
面向数字人文的《四库全书》子部自动分类研究
——以SikuBERT和SikuRoBERTa预训练模型为例*
2022-12-15 02:50胡昊天张逸勤邓三鸿王东波冯敏萱
图书馆论坛 2022年12期
胡昊天,张逸勤,邓三鸿,王东波,冯敏萱,刘 浏,李 斌
0 引言
数字人文(Digital Humanities)是将人文社科研究内容和计算机技术相结合的新研究范式。面对数字化的海量中华传统典籍与文献,借助高性能的算法模型与软件工具,挖掘共性与特异性的隐含知识并建立联系,可以实现对传统文化与历史信息的再组织与再利用,构建知识与实体的新关联。从古籍中挖掘出的精神财富、智慧资源与文化传统能进一步服务于新时代的历史学、古汉语文学、图书与文献学、语言学等学科研究,促进大众科普与社会教育,对传承中华文化具有指导意义。
中华古籍图书的集大成者《钦定四库全书》(以下简称《四库全书》)是清乾隆时期编纂的大型丛书,同期诞生的四库分类法是一套完整的古籍分类体系。《四库全书》通过将典籍图书按照经、史、子、集四部分类,实现了对传统文化体系化的组织与整理,类别范围几乎覆盖全部古籍。其中,子部被划分为儒家、兵家、法家、农家、医家、天文算法、术数、艺术、谱录、杂家、类书、小说家、释家、道家14个类别。子部内容最庞杂、思想多元,最具文化与文学价值,在中国思想史和文学史上具有特殊意义[1]。这使得研究子部分类体系具有重要价值。不同类别的古籍能反映出共性与特性的文化关联与时代特征,基于数据分析技术对特定类别的古籍进行数据挖掘,能揭示文字背后蕴含的隐式知识。
随着越来越多的纸本古籍数字化,需要对电子古籍遵循特定的类别进行组织与存储,以便于检索与使用。大量古书缺少类别信息,而且众多典籍在传世过程中遭到损坏或遗失,仅仅依靠人工进行分类,任务巨大,也难以准确归入某一类别。为此,本文基于面向古文自然语言处理任务的SikuBERT和SikuRoBERTa预训练语言模型,在《四库全书》子部古籍文本上进行微调,与BERT、BERT-wwm、RoBERTa和RoBERTawwm预训练模型对比在《四库全书》子部上的文本自动分类效果,最终构建四库子部自动分类模型,实现对典籍的类别自动划分。
1 相关研究
(1)文本分类。深度学习技术与预训练语言模型在文本分类领域得到广泛应用。以卷积神经网络(CNN)、循环神经网络(RNN)为代表的深度神经网络模型能自主学习待分类语料的类别特征,分类性能提升显著。比如,Hao等[2]提出用于短文本分类的互注意力卷积神经网络(Mutual-Attention CNN)模型,通过结合字符和词汇级别特征,提升了分类性能。Qiao等[3]提出结合词汇和字符两个级别注意力模型的分类方法(WCAM),能同时捕捉具有语义相关性和类别区分度的文本,最后联合Word-GRU和Character-CNN的预测结果获得最佳分类标签。
限制深度学习模型分类效果提升的原因之一是昂贵的标注成本导致数据匮乏。而以BERT为代表的预训练语言模型能直接在超大规模无标注数据集上进行语言建模,通过迁移学习的形式将预训练阶段学习的语言与文本特征应用到下游特定任务。其强大的语义学习与上下文表征能力使越来越多的学者将其引入分类任务。比如,Yu等[4]提出基于BERT 改进的文本自动分类模型BERT4TC,通过构建不同粒度的辅助句对,使BERT具备面向特定分类任务的领域知识,在多分类任务上表现优异。
