
面向混叠文字检测的单向投影Transformer方法
2022-12-18 12:06冯智达
计算机应用 2022年12期
冯智达,陈 黎
(1.武汉科技大学 计算机科学与技术学院,武汉 430065;2.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学),武汉 430065)
0 引言
近年来,学者们在自然场景文字检测方面做了大量的研究,与基于传统的机器学习的方法[1-6]相比,基于深度学习的方法取得了更高的精度。这些方法根据预测类别可以分为基于目标预测的方法和基于分割的方法。
基于目标预测的方法一般是对Faster R-CNN(Region-Conventional Neural Network)[7]、SSD(Single Shot Detector)[8]或YOLO(You Only Look Once)[9]等目标检测算的改进,使之更符合场景文字检测。如为了应对多方向的问题,R2CNN(Rotational Region CNN)[10]对Faster R-CNN 进行改进,增加了倾斜框的坐标回归来针对多方向的文本检测;而RRPN(Rotation Region Proposal Network)[11]则是通过设计多方向的锚框来检测倾斜的文字。随着YOLO 和SSD 等单阶段目标检测算法的出现,极大地提高了算法检测速度。SSTD(Single Shot Text Detector)[12]通过在SSD 算法中加入文本注意力,显著地提高了文字检测的速度;基于SSD 的TextBoxes[13]和TextBoxes++[14]算法不需要二次回归并且可以检测任意方向的文本;同样是参考SSD 算法的SegLink[15]网络首先预测文本行的各部分,再通过深度优先搜索将属于同一文本行的各部分连接起来。
随着图像分割技术的发展,特别是全卷积网络(Fully Convolutional Network,FCN)的提出,图像分割领域出现了很多优秀算法,其中代表算法有Mask R-CNN[16]和DeepLab[17-20]系列等。受这些算法启发,文本检测领域出现了很多基于分割的方法,基于分割的方法可以处理各种形状的文本,并有效解决了边界不准问题。基于实例分割的PixelLink 算法[21]从实例分割结果中获取文本位置信息,该网络通过预测每个像素隶属于文本/非文本类别和每个像素的8 个方向的近邻是否连接2 个任务来表示文本实例。