
融合注意力特征的遮挡物体6D姿态估计
2022-12-18 08:10马康哲皮家甜熊周兵
计算机应用 2022年12期
马康哲,皮家甜,熊周兵,吕 佳
(1.重庆师范大学 计算机与信息科学学院,重庆 401331;2.重庆国家应用数学中心(重庆师范大学),重庆 401331;3.北京理工大学重庆创新中心,重庆 401120)
0 引言
近年来,随着机器人产业的不断发展,相关的工业应用被广泛部署。机械臂抓取作为其中较为重要的任务之一,在制造业自动化、家政服务、智慧医疗等领域有重要的应用场景。传统的二维空间(Two-Dimensional space,2D)目标检测只能够提供目标对象的2D 边界框,由于其在空间位置信息上的缺失,在实际应用场景中很难实现对目标物体的精准抓取。估计目标物体的6 个方向的自由度(Six Degree of freedom,6D)姿态信息可以为机器人提供丰富的二维空间与三维空间(Two-Dimensional space and Three-Dimensional space,2D-3D)交互信息。物体的6D 姿态通常是指物体坐标系与传感器坐标系的坐标变换,由3 个自由度的平移变换和3 个自由度的旋转变换构成。因此,对目标物体进行6D 姿态估计,是机器人能够准确抓取物体的重要步骤。
现有的算法在面对复杂背景、光照不足、遮挡等真实的自然场景时,效果仍然不佳。虽然RGBD(Red-Green-Blue-Depth)图像的方法可以利用深度信息来消除透视投影过程中造成的对象比例歧义,在准确率上有明显优势;但主流的基于RGBD 图像的6D 姿态估计网络普遍依赖于点云特征提取网络PointNet[1],计算量大,推理速度慢,难以投入实际应用。
仅使用RGB(Red-Green-Blue)图像来识别物体的6D 姿态是计算机视觉领域的重点及难点,其中基于关键点的方法在实时性和准确率上取得了很好的平衡。该方法通常使用网络回归关键点的坐标,通过求解透视投影PnP(Perspectiven-Point)问题得到相机坐标系到物体坐标系下的转换矩阵。Nibali 等[2]为了克服全连接层回归坐标泛化能力差的缺陷,使用热图匹配的方式来计算2D 关键点坐标;但该方法在关键点被遮挡时不能够有效发挥作用。Peng 等[3]为图片中每个像素回归了指向关键点的矢量,通过投票的方式选取关键点的位置,取得了很好的效果;但是该方法不可微,不适合网络的学习。Yang 等[4]在自监督领域的物体6D 姿态估计中提出了一个新颖的求解关键点方法,通过双尺度的关键点的对应关系求解姿态;但是因使用了两个大型网络,很难达到实时的目的。
针对上述问题,本文首先对网络学习过程中的特征进行了改进,提出将能够聚焦空间通道注意力信息的卷积注意力模块(Convolutional Block Attention Module,CBAM)[5]引入到物体6D 姿态估计的网络中的跳跃连接(Skip connection)阶段,注意力机制能够让网络关注非凸优化中更具影响力的特征,空间注意力信息让网络更好保留位置信息,通道注意力可以增强网络的分割效果。其次,舍弃了关键点投票的策略,引入一种可微的方法求解关键点,并将其用于轻量级网络中:第一步采用弱监督方式得到与图像尺寸大小相同的偏置注意力图(Attention Map);第二步将其与生成的偏置图(Offset Map)在对应目标掩码像素下相乘;最后累加求和得到关键点。实验结果证明,该策略能够充分利用每个像素点的位置信息,同时在面对遮挡场景下的物体具有较好的鲁棒性。本文的主要工作如下:
