
基于强化迭代学习的四旋翼无人机轨迹控制
2022-12-18 08:11:42刘旭光杜昌平
计算机应用 2022年12期
刘旭光,杜昌平,郑 耀
(浙江大学 航空航天学院,杭州 310027)
0 引言
四旋翼无人机(quadrotor)作为最为经典的无人机(Unmanned Aerial Vehicle,UAV)结构,因其结构简单、稳定性强主要被应用于航拍、勘探等领域。稳定准确地对目标轨迹进行跟踪是完成一系列复杂任务的基础,所以如何在现有控制架构的基础上进行优化,实现跟踪精度的提升有重大的研究价值。
针对轨迹跟踪精度指标的优化方法,国内外研究人员出了各种不同的优化方法。Rosales 等[1]提出了一种自适应比例-积分-微分(Proportional-Integral-Derivative,PID)控制的方法,通过神经网络对六轴无人机系统进行系统辨识,以反向传播输出误差来调整PID 增益,从而达到减小误差的目的,但是由于神经网络在线进行系统辨识需要大量复杂计算,导致了算法的可用性降低。另外基于自适应整定PID 的思路,研究人员引入了遗传算法、线性二次型调节器(Linear Quadratic Regulator,LQR)控 制、模糊控 制、强化学 习(Reinforcement Learning,RL)等方法[2-6]来调整PID 控制器的参数;由于是对无人机反馈控制系统的PID 控制器直接进行调整,各种算法带来的计算负担将对算法的实时性产生较大影响。为了避免对无人机传统控制结构改良带来的负面效果,一部分研究人员摒弃了传统的无人机控制架构转而引入诸如滑模变结构控制(Sliding Mode Control,SMC)[7-10]、无模型强化学习控制[11]等方法。刘小雄等[12]应用DQN(Deep QNetwork)算法对无人机高度及水平位置控制器进行优化,高度及水平位置控制器由两个不同的神经网络来构建,神经网络参数通过强化学习算法进行优化,优化后的网络参数的控制器保证了无人机的跟踪精度。滑模变结构控制方法同样存在着较大的弊端,即在滑模面附近的抖振现象,存在抖振的控制输入作用到作动器上势必导致作动器高频的动作变换,从而极大降低无人机的寿命。而强化学习由于需要大量的数据支撑以及长时间的数据分析处理,在实时性上很难满足飞行控制需求,难以应用于无人机实际飞行控制中。针对以上问题,一种前馈的学习控制方法——迭代学习控制(Iterative Learning Control,ILC)逐渐得到重视,它可以作为传统反馈控制器的前馈环节嵌入无人机的飞行控制系统中,具有可移植性强、精度高、算法结构简单等特点。