
基于YOLO与轨迹关联的多目标跟踪算法
2022-12-20 02:17:28胡树宝
南昌工程学院学报 2022年3期
胡树宝,吕 莉,徐 畅,康 平
(南昌工程学院 信息工程学院,江西 南昌 330099)
随着计算机视觉技术的快速发展,作为主要研究分支的目标跟踪受到广泛关注,在智慧交通、视频监控以及人机交互等领域发挥着重要作用。根据被跟踪目标数量的不同,目标跟踪算法可分为单目标跟踪与多目标跟踪两类。从国内外跟踪领域的总体发展来看,单目标跟踪技术已经相对成熟,而多目标跟踪技术仍然具有较大的发展空间。在单目标跟踪中,一般方法是人为设定一个先验目标框,然后在后续帧中对先验框内目标位置进行预测,然而多目标跟踪过程不再只是预测单一目标位置,人为设定先验目标框的方式也无法适应多变量估计问题。目前应用于多目标跟踪任务的主流算法是基于检测的跟踪策略(tracking-by-detection,TBD)。TBD类跟踪策略利用检测器区分多目标跟踪任务的前景与背景,通过跟踪器在预测目标位置的同时,不断与检测器进行信息交流的方式,提高跟踪过程鲁棒性。例如,Dicle[1]等基于TBD策略提出The Way They Move:Tracking Multiple Targets with Similar Appearance(SMOT)算法,该算法将检测器与跟踪器融合,利用运动动力学作为线索区分外观相似的目标,最大限度地减少目标错误识别,恢复由于遮挡以及目标超出视野范围而丢失的数据,在处理遮挡问题时表现出色。Song[2]等人基于TBD策略提出Gaussian Mixture Probability Hypothesis Density(GM-PHD)算法,采用高斯混合概率假设密度处理噪声干扰,有效降低了误检率和漏检率,在处理遮挡问题和碎片现象时取得了良好的效果。目前,虽然许多目标跟踪算法取得了不错的跟踪效果,但是由于多目标跟踪过程较为复杂,且易受光照变化、目标遮挡、目标形变等因素干扰的原因,使得如何处理遮挡、如何准确关联轨迹以及如何提高实时性等问题依然是多目标跟踪任务中困扰学者们的主要挑战。
针对上述挑战,本文沿用TBD策略对行人进行跟踪,提出基于YOLO与轨迹关联的多目标跟踪算法。通过改进YOLOv3[3]检测器,提出YOLOv3-SE检测框架,完成跟踪过程中目标检测任务,提高整体跟踪速度;将卡尔曼滤波[4]作为跟踪器,预测下一帧目标位置坐标;利用行人重识别基线模型[5]提取具有判别性的外观特征,计算外观相似度,结合运动模型构建轨迹间关联概率,再与匈牙利关联策略[6]相融合,提出一种基于外观与运动特征的关联模型,提升轨迹关联鲁棒性。在MOT2016公开数据集上的实验结果表明,与当前一些主流跟踪算法相比,本文算法取得了较好的跟踪准确率,在实时性等多个指标上取得了领先。
1 基于检测的多目标跟踪算法
1.1 YOLOv3-SE检测框架
YOLOv3作为One-stage类检测框架,检测速度优势明显,但在检测精度上仍有较大的提升空间。因此,本文在YOLOv3的基础上,利用通道注意力机制、跨阶段局部网络(Cross Stage Partial Network,CSPNet)[7]以及 1×1 网络[8]进一步提升其检测精度,提出YOLOv3-SE检测框架。如图1所示,YOLOv3-SE检测框架分为3个阶段:特征提取、特征融合以及预测输出。
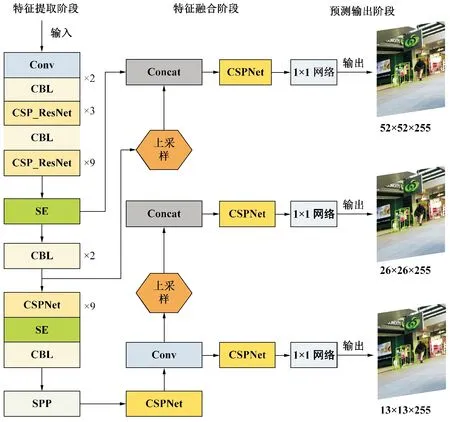
图1 YOLOv3-SE检测框架
(1)特征提取阶段。输入图像经卷积层与CBL(卷积—批量归一化—带泄露线性整流函数)层,完成图像特征信息的初次提取和两次降维,获取多种分辨率的特征图;利用包含残差网络的跨阶段局部网络(CSP_ResNet),降低计算成本以及由于网络层数增加所带来的梯度消失的风险;采用通道注意力机制(Squeeze-and- Excitation,SE)[9],重新调整各通道特征权重,抑制无用特征的同时,保证关键特征信息得到充分利用。结构如图2所示。Squeeze实际是一种空间域上的特征压缩,即对C×H×W的特征图进行平均池化得到C×H×W特征向量的过程,计算过程如式(1)所示。