1)提出在物体姿态估计网络中的Skip connection 阶段引入CBAM,优化分割效果的同时减小回归关键点位置信息带来的定位误差。
2)针对基于随机抽样一致算法(RANdom SAmple Consensus,RANSAC)的关键点投票方法耗时长、不可微的问题,提出使用归一化损失函数以弱监督的方式回归的注意图作为对应像素位置上偏置的权重分数,累加求和得到关键点的策略。
3)本文算法与现有的物体姿态估计方法相比,准确率更高,在遮挡场景下更鲁棒。
1 相关工作
基于RGB 图像的物体6D 姿态估计算法大致可以分为3种:网络直接回归的方法、基于2D-3D 稠密对应关系的方法和基于关键点的方法。
网络直接回归的方法将6D 姿态估计的问题视为回归或者分类任务,网络模型直接从输入图片预测相关的参数,如欧拉角、四元数。Xiang 等[6]首次提出了端到端的姿态估计网 络PoseCNN(Convolutional Neural Network for 6D object Pose estimation in cluttered scenes),在内部解耦了旋转和平移,直接回归了目标物体的质心的平移矩阵和四元数代表的旋转矩阵,并提出了一个能够处理对称物体的损失函数。Kehl 等[7]提出了SSD(Single Shot multibox Detector)-6D 网络,扩展了2D 检测器SSD 的任务;由于旋转空间不连续,该方法将姿态估计任务转换成了离散视角点分类的问题。Sundermeyer 等[8]使用CAD(Computer Aided Design)模型渲染的合成数据来学习旋转空间特征的隐式编码,然后将预测的隐式特征与码本进行匹配。梁达勇等[9]使用网络对物体多角度视图编码得到隐式的几何特征与纹理特征进行融合。上述方法都高度依赖姿态细化网络来提高性能。
基于2D-3D 稠密对应关系的方法通过求解PnP 问题来恢复物 体姿态。Li 等[10]提出的CDPN(Coordinates-based Disentangled Pose Network)通过卷积神经网络预测了物体在3D 空间的坐标,用来建立稠密的2D-3D 对应关系。Zakharov等[11]提出的DPOD(Dense Pose Object Detector)通过UV 贴图(UV Mapping)估计其在3D 物体表面的对应位置,通过UV 图作为中间表征构建起2D-3D 对应关系。Hodaň 等[12]提出的EPOS(Estimating 6D Pose of Objects with Symmetries)将目标物体用片段来表示,使用编码解码的结构预测采样像素和片段之间的对应关系。基于2D-3D 稠密对应关系的方法需要从较大空间中搜索合适的解,同时需要用到大量的RANSAC、PnP 操作来求解姿态。