Ma 等[13]提出了一种由比例-微分(Proportional-Derivative,PD)控制器组成的迭代学习控制器的方法来控制四旋翼飞行器在恒定高度上遵循相同的轨迹,算法结构简单,能够便捷地移植到飞行器的控制系统中,但是该方法PD 存在控制器参数整定困难的问题。Dong 等[14]基于PID 型迭代学习控制器引入了一种新的控制律,即通过模糊控制的方法整定控制器中的学习参数,消除了不确定因素对系统的影响,也降低了参数整定的难度;但模糊控制较为依赖专家经验,使得该方法难以得到大范围的推广应用。综上,目前无人机轨迹控制研究主要分为两个方向:一是经典控制方法,这类控制方法往往需要对控制系统及环境建立精确的模型,而往往复杂的飞行环境及高度非线性系统无法进行精确建模,导致经典控制方法的精度无法提升,对于经典飞行剖面的历史飞行信息无法进行利用,同时抗干扰性较差;二是智能控制方法,该方法不需要精准的控制系统建模,可以利用神经网络对非线性系统进行模拟,但是往往需要大量数据和大规模的计算,难以在线应用,同时由于完全摒弃了传统控制结构,单纯的神经网络控制在主流飞控平台上可迁移性较差。
综上所述,经典反馈控制方法中存在精度难以提升、抗干扰性差、难以实现静态稳定等问题;而不依赖模型的智能控制架构则需要大量数据计算来对整个系统模型进行模拟,实时性较差。本文将两种控制方法进行融合,以经典反馈控制系统架构为基础,引入迭代学习前馈控制环节解决传统反馈控制具有时滞及难以实现静态稳定的问题;并且在前馈控制器中,将强化学习与迭代学习控制算法相结合,提出强化迭代学习控制(Reinforcement Learning-Iterative Learning Control,RL-ILC)算法。该算法依靠强化学习强大的大范围内最优值搜索能力来整定迭代学习中学习律参数,使得迭代学习能够更精细准确地在小范围内利用典型飞行剖面的历史飞行信息与环境信息进行迭代学习,对系统的前馈控制输入进行进一步的细致优化。在保证迭代学习控制器在未知环境噪声干扰下保持收敛的同时提高其迭代速度,使得系统可以更快实现对目标轨迹的完美跟踪。
1 无人机系统模型
1.1 系统动力学模型
本文主要参考DJI 公司生产的450 mm-1.5 kg 型号的四旋翼无人机[15]。无人机系统模型主要为无人机动力学模型和无人机控制系统模型两部分。其中,无人机桨翼产生的升力分析在机体坐标系中进行[16],桨翼产生升力fi的计算公式如下:

其中:CT为单桨综合拉力系数,ω表示桨翼的转速。机体系下无人机的总升力FT为:

不考虑风阻的情况下,在地理坐标系中对无人机平动的三轴加速度进行计算,记航向角、俯仰角、滚转角分别为φ、θ、γ。进一步可得地理系下无人机平动三轴加速度如下:
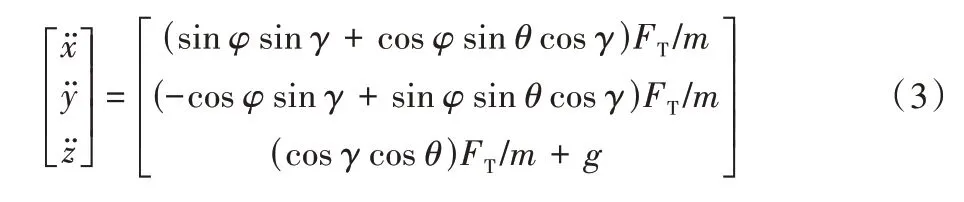
其中:x、y、z分别表示地面坐标系中x、y、z轴的位移分量。定义转动惯量J,可得无人机的姿态角加速度如下:
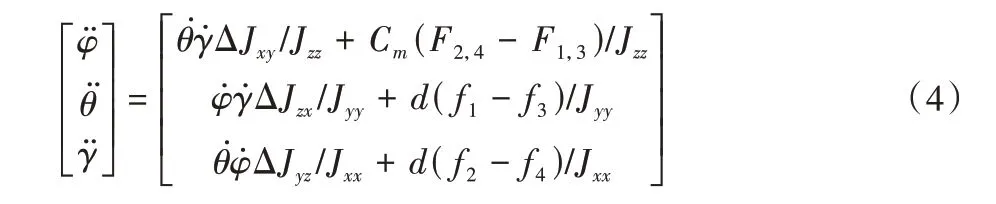
其中:ΔJij=Jii-Jjj,Fi,j=fi+fj(i,j=x,y,z)。假设无人机系统控制输入的4 个分量分别对应U1=FT,U2=f2-f4,U3=f1-f3,U4=F2,4-F1,3,代入上述模型中可得无人机系统的动力学模型如下:
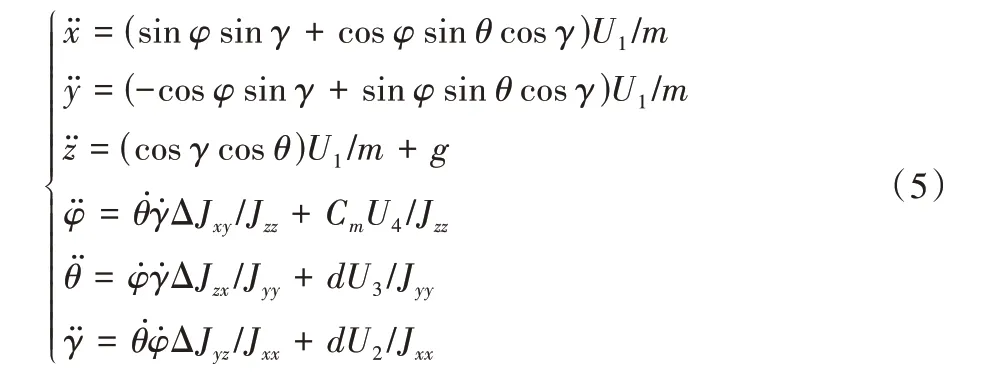
其中部分参数在表1 中进行说明注解。
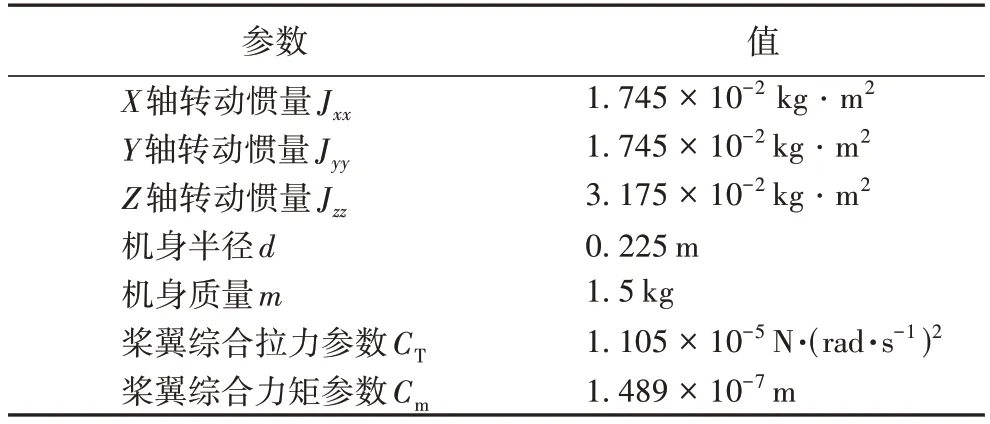
表1 四旋翼无人机的部分参数Tab.1 Some parameters of quadrotor
1.2 控制系统模型
传统的飞行控制系统多采用PID 控制算法,单独的反馈控制器会给系统带来很大的时延,这使得系统无法实现快速跟踪。当环境中存在较大的环境噪声时,反馈控制器的时延会导致被控系统容易出现在稳态附近振荡的现象,从而带来无法达到控制精度的问题。引入前馈控制器与反馈控制器组成前馈-反馈控制系统可以提升系统的时间响应特性,抑制环境扰动。本文在经典的无人机反馈控制结构的基础上增加了使用迭代学习控制算法的前馈控制器,控制系统的结构示意图如图1。
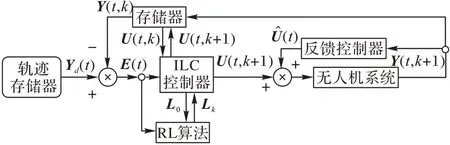
图1 无人机控制系统结构Fig.1 Structure of UAV control system
U(t,k+1)中的k表示迭代域内当前的代数;L0及Lk均为学习参数矩阵,前者对应迭代学习控制器中的学习参数矩阵的初始值,后者对应经过强化学习(RL)算法优化后的第k次迭代时学习参数矩阵;Yd(t)表示在t时刻预设理想轨迹的值;E(t)表示在t时刻轨迹误差值。
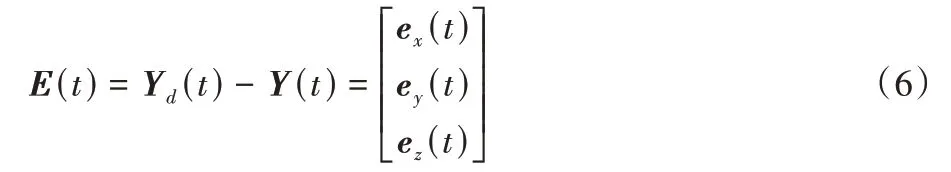
计算得到的误差E(t)的各个分量用于计算反馈控制器的输出(t)中的分量(t),计算方法如式(7):
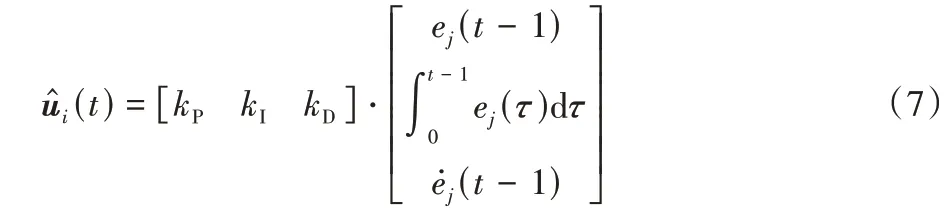
2 迭代学习控制方法
