
基于BERT-CRF与对抗训练的水利领域命名实体识别
2022-12-20 02:17:26顾乾晖徐力晨涂振宇黄逸翠
南昌工程学院学报 2022年3期
顾乾晖,徐力晨,涂振宇,黄逸翠
(南昌工程学院 信息工程学院,江西 南昌 330099)
近几年来,随着高性能处理器、大数据技术和人工智能技术的蓬勃发展,信息化技术被广泛应用于水利领域。当今各地水利部门着手建立水利信息综合平台,每天都有来自不同的地域、不同类别的水利信息在全国各地产生,这些海量的数据最后都会汇总至水利信息库中。因此水利信息库中虽然有结构化数据,但还有大量的非结构化数据,比如各种水利相关的文档、行政函、报表、文献等。由于非结构化的水利信息数据具有复杂化、非结构化、跨领域化、海量化等特点,这使得对水利文本信息进行挖掘变得十分困难。如何从海量的水利文本中提取出水利的主题信息是亟需解决的问题。
命名实体识别(Named Entity Recognition,NER)是自然语言处理(Natural Language Processing,NLP)重要的组成部分,它的核心任务是自动提取出有特定意义的实体,如人名、地名、组织机构等[1]。
传统的命名实体识别方法为两类,第一类是利用词典和规则的方法,这种方法主要通过人工制定规则模板,但是这种方法不仅费时费力,而且具有主观性过强,易产生误差,可移植性差等特点[2]。第二类是基于统计学习的方法,如俞鸿魁[3]等人利用层叠隐马尔可夫模型对实体进行识别,在汉语分词大赛中取得了良好的成绩。何炎祥和罗楚威[4]等人利用CRF和实体规则相结合建立了地理信息实体的识别模型,有效提高了识别准确率。但是基于统计学习的方法在特征选择和实体标注上仍需要专业领域的人员进行繁琐的手动操作,效率低;另外,基于统计学习的识别效果依赖特征选择,主观性较强。
近几年来,以神经网络模型为代表的深度学习技术得到了空前发展,这大力促进了自然语言处理领域的进步。由于深度学习的方法具有较强的泛化能力,自动寻找潜在的特征模板集合,不需要复杂的特征工程等特点,这使得深度学习方法成为命名实体识别领域的主流。Lample[5]等人于2016年提出了双向长短时记忆神经网络(Bidirectional Long-Short TERM,BiLSTM)与条件随机场(Conditional random field,CRF)结合组成BiLSTM-CRF模型,有效提高了识别效果。李丽双[6]等人通过加入CNN特征选择机制的BiLSTM-CRF模型对生物医学命名实体进行识别。李韧和李童等人[7]利用Transformer编码器进行特征处理,再与BiLSTM-CRF结合对桥梁检测领域命名实体进行识别,实验结果发现能有效提高模型识别能力。以上这些深度学习技术虽然在NER任务上取得不错的效果,但无法解决一词多义问题。