相比而言,基于关键点的方法预测稀疏的对应关系更有希望应用在未来真实场景中。Rad 等[13]提出了BB8 方法,首先使用一个网络粗略的分割目标物体,然后通过另外一个网络回归长方体边界框的8 个顶点的2D 投影。由于2D 位置坐标在面对遮挡时会失效,Oberweger 等[14]提出使用2D 关键点热图来代替关键点坐标的位置,提升了模型的抗遮挡能力;但是由于热图尺寸固定,很难预测在图像外面的点。Peng等[3]提出了逐像素投票网络(Pixel Voting Network,PVNet),为每个像素点预测一个关键点矢量,通过RANSAC 算法进行投票,最后PnP 算法求解姿态。Song 等[15]将单一关键点关表征扩张到了混合的表征,包括关键点、边缘矢量、对称性关系;然而回归更多的表征也限制了其性能。
Woo 等[5]提出了一种简单而高效的卷积注意力模块(CBAM),可以有效融合通道和空间注意力特征。李坤等[16]将坐标注意力引入到人体姿态估计网络,特征图的精确位置信息得到了加强。Stevšič 等[17]首次将空间注意力用于迭代的物体6D 姿态估计细化网络中,显著提升了网络的性能。
2 基于关键点的物体6D姿态估计网络
考虑到算法的实用性,本文采用了基于关键点的方法。在理想的状态下,提出的解决方案应该能够很好地处理弱纹理物体,并且在复杂背景、不同光照、遮挡情况下都能准确计算出关键点的位置,同时在实时性和准确度上都达到一定的要求。在不大幅度增加网络计算量的前提下,本文对PVNet的架构进行了改进:首先,在每个Skip connection 阶段的浅层特征后增加了一个CBAM 来增强不同尺度下的特征;其次,在轻量级骨干网络ResNet18 的编码阶段之后,加入一个卷积核为3 × 3 的卷积层和一个上采样层,通过归一化损失函数采取弱监督的方式,回归得到关键点偏置的注意力图;最后,网络在解码阶段回归了物体掩码和关键点的偏置图。在此基础上,通过掩码图剔除背景无关的像素,逐像素对偏置赋予注意力权重累加求和计算出关键点。整体架构如图1所示。

图1 物体6D姿态估计网络整体架构Fig.1 Overall architecture of object 6D pose estimation network
2.1 CBAM注意力机制
注意力机制通过对不同重要程度的特征分配不同大小的权重,可以让模型专注于目标任务相关的特征而不是包含无关背景的冗余特征。注意力机制通常分为两种,即通道注意力和空间注意力。本文采用的卷积注意力模块是一个简单而有效的混合注意力模块,由通道注意力和空间注意力串联组成:通道注意力关注的是不同通道对目标任务结果的影响,空间注意力判断哪个位置的信息对目标任务结果比较重要。
如图2 所示,在通道注意力模块(Channel Attention Module,CAM)中,给定一个大小为H×W×C的特征F,其中H、W、C分别为特征图的长、宽、和通道数。特征图首先分别经过最大池化和平均池化后,得到大小为1 × 1 ×C的特征,将其送入共享权重的多重感知机(Muti-Layer Perceptron,MLP),其中隐藏层神经元个数为C/r,r为缩减倍数,激活函数为ReLU(Rectified Linear Unit),经过MLP 得到两个特征相加再经过一个Sigmoid 激活函数得到通道注意力权重系数Mc,最后将输入特征与Mc相乘即可得到通道注意力特征。