
基于GPU的低密度奇偶校验码译码加速技术
2022-12-18 08:11徐启迪刘争红
计算机应用 2022年12期
徐启迪,刘争红,郑 霖
(广西无线宽带通信与信号处理重点实验室(桂林电子科技大学),广西 桂林 541004)
0 引言
软件无线电就是采用软件的方式来实现无线通信系统中的各种功能,是继无线通信技术从模拟制式过渡到数字后的又一次革命性的飞跃。目前,存在有多种主流的软件定义无线电(Software Defined Radio,SDR)硬件平台结构。基于现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)架构的SDR 结构由中心处理器进行全部资源调配和逻辑控制,由FPGA 完成计算量较大的基带信号处理,其架构特点倾向于多指令单数据(Multiple Instruction Single Data,MISD)方式,而实际上无线通信信号更合适用单指令多数据(Single Instruction Multiple Data,SIMD)方式处理。另外一种基于中央处理器(Central Processing Unit,CPU)的SDR 结构则是通过CPU 来运行信号处理系统,虽然此类SDR结构对通信系统的开发与维护提供了更便利的实现方式,但无线通信运行过程中常伴随着大量的数据并行运算,CPU 流式架构的指令执行方式难以满足宽带通信系统的实时性要求。
图形处理器(Graphic Processing Unit,GPU)由数量众多的计算单元和超长的流水线组成,适合处理数据类型高度一致、相互无依赖的大规模数据。GPU 作为高并行度的运算设备,相较于FPGA 更易于编程实现与修订,且在逻辑资源的拓展中更具有优势,成本也更低。与CPU 相比,GPU 代表的众核架构一般存在数千个运算核心,这使得GPU 在应对信号处理中超大的数据时比CPU 更具有超高速计算能力和超大数据处理带宽,如NVIDIA TITAN RTX 系列GPU 峰值吞吐量为16.3 TFLOPS(参考网址https://developer.nvidia.com/cuda-gpus),该吞吐量是目前主流CPU 的数十倍到数百倍以上,其主流设计平台是以C/C++语言为基础的计算统一设备架构(Compute Unified Device Architecture,CUDA)。
低密度奇偶校验(Low Density Parity Check,LDPC)码具有误码率低、低时延和校验矩阵构造简单的特点,纠错能力接近香 农极限。它 于1962 年 被Gallager[1]和Tanner[2]发 明,并随之提出了相应的迭代译码算法。1996 年LDPC 码受到Tanner[2]和MacKay 等[3]重视,并在其基础上提出了优化后的置信传播(Belief Propagation,BP)译码算法。之后,Chen 等[4]将BP 算法的复杂度进一步降低,在牺牲一定译码性能的情况下提出了最小和(Min-Sum,MS)译码算法,该算法极大地简化了关于LDPC 译码中节点更新的计算复杂度,并且不需要对加性高斯白噪声(Additive White Gaussian Noise,AWGN)信道进行噪声功率估计。