谷歌团队的Devlin[8]等人在2018年提出了基于双向Transformer结构的BERT预训练模型,BERT模型不仅可以增强语义表示,还可以根据上下文生成相关的字向量,能够很好解决一词多义的问题。王子牛[9]等人提出了BERT-CRF命名实体方法,在人民日报数据集上取得了很好的效果。李妮[10]等人提出了基于BERT-IDCNN-CRF的中文命名实体识别方法,实验表明,该模型在MSRA语料上表现出很好的效果。但在实际中文命名实体识别的训练过程中,文本标注是一项繁琐的过程,由于标注者在标注过程中难免遇到一些失误,出现漏标、错标等状况,会造成训练时出现过拟合现象。
对抗性训练是一种通过加入噪声,来提高模型的泛化能力和鲁棒性的训练方式。在自然语言处理任务中,对抗训练通常在embedding层中加入对抗扰动,这能有效提高语言模型的泛化能力[11]。因此本文提出一种利用FreeLB对抗训练模型结合BERT-CRF语言模型的面向水利领域的命名实体识别方法,即FreeLB-BERT-CRF模型。
1 FreeLB-BERT-CRF模型结构
1.1 模型概述
本文提出的FreeLB-BERT-CRF模型结构如图1所示。该模型主要由由FreeLB对抗训练模块、BERT嵌入层模块、BERT的Transformer模块、CRF模块这4部分组成。
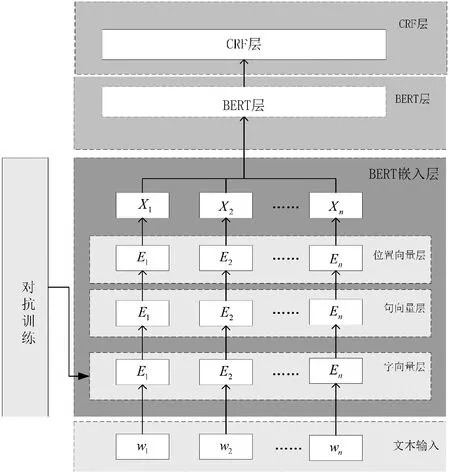
图1 FreeLB-BERT-CRF结构图
1.2 BERT模型
BERT模型是一种语言预训练模型,它的主要任务是通过大量的无标注数据进行自监督训练,从而获得字向量的语义表示。
BERT模型的输入如图2所示,输入文本的字符通过BERT嵌入层转换成字向量形式。BERT的嵌入层由字向量层、句向量层、位置向量层混叠而成,其中位置向量层是将字符的位置信息转换成位置向量,句向量层是用以区别是否为一种句子。
输入文本通过BERT嵌入层表示成字编码向量(E1,E2,…,En),同时(E1,E2,…,En)作为BERT模型的输入向量,并在大规模训练后输出(T1,T2,…,Tn),如图3所示。