古代汉语在词法、句法等层面均与现代汉语存在差异,难以直接将在现代汉语上学习的文本特征迁移至古文自动分类任务,需要构建面向古文分类的标注数据集,训练机器学习与深度学习自动分类模型。比如,王东波等[5]探究SVM模型在不同特征下的分类性能,分别将TF-IDF、信息增益、卡方统计和互信息作为输入特征,对比在《论语》《孟子》等9部先秦典籍上的分类效果,实验结果表明基于TF-IDF特征的SVM分类器在古汉语分类任务上表现最佳。
上述研究表明,深度学习与预训练语言模型已广泛用于文本分类任务,但在古籍文本分类领域缺少对预训练语言模型应用的探究。当前主要采用传统的机器学习和深度学习模型,需要面向特定语料构建标注数据集,训练所得的分类模型也难以迁移到不同风格体裁的古籍分类任务。此外,现有研究用于古籍分类的数据集大多数为先秦典籍等规模较小的标注语料,缺乏可供深度学习和预训练模型训练的大规模古籍分类数据集。
(2)预训练模型。LSTM、CNN等深度学习模型在古文自动处理领域得到较多应用[6],但随着模型结构复杂度提升,昂贵的标注成本与时间成本制约了模型性能提升[7]。而基于自监督学习的预训练模型(PTMs)能在未标注的大规模语料上自主学习通用文本表示与语言特征,在面向下游任务时仅需少量标注数据集即可取得超越深度学习模型的表现,成为研究热点。
BERT(Bidirectional Encoder Representations from Transformers)模型基于预训练和微调两部分的形式进行构建。在预训练阶段,采用双向语言模型,即通过掩码语言模型随机遮蔽输入序列中的词汇,以自监督方式使得模型利用前后两个方向的信息预测词汇,获得双向深层文本表示。该模型还引入下一句预测任务学习句子关系。BERT的出现在预训练模型发展史上具有里程碑式的意义[8],催生了大批改型。
RoBERTa(Robustly optimized BERT approach)[9]对BERT模型进行3大优化:更深度的训练方法、更有效的掩码方式、更全面的输入表示。BERT-wwm[10]模型针对中文词汇与英文词汇的不同,将BERT 原始字符级掩码机制替换为全词掩码(Whole Word Masking)的方式。ERNIE(Baidu,Enhanced Representation through Knowledge Integration)[11]在BERT字符掩码的基础上额外增加中文实体层面和短语层面的掩码,引入更多外部知识。ERNIE(THU,Enhanced Language Representation with Informative Entities)[12]将知识图谱中的命名实体信息与原始文本信息对齐后共同作为模型输入,引入外部的实体信息以增强原始的文本表示,最终在知识驱动型等任务上取得超越BERT 的效果。MASS[13]针对序列到序列任务,提出序列掩码训练(Masked Sequence to Sequence Pretraining)方式,对输入文本序列,直接遮蔽指定长度的连续文本段,通过训练实现对词汇间依赖关系的语言建模。该模型在摘要生成、自动翻译、对话生成等任务上表现较优。
上述预训练语言模型研究,对自然语言理解相关的文本分类、知识抽取等任务,以BERT为代表的双向语言表示模型能取得更优表现。对中文文本处理,基于全词掩码、实体掩码等方式的预训练模型较基于字符掩码的BERT可以更充分地对中文词汇建模。但现有的中文预训练模型多是基于通用现代汉语文本进行语言特征学习,在面向古文自然语言处理任务时,由于预训练和下游任务语料不适配,难以充分发挥性能。