近年来,也有不少专家致力于LDPC 码的研究,文献[5]中基于BP 算法的LDPC 卷积码的窗口解码方案,提出了对于BP 解码器和加窗解码器,探讨在无记忆擦除信道上获得接近理论极限的性能。文献[6]中则通过将多个不相交或未耦合的LDPC 码Tanner 图耦合到一个耦合链中,用一种新的方式利用低复杂度译码在无内存的二进制输入对称输出通道上构建实现代码。文献[7-8]中提出的空间耦合LDPC 码构建方式在相应的应用场景有着更优秀的性能。与此同时,非二进制(Non-Binary)LDPC 码也在飞速地更新发展,文献[9]中在考虑了非二进制的准循环LDPC 码特征的情况下,提出了早期分层解码调度方案,实现了比以往更大更高的吞吐量和效率;文献[10]中则将有限域上的非二进制低密度奇偶校验(Non Binary-Low Density Parity Check,NB-LDPC)码视为子域上的码,在略微损失性能的情况下降低了解码复杂度。
LDPC 译码器常用的主流框架为FPGA 架构,随着GPU设计理念的不断更新迭代,研究者也开始探寻基于GPU 架构设计译码器的可能性。文献[11]中提出了一种在CUDA平台的并行滑动窗口置信传播(Sliding Window Belief Propagation)算法来解码LDPC 码字,提出的基于CPU+GPU的异构并行算法相比CPU 架构获得了14~118 倍的加速比。文献[12]中分析了FPGA 架构的缺点,探讨了GPU 架构以更短的部署周期、灵活开发且可扩展成本更低的优点作为替代方案的可能,并且在高码率、采用提前中止策略的情况下获得了较高的吞吐量。文献[13]中实现了基于GPU 的加权比特可靠性(weighted Bit Reliability Based,wBRB)解码器,并探讨了在列度较大、速率较高情况下所提出译码器平衡误码性能和吞吐量性能的方法。文献[14]中额外使用了GPU 的高速片上内存,使得普通GPU 译码器的性能提升了5.32~10.41 倍,文献[15]中的GPU 增强准最大似然(Enhanced Quasi-Maximum Likelihood,EQML)译码器则在保持纠错性能的同时译码速度相较于CPU 提升了约2 个数量级。
1 LDPC译码原理
1.1 NMS译码算法
LDPC 的BP 译码算法的主要思路是通过消息传播将当前节点的概率分布状态传递给相邻的节点,并且更新相邻某节点的概率分布状态,进而让节点的概率分布状态在多次更新中得到收敛;但由于算法双曲正切(tanh)函数的存在,使得译码过程中的计算极为复杂。归一化最小和(Normalized Min Sum,NMS)算法是在BP 算法的基础上对复杂的运算操作进行简化的一种算法,如式(2)所示,用和积运算替换了tanh 操作,从而降低了计算的复杂度。NMS 算法的另一个优势在于初始化软信息时不需要相关的信道信息,算法步骤如下所示:
1)初始化。

其中:L(rij)为校验节点i传给变量节点j的信息,Lj为信号的初始信息,yj为实际接收码字,L(qji)表示变量节点j传给校验节点i的信息。
