Inception-Resnet-V2网络进行对比。在同一数据集下,各网络模型的性能评价结果如表2所示。
在表2中,改进的Inception-Resnet-V2网络模型在测试集中准确率为92.50%,召回率达到92.52%,F1_score达到了92.51%,综合性能做到了平衡。改进后的网络模型精度高于Alexnet、VGG等经典网络模型的精度,与X-ception网络模型精度相同,但参数量与计算量得到了进一步降低且具有其优良的网络结构。与Inception-Resnet-V2网络模型相比,在保证达到92%以上高精度的同时,只损失了3个百分点的精度,却降低了参数量和计算量。故对比本文所选的其他经典网络模型,改进的Inception-Resnet-V2网络模型能够在保证较高精确度与优越网络结构的同时,减少网络模型的参数量与计算量,提高时效性。
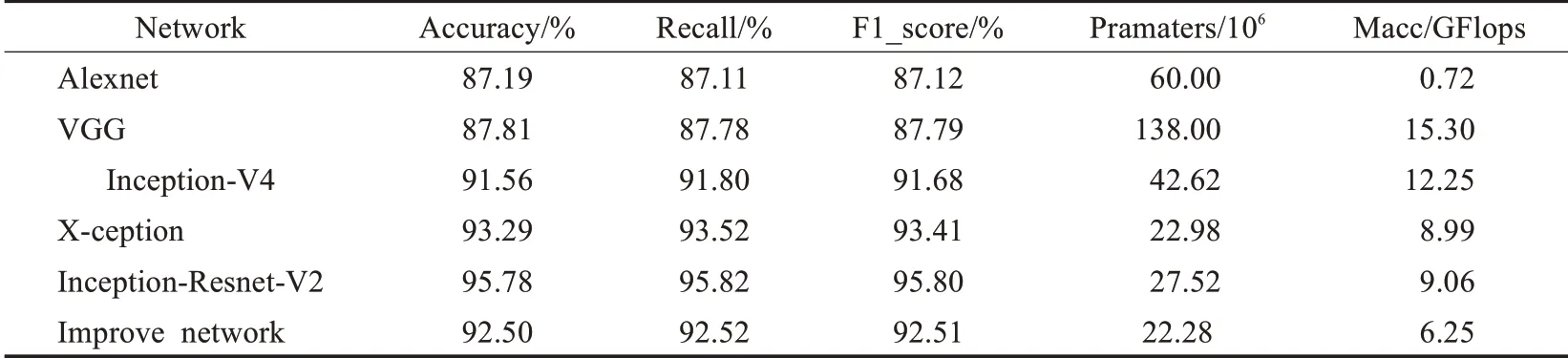
表2 改进Inception-Resnet-V2与其他网络模型的对比Table 2 Comparison of performance between improved network and other network models
Inception-Resnet-V2网络模型的计算总量为9.06 GFlops,参数总量为2.752×107。改进后的网络模型的计算总量为6.25 GFlops,参数总量为2.228×107。改进后的网络模型stem模块中的参数总量约为1.2×105,而Inception-Resnet-A、Reduction-A和Reduction-B模块的参数总量分别约为3.4×104、5.3×105和1.42×106。在Incepon-Resnet-V2网络中,stem模块中的参数总量约为6.0×105,Inception-Resnet-A、Reduction-A和Reduction-B模块的参数总量分别约为8.8×104、2.9×106和3.54×106。改进后网络模型和原网络各组成模块的参数量对比如图5所示,改进后的网络模型在stem层、Inception-Resnet-A以及Reduction-A、B层的参数量明显降低。
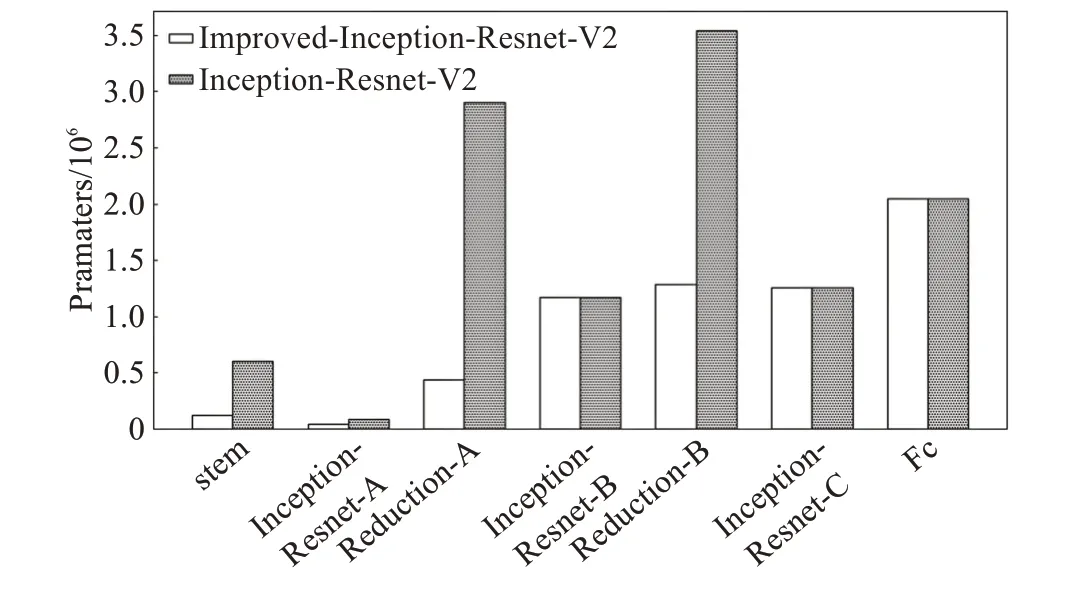
图5 改进网络模型与原网络各模块参数量的对比Fig.5 Comparison of parameters between improved network and original network
改进后网络模型各模块的卷积计算量如表3所示。综合网络的识别精度与计算复杂度,改进后的网络模型与其他网络模型相比得到了有效的提升。