2 SikuBERT预训练语言模型
2.1 SikuBERT
SikuBERT 模 型 (https://huggingface.co/SIKU-BERT/sikubert.)是基于BERT 框架,在BERT-base-Chinese模型上继续训练得到,其训练数据集为文渊阁版繁体字《四库全书》全文语料。与原始BERT 模型相比,在预训练过程中仅保留掩码语言模型(Masked Language Model,MLM)任务,移除了对性能提升表现不佳的下一句预测任务(Next Sentence Prediction,NSP)。图1 是SikuBERT 模型预训练过程示例。对输入语句,随机遮蔽15%字符并采用[MASK]标记替代,基于双向Transformer编码器,使模型以自监督方式从前后两个方向同时预测被遮蔽字符,从而更有效地学习典籍文本的文法、句法、语言风格等特征。
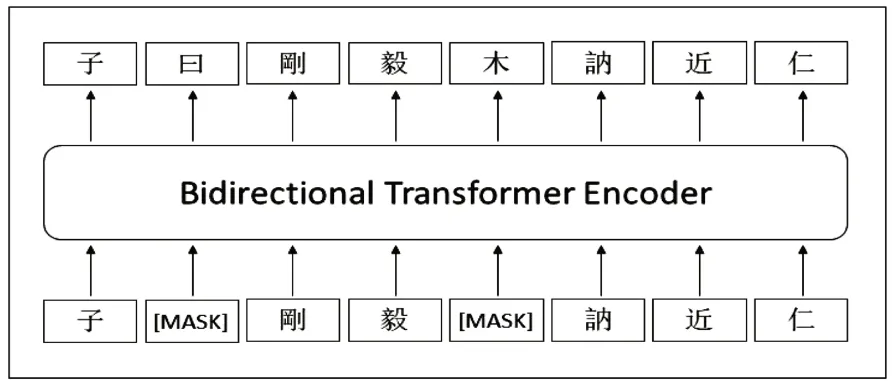
图1 SikuBERT模型预训练示意图
2.2 SikuRoBERTa
SikuRoBERTa 模 型 (https://huggingface.co/SIKU-BERT/sikuroberta)是基于中文版Ro-BERTa-wwm模型在《四库全书》全文语料上预训练后构建的。与原始RoBERTa模型不同的是,RoBERTa-wwm模型在采用掩码语言模型预训练过程中采用全词遮蔽技术(whole word masking,wwm),实现对中文文本词汇层面的遮蔽,使模型能进一步学习到深层的中文词义与词法信息。SikuRoBERTa 在保留RoBERTawwm模型优势的基础上,从5亿余字的《四库全书》全文语料(已删去原文中注释部分)上学习古代汉语的遣词造句与语言学信息,从而提升在繁体文本上的表现。图2 是SikuBERT 和Siku-RoBERTa模型用于典籍自动分类微调任务的架构图。对输入序列“子曰所謂大臣者以道事君不可則止”,会被SikuBERT 或SikuRoBERTa 模型根据词表映射为字符嵌入、句子嵌入和位置嵌入3种向量的组合形式,经过Transformer编码器提取特征后,通过Softmax分类器计算输入序列的各类别概率,并输出概率最大类别作为该序列的四库子部类别信息。
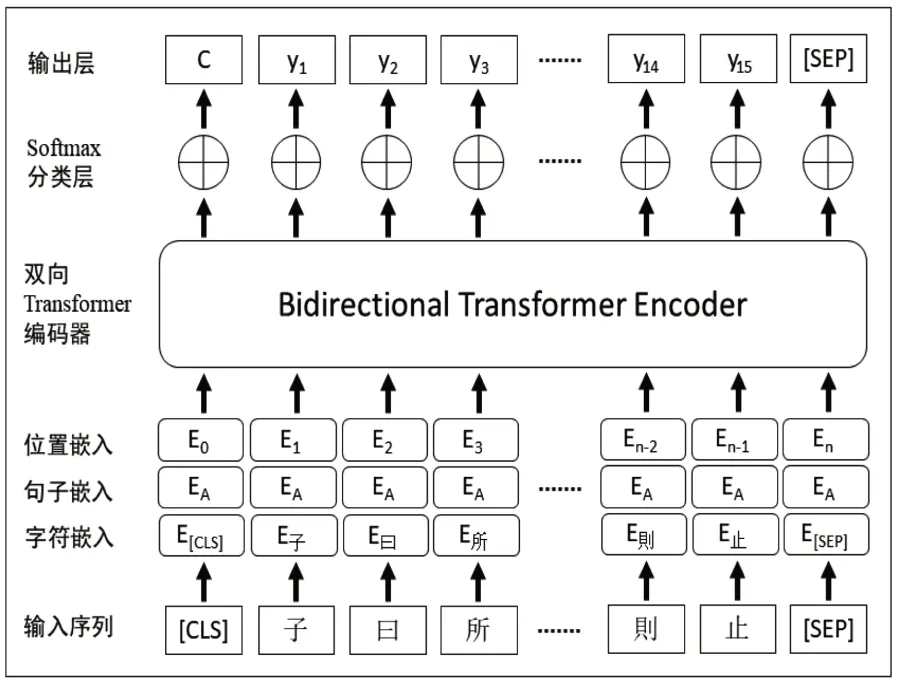
图2 SikuBERT与SikuRoBERTa分类模型架构图
3 《四库全书》子部数据统计分析
通过网络爬虫获取繁体字版本的文渊阁《四库全书》子部全文数据,该语料未经过加注标点符号,也无断句标记。除标题、目录、编撰人信息外,正文部分文本均以段落为最小单位进行组织。此外,注释内容也包含在正文文本中。
3.1 外部特征分析
《四库全书》子部数据集中包含897 部古籍、2,233,410个段落、186,521,284个字符,见图3。图3中数据标签数值显示各类别古籍的具体段落数量。综合段落数和字数分布情况,《四库全书》子部中数据量较大的类别有类书、医家、杂家,数据量较小的类别为法家、兵家、农家等。无论是字数还是段落数,法家类数据量均为最小,类书类的数据量最大。
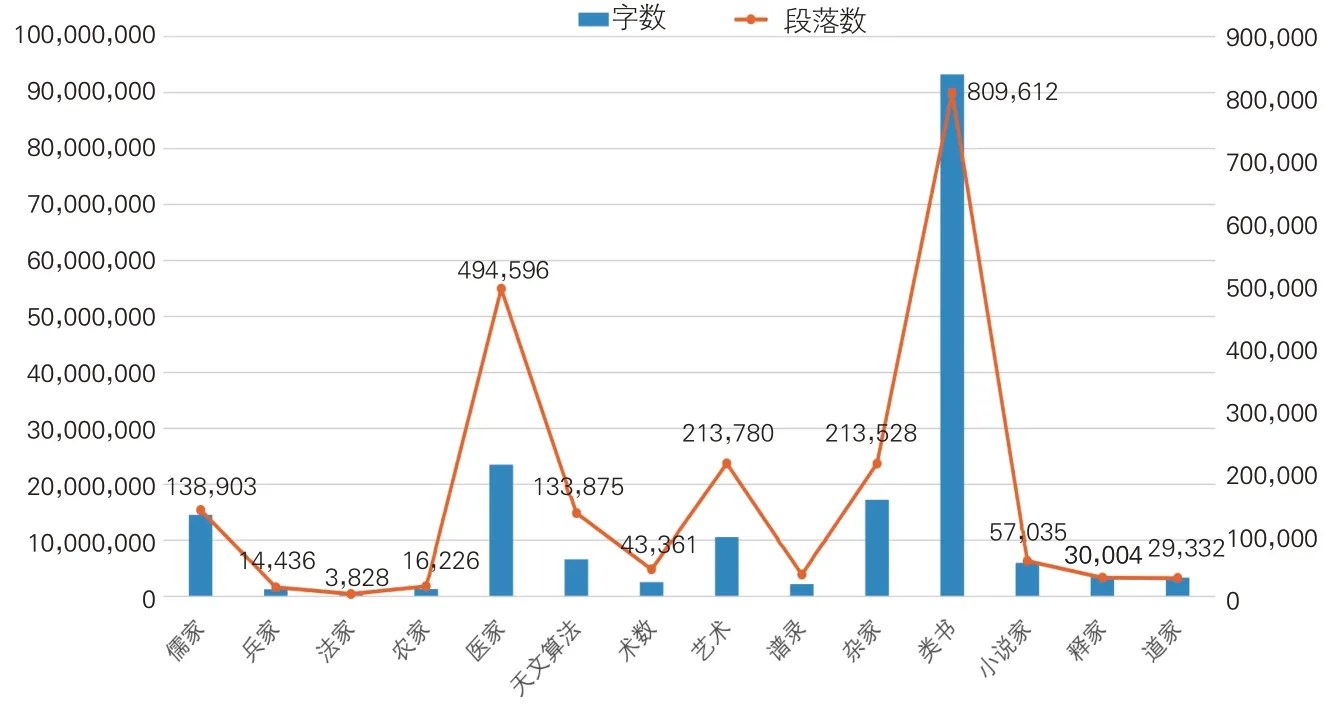
图3 各类别古籍段落数与字数分布