2)更新校验节点、变量节点信息。
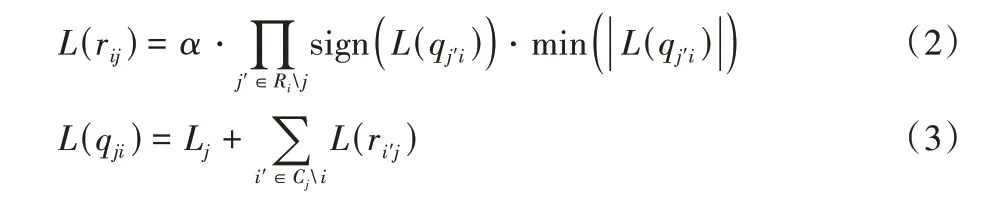
式(2)中Rij表示与校验节点i相连的变量节点的集合Ri与第j变量节点的差集,式(3)中Cji表示与变量节点j相连的变量节点的集合Cj与第i校验节点的差集。
3)信息更新并判决。

式(4)中表示每次迭代更新后的软信息。式(5)则根据线性分组码的特性,判断是否满足HcT=0 或译码循环迭代次数是否达到最大:是则停止迭代并直接输出译码码字c;否则跳转到步骤2 重新迭代,其中H为校验矩阵。
NMS 算法优化了迭代中节点信息的更新方式,同时在译码迭代过程中加入了系数α(0 <α<1)来弥补译码过程中因简化计算方式而导致的性能损失。
1.2 分层译码算法
LDPC 译码方法中消息的传递方式主要分为两种形式:泛洪式(Flooding)译码方案和分层(Layered)译码方案。泛洪式译码作为传统的译码方案,其译码过程如上述NMS 译码算法所示,在迭代过程中通过依照H的非零项顺序逐行更新变量节点,然后逐列更新变量节点来完成译码。分层式归一化最小和(Layered Normalized Min Sum,LNMS)方案则与前者不同,主要是将H矩阵按某种特定的规则在行层面分层,按层结构对每一层的节点信息进行更新,然后将更新好的消息直接传入下一层作为已知参数继续更新消息。以NMS 算法为例,其分层译码过程如下所示:
1)初始化。
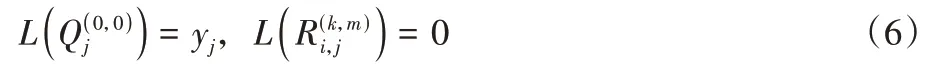
2)分层更新。

分层译码方案的优势在于能将本次迭代中已经计算出的校验节点信息及时地更新到总的节点信息中,使其可以用于计算下一个校验节点的校验信息,这将极大地提高译码的收敛速度。通过Matlab 仿真证明,分层消息传递机制的平均译码迭代次数在相同的信道环境下是泛洪式消息传递机制的一半,且分层译码机制的优势在于较少的中间变量更加适合通过硬件实现,节省硬件资源。
图1 展示了基于NMS 算法IEEE 802.16 标准下各算法性能对比,其中,所有算法的迭代次数上限为10 次,并添加了迭代的提前终止条件。可以看出,在泛洪式和分层译码结构下,BP 算法性能最佳,NMS 算法次之,硬判决算法性能最差;对比两种结构的译码方案,分层译码方案能在更少的迭代次数下取得更好的译码性能。
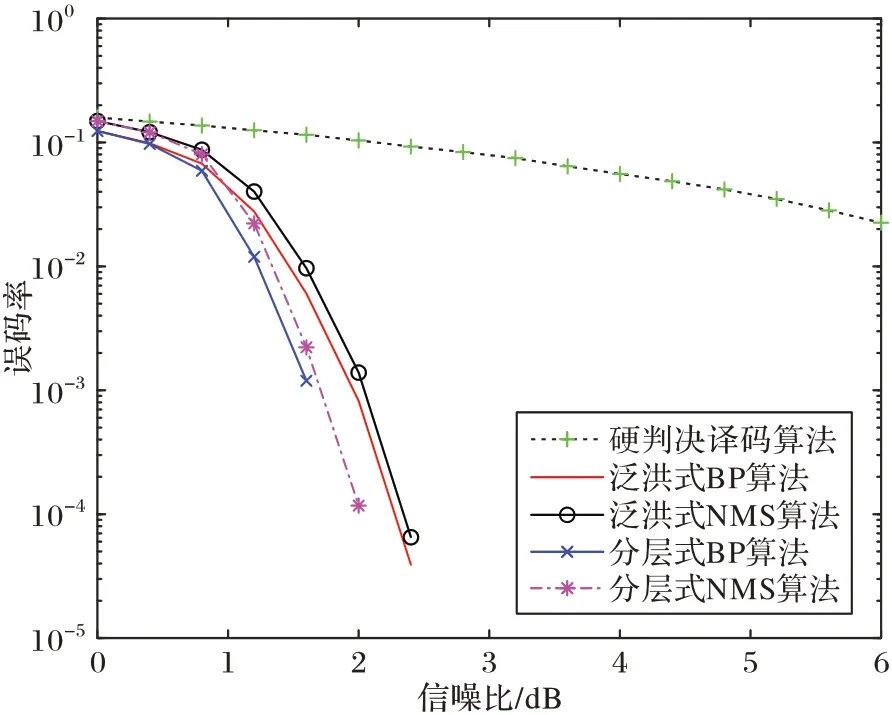
图1 LDPC译码算法性能对比Fig.1 Performance comparison of LDPC decoding algorithms
2 并行译码方案
LDPC 码的译码过程中涉及多次且复杂的运算,这导致流式的LDPC 译码器在高速无线通信系统中无法满足系统的实时性要求,造成较大时延。分析LDPC 的译码流程可看出,迭代过程中各校验节点与变量节点软信息的更新之间并无依赖关系,因此等信息的迭代更新可以采用GPU 进行加速,利用GPU 的多线程和高并行性将会极大地提高LDPC 译码器的译码效率和减小译码延迟。
2.1 并行框架