在空间注意力模块(Spatial Attention Module,SAM)中,将通道注意力特征作为输入特征,经过最大池化和平均池化后在通道进行拼接后得到大小为H×W× 2 的特征,将其输入到卷积核为7 × 7 的卷积层中,经过Sigmoid 激活函数得到空间注意力权重系数Ms,最后将通道注意力特征与Ms相乘得到增强后的特征F′。
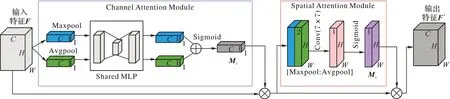
图2 CBAM结构Fig.2 CBAM structure
2.2 物体6D姿态求解
基于关键点的方法需要首先求得关键点的坐标位置,使用固定尺寸热图来替代关键点坐标的方法不能解决遮挡问题,使用投票的方式求解关键点的坐标,其过程不可学习,属于次优的方案。受文献[4]方法的启发,本文采用一种可微的方式求解关键点。在得到2D 平面的关键点的信息后,将其与3D 模型中标注的关键点构成2D-3D 映射关系,求解PnP问题恢复物体姿态。为简化模型,本文采用EPnP(Efficient PnP)算法[18]求解物体姿态。
在关键点选择的过程中,为了充分利用掩码图中每个像素点对关键点的坐标位置的相互关系,如图3 所示,本文提出的网络回归了目标物体掩码以及每个关键点的偏置图,通过对位置坐标的约束以弱监督的方式得到了对应关键点的注意图。通过注意力分数加权平均前景像素关键点偏置图可以计算出关键点。计算公式如式(1)所示:
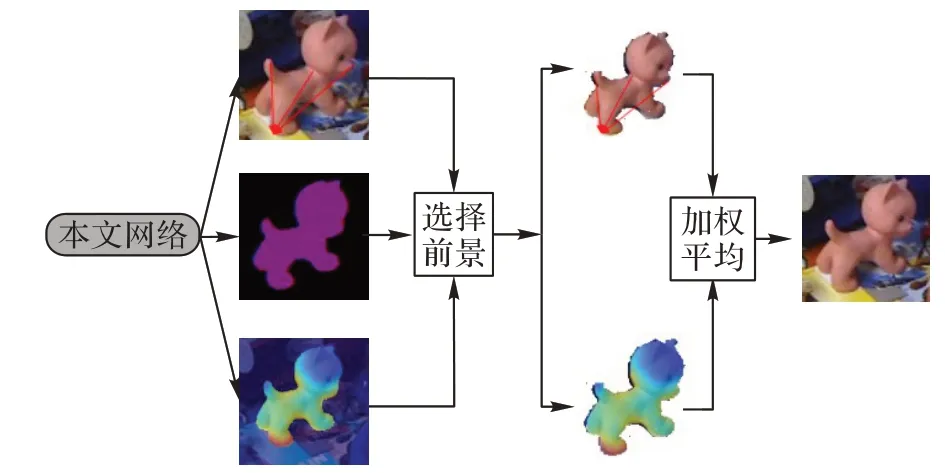
图3 关键点计算Fig.3 Key points calculation

2.3 损失函数
本文模型主要采用编码解码的结构,目标函数由三部分组成:第一部分语义分割损失Lseg采用交叉熵损失,第二部分偏置图损失Loff采用smooth L1 损失,第三部分关键点损失Lkey采用 L1 损失。整体的损失函数L如式(2)所示:

其中:λ1、λ2、λ3分别为平衡常数。
当物体在2D 平面投影的面积越大时,其偏置图损失函数值也越大;因此,需要首先对其进行归一化。由于在2D 平面中目标物体尺寸缺失,而物体掩码的像素点个数易受遮挡条件的影响,本文在关键点的损失函数中,将物体实例分割的外接矩形框的最长边作为尺度归一化因子。具体公式如式(3)所示:
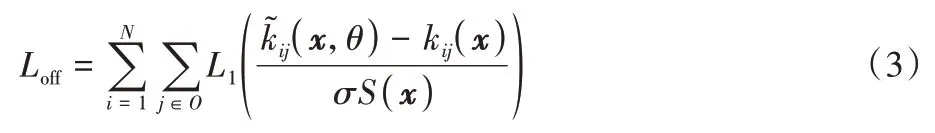
本文方法采用弱监督的方式得到注意力图,通过在网络中加入关键点的损失函数来约束特征图随机生成注意力图。公式如式(4)所示:
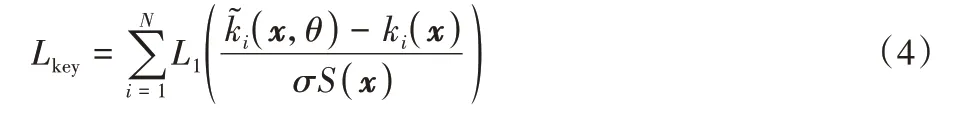
3 实验与结果分析
3.1 数据集
LINEMOD 数据集[19]由15 783 幅图像组成,其中包含13 个弱纹理对象,每个对象包含约1 400 幅图像。由于目标对象缺少纹理,且图像中混乱的场景以及光照变化使该数据集面临挑战。本文按照先前的工作[10,19]划分训练和测试集,并根据文献[10]方法生成用于训练的合成图像。