图4 呈现《四库全书》子部中14个类别古籍的平均段落长度。法家类字符数与段落数最少,但平均段落长度最长,每个段落平均由175.48个字符构成。平均段落长度大于100的古籍类别还有儒家、类书、小说家、释家和道家类。医家类数据量位居第二,但平均段落长度最短,每个段落平均仅包含47.55个字符。平均段落长度小于50的类别还有艺术和天文算法。
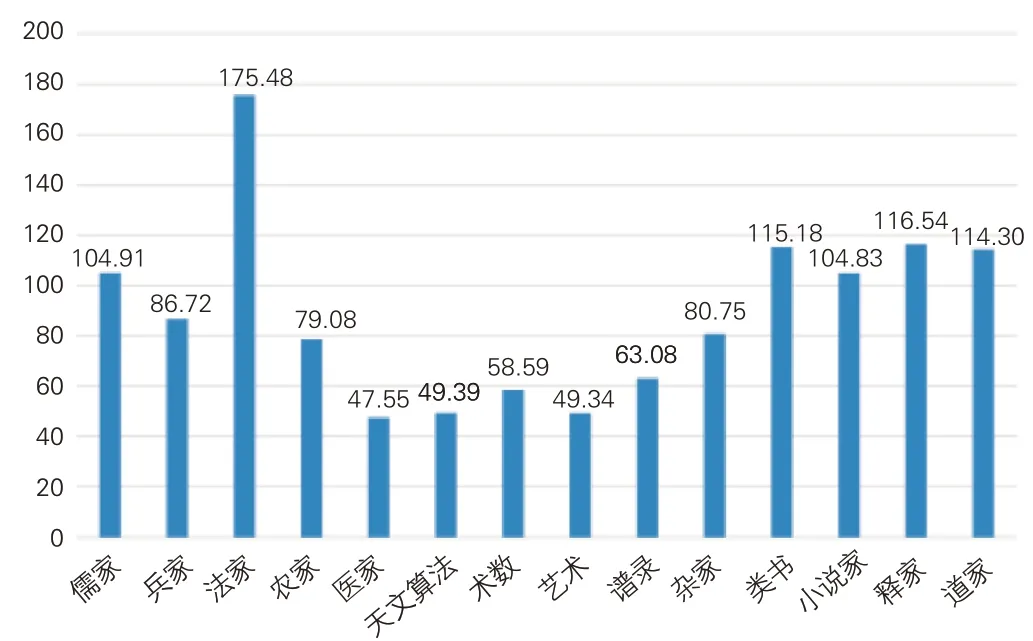
图4 各类别古籍平均段落长度
图5中前14个子图横坐标为段落长度,纵坐标为段落数对应各类别古籍的段落长度分布情况。每种类别的古籍均呈现长度介于1-200的段落数量。各类别段落长度的变化趋势总体相似,在长度1-50内均呈现出明显的下降趋势,在长度大于100 后数量降幅放缓,但各类古籍的段落数量下降趋势与幅度并不相同。例如,医家、艺术、杂家类的段落数量随长度增加下降幅度较大,说明对上述类别,绝大部分段落长度较短。

图5 各类别古籍段落长度分布
图5 中最后一个子图展示了长度小于200的各类别古籍段落数量。其中,类书和医家类图书的段落数量较多,法家、兵家、农家类的段落数量最少。这一分布情况也与《四库全书》子部整体段落的分布相似。表1展示各个类别长度小于200的段落数量占语料库中全部段落数量的百分比,除法家类的占比为79.81%外,其余全部类别均超过80%,有7个类别的占比超过90%,说明各个类别绝大多数段落的长度都在200字以内。
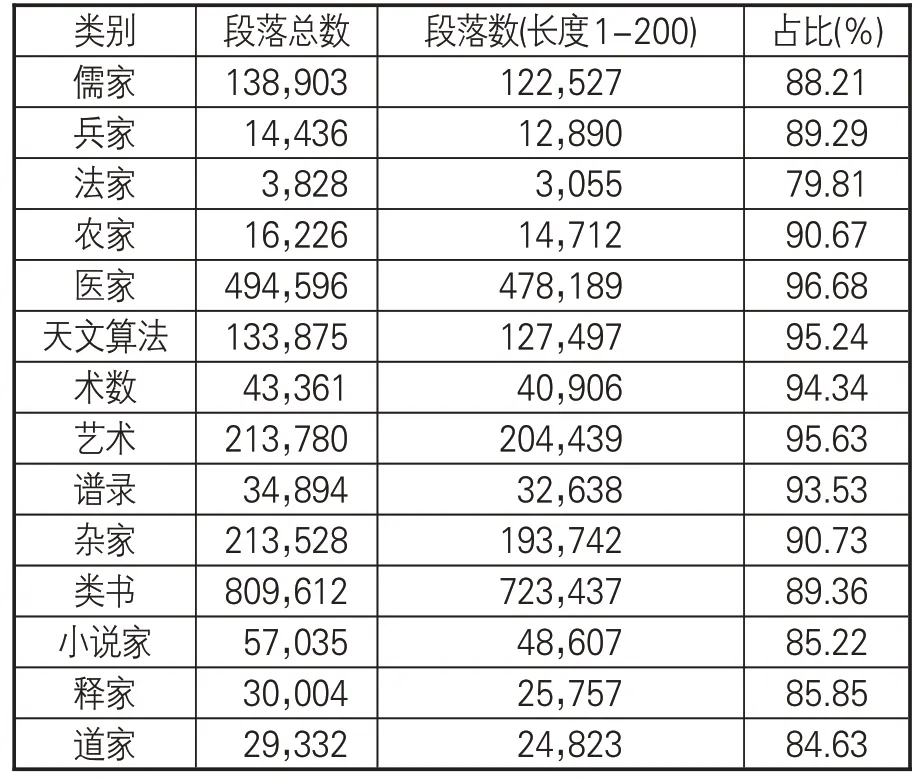
表1 各类别长度小于200的段落占比
3.2 内部特征分析
由于《四库全书》子部语料未经过分词标注,也未进行断句标点,因此本部分从字的角度出发统计各类别古籍的高频一元字。由于古文中含有大量“之”“不”“也”“而”等助词、副词、语气词,没有实际含义,很难体现出类别信息,因此在统计字频时删除上述字。最终得到清洗后各类别高频出现的汉字。为直观呈现不同类别古籍字级别内容的差异,表2 列出字符特征最为明显的6 个类别古籍中的部分高频字。在表2 中,各汉字均明显体现出不同古籍的类别信 息 。 例如,对兵家类古籍,高频出现的汉字 “ 兵 ”“軍”“將”等具有军事与战争的特征;在农家类中,高频字“水”“種”“葉”均与农耕息息相关;艺术类古籍的高频汉字“書”“字”“畫”,均是文学艺术的代表性字词。仅仅通过《四库全书》子部各类别的高频字就可以容易地区分部分古籍的类别特征,说明采用文本自动分类的方式对《四库全书》子部古籍进行类别划分,并构建子部分类体系是可行的。
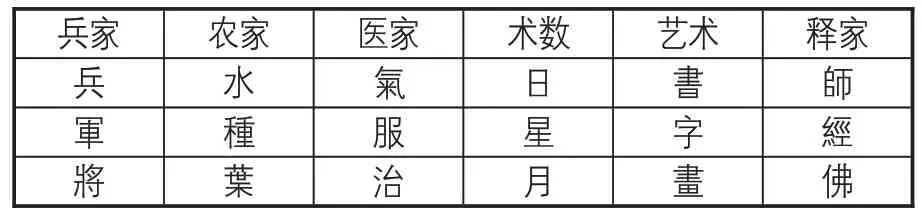
表2 部分类别高频字统计
4 实验与分析
4.1 评价指标
对各类别图书分类性能,采用精确率(Precision)、召回率(Recall)、F值(F-score)指标进行评价。对总体分类性能,使用微平均精确率(Micro_P)、微平均召回率(Micro_R)、微平均F 值(Micro_F)进行计算,公式如下:
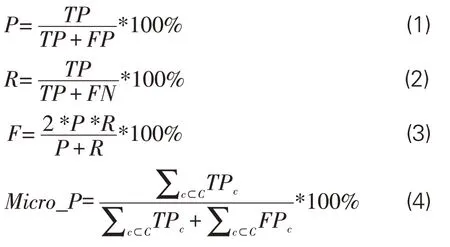
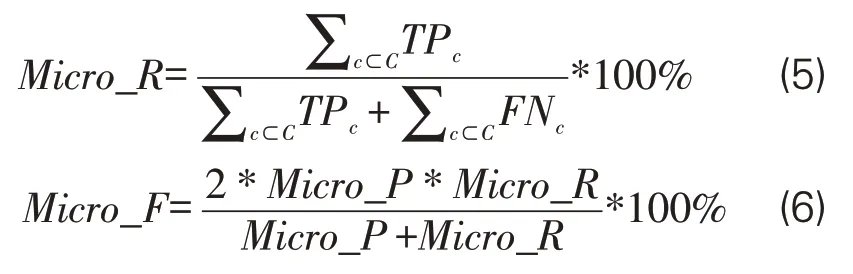
4.2 探索性实验
为获得最佳的超参数设置与数据集选取范围,前期基于SikuRoBERTa模型进行多个维度的探索性实验。
