
基于卷积神经网络的5G蜂窝网络无线定位方法
2022-12-13 05:39熊星月何至军周志成
数据采集与处理 2022年6期
熊星月,何 迪,何至军,周志成
(1.上海交通大学电子信息与电气工程学院北斗导航与位置服务上海市重点实验室,上海 200240;2.北京集智数字科技有限公司,北京 100871;3.深圳达实智能股份有限公司,深圳 518057)
引 言
在无线定位领域,传统的定位方式包括:使用接收信号强度指示(Received signal strength indica‑tion,RSSI)[1]、到达时间(Time of arrival,TOA)[2]、到达时间差(Time difference of arrival,TDOA)[3]、到达角(Angle of arrival,AOA)[4]等数据的三边定位,这些计算型的定位方式有较高的硬件要求;同时使用这类数据的指纹定位,其算法简易设备简单但应变与抗干扰能力差,需要频繁更新数据库的概率更高,但在室内等遮挡环境下相对计算型的定位方式,定位精度也相对更高。
深度学习由于其强大的功能性在不同领域得到广泛应用[5]。深度学习和机器学习的主要目的是让计算机能够仿照人类大脑积累的经验来进行各类判断,目前在图像的分割与分类[6]、大数据处理[7]、人体运动分析[8]等领域取得了较好的应用成果。然而在三维空间的测距与定位方面,深度学习被使用的频率和深入程度都有待提升。现阶段已有的深度学习相关定位方法基本滞留于两个方面:使用固定时间间隔上传的图片或摄像头实时捕捉的画面对已知事物的画面定位与景深测定[9];使用多个不同位置天线数据上的无线通信的RSSI或信道状态信息(Channel state information,CSI)来进行预先规划的分区指纹信息登录与训练,进而进行深度学习后运用相同数据自动分类定位[10‑11]。华为等企业也使用以天线矩阵为基础,辅以物联网(Internet of things,IOT)等方案进行精确的室内定位,但并未使用具体的深度学习方案[12]。本文基于深度学习算法,使用无线通信对信道传输中的各类特征值进行训练,使用神经网络回避指纹定位中庞大的指纹库与随指纹库正比例增长的分类计算复杂度,结合深度学习算法在学习完成后的分类高效性与抗干扰能力,最终实现一套易于在移动终端配置、抗干扰性更强、定位实时性更高的无线定位方案。本文方法与现有深度学习方案的区别在于:本文对卷积层在无线定位功能的深度学习网络中的功能特殊性做出假设,随后在分析与实验中对该假设进行验证,构成了性价比更高的无线定位方法。
1 研究背景与相关工作
针对无线移动通信系统天线接收信号数据深度学习的无线定位方法,目前已有许多学者对其进行了相应的研究。因此,面向这种智能信号处理与传统无线定位技术相融合的新兴技术,本节首先对已经提出的一些理论和方法作简要介绍和分析。
由于在室内环境下全球导航卫星系统(Global navigation satellite system,GNSS)信号接收较弱,文献[13]使用卷积神经网络对摄像头内的视频进行分类来实现对室内停车场的汽车进行定位,该定位分为3个步骤:首先对摄像头的视频信息进行逐帧缓存,并对相邻帧进行差值比较,当该值大于设定阈值时认为摄像头内的物体产生了运动,对这些帧数进行第2步处理,否则不进行后续处理;然后将第1步中获取的224像素×224像素图像输入精调试的GoogleNet中进行车辆与非车辆的分类判定;最后通过计算得到图像中车辆相对于摄像头的位置并确认车辆的定位坐标。该方案最终在多个视频样例中达到了至少65.69%的准确率。这种定位方式的不足之处在于需要使用高成本设备,如摄像机,因此很难在较大的室内场景进行高覆盖率的配置,并且对于视频信号的处理较为繁杂,需要使用更复杂的神经网络进行训练与后续分类,最终的参数数量过于庞大且必须要有服务器支持,不适用于移动端配置。
文献[14]提出了一个基于对Wi‑Fi的RSSI数据进行深度学习的室内无线定位方法。在该方法中使用了一个包含5层隐藏层的深度神经网络,同时使用了多达520个Wi‑Fi接入点(Access point,AP)来制作特征样本,但该方法的定位对象仅精确到建筑与楼层,而不涉及更具体的位置定位。同时文献[14]也指出了对于缺省的AP应当使用对模型冲击更小的数值作为默认值,这个默认值一般可以设为接近合法样本中同类数据最小的值。该文献使用的AP数量较多,在实际应用时其硬件条件较难实现,同时由于隐藏层数量很少,即使使用了大量AP进行特征量的补充,其定位精度依然非常低下,仅仅能区分出目标所在的建筑物与楼层。
文献[15]研究了输入数据预处理与数据增强对利用深度学习的无线定位方法的影响。文中使用的数据为移动网络基站的小区信号,对每个小区信号记录其移动通信网络中小区的编号(Cell ID,CID)与接收信号强度(Received signal strength,RSS),其中CID为标识小区ID的唯一值。在预处理环节中,该方法将所获得的RSS进行标准化,使所有的RSS值转化至[0,1]区间内,以此提升训练速度。在数据增强环节中,文献[15]提出了4种增强方案:第1种方法为对每个样本添加加性噪声,其噪声为一个正态分布,该正态分布的标准差为在同一CID中所有样本RSS值的标准差;第2种方法为通过与现有数据对比得出RSS值更趋向于服从贝塔分布,随后通过对每个CID在每个分类位置建立贝塔分布并从中取样得到新的样本;第3种方法为对应包含多CID数据的样本,通过随机舍去来自每个CID的数据建立新样本;第4种方法为使用变分自编码(Variational auto‑encoder,VAE)生成新样本。最终结合上述方案,在室内与室外情况下分别达到了57%与50.5%的强化训练效果。文献[15]证明了在对无线信号特征进行深度学习的情况下,对数据集进行的预处理与数据增强能够极大地提升了整体定位性能。
文献[16]提出了一种对Wi‑Fi的信道特征基于深度学习进行室内定位的方案Deep Fi。在该方案中使用的是单个包含3根天线的AP,而定位目标为4 m×7 m与6 m×9 m的两组室内环境,每组分别包含54个与81个采样目标点,通过一个包含7层隐藏层的深度学习网络进行分类。最终证明深度学习方案拥有更高的精度:DeepFi在两种环境下的平均误差距离为0.95 m与1.8 m,以20%的性能优势优于细粒度室内指纹系统(Fine‑grained indoor fingerprint system,FIFS),Horus定位系统与最大似然(Maxi‑mum likelihood,ML)的平均误差距离则均大于2.6 m。该方案充分利用了MIMO系统的特性,对于每根天线采集其全部30个副载波上的CSI,从而在每个样本中有效利用90个CSI作为特征值。文献[16]提出了利用CSI覆盖面作为特征的定位方法,对于本文的研究起到一定的启示作用,同时也初步验证了深度学习作为定位方案相对于传统指纹定位方案与传统机器学习方案的优势性。