然而基于分割的方法一般产出为像素级的预测,难以区分文本级的实例。PSENet(Progressive Scale Expansion Network)[22]、DB(Differentiable Binarization)[23]等方法通过预测一个收缩的文本预选框来处理这一任务。PSENet 在不同收缩尺度的语义分割图上,自下而上逐级扩张,融合得到文本级实例;但这一过程需要较长的推理时间。针对这一问题,DB 采用单一的收缩尺度,并用一个边界预测图来控制预测文本边界。
在现实应用场景中,除常规文字检测情形外,还存在着文字混叠的情况。文字混叠是指文本行与行融合在一起难以区分的情况。在出现文字混叠的情形下,采用经典的基于分割方法无法区分开互相混叠的文本实例(图1)。
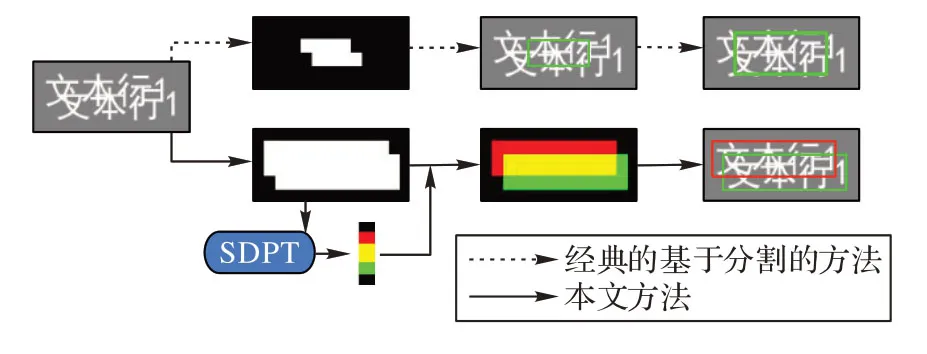
图1 本文方法与经典的基于分割的方法的比较Fig.1 Comparison of the proposed method and classical segmentation-based methods
本文首先分析了文字混叠情形,将文字混叠分为3 种,并提出了具体的指标;然后聚焦于高混叠度文字(主要是监控场景下的文字),提出了一个文本实例建模模块,对图像水平方向进行实例建模;最后预测出文本实例分割图,并对二值语义分割图、水平实例表示、文本实例分割图进行联合训练,在高文字混叠情况下取得了很好的效果。
本文的主要工作有:1)首次系统性地分析了文字混叠情况,并提出了科学的指标;2)使用单向投影Transformer(Single Direction Projected Transformer,SDPT)建模文本全局特征,对文本进行实例分割;并在本文使用的混叠地点信息数据集上,取得了比现有其他方法更好的性能。
1 文字混叠
文字检测旨在定位文本实例位置。文本中的文本实例指水平方向连续的多个字符,在下文中:文本行、文本、文字、文本实例都是相同含义。
图2(a)为外混叠(Inter-Aliasing),指行与行有一定间隔,文本实例较容易判别;图2(c)为内混叠(Intra-Aliasing),内混叠指行与行有重叠部分,很难分辨文本边界框位置;图2(b)为临界混叠(Critical-Aliasing),为介于外混叠与内混叠之间的混叠状态。