(1)数据清洗程度。在《四库全书》子部语料中除正文文本外,还包含注释信息。此类文本均为编纂《四库全书》时留下的注释,对解释图书内容和体现不同类别的特征具有意义。语料中还包含目录、题名等信息。为探究上述信息的保留与否对整体分类性能具有何种影响,本文对比了保留全部数据、删除注释、删除注释目录标题等3种情况下的效果。从表3可知,保留注释、目录、标题等信息的模型F值最高,说明注释等文本对提升分类性能具有正向作用,因此在构建数据集时对此类解释性文本予以保留。
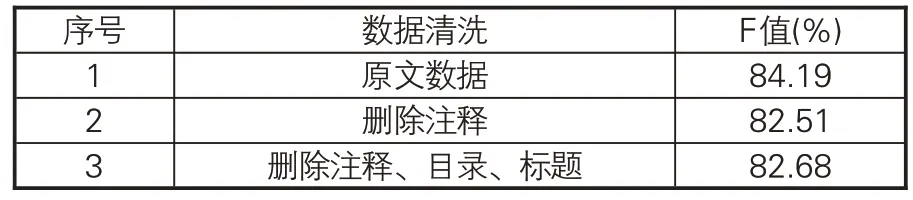
表3 数据清洗程度对模型性能影响
(2)序列长度。由于原始文本未经过断句与标点,均以段落为单位存储,因此模型序列长度的选取较重要。对语料中字数少于10的段落,一方面长度较小,信息量较低,另一方面大多数为“上篇”“欽定四庫全書卷”“總校官【臣】陸費墀”等书名、卷号、编撰校对者信息。据图4-5和表1 可知,各个类别古籍的段落在长度大于100后的数量均较少。为探究不同输入序列长度对模型分类性能的影响,开展表4 所示对比实验,当输入序列最小长度为10,最大长度为128时,模型可获得最优的分类性能。
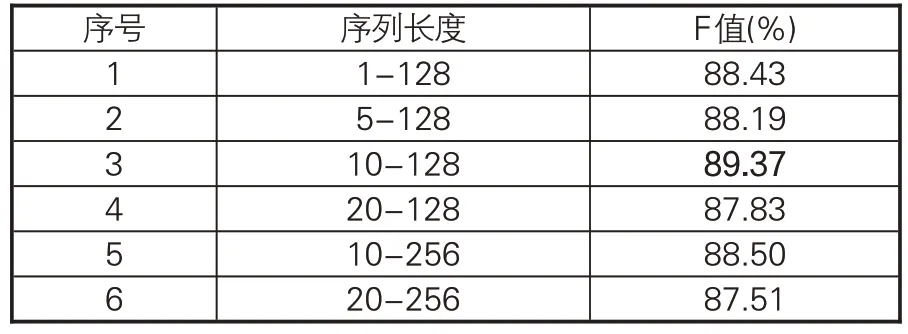
表4 不同序列长度对模型性能影响
(3)数据平衡。由图3可知,14个类别古籍的数据量相差悬殊,数据量最大的类书类的段落数是最小的法家类段落数的200余倍,容易导致模型过度学习大样本类的特征而无法充分提取小样本类的特征。因此,本文探究是否采取类别平衡以及数据量大小对性能的影响。表5中,实验2是以法家类的全部段落数3,828为基准,对其他所有类别进行下采样。实验3是在维持法家类为3,828条数据的基础上,将其他类别均下采样至10,000条数据。实验4全连接指的是将每一本古籍的文本全部按顺序首尾相接,然后按照给定的最大序列长度进行切分,设定的最大序列长度为128。结果表明,全部类别均保留3,828 条数据时可以获得最佳效果。最终构建的数据集包含53,592个段落,共3,263,008个字符。数据集中各类别图书的字数分布情况如图6所示。与图3字数相比,数据集得到了很好的平衡。对学习率、迭代次数等其他超参数的预实验此处不再赘述。综合全部探索性实验的结果,本文最终获得了下一小节所列出的最佳超参数设置。
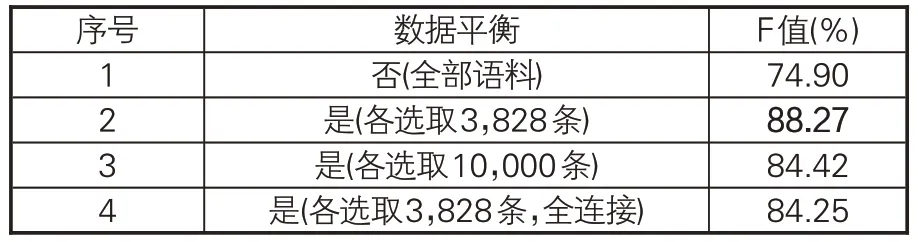
表5 是否采取类别平衡对模型性能影响
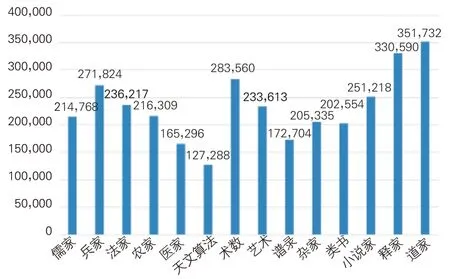
图6 数据集各类别字数分布
4.3 超参数与环境配置
由 于 SikuBERT、 SikuRoBERTa 模 型 和BERT、BERT-wwm、RoBERTa、RoBERTawwm均采用相同的架构预训练,因此采用统一的超参数进行自动分类任务,设置见表6。本文实验环境配置中,CPU:Intel(R)Xeon(R)CPU E5-2650 v4@2.20GHz;内存:512GB;GPU:NVIDIA®Tesla®P40;显存:24GB;操作系统为:CentOS 3.10.0。所有模型均基于Pytorch后端的BERT框架进行训练与测试。用于对比的BERT(https://huggingface.co/bert- base- chinese)、BERT-wwm(https://huggingface.co/hfl/chinesebert-wwm)、RoBERTa(https://github.com/brig htmart/roberta_zh/)和 RoBERTa-wwm(https://huggingface.co/hfl/chinese-roberta-wwm-ext)均选用开源的Pytorch版本预训练模型。