文献[17]提出了一种通过对Wi‑Fi的RSSI特征进行深度学习的室内外定位方法。该方法中使用了163个AP对91个1.8 m×1.8 m室内类进行定位,使用了359个AP对105个2 m×2 m的室外类进行定位,最终在室内环境下达到了0.398 m的平均定位误差,在室外环境下达到了0.368 m的平均误差。值得注意的是,文献[17]研究了对于不同学习算法而言样本库大小对最终定位均方根误差(Root meat square error,RMSE)的影响。文中定义总样本库为100N,并从该样本库中随机选取20N、40N、60N、80N以及100N作为样本库对不同算法进行基于RMSE的性能比对。结果表明,基于K最近邻(K‑nearest neighbors,KNN)、支持向量机(Support vector machine,SVM)或局部线性嵌入(Locally lin‑ear embedding,LLE)的定位算法在样本库扩张时相较于基于DNN的算法表现更差;在样本库扩张到100N时基于KNN、SVM与LLE的算法产生的RMSE与其在20N样本库时产生的RMSE的比值分别为247.3%、233.0%、250.4%。而基于DNN的两种算法中,当采用受限波尔兹曼机(Restricted Boltzmann machines,RBM)进行预训练时该比值为83.5%,采用堆栈降噪自编码(Stacked denoising au‑toencoder,SDA)进行预训练时该比值为120.6%。结果表明,对于无线信号特征值这种不稳定的大方差样本而言,基于神经网络的分类器具有优于其他分类器的抗干扰能力。
文献[18]提出了一种对CSI进行深度学习的无线定位方法ConFi。在该方法中使用了一个具有3个天线以及30个副载波的CSI采集系统,并对该系统得到的CSI值进行时间跨度上的组合。ConFi使用的并非是基于全连接的传统神经网络,而是基于卷积层的卷积神经网络,该方法对于大小为30×30×3的输入图像,使用了一个包含3层卷积层,每层卷积层均使用5×5的10个卷积核,最后连接一层有900神经元的全连接层与一层用于分类的全连接层的卷积神经网络进行学习。该文献与文献[16]一样,讨论了文中方法与基于RSS或CSI方法的性能对比,并得到了ConFi拥有更优性能的结论。同时文献[18]也将ConFi作为CNN基础的定位方法与其他DNN基础的定位方法的性能对比,其中包括文献[16]所提出的DeepFi,对比结果为:在平均误差方面,ConFi以9.2%与21.64%的性能提升分别优于DeepFi与DANN,由此证明CNN在提取CSI特征方面优于传统基于全连接层的DNN。
2 基于卷积神经网络的无线定位方法
2.1 输入数据构建
在当前的5G基站设备中多采用天线阵列的结构。天线阵列由多天线有规律地排布组成,在同一阵列中,任意两根天线的距离是已知的,由此每个阵列都可以通过信号强度差和相位差等数据配合天线间距计算得到一个定位结果。每个阵列都具有独立定位能力的优势在于不仅多阵列同时定位可以进一步降低误差,如果某个甚至多个基站到接收端的信号传播受到阻挡或干扰,只要存在任何一个信号正常传播的基站,便可以依据该基站的矩阵数据进行正确定位。
本文方法的重点之一在于使用卷积神经网络进行无线定位的特征数据学习,而输入数据构建是使用卷积神经网络学习中非常重要的一个环节。如前所述,卷积层在学习过程中是以卷积核为单位对输入数据进行多特征同步运算,卷积层所学习的数据特征也倾向于基于卷积核所覆盖的多个特征值产生的跨特征值综合性数据特征。因此在输入数据的格式构建时需要考虑矩阵构成中相邻的数据应当具有合理性,这种合理性是指在同时观察这些数据时应当能比单独观察其中某个数据获得更多的具备分类能力的信息。通过对输入数据的结构进行合理安排,卷积层可以在减少参数量的同时,每个卷积核都具有识别输入样本的分类能力,可以极大地提升神经网络的效率。从无线定位方法的角度来看输入数据与神经网络卷积层的关系,期望输入“图像”的相邻像素来自不同的源信号,这样能最大程度地利用卷积层的特性构成效果更好的神经网络。由于一般实际定位过程中所使用的硬件设备很少会使用多于4个的无线发射基站,故在分析中对数据来源做出假设时,本文也考虑终端所接收到的基站发射信号不多于4个。
2.2 算法步骤
为论述方便,不失一般性,假设待定位区域为一个矩形区域(在实际应用中可以考虑任意不规则形状区域)。图1为本基于卷积神经网络的无线定位方法原理图。基于卷积神经网络的无线定位方法步骤如下:
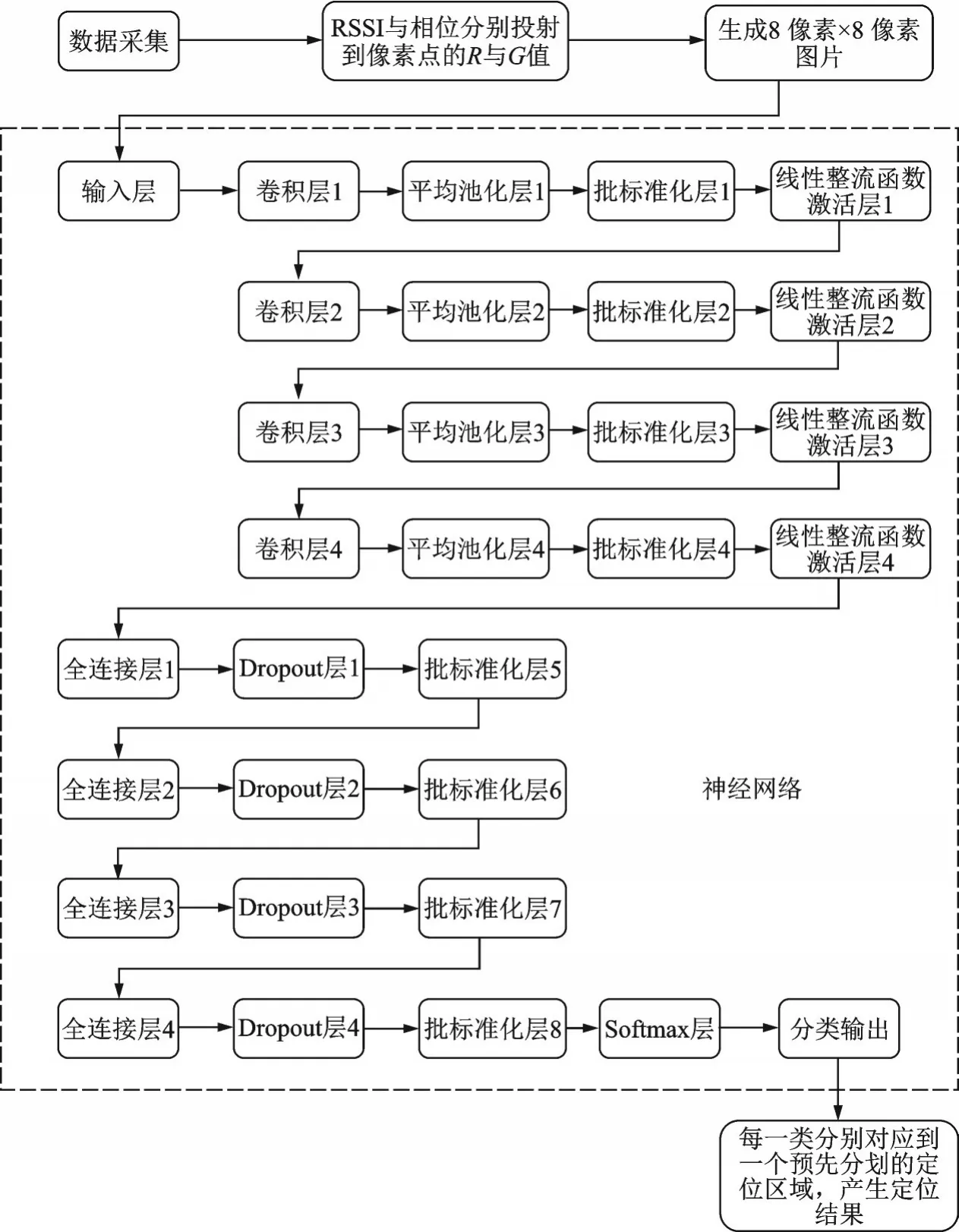
图1 基于卷积神经网络的无线定位方法原理图Fig.1 Diagram of wireless localization method based on convolutional neural network
(1)采集多个天线上的RSSI数据和TOA数据,并将TOA数据转换为信号相位数据;将同一天线、同一时刻的RSSI数据和相位数据均映射到0~255的整数区间,分别作为RGB空间中的R值和G值,形成一个像素点;将多个天线同一时刻对应的像素点组成一张图片,作为机器学习的输入。
(2)输入的图片依次经过多次卷积单元形式的子网络结构、多次全连接单元形式的子网络结构后进行分类。
(3)每一类分别对应一个预先划分的定位区域,分类结果输出得到定位结果。例如,根据经典开阔地的无线信号的空间衰落公式为
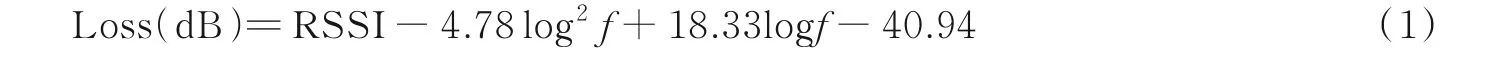
式中:Loss(dB)表示无线信号衰落的RSSI分贝值;RSSI为终端所接收到的RSSI数值;f为发射信号的频率。
除此之外,由于5G移动通信使用的频率包括0.5~6 GHz和毫米波24.25 GHz以上,路径损耗、阴影衰减、穿透损耗、植被损耗、人体损耗、大气损耗及雨衰损耗等都会引起相应电波传播时的衰减损耗。大量的科研组织和科技人员对5G移动通信无线传播模型展开了研究,其中有4个主要组织各自发布了5G传播模型,分别是:(1)3GPP,3GPP提供连续的工作进展报告,为5G行业提供国际标准,相应的5G传播模型文档为3GPP TR 38.901;(2)5GCM,5GCM是由15家公司和大学合作组成的特设小组,根据广泛的测量活动对3GPP的开发模型进行补充和修正;(3)METIS 2020,METIS 2020是由欧联赞助的大型研究项目组;(4)mmMAGIC,mmMAGIC是由欧联赞助的另外一个大型研究项目组。
需要说明的是,5GCM、METIS 2020、mmMAGIC所发布的传播模型都是在3GPP发布的模型基础上进行校正的,适用于特定的场景、环境和条件。在基于卷积神经网络的无线定位方法步骤(1)中,设D=10RSSI_m+RSSI_1-30,其中RSSI_m表示RSSI的测量值,单位为dB,RSSI_1表示1 m处的标准RSSI值,则有
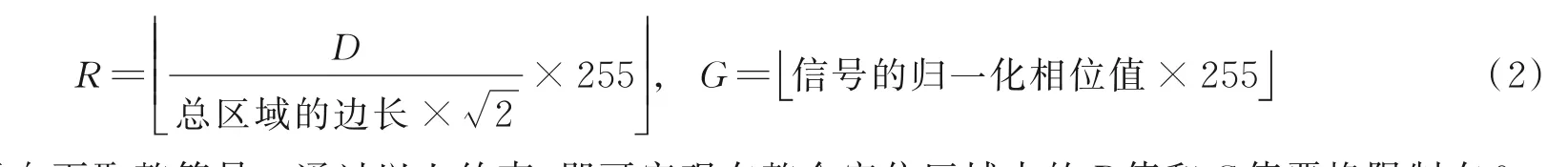
在步骤(2)中,所述卷积单元包括依次连接的2D卷积层、2D平均池化层、批标准化层和Relu函数激活层;多个卷积单元串联形成第一子网络结构;所述全连接单元包括依次连接的全连接层、Dropout层和批标准化层;多个全连接单元串联形成第二子网络结构;输入的图片经过第一子网络结构后进入第二子网络结构,分类采用全连接层到Softmax层,再到输出层的形式,即第二子网络结构的输出进入全连接层,再到Softmax层,最后由输出层输出分类结果。
图2为本文方法中定位区域RGB效果示意图,而图3则为在图2中右下角两个相邻区域的RGB效果示意图。从图3中可以较为清晰地看出,两个区域的RGB效果有着非常直观的差异,这种肉眼可见的差异性对于定位或区域分类来说具有十分重要的辨识度,对于有效提高定位区域的辨识度和提升整体区域的定位都具有非常重要的作用。