图2 文字混叠的3种情形Fig.2 Three situations of text aliasing
本文提出混叠度(Aliasing Level)来表示文字与文字混叠的程度,文本行ti和tj的混叠度可表示为:
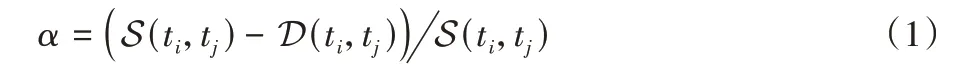
其中:S表示文本行之间的纵向距离,D表示文本行字体高度的算术平均值,即:

其中:yi,yj为文本中心点的纵坐标;hi和hj为文本的字体高度。混叠度计算示例图见图3。

图3 混叠度计算示例Fig.3 Example of aliasing level calculation
基于所提出的混叠度,文字混叠度可分为3 种情形,这3种情形对应文本行的外混叠(α<0)、临界混叠(α=0)和内混叠(α>0)。
2 本文方法
本文方法的整体流程如图4。
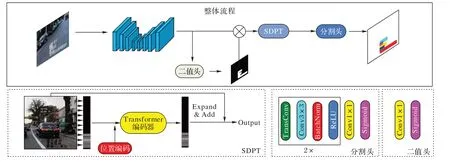
图4 本文方法整体流程Fig.4 Overview flow of the proposed method
本文在基于分割方法的基础上,受到具有全局感知的自注意力机制的启发,在分割模型中加入Transformer 编码器[24]对图像水平方向编码,最终直接预测出文本的实例分割图,有效解决了混叠文字的检测问题。
2.1 多尺度特征融合
文字存在字体大小不同的情况,即存在尺度多样性的问题。为了解决这一问题,需要提取图像中不同尺度的特征,因此使用特征金字塔网络(Feature Pyramid Network,FPN)[25]来融合多尺度的特征。
本文方法的主干网络使用深度残差网络(Residual Network,ResNet)[26]。网络中不同深度的特征图包含着不同级别的语义信息和比例特征信息:低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,其语义性更低;高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。因此,融合高、低层的特征图是很有必要的。
如图5 所示,分别取出ResNet 中Stage1~Stage4 的特征图,其分辨率分别为输入图像的1/4~1/16。然后使用Proj 模块将不同分辨率、不同通道数的特征图转换到相同的分辨率和通道数,Proj 模块操作为:首先使用最近邻差值将输入特征图上采样到输入图像的1/4;然后使用1×1 卷积将通道投影到k维。随后,将4 张特征图沿通道方向拼接,并使用1×1卷积将通道数由4k投影到k,得到输出特征图。这样,输出的特征图就融合了多尺度的特征。
