
贵州省喀斯特区土地利用变化及驱动力分析
2022-12-13 12:13:44罗笑,卢鹏
贵州林业科技 2022年4期
罗 笑,卢 鹏
(贵州省林业调查规划院,贵州 贵阳 550003)
土地是人类赖以生存的物质基础,近些年来,贵州社会经济发展和各项基础设施建设飞速发展,省内土地利用也发生着剧烈的变化。在城市化和工业化的过程中经济有所增长,但是也带来了一系列诸如气候变化、环境污染等问题。因此,合理利用土地资源也是当前贵州持续发展的重点。开展土地利用变化的研究,有利于贵州省土地资源的合理配置、开发和保护,有利于实现生态、环境、经济的协调发展。影响土地利用的因素有很多,彼此之间的关系也不是简单的线性作用,了解动态因素和驱动过程,有利于揭示土地利用动态机制。
1 材料与方法
1.1 研究区概况
贵州省简称“黔”,地处中国西南腹地,是西南交通枢纽。国家生态文明试验区,内陆开放型经济试验区。贵州境内地势西高东低,自中部向北、东、南三面倾斜,高原山地居多,是全国唯一没有平原支撑的省份。属亚热带湿润季风气候,四季分明、春暖风和、雨量充沛、雨热同期。气温变化小,冬暖夏凉,气候宜人。降水较多,雨季明显,阴天多,日照少。贵州河流处在长江和珠江两大水系上游交错地带,是长江、珠江上游地区的重要生态屏障。贵州省是世界上岩溶地貌发育最典型的地区之一,根据喀斯特数据中心公布的岩溶面积显示,贵州省岩溶出露面积占全省总面积的61.92%,是全国石漠化面积最大、类型最多、程度最深、危害最重的省份[1],各类型石漠化均有分布,也是石漠化与影响因子关系研究的典型地区。
1.2 数据来源
本研究使用的贵州省DEM数据,来源于美国奋进号航天飞机的雷达地形测绘SRTM数据,使用GIS软件,得到焦点统计和栅格计算器工具提取出贵州省地形起伏度数据。土地利用数据来源于中科院资源环境科学数据中心。全省GDP和人口数据来源于中国科学院资源环境科学数据中心,人均GDP数据利用GIS软件栅格计算机对人口和GDP数据计算获得。铁路、公路、水系数据来源于全国地理信息资源目录服务系统,由该网站获得相应矢量数据。各县(市)喀斯特比例分布数据来源于熊康宁教授[2]。
1.3 研究方法
Friedl等[3]利用单变量决策树法进行全球范围内的土地覆盖分类,在大尺度的土地利用分类中有比较好的稳定性;刘世梁等[4]使用向量机分类对广西沿海进行监督分类,精度较高,但是以上这两种情况都会产生椒盐现象,产生大量碎班,对分类的效果产生不利影响;渠爱雪等[5]使用土地利用现状图和遥感影像对徐州土地利用的空间变化进行分析,但是过程繁杂,由于地表覆盖物光谱具有易混淆性和异质性,一般的方法很难将道路与城市其他地物划分开。在土地利用变化的驱动力研究过程中,许多学者采用的方法主要有主成分分析、相关分析、回归分析、系统动力学模型和人工神经网络等方法[6-10]。随着土地利用现状数据和卫星遥感数据的普及,逻辑斯蒂回归模型逐渐成为土地利用变化研究中比较常用的方法,该方法解决了线性回归不适用于因变量为分类变量的问题[11]。
对土地利用数据进行重分类,使用土地利用转移矩阵对1990、2000、2010、2018年土地利用数据进行分析,了解转移前后各地类结构特征[12]。转移矩阵模型为:

(1)
借助转移矩阵分析综合利用动态度,综合地类动态度表示地形因子对研究区内各种地类变化的综合影响[13]。其数学模型为:
S=[∑ni=1(△Si-j/Si)]×100×1/t×100%
(2)
式中:△Si-j为研究时段内第i类地类转换为其他地类的面积:Si为研究开始时间第i类地类的面积;t为研究的时间段。
利用逻辑斯蒂回归模型研究土地利用变化的驱动力,驱动力研究旨在研究土地变化背后的驱动因素和其作用机制,是一种动态的模拟。逻辑斯蒂回归模型是研究1个因变量和多个自变量之间的多元回归关系,从而预测土地变化的概率[14]。逻辑斯蒂回归模型假定这个概率能表达为如下形式:
Pi=exp(β0+β1X1+……+βnXn)/[1+exp(β0+β1X1+……+βnXn)]
(3)
式中:Pi为概率值:exp为指数函数。
目前,SPSS、SAS等软件都可以实现逻辑斯蒂回归分析,本文利用SPSS软件进行该逻辑斯蒂回归分析。
1.4 数据处理
1.4.1 土地利用变化
本文选取1990、2000、2010和2018年四个年度的土地利用数据进行动态分析,通过GIS重分类工具将土地利用数据划分为耕地、林地、草地、水域、城乡居民用地和未利用地六种一级地类。分析28 a间四个时期的土地利用面积和各项地类的动态转移度。
通过表1分析,耕地在1990年至2018年间呈现先增后减的趋势,这和近十年内贵州省经济迅速发展有一定的关系,基础设施建设增加,间接导致耕地面积的减少。
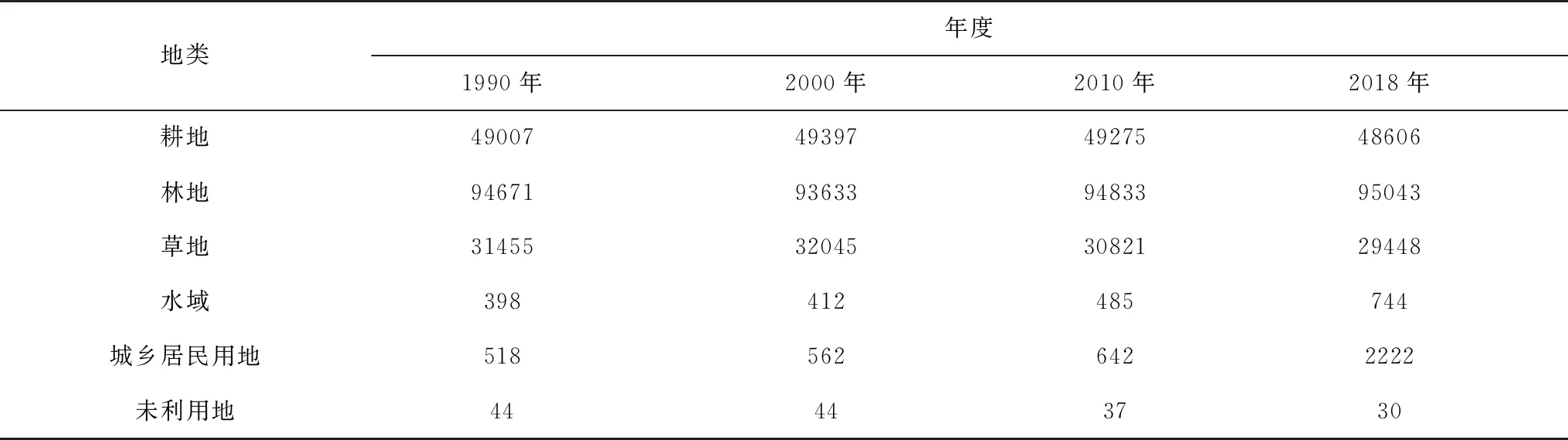
表1 各年度分面积统计表 km2
而林地呈现出先减后增的趋势,2000年为林地面积最低点,2000年后,贵州大力保护生态发展,之后的2010年和2018年保证林地面积的稳步增长。
草地先增后减,从表面看草地面积有所下降,但是根据动态度分析可得出,草地减少的部分逐渐转移为林地,是生态环境越来越好的表现。
水域则是由最初的398 km2逐渐增加,2000年为412 km2,2010年为485 km2,2018年为744 km2。根据贵州省水利厅统计年鉴数据,截止2019年全省一共建设大中型水库111座,蓄水量达287.11亿m3。大中型水电站的建设促使贵州省水域面积的增加。
随着经济的飞速发展,城乡居民用地呈现井喷式增长,1990、2000、2010年还维持在518至642 km2的水平中,从2010年到2018年短短八年的时间,城乡居民用地增长近3.5倍。
贵州省未利用地本来非常少,从面积的变化中可以看出未利用地有所减少的趋势。
1.4.2 土地利用转移
利用转移矩阵可以得出1990年和2018年两个年度土地利用类型相互渗透和转移的情况,本文利用GIS栅格计算器的功能计算1990至2018年间土地利用转移矩阵,得到表2。

表2 土地利用转移矩阵表 km2
由表2可以看出,1990年和2018年两个年度各种土地类型的转移情况,耕地、林地和草地之间转移比较多,因为这三种土地类型的面积也最多。前面分析的草地的转移情况,由表2可以看出,草地的减少是因为原面积的40%都转移成了耕地和林地,所以导致草地面积的下降。这三种大样本土地类型分别向城乡居民用地转移了959 km2、562 km2和391 km2,这也促成了城乡居民用地面积的猛增。
表3综合利用动态度从大到小依次排序为:城乡居民用地、水域、未利用地、耕地、草地和林地。

表3 综合地类动态度表
1.4.3 自变量处理
本研究共选取喀斯特出露面积、DEM、地形起伏度、水系密度、铁路密度、公路密度、人均GDP、人口、GDP共9个自变量因子。选取这9个因子的过程中已经通过查阅相关文献剔除和土地变化驱动力相关性不大的因子。