(1)
式中Uc表示U中第c个二维特征矩阵,下标c表示对应通道;H和W分别表示特征图的高和宽。Excitation过程则是依据两个全连接层间建模相关性,依据输入特征数目生成对应的权重值,计算过程如式(2)。
Ac=Fex(Zc,W)=σ(W2δ(W1Zc)),
(2)
式中xk-1=(Lk-1,vk-1)表示第一次全连接;δ(.)表示ReLU激活函数;W2δ(.)表示第二次全连接;σ(.)表示Sigmoid函数。Squeeze与Excitation操作完成后,开始对张量X的特征重新标定,就是将归一化权重Ac加权到每个通道的特征上,标定过程如式(3)。
(3)
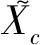

图2 通道注意力机制
(2)特征融合阶段。对13×13、26×26尺寸特征图进行上采样,并与降维后的特征图拼接,得到包含不同深度特征信息的新特征图,利用特征金字塔结构输出13×13、26×26、52×52三种尺寸的特征图。
(3)预测输出阶段。采用1×1网络在不同大小的特征图上进行预测,利用1×1卷积核减少卷积过程的参数量,降低运算复杂度。为避免同一目标输出多个预测框,通过非极大抑制(NMS)[10]去除冗余预测框,保留得分最高的预测框作为最终预测结果。
1.2 目标状态预测
使用具有良好抗噪声干扰能力的卡尔曼滤波[4]预测目标位置。设待跟踪目标上一状态为xk-1=(Lk-1,vk-1),其中L和v分别表示位置和速度,k-1表示上一帧图像。考虑到外部控制量和外部噪声干扰的问题,由运动学和相关数学公式可得状态预测方程如式(4)。
(4)
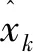

(5)

1.3 基于外观与运动特征的关联模型
一般的轨迹关联方法仅靠预测值与检测值之间面积交并比作为轨迹关联的依据,无法准确判断长期遮挡前后目标是否一致,轨迹误匹配问题相对严重。本文受行人重识别技术善于根据行人的衣着、体态、发型等外观信息,从跨摄像机视角下的图像集合中识别同一行人身份的启发,采用以ResNet50为骨干网络的行人重识别基线模型提取外观特征,设计外观关联代价用于轨迹关联。但考虑到多目标跟踪场景较为复杂,不同目标有时会具有相似的外观,若仅依赖外观特征容易导致错误关联。因此引入运动模型,利用目标空域信息提高轨迹间关联准确率,从而解决跟踪过程中目标被长期遮挡后轨迹误匹配问题。
1.3.1 外观关联代价设计
行人重识别基线模型识别行人身份过程如图3所示。来自不同帧的n个图像输入模型后,进入ResNet50骨干网络(Backbone network),经过5个阶段提取外观特征,输出形状为7×7×2048(宽×高×通道数)的Feature Map(特征图),再经平均池化(Pooling Layer)与全连接层(FC Layer)降维得到形状为1×1×751的新特征图,通过SoftMax函数输出Person ID(行人身份标签)。

图3 行人重识别基线模型识别行人身份过程
依据行人重识别基线模型提取的各帧外观特征,计算检测值与预测值之间的外观关联代价DA(i,j)。
(6)
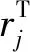
1.3.2 运动关联代价设计
依据检测目标的位置坐标,得到预测目标和检测目标之间位置差,以此计算运动关联代价DM(i,j)。
DM(i,j)=‖pj-pi‖2,
(7)
式中pj为检测目标中心的二维坐标矢量,pi为预测目标中心的二维坐标矢量。
1.3.3 轨迹关联概率设计
依据外观相似度与运动关联代价,将二者加权(λ表示权重)结合得到最终的轨迹关联概率D(i,j)。
D(i,j)=λDA(i,j)+(1-λ)DM(i,j).