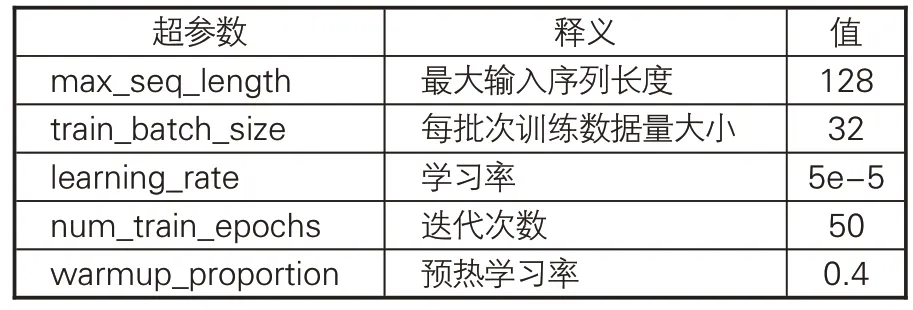
表6 主要超参数设置
4.4 自动分类对比实验
SikuBERT和SikuRoBERTa模型和其他4种用于对比的基线模型均采用十折交叉验证方式进行自动分类任务,取十折实验的均值作为模型最终的评价结果。表7 给出6 种模型在《四库全书》子部上的整体分类性能得分。SikuBERT和SikuRoBERTa 模型表现最优,是因为相较于其他基线模型,二者更充分学习了古文的词法、句法、语义等特征。基于全词遮蔽的BERT-wwm模型在全部3 种评价指标上均超过原始BERT,说明对于BERT模型来说,全词遮蔽的预训练方式更加适合开展面向中文的自然语言处理任务。RoBERTa-wwm在全部模型中表现最差。
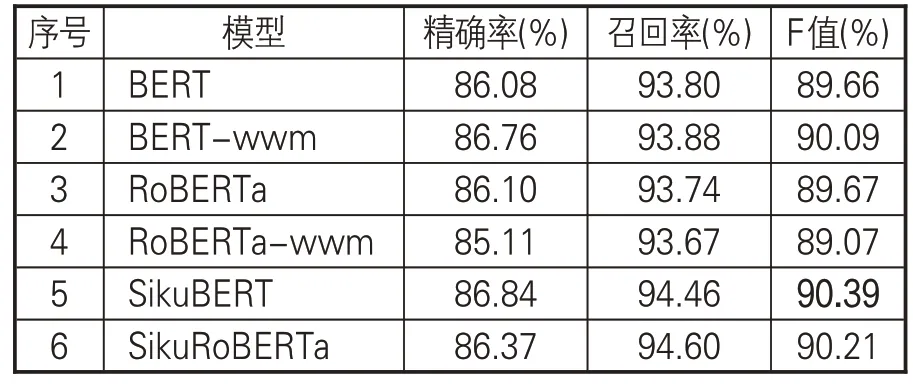
表7 各模型整体分类效果对比
进一步对比SikuBERT 和SikuRoBERTa 模型的各类别古籍具体分类效果,探究模型在《四库全书》子部各个类别上的分类性能。在十折交叉验证中,整体表现最优的SikuBERT模型各类别详细的精确率、召回率、F值的测评得分见表8。在14个类别中,SikuBERT模型对天文算法和释家类的识别在精确率、召回率和F值3种评价指标上均取得较高的得分,而对小说家、杂家、儒家类的分类效果差。这是由于天文算法类书籍具有非常明显的特征,如段落“晦朔㑹為坤象三日朏而出於庚為震象五日上”具有极强的描述天文现象的特征。释家类主要收录佛教书籍,而佛经的篇章结构、段落布局、遣词造句等与其他各类别文本都存在较大差异,因此分类准确率较高。小说家和杂家类图书由于收录范围较广,类别特性相对不明显,因此效果欠佳。
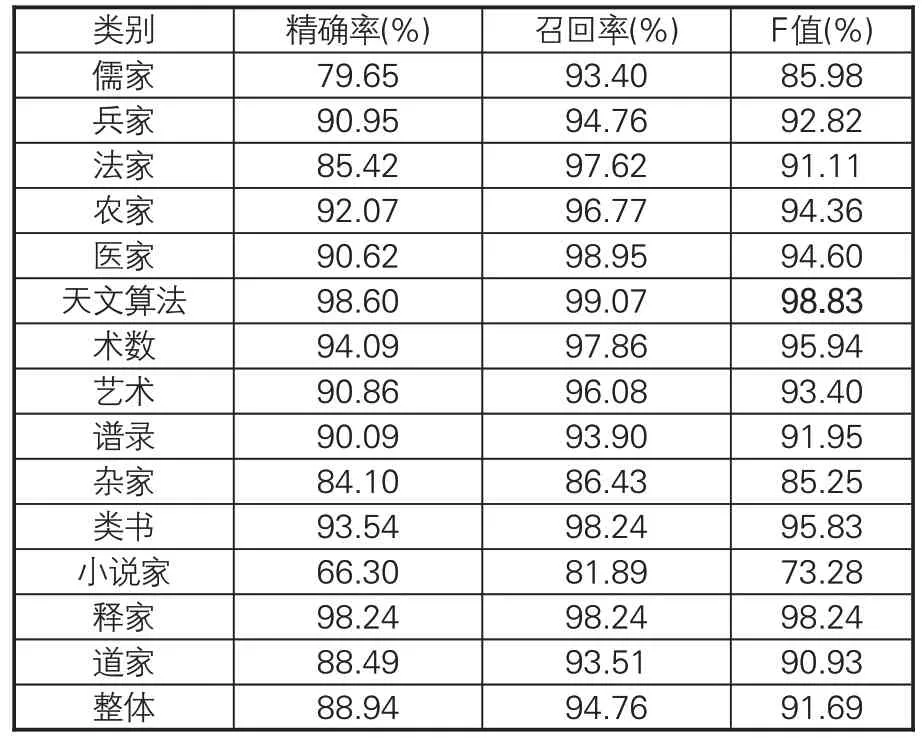
表8 SikuBERT性能最优模型各类别分类效果
对F 值得分排名第二的SikuRoBERTa 模型,表9给出十折交叉验证中各个类别详细的测评情况。SikuRoBERTa 模型同样对天文算法类识别的效果最佳,精确率、召回率和F值均超过98%,再次印证天文算法类图书具有较独特的语言特征。该模型对小说家和杂家类的识别表现差,但F值均超过80%,优于SikuBERT模型在小说家类的分类表现。虽然SikuBERT模型平均F值得分高于SikuRoBERTa模型,但十折交叉中表现最佳的SikuRoBERTa 模型取得92.02%F值,较表现最佳SikuBERT模型提升0.33%。
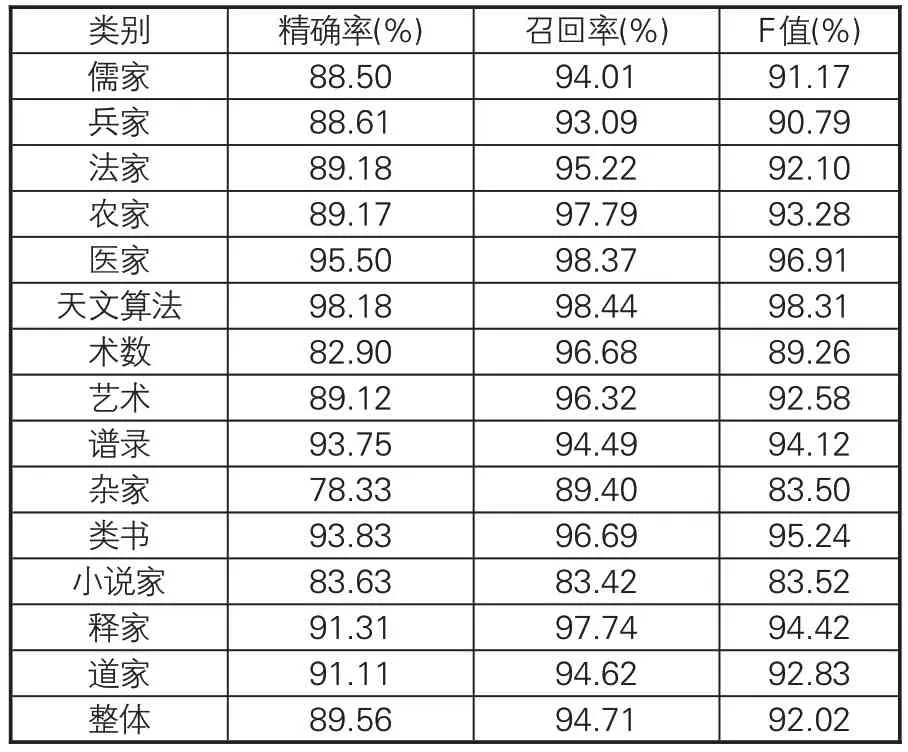
表9 SikuRoBERTa性能最优模型各类别分类效果
综合 SikuBERT 和 SikuRoBERTa 的各类别分类表现,发现模型对天文算法、释家、医家类3种类别的识别效果最好,说明3个类别的文本具有较强的类别特性,文本内容与行文手法相对较为独立,自成一派。两种模型对小说家和杂家的识别表现差,说明一方面小说家和杂家类书籍收录范围较广泛,涵盖各家之长,形式多样,内容繁多,共性特征不明显;另一方面,说明预训练语言模型对类别特征存在交叉的文本进行分类时,存在改进空间。表10列出各模型在十折交叉验证中表现最佳的模型整体分类效果,无论是十折交叉的平均结果,还是表现最佳的一折模型,SikuRoBERTa模型和SikuBERT模型均取得最优的分类性能。