迭代学习控制最早由日本学者提出并应用于机械臂的运动控制中,控制精度极高。对于类似机械臂这类运动具有周期性的系统,迭代学习算法可以不断对每个周期内的运动轨迹的误差进行学习,而后在时间域内修正控制输入。在迭代域内不断重复直至实现在有限时间内对轨迹的完美跟踪。在无人机轨迹控制领域存在一些典型的飞行剖面具有学习价值,同时空中也存在反复出现且无法精准测量和预知的干扰。传统的前馈控制器无法对重复未知干扰给出相应的补偿也无法利用典型飞行剖面的历史飞行信息,所以普通前馈环节并不能保证理想的系统输出。本文中的前馈控制器采用迭代学习控制方法对典型的飞行剖面进行学习,能够充分利用历史飞行数据不断学习,排除未知环境噪声的影响,在有限时间内最大限度地提升对典型飞行剖面的跟踪精度。
四旋翼无人机系统作为经典的非线性欠驱动系统,系统的状态量之间耦合性很强,所以在进行分析解算时需要针对不同的任务需求对系统进行相应的简化分析。本文的控制任务是在存在未知扰动Dr的环境下令飞行器跟踪一段着陆轨线Yd=[xd,yd,zd]T。假设无人机进行小角度ε(ε=φ,θ,γ)机动,即cosε≈1,sinε≈ε,εi·εj≈0,令=-g,无人机系统模型可以简化为式(8)形式:
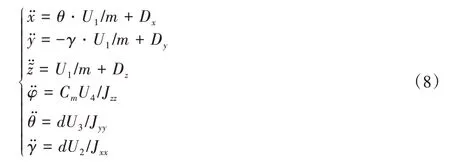
其中:Dx、Dy、Dz分别为未知时变扰动Dr于特定时刻在3 个轴向上的分量。由式(8)可知系统输入仅可以由输入直接控制,纵向及横向加速度受U3和U2的间接控制。为了减小控制系统的相对阶数得到目标与输入的直接关系,将理想轨线之于纵向x及横向y的加速度要求转移到俯仰角θ和滚转角γ的角加速度上。期望姿态角的计算公式如下:

对期望位置轨迹的跟踪可以转换为对期望姿态角(θd,γd)以及期望高度zd的跟踪。
根据式(8)及式(9)确定系统状态变量、系统输入量、系统输出量如下:

系统的动力学模型可以重写为系统的状态方程如下:

其中:A∈R6×6、B∈R6×3、C∈R3×6分别为系统的状态矩阵、输入矩阵以及输出矩阵[17],矩阵中的参数可以对照表1 中参数计算得到,矩阵D为全0 阵。
本章提出的迭代学习控制算法为PD 型迭代学习控制(PD Iterative Learning Control,PD-ILC)算 法,控制器结构如下。
如图2 所示,迭代学习控制系统由3 个迭代学习控制器及若干存储器构成。由于X向与Y向控制器同时与姿态角和控制输入U1相关,3 个控制量之间存在耦合,故在每个迭代周期内,先令X向与Y向控制器同时进行优化计算确定当前迭代中的θd与γd;更新后的U2(k+1)、U3(k+1)输入到被控无人机系统中得到用于Z向迭代学习控制器的Z向误差ez(k);最终Z向控制器完成对U1的更新,将得到的U1(k+1)、U2(k+1)与U3(k+1)输入无人机系统得到下次迭代周期的误差E(k+1),开始下一次迭代。