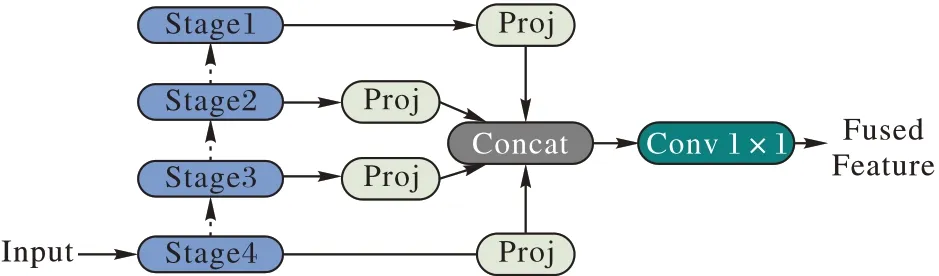
图5 多尺度特征融合Fig.5 Multi-scale feature fusion
2.2 二值化掩码
为减少非文本区域对文本实例建模的影响,本文设计了二值化掩码模块,即将深度特征图与文本概率图相乘,抑制了非文本即背景区域的特征。
文本概率图由二值头产生,二值头由一层1×1 卷积和Sigmoid 激活函数构成。将深度特征图转化为文本概率图,每个像素点表示当前位置有文本的概率,进行二值掩码(Binary Masking,BM):

其中:F 为深度特征图,⊗为哈达马积,P为文本概率图。
2.3 单向投影Transformer
在本文的文字实例分割中,每个文本实例需要获取其余所有文本实例的表示,并据此预测出本身隶属的文本实例序号,因此需要获取全局特征。Transformer 使用自注意力机制,使得每个位置与其他所有位置交互,从而获得其余所有位置的信息,即具有全局的感受野。
Transformer 的计算时间复杂度与输入序列长度呈平方关系,直接将特征图送入Transformer 将会带来巨额计算开销。根据分析,文本数据多具有单方向的性质(在本文所用的数据集中,文本都为横向),因此本文设计了单向投影Transformer(SDPT)。首先使用投影操作将二维特征图投影为一维特征序列,再送入Transformer 来降低时间复杂度。上述投影操作如下:
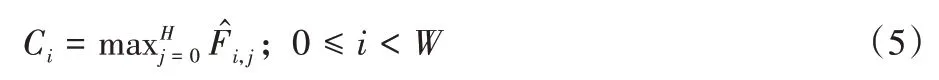
其中:为融合了多尺度的特征图,W和H为特征图的宽和高。然后输入到Transformer Encoder 模块中,结构见图6。Transformer Encoder 模块为N层Transformer Encoder Layer 的叠加。
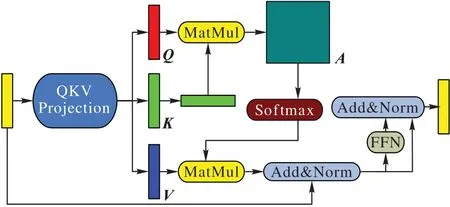
图6 Transformer编码器Fig.6 Transformer Encoder
每一层SDPT 模块的操作可以解释为:输出的第i行的向量表示根据与其他行的相似度大小,并根据相似度获得了其他行的表示,由于属于同一文本实例的相似度高,所以经过这一操作后属于同一文本实例的特征表示会更加接近。