图2 基于卷积神经网络的无线定位方法定位区域RGB效果示意图Fig.2 RGB effect diagram of localization area by wireless localization method based on convolutional neural network

图3 图2右下角两个相邻区域的RGB效果示意图Fig.3 RGB effect diagram of adjacent localization area in Fig.2
3 性能分析
为了证明卷积层具有优越的无线定位能力,在性能分析中将使用不同尺寸的卷积核与步长,通过调整这些超参数来验证卷积层在本文无线定位方法中的作用。同时为了验证本文方法的通用性,本节将在几种不同的假设环境中进行仿真,分别涵盖不同大小的总区域与子区域。通过选取相同大小的总区域与不同大小的子区域,可以得到类尺寸的选取与最终平均定位误差的关系。由于采用了小区域仿真的方案,当随机选取出的(x0,y0)位置不同时,模型的性能会有少许差异,但经过反复随机与手动按照固定间隔选择(x0,y0)的验证可以保证该差异造成的性能评估参数差异不超过中位数的5%。
3.1 卷积层参数选取
本节使用的总区域为100 m×100 m的正四边形,子区域为1 m×1 m的正四边形,假设输入数据的来源为4组天线阵列,每组天线阵列包含4×4共16根天线,其产生的数据(包含RSSI与TOA)占据输入矩阵的4×4×2个单元,本节将在此基础上对卷积层进行调试。另外,为便于对比,对于不同方案使用相同的(x0,y0)。
方案1为在图1所示卷积神经网络的第1层直接采用4×4尺寸的卷积核,并采用[4 4]的步长进行实验。由前文的假设可以认为:卷积核共执行4次操作,并对4组天线阵列的特征值分组进行运算,以每一个阵列为整体通过相似度拟合近似的无线定位算法得到一个该天线阵列对应的定位信息。具体的相似度拟合近似算法有很多种,例如:在无线定位方法中单个天线阵列的RSSI和DOA信息已经具有独立的定位能力;或者由相邻天线的相位差(或时间差)信息,并结合所得到的信号到达角信息也可以进一步进行计算,得出定位信息等。在此方案中,同时考虑信号的相位差(或时间差)以及信号到达角来进行相似度拟合近似计算。在此基础上调试后续的隐藏层,可得出方案1的性能如表1所示。