Occlusion LINEMOD 数据集[20]是LINEMOD 数据集的重新注释,每张图像都包含多个部分遮挡物体。由1 435 幅图像组成,包含8 个物体。通常的规则是在LINEMOD 数据集上训练网络,然后在Occluded LINEMOD 数据集上测试,以验证算法面对遮挡场景的鲁棒性。
3.2 评价指标
为了评价模型的性能,本文使用2D 投影指标[21]和点平均距离(ADD(-S))指标[6]分别对模型进行评估。
2D 投影指标 该指标计算的是预测的姿态投影的点与真实标注姿态投影的点之间的平均距离。当平均距离小于5 个像素的时候,估计的姿态认为是正确的。
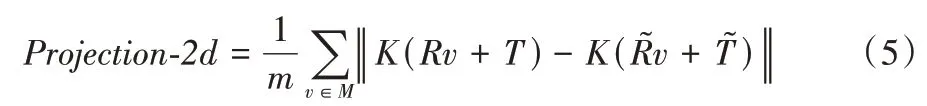
其中:M代表目标物体3D 模型中的顶点合集;m代表顶点的个数;R、T分别代表真实的旋转和平移;、分别代表预测的旋转和平移。
ADD(-S)指标 当预测的点云与实际的点云差值小于物体直径的10%时,该指标认为估计的转换矩阵是正确的。
对于非对称物体,ADD 度量计算通过预测姿态和地面真实姿态转换的物体顶点之间的点对平均距离,对于对称物体,本文使用最近点对距离ADD-S 度量。相关定义如下:
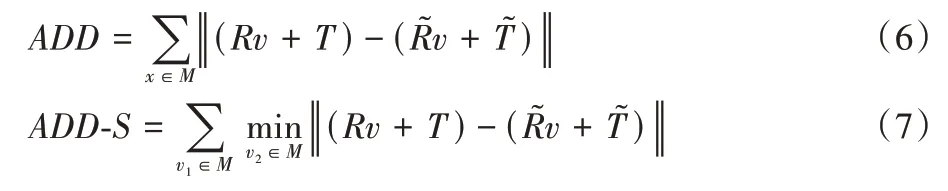
3.3 实验设置
数据集方面,本文模型使用了两个公开数据集LINEMOD 数据集和Occlusion LINEMOD 数据集。实验将LINEMOD 数据集85%的样本作为训练样本,剩下15%的样本作为测试样本;Occlusion LINEMOD 数据集仅用来测试。关键点的位置通过最远点采样算法(Farthest Point Sampling,FPS)计算得出,本文选取8 个关键点作为注释。为了防止过拟合,本文方法对图像进行了常规的图像增强操作,包括随机裁切、旋转和色彩变化等操作。为了增加数据集样本大小,本文使用了PVNet 中的数据集扩增方法生成了10 000 幅只包含单个物体的渲染图像,图像背景从SUN397 数据集[22]中随机选择;另外为了模拟真实的遮挡场景,生成10 000 幅包含多个物体相互遮挡的合成图像。
在模型训练过程中,初始学习率设置为0.001,bathsize设置为10,epoch 设置为100,σ设置为0.5,使用Adam 优化器,前5 个epoch 使用了warmup 策略对模型进行预热,学习率调整通过每训练5 个epoch 衰减0.85。
3.4 实验结果分析
3.4.1 模型实时性分析
实验所用计算机CPU 型号为 AMD Ryzen R5 5600X 3.7 GHz,GPU 使用一张Titan XP 显卡,batchsize 设置为10。在LINEMOD 数据集上,输入尺寸大小为480 × 640的图像,测试结果可以达到23 FPS。其中数据导入耗时28.1 ms,前向传播耗时3.5 ms,EPnP耗时2.7 ms,关键点计算耗时11.2 ms,可以满足机器人在现实环境中进行物体实时抓取的基本要求。如表1 所示,相比基于RANSAC 投票的计算方法,本文提出的关键点计算方法耗时减小了50.9%。