BERT最核心的部分是双向Transformer编码器,由于Transformer不含RNN和CNN网络结构,只含有注意力机制,所以BERT模型能够利用注意力机制充分融合字的上下两边的信息,从而得到更好的表征形式。如图4所示,每一个Transformer编码单元包含多头注意力机层(Self-Attention)、全连接层(FeedForward)、残差链接和归一化层(Add&Normal)。其中自注意力机制是Transformer中最重要的部分,自注意力机制主要作用是计算出文本中字与字之间的关联程度,并根据关联程度调整每个字的权重,关联程度计算方法的见式(1):
(1)
式中Q表示查询向量;K表示建向量;V表示值向量;dk表示缩放因子。
1.3 CRF模型
BERT模型只考虑字上下文的关系,无法考虑各标签间的依赖关系,而条件随机场[11](CRF)能够提取标签之间的约束关系来确保输出是最合理的标签序列,因此本文通过CRF进行标签序列建模。
CRF给定输入序列x=(x1,x2,x3,…,xn)和对应的标签序列y=(y1,y2,y3,…,yn),定义评估分数计算公式如式(2)所示:
(2)
其中A表示转换矩阵;Ai,j表示标签转移分数;Pi,yi表示该字符第yi标签的分数;标签序列y对应的预测概率可表示式(3):
(3)
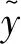

图2 BERT嵌入层
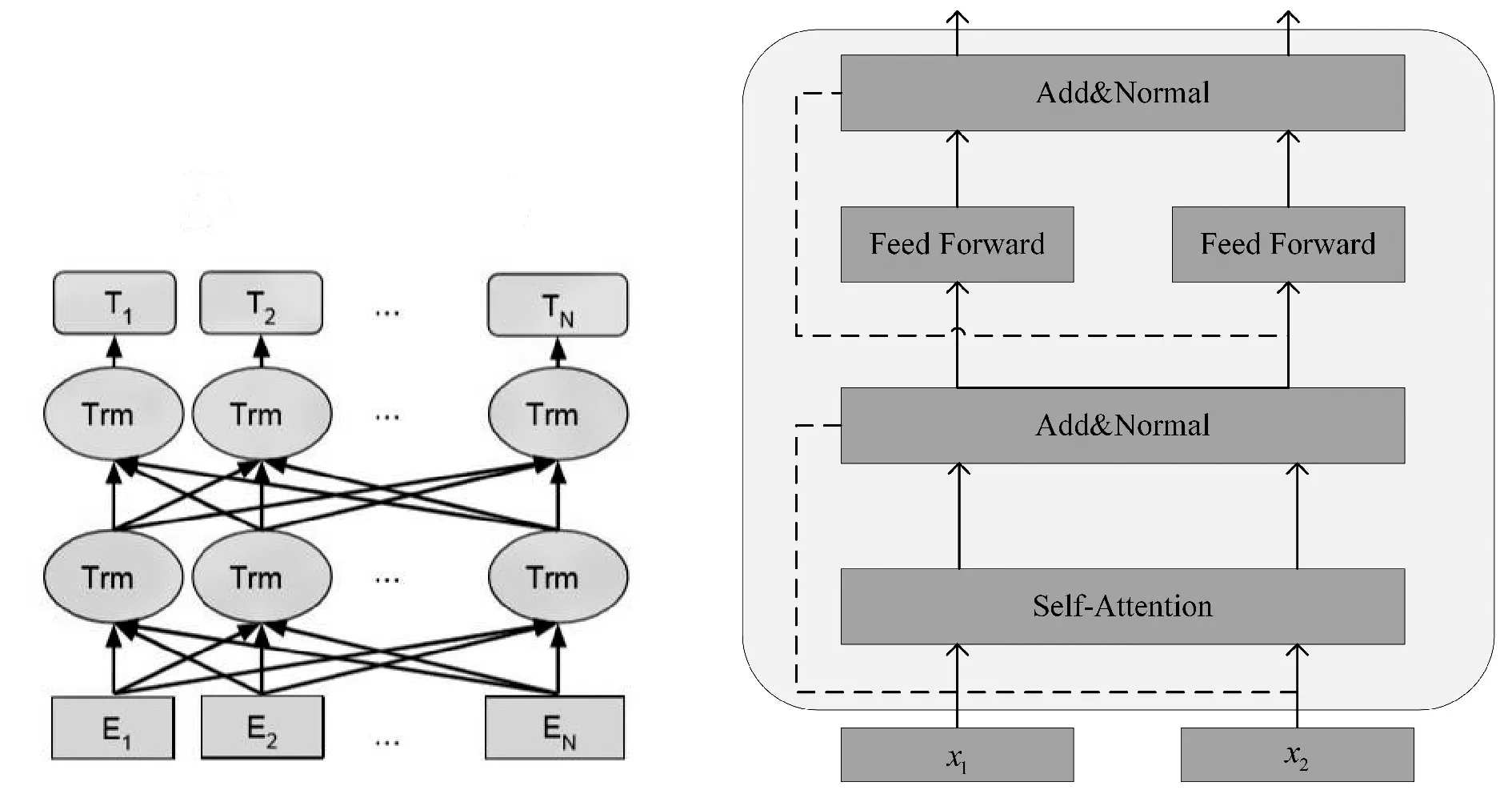
图3 BERT预训练模型结构 图4 Transformer编码单元
1.4 FreeLB
在自然语言处理任务(NLP)中,大部分对抗训练通过对BERT等预训练模型中的Embedding层增加扰动,来提高模型的泛化能力和鲁棒性。
FreeLB模型是由Zhu C[12]等人在2019年提出的一种面向自然语言处理的新型对抗训练模型。相对于其他的对抗训练模型FGM[13]、FGSM[14]、PFD[15]、YOPO[16],经过FreeLB对抗训练出的NLP模型具有更强的鲁棒性和泛化能力。
FreeLB模型采用梯度上升的方法对语言模型嵌入层中的字向量层进行扰动,而位置向量层和句向量层保持不变,公式可表示为
(4)
式中y表示语言模型的输出;V表示嵌入矩阵(列如BERT模型中的BERT嵌入层);θ语言模型所有可能的参数;Z表示文本的字序列;δ表示对抗性扰动,为了保持语义,通常把δ值设置很小。
FreeLB模型在对抗训练过程中,进行了多次迭代,在每次迭代过程中不断积累梯度,见式(5)。然后在每一次迭代中通过积累的梯度在模型更新噪声扰动δ,见式(6)。最后完成迭代同时,利用已积累的梯度更新模型参数θ,见式(7)。

(5)
gadv=∇δL(fθ(X+δt-1),y),
δt=∏(δt-1+α·gadv/||gadv||F),
(6)
θ=θ-τgK.