表1 方案1性能结果Table 1 Performance results of Scheme 1
方案2在方案1的基础上稍做改变。首先通过减小步长到[1 1]从而允许卷积层进行跨阵列的运作,除了该步长外并不调整第1层卷积层内的其他超参数,即卷积核尺寸与个数保持不变,且与方案1相同。在卷积神经网络中这种步长的调整较为普遍,尤其是在如本文仿真的相似环境下,由于样本的特征值较少,理论上应当使用如[1 1]等更小的步长尽可能多地保留其特征量,并尽可能全面地学习信号的局部特征。在此条件下调试后续隐藏层并进行学习,获得方案2的性能如表2所示。

表2 方案2性能结果Table 2 Performance results of Scheme 2
通过对比表1与表2可以发现,小步长的方案2拥有更高的训练集准确率,然而有更低的测试集准确率,这意味着方案2产生了更严重的过拟合,且相较于方案1反而在一定程度上造成了定位性能的下降,更高的特征利用率反而降低了分类性能。使用本文提出的假设可以有效地解释这个现象:由于天线的排布规律在卷积核跨越天线阵列时发生了变化,同一个卷积核作为定位算法的特征提取模式,在卷积核内均为同一阵列与卷积核内包含跨阵列数据的两种情况下无法通用,这导致了跨天线阵列的卷积操作不能有效地产生定位依据,反而产生了不准确的定位依据,从而在一定程度上干扰了后续隐藏层的学习。从卷积层的工作逻辑上则可解释为,在从天线阵列数据中提取特征以完成定位的过程中,对完成定位更具有意义的是全局性的特征,而非局部性的特征。另外,方案2相较于方案1使用了更小的步长,而步长与该卷积层输出特征图的高度与宽度呈反比,这意味着方案2中该卷积层输出的特征量为方案1的16倍,但没有提升定位性能,只是单纯地增加了神经网络中流动的冗余特征量,增加了调试难度,以及训练与训练后分类的运算时间。通常,在进行卷积操作时选用的卷积核边长应为奇数,这是由于边长为奇数的卷积核更适合进行保留特征量的填充,同时奇数边长的卷积核在抵达边缘时由于具有对称中心,在提取特征时更为敏感。
方案3为假设使用4个仅包含9根天线的天线阵列,因此在方案1的基础上等比例缩小了输入的特征图以及卷积核的尺寸与步长,使用3×3的卷积核与[3 3]的步长。方案4则在方案3的基础上改为使用[1 1]的步长。两种方案性能对比如表3所示。从表3中可以得出,即使是使用更适用于小步长的特征精细提取的奇数边长卷积核,最终的性能对比结果与方案1、方案2的对比结果相同,精细的局部特征提取仅能增加过拟合并在一定程度上降低定位精度,而对天线阵列整体进行的全局特征提取则拥有较好的效果。