本文采用的并行方式为以分层译码机制为基础的针对准循环低密度奇偶校验(Quasi Cyclic-Low Density Parity Check,QC-LDPC)码的部分并行译码。LDPC 译码算法的流程如图2 所示,分别使用基于CPU 的流串行式和基于CPU+GPU 的异构并行式对译码算法中的部分流程进行处理。
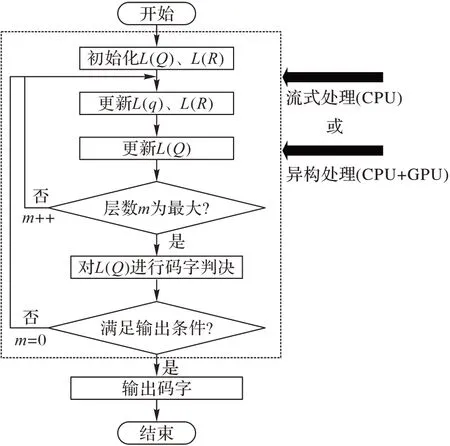
图2 LNMS译码算法流程Fig.2 Flow chart of LNMS decoding algorithm
设DataNums为检验矩阵H的基矩阵Hb中的非零项数量,Zc为H的扩展因子,M为Hb的行数,RowDegree为H的最大行重。从LDPC 码的译码过程可知,传统串行译码在每一次更新校验节点或变量节点时需遍历DataNums个的数据,在分层译码机制下,这些数据的更新只与上一层传递的消息有关;因此,可将QC-LDPC 码的校验矩阵以基矩阵Hb的形式,按Zc行划分M个子矩阵,则每个子矩阵是维度为Zc×N、列重不大于1 的稀疏矩阵,并分配Zc×RowDegree个线程对每一层的子矩阵进行译码。具体的和等信息更新的并行策略如图3 所示,以行重、列重分别为3、1,Zc为6 的子矩阵为例,则总共需要分配18 个线程进行计算。
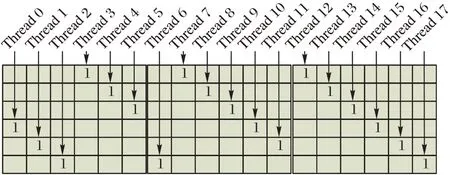
图3 并行策略Fig.3 Parallel strategy
根据图3 的并行策略可以扩展到实际的LDPC 码并行分层NMS 译码算法设计。现考虑一个序号为id的线程,有:
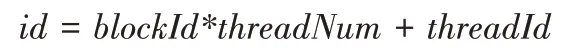
其中:blockId为当前线程(thread)所处的线程块索引,threadId则为所处线程块中的线程索引,threadNum为单个线程块拥有的线程数。将id代入式(7)~(10)中的j变量,变量i则对应校验矩阵H第m层中第id列非0 位置的行数索引。
LNMS 的GPU 并行思路是在不同层迭代时调用不同数量的线程以完成分层NMS 算法的并行实现,具体流程如算法1 所示。
算法1 基于GPU 的LNMS 算法。

算法1 中MaxIter为最大迭代次数,chunkNum为校验矩阵的行子矩阵数量,RowNum为基矩阵对应行的行度,由于本文使用的是非规则LDPC 码,所以RowNum的大小是扩展因子Zc与基矩阵各行行重的乘积,Syncthreads 和threadfence均为CUDA 内置函数。对接收的信号进行初始化后,依据校验矩阵H对其进行分层译码,考虑到校验矩阵存在非规则的情况,即每一层的行度可能不一致,因此事先将每一子矩阵行度储存在RowNum矩阵中,该算法的并行部分主要体现在更新第m行节点信息时都使用RowNum[m]个线程进行处理。
2.2 全局同步