(8)
1.4 算法流程
本文多目标跟踪算法流程如图4。
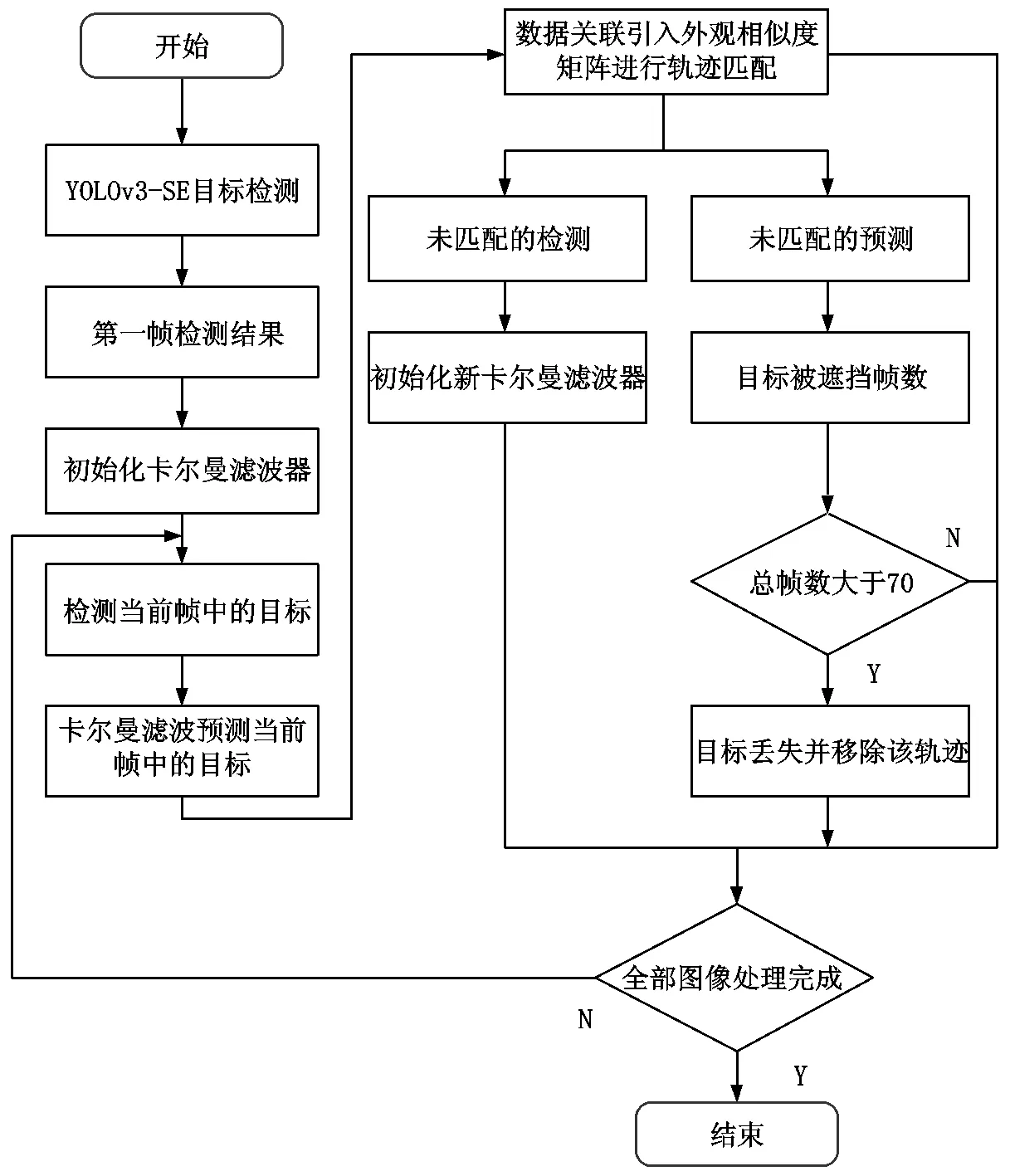
图4 算法流程图
具体算法步骤可总结如下:
(1)输入图像后,YOLOv3-SE进行目标检测;
(2)利用检测结果,初始化卡尔曼滤波器,并预测下一帧图像中目标的位置坐标;
(3)检测当前帧目标,使用行人重识别基线模型提取外观特征信息,得到外观关联代价,再结合运动关联代价构建轨迹关联概率,将最终轨迹关联概率融入匈牙利关联策略中,完成轨迹关联匹配;
(4)若有未匹配的检测结果,则初始化新的卡尔曼滤波器;若有未匹配的预测结果,则判定该目标可能被遮挡或消失,同时记录历史遮挡帧数,若遮挡帧数累计大于70帧,则认为目标消失,移除该轨迹;
(5)更新卡尔曼滤波器的相关参数,并返回步骤(3),经过多次迭代直至所有图像被处理完毕。
2 实验结果与分析
本文在COCO[11]与MOT2016[12]数据集上进行实验。实验条件:运行内存为64GB,GPU为RTX2080Ti。
2.1 评价指标
2.1.1 目标检测评价指标
目标检测评判指标主要为平均精确率(AP),验证集平均精确率(APval),测试集平均精确率(APtest),预测框与真实框的交并比大于0.50时平均精确率(AP50),单帧检测耗时(Speed)。
2.1.2 目标跟踪评价指标
目标跟踪评判指标主要为跟踪准确率(MOTA),跟踪轨迹命中率(MT),跟踪轨迹丢失率(ML),身份标签切换总次数(IDS),跟踪精度(MOTP),每帧跟踪速度(FPS),本文中FPS同时考虑检测与关联的时间。MOTA的计算公式如式(9)。
(9)
式中FP表示误判总数,当预测值和检测值没有匹配上时,将错误的预测值称为FP。FN表示漏检总数,当预测值和检测值没有匹配上时,将未被匹配的真实标注目标称为FN。IDS表示规定帧内目标身份标签切换总次数。GT表示规定帧内所有真实标注目标的总数。
2.2 检测框架性能对比