(7)
2 实验分析
2.1 实验数据
本文通过网络爬虫技术,对百度百科、知网文献、百度文库以及各大水利相关新闻网站爬取水利文本来构建水利领域语料库,对BERT-CRF模型进行实验。语料库中一共4 300条短文本,根据水利领域专家指导,标记7种不同的水利实体类别。其中各类实体统计如表1和图5,水利领域实体类别描述见表2。
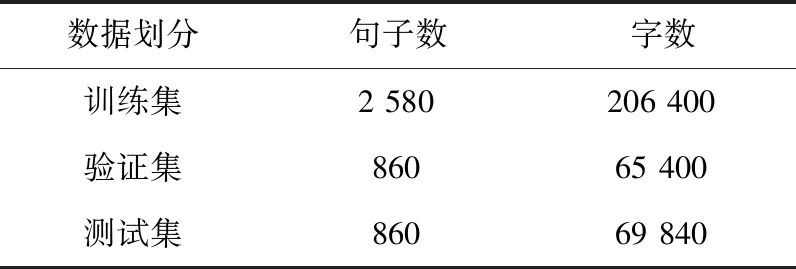
表1 水利语料数据划分

表2 水利实体类别示例
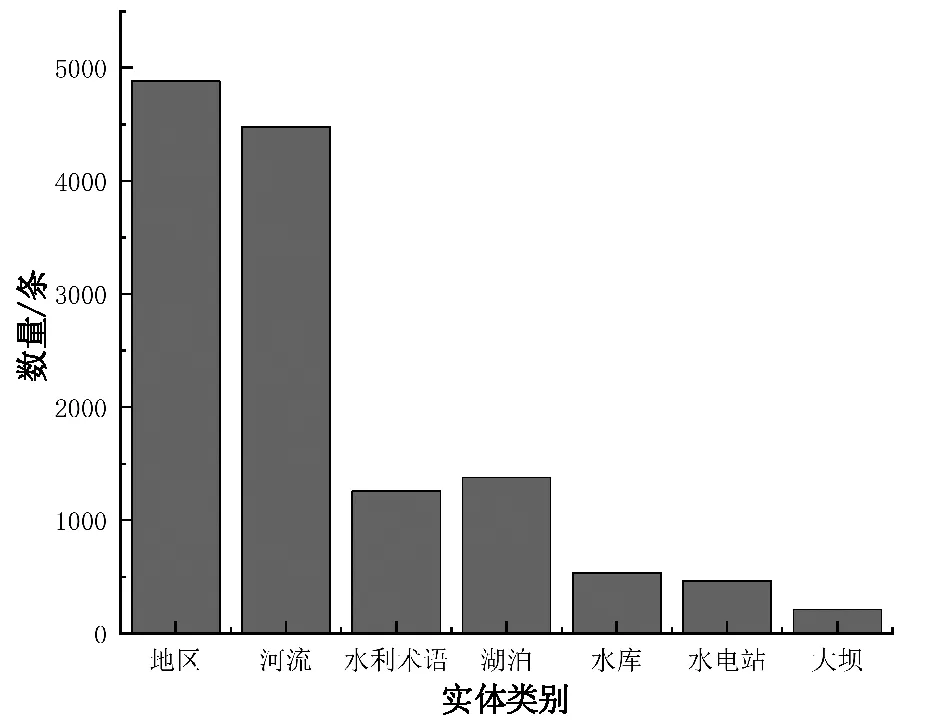
图5 实体数量
2.2 标注方法和评价指标
本文采用BIO标注策略对文本中的实体进行标签标注。命名实体识别的评价指标有精确率(P)、召回率(R)、F1-score(F1)。P表示正确识别的实体占全部识别出实体的比例,R表示正确识别的实体占应识别实体比例,F1是结合了P和R的综合评价指标。这3种评价指标公式如式(8~10)所示:
(8)
(9)
(10)
式中TP表示模型正确识别的实体个数;FP表示为模型识别错误实体的个数;FN表示模型没有识别到的实体个数。部分实体标注例子见表3。
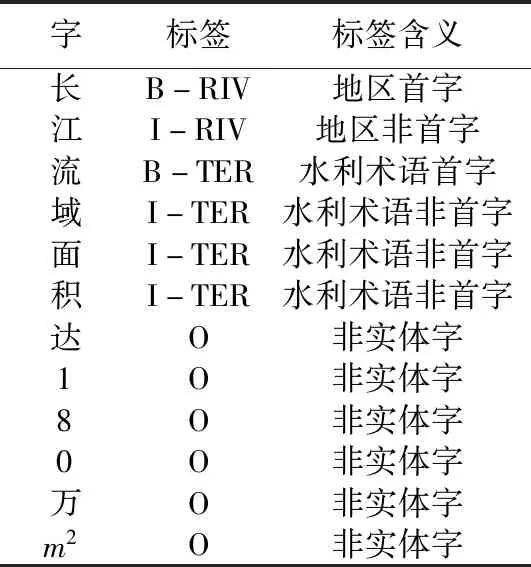
表3 水利实体标注示例
2.3 实验过程
2.3.1 实体标注
自然语言处理的大部分任务是监督学习问题。序列标注问题如中文分词、命名实体识别,分类问题如关系识别、情感分析、意图分析等,均需要标注数据进行模型训练,而标注数据就需要各种标注工具。如今,NLP领域有着许多标注工具,但是这些标注工具大多面向英文,对英文生态很友好。中文开源语料以及基于中文的标注工具就少得多,各种面向英文的自然语言模型和前沿技术都因为中文语料的匮乏很难迁移过来。