LDPC 码的译码步骤之间存在着依赖关系,即当前步骤计算所需的数据依赖于上一步所得数据,且在程序初始化的并行配置中需要用到多个线程块;因此,在CUDA 核函数中间有必要适当地对GPU 设备中的全局内存进行数据同步,即需要每个线程块在完成上一步骤之后对所有的线程块进行全局同步,以统筹、更新数据。常见的处理方式为使用多个核函数进行串行处理,但是会造成额外的时间损耗。因此本文采用的方式是在单个核函数上进行数据同步。CUDA编程中虽然没有针对网格之间同步的函数,但是译码数据的全局同步可以采用如图4 所示的方式实现。
Syncthreads 函数为程序中的显式栅栏,要求块内的线程必须等待直到所有线程完成先前的操作。threadfence 函数将阻塞调用线程,直到当前线程对全局内存或共享内存的写入对其他线程可见为止。atomicAdd 为CUDA 原子操作,保证了在同一个显存变量依次进行“读-计算-写”操作时的连贯执行,而不会被其他线程进行中断。
如图4 所示,实线箭头为该线程实际的运行时间,虚线箭头为该线程的等待时间,可以看出每个线程块(Block)中的所有线程在完成任务后首线程进入while 循环,并等待其他线程块是否到达障碍点。若所有的线程块完成操作,则进入下一阶段运算。这种全局内存同步方式可实现凭单个核函数就能完成单个码字的译码,并可以拓展到多个码字的情况。
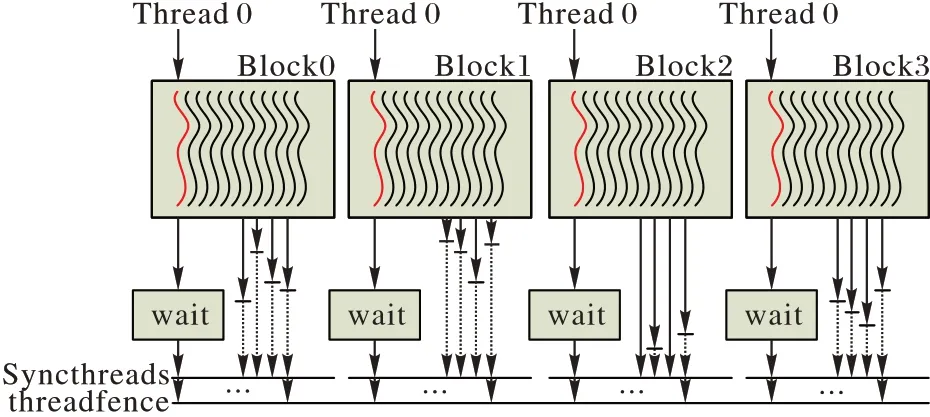
图4 同步实现方式Fig.4 Synchronization implementation method
2.3 矩阵压缩
LNMS 算法在译码过程中需要频繁地使用校验矩阵H,如果将校验矩阵信息直接储存在GPU 内存会导致显存空间的大量占用,同时也不利于数据的位置索引与调度。本文在参考文献[16]中构造压缩矩阵的基础上,给出一种不规则LDPC 码的校验矩阵压缩存储方案:将校验矩阵H分解为1个二维矩阵HRow和1 个一维矩阵RowNum,其中HRow存储着H矩阵中每行的非0 项元素的列索引,RowNum存放着H矩阵每行的非0 项元素的数量,这两个矩阵中包含了译码过程中所需的所有校验矩阵信息。可以看出,由于校验矩阵的稀疏性,一个M行N列、行重和列重分别为m和n的矩阵H,m和n远远小于M和N,经压缩后只需要M(m+1)个数据即可完整表示H矩阵的所有所需信息,矩阵的压缩效率与m有关。此外,译码迭代中的等概率信息也将以这种方式构建,矩阵内元素的位置索引可直接从压缩后的矩阵获得,而无需额外的内存空间储存信息;同样地,在对节点信息进行更新时也能调用更少的线程,进而节省GPU 设备资源。与此相同,规则LDPC 码这种压缩方式也适用于本文所使用的非规则LDPC 码。
2.4 优化策略
CUDA 程序运行前后需要先在CPU 和GPU 之间通过PCI-E 总线进行数据通信,数据的传输速度取决于总线的带宽,这一部分数据通信的时间是除了kernel 执行函数之外额外的时间损耗。因此,为了优化CPU 与GPU 之间的数据调度机制,引入了CUDA 的流并行机制对多个输入码字进行并行处理。
常量内存(Constant memory)在每个SM 中有专用的片上缓存,大小一般限制为64 KB,在常量缓存中读取内存比直接在全局内存中读取的延迟要小得多;因此可将类似校验矩阵H经压缩后的HRow和RowNum等不需要改写的数据放入常量内存中,以减少译码延迟。