表1 计算关键点方法耗时对比 单位:msTab.1 Time consumption comparison of calculating key points unit:ms
3.4.2 LINEMOD 数据集实验结果分析
为了体现方法的优越性,本文将该方法使用2D 投影指标与ADD(-S)指标对物体6D 姿态估计领域中不同方法进行对比,包括BB8[13]、YOLO6D(YOLO(You Only Look Once)for 6D object pose estimation)[23]、PVNet[3]、DPOD[11]、CDPN[10]、HybridPose[15],实验结果如表2、3 所示。

表2 使用2D投影指标在LINEMOD数据集上各方法对比 单位:%Tab.2 Comparison of methods on LINEMOD dataset in terms of 2D projection metric unit:%
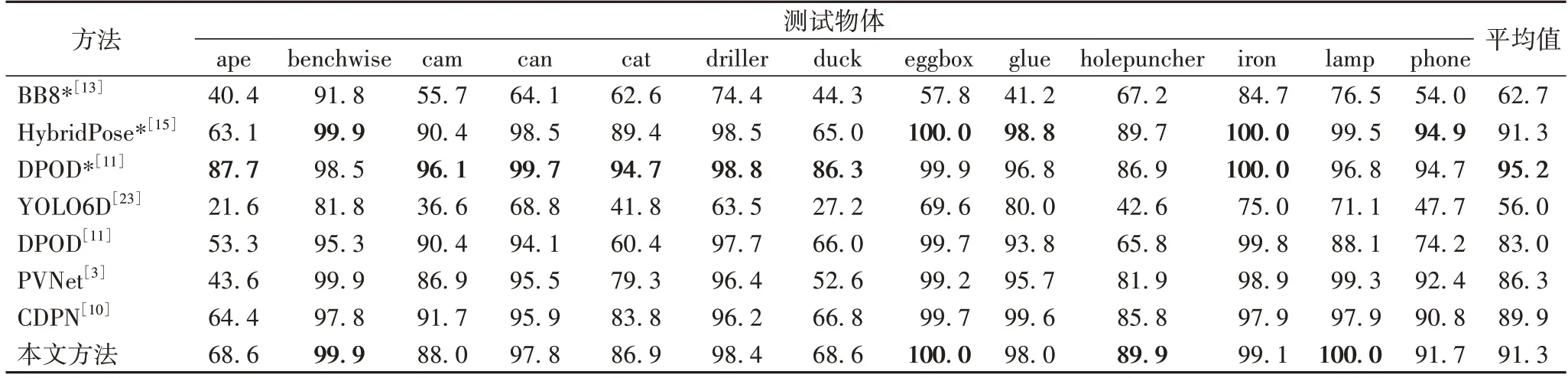
表3 使用ADD(-S)指标在LINEMOD数据集上各方法对比 单位:%Tab.3 Comparison of methods on LINEMOD dataset in terms of ADD(-S)metric unit:%
BB8 使用3D 矩形框上的8 个点作为关键点,直接回归坐标的位置,PVNet 和HybridPose 使用关键点投票的策略定位物体表面的关键点,DPOD 通过UV 图建立稠密的2D-3D 对应关系。其中BB8、DPOD、HybridPose 通常使用细化网络提高其精度。
在LINEMOD 数据集中,本文方法不使用细化网络达到了最高精度,相较于基于投票策略的网络PVNet,2D 投影指标和ADD(-S)指标分别提高了0.3 个百分点和5.0 个百分点,验证了本文方法对于弱纹理物体以及复杂背景下计算关键点的有效性以及准确性,大幅提升了旋转矩阵和平移矩阵的精度。尤其对于小尺寸类别ape 和duck,在ADD(-S)指标分别提升了25.0 个百分点和16.0 个百分点,验证了本文方法在融合多尺度上下文信息有明显优势。实验结果表明本文方法在精度上可以媲美较新的一些加了细化网络的方法,如HybridPose。
3.4.3 Occlusion LINEMOD 数据集实验结果分析
遮挡条件下的物体6D 姿态估计是该领域的一项挑战,本文总结对比了Oberweger[14]、SegDriven[24]、PVNet[3]、SSPE(Single-Stage Pose Estimation)[25]、DPOD[11]、HybridPose[15]在Occlusion LINEMOD 数据集上的实验结果,如表4、5 所示。

表4 使用2D投影指标在Occlusion LINEMOD 数据集上各方法对比 单位:%Tab.4 Comparison of methods on Occlusion LINEMOD dataset in terms of 2D Projection metric unit:%
在2D 投影指标中,在Occlusion LINEMOD 数据集上,本文方法的性能接近PVNet,但是仍然提升了0.4 个百分点。ADD(-S)将对称物体纳入考虑范围之内,相较于2D 投影指标更严谨,故本文将其引入对模型进行进一步评估。