表3 改进Inception-Resnet-V2网络模型各模块的卷积计算量Table 3 Convolutional computation for each module of improved Inception-Resnet-V2 network
为直观地展现改进后网络模型的优越性,绘制了Improved Inception-Resnet-V2网络 与VGG网络基于测试集实验结果的ROC曲线。该曲线根据网络模型的预测结果,从阈值选取的角度评价网络模型的泛化性能与精度。ROC曲线的纵轴是真正例率TPR,是指正确预测为正例的样本占所有正例的比例。横轴是假正例率FPR,是指错误预测为正例的样本占所有负例的比例。两者分别定义为:

ROC曲线将真正例率和假正例率以图示方法结合在一起,可准确反映改进Inception-Resnet-V2真正例率和假正例率的关系,是检测网络模型准确性的综合代表。通过该曲线可以简单、直观地分析网络模型的准确性。本文将测试集中各样本数据的预测得分值,从小到大依次排列作为阈值,计算FPR、TPR并绘制了各类别的ROC曲线,如图6、图7所示。
由图6、图7所示的ROC曲线分析可知,在同一测试集下,改进的Inception-Resnet-V2网络对应于测试集中各类别的ROC曲线,比VGG网络对应类别的ROC曲线,更靠近坐标系的左上角,这一特性表明了改进的Inception-Resnet-V2网络比VGG网络有更高的准确性。综上可知,改进后的Inception-Resnet-V2网络在参数量与MACC计算总量缩减的同时仍具有较好的识别效果。
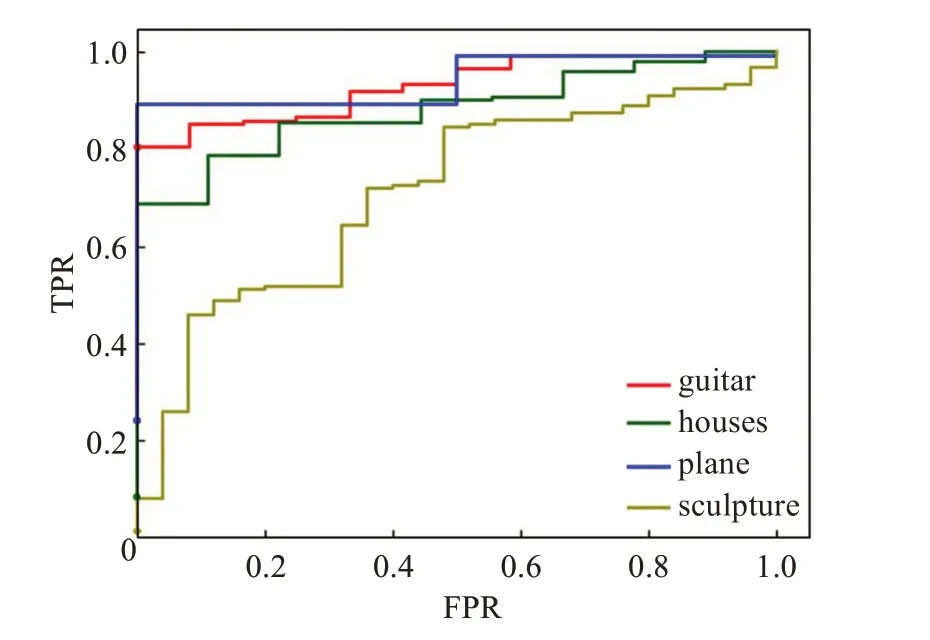
图6 改进的Inception-Resnet-V2的ROC曲线Fig.6 ROC curve of improved Inception-Resnet-V2