得到水平文本实例表示后,将其与特征图相加,得到实例特征图:

通过上述过程,在特征图中同时包含文本的前景背景信息和文本实例信息。然后将其输入到分割头中,此模块包含两组上采样层和一层分类层,上采样到跟输入图片相同的分辨率,并根据所包含的文本信息及实例信息对文本实例形状进行微调,输出最后的文本实例分割图。
2.4 多目标联合优化
在网络的训练优化设计中,本文选择对水平文本实例表示C、文本概率图B和实例分割图P进行联合优化。模型优化的损失为:
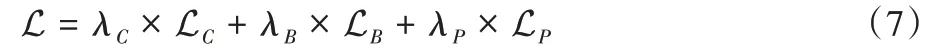
其中:λC和LC为水平实例表示C的权重和损失,λB和LB为文本概率图的损失及其权重,λP和LP为文本实例图的损失及其权重。
在LC的计算上,本文使用二值交叉熵作为损失函数,即:
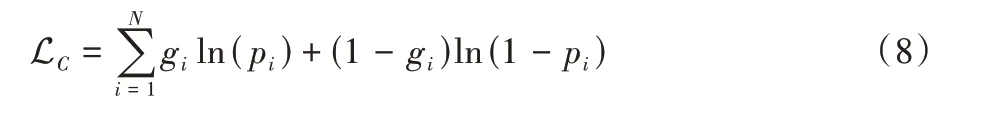
其中:N为文本实例的个数,p为模型预测,g为标签。
对于LB和LP,本文都使用Dice Loss。
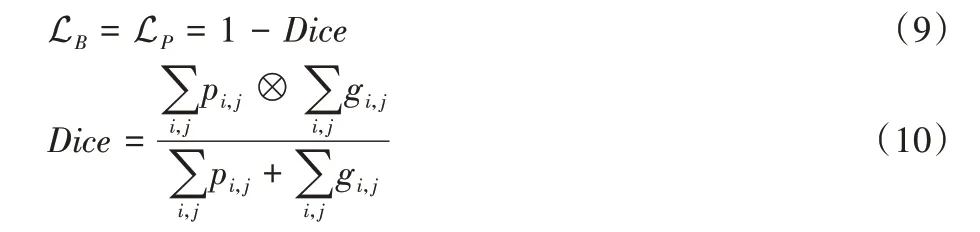
其中:p表示网络模型的预测,g表示标签。
3 实验与结果分析
3.1 数据集
本文的实验数据为安防监控场景图像,安防监控场景下的地点信息文字常出现文字间距过小和文字融入背景等情况,属于典型的文字混叠场景。因保密需要,本文只给出真实数据集的实验结果;另外,实验中还使用了人工合成的仿真数据集,用于可视化和结果展示。在本文实验中,分别使用仿真数据集BDD-SynText和真实数据集RealText组织实验。
BDD-SynText为仿真数据集,制作过程是将自动驾驶数据集BDD-100K[27]作为背景,根据不同的混叠混印上字。在本文实验中,使用不同的混叠度(-0.1~+0.5)生成了7 个数据集,每个数据集有3 000张训练图片和1 000张测试图片。图7展示了BDD-SynText 数据集的图片示例,从左至右混叠度递增。

图7 BDD-SynText图片示例Fig.7 Image examples of BDD-SynText
RealText 为来自真实监控摄像头截取的监控画面图像,采集地点为湖北、江苏、江西、湖南等地,图像中的地点信息存在大量文字与文字混叠情况。标签为人工标注,共有6 000 张图片作为训练集,2 070 张图片作为测试集。因保密需要,实验中将不会给出具体图像。