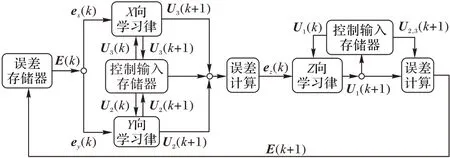
图2 迭代学习控制系统结构Fig.2 Structure of iterative learning control system
决定迭代学习控制器控制精度的主要因素包括初始控制输入以及学习律。本文选择的学习律是经典的PD 学习律,即以本次迭代当前时刻的轨迹误差与轨迹误差的导数信息来更新下次迭代相同时刻的控制输入,设计X、Y、Z三向的迭代学习控制律如下:
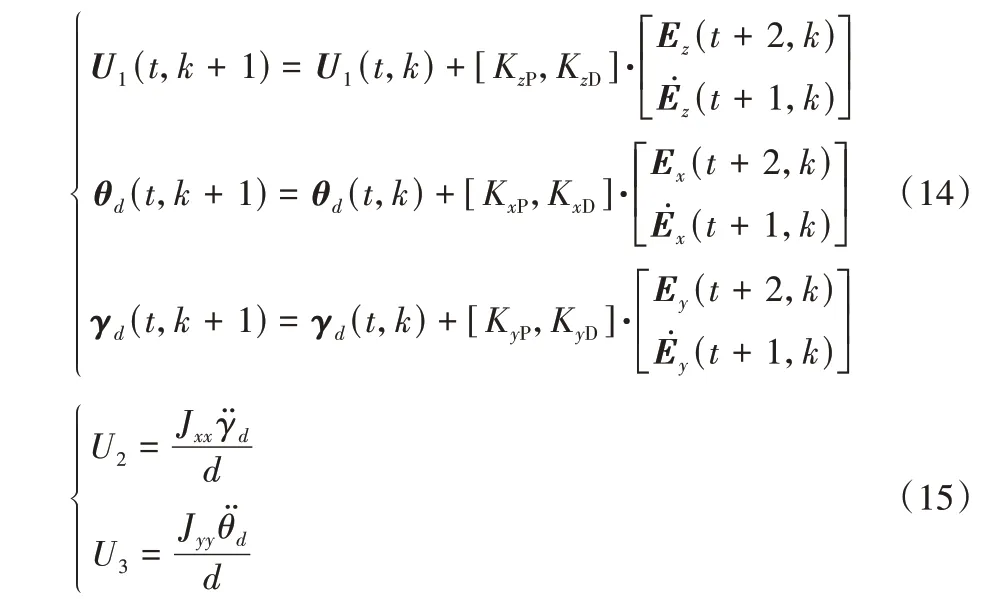
其中:Ei(t,k)、(t,k)分别为第k次迭代中t时刻的轨迹误差值及其导数,KP及KD则依据下标分别对应3 个轴向迭代学习控制器的学习参数。由于未知扰动的存在,式(9)无法通过计算求解,故采用迭代学习方法寻优。将得到的最优姿态角按照式(15)进行反解即可得控制输入U2、U3。
通过上述推导可知,控制输入Ui直接作用的状态量是加速度或角加速度,其作用到位移或角度上是存在时延的,时延问题在所有的高相对阶系统中都存在。为了减弱控制滞后带来的负面影响,本文在经典的PD 学习律的结构上进行修改,用顺延2 个时间步长的误差量以及顺延1 个时间步长的误差的一阶导数来更新当前时刻的控制输入,实验结果显示此种设计在一定程度上减小了控制滞后的影响。
3 基于强化学习的参数整定方法
PD 型迭代学习控制算法的核心是学习律中PD 的参数选择,不合适的参数选择无法保证算法的收敛性,不同学习参数下算法的收敛速度以及受噪声的影响也大不相同。迭代学习控制算法的学习参数选择多为李雅普诺夫法结合专家经验进行选择,需要对模型及环境进行精准建模才能保证算法的性能。Q-learning 算法作为一种典型的无模型强化学习算法,不需要明确的模型,通过智能体与环境的不断交互即可得到最优策略,非常适合应用于类似PD 参数整定的这类状态空间不大且环境简单的任务中[18]。本章提出一种基于强化学习Q-learning 算法的PD 学习律参数整定方法,与前文迭代学习算法相结合,解决传统的PD-ILC 算法存在的学习律参数选择困难的问题。
基于强化学习Q-learning 参数整定方法中涉及的主要对象包括:智能体Agent 为无人机控制系统的迭代学习控制器;环境E为无人机系统;状态空间S,其中的每个状态s∈S,s=[KP,KD]T;动作空间A,其中每个动作a∈A,a=[ΔKP,ΔKD]T;R为奖励值。算法的基本思想如下:
选取迭代学习控制器中的两个学习律参数KP、KD作为状态,在该状态下采取的动作为ΔKP,ΔKD,则对应的状态转移计算公式为:
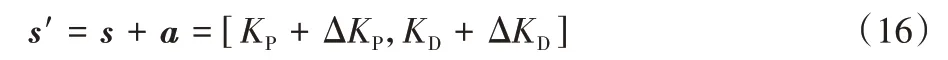
动作选择策略π则采用“ε-贪心策略”:

奖励函数的设置会在很大程度上影响模型的训练效果[19]。针对迭代学习控制最基本的精度目标,在奖励中设置如下指标:
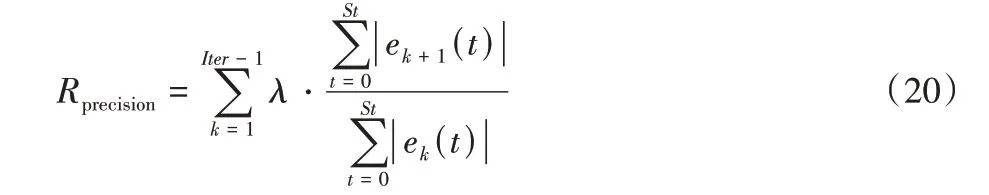
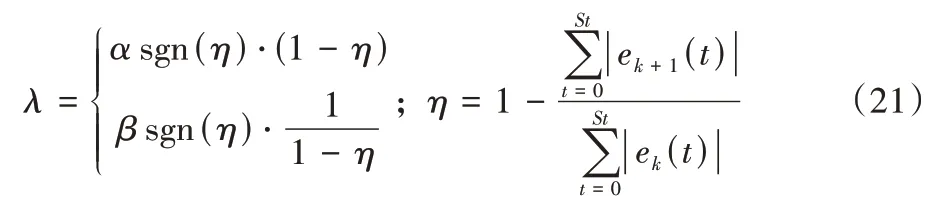
式(20)(21)中:α和β均为正常数,St表示仿真时间,Iter表示迭代次数。将不同次迭代的轨迹误差和的收敛情况与奖励值大小相关联,筛选出在保证迭代过程收敛的同时能用尽可能少的迭代完成收敛的学习参数。另外在实际应用过程中,除了对精度和收敛性的要求外,对于单次飞行过程中无人机跟踪轨迹的快速稳定追踪指标也有要求。参照精度指标的设计思路,对无人机轨迹控制稳定时间的奖励函数设计如下:
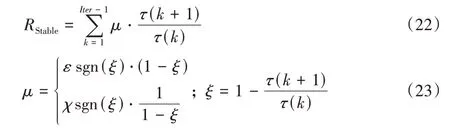
式(22)(23)中:ε和χ均为正常数,τ(k)表示第k次迭代过程中跟踪误差稳定在0.05 m 以内的起始时间。如果在当前的学习参数下稳定起始时间能随着迭代逐次降低,则给予该参数稳定时间奖励RStable,且该奖励值与优化效果成正比。所以最终的奖励函数为:

确定Q-value 的更新方法及奖励函数的设计方法后,进行算法的整定工作,算法流程如下。

4 实验与结果分析
为了检验本文设计的强化迭代学习控制(RL-ILC)算法对于经典着陆飞行轨线的跟踪性能以及在存在未知扰动的环境中的鲁棒性,在Matlab 中进行仿真实验并与未经学习参数寻优的传统迭代学习控制(ILC)算法、经典PID 控制算法及滑模控制(Sliding Mode Control,SMC)算法的轨迹控制结果作对比。假设无人机在着陆任务初始时悬停于高度120 m的空中,着陆时速度为0 m/s。综合以上几点要求,设置标准着陆轨迹的Z向分量Zd为:
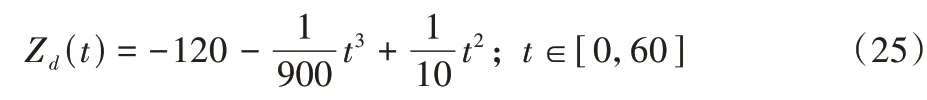
横侧向分量Yd为:
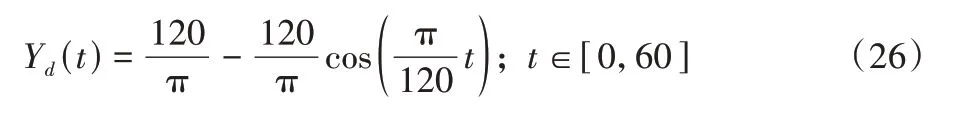
纵向分量Xd为:
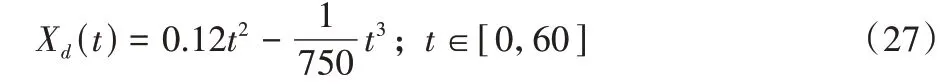