本文采用的自变量因子所使用的栅格数据分辨率均为1KM*1KM,和因变量分辨率大小一致。以GDP数据为例,GDP是社会经济发展、区域规划和资源环境保护的重要指标之一,通常以行政区为基本统计单元。GDP空间化以空间统计单元代替传统的行政统计单元,为多领域之间数据共享、进行空间统计分析带来极大便利。贵州省GDP空间分布公里网格数据集在贵州省分县GDP统计数据的基础上,综合考虑了与人类经济活动密切相关的土地利用类型、夜间灯光亮度、居民点密度等多因素,利用多因子权重分配法将以行政区为基本统计单元的GDP数据展布到栅格单元上,从而实现GDP的空间化。
该方法首先计算土地利用类型、夜间灯光亮度、居民点密度的GDP分布权重,进而在对上述3方面影响权重标准化处理的基础上计算各县级行政单元的总权重,然后在计算各县级行政单元单位权重GDP占比的基础上,运用栅格空间计算,把单位权重上的人口数与总权重分布图相结合,进行人口的空间化。计算公式为:
GDPij = GDP × (Qij/Q)
(4)
式中,GDPij是空间化之后的栅格单元值;GDP为该栅格单元所在的县级行政区单元的GDP统计值;Qij为该栅格单元的土地利用类型、夜间灯光亮度、居民点密度的总权重;Q为该栅格单元所在县级行政单元的土地利用类型、夜间灯光亮度、居民点密度的总权重。
1.4.4 因变量处理
本研究主要研究的是土地类型的变化,所以因变量的值就存在两种情况,一种是变化,另一种是维持不变。利用GIS空间分析工具,将两期土地利用数据对应值进行差异化处理,并使用栅格计算器进行变化分析。然后进行重分类处理,便可以得到二分的因变量数据,将变化栅格值取为1,未变化栅格值取为0。
2 结果与分析
将因变量和自变量数据处理完成后,每个栅格单元都有对应值,分别代表因变量和自变量所代表因子高低程度的值。为了便于分析,将自变量因子均划分为五个等级,利用GIS重分类工具的分位数分级法分为5级,分别对应新值1、2、3、4、5,以便于在逻辑斯蒂回归分析中做分析使用。
本文使用的栅格均为1KM分辨率,采用GIS转换工具将因变量因子栅格转换为点,此时属性表中grid_code值分别为0和1,1值栅格即为发生土地利用变化的栅格斑块,0是未发生变化的斑块。然后对9个自变量的栅格对应值提取,将属性中缺失值剔除。在样本点中随机提取出土地利用变化和未变化的样本点,经过模型精度分析,逻辑斯蒂回归方程具有90%以上的预测概率,此时方程中的预测值才准确。

表4 Hosmer 和 Lemeshow 检验
Hosmer和 Lemeshow 检验是检验模型的拟合优度。当Sig值不小于检验水准时(即P>0.05),认为当前数据中的信息已经被充分提取,模型拟合优度较高。P=0.066,故该模型的拟合优度较高。
如表5所示,在已参与分类预测的随机点中,变化的图斑有97.3%预测准确,未变化的图斑有60.6%预测准确,总计预测精度达到93.4%,证明此逻辑回归方程精确度达到93.4%。预测结果可信。

表5 分类表
利用随机点对应的值,使用二元逻辑斯蒂回归分析,结果见表6。

表6 方程中的变量
表6中,B为模型常数项估计值,S.E为B的标准误差,Wals为Wald卡方检验,df为自由度,Sig.为差异性显著的检验值,Exp (B)为系数。
根据表6列出的逻辑回归方程为:
lg(P0/1-P0)=-0.003+0.122X1-0.003X2+1.724X3-0.33X4-0.763X5+0.701X6+0.518X7-1.088X8+0.260X9
由表6可以看出,Wals统计量值较大的自变量因子有铁路密度、喀斯特程度、人均GDP、地形起伏度、GDP,表示以上自变量因子在该逻辑回归方程中更加重要。
分析结果可以看出,贵州省1990年至2018年间土地利用变化与人均GDP、GDP、铁路密度、水系密度、DEM呈正相关。人均GDP每增加1个单位,土地利用变化发生的概率变为原来的2.016倍;GDP每增加1个单位,则土地利用变化发生概率变为原来的1.679倍;铁路密度每增加1个单位,土地利用变化发生的概率变为原来的5.608倍;水系密度每增加1个单位,土地利用变化发生的概率变为原来的1.129倍;DEM每增加1个单位,则土地利用变化发生概率变为原来的1.297倍。
人口、公路密度、地形起伏度和喀斯特程度的增加会减少土地利用的变化。人口每增加1个单位,则土地利用变化发生概率变为原来的0.967倍;公路密度每增加1个单位,则土地利用变化发生概率变为原来的0.997倍;地形起伏度每增加1个单位,则土地利用变化发生概率变为原来的0.377倍;喀斯特程度每增加1个单位,则土地利用变化发生概率变为原来的0.466倍。
3 结论与讨论
以上分析可以看出,贵州省1990年至2018年间土地利用变化的驱动力主要是在人均GDP、GDP、铁路密度、水系密度、DEM。GDP作为代表一个区域经济发展水平的指标之一,经济发展得越快,基础建设和城市扩张就越是加显著,所以土地利用变化会变得更加剧烈。而铁路密度的增加本来会改变沿线的土地利用,在特殊区域例如火车站点的地方也会随着铁路的出现形成人群密集区域,从而改变土地利用类型。自古以来河流旁最容易形成人群聚集地,人类对水系旁土地利用变化的贡献大于任何一种生物。DEM和地形起伏度的影响应该相对来看,贵州属于高原,高程相对较高,基础建设等土地利用变化剧烈的措施在高程较高处也经常发生,地形起伏度越大表示单位面积内的地形切割越大,则区域内部的土地利用越稳定。
人口、公路密度、以及喀斯特程度和土地利用变化概率成负相关。喀斯特程度越高代表岩石裸露率越高,难以进行建设利用,因此会降低土地利用变化的几率。本研究中,对建设用地未进行细分类,而公路也属于建设用地,人口密集的地方主要以建设用地为主,转移为农田、林地、草地等土地利用类型的几率较小,所以和土地利用类型变化概率成负相关关系。
猜你喜欢
贵州畜牧兽医(2022年6期)2022-12-29 03:17:48
中国药房(2022年7期)2022-04-14 00:34:30
科技创新与应用(2021年31期)2021-11-09 13:11:18
——与非适应性回归分析的比较
四川精神卫生(2019年2期)2019-06-18 02:45:00
自然资源情报(2018年8期)2018-12-28 00:53:56
文理导航(2017年20期)2017-07-10 23:21:03
领导决策信息(2017年17期)2017-06-21 09:51:17
中国交通信息化(2015年11期)2015-06-06 06:51:36
弹箭与制导学报(2015年1期)2015-03-11 15:32:23
雷达学报(2014年4期)2014-04-23 07:43:13