本文方法在对PVNet 进行改进之后,在Occlusion LINEMOD 数据集中,ADD(-S)指标平均值从40.8%提升到了46.3%;且在多个类别中取得了最高的分数,包括ape、can、driller、duck、holepuncher。在不加任何细化网络的前提下,本文方法的准确率最高,优于DPOD 方法13.5 个百分点,验证了本文方法在遮挡条件下具有更出色的性能。对于对称物体glue、eggbox,性能有轻微下降,通过分析可知是由于轻量级网络对于对称信息的学习不敏感造成对注意力图的影响。但总体而言,本文方法在遮挡场景下有较强的鲁棒性。
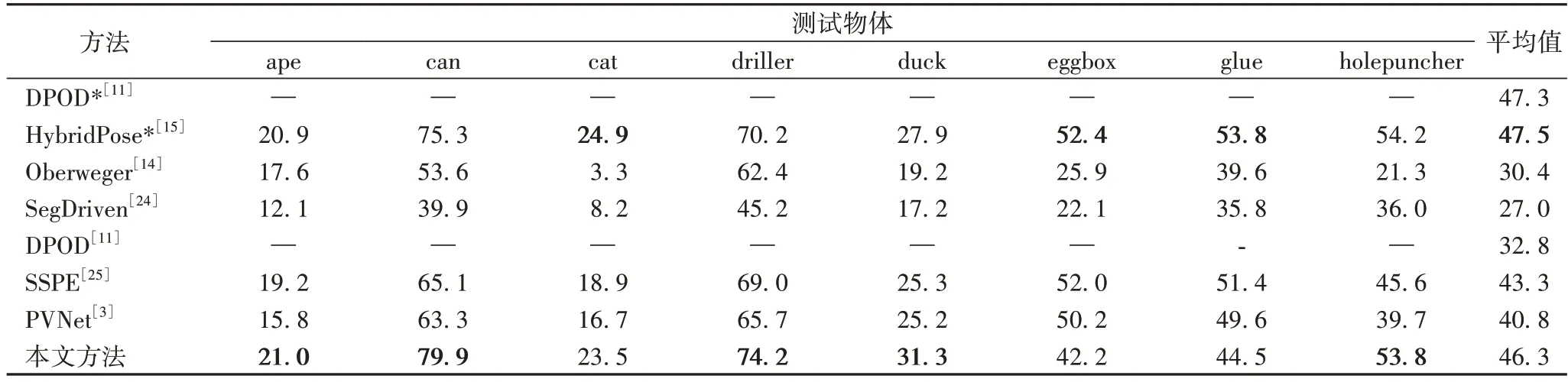
表5 使用ADD(-S)指标在Occlusion LINEMOD 数据集上与其他方法对比 单位:%Tab.5 Comparison with other methods on Occlusion LINEMOD dataset in terms of ADD(-S)metric unit:%
3.4.4 超参数σ对模型影响分析
σ的作用是对尺度的值进行范围调整。在实验中,将尺度敏感因子σ设置为0.5,即每次预测误差都被归一化到其对象尺度的一半。根据实验观察,将σ设置为0.5 的误差值始终小于将σ设置为1 的误差值,因此处于Smooth L1 损失或L1 损失的非线性区域,能够进行有效的反向梯度传播。
3.5 消融实验分析
为验证融合注意力的增强特征对遮挡物体姿态估计的影响以及使用注意力图求解关键点相较于基于RANSAC 投票求解关键点对实验结果精度的影响,本文设计了消融实验。通过消除CBAM 以及使用注意力图求解关键点的方法替代投票选取关键点的策略与基模型PVNet 进行对比,实验在LINEMOD 数据集和Occlusion LINEMOD 数据集上进行。
实验结果如表6 所示。采用控制变量法对2.1 节、2.2 节中的优化策略进行实验表明,使用注意力图求解关键点的策略,相较于基于RANSAC 投票策略,在LINEMOD 数据集中2D 投影指标和ADD(-S)指标分别提升了0.2 和4.6 个百分点;在Occlusion LINEMOD 数据集中ADD(-S)指标提升了3.4 个百分点;2D 投影指标有所下降,这是由于特征表达能力受限,注意力图得分较高的像素点集中分布在关键点周围,当物体被严重遮挡时,关键点的位置产生偏差。模型在跳跃连接阶段加入CBAM 之后,相较于只使用投票策略的方法,在LINEMOD 数据集中2D 投影指标和ADD(-S)指标分别提升了0.3 和5.0 个百分点;在Occlusion LINEMOD 数据集中2D 投影指标和ADD(-S)指标分别提升了0.3 和5.5 个百分点,验证了融合注意力模块之后的基于注意力图关键点求解策略大幅度提升了姿态估计方法的精度。
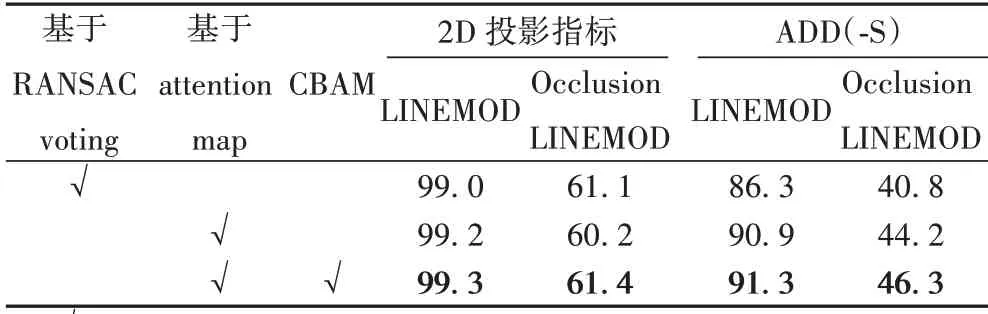
表6 消融实验结果Tab.6 Ablation experiment results