表3 方案3与方案4性能对比Table 3 Performance comparison between Scheme 3 and Scheme 4
3.2 卷积层在无线定位中的应用
本环境的设定为3.1节中的第1种情况:总区域为100 m×100 m的正四边形,子区域为1 m×1 m的正四边形。在此环境下生成10 000个训练样本与3 000个测试样本,训练样本采用70 d B信噪比,测试样本采用30 dB信噪比。设置学习速率为0.003,验证耐心为15。表4为在本环境下训练结束后训练集产生的混淆矩阵,其中R/C表示矩阵的每行为实际分类,每列为预测分类结果。为了便于查看,表中的第1行与第1列用于标注实际混淆矩阵行与列的序号,实际混淆矩阵从第2行第2列开始。混淆矩阵的行数和列数同分类数,因此本混淆矩阵应为25×25的矩阵,但由于篇幅限制,在表4中只展示其中的前12行与前12列。混淆矩阵由已知的训练集与模型预测的对应关系生成,其中每一行依次包含实际属于这一类的样本,每一列包含被模型预测到此类的样本。以表4的第7行为例(表中未能展示,但该行在第12列之后均为0),该行表明在测试集的第7类中总共包含397个样本,其中有372个被训练后的模型正确分类到了第7类,有7个被错误分类到了第2类,有6个被错误分类到了第6类,有12个被错误分类到了第12类。显然,混淆矩阵的左上‑右下对角线上的数值即为每一类当中被正确分类的样本个数,根据混淆矩阵可以快速计算分类准确率。同样地可以获得对测试集的混淆矩阵如表5所示。

表4 100 m比1 m环境下训练集混淆矩阵Table 4 Confusion matrix of training set in 100 m to 1 m environment

表5 100 m比1 m环境下测试集混淆矩阵Table 5 Confusion matrix of test set in 100 m to 1 m environment
从表4、5中可以看出,第x类最容易被错误分类至的类为第x-1类、第x+1类、第x-4类和第x+4类,对照几何关系可知,这些易混淆类即为正确分类相邻的类,这与前面所做的假设相吻合。结合表4、5可以得到训练集与测试集的两组性能评测数据。但为了证明本文方法的优势,进一步使用经典的RSS三边定位算法进行对比仿真。在RSS算法中使用与本文方法相同的采样方案,即在总定位区域内随机选取(x0,y0)并以此为原点向x轴与y轴正方向拓展出5个子区域边长,随后在此定位区域内随机取点获取RSSI进行后续分析。
在RSS三边定位方法的计算过程中,与卷积神经网络的测试集生成方案相同,取样本的信噪比为20 d B。每个阵列的16根天线所获取的数据都被充分利用以加权平均的形式降低噪声的影响。三边定位与卷积神经网络方法同样取3 000个测试点进行评估,不同的是由于没有类的划分因此不存在分类准确率,对该算法只计算平均距离误差。为了使该平均误差距离与神经网络的平均距离误差在同条件下比较,对三边定位产生的结果再进行额外的分类处理,通过将三边定位得到的接收端坐标与子区域的类进行对应从而获得三边定位所得的分类结果,同样计算得到以子区域偏移为基准的基于距离的误差。在最终得到了平均距离误差后,结合卷积神经网络方法的性能评测数据如表6所示。

表6 100 m比1 m环境下性能评测数据Table 6 Per for mance evaluation data in 100 m to 1 m envir onment
从表6中训练集准确率与测试集准确率可以看出,模型存在一定程度的过拟合,但测试集准确率仍然达到了较优秀的效果。对于测试集的处理速度足够快,平均每个样本仅需要1.56×10-5s。通过对比测试集平均误差与三边定位平均误差可以发现,本文方法所提供的定位精度优于传统三边定位的定位精度,其平均误差距离仅为传统三边定位的平均误差距离的17.90%。
3.3 大区域低精度要求下的结果与分析
本环境下总定位区域仍然维持100 m×100 m,但将类的精度降低,子区域大小调整为3 m×3 m。训练集与测试集的尺寸维持不变,仍然生成10 000个训练样本与3 000个测试样本;其信噪比维持不变,训练集使用70 d B的信噪比,而测试集使用30 d B的信噪比。取学习速率为0.003,验证耐心为15,训练结果如表7所示。

表7 100 m比3 m环境下性能评测数据Table 7 Per for mance evaluation data in 100 m to 3 m envir onment
对照表6、7可以得出,每一类子区域尺寸的提升将增加模型的准确率,但也会增加分类错误时产生的误差距离,因此平均误差距离有所上升。在本环境下子区域边长增加了200%,测试集平均误差增加了约93%,而三边定位的平均误差距离增加了近200%,本文方法平均误差仅相当于三边定位平均误差的12.42%,相较3.2节所述环境相对性能并未下降,说明在本节环境下本文方法仍然是一种具有优势的定位方法。
子区域尺寸是一个需要权衡的重要参数,然而对其进行选择的参考条件并不能在仿真环节中得到良好体现,这是由于子区域的选择直接关系到算法所期望的定位精度以及训练样本采集的困难程度,这些要素在实际实验中将会得到更好的展现。
3.4 小区域高精度要求下的结果与分析
本环境取总定位区域尺寸为10 m×10 m,子区域尺寸为0.1 m×0.1 m,总区域与子区域的面积比例与3.3节相同,但两者都进行了缩小。训练集与测试集的样本数量维持不变,仍然生成10 000个训练样本与3 000个测试样本;由于发射基站距离接收端距离更近,对信噪比进行提升,训练集使用70 dB的信噪比,而测试集使用30 d B的信噪比。取学习速率为0.003,验证耐心为15,训练结果的混淆矩阵略过不表,在混淆矩阵中观察,最易混淆的类是与正确类相邻的类依然成立,性能结果如表8所示。可以发现,在维持相同的总区域与子区域边长比的前提下,总区域与子区域的绝对边长对本文方法所构建模型产生的影响较小。准确率的下降可能是由于相邻两子区域之间的无线信号特征相似程度的大幅增加,因此神经网络更难对其进行区分。在本节环境下,本文方法与三边定位的平均距离误差比为15.65%,仍然占有绝对性的优势。