图7 VGG网络模型的ROC曲线Fig.7 ROC curve of VGG network model
3 改进网络在电力巡检航向识别中的应用
为验证无人机搭载改进后网络模型进行实际电力巡检时航向识别的效果,本文采用大疆无人机M210RTK进行实验。实验的操作环境为64位Windows7操作系统、GTX 1080Ti GPU、Pycharm2018、MagicEXIFv1.08、Visual Studio2017。
首先对复杂环境下的基塔图像进行采集,对其预处理并制作数据集。数据集共有1 600个样本,其中包含训练集1 280个样本、验证集160个样本、测试集160个样本。使用MagicEXIF元数据编辑器分析样本图像,得到训练集中每个样本图像数据标题的标签值,从而获得位置信息。无人机航向下行偏移量、左下偏移量、左偏移量、左上偏移量、右下偏移量、右偏移量、右上偏移量、上升偏移量的标值分别设置为0~7。测试集中左右标题的样本图像如图8、图9所示。

图8 无人机左偏移航向数据集样本Fig.8 Sample of left offset heading dataset

图9 无人机右偏移航向数据集样本Fig.9 Sample of right offset heading dataset
为了直观地体现出改进卷积结构的效果,将改进后的卷积层卷积操作后得到的特征图可视化。图8、图9所示的样本图像分别被改进后Inception-Resnet-V2网络的Stem层第一层3×3的卷积层卷积操作后,得到的特征图如图10、图11所示。可见输出特征图的纹理、细节特征都很清晰,便于后续深层网络的卷积运算。

图10 图8的特征图Fig.10 Feature map of Fig.8

图11 图9的特征图Fig.11 Feature map of Fig.9
无人机搭载训练后的网络,在对有方向标签的图像进行识别后,输出的航向预测结果如图12、图13所示。其中图8的测试样本实际方向为左偏移航向,图12中对应的预测结果标签值为2,航向为Left,预测概率约为0.99。图9中实际方向是右偏移航向,图11中对应的预测结果的标签值为5,航向为Right,预测概率约为0.99,准确预测了无人机的航向。测试集中其他样本也具有较高精度的预测结果,可见本文提出的方法能使无人机在复杂环境下电力巡检时高精度的识别出基杆塔,并且以较高预测分数进行航向识别。
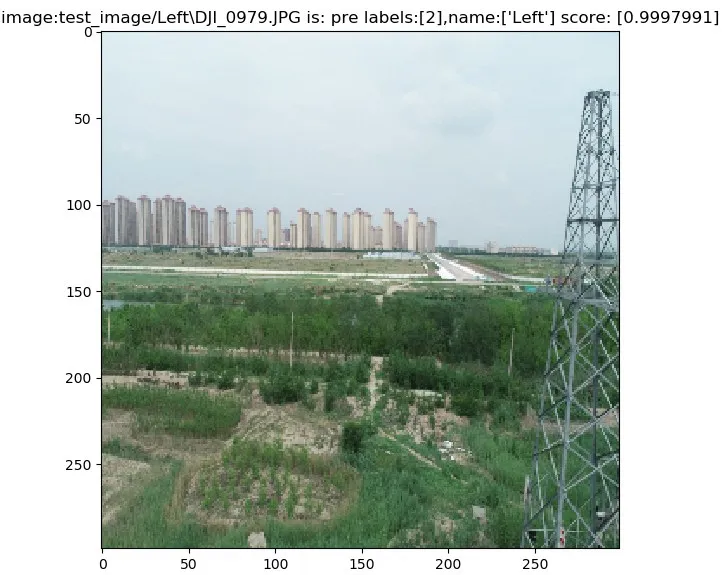
图12 左偏移航向数据集样本的预测结果Fig.12 Prediction results for offset heading dataset sample