中文标注工具的出现,改变了中文在NLP领域的尴尬场面。中文文本标注工具Chinese-Annotator因为有着直观易懂的中文标注界面、友好的中文生态、简便的操作方法等特点,受到大家的欢迎。
2.3.2 模型参数
BERT模型采用BERT-Base预训练语言模型,BERT-Base共12层,768个隐藏单元,采用12头模式,BERT-Base超参数设置如表4所示。
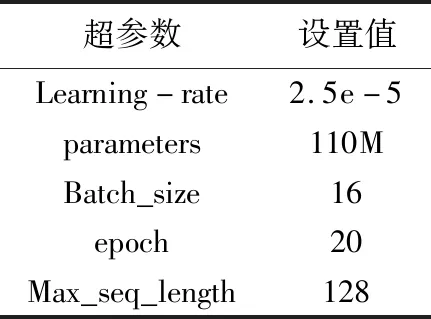
表4 BERT-Base超参数设置
为了验证本文提出的模型的有效性,实验使用了不同的语言模型对水利文本数据集进行训练。对比模型包括BiLSTM、BiLSTM-CRF、BERT、BERT-CRF、BERT-BiLSTM-CRF。
2.4 实验结果以及分析
各类模型性能对比结果如表5与图6所示。BiLSTM模型在epoch为12时得到最优F1值,为 67.7%,但是之后随着迭代次数增加,模型效果变差。BiLSTM-CRF模型在epoch为12时得到最优F1值,为68.8%,但是之后随着迭代次数增加,模型效果变差。BERT模型在epoch为7时得到最优F1值,为74.8%。BERT-CRF模型在epoch为10时得到最优F1值,为78.6%,且模型达到收敛。 BERT-BiLSTM-CRF模型在epoch为7时得到最优F1值,为80.3%,且模型达到收敛。FreeLB-BERT-CRF模型在epoch为5时得到最优F1值,为85.6%,且模型达到收敛。
FreeLB-BERT-CRF预训练模型相比其他对比模型,能够快速收敛,并在F1评价指标上取得很好的效果。BiLSTM和BiLSTM-CRF预训练模型由于以LSTM神经网络为基础,随着训练时间过长,会出现梯度消失的情况,即效果随着迭代次数的增加慢慢变差。BERT-CRF与BERT预训练模型收敛速度比FreeLB-BERT-CRF预训练模型稍慢,F1评价指标也在模型收敛后比FreeLB-BERT-CRF预训练模型稍逊。