在COCO目标检测数据集上进行实验,实验结果见表1。由表1可知,YOLOv3-SE 检测精度明显优于 YOLOv3,同时单帧检测耗时仅比YOLOv3增加0.9ms,依然保持了检测速度上的优势。
2.3 目标跟踪算法性能对比
2.3.1 消融实验
为了更准确的了解SE模块与关联模型对跟踪性能的影响,在MOT2016数据集上进行消融实验。将YOLOv3-SE的SE模块去除并联合特征提取器作为基线(Baseline)跟踪算法,Baseline+SE表示在Baseline中添加SE模块,Baseline+SE+M表示在Baseline中添加SE模块与关联模型。消融实验结果见表2。
由表2可知,Baseline+SE与Baseline相比,MOTA提高0.3个百分点,MOTP提高0.4个百分点,MT提高0.2个百分点,IDS降低25次。Baseline+SE+M与Baseline+SE相比,MOTA提升0.1个百分点,MOTP指标持平,MT提升0.6个百分点,IDS降低15次。消融实验结果表明,SE模块与关联模型可以有效提升跟踪性能。
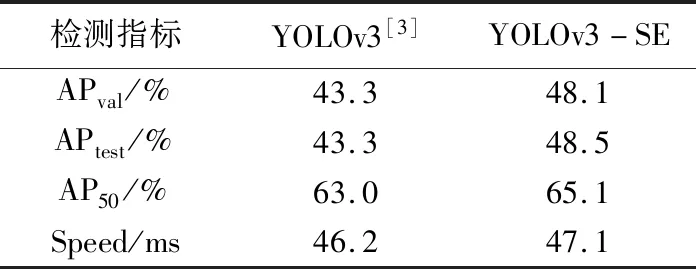
表1 检测框架在COCO数据集上的实验结果
2.3.2 不同测试序列上的实验结果
在MOT2016数据集不同测试序列上进行实验。实验结果见表3。
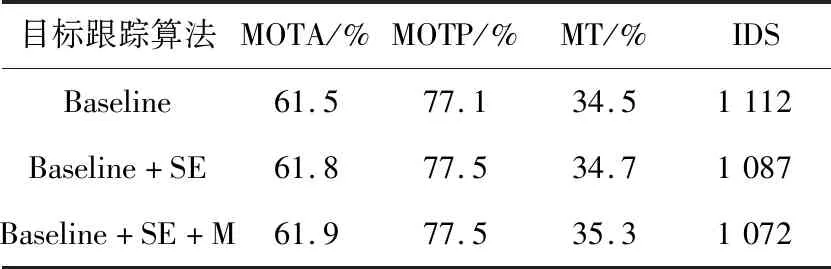
表2 在MOT2016数据集上的消融实验结果
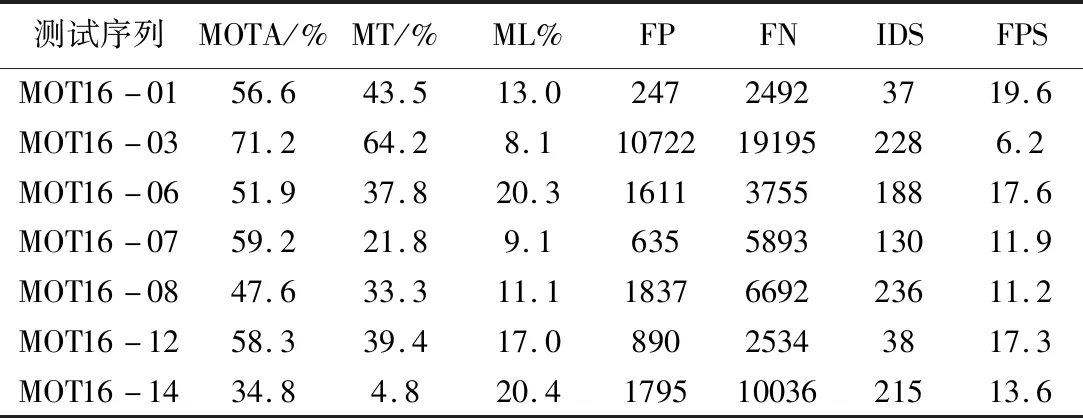
表3 本文算法在不同测试序列上的实验结果
由表3可知,本文算法在MOT16-03测试序列上的跟踪性能最佳;在MOT16-14测试序列上的跟踪性能最差。部分原因是MOT16-14测试序列由车载摄像头采集,相机镜头存在移动与抖动,导致镜头中的目标模糊。首先,这会造成行人重识别基线模型提取的外观特征模糊,对轨迹关联的优化作用减小;其次会给卡尔曼滤波进行状态预测带来干扰,增大预测值与真实值之间的误差。