在跳跃连接阶段加入CBAM 后,浅层特征通过注意力模块后可以摒弃掉特征矩阵中与背景相关的冗余信息,增强浅层特征表达能力;通过与深层特征的融合,有利于捕捉全局信息优化分割效果,同时提升回归偏置图精度,让注意图分数不单单聚集在关键点周围,有更好的分布性。如图4 所示,加了CBAM 的模型回归的注意力图更能充分利用每个位置的信息,权重不单一集中在关键点周围。配合注意力图求解关键点方法的结果更准确;同时,该方法在关键点被遮挡条件下,仍然具有良好的鲁棒性。

图4 注意力图可视化Fig.4 Visualization of attention map
3.6 实验结果可视化
本文在LINEMOD 数据集和Occlusion LINEMOD 数据集中对类别ape、cat、driller、glue 随机选取了一些图片进行可视化,如图5 所示。其中图5(a)为原图,图5(b)为预测物体掩码图及其最大的外接矩阵,图5(c)为预测关键点,图5(d)为立体矩形框,包围矩形线条分别代表物体的预测姿态与真实姿态。第一行类别ape 和第二行类别cat 是在LINEMOD 数据集测试结果,第三行类别driller 和第四行类别glue 是在Occlusion LINEMOD 数据集上的测试结果。
从图5 中可以看出,无论是对于小尺寸类别ape 或者是大尺寸类别driller,本文方法都能准确检测到关键点的位置;此外,在Occlusion LINEMOD 数据集中的场景下,即使关键点被遮挡,本文方法仍然能够准确检测到关键点的位置,求解出物体姿态,可以有效应用于机械臂抓取。

图5 部分实验结果可视化Fig.5 Visualization of some experimental results
4 结语
本文在基于关键点的单目图像物体6D 姿态估计方法中,对PVNet 网络架构以及关键点求解策略进行了改进,在几乎不增加网络负担、满足机械臂抓取实时性要求下,通过加入融合通道空间注意力信息的CBAM 并采用一种可微的求解关键点方法,提升了网络的性能。实验结果表明,本文方法在LINEMOD 数据集中ADD(-S)指标提高了5.0 个百分点,在Occlusion LINEMOD 数据集中ADD(-S)指标提高了5.5 个百分点,显著提升了模型在遮挡场景下的单目RGB 图像的物体6D 姿态估计的鲁棒性,甚至可以媲美一些加了细化网络的方法。
但是在研究过程中还存在一些问题,例如对于对称物体,轻量级网络在学习过程中和遮挡场景下的关键点求解过程中未能充分有效利用其对称信息,另外该方法依赖于真实数据集标注,需要大量标签;因此,下一步工作的重点将会针对轻量级网络下对称物体关键点求解策略以及在无标签场景下采用无监督方式对单目图像进行物体6D 姿态估计。
猜你喜欢
今日农业(2021年8期)2021-11-28
建材发展导向(2021年11期)2021-07-28
数学物理学报(2021年1期)2021-03-29
学生天地(2020年3期)2020-08-25
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
新高考·高一物理(2015年5期)2015-08-18