表8 10 m比0.1 m环境下性能评测数据Table 8 Performance evaluation data in 10 m to 0.1 m envir onment
3.5 性能对比与分析
本节采取与3.2节中相同的仿真环境,除3.4节中已使用的三边定位外,本节引入了传统指纹定位与传统机器学习的基于特征值指纹分类的定位方法作为对比方案。每一种分类器均使用AutoML对模型进行最优化调试,最终所得模型的性能对比如表9所示。由表9可见,在分类精度上本文方法与非卷积DNN、优化SVM的性能相近,然而本文方法在准确率、空间占用与分类速度上均优于非卷积DNN,而优化SVM的准确率虽然略高于本文方法,但其空间占用与分类速度相对本文方法而言劣势巨大,因此可以认为本文方法是一种性能优异的定位方法。
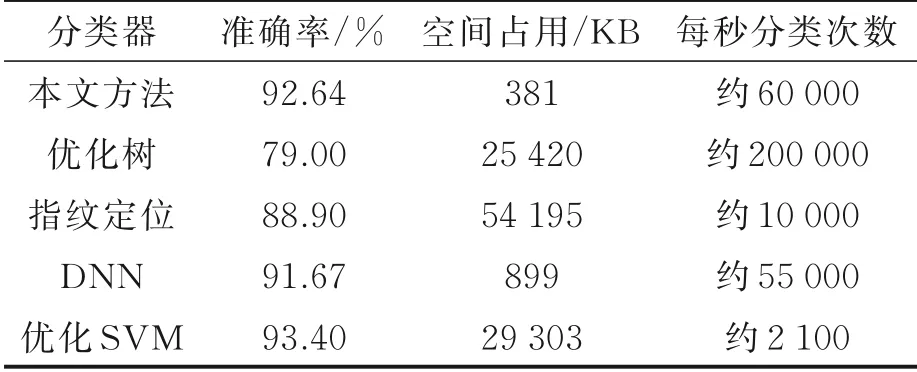
表9 不同定位方法性能对比Table 9 Performance comparison of different locati⁃zation methods
4 外场测试实验验证
4.1 室外实验
4.1.1 实验场景
本次实验场景位于某个特定的室外区域,3个无线小区ID分别注册为物理小区标识PCI=199,PCI=45与PCI=137。每个基站可以对接收端提供3种不同的特征:RSSI,定时提前值(Timing ad‑vance,TA)和DoA。其中TA是与距离相关的参数,而DoA在特征数据中又分为hDoA与v DoA,分别代表水平方向的波达方向角与竖直方向的波达方向角。样本的选取集中在“测试点位”区域,在该区域中间隔10 cm左右取一个采样目标点,在同一条直线上共取9个点作为9个类别。
4.1.2 数据采集
在实验中采集所得数据格式如表10所示,其中puschTa表示上行信道的时间提前量。表10展示了在其中一个点位,由PCI=199区域的基站提供的部分数据作为参考,可见基站返回的数据中包含时间戳与4种特征值。
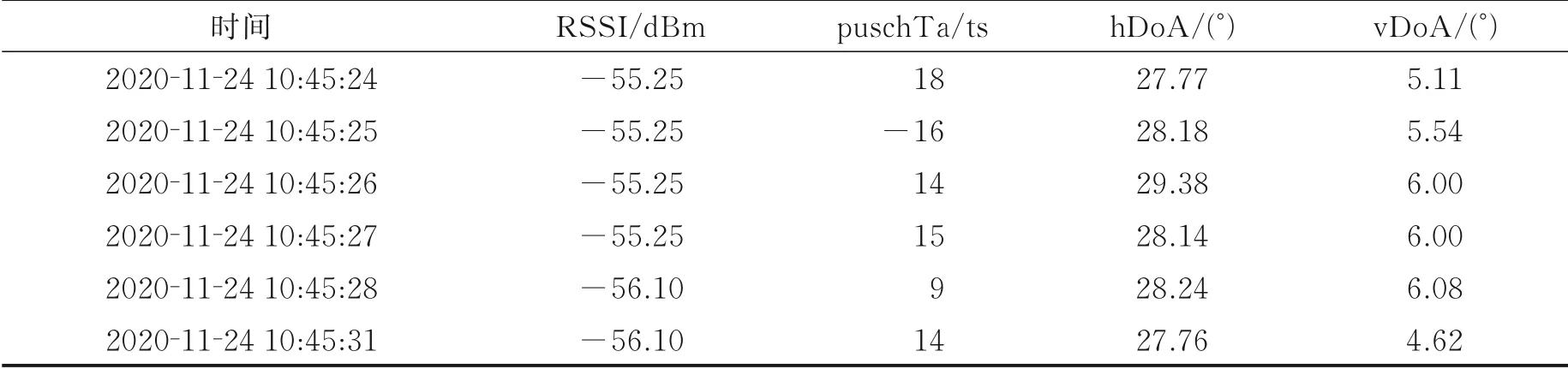
表10 室外实验采集所得数据Table 10 Data collected fr om outdoor experiments
综上所述,本实验过程中采用的训练数据格式为:抓取每个PCI样本中同PCI时间戳排序顺位相同的样本,并将其组合为一个用于训练的样本。如表11所示,本实验中使用的输入格式为3×4×1矩阵,其中同行的数据来自相同PCI,而同列的数据具有相同的特征类型。这种排布满足前文所述的相邻数据的组合,具有额外的定位价值,是一种合理的排布形式。由于样本中的特征值相较仿真实验更少,卷积神经网络的应用将得到进一步考验。最后,在训练前对数据集进行了预处理,消除了飞点与PCI数量不足3个的样本。相反,测试集应当反映实际应用的结果,不应当进行筛选,因此测试集一律使用的是未经任何处理而直接组合成输入数据格式的样本。

表11 室外实验输入数据格式Table 11 Input data format of outdoor experiments
4.1.3 现场实验结果分析
虽然实验中使用的数据受到限制无法直接获得多天线数据,但由于发射基站能够返回波达角作为额外的特征值,因此每个基站仍然具有独立的定位能力,从定位的概念而言与仿真中所使用的天线阵列相似。在此神经网络基础上进行训练时,由于数据本身已经是实测数据,不再对其添加噪声,而是直接使用。使用0.001学习速率进行训练后得到的结果如表12和表13所示。对比表12与表13可以发现,由于测试集数据为原始数据并未筛去飞点样本与PCI数量不足3的样本,导致测试集的分类结果中产生了一些与训练集的分类结果错误模式不同的随机错误。

表12 室外实验环境下训练集混淆矩阵Table 12 Confusion matrix of tr aining set in outdoor experimental environment

表13 室外实验环境下测试集混淆矩阵Table 13 Confusion matr ix of test set in outdoor exper imental envir onment
表14进一步给出了室外实验环境下性能评测数据。从表14中可以发现,本文方法最终的分类和定位效果极佳,虽然测试集准确率与训练集准确率的差距表明该情况下的过拟合比仿真更严重,但这是由于采集数据中的飞点与训练集本身较小的双重原因导致的。实验环境下的测试集平均误差大于3.4节仿真中小区域高精度环境下的测试集平均误差,这应当是由前述的飞点样本与PCI小于3的样本导致的不可预期误差。若要改善这些误差,降低PCI缺失样本造成的精度损失的最佳方案是从硬件或逻辑上改善数据采集方案,使得在实际运用时能够在短时间内(此处强调短时间内是为了保障定位的时效性,实际分类并不需求3个PCI返回的数据时间戳相近)抓取全部3个PCI的数据构成输入数据;若要降低PCI返回数据本身与平均数值相差过大造成飞点产生的精度损失,则应当从获取到的数据本身下手,通过在定位方案中加入已知定位区域的各个特征值合理上下限逻辑判定来直接丢弃误差严重的样本,并重新向相应PCI请求新的样本。