3.2 实验细节
在本文的所有实验中,选择ResNet 作为骨干网络。在SDPT 模块中,hidden size 设置为512,前馈网络维度为2 048,head 数为8,网络层数为6。训练的超参数如下:epoch 为15,batch size 为4。并且在本文实验中使用了梯度累计,每训练4 个mini batch 更新一次参数,模型训练的初始学习率为0.000 1,然后线性衰减至0。输入图像分辨率为长边512,短边保持比例放缩。
实验使用的数据增强包括4 种:1)随机翻转:输入图片以25%的概率进行水平或垂直翻转;2)随机缩放:输入图片的长宽乘以缩放系数;3)图像模糊:25%的概率对图像使用高斯模糊;4)增加噪声:25%的概率给图片增加高斯噪声。
在模型评价部分,使用P(Precision),R(Recall)和F(F1-Score)作为评价指标。不同于其他的场景文字检测只使用IoU(Intersection over Union)阈值为50(记为IoU50),为验证模型在混叠文字检测上的准确率,本文实验将同时使用IoU50 和IoU75 作为正例评判标准。
3.3 与其他方法的比较
为验证本文方法的有效性,将其与较新方法在BBDSynText 数据集上做定量比较,对比方法为PSENet、PAN(Pixel Aggregation Network)[28]和DB。所有方法的训练超参数和数据增强参数都与本文方法相同。
在仿真数据集BDD-SynText上的实验结果见表1、2。从表1、2 中可以看出,本文方法在Precision、Recall 和F1-Score 上均取得了最高分数。在IoU75时,使用ResNet18时,比第2的方法PAN分别高出14.06、16.61和15.73个百分点;在骨干网络使用ResNet50 情况下,比第2 的方法PSENet 分别高出了14.68、25.77和21.36个百分点,混叠文字检测准确率提升巨大。
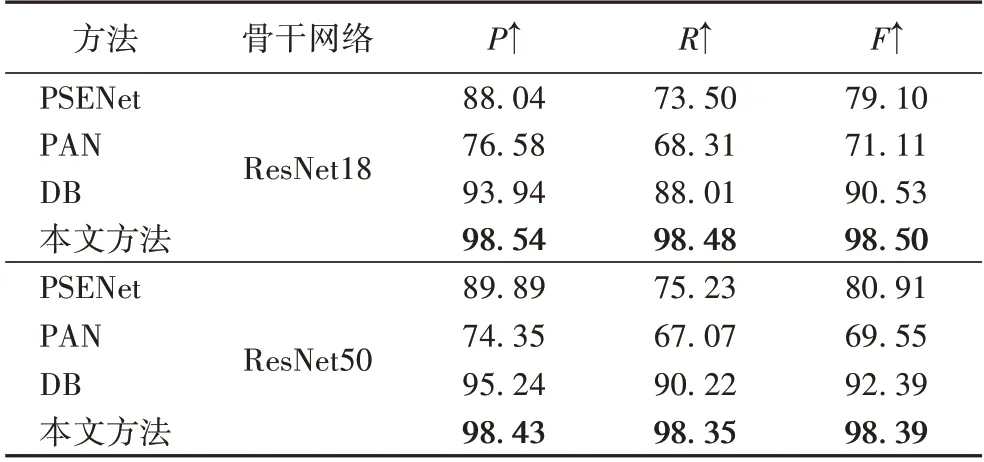
表1 在BBD-SynText数据集上IoU50基准的比较结果 单位:%Tab.1 Comparison results of IoU50 benchmark on BDD-SynText dataset unit:%