图13 右偏移航向数据集样本的预测结果Fig.13 Prediction results for right offset heading dataset sample
将测试集的预测结果用混淆矩阵表示,图像横轴为航向的预测结果,纵轴为真实的航向,其中0~7分别表示8个方向的标签值,分别为垂直下降、左下偏移、左下偏移、左上偏移、右下偏移、右上偏移和垂直上升。在混淆矩阵中,正确的预测结果都在对角线上,预测错误的数据量呈现在对角线外面。当混淆矩阵的预测结果大量集中于混淆矩阵的对角线时,航向识别的预测结果较好。
针对不同的航向,本文共进行20次无人机实验。航向预测的混淆矩阵如图14所示,图中右侧为样本数量与混淆矩阵色图颜色对应示意,样本最大值20对应图中最深颜色,样本最小值0对应图中最浅颜色。其中,对下左偏移量、左偏移量、右偏移量、垂直上升量的样本数据进行了正确预测。对于垂直下降、左上偏移和右下偏移的样本数据,每类中有两个样本数据的预测是错误的,左上偏移航向中的一个样本数据的预测是错误的。
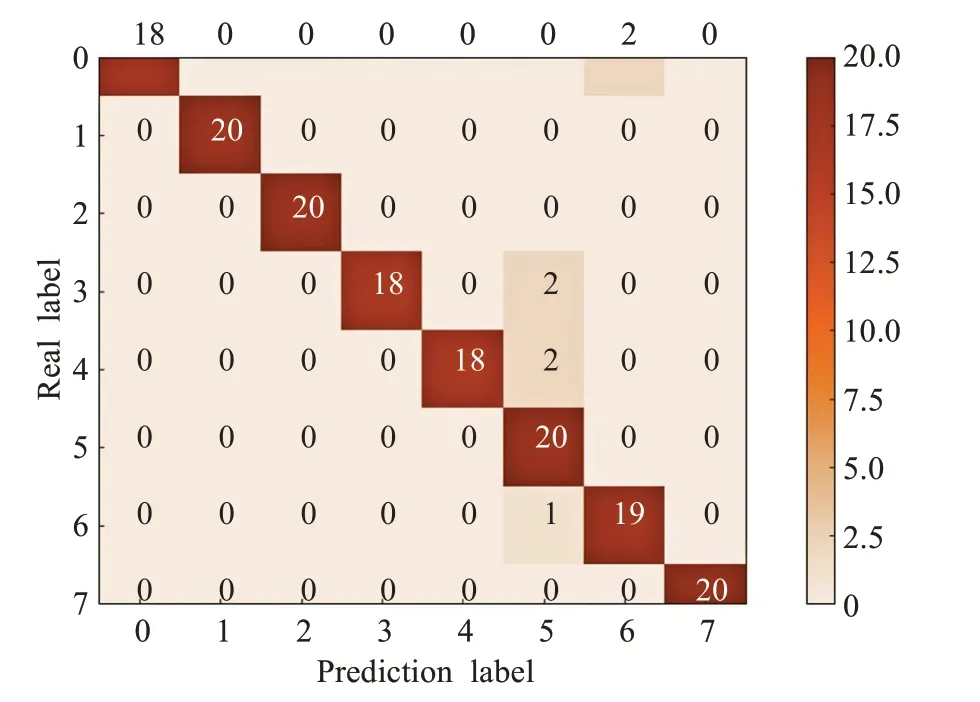
图14 测试集的预测结果混淆矩阵Fig.14 Confusion matrix of test set prediction results
对混淆矩阵进行分析可得各航向的精度,如图15所示。各航向的预测准确率都较高,其中最高预测准确率为100%,最低预测准确率为90%。在实际飞行实验中,共对160幅样本图像进行预测,其中正确预测了153幅图像,平均预测准确率为95.63%,召回率为96.31%。
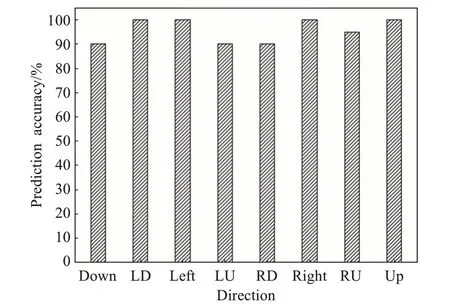
图15 各航向的预测精度Fig.15 Prediction accuracy of each heading
因此,改进后的Inception-Resnet-V2网络模型在实际复杂的环境下进行电力巡检时,可以高精度地识别基杆塔并能够较好地预测无人机的飞行航向。在实际应用中表明,改进的网络模型不仅具有Inception优秀的网络结构,而且能够较好地兼顾航向识别精度与实时性。
4 结论
本文基于Inception-Resnet-V2网络,引入深度可分离卷积,对其结构中Stem层以及各网络模块中3×3卷积层进行改进。优化了Inception-Resnet-V2网络结构,降低了参数量与计算量,在保持网络模型对图像高精度识别的同时提高了运行的实时性。通过在标准数据集上与其他同类网络的性能进行对比,取得了明显的优势。在实际复杂环境下电力巡检的实验中能够准确识别基杆塔,依据识别后的图像信息还原位置信息从而预测出无人机航向,预测精度高达95.63%。因此,本文提出的基于改进Inception-Resnet-V2网络的无人机航向识别方法具有实际应用价值。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
新世纪智能(高一语文)(2021年3期)2021-07-16 08:30:16
电子制作(2019年11期)2019-07-04 00:34:38
民用飞机设计与研究(2019年4期)2019-05-21 07:21:26
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子制作(2017年24期)2017-02-02 07:14:16
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