3 实验与结果分析
3.1 实验环境
本文实验所用的CPU 为Intel Xeon Gold 5122 CPU @3.60 GHz,GPU 为Quardro RTX 5000,该显卡 全局内存为16 GB,计算机内存为64 GB,操作系统为Ubuntu 18.04.5 LTS,64 bit,编程环境为CUDA 11.0,GCC 版本为gcc 7.5.0,Cmake 版本为cmake 3.19.2 Linux。本文实验的GPU 端代码使用CUDA C 编写,CPU 端代码使用C/C++编写,编译、调试方式采用CMake 工具。
3.2 性能分析
并行算法的加速性能一般使用加速比表示,加速比的大小取决于算法中串行与并行部分的占比和GPU 的处理器数量,如式(10)所示,可通过计算译码时延获得加速比:
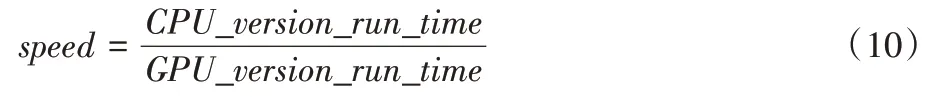
其中:CPU_version_run_time为LDPC 译码程序在CPU 上运行的实际时间;GPU_version_run_time则是程序在GPU+CPU 异构平台上运行的实际时间。图5 为各种并行码字数量下加速比的性能曲线,纵轴已进行对数处理。对于译码器的性能常用吞吐量衡量,如式(11)所示:
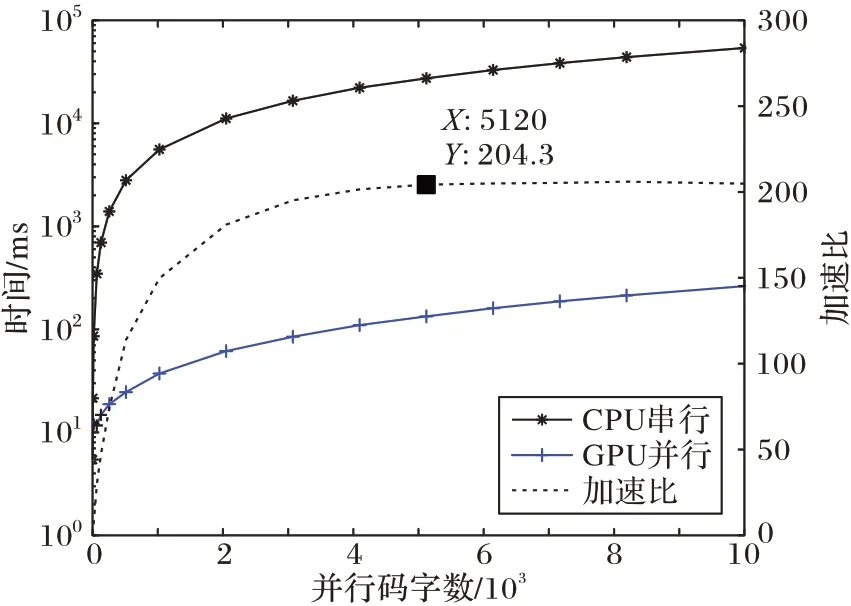
图5 多码字并行度下的加速比性能Fig.5 Speedup performance under multi-codeword parallelism

其中:Throughput为吞吐量(b/s),N为码字的位数(bit),Cn为并行的码字数量,Tp为迭代次数,T为单次迭代时延(s)。在实际测试中,根据码字并行的数量不同,吞吐量性能如图6所示,其中使用的码字结构为(2 034,1 152)的QC-LDPC,调制方式为BPSK 调制,信道为高斯白噪声信道。译码器未设置迭代提前结束条件,因此,所使用的算法一直持续到最大迭代次数;同时,为了查看所提出译码的实际性能,本文经过多次测量得出了保证最佳误码率结果所需的迭代次数,固定为10 次,所测并行码字数量为1~10 000。由于GPU 设备的设置时间与译码器实际性能无关且会影响吞吐量的计算,因此测试中忽略了GPU 设备的初始化时间。本文所进行的测试均在移植了译码CUDA 程序的GNU Raido 平台上进行。
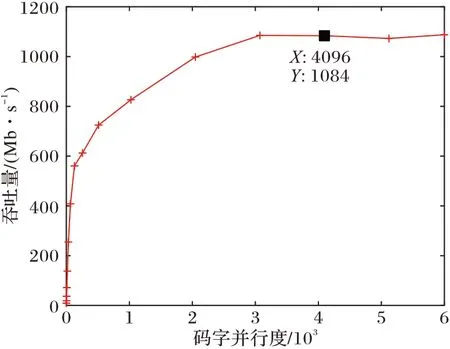
图6 多码字并行度下的吞吐量性能对比Fig.6 Comparison of throughput performance under multi-codeword parallelism