表3、4 为RealText 数据集上的实验结果,在不同骨干网络和不同的IoU 评价指标下,本文方法都取得了最优的结果。在IoU50 下,F1-Score 比第2 的方法PSENet 提高了3.14个百分点(ResNet18)和2.14 个百分点(ResNet50);在IoU75下,比第2 的方法PSENet 高了16.76 个百分点(ResNet18)和18.11 个百分点(ResNet50)。
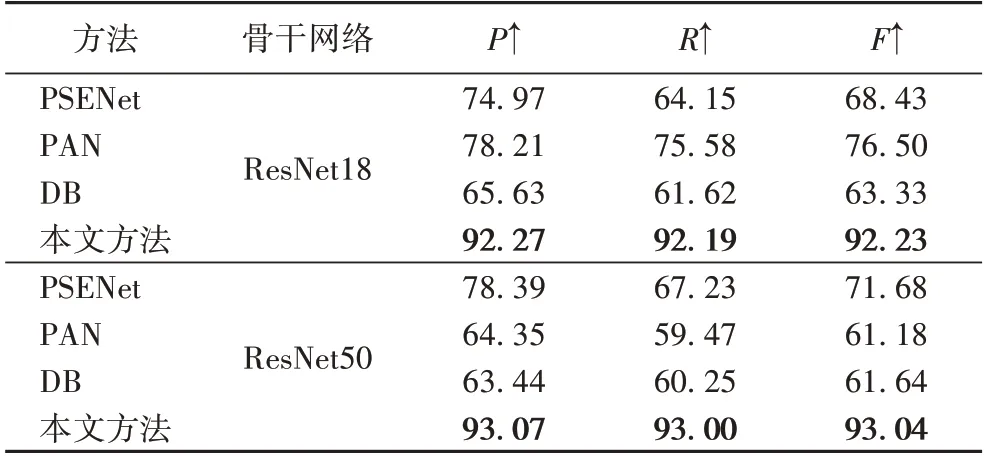
表2 在BBD-SynText数据集上IoU75基准的比较结果 单位:%Tab.2 Comparison results of IoU75 benchmark on BDD-SynText dataset unit:%
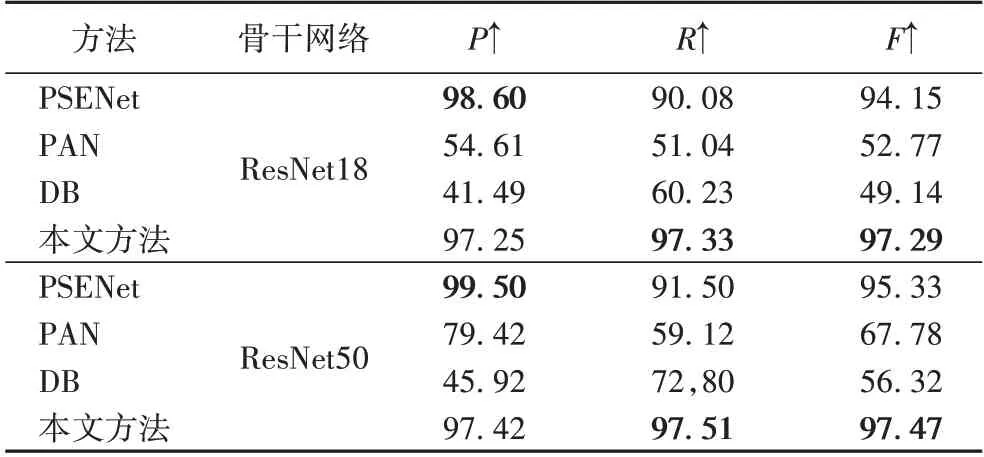
表3 在RealText数据集上IoU50基准的比较结果 单位:%Tab.3 Comparison results of IoU50 benchmark on RealText dataset unit:%
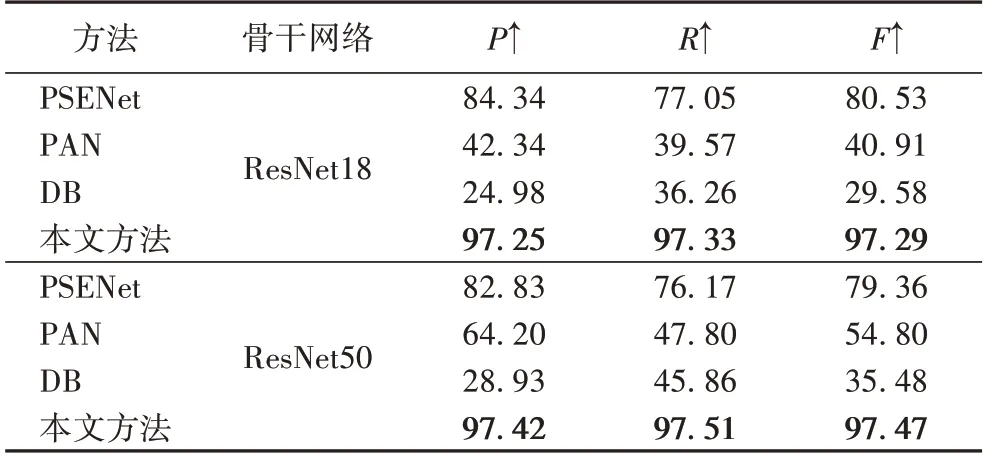
表4 在RealText数据集上IoU75基准的比较结果 单位:%Tab.4 Comparison results of IoU75 benchmark on RealText dataset unit:%
图8 展示了各方法在混叠文本上的可视化结果。从第一行至最后一行混叠度递增,可以看到随着混叠度的提高,其他方法会把多个文本实例判断为一个文本实例,导致准确率下降;而本文方法随着混叠度的提高仍保持着较高的准确率。
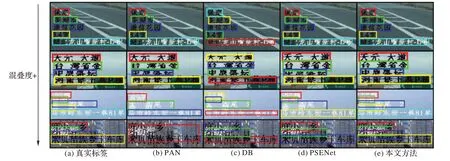
图8 不同方法的可视化结果Fig.8 Visualization results of different methods
图9 展示了各方法在不同混叠度下的F1-Score 结果。在混叠度不大于0 的情况下,PSENet、PAN 等方法取得了不错的效果,基本与本文方法持平;但随着混叠度的提高,本文方法逐渐取得了最好的效果。这表明了本文方法在高混叠度文本检测上的有效性。
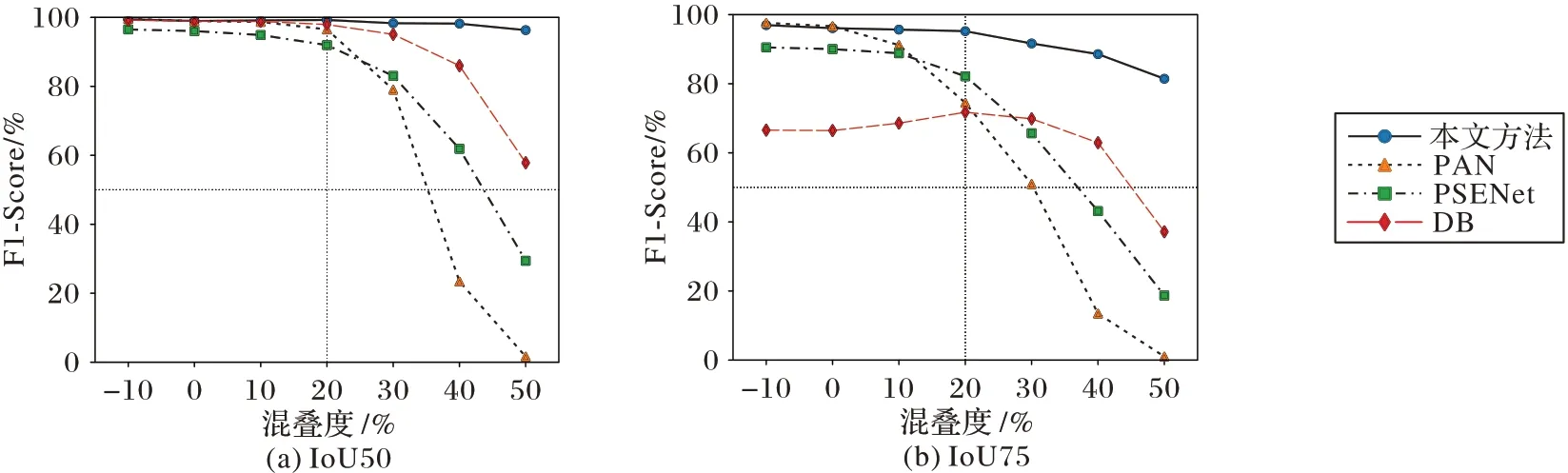
图9 不同混叠度下各方法的F1-ScoreFig.9 F1-Score of each method under different aliasing levels