而MOT16-03测试序列由静止摄像头采集,镜头角度固定,采集的画面相对平稳且清晰,虽然目标数较多也较为拥挤,但行人重识别基线模型提取的外观特征丰富,对轨迹关联的优化作用较为明显,对卡尔曼滤波进行状态预测的干扰较少,预测目标位置相对精准。对于其他测试集而言,干扰因素类别和程度的不同是造成跟踪效果差异较大的重要原因之一。如MOT16-01、MOT16-06以及MOT16-07测试序列中遮挡问题较为突出,频繁遮挡会对多目标跟踪造成较大的困扰,降低跟踪的准确率;MOT16-08测试序列中目标尺寸变化大的问题以及MOT16-12测试序列中目标被长期遮挡的问题,都会给跟踪过程带来不同程度的干扰。同时,不同测试集帧内跟踪目标数量也有差别,尤其是MOT16-01中每帧目标数量相对较少,对于FN、FP以及IDS这类绝对数值指标影响较大,这也是造成相同算法在不同测试集跟踪效果差距较大的重要原因之一。
为了直观的体现本文算法处理长期遮挡的性能,截取在MOT16-12 测试序列上第80帧至第91帧的跟踪结果,如图5所示。

图5 第80帧至第91帧的跟踪结果
由图5可知,本文算法可以较好的跟踪到帧内行人目标,并且在第91帧中正确恢复了由于大面积遮挡而在第81帧中丢失长达10帧,目标“11”的身份标签。充分说明本文设计的轨迹关联概率,一定程度上解决了目标被长期遮挡后,轨迹误匹配问题。
2.3.3 多目标跟踪算法实验结果比较
不同跟踪算法在MOT2016测试集上的实验结果见表4。由表4可知,本文算法与EAMTT[13]、MOTDT[14]、SORT[15]、DeepSort[16]和TubeTk[17]算法相比,MT、ML、FN以及FPS指标均为最优。其中,MT达到35.3%,ML和FN仅为17.7%与50 597次,FPS达到13.9Hz。MOTA 则达到61.9%,仅次于TubeTk算法的64.0%。