如式(25)~(27)所示仿真时间设定为60 s,计算步长为0.01 s,使用欧拉法进行数值积分。输入变量及部分状态变量对应初始参数见表2。

表2 输入变量初始参数Tab.2 Initial parameters of input variables
表2 中的初始参数为第一次仿真过程中的恒定值,不随时间变化。实验过程中不涉及航向角变化故设置航向角φ及对应的角速度以及输入U4数值均为0。强化学习整定的初始学习参数为(0.6,0.9),以此为起点进行学习参数的优化。
通过大量数据实验,最终得到的Q-table 经过处理后,由图3 将强化学习寻优学习参数的过程以散点图的形式呈现。不同的(KP,KD)组合有不同的Value 值,Value 值与前文的奖赏值正相关,即收敛性好、收敛速度快的学习参数组合有更高的Value 值。按照Value 值的大小即可筛选出此状态下的最优学习参数。
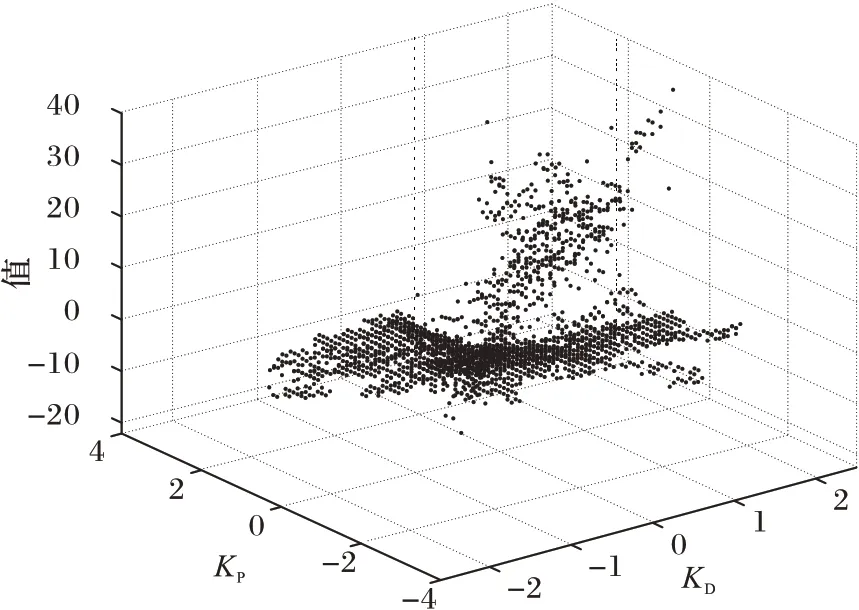
图3 强化学习参数寻优散点图Fig.3 Scatter diagram of reinforcement learning parameter optimization
图4(d)表示强化学习寻优学习参数前后仿真时间内轨迹误差的绝对值之和随着迭代次数的变化示意图,经过强化学习优化后的学习参数在收敛速度上优化显著。未经参数优化的迭代学习选取的初始学习参数不佳导致总误差随迭代次数增加而增大,即轨迹控制发散;而通过强化学习优化后,仅需要2~3 次迭代即可将总误差缩减至初始误差和的0.2%,满足总体误差要求。
图4(a)~(c)则从时间域角度出发,分别展示了在有随机噪声存在的情况下4 种控制算法的纵向位移X,横向位移Y以及高度向位移Z这3 个自由度上的位置量随时间的变化;图4(e)为实验设置的随机噪声;图4(f)则是4 种不同算法下三维运动轨迹与理想轨迹之间的对比。从时间域角度来看,由于噪声的存在,优化学习参数后的迭代学习算法输出的实际轨迹在目标轨迹附近略有波动,但波动均十分微小,跟踪效果优异。与之相比,未经参数优化的普通迭代学习算法在任务初期有明显的波动效果;且由于参数性能较差,算法并不能保证收敛,导致轨迹误差进一步发散。通过将未经参数优化的方法迭代20 次的结果与优化后的方法迭代10 次的结果进行对比,不难发现不良的学习参数带来的误差即使通过增加迭代次数来进行补偿也未能带来明显的改善。另外两种传统的飞行控制算法,在存在未知扰动的环境下也存在轨迹跟踪效果较差的问题。PID 算法在有扰动的情况下容易在目标轨线出现波动,轨迹误差较大且没有随时间增长收敛到理想轨迹的趋势。SMC 算法相较于PID 算法,其收敛性更好,能够收敛到理想轨迹附近,抗扰性略优于PID 算法;但相较于RL-ILC 算法,SMC 算法的调节时间较长,无法在有扰动的情况下快速响应完成调节。综合来看,经过强化学习算法寻优后的参数能够实现环境自适应,在不同的环境中自适应进行参数调节保证迭代学习算法的快速收敛以及轨迹跟踪的精准度。