3.4 消融实验
在本节的消融实验中,将分别验证二值掩码(BM)、SDPT 以及多目标训练(Multi-Target Training,MTT)的有效性。消融实验结果见表5。
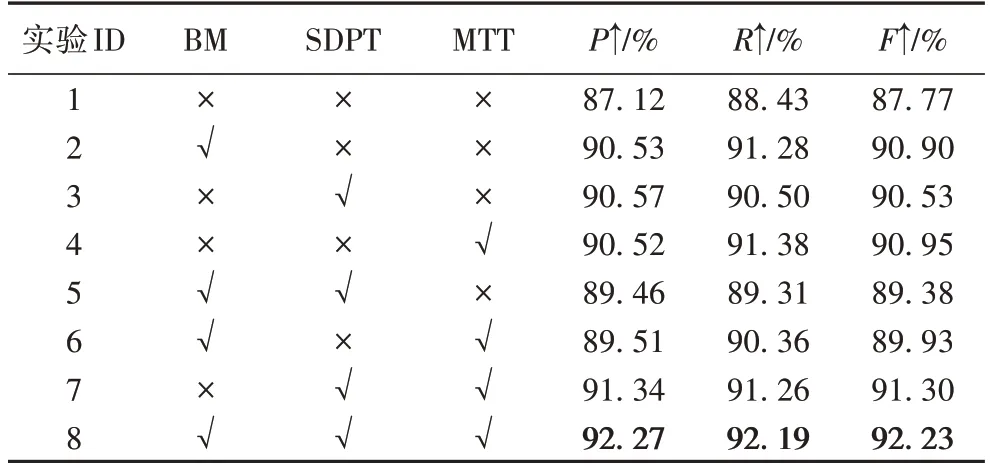
表5 消融实验结果Tab.5 Results of ablation experiment
在实验1 和2、实验7 和8 的对比中,加入二值掩码,使F1-Score 分别提升了3.13 个百分点和0.93 个百分点,原因是对特征图进行二值掩码后,抑制了特征图中的无文本区域,更有利于对有文本区域进行实例建模。
在实验1 和3、实验6 和8 的对比中可以看出,加入SDPT模块后,F1-Score 分别提高了2.76 个百分点和2.30 个百分点,充分证明了SDPT 模块在本文模型中的重要性。
在实验1 和4、实验5 和8 的对比中可以发现,多目标联合优化将F1-Score 分别提高了3.18 和2.85 个百分点,这说明了在模型训练中,对模型中间层的输出设计多个损失函数联合优化,会带来一定的收益。
4 结语
本文聚焦混叠文字场景下的文本检测,提出了一种快速的混叠文本检测的方法,提出的SDPT 模型能够快速对水平文本行实例建模,在很小的计算代价下准确检测出混叠文本实例。在BDD-SynText 和RealText 两个混叠文本检测数据集上对方法进行评估,实验结果表明在混叠文本场景下所提出的方法优于几种对比文字检测算法。另外,消融实验也验证了所提模块的重要性。
接下来会寻求更加灵活的投影方法,投影任意方向的文本,进一步扩大模型的应用范围;另外,进一步探索如何将基于目标检测的文本检测方法与本文方法结合起来,简化后处理过程。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小天使·一年级语数英综合(2021年9期)2021-09-22
小雪花·小学生快乐作文(2020年6期)2020-10-13
文苑(2020年12期)2020-04-13
当代陕西(2019年10期)2019-06-03
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
互联网周刊(2009年13期)2009-07-29
阅读(中年级)(2009年11期)2009-04-14