EAMTT算法采用强弱检测相结合的方式提升检测阶段准确率,但这也直接导致检测耗时增加,整体算法FPS降低,而且数据集强弱分类存在一定误差,容易使分类检测的FN升高;MOTDT、SORT以及DeepSort算法,三者都采用两段式检测方法,检测速度较慢,导致整体算法FPS偏低,其中SORT算法轨迹关联依据单一,也是造成其IDS较高的主要原因。由式(9)可知,影响MOTA的主要是FP、FN以及IDS总和,总和越低MOTA越高。TubeTk算法的FP比本文算法低6 775次,两者FP差距较大,直接导致TubeTk 算法的FP、FN以及IDS三者总和低于本文算法,也是其MOTA优于本文算法的主要原因。但是在 MT、ML、FN、IDS 以及FPS各项指标上,本文算法均优于TubeTk算法,尤其是FPS指标,比TubeTk算法高12.9Hz,实时性优势明显。
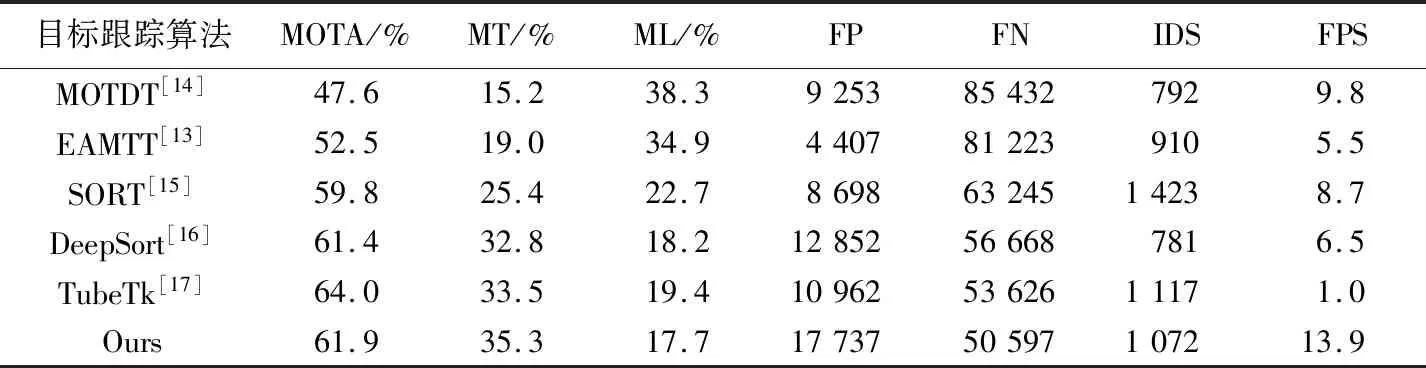
表4 不同算法在MOT2016数据集上的实验结果
3 结论
本文提出的YOLOv3-SE检测框架可以快速精准的检测跟踪目标,提出的轨迹关联模型可以准确的关联跟踪轨迹,一定程度上解决了多目标跟踪过程中实时性与长期遮挡的问题。实验结果表明,本文算法与EAMTT、MOTDT、SORT、DeepSort以及TubeTk算法相比,具有较好的实时性,且有效提高了跟踪准确率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:59:12
阅读(快乐英语高年级)(2022年6期)2022-06-17 04:48:48
家庭影院技术(2021年10期)2021-11-20 06:08:52
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
当代陕西(2019年15期)2019-09-02 01:52:00
现代装饰(2018年5期)2018-05-26 09:09:39
学苑创造·A版(2018年11期)2018-02-01 06:29:20
紫禁城(2017年6期)2017-08-07 09:22:52
中国三峡(2017年2期)2017-06-09 08:15:29