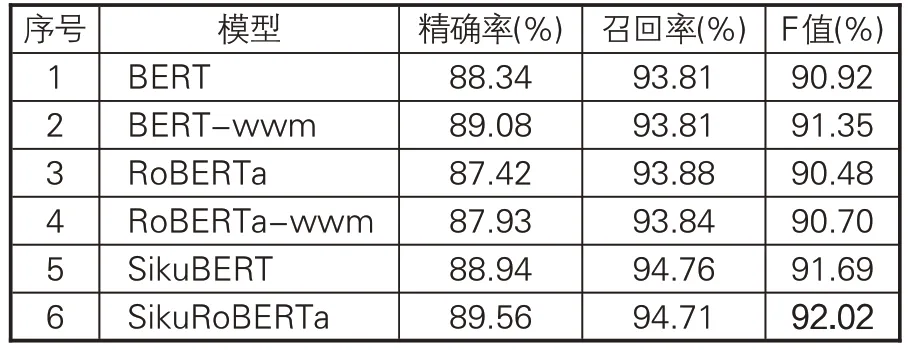
表10 十折交叉最佳模型整体分类效果对比
4.5 自动分类预测结果对比
为更细致地检查模型对各类别古籍的分类效果,分析错误分类,设计自动分类预测对比任务。首先,随机从子部14个类别的古籍中采样一定数量的段落,用以构建古籍类别自动预测数据集。其次,采用6种模型中各自十折交叉表现最优的模型,对该数据集进行自动标注,实现对古籍段落类别的预测。最后,从宏观和微观角度对比各模型正确预测类别的段落数量。6种模型具体自动分类结果见表11。SikuRoBERTa在全部模型中表现最优,测试集中95.30%的段落都被正确归类到所属古籍类别。紧随其后的SikuBERT模型分类正确率也超过95%。BERT和RoBERTa-wwm 模型均取得94.53%的分类正确率,在全部5,231个段落中将4,945个段落正确归类。本文提出的方法在自动分类预测任务中的表现优于基线模型,能精准正确预测典籍文本所属古籍类别。
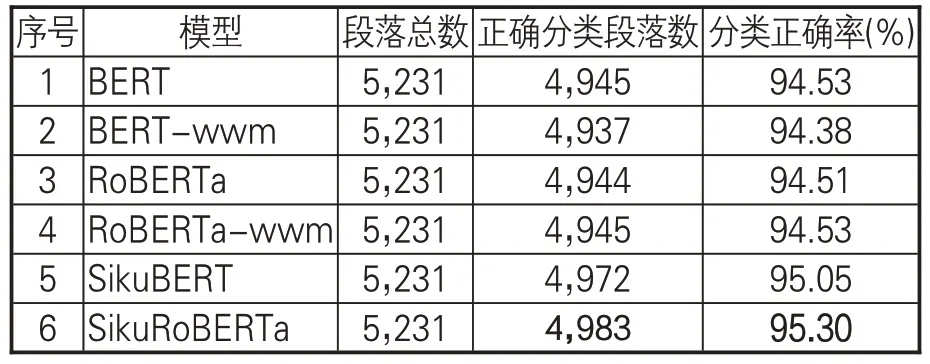
表11 各模型自动分类预测效果对比
对预测效果较好的SikuBERT 和SikuRoBERTa 模型,进一步按照子部14 个类别,给出每个类别模型预测正确的段落数量,以及错误预测为其他类别的段落数量,从微观角度对模型的分类性能进行分析。表12-13分别是SikuBERT和SikuRoBERTa 模型的自动分类预测结果汇总,纵向为段落的真实类别,横向为模型自动预测的类别。
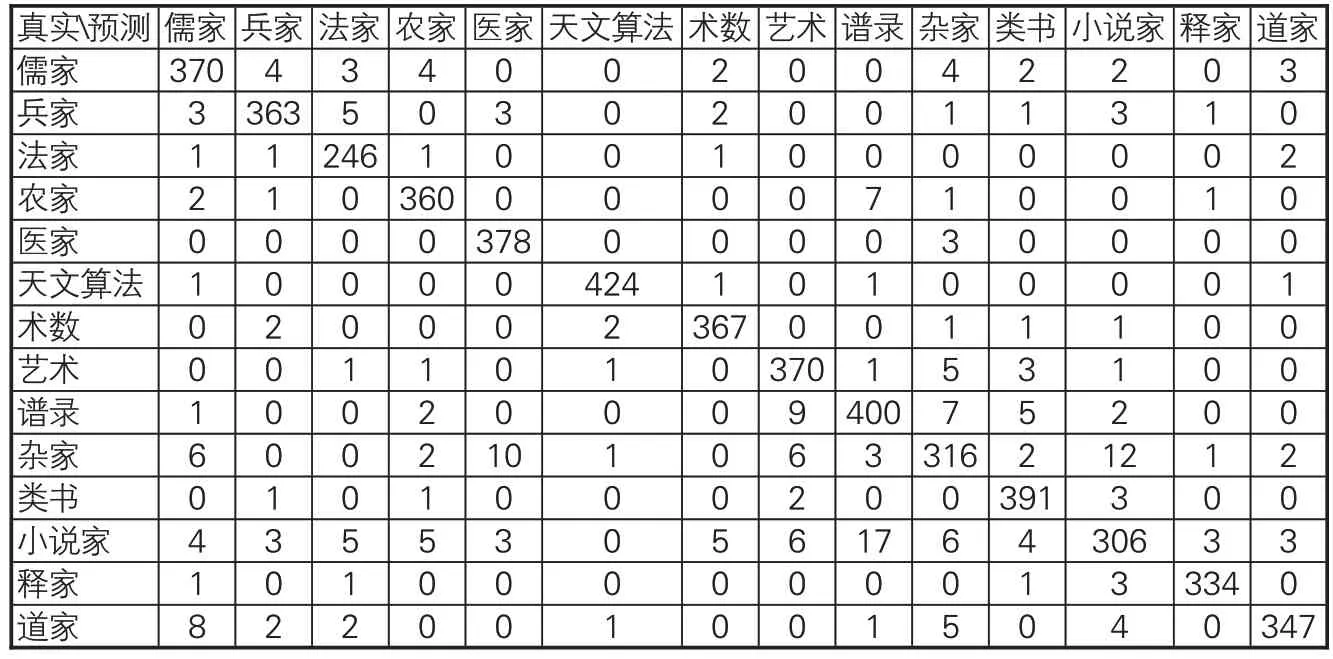
表12 SikuBERT自动分类预测结果
绝大部分类别的预测结果正确,且错误预测的类别数量也相对较少。但在杂家类361 个段落中有10 个被错误预测为医家;在小说家类370 个段落中,17 个段落被错误的预测为谱录类。进一步检查被错误预测的段落原文,如小说家类的文本“紅沫練丹砂爲黃金碎以染筆書入石中削去逾明名曰紅沫”被错误的预测为谱录类。而在子部总序中对谱录类的描述为:“《诗》取‘多识’,《易》称‘制器’,博闻有取,利用攸资,故次以谱录。”[1]因此,推测可能是此段落和谱录类文本的内容特征存在相似之处,模型错误地将其预测为谱录类。
SikuRoBERTa 模型整体预测错误率低,但与SikuBERT模型类似,杂家类有9个段落被错误归类为医家类,小说家类中有9 个段落被错误归类为杂家,道家类有10个段落被归类为儒家类。检查分类错误的原始段落,发现通常是该段落具有被错误划分类别的特征。例如,杂家类段落“香身丸治遍身熾氣惡氣及口齒氣”,具有明显的医学类古籍语言与内容特征,被SikuRoBERTa 模型错误预测为医家类。再如,道家典籍《庄子》中的段落“知天之所為知人之所為者至矣”,被错误预测为儒家类。由于道家和儒家均有对天与人思想的阐述,因此模型未能很好区分该段落的类别信息。

表13 SikuRoBERTa自动分类预测结果
5 古籍自动分类模块构建及应用
为实现对古籍文本的多粒度、多维度、智能化处理,辅助学者以便捷的可视化方式开展数字人文科研,本文基于SikuBERT预训练语言模型构建了古籍自动分类模块,并融入单机版SIKUBERT典籍智能处理系统。该系统基于Python程序语言设计,采用PyQt5工具包搭建平台并实现前端与后台数据传输,其主界面见图7。

图7 SIKU-BERT典籍智能处理系统主界面