由图5 可知,随着并行码字的增加,加速比逐渐增加,并在约4 000 个码字并行时达到峰值,随后译码器的加速比稳定维持在200 倍左右。经验证,该译码器的误码率性能与图1 中Matlab 仿真的结果基本相同,无额外的译码性能损失。值得注意的是,在码字并行度较小的情况下(<5),GPU对于译码程序性能收益较小,这是由于在程序调用核函数时GPU 设备和上下文初始化的开销较大,为10 ms 左右,然而这部分性能开销一般是固定的,不会随着数据量的增加而变化。因此,在小并行度时,该部分时延占据了大部分的性能开销,从而导致性能收益不大甚至负收益。但是随着数据量的上升,该部分耗时占比逐渐下降到可以忽略的程度,而程序运行时间占比逐渐上升并占据主要开销,使得GPU 加速的性能优势得以显现并最终保持稳定。
由图6 可看出,随着码字并行数量的增加,译码器的吞吐量随之上升,在码字数量为3 000 左右时变化逐渐稳定,与图5 相比提前1 000 码字就趋于平稳,原因是计算加速比时还考虑了GPU 设备和CUDA 流的初始化时间。最终译码器的延迟仅维持在2.1 μs 左右,吞吐量的维持在1 Gb/s 左右,上下浮动误差不超过10 Mb/s。通过分析可知,吞吐量趋于稳定的原因可以归纳为当前GPU 硬件资源的占用率已经达到上限,即并行译码码字数量和GPU 的处理效率达到峰值,使得吞吐量不再变化;若想进一步提高性能,可考虑将单个GPU 换为多个GPU 集群。
本文同时参考了其他文献所设计的LDPC 译码器,并与它能到达的吞吐量性能进行对比,如表1 所示。理论上,对于相同设计框架的并行译码器来说,码率越大,吞吐量会随之增加,但译码性能也会随之降低。可以注意到,与其他基于GPU 的LDPC 解码器相比,本文提出的译码架构在同等条件下实现了更低的译码延迟。
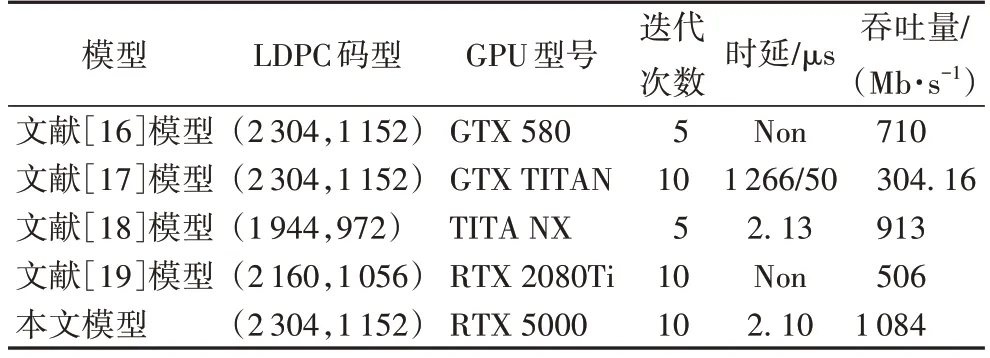
表1 不同译码器的对比Tab.1 Comparison of different decoders
4 结语
本文通过提出一种能运行在GNU Radio 平台上的基于GPU 的并行LNMS 译码方法对非规则LDPC 码进行加速译码,并在GPU 设备底层原理基础上提出了一些优化策略以提高加速性能。本文算法由NVIDIA RTX 5000 GPU 加速,与串行顺序的LNMS 算法流程不同,并行LNMS 算法流程中通过同时调用数千个CUDA 线程来完成各节点的信息交换与更新,并通过妥善处理GPU 的内存体系结构减少了线程对于全局内存的读写次数与读写时间。为了研究加速效应,本文在GNU Radio 平台上分别构建了串行顺序LNMS 算法译码器和并行顺序LNMS 算法译码器。实验结果表明,非规则LDPC 码的并行LNMS 译码器能达到约200 倍的加速比,在多码字并行的情况下吞吐量稳定在1 Gb/s 以上。后续,可针对当前算法中CPU 与GPU 通信时间仍然较大的缺点进行优化,进一步减少通信时间在总流程中的占比,以提高实际的吞吐量性能。
猜你喜欢
计算机工程(2022年1期)2022-01-14
沈阳工业大学学报(2021年6期)2021-11-29
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
扬子江(2018年1期)2018-01-26
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
科教导刊·电子版(2016年36期)2017-04-22