表14 室外实验环境下性能评测数据Table 14 Per for mance evaluation data in outdoor experimental environment
为了验证本文方法的有效性,同样将本文方法与其他分类方法进行对比,结果如表15所示。在本实验的性能对比过程中,通过使用AutoML对基于各类分类器的模型使用贝叶斯优化的超参数调整,确保模型性能后,从最优化的参数状态开始手动调整模型复杂度以权衡分类精度与模型体积,最后与本方法进行对比。由于三边定位、DOA、TDOA与AOA等计算型的无线定位算法在有建筑物遮蔽信号源的状态下不可使用,此处不进行对比。从表15中可以得到,在实验环境中虽然由于可利用的移动网络基站并不具有多天线分别返回特征值的能力,导致单个样本内的特征量减少至仅有12个,作为一种基于分类的定位方法,本文方法仍然对绝大多数同样基于分类的无线定位算法具有优势。传统的指纹定位与机器学习方案均在准确率上劣于本文方法,而非卷积的DNN分类方法在准确率上相对本文方法具有微弱优势。在本实验环境中由于样本复杂度低且样本库较小,本文方法在空间占用上与分类速度上的优势无法得以体现,但本文方法仍然是一种高效、高精度的无线定位方法。
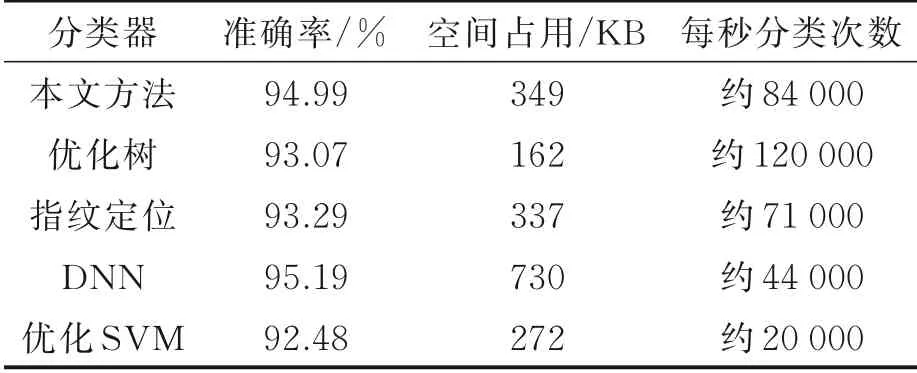
表15 室外实验性能对比Table 15 Compar ison of outdoor experimental per⁃formance
4.1.4 室外实验结果
以上主要介绍了室外实验的实验过程与实验结果。由于实际运用时的数据采集受到预定位区域可用的无线发射基站的硬件机能限制,因此仿真时所使用的输入数据格式与卷积神经网络构造均不可直接运用,但在经过对这两者小幅度修改以及对超参数的调整后,本文方法依然实现了与优于仿真环境的大于92%的定位准确率,达到了10 cm级别的定位精度误差,具有较优的定位性能。通过与其他定位方法的对比也证明了卷积神经网络即使在样本复杂度极低的无线定位中仍然具有良好的实践效果。
4.2 室内实验
4.2.1 实验场景
图4为自制室内数据采集App中的场景图,该室内场景为某电信营业厅,绿色标记为已采集子区域,蓝色标记为当前采集子区域,移动网络基站位置如图红色PRRU中所示,建筑承重柱等电磁波遮挡作用强的物体以黑色正方形与圆形标示,展示柜等电磁波遮挡作用低的物体用浅色线标示。

图4 室内实验环境图Fig.4 Indoor experimental environment map
4.2.2 数据采集
数据采集时的子区域分划中,每个网格的边长均为3 m,本次实验仅针对营业厅的一楼进行。由环境图可见大多数有效的采集区域集中在第1~7行以及第3~15列,将其命名为R1~R7以及C3~C15。同样地,由环境图可见,营业厅中存在部分子定位区域,其大部分面积均被不可踏入的物体所覆盖,例如R2C12被承重柱覆盖,R3C14在大门内部等,此类由于用户无法到达因而被排除在外的子区域共5个。如R5的C6~C10这种有一半面积被扶手电梯的底座所覆盖的子区域,则在其可供人行的部分进行数据采集。
以某一次采集为例,在每个子区域中采用4部手机同时进行数据采集,采集逻辑为以每秒一次的频率将手机所能检测到的所有移动网络基站的各类网络特征记录下来作为一组数据。在每个子区域内共采集1 min,采集过程中手持手机在靠近子区域中心的位置走动以增加样本的多样性。对从现场采集可用的数据来源手机中获取的数据集进行初步处理,将冗余的时间戳等数据删除后数据如表16所示,其中,AsuLevel为手机信号强度,RSRP为参考信号接收功率,RSRQ为参考信号接收质量。