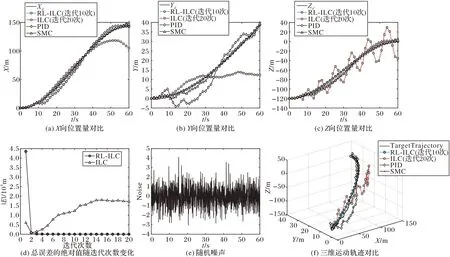
图4 强化迭代学习与迭代学习的轨迹跟踪对比Fig.4 Trajectory tracking comparison between reinforcement learning-iterative learning and iterative learning
5 结语
本文针对经典PID 控制系统下四旋翼无人机轨迹跟踪特定飞行轨迹时存在精度较差的问题,提供一种新的解决方法:在经典的反馈控制结构中加入迭代学习前馈控制器,通过不断对典型的飞行剖面进行学习,优化控制器输入来逐渐减小轨迹误差,从而实现完美追踪。RL-ILC 与ILC 的对比实验结果显示,迭代学习控制器中的学习参数选择对控制效果的影响较大。通过引入强化学习Q-learning 算法优化迭代学习控制律的学习参数,解决了迭代学习算法学习参数选择困难的问题。在不同的环境以及任务下,强化学习强大的学习搜索能力能在保证迭代学习算法快速收敛且达到最优控制效果的同时,降低系统对环境的依赖性,从而大幅提升算法的抗干扰性、稳定性和实用性。最后的仿真实验结果也显示优化学习参数后的迭代学习算法在存在较大的随机环境噪声的情况下仍可实现接近完美的轨迹跟踪。在今后的实验研究中,可以考虑将该控制方法应用于实际飞行中,利用实际飞行数据来进一步优化控制算法。
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
现代装饰(2018年5期)2018-05-26 09:09:39
制造技术与机床(2017年6期)2018-01-19 02:41:07
中国三峡(2017年2期)2017-06-09 08:15:29
电源技术(2015年9期)2015-06-05 09:36:06
筑路机械与施工机械化(2014年4期)2014-03-01 02:59:05
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:54
自动化博览(2014年9期)2014-02-28 22:33:17
自动化博览(2014年4期)2014-02-28 22:31:15