但是在模型训练耗时上,FreeLB-BERT-CRF模型却比其他模型耗时都要长,这是由FreeLB对抗训练模型的特性导致,具体耗时见表5所示。
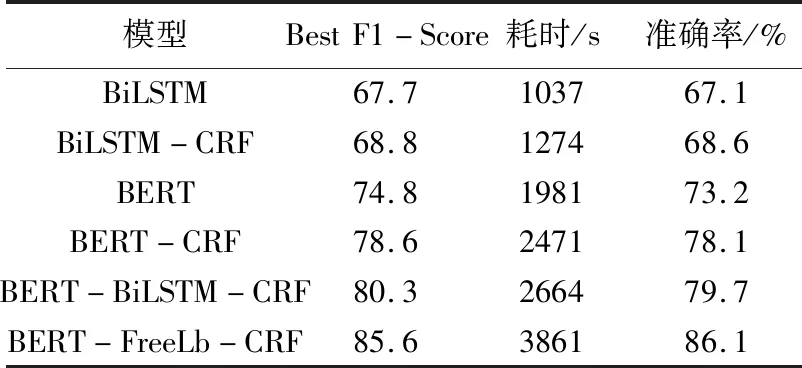
表5 各模型性能比较
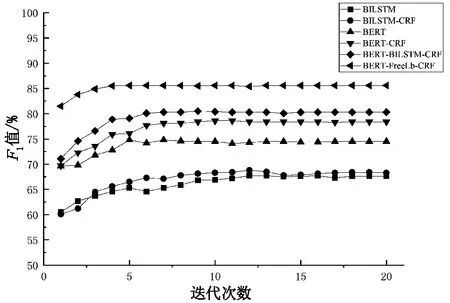
图6 各模型F1值变化
在水利文本数据集上进行不同的对比实验,各类模型性能对比如表5所示。从表5可以看出,本文提出的FreeLB-BERT-CRF模型在准确率、召回率、F1值上都比其他对比模型表现更好。
3 结论
本文针对水利领域的命名实体识别展开了研究,提出一种基于对抗训练FreeLB和BERT-CRF相结合的水利信息命名实体识别方法。该模型利用BERT模型获得水利文本的字向量表示,同时利用对抗训练模型FreeLB对BERT中的字向量层进行扰动,提升BERT语言模型的泛化能力和准确率,最后通过CRF来获得最合理的标签序列。
实验结果表明,本文FreeLB-BERT-CRF模型相对于其他对比模型,不仅在3种评价指标(P、R、F1)上都取得最优的效果,而且收敛速度快。
但是FreeLB-BERT-CRF模型由于加入了对抗训练需要大量的计算,这导致与其他模型相比训练耗时过长。因此在下一步研究中,考虑拥有large-batch的模型(RoBERTa等模型)来节省计算开销,加快训练速度。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
中国外汇(2019年18期)2019-11-25 01:41:54
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
公民与法治(2016年10期)2016-05-17 04:12:58