表16 室内实验采集所得数据Table 16 Data collected fr om indoor exper iments
在对处理后得到的数据集进行分析发现,整个区域共有13个出现较为频繁的移动网络基站,通过识别其具有唯一性的PCI编号抓取每个移动网络基站对应的RSSI、RSRP与RSRQ值,并依序进行排布,最终构成一个13×3的矩阵,每个矩阵作为一个样本组成训练集进行训练。当一个样本中没有出现这13个标记PCI中的某个数据时,将样本中的RSSI、RSRP与RSRQ值以缺省值-131、-131与-22进行填充,这些缺省值来源于CellSig‑nalStrength类中对应返回值的值域下限。通过使用上述缺省值代替默认的0值可以减小PCI缺失时样本对神经网络产生的冲击,提升神经网络的整体性能。
4.2.3 神经网络的调整与训练
相较于之前的室外实验,本实验中所使用的输入样本包含更多的特征值,尤其是从卷积层的角度更关注的是每一层中所包含的特征值数量,而在本实验中该数量为195,和仿真过程中使用的每层64特征值更相近,在调整后发现相对室外实验所使用的神经网络,仅对第1层卷积层进行卷积核尺寸与数量的修改即可进行训练。
本实验中每个移动网络基站所具有的特征值为3个,由4.1节中的设想可知在第1卷积层使用3×3的卷积核与[3 3]的步长最为理想。在进行调参尝试后发现该参数确为理想参数,相较其他卷积核尺寸与步长而言有更高的准确率(平均约高3%)与更低的平均误差(平均约低0.15 m)。
4.2.4 现场实验结果与分析
将总数据集进行随机乱序处理,并从中以7∶3的比例分割得到训练集与测试集。调整训练超参数后,进行训练得到训练集、测试集混淆矩阵(部分截取)与训练集、测试集分类准确率与平均误差结果,如表17~19所示。由表17、18的混淆矩阵可以看出,对于部分子区域组合如子区域4与子区域5,其样本之间仍然存在严重的重合率。这主要是由于安卓系统所提供的类只允许输出最高精度为1的无线信号特征值,而对于某些相邻的子区域而言,其之间的特征值差距并无法达到该阈值,因此安卓系统返回了完全相同的值,因此该问题并没有有效的解决途径。由表19可知,本实验的训练结果没有产生过拟合,而在训练集与测试集中均有约23%的样本被错误分类。在平均误差的计算时,两个子区域之间的误差距离为子区域中心的距离,即产生错误分类时,若分类结果为正确结果相邻的子区域,其误差距离应为3 m。参考测试集的平均误差并对比分类结果可知,在所有错误分类中有85%的错误为分类至相邻子区域。进一步查看测试集中的错误分类样本与训练集中错误类内的样本发现,在错误分类中有95%以上均为由于测试样本与训练集中的其他类样本完全一致所导致,即上述暂无有效解决途径的数据采集误差。

表17 室内实验环境下训练集混淆矩阵Table 17 Confusion matrix of training set in indoor experimental environment

表19 室内实验环境下性能评测数据Table 19 Per for mance evaluation data under indoor exper imental environment
在本实验的性能对比过程中,通过使用AutoML对基于各类分类器的模型使用贝叶斯优化的超参数调整,确保模型性能后从最优化的参数状态开始手动调整模型复杂度以权衡分类精度与模型体积,最后与本文方法进行对比,结果如表20所示。与之前的室外实验相同,由于三边定位、DOA、TDOA与AOA等计算型的无线定位算法在室内隔断、水泥墙体等遮蔽物存在的非直射状态下不可使用,此处不进行对比。由表20可以得知,在本实验环境下,优化树方法拥有与本文方法相似的优秀性价比,而指纹定位、优化SVM与DNN等方案则分别由于空间占用与准确率性价比较低,性能不理想。
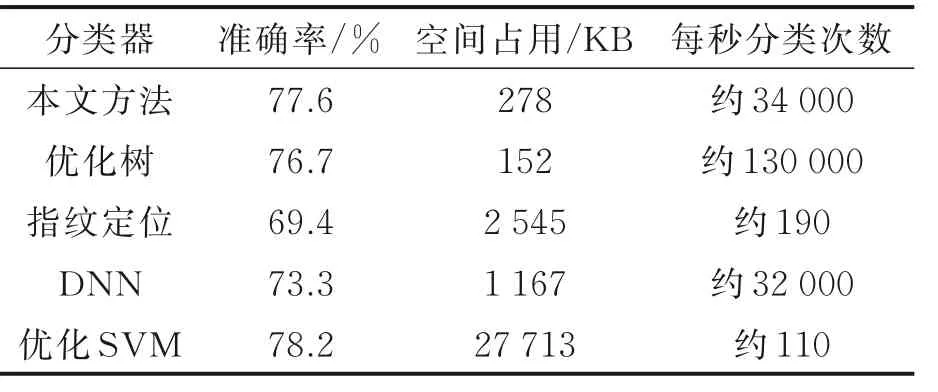
表20 室内实验性能对比Table 20 Comparison of indoor experimental per⁃for mance
结合上述性能分析、室外实验与室内实验三者的结果可以得到以下结论:(1)特征值精度越高,样本的多样性越强,重复率越低,则神经网络型的模型越具有优势;(2)样本量的增大对神经网络型与树型的模型会提升性能,负面影响很小,但会导致指纹定位型与SVM型的运算负荷与模型体积高速增加,降低其在移动端使用的性价比;(3)基于CNN的模型相对于普通基于DNN的模型具有更优秀的可学习参数利用率,能够以更小的体积与更高的运算速度达到相同或更好的精确度。

表18 室内实验环境下测试集混淆矩阵Table 18 Confusion matrix of test set in indoor experimental envir onment
4.2.5 实验小结
在包含不可避免误差的状态下,本实验最终得到的定位准确率为77.60%。对于通过分类器进行定位的方法而言这个结果虽然不够理想,但由于该误差来源的无法区分样本均在距离近的子区域之间产生模糊,最终产生的平均定位误差较低,从平均定位误差的角度而言,在较为复杂的室内实验环境下定位误差仍然能够达到0.739 5 m,效果较好。
5 结束语
本文提出了一种基于对5G蜂窝网络特征数据使用卷积神经网络进行深度学习的无线定位方法。该方法用一个训练后的卷积神经网络来替代指纹定位中的指纹库与邻近算法两部分:由于分类需求出现时不必计算数量正比于指纹库中样本量的距离值,本文方法可以拥有更快的分类速度;同时由于训练后的神经网络仅储存网络结构与每个隐藏层内的权重与偏置,将占用远小于指纹库的数据空间,对于移动端应用十分有利。结合仿真与两种不同实验环境的对比结果可以得到以下结论:基于神经网络的模型在使用5G蜂窝网络的无线定位中相较传统定位方案而言具有优势,且这种优势随着5G蜂窝网络特征值精度的提升与样本重复率的下降而增加。在基于神经网络的模型中,基于卷积神经网络的模型相较不使用卷积层的神经网络模型具有更高的性价比,这是由于卷积层的工作原理与无线定位对5G无线网络特征值的运用方式相吻合,从而可使用更少的可学习参数完成同等或更强的定位精确度,在模型占用体积与分类速度上产生优势。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
无线互联科技(2021年4期)2021-04-21
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
小猕猴智力画刊(2019年3期)2019-04-19
电子制作(2019年24期)2019-02-23
电子制作(2018年23期)2018-12-26
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