系统提供单文本处理和语料库处理两种入口,可根据数据量大小选择最适合的处理方式。用户可调用训练好的SikuBERT 预训练语言模型,仅通过鼠标点击方式,即可实现对古籍文本的自动分词、词性标注、自动分类等功能。在典籍智能处理过程中,用户无需掌握复杂的编程知识,也不需要了解自然语言处理的基本原理,上手即用。图8是单文本模式下,调用典籍自动分类模块对古文进行自动类别判断的示例。

图8 SIKU-BERT典籍自动分类模块(单文本模式)
在图8界面的左侧为原始文本输入框,此处输入的“孔子曰其如示諸斯乎指其掌……施諸已而不願亦勿施於人此又掠下教人”选自儒家类古籍。界面右侧文本框用于输出分类结果。用户点击“自动分类”按钮后,系统自动调用SikuBERT模型对其进行类别判定,最终正确识别出该输入文本的四库子部分类法类别为“儒家类”。图9展示系统对用户本地语料库进行批量自动分类的过程。

图9 SIKU-BERT典籍自动分类模块配置过程(语料库模式)
用户点击“浏览”按钮分别选择待分类语料库所对应的文件夹路径,以及分类后文本的输出路径,系统即会在信息提示框中输出语料库中全部待分类文本的路径信息。点击“自动分类”按钮后,系统会调用SikuBERT古籍分类模型进行自动分类,并在信息提示框中动态显示当前处理进度(见图10)。全部分类完成后,用户进入输出路径,即可查看语料库中文本经模型预测后,被自动分类的古籍类别信息。
图10 SIKU-BERT典籍自动分类模块运行过程(语料库模式)
6 结语
本文基于面向古文自然语言处理与自然语言理解的SikuBERT 与SikuRoBERTa 预训练语言模型,分别构建两种四库子部典籍自动分类模型,实现对古汉语文本的类别自动划分。在此基础上开发SIKU-BERT典籍智能处理系统,提供典籍自动分类工具。本文提出的模型在自动分类与预测上的表现均优于用于对比的BERT、BERT-wwm、RoBERTa、RoBERTa-wwm基线模型,具有较强的分类准确性与鲁棒性。开发的典籍自动分类工具可服务于古汉语文学、历史学、语言学等学科研究,减少人力、物力与时间成本投入。
未来一方面将采用上采样与下采样结合的方式,增加参与训练的数据量,筛选能够全面涵盖类别特性的古籍参与训练,进一步提升分类效果;另一方面,将Transformer 架构替换为Transformer-XL,实现对长文本的学习,并尝试对数字化后的现存典籍残本进行类别预测。此外,由于当前基于BERT改进的预训练模型大多基于字级别数据进行预训练,为了保证上下游数据的一致性,目前采用的《四库全书》子部语料为未经过分词标注,也未添加断句与标点符号的字级别文本,缺失了词汇和句子特征,可能在一定程度上会对最终分类结果产生影响。在后续的研究中,拟采用人工与算法相结合的标注方式,对原始文本进行加工,构建更适用于文本分类任务的数据集。
猜你喜欢
小学阅读指南·低年级版(2022年5期)2022-05-09
湖南科技学院学报(2021年2期)2021-12-14
汉字汉语研究(2021年3期)2021-11-24
天一阁文丛(2020年0期)2020-11-05
天一阁文丛(2020年0期)2020-11-05
天一阁文丛(2020年0期)2020-11-05
小学阅读指南·低年级版(2020年9期)2020-10-12
布达拉(2020年3期)2020-04-13
阅读(快乐英语高年级)(2020年9期)2020-01-08
天一阁文丛(2019年0期)2019-11